建構反應題中能力估計準確性的影響因素:評分者人數和項目個數的交互作用
2018-03-01 03:32:38孫小堅康春花曾平飛
心理學探新 2018年1期
孫小堅,康春花,曾平飛,辛 濤
(1.北京師范大學中國基礎教育質量監測協同創新中心,北京 100875;2.浙江師范大學教師教育學院,金華 321004)
1 前言
建構反應題(Constructed Response item,CR題)因其可以對個體的分析、綜合、應用等能力進行較為準確地測量(康春花,辛濤,2010),受重視程度也日益增加。但由于CR題沒有統一的標準答案,因此需要額外的評分人員對學生的作答進行評分,而各評分員由于其自身的知識、能力、經驗和情緒狀態的不同,導致CR題的評分誤差相對較大(Attali,2014;Kim,Walker,& McHale,2010;周群,2007),以及不同評分員之間的誤差也各不相同(田清源,2006)。如此,評分者信度問題將受到一定程度的挑戰。如何一方面保證學生能力估計值的準確性,另一方面分離出評分者寬嚴度等隨機誤差的大小及其影響因素是當前研究的一個重要問題。
目前,從測量學的角度,主要通過多水平模型來分離學生能力水平、評分誤差及其影響因素,從而達到對學生能力特質更為精確的估計,如多水平隨機系數模型(Multilevel Random Coefficient Model,MRCM),廣義分部評分多水平側面模型(G-MLFM;Wang & Liu,2007)。然而,MRCM是線性模型,而G-MLFM不適于繼時性加工的任務情境(Andrich,1995;Tutz,1990)。為此,康春花等(2016)將多面Rasch模型、多水平模型和等級反應模型(GRM)三者結合,構建了等級反應多水平側面模型(Grade Response Multilevel Facets Model,GR-MLFM),并通過兩個模擬研究探討了GR-MLFM的返真性,結果表明:模型可以很好地估計出被試參數、項目參數和評分者參數,具有較好地適用性和可行性。GR-MLFM兼具多面Rasch模型、MRCM和GRM的特征,可用于CR題如數學應用題問題解決,公式推導等邏輯性強,解法多樣的評分情境,以考察評分者的寬嚴度及其相關的影響因素。根據GR-MLFM的特征,不難看出,在對CR題評分數據的分析中,影響GR-MLFM能力參數估計準確性的因素主要有被試特質、項目特質和評分者特質,而評分者特質又可包括評分者人數多少及評分者個人特質如評分經驗、人格特征等。
就被試特質而言,研究認為被試作答態度的隨意性和偶然性會影響其能力估計的準確性,偶然性作答分為兩種情況,一種是低能力被試答對較難的項目,另一種是高能力被試答錯較容易的題目,這兩種情況的出現均會影響對被試能力估計的準確性(戴海崎,簡小珠,2005;Wright,1977)。關于項目特質,有研究指出,在不增加評分者人數的情況下,通過增加測驗項目數便可以提高被試能力估計的準確性(Decarlo,2010;Decarlo,Kim,& Johnson,2011;Kim,2009)。而在評分者特質方面,有研究指出(Hombo,Donoghue,& Thayer,2001;Linacre,2007;Wolfe,2004),在固定項目個數的前提下,通過增加每個項目上的評分者人數則可提高能力參數估計的準確性。此外,評分者的評分經驗、人格特質等也會影響其評分的準確性,從而間接影響了對被試能力估計的準確性(Wolfe,2004)。
由上可以看出,以往研究對多水平IRT模型在被試能力特質估計準確性的影響因素上有所涉及,但在探討評分者人數和項目個數對被試能力估計準確性時,只對其中的一個因素進行分析,將另一個因素作為控制變量。而實際上,不同的題目個數或測驗長度,所需的評分者人數是否也存在不同?是否無論題目個數的多少,只要增加評分者人數就可達到準確估計的目的?為找到問題的答案,為主觀題測驗編制及評分設計提供有用信息,節約考試成本,研究擬基于GR-MLFM的模擬設計,進一步探討項目個數與評分者人數對被試能力估計準確性的影響模式。
2 方法
2.1 研究目的
采用康春花等(2016)提出的GR-MLFM探討項目個數和評分者人數對被試能力估計準確性的影響,以期為測驗的組織者在項目個數和評分者人數的選擇上提供參考。
2.2 研究模型
考慮到研究主要關注被試的能力估計準確性的問題,研究將使用GR-MLFM中的評分者固定效應模型,其公式如下
水平1公式:
(1)
水平2公式:
Bij=γijDr=γr
(2)


將式(1)和式(2)進行整合,得到:
(3)
2.3 模擬設計
2.3.1 評分情境
考慮到完全交叉設計在小規模評價中經常使用(Muckle & Karabatsos,2009;鐘曉玲,康春花,陳婧,2013),故研究以該設計為例。50個被試作答2到5個項目,同時2到5個評分者對所有被試的作答情況進行1到4級的評定,1表示作答情況非常差,4則表示作答情況非常好。
2.3.2 實驗變量
研究采用4 × 4的被試間實驗設計。自變量有兩個:項目個數(2個、3個、4個、5個)和評分者人數(2人、3人、4人、5人)。因變量有4個,分別為能力估計值與真值的相關r、偏差(Bias)、平均絕對偏差(Mean Absolute Bias,MAB)和誤差均方根(Root Mean Square Error,RMSE)。
2.3.3 參數設定
模型涉及到被試、項目和評分者三個層面的參數,各層面的參數設定如下:
被試參數:設定被試總體的能力均值為0,即γ00=0,各被試隨機效應從標準正態分布N(0,1)中隨機抽取。
項目參數:(1)為保證模型可被識別和方便設計,項目1的區分度參數固定地設置為1,而剩余的項目區分度則從對數標準正態分布中隨機抽取。(2)項目難度參數則從標準正態分布中抽取,考慮到每個項目均有3個難度閾值,此時將逐個生成項目的難度參數,具體過程為:針對第一個項目,從標準正態分布中隨機抽取3個值,之后對這3個值由小到大進行排序,最后將排序后的3個值分別作為該項目的第1、2、和第3個難度閾值。其它項目的難度參數也依此步驟依次生成。
評分者參數:Muckle和Karabatsos(2009)將Dr=1和Dr=-1 分別稱為評分者中等嚴格和中等寬松。研究將評分者參數限定在此區間內并進行細分,具體的寬嚴度為D=(-1,-0.5,0,0.5,1),而各評分者的具體寬嚴度值將從該向量中隨機抽取。
2.4 數據生成
被試的作答反應數據將通過R軟件自編程序實現。具體步驟為:(a)從標準正態分布N(0,1)中生成50名被試的能力值;(b)根據2.3.3章節中關于項目和評分者參數的設定方法生成相應的參數;(c)將生成的被試、項目和評分者參數代入到公式(3)中,計算相應的累積概率和類別概率;(d)將(c)中得到的累積概率和從均勻分布U(0,1)中生成的隨機數進行比較,如果該隨機數小于第一個累積概率,則令隨機數為1,若隨機數在第一個和第二個累積概率之間,則令隨機數為2,以此類推,最終得到所有評分者對于所有被試在所有題目上的作答數據。為減少抽樣誤差,每種實驗條件均重復50次。之后用R2OpenBUGS程序包在R軟件中調用OpenBUGS軟件進行參數估計,最終的估計值為50次估計值的均值。
2.5 評價標準
擬合指標有4個:估計值與真值間的相關r、偏差(Bias)、平均絕對偏差(MAB)和誤差均方根(RMSE)。其中相關系數r反映能力估計值與真值間的相互關系及方向;偏差則反映估計值與真值之間的系統誤差(de la Cruz,1996),越接近于0越好;MAB和RMSE則用于測量估計值與真值之間的整體誤差(Wetzel,B?hnke,& Rose,2016)這兩個指標則是越小越好。各指標的計算公式為:
3 結果
3.1 估計值與真值的相關
表1呈現了各實驗條件在50次重復試驗下各被試能力估計值與真值相關系數的描述統計量。由表可知,總體而言,隨著項目個數的增加,估計值與真值間的相關程度不斷加強,并且最大值與最小值之間的差距也在不斷縮小,且該趨勢不受評分者人數的影響。再者,當項目個數和評分者人數均為2個時,估計值與真值之間的相關最低,且其標準差最大(SD=0.051),說明二者間的相關有比較大的波動,該波動可從其變化范圍給予驗證。當然,需要注意的是當只有2個項目時,4種評分者人數條件下的能力估計值與真值的相關均在0.80以下,說明當項目個數相對較少時,被試能力估計值與真值差異較大,且不易受評分者人數的影響。此外,當項目個數為5個時,在4種評分者人數條件下被試能力真值與估計值間的相關均在0.90以上,且在4個評分者時達到所有條件下的最大相關(0.98),說明此時被試能力估計值與真值間的關系最為密切。
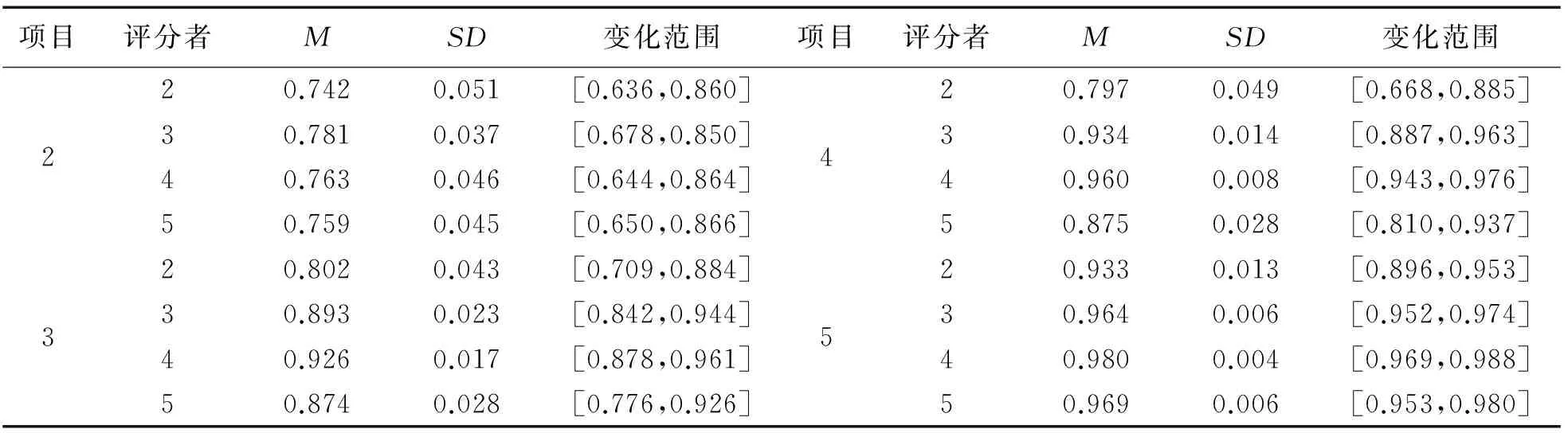
表1 各實驗條件下的相關系數的描述統計結果
3.2 估計值與真值的Bias
表2為各條件下的偏差統計結果。表中的結果顯示,在所有16種條件下,大部分條件下的偏差值為負值(10個),說明大多數條件下被試的能力值被低估。同時,不同項目個數下,各偏差值的范圍分別為:-0.083 ~ 0.135,-0.289 ~ 0.055,-0.134 ~ 0.124,以及-0.183 ~-0.101。可見,3個項目條件下的偏差變化最大,且大部分的偏差值均為負數,說明該條件下的被試能力易被低估。當具體到每一個條件時,2個項目和2個評分者組合下的偏差變化范圍最大(全距=2.584),且偏差的SD也是最大的,說明該條件下的能力估計值不穩定,模型無法較為準確地估計出被試的真實能力。其次,2個項目4個評分者組合下的偏差波動范圍和SD標準也相對比較大,在該條件下,模型也較難估計出被試的真實能力。
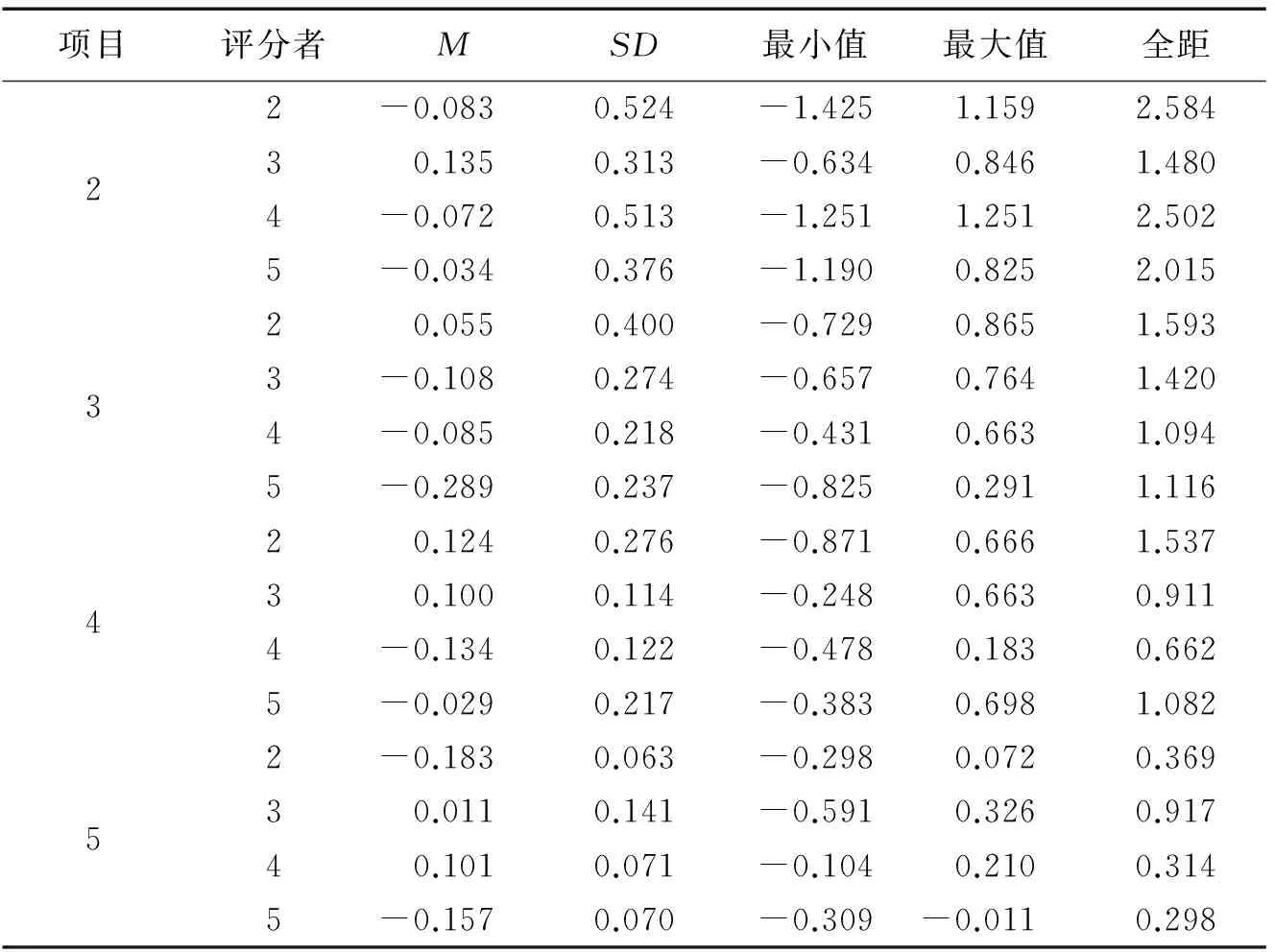
表2 各實驗條件下的偏差估計結果
圖1更為清楚地呈現了各組合條件下的偏差分布情況。由圖可知,5個項目3個評分者時的偏差值最接近0,而3個項目5個評分者條件下的偏差離0值最遠。此外,3個評分者和5個評分者在不同項目個數上的變化模式是一樣的,均為先向下,后向上,最后再向下的變化趨勢;而2個評分者和4個評分者的變化模式則相反:2個評分者的變化趨勢是先向上,然后再向下;而4個評分者則是先向下,然后向上變化,并與2個評分者發生交叉。

圖1 各實驗條件下偏差值分布情況
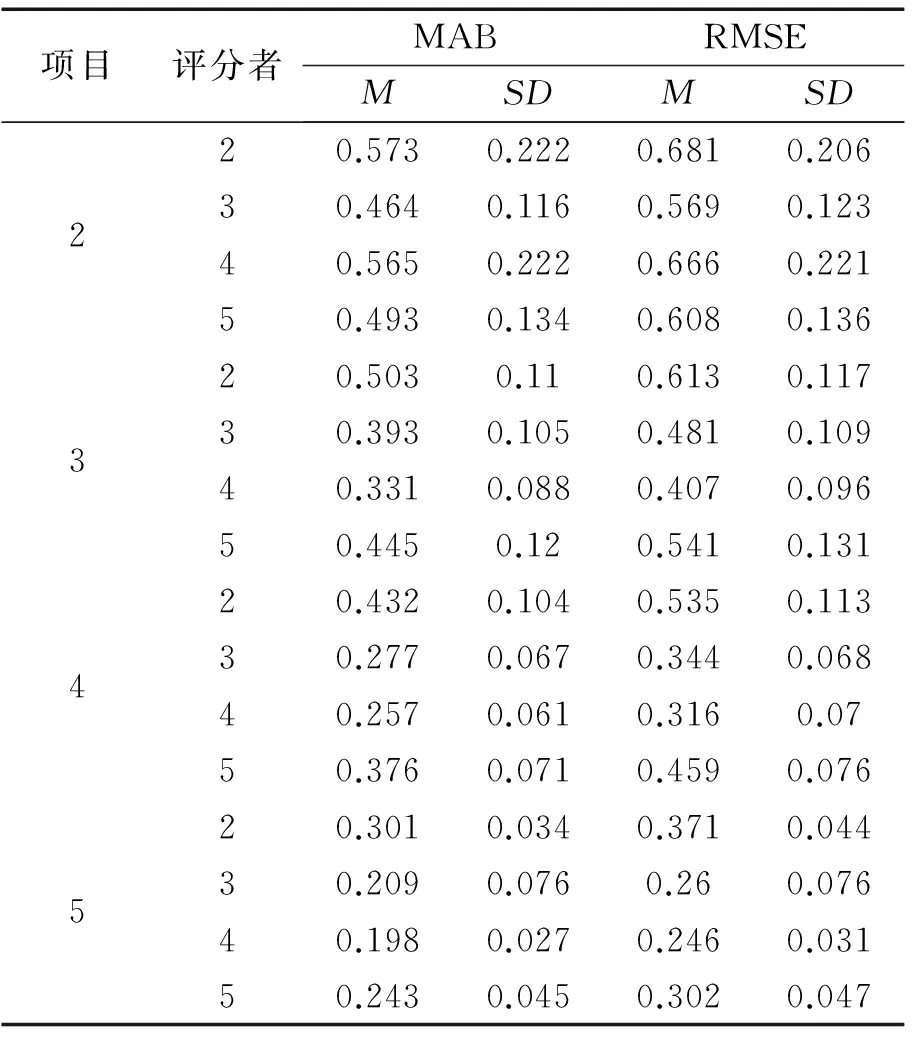
項目評分者MABRMSEMSDMSD220.5730.2220.6810.20630.4640.1160.5690.12340.5650.2220.6660.22150.4930.1340.6080.136320.5030.110.6130.11730.3930.1050.4810.10940.3310.0880.4070.09650.4450.120.5410.131420.4320.1040.5350.11330.2770.0670.3440.06840.2570.0610.3160.0750.3760.0710.4590.076520.3010.0340.3710.04430.2090.0760.260.07640.1980.0270.2460.03150.2430.0450.3020.047
3.3 估計值與真值的MAB和RMSE
表3呈現了被試的能力估計值與真值在50次重復條件下MAB和RMSE的描述統計量。由表3可知,5個項目4個評分者組合下的MAB和RMSE的均值和標準差均最小,而2個項目2個評分者組合下的MAB和RMSE的均值最大。各實驗條件下的兩個指標的標準差均比較小(分別為:0.027~0.222和0.031~0.221),說明兩個指標在50次試驗下的估計結果相對比較穩定。同時,各條件的RMSE和MAB的相對位置和發展趨勢是一致的。
方差分析的結果發現,RMSE的分析結果與MAB的結果大致相同,故研究只呈現MAB的結果。表4呈現了被試能力估計值的MAB的方差分析結果。由表4可知,評分者變量和項目變量二者均存在顯著的主效應;并且二者的交互效應也顯著,其效果量(ηp2)達到了中等效果量的標準(Cohen,1988)。

表4 能力估計值的MAB方差分析結果匯總表
由于評分者和項目個數二者間存在交互作用,有必要對它們進行簡單效應分析,二者的交互效應見圖2。經簡單效應分析發現評分者人數在項目個數上的簡單效應均顯著(2個項目:F(3,196)=4.407**,ηp2=0.063;3個項目:F(3,196)=23.714***,ηp2=0.266;4個項目:F(3,196)=56.477***,ηp2=0.464;5個項目:F(3,196)=44.514***,ηp2=0.405);同時,不同評分者人數在各個項目個數條件下的多重比較結果發現:2個項目情況下,2個評分者和4個評分者間的MAB不顯著,3個評分者和5個評分者間的MAB不顯著,其它的多重比較結果均存在顯著差異(此時,3個評分者時的能力估計準確性最高);3個項目情況下,不同評分者人數間存在顯著差異,此時MAB由小到大為4個、3個、5個和2個評分者;再者,在4個和5個項目情況下的MAB值由小到大的順序與3個項目情況MAB的順序相同,但無論是在4個還是5個項目情況下,4個評分者和3個評分者之間的差異均不顯著,而在其它評分者多重比較中(如2個VS. 3個、4個和5個評分者;5個VS. 3個和4個評分者)存在顯著差異。另一方面,項目個數在不同評分者人數也存在顯著的簡單效應(2個評分者:F(3,196)=36.631***,ηp2=0.359;3個評分者:F(3,196)=75.356***,ηp2=0.536;4個評分者:F(3,196)=84.555***,ηp2=0.564;5個評分者:F(3,196)=59.974***,ηp2=0.479),并且在4種不同評分者人數上均表現出項目個數越多表現越好的趨勢。

圖2 評分者人數與項目個數的交互效應
4 討論
作為教育與心理測驗中常用的考試題型,CR題評分的準確性會影響被試的測驗分數,而評分者效應作為CR題評分中的系統誤差(Scullen,Mount,& Goff,2000),該效應的出現一方面降低了評分者的信度,另一方面將極大地影響被試能力估計值的準確性。研究在前人的基礎上將評分者人數和項目個數兩個變量同時加以考慮,并使用康春花等(2016)提出的GR-MLFM來探討此二者的不同水平對被試能力估計準確性的影響。
4.1 項目個數越多能力估計準確性越高
通過模擬研究發現,隨著項目個數的增加,估計值與真值間的相關系數逐漸增大,該趨勢不受評分者人數影響,而偏差、MAB以及RMSE三個指標均不斷減小,說明被試能力估計的準確性在不斷增加,該結果與前人的研究結果及論斷相一致(Decarlo,2010;Decarlo,Kim,& Johnson,2011;Kim,2009)。該結果是可理解的,教育與心理測驗中,項目可以看作是測量被試潛在能力的外部行為指標,被試在項目上的作答反應是其能力的外在表現。IRT中,測驗所包含的項目數越多,測驗的標準誤就越小,則對被試能力的掌握情況越清楚,從而對其能力的估計就越發的精確(羅照盛,2012)。
4.2 項目個數不同,則所需評分者人數不同
事后分析的結果表明,隨著項目數的增加,評分者人數與能力估計準確性之間呈倒U關系。當被試作答的項目數比較少時,3個評分者的評分結果相對較好,此時被試的能力估計值比較準確;而當項目個數增加到3個時,4個評分者可以得到最優的能力估計值;此后,隨著項目個數的增加,3個和4個評分者得到的被試能力估計準確性并沒有顯著性差異,但此二者與1個和2個評分者條件下均存在顯著差異。此結果與前人的研究結果并不一致,前人的結果表明被試能力估計的準確性隨著評分者人數的增加而不斷提高(Hombo et al.,2001;Linacre,2007;Wolfe,2004)。出現不一致結果的原因可能是變量設置上的差異,前人的研究(如Hombo et al.,2001)主要是在控制項目個數的情況下,探討評分者人數對被試能力估計準確性的影響,得出評分者人數越多估計越準確的結論。但正如研究得出的結果所示,評分者人數與項目個數之間具有交互作用,如此,若只考慮評分者人數對能力準確性的影響,其結論可能有失偏頗。
與此同時,研究的結果也有較大的實踐意義。實際條件下,人們若為了提高被試能力估計的準確性而無限制地增加評分者人數,該做法將極大地增加測驗的成本,不利于測驗的發展。而本研究則說明,提高被試估計的準確性并不需要不斷增加評分者人數,只需將評分者人數控制在一定范圍即可。
4.3 研究展望
研究通過一個模擬研究得到了一些比較有指導作用的結果,同樣研究還存在一些值得進一步研究的地方,主要表現在:(1)評分情境的研究。研究采用的是完全交叉設計,該設計要求所有評分者評定所有被試的所有作答,其相對于嵌套設計和混合設計來說,評分者的工作量比較大,所需的資源也比較多,故當測驗的被試量較大時,該設計將變得較復雜和繁瑣,因此未來研究有必要探討在嵌套設計和混合設計下評分者人數與項目個數對被試能力估計準確性的影響。(2)項目參數的研究。研究使用2 ~ 5個項目進行研究,結果表明項目個數越多,能力估計準確性越好。那么,隨著項目個數的繼續增加,該趨勢是否會一直持續下去?也是未來值得關注的重要問題。
5 結論
研究通過模擬研究探討了項目個數和評分者人數對被試能力估計準確性的影響,得到以下幾個結論:
(1)項目個數和評分者人數的主效應和交互效應均顯著。
(2)無論評分者人數多少,被試能力估計值的準確性均隨著項目個數的增加而提高。
(3)項目個數不同時,被試能力估計的準確性隨評分者人數的不同而不同。項目數為2個時,3個評分者得到的準確性最高;隨著項目數的增加,4個評分者得到的能力估計的準確性變得最高。
戴海崎,簡小珠.(2005).被試作答的偶然性對 IRT 能力估計的影響研究.心理科學,28(6),1433-1436.
康春花,孫小堅,曾平飛.(2016).基于等級反應模型的多水平多側面評分者模型.心理科學,39(1),214-223.
康春花,辛濤.(2010).基于 IRT 的評分者效應模型及其應用展望.中國考試,(08),3-8.
劉紅云,駱方.(2008).多水平項目反應理論模型在測驗發展中的應用.心理學報,40(1),92-100.
劉慧,簡小珠,張敏強,熊悅欣.(2012).多水平 IRT 的發展與應用述評.心理科學進展,20(4),627-632.
羅照盛.(2012).項目反應理論基礎.北京:北京師范大學出版社.
田清源.(2006).主觀評分中多面Rasch模型的應用.心理學探新,26(1),70-74.
鐘曉玲,康春花,陳婧.(2013).基于 CTT、 GT、 IRT 的評分者信度研究——以某屆奧運會女子跳水決賽為例.考試研究,(05),41-52.
周群.(2007).主觀題評分標準研究.考試研究,(01),005.
Andrich,D.(1995).Distinctive and incompatible properties of two common classes of IRT models for graded responses.AppliedPsychologicalMeasurement,19(1),101-119.
Attali,Y.(2014).A ranking method for evaluating constructed responses.EducationalandPsychologicalMeasurement,74(5),795-808.
Cohen,J.(1988).Statisticalpoweranalysisforthebehavioralsciences(2ed).Hillsdale,NJ:L.Lawrence Earlbaum Associates.
DeCarlo,L.T.(2010).Studies of a latent class signal detection model for constructed response scoring II:Incomplete and hierarchical designs.ETSResearchReportSeries,(1),i-65.
DeCarlo,L.T.,Kim,Y.,& Johnson,M.S.(2011).A hierarchical rater model for constructed responses,with a signal detection rater model.JournalofEducationalMeasurement,48(3),333-356.
de la Cruz,R.E.(1996).Assessment-biasissuesinspecialeducation:Areviewofliterature.ERIC Document Reproduction Service No.ED390246.
Hombo,C.M.,Donoghue,J.R.,& Thayer,D.T.(2001).A simulation study of the effect of rater designs on ability estimation.ETSResearchReportSeries,(1),i-41.
Kim,S.,Walker,M.E.,& McHale,F.(2010).Investigating the effectiveness of equating designs for constructed-response tests in large-scale assessments.JournalofEducationalMeasurement,47(2),186-201.
Kim,Y.(2009).Combiningconstructedresponseitemsandmultiplechoiceitemsusingahierarchicalratermodel.Unpublished doctoral dissertation,Columbia University,New York,NY.
Linacre,J.M.(2007).Auser’sguidetoFacets:Rasch-measurementcomputerprogram.Chicago.Online:www.winsteps.com/facets.htm(01.02.08).
Muckle,T.J.,& Karabatsos,G.(2009).Hierarchical generalized linear models for the analysis of judge ratings.JournalofEducationalMeasurement,46(2),198-219.
Scullen,S.E.,Mount,M.K.,& Goff,M.(2000).Understanding the latent structureof job performance ratings.JournalofAppliedPsychology,85(6),956-997.
Tutz,G.(1990).Sequential item response models with an ordered response.BritishJournalofMathematicalandStatisticalPsychology,43(1),39-55.
Wang,W.-C.,& Liu,C.-Y.(2007).Formulation and application of the generalized multilevel facets model.EducationalandPsychologicalMeasurement,67(4),583-605.
Wetzel,E.,B?hnke,J.R.,& Rose,N.(2016).A simulation study on methods of correcting for the effects of extreme response style.EducationalandPsychologicalMeasurement,76(2),304-324.
Wolfe,E.W.(2004).Identifying rater effects using latent trait models.PsychologyScience,46,35-51.
Wright,B.D.(1977).Solving measurement problems with the Rasch model.JournalofEducationalMeasurement,14(2),97-116.
猜你喜歡
發明與創新(2022年30期)2022-10-03 08:40:56
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
動漫星空(興趣百科)(2020年12期)2020-12-12 05:31:40
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
人大建設(2018年6期)2018-08-16 07:23:10
文理導航·科普童話(2017年5期)2018-02-10 19:42:14
無人機(2017年10期)2017-07-06 03:04:36
