群組發(fā)展模型
——干預(yù)研究的新方法
2018-03-01 03:31:43呂浥塵
心理學(xué)探新 2018年1期
呂浥塵 趙 然
(中央財(cái)經(jīng)大學(xué)社會(huì)與心理學(xué)院,北京100081)
1 引言
心理學(xué)研究的目的是對心理與行為進(jìn)行描述、解釋、預(yù)測和控制(彭聃齡,2011)。其中控制是建立在描述、解釋和預(yù)測的基礎(chǔ)之上,對不利于發(fā)展的行為或心理狀態(tài)實(shí)施干預(yù)。心理學(xué)研究者一直致力于干預(yù)研究,試圖通過教育、咨詢、知識普及等方式改善個(gè)體行為,促進(jìn)個(gè)體的心理健康。
干預(yù)研究作為廣義追蹤研究的一種形式(劉紅云,張雷,2005),通常采用隨機(jī)對照實(shí)驗(yàn)設(shè)計(jì)(Lee et al.,2014),將被試隨機(jī)分配到干預(yù)組和對照組,在干預(yù)前和干預(yù)后對被試進(jìn)行多次的測量,關(guān)心干預(yù)組與對照組在平均水平和發(fā)展趨勢的差異。研究者不僅關(guān)注干預(yù)的即時(shí)效果,也越來越關(guān)注干預(yù)的持續(xù)效果(Armitage,Rowe,Arden,& Harris,2014),以及觀測值的整體發(fā)展趨勢、個(gè)體發(fā)展趨勢及趨勢中的個(gè)體差異等(李麗霞,郜艷暉,張敏,張巖波,2012)。
根據(jù)研究目標(biāo)的不同,采用的數(shù)據(jù)處理方法也有所差異。重復(fù)測量方差分析側(cè)重于總體平均發(fā)展趨勢,而潛變量增長曲線模型(latent growth curve model,LGM)和多層線性模型(hierarchical linear model,HLM)除了總體平均發(fā)展趨勢之外,同時(shí)注重個(gè)體發(fā)展趨勢之間的差異(劉紅云,張雷,2005)。唐文清、方杰、蔣香梅和張敏強(qiáng)(2014)統(tǒng)計(jì)了中國1982年至2013年發(fā)表的研究論文,發(fā)現(xiàn)2005年之前國內(nèi)追蹤研究主要運(yùn)用t檢驗(yàn)和重復(fù)測量方差分析追蹤數(shù)據(jù),2005年后多層線性模型、潛變量增長曲線模型等分析方法有所應(yīng)用,開始關(guān)注個(gè)體間的發(fā)展差異。
上述模型均假設(shè)研究樣本存在相同的發(fā)展軌跡,即內(nèi)部同質(zhì)(homogeneity),大多數(shù)個(gè)體具有共同的發(fā)展軌跡。然而很多心理狀態(tài)和行為的發(fā)展過程并不存在普適的變化趨勢,這一假設(shè)并非總能滿足(王孟成,畢向陽,葉浩生,2014)。
以未成年人加入不良團(tuán)體的研究為例。當(dāng)研究者認(rèn)為個(gè)體是同質(zhì)的,男生加入不良團(tuán)伙的概率在個(gè)體間是相同的,則可以用一條曲線模擬發(fā)展軌跡,如圖1中的左圖所示。而群組發(fā)展模型分析發(fā)現(xiàn),可以將群體進(jìn)一步分為三個(gè)亞組(如右圖所示)。其中,74.4%的青少年幾乎不可能加入不良團(tuán)伙,12.8%的青少年則是“青春期”組,而最后的一組為“童年”組占總體的12.8%(Lacourse,Nagin,Tremblay,Vitaro,& Claes,2003)。可以看出,群體中由此往往存在不同的發(fā)展軌跡。如果將個(gè)體視為同質(zhì),那么估計(jì)的概率會(huì)被“折中”。
干預(yù)研究也開始關(guān)注個(gè)體的異質(zhì)性(heterogeneity)(Peer & Spaulding,2007)。Nagin(1999)提出群組發(fā)展模型*巫錫煒(2009)曾將其譯為“組基發(fā)展建模”。(group-based trajectory model,GBTM),用以識別群體內(nèi)遵循不同發(fā)展軌跡的亞組,并描繪亞組成員的發(fā)展軌跡曲線。Eggleston,Laub和Sampson(2004)認(rèn)為群組發(fā)展模型是一種潛類別分析(latent class analysis),而紀(jì)林芹和張文新(2011)將其歸為潛類別增長分析(latent class growth analysis,LCGA)。

圖1 個(gè)體同質(zhì)與個(gè)體異質(zhì)發(fā)展軌跡對比
2 群組發(fā)展模型的異質(zhì)性
正如上文所說,多層線性模型、潛變量增長曲線模型認(rèn)為群體是同質(zhì)的,而群組發(fā)展模型的基本邏輯是群體具有異質(zhì)性,為了更好地說明個(gè)體異質(zhì)性,接下來將具體討論這三種模型的區(qū)別。
多層線性模型和潛變量增長曲線模型認(rèn)為個(gè)體可能存在變異性,并對這種變異性進(jìn)行檢驗(yàn)(截距和斜率),但是認(rèn)為群體中的個(gè)體是同質(zhì)的,群體只具有一般的發(fā)展軌跡。Morgan,F(xiàn)arkas和Wu(2011)使用多層線性模型分析兒童學(xué)習(xí)的發(fā)展軌跡,發(fā)現(xiàn)患有學(xué)習(xí)障礙或語言障礙的兒童與健康兒童在閱讀測試的平均值和變化速率(斜率)上均存在差異,并用種族、性別和自尊水平等因素解釋這種差異。
與上述兩種模型不同,群組發(fā)展模型認(rèn)為個(gè)體間的發(fā)展軌跡可能存在質(zhì)性差異,可以將群體劃分為不同的軌跡組(或亞組),群體是一個(gè)包括有限個(gè)軌跡組的混合。其中軌跡組的劃分是基于統(tǒng)計(jì)分析和相關(guān)理論獲得的,并非依據(jù)研究者的事后分析或特定的劃分標(biāo)準(zhǔn)而確定的。因此,群組發(fā)展模型具有一定的統(tǒng)計(jì)效度,能夠區(qū)分個(gè)體差異中的隨機(jī)變異和真實(shí)變異,可驗(yàn)證模型的擬合效果。群組發(fā)展模型更近于真實(shí)情況,在實(shí)際應(yīng)用中具有重要的意義。對17~42個(gè)月嬰兒的攻擊性研究發(fā)現(xiàn),可以劃分為三個(gè)軌跡組。28%的嬰兒屬于“低攻擊組”,攻擊性較低近似沒有;14%的嬰兒具有較高的攻擊水平,且不斷提高,為“高攻擊組”;大多數(shù)兒童(58%)則屬于“中度攻擊組”,具有適度的攻擊性,緩慢上升(Tremblay et al.,2004)。并且不同亞組的發(fā)展軌跡不同,其預(yù)測變量和結(jié)果變量很可能也有所差異。
基于兩個(gè)研究的對比可以發(fā)現(xiàn),潛變量增長曲線認(rèn)為群體是同質(zhì)的,分組依靠于測量指標(biāo),關(guān)注不同類型兒童的平均軌跡,以及個(gè)體特征如何影響個(gè)體對平均軌跡的偏離。群組發(fā)展模型則關(guān)注個(gè)體間的差異,識別潛在的軌跡組,包括不同軌跡的形狀、軌跡組間的差異、區(qū)別軌跡組成員的因素以及可能改變軌跡的事件等(Nagin,2005)。因此,這兩種研究方法是互相補(bǔ)充的,而不是相互對立的。潛變量增長曲線適用于分析具有共同發(fā)展軌跡的心理現(xiàn)象或行為,或特定分組(如性別、種族等)的發(fā)展軌跡等研究。而群組發(fā)展模型可以發(fā)現(xiàn)群體中無法確定亞組的、潛在的、具有質(zhì)性差異的發(fā)展軌跡,而且可以研究干預(yù)、轉(zhuǎn)學(xué)等轉(zhuǎn)折點(diǎn)對發(fā)展軌跡的影響。
王孟成、畢向陽和葉浩生(2014)指出,群組發(fā)展模型與潛變量混合增長模型(latent growth mixed model,GMM)是目前兩種最常用也是影響最大的處理群體異質(zhì)增長的模型。二者最大的區(qū)別在于,群組發(fā)展模型假定各軌跡組內(nèi)的個(gè)體具有相同的發(fā)展軌跡,組間同質(zhì)而組間異質(zhì),通過不同軌跡組之間的差異來估計(jì)發(fā)展軌跡中的個(gè)體變異。而潛變量混合增長模型在確定亞組軌跡的同時(shí),允許發(fā)展軌跡的增長參數(shù)(截距、斜率等)存在亞組內(nèi)變異(劉紅云,2007),模型的估計(jì)更加復(fù)雜。
3 基本模型的建立
3.1 建立似然函數(shù)
與傳統(tǒng)的聚類分析不同,群組發(fā)展模型的基礎(chǔ)是最大似然估計(jì),基其本思想是通過參數(shù)估計(jì)使得所有觀測數(shù)據(jù)發(fā)生的概率最大。群組發(fā)展模型認(rèn)為總體是由有限個(gè)潛在亞組構(gòu)成的,可以用有限個(gè)多項(xiàng)式函數(shù)進(jìn)行表達(dá)。每個(gè)亞組的發(fā)展軌跡不同,其概率分布也會(huì)存在差異。因此觀測值發(fā)生的概率依賴于個(gè)體i所屬軌跡組j的概率分布,以及個(gè)體i屬于該軌跡組的可能性πj。最大似然估計(jì)的目的就是得出令觀測值發(fā)生概率最大的參數(shù)值。
軌跡組的函數(shù)是觀測值關(guān)于時(shí)間的變化,必須要考慮到不同時(shí)間點(diǎn)間的關(guān)系,因此不得不提到群組發(fā)展模型的另一基本原理——條件獨(dú)立假設(shè)(conditional independence assumption)。這一假設(shè)認(rèn)為對于指定軌跡組j的每一個(gè)體,任意時(shí)間上測量值的分布獨(dú)立于之前時(shí)間點(diǎn)的測量結(jié)果。雖然這一假設(shè)看似難以置信,當(dāng)下的行為表現(xiàn)通常與之前的行為相關(guān),但是條件獨(dú)立性假設(shè)是假定個(gè)體的偏離程度之間互不存在相關(guān)。因此指定軌跡組j中觀測值的概率分布函數(shù)是相互獨(dú)立的,不包括之前的測量值的影響。
基于這兩個(gè)原理,可以建立兩個(gè)函數(shù)進(jìn)行估計(jì):(1)使用適宜的概率分布函數(shù)描述觀測值發(fā)生的概率,(2)以時(shí)間為自變量建立函數(shù)定義觀測值與時(shí)間的關(guān)系,從而將發(fā)生概率、觀測值、時(shí)間和參數(shù)聯(lián)系起來,進(jìn)行參數(shù)估計(jì)。
3.2 確定軌跡組數(shù)和軌跡形狀
群組發(fā)展模型中每個(gè)亞組均具有不同的軌跡趨勢,亞組的數(shù)量也就是描述發(fā)展軌跡的函數(shù)數(shù)量。因此,組數(shù)會(huì)影響最大似然估計(jì)中的參數(shù)數(shù)量,每個(gè)亞組的具體軌跡形狀,以及模型的擬合程度。所以建立群組發(fā)展軌跡模型的第一步,也是最具挑戰(zhàn)的一步就是確定軌跡組組數(shù)J。
首先,要明確劃分亞組的原則。群組發(fā)展模型假定軌跡組內(nèi)同質(zhì)而組間異質(zhì),組間的差異近似于群體差異。因此,劃分亞組的目的是發(fā)現(xiàn)具有相似發(fā)展軌跡的亞群體。模型應(yīng)該能夠以盡可能簡潔、有效的方式呈現(xiàn)群體中的差異(Nagin & Odgers,2010)。軌跡組的劃分不僅依賴于統(tǒng)計(jì)標(biāo)準(zhǔn),也要基于理論支持和一定的主觀分析。
在群組發(fā)展模型中,用于評估模型擬合的指標(biāo)包括貝葉斯信息標(biāo)準(zhǔn)(Bayesian information criteria,BIC)、赤池信息標(biāo)準(zhǔn)(Akaike information criteria,AIC)等,其中最常用的是貝葉斯信息標(biāo)準(zhǔn)進(jìn)行軌跡模擬,BIC=log(L)-0.5klog(N)(L是模型的似然值,N是樣本量,k是模型中參數(shù)的數(shù)量),最高的模型最為適宜。利用BIC選擇最佳擬合模型時(shí),需要不斷調(diào)整參數(shù)量,而參數(shù)量受到亞組數(shù)J和發(fā)展軌跡階數(shù)兩方面的影響。因此,Nagin(2005)提出選擇最佳模型為兩步:
第一步,預(yù)設(shè)方程階數(shù),估計(jì)模型的組數(shù)J。發(fā)展軌跡可以是零階(平坦直線),一階(有斜率的直線),二階(曲線)或者三階等等。其中二階曲線能夠反映出多樣的發(fā)展趨勢,較為靈活。三階函數(shù)太為復(fù)雜,難以抓取特征。因此通常假設(shè)發(fā)展曲線是二階的,從而確定組數(shù)。
第二步,組數(shù)確定的基礎(chǔ)上,調(diào)整方程階數(shù)使得軌跡擬合更優(yōu)。例如,第一步發(fā)現(xiàn)4個(gè)二階函數(shù)的軌跡組最優(yōu),但是其中一個(gè)軌跡組模型的標(biāo)準(zhǔn)差較大,或從經(jīng)驗(yàn)上認(rèn)為可能存在一個(gè)零階軌跡,則進(jìn)一步對比兩個(gè)模型。在組數(shù)J確定的基礎(chǔ)上進(jìn)行微調(diào),確定最為適宜的發(fā)展軌跡階數(shù)。
3.3 后驗(yàn)概率及模型檢驗(yàn)
群組發(fā)展模型建立之后,還需要檢驗(yàn)?zāi)P偷臏?zhǔn)確性,計(jì)算軌跡組分配的后驗(yàn)概率(posterior probability),判斷模型是否真實(shí)反映了樣本數(shù)據(jù)的情況。
對于已經(jīng)確定的模型,具有已知觀測值的個(gè)體在組J的可能性即為后驗(yàn)概率。可以通過在組J出現(xiàn)觀測值的概率計(jì)算而得,然后根據(jù)最大后驗(yàn)概率分配原則分派個(gè)體。
Nagin(2005)總結(jié)出四種檢驗(yàn)?zāi)P蜏?zhǔn)確率的具體方法,其中兩種方法以最大后驗(yàn)概率分配的準(zhǔn)確性為衡量標(biāo)準(zhǔn),另兩種方法則關(guān)注估計(jì)πi的準(zhǔn)確度:
(1)軌跡組中個(gè)體的后驗(yàn)概率均值大于0.7;
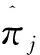
3.4 對軌跡組的概況描述
基于最大后驗(yàn)概率分配原則將個(gè)體進(jìn)行分配,即可獲得了每個(gè)軌跡組的成員構(gòu)成。結(jié)合樣本數(shù)據(jù)中的個(gè)體特征信息,就可以進(jìn)一步對不同軌跡組進(jìn)行簡單描述。
通常采用交叉列聯(lián)表的形式,不僅可以清晰呈現(xiàn)每個(gè)軌跡組中具有該特征的人員比例,而且可以比較不同軌跡組間的差異(如表1所示)。
需要注意的是,概況描述是基于后驗(yàn)概率之上的,而不是參數(shù)估計(jì)。概況描述只是描述性數(shù)據(jù),缺乏統(tǒng)計(jì)檢驗(yàn),只能說明每個(gè)軌跡組的個(gè)體更傾向于具有哪些特點(diǎn),無法證明這些特征會(huì)影響軌跡組的分配。在下一部分將會(huì)具體介紹如何進(jìn)行統(tǒng)計(jì)檢驗(yàn),發(fā)現(xiàn)影響個(gè)體進(jìn)入該軌跡組的因素。
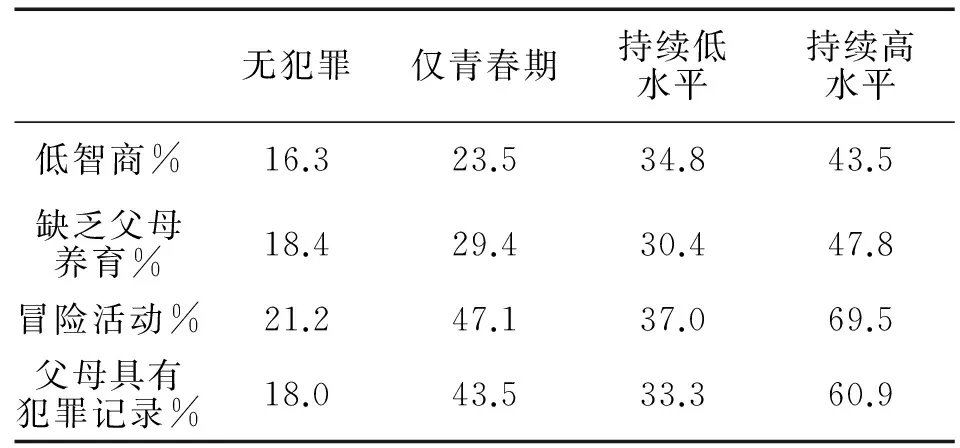
表1 犯罪軌跡發(fā)展曲線的概況描述
注:來自于Nagin(2005)
4 干預(yù)研究中的應(yīng)用
假設(shè)要研究記憶方法的干預(yù)對學(xué)生閱讀理解能力的影響,如何分析這一方法的學(xué)習(xí)對學(xué)生發(fā)展軌跡潛在影響呢?在群組發(fā)展模型中,描繪群體中結(jié)果變量的分布具有兩個(gè)核心指標(biāo)——發(fā)展軌跡和人員分配比例πj。因此群組發(fā)展模型對干預(yù)的研究存在兩種完全不同的邏輯。
一種研究邏輯是將干預(yù)視為預(yù)測變量(predictor),探討干預(yù)是否引起分組比例變化。其前提是認(rèn)為軌跡穩(wěn)定,干預(yù)只會(huì)改變個(gè)體所屬的軌跡組,影響人員分配比例πj。因此關(guān)注干預(yù)是否能夠預(yù)測分配比例πj。這種邏輯的核心在于,干預(yù)會(huì)引起質(zhì)的改變(從軌跡組1到組2)。
另一種則認(rèn)為干預(yù)是軌跡的轉(zhuǎn)折點(diǎn)(turning point),探討干預(yù)是否改變了發(fā)展軌跡。這種思路認(rèn)為人員分配比例πj是固定的,干預(yù)不會(huì)改變個(gè)體所屬的軌跡組,而是直接影響整個(gè)軌跡組的發(fā)展軌跡。研究者關(guān)注干預(yù)前后軌跡趨勢是否發(fā)生變化。因此,該邏輯傾向于認(rèn)為干預(yù)會(huì)導(dǎo)致量的變化(軌跡的扭轉(zhuǎn))。
4.1 作為預(yù)測變量
正如3.4所說,不同軌跡組發(fā)展軌跡的描述性數(shù)據(jù)缺乏統(tǒng)計(jì)檢驗(yàn),不足以確定該特征是否能夠預(yù)測分組。因此,確定預(yù)測變量需要進(jìn)行進(jìn)一步的參數(shù)估計(jì)。
發(fā)展軌跡是一個(gè)觀測值的長期發(fā)展趨勢。如果初始狀態(tài)時(shí)變量X的水平能夠估計(jì)個(gè)體未來的發(fā)展趨勢,那么X則是一個(gè)預(yù)測變量。因此若研究者將干預(yù)視為一個(gè)預(yù)測變量,則干預(yù)應(yīng)當(dāng)在第一次測量之前。
從統(tǒng)計(jì)分析上而言,當(dāng)個(gè)體i在變量X上的水平xi能夠有效預(yù)測人員分配比例πj,則變量X為預(yù)測變量。因此建立函數(shù)關(guān)系πj(xi),用Logit分布函數(shù)進(jìn)行參數(shù)估計(jì)。對于具有J個(gè)軌跡組的模型,需要選擇一個(gè)固定的對照組,對照組的參數(shù)設(shè)定為零,對其他J-1個(gè)軌跡組的參數(shù)進(jìn)行Z檢驗(yàn)。要進(jìn)一步比較J-1個(gè)軌跡組間的差異,可采用Z分?jǐn)?shù)檢驗(yàn)或Wald檢驗(yàn)。
4.2 作為轉(zhuǎn)折點(diǎn)
當(dāng)把干預(yù)視為發(fā)展軌跡的轉(zhuǎn)折點(diǎn)時(shí),干預(yù)發(fā)生在發(fā)展軌跡的時(shí)間區(qū)間內(nèi),基于干預(yù)之前的發(fā)展趨勢進(jìn)行對比。如果軌跡發(fā)生了變化,則說明干預(yù)使發(fā)展軌跡發(fā)生了偏離,干預(yù)對觀測值存在一定影響。這也是在干預(yù)研究中使用群組發(fā)展模型的優(yōu)勢之一。
除此之外,此時(shí)干預(yù)前后的比較是軌跡組內(nèi)的,均都具有相似的發(fā)展歷程,個(gè)體是同質(zhì)的。并且群組發(fā)展模型有助于發(fā)現(xiàn)發(fā)展軌跡和干預(yù)的交互作用,即干預(yù)對不同軌跡組的影響差異。但是需要注意,在群組發(fā)展模型中,是否參與干預(yù)往往不是隨機(jī)分配的,因此不能獲得因果結(jié)論,難以確定參與干預(yù)和結(jié)果變量之間的因果關(guān)系。
當(dāng)把干預(yù)作為軌跡的轉(zhuǎn)折點(diǎn),考察事件(或干預(yù))Z對發(fā)展軌跡的影響時(shí),需要建立事件Z和發(fā)展軌跡的關(guān)系,即重新建立關(guān)于時(shí)間的多項(xiàng)函數(shù)。
綜上所述,根據(jù)研究者關(guān)注的內(nèi)容和干預(yù)的程度,可以采用不同的方法進(jìn)行分析。如圖2所示,若認(rèn)為干預(yù)會(huì)引起質(zhì)的改變,則作為預(yù)測變量X,探討干預(yù)對分組的影響;如果只是發(fā)生量的變化則將其視為轉(zhuǎn)折事件Z,研究干預(yù)如何影響發(fā)展軌跡。
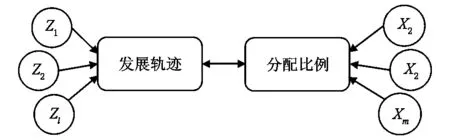
圖2 干預(yù)研究總模型
5 未來發(fā)展
Nagin和Land(1993)為了研究人群中犯罪行為的異質(zhì)性提出了一種統(tǒng)計(jì)方法,漸漸發(fā)展為群組發(fā)展軌跡模型,并嘗試將其應(yīng)用于各個(gè)領(lǐng)域,對模型不斷擴(kuò)展。為了解決干預(yù)研究中非隨機(jī)分組問題,可以將群組發(fā)展模型與傾向分?jǐn)?shù)模型(propensity score modeling)相結(jié)合,促進(jìn)因果推斷的獲得(Haviland,Nagin,& Rosenbaum,2007)。另外還提出了雙軌跡模型用以分析同時(shí)發(fā)展的兩個(gè)結(jié)果變量(Nagin & Tremblay,2001),以及多軌跡模型(Nagin,2005)。近年來,群組發(fā)展模型的應(yīng)用主要圍繞著犯罪領(lǐng)域(Ward et al.,2010),在干預(yù)研究中的具體應(yīng)用還較為缺乏。
目前有兩個(gè)成熟的插件用于分析群組發(fā)展模型:SAS程序的Proc TRAJ模塊(Jones & Nagin,2007)和Stata軟件的Traj插件(Jones & Nagin,2013),都可以從http://www.andrew.cmu.edu/user/bjones免費(fèi)獲得。
5.1 模型優(yōu)勢
(1)群組發(fā)展模型關(guān)注個(gè)體的異質(zhì)性,能夠識別群體中具有相似發(fā)展軌跡的個(gè)體,發(fā)現(xiàn)群體中典型的和非典型的發(fā)展歷程(Nagin & Odgers,2010);
(2)基于統(tǒng)計(jì)分析和相關(guān)理論劃分軌跡組,而不是根據(jù)特定的分組標(biāo)準(zhǔn)(如性別、種族)或事后分析,具有一定的統(tǒng)計(jì)效度,能夠區(qū)分個(gè)體的真實(shí)變異和隨機(jī)變異;
(3)可以將干預(yù)作為預(yù)測變量或轉(zhuǎn)折事件進(jìn)行分析,從不同角度考察干預(yù)作用。作為轉(zhuǎn)折事件進(jìn)行分析時(shí),在軌跡組內(nèi)進(jìn)行比較能夠發(fā)現(xiàn)干預(yù)前后軌跡的變化,以及干預(yù)對不同軌跡組的影響差異。
5.2 應(yīng)用局限
(1)群組發(fā)展模型是對縱向數(shù)據(jù)的分析,因此對缺失值的處理也是影響群組發(fā)展模型一個(gè)重要問題。雖然有相關(guān)的統(tǒng)計(jì)方法和模型有助于解決缺失值問題(Haviland,Jones,& Nagin,2011),但是缺失值的存在或多或少都會(huì)影響模型的可靠性。
(2)群組發(fā)展模型需要足夠的被試量。當(dāng)被試較少時(shí),觀察值較少,往往難以發(fā)現(xiàn)群體中比例較小的軌跡組。研究發(fā)現(xiàn)當(dāng)樣本量超過200之后,軌跡組的劃分趨于穩(wěn)定(Nagin & Piquero,2010)。
(3)軌跡組的劃分和軌跡形狀是非固定的,沒有最完美的模型。追蹤時(shí)間長短也會(huì)影響軌跡的擬合。
綜上所述,群組發(fā)展模型可以發(fā)現(xiàn)群體中無法確定亞組的、潛在的、具有質(zhì)性差異的發(fā)展軌跡,獲得不同軌跡組的分配比例和軌跡形狀,更接近生活實(shí)際。而且能夠獲得干預(yù)前后軌跡組的變化情況,以及對不同軌跡組的影響差異。因此群組發(fā)展模型對干預(yù)研究效果的檢驗(yàn)具有重要意義,可以有效出識別干預(yù)效果最好的群體,進(jìn)行針對性的干預(yù)。
紀(jì)林芹,張文新.(2011).發(fā)展心理學(xué)研究中個(gè)體定向的理論與方法.心理科學(xué)進(jìn)展,19(11),1563-1571.
李麗霞,郜艷暉,張敏,張巖波.(2012).潛變量增長曲線模型及其應(yīng)用.中國衛(wèi)生統(tǒng)計(jì),29(5),713-716.
劉紅云,張雷.(2005).追蹤數(shù)據(jù)分析方法及其應(yīng)用.北京:教育科學(xué)出版社.
劉紅云.(2007).如何描述發(fā)展趨勢的差異:潛變量混合增長模型.心理科學(xué)進(jìn)展,15(3),539-544.
彭聃齡.(主編).(2011).普通心理學(xué)(修訂版).北京:北京師范出版社.
唐文清,方杰,蔣香梅,張敏強(qiáng).(2014).追蹤研究方法在國內(nèi)心理研究中的應(yīng)用述評.心理發(fā)展與教育,30(2),216-224.
王孟成,畢向陽,葉浩生.(2014).增長混合模型:分析不同類別個(gè)體發(fā)展趨勢.社會(huì)學(xué)研究,4,220-241.
巫錫煒.(2009).中國高齡老人殘障發(fā)展軌跡的類型:群組發(fā)展建模的一個(gè)應(yīng)用.人口研究,33(4),54-67.
Armitage,C.J.,Rowe,R.,Arden,M.A.,& Harris,P.R.(2014).A brief psychological intervention that reduces adolescent alcohol consumption.JournalofConsulting&ClinicalPsychology,82(3),546-550.
Eggleston,E.P.,Laub,J.H.,& Sampson,R.J.(2004).Methodological sensitivities to latent class analysis of long-term criminal trajectories.JournalofQuantitativeCriminology,20(1),1-26.
Haviland,A.,Jones,B.,& Nagin,N.S.(2011).Group-Based Trajectory Modeling Extended to Account for Non-Random Subject Attrition.SociologicalMethods&Research,40(2),367-390.
Haviland,A.,Nagin,D.S.,& Rosenbaum,P.R.(2007).Combining propensity score matching and group-based trajectory analysis in an observational study.PsychologicalMethods,12(3),247-267.
Jones,B.L.,& Nagin,D.S.(2007).Advances in group-based trajectory modeling and an sas procedure for estimating them.SociologicalMethods&Research,35(4),542-571.
Jones,B.L.,& Nagin,D.S.(2013).A note on a stata plugin for estimating group-based trajectory models.SociologicalMethods&Research,42(4),608-613.
Lacourse,E.,Nagin,D.,Tremblay,R.E.,Vitaro,F(xiàn).,& Claes,M.(2003).Developmental trajectories of boys’ delinquent group membership and facilitation of violent behaviors during adolescence.JournalofAdvancedNursing,15(1),183-197.
Lee,C.M.,Neighbors,C.,Lewis,M.A.,Kaysen,D.,Mittmann,A.,Geisner,I.M.,& Larimer,M.E.(2014).Randomized controlled trial of a spring break intervention to reduce high-risk drinking.JournalofConsulting&ClinicalPsychology,82(2),189-201.
Morgan,P.L.,F(xiàn)arkas,G.,& Wu,Q.(2011).Kindergarten children’s growth trajectories in reading and mathematics:Who falls increasingly behind?JournalofLearningDisabilities,44(5),472-488.
Nagin,D.S.(1999).Analyzing developmental trajectories:A semiparametric,group-based approach.PsychologicalMethods,4(2),139-157.
Nagin,D.S.(2005).Group-basedmodelingofdevelopment.Cambridge,MA:Harvard University Press.
Nagin,D.S.,& Land,K.C.(1993).Age,criminal careers,and population heterogeneity:Specification and estimation of nonparametric mixedpoisson model.Criminology,31(3),327-362.
Nagin,D.S.,& Odgers,C.L.(2010).Group-based trajectory modeling in clinical research.AnnualReviewofClinicalPsychology,6(4),109-138.
Nagin,D.S.,& Odgers,C.L.(2010).Group-based trajectory modeling(nearly)two decades later.JournalofQuantitativeCriminology,26(4),445-453.
Nagin,D.S.,& Piquero,A.R.(2010).Using the Group-Based Trajectory Model to Study Crime Over the Life Course.JournalofCriminalJusticeEducation,21(2),105-116.
Nagin,D.S.,& Tremblay,R.E.(2001).Analyzing developmental trajectories of distinct but related behaviors:A group-based method.PsychologicalMethods,6(1),18-34.
Peer,J.E.,& Spaulding,W.D.(2007).Heterogeneity in recovery of psychosocial functioning during psychiatric rehabilitation:An exploratory study using latent growth mixture modeling.SchizophrRes,93,186-193.
Tremblay,R.E.,Nagin,D.S.,Séguin,J.R.,Zoccolillo,M.,Zelazo,P.D.,Boivin,M.,& Japel,C.(2004).Physical aggression during early childhood:Trajectories and predictors.TheCanadianChildandAdolescentPsychiatryReview,14(1),3-9.
Ward,A.K.,Day,D.M.,Bevc,I.,Ye,S.,Rosenthal,J.S.,& Duchesne,T.(2010).Criminal trajectories and risk factors in a canadian sample of offenders.CriminalJustice&Behavior,37(11),1278-1300.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
音樂探索(2022年2期)2022-05-30 21:01:37
體育科技文獻(xiàn)通報(bào)(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
小天使·一年級語數(shù)英綜合(2019年8期)2019-08-27 02:23:00
民用飛機(jī)設(shè)計(jì)與研究(2019年4期)2019-05-21 07:21:24
小學(xué)科學(xué)(學(xué)生版)(2018年7期)2018-08-13 09:33:04
