電商評論中細粒度主題情感混合模型建構
2018-01-10 12:28:25張帆
商業經濟研究 2017年24期
張帆
內容摘要:本文對細粒度觀點挖掘的相關理論做了深入探討,詳細研究了LDA模型,又對該模型加以改進,提出了細粒度主題情感混合模型,該模型能對實體提取、意見詞識別、情感傾向分析、評論信息自動匯總分析、用戶評價等提供評價分析,為用戶提供直觀的信息。
關鍵詞:細粒度挖掘 電商評論 主題模型
研究的背景
用戶網絡購物時常常先查閱商品的評論信息,把消費者對產品或服務使用后的真實評價作為重要參考,商家也把評論作為反饋機制,自身產品與服務的不足之處可以從評論中得以發現,進而對產品進行改進或者對銷售策略進行調整。
近幾年來,網絡購物深入到青年、中年、老年等各個人群,購物結束后人們也越來越習慣于對商品做出評論,如此網站中電商評論的信息巨增,對于一件商品其評論信息會達到幾千甚至上萬條。消費者和商家都不可能對評論信息逐條閱讀,但僅看其中的一部分評論得到的結果卻又很片面。因此,從大量的評論信息中幫助消費者或商家提取有價值的信息成為當前最為迫切的問題,傳統的觀點挖掘方法對整條評論或對句子的層次做情感分析,這種方法不能反映產品或服務某種屬性的評價具體情況,只是對產品或服務的優劣情況做反饋。
針對電商評論的細粒度觀點挖掘,采用建構細粒度主題情感混合模型的方法對某個方面進行的挖掘,一方面能夠反映評論信息的整體評價,另一方面還可反饋用戶對產品或服務每個方面的評價褒貶情況,從而對消費者和商家提供更重要的、有價值的信息。消費者所關心的產品的某個或某些方面的評價從中可以直接地了解,進而在綜合考慮的基礎上,制定和自身利益相符的決策。產品和服務在具體方面的優缺點商家也可以從中獲得,在此基礎上對產品進行進一步改進,形成更合理、更合適的營銷方案。
細粒度觀點挖掘理論與相關個性化技術
(一)觀點挖掘的概念
觀點挖掘涉及到實體和觀點兩種相關術語,下面分別對其進行定義和解釋。
實體:實體通常由E(t,w)表示,E表示實體,T表示實體組件的層次結構,或子組件的層次結構,w表示實體E屬性的集合。以華為P10手機為例,它是一個實體,電池、屏幕、充電器等是這個實體的組成部件,大小、機身內存等是手機的屬性,每一個組成部件也有其自己的屬性,比如屏幕的屬性有可操作性、像素大小、屏幕大小等。其組成部分屏幕也有自己的屬性如顏色、可操作性。
實體是一棵倒樹型的層次結構。實體本身等同于樹的根結點,實體的組成部分或子組成部分處于樹的各個非根結點,每一個結點之間分別具有其聯系的屬性。
觀點:五元組結構表示法(ej,ajk,soijkl,hi,tl)常常用來表示觀點,其中每一個元素含義為:ej實體;aj實體的特征或方面;soijkl在特定的時間,觀點持有者的情感評價;hi做評論的用戶即觀點持有者;tl表述觀點的時間。這種五元組描述方法設計了一種框架,該框架能夠把無結構的文本轉化為結構化的數據,使用該框架可以完成對信息量眾多的數據實現量化分析。
(二)相關個性化推薦技術
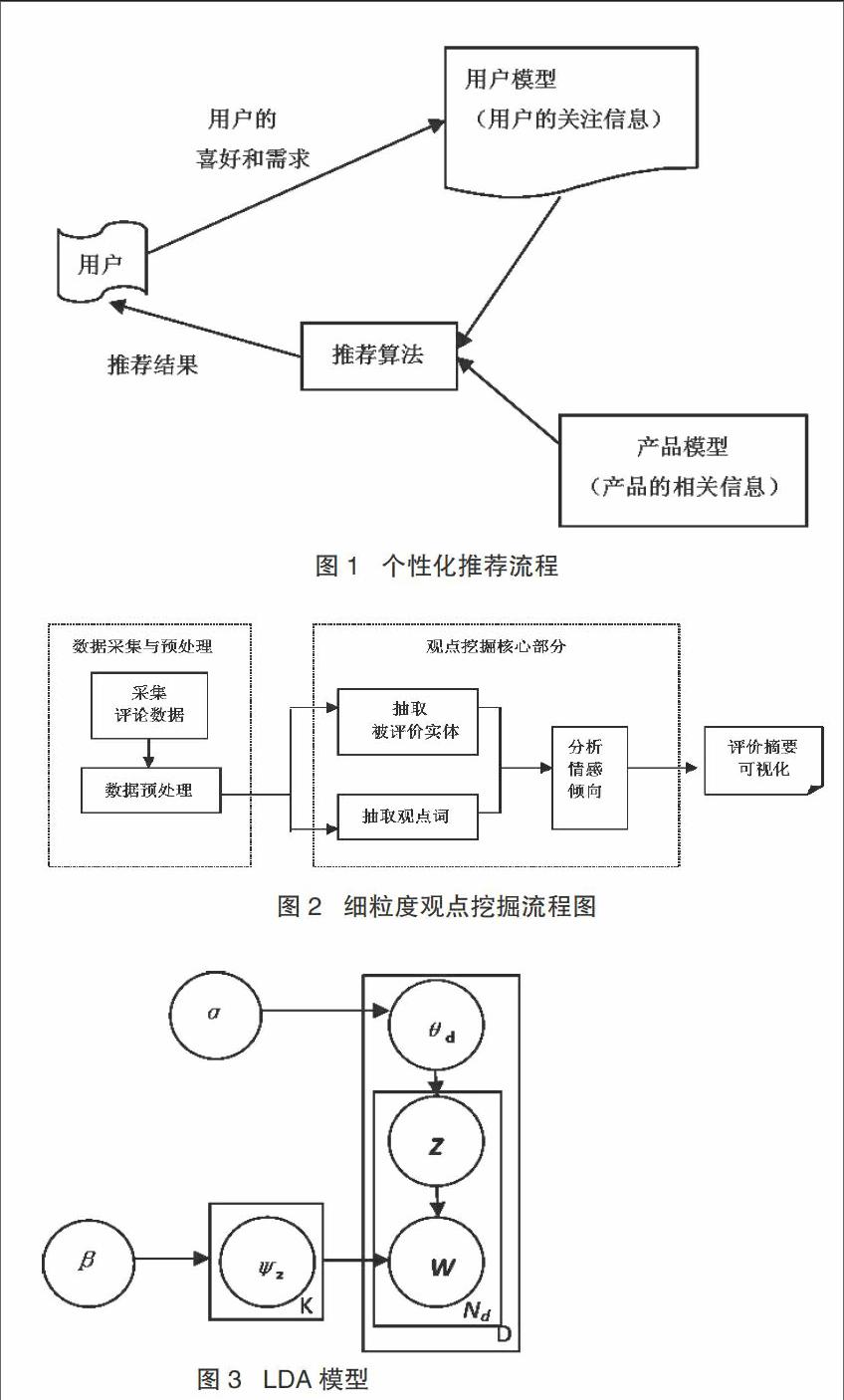
個性化推薦技術是在推薦技術基礎上發展和改進的結果,是目前被用來解決評論信息量過大的有效處理辦法。參考用戶的愛好及用戶日常的瀏覽足跡,個性化推薦系統綜合考慮推薦對象的特點,將推薦對象列表以個性化的方式向用戶推薦。個性化推薦如圖1所示,其過程為:根據用戶瀏覽歷史,對用戶的喜好、興趣與需求做出判斷;在眾多的用戶推薦對象信息中建設推薦對象模型;利用最佳推薦算法形成個性化推薦結果,并將推薦結果呈現給用戶。
當前,在處理評論內容信息量過大過程中,個性化推薦技術作為最有效的技術手段被普遍應用。該技術手段多采用基于內容的推薦算法、協同過濾算法和混合推薦算法。基于內容的推薦算法。此算法可以在用戶對推薦對象不做評價的情況下,能夠抽取出推薦對象內容的特征,還能夠依據用戶確定的對象的內容特點取得用戶的愛好,從而使用戶獲得與其愛好匹配率最高的對象。協同過濾推薦算法。此算法的推薦原則是:購物與生活習慣或喜好相近的用戶所需要的信息也是相同的。該推薦方法以過濾和選擇具有相似購物習慣的用戶為目標,統計用戶之間愛好的最大相似性。混合推薦。混合推薦算法綜合應用了基于內容的推薦算法和協同過濾推薦算法。
現在所使用的個性化推薦方法源于基于推薦的方法,用戶的評分信息評論被作為所使用的數據。由于用戶有時不是完全用心地給商品做出評價與評分,所以個性化推薦方法得出的結果不是特別有用。
(三)細粒度觀點挖掘
從研究對象層次方面劃分,觀點挖掘可分為三種層次類型,各類型及其研究層次如下:第一,把文檔作為分析基礎的挖掘即基于文檔級的觀點挖掘,在這種方法應用中整個評論信息在情感方面被分類處理。第二,基于句子級的觀點挖掘,這種方法與文檔級層面的區別是在于情感分類時基于評論信息中的句子級。不能獲得具體的細節信息是第一、二種挖掘方法的相同點。第三,基于方面級的觀點挖掘。前兩種觀點挖掘方法不能得到具體的細節信息,基于方面級的觀點挖掘又稱為細粒度觀點挖掘,使用過程中評論中的被評價實體方面被這種方法細節化,實體所有方面的詳細觀點和情感傾向都能被分析得出。實現較深層次的任務是細粒度觀點挖掘的一大優勢,另一優點是向消費者或商家提供被評價實體與之相關的情感觀點信息,細粒度觀點挖掘獲得的信息可以滿足用戶更高層次的需求。
(四)細粒度觀點挖掘承擔的主要任務
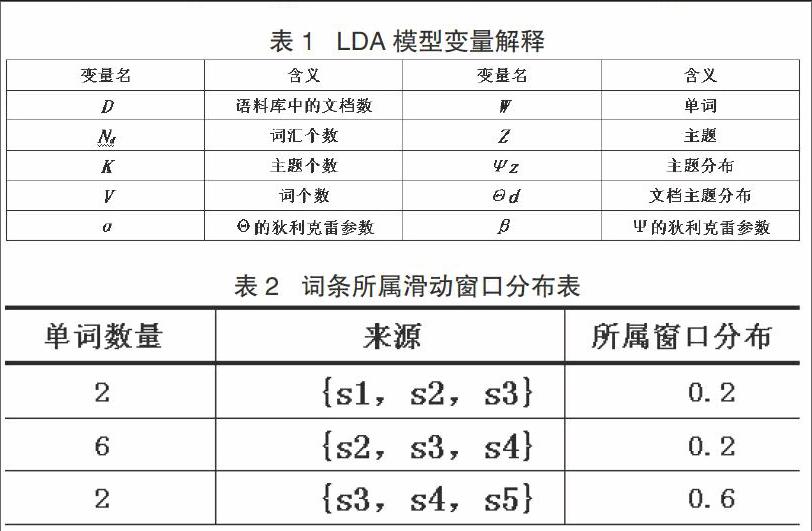
細粒度觀點挖掘的目標定在被評價實體方面的抽取,抽取過程中注重情感分析,即從眾多的評論中生成評價摘要。提取實體、提取意見詞和分析情感傾向是細粒度意見挖掘的三個主要任務。圖2展示了細粒度觀點挖掘的流程。
挖掘過程為:采集電商網上消費者的評論數據→過濾無用數據(數據預處理)→刪掉停用詞等→轉化數據,生成可識別的格式供算法使用→抽取被評價實體方面和觀點詞,在此基礎上從情感傾向角度進行分析→生成評價摘要且評價摘要可視化。endprint
細粒度主題情感混合模型
(一)主題模型
文檔中常常有一些隱含的主題,對于這些主題的建模采用主題模型的方法實現,每一個文檔的生成模型稱為主題模型。若干個詞語組成了文檔,文檔的形成包括以下過程:詞語確定主題;在這個主題中選擇詞語;不斷重復前兩步的選擇過程,從而生成文檔。
主題模型在上述選擇主題或詞的過程中均以采取相應的概率為前提,PLSA和LDA是電商評論中被普遍采用的兩種主題模型,這兩種模型在應用過程中的使用情況如下:PLSA模型容易出現過擬合,應在文檔層和主題層之間增加概率模型;LDA模型在PLSA模型基礎上做了改進,在文檔和主題層之間設置了超參數,解決了PLSA模型過擬合現象。
(二)LDA模型
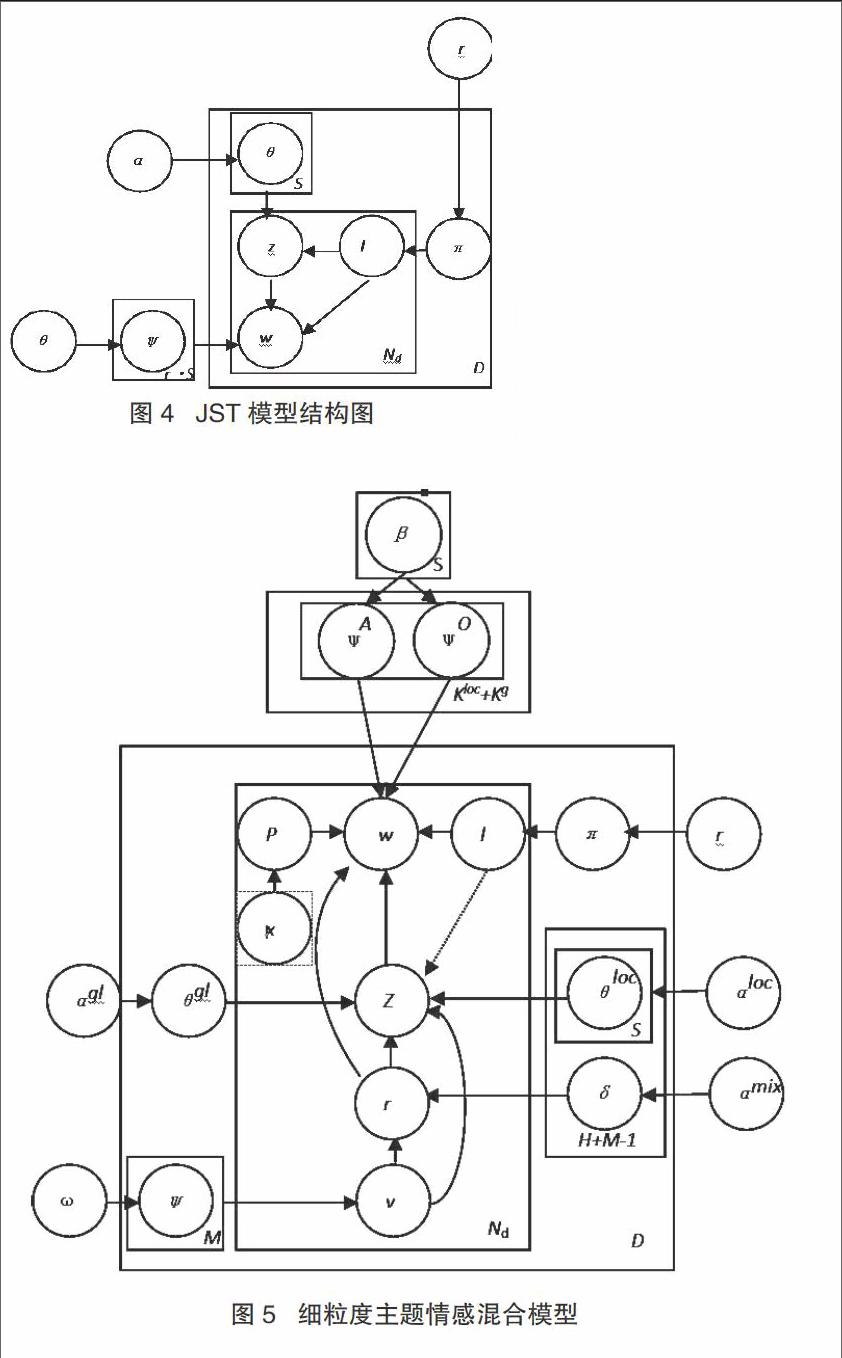
文本文檔的LDA模型被認為是由多個主題組成的概率分布,如圖3所示,它是由文檔、主題和詞組成的三層模型,每個主題的概率分布由多個詞組成。圖3中各變量的含義如表1所示。LDA模型先確定評論文檔的主題分布,再選擇一個主題,接著選擇一個詞語,從上一步驟生成的對應主題詞條分布中進行選擇,反復進行上述兩個過程,完成文檔的編輯后過程結束。
(三)細粒度觀點挖掘主題模型設計
細粒度觀點挖掘的實現目標有以下四個方面:在眾多的評論信息中進行抽取,獲得被評價實體方面和與其相對應的情感;生成評價摘要;為消費者和商家提供信息所需;為商家提供決策性支持。傳統的LDA模型由于使用文檔級的詞共現信息識別主題,因此聚類得到的主題粒度較粗,不能對被評價實體方面進行識別,另外LDA模型把詞和觀點詞集為一體,不能一目了然地呈現描述方面的詞和觀點詞,情感也沒有做建模處理,不能實現情感傾向分析。由于上述缺陷,對主題模型進行拓展和設計的重點應充分考慮被評價實體,應把評價實體方面的抽取做為改進工作的核心,兼顧考慮如何分離描述詞和情感詞。
細粒度觀點挖掘主題模型拓展設計如下:第一,引入滑動窗口。一篇評論文檔由若干個滑動窗口組成,使用拓展模型,對滑動窗口進行主題的抽取,局部主題被抽取后將幾個句子組成一個滑動窗口,例:一篇評論有5個句子,滑動窗口大小為3,則將有7種窗口,分別是{s1}、{s1,s2}、{s1,s2,s3}、{s2,s3,s4}、{s3,s4,s5}、{s4,s5}、{s6}。如果句子s3有10個單詞,各個詞的來源窗口分布如表2所示。由表2可知,同一個句子不僅僅只包含在相同的窗口中,不同的滑動窗口也可以包括相同的句子,處理單個句子級別詞共現缺乏時可以用這種方法。
第二,充分考慮用戶的情感傾向。在細粒度觀點挖掘中,不僅要識別被評價實體,還應了解用戶的情感傾向,解決這一問題的方法是將情感層加在文檔層與主題層之間,同時對主題和情感建模,從而實現對被評價實體方面的情感分析。增加情感層的主題模型相對于傳統的方法而言,充分考慮了情感傾向,各種主題與情感中的詞語分布情況都能夠通過被分析而獲得,情感所呈現出的正面與負面的情緒因素也可以被判斷,這樣便能夠達到觀點挖掘的目的。
第三,使用指示變量將情感與方面進行分離。分析結果中所有描述方面的詞和表述情感方面的詞構成了一個集合,稱之為詞聚類的集合,該集合作為主題模型的結果被輸出。為了將其分離,將模型中的詞進行分類,分為:方面詞和觀點詞。描述被評價實體某一方面的詞定義為方面詞,例如手機的“電池”方面上有“待機時間、耗電”等詞;觀點詞被用來描述或表達被評價實體方面,“高、低”、“長、短”都屬于觀點詞,模型中通過兩個增加變量可以將兩方面的詞分離,變量一決定詞是否存在情感字典中,變量二代表詞的類型。
(四)常用的情感主題混合模型
JST模型在LDA模型上進行進一步改進,增加了情感分析的功能,該模型的結構如圖4所示。由圖4JST模型結構圖可以看出:JST模型中,每個詞分別具有兩個屬性即主題和維度;JST模型為了實現情感分析的目標,在模型設計上充分顧及兩種關系:一種是情感與主題的關系,一種是情感與文檔的關系;每個情感的主題不是單一的,而是多個不相同的主題共存;情感維度決定了主題的生成;情感與主題兩個方面的信息生成詞。
(五)細粒度主題情感混合模型描述
細粒度主題情感混合模型如圖5所示。模型在LDA模型基礎上在以下幾個方面有了創新:第一,融入了情感信息,增加了情感層,每一個情感標簽用l表示,在模型中局部主題下兩種類型詞分布分別是ψ loc,AZ,l和ψ loc,OZ,l,它們分布在情感標簽l。第二,模型引入了滑動窗口,注重詞在文檔中局部共現,過而識別細粒度的主題。第三,為了便于區分方面詞和觀點詞,將兩個變量p和x引入模型,其中p是詞類型變量,x是指示變量,這兩個變量通過情感字典來構造,在整個過程中不必人工對其進行再標注。
參考文獻:
1.[美]劉兵.情感分析:挖掘觀點、情感和情緒.機械工業出版社,2017
2.老A電商學院.淘寶網店大數據營銷:數據分析、挖掘、高效轉化者.人民郵電出版社,2015
3.李進華.電子商務數據庫基礎與應用.首都經濟貿易大學出版社,2010
4.楊偉強.電子商務數據分析:大數據營銷、數據化運營、流量轉化.人民郵電出版社,2016
5.張鑫,朱振中.在線評論有用性影響因素研究綜述.商業經濟研究,2017(6)endprint
