中文產品評論的維度挖掘及情感分析技術研究*
2018-03-12 08:38:03趙志濱
計算機與生活 2018年3期
趙志濱,劉 歡,姚 蘭,于 戈
東北大學 計算機科學與工程學院,沈陽 110819
1 引言
近些年,電子商務迅猛發展,消費者可以通過電商平臺完成在線購物和支付,這一方面提高了交易效率,同時也減少了商品流通環節和倉儲費用,降低了交易成本。為了提升服務質量和吸引消費者,絕大多數電商平臺都鼓勵消費者發表購物評論,以表達消費者對產品各個屬性維度上的意見。這些包含了消費者購物和產品使用體驗的評論成為一種重要的市場信息資源。消費者可以將他人的評論作為指引,了解目標商品在各個屬性維度上的指標或者優缺點,從而最大可能地實現理性消費和科學消費。對于商家或者生產者來說,這些消費者評論是最為直接和重要的市場反饋信息,據此可以了解市場需求,從而有的放矢地改進服務,提升產品質量,指導新產品研發,或者實現精準營銷。
一個商品會包含眾多的屬性維度,消費者的評論談及其中的某些維度,并包含針對具體屬性維度的評價,即維度情感。消費者綜合考慮不同維度的情感,潛在地為產品評論賦予整體情感。例如,表1中列舉了3條來自于京東商城洗衣液商品的評論。表2則是表1中3條評論所描述的屬性維度、維度情感和整體情感。
評論r1談到了商品的“香味”和“物流/送貨速度”兩個維度,且維度情感都為正面。顯然,評論r1的整體情感為正面。
評論r2談到了“物流/送貨速度”、“濃度”、“清潔效果”三方面,其中對于“物流/送貨速度”評價為正面,而對于“濃度”和“清潔效果”的評價為負面。顯然,r2的整體情感為負面。

Table 1 Examples of product's reviews表1 產品評論舉例

Table 2 Dimensions,dimensional sentiments and overall sentiments of reviews in Table 1表2 表1中評論的維度、維度的情感、整體情感
評論r3談到了“物流/送貨速度”、“易漂洗性”和“產品價格”3個屬性維度。同r2一樣,評論在不同屬性維度上所表達的情感有正有負。如果依靠傳統的情感標注方法,即整體情感是各個維度情感的簡單累加,那么r3的情感值將會被判定為負面。這顯然是錯誤的,因為評論中明確地表達了消費者繼續購買這款洗衣液的意愿。這也就意味著,消費者對于該產品的整體情感應為正。
從上面的例子中可以看出:(1)一條評論的整體情感是該評論所包含的屬性維度及其對應情感的綜合結果;(2)對于同一種商品,消費者對于商品的不同屬性的重視程度也不相同。反映到評論中,商品的不同屬性應有不同的權重,權重大的維度上的情感對于整體情感的影響也更大。換句話說,評論的整體情感不僅依賴于所包含的維度情感,也與屬性維度對于商品的重要性程度,或者說與消費者對于商品不同維度的關注度有關。
本文使用規則匹配的方法抽取評論維度,然后使用決策樹算法計算評論維度情感。雖然消費者對于不同產品維度的重視程度具有個體差異,但從群體來講,具有統計規律。因此,本文通過對人工標注數據集中的維度被提及的概率以及維度情感和總體情感的一致性分析計算維度權重。評論的整體情感是維度情感的加權累加。本文主要貢獻如下:
(1)構造了包括詞語搭配關系的維度詞典,并實現了基于詞典的評論維度挖掘;使用卡方統計對維度詞典進行擴充。實驗結果表明,基于詞表的規則匹配方法在維度挖掘方面具有很好的準確性,結果的可解釋性也更好。
(2)使用監督學習的決策樹算法進行維度情感分類,其中使用最小Gini系數選擇分裂屬性。實驗表明,這種方法可以得到較好的維度情感分類準確性。
(3)用戶對產品各個屬性的重視度不同,因此評論中各個維度的權重對于評論整體情感的影響也不同。本文提出了維度權重計算方法,其中考慮了維度在評論中的提及概率以及維度情感與整體情感的一致性,最后綜合維度情感和維度權重來計算評論的整體情感。
在此需要特別指出的是,本文在評論有效性判定、評論維度抽取方面采用的是規則匹配的方法,其基礎是維度詞典,因此只適用于中文評論文本。但是,本文所提出的處理思想可適用于其他語言的評論文本挖掘工作。
本文組織結構如下:第2章是相關工作,介紹了維度抽取和文本情感分析方面已有的最新研究成果;第3章給出了本文工作的相關概念以及符號定義,包括問題的形式化描述;第4章詳細介紹了維度抽取、維度情感分析、維度權重計算以及評論整體情感計算方法;第5章介紹了實驗細節,并分析了實驗結果;第6章總結全文,并提出后續的研究計劃。
2 相關工作
本文工作的核心是評論維度抽取和評論情感分析。現就這兩方面的最新研究成果進行總結。
如果把每一個產品維度都看作是一個標簽,那么一條評論包含多個產品維度,也就應被分配多個標簽。因此,評論文本的產品維度抽取,本質上是一個多標簽分類問題,這是學術界關注的一個熱點問題。大體上,解決多標簽分類問題可以有三種方法:傳統的機器學習算法、深度學習算法和基于詞表的規則匹配算法。Zhang等人[1]系統地總結了多標簽機器學習算法:(1)一階算法,假設標簽之間相互獨立,那么就可以把多標簽分類問題轉換為一系列獨立的傳統分類問題。典型的一階算法有BR(binary relevance)[2]、ML-kNN(multi-labelk-nearest neighbor)[3]和ML-DT(multi-label decision tree)[4]。(2)二階算法,考慮了標簽之間的兩兩相關性,這也導致了二階算法較一階算法的計算復雜度有顯著的增加。典型的二階算法有Calibrated Label Ranking[5]、Rank-SVM(ranking support vector machine)[6]和 CML(collective multi-label classifier)[7]。(3)高階算法,考慮多個標簽之間的相關性,自然計算復雜度會更高。典型的高階 算 法 有 Classifier Chains[8]和 Randomk-labelsets[9]。Zhang等人[10]研究了維度抽取和實體抽取兩大核心問題,分析了維度抽取的3種主要方法,并提出了基于半監督的實體抽取方法。近些年,深度學習技術被應用到了解決多標簽分類問題上。例如,Read等人[11]使用Restricted Boltzmann Machine構建隱含層,既提高了分類的準確性,也降低了分類時間。
無論是機器學習方法,還是深度學習方法,在解決多標簽問題時,都存在著兩個棘手的問題:第一,高質量訓練數據的獲取問題。這里高質量的含義是既要準確,又要充分。但是當標簽數量很多時,數據傾斜現象會非常嚴重,某些標簽下很難獲得充足的訓練數據。這就導致了機器學習算法,或者深度學習算法對這些標簽的分類結果準確性下降。第二,結果缺乏可解釋性,難于進行調試。上述兩個缺點是機器學習算法和深度學習算法工程應用的巨大阻礙。
文本情感分析又稱文本傾向性分析、意見挖掘,它是對帶有情感色彩的主觀性文本進行分析、處理、歸納和推理的過程。文本情感分析的方法主要分為兩類:一是基于情感詞典的文本情感分類方法;二是基于機器學習的文本情感分類方法。
基于情感詞典的文本情感分類方法的基礎是準確而且全面的情感詞典。Tong等人[12]人工抽取影評領域的詞語,并進行極性(position/negative)的標注,從而建立了專門的情感詞典。Hu等人[13]通過使用已標注極性的形容詞,結合WordNet中詞間的近義、同義關系來判斷新詞的情感極性,以計算主觀文本的情感極性。為了計算微博數據傳達的情感,Shen等人[14]對情感詞進行了細分,建立了態度權重詞典(weight dictionary,WD)、消極詞典(negative words dictionary,NWD)、程度詞典(degree words dictionary,DWD)和感嘆詞典(interjection words dictionary,IWD),如此計算的微博情感指數更加精確。在假定具有了完善的情感詞典后,另一項核心工作是確定具體語境中各個細分詞典詞語之間的搭配關系,如使用句法分析技術,這樣才能盡可能地保證分析結果的準確性。
機器學習分類算法如決策樹、支持向量機、樸素貝葉斯等,其核心思想是通過訓練集構造分類模型,從而對新數據進行預測。Pang等人[15]使用樸素貝葉斯、支持向量機和最大熵分類器進行文本情感分類,他們嘗試用不同的特征選擇方法進行實驗,并比較實驗結果。Hassan等人[16]采用監督型馬爾科夫模型,使用詞性信息和依存關系來確定消息極性。劉志明等人[17]使用3種機器學習算法、3種特征選取算法以及3種特征項權重計算方法對微博進行情感分類研究。實驗結果表明,針對不同的特征權重計算方法,支持向量機和樸素貝葉斯分類算法各有優勢,信息增益特征選取方法相比于其他方法效果明顯要好。Basari等人[18]使用支持向量機模型結合粒子群優化算法計算文本情感,實驗結果的準確率達到77%。
文獻[19-20]的工作與本文的工作比較相似。文獻[19]提出了LARAM(latent aspect rating analysis model)模型,在已知評論整體情感的情況下,挖掘評論中的潛在維度、維度情感和個性化的維度權重。針對旅館的評論數據集和MP3播放器數據集進行實驗驗證,證明了算法的有效性。文獻[20]通過統一框架CARW(collectively estimate aspect ratings and weights)來完成同樣的3個任務。上述兩個工作和本文工作的主要區別是:
(1)雖然都是對評論所談及的維度進行挖掘,但本文采用的方法與上述工作不同。本文以維度詞典為基礎,并確定了維度詞的搭配關系,同時引入了句法分析技術,這一方面能夠提高維度挖掘的準確性,另一方面也適用于維度數量較多的情況。以電商平臺上的洗衣液評論為例,在領域專家的指導下,需要抽取的維度數量為69個。其中關于某些維度的評論非常稀疏,在這種情況下,使用機器學習或者深度學習的方法就會面臨訓練集標注工作量巨大和數據傾斜問題。此時,詞典方式是最為直接有效的方法。
(2)在獲取了維度情感的基礎上,本文的目標是挖掘消費者整體對于產品各個維度的關注度,從而推導出產品的維度權重,并通過維度情感的線性組合得到整體情感。這與文獻[19-20]分析個別用戶的維度偏好也是不同的。
3 問題描述
設R={r1,r2,…,rR}表示一組評論集合,S={S1,S2,…,SR}表示R中評論的整體情感的集合,其中Si∈S是評論ri∈R的整體情感。
定義1產品維度,也稱產品屬性,是產品本身及外延性質的總集,可表示為A={a1,a2,…,aA}。消費者對產品進行評論時會涉及產品的若干維度。例如,洗衣液產品有“價格”、“清潔效果”、“產品質量”等維度。
評論ri所包含的維度可以表示為一個A維向量

定義2維度情感,評論ri中針對某一個具體產品維度ax(ax∈A)的情感傾向稱為ax的維度情感,記作本文維度情感的情感等級分為:1-負面,3-中性,5-正面。
顯然,評論ri的全部維度情感構成一個A維向量
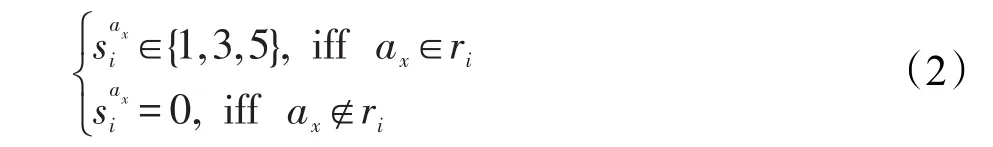
定義3維度權重,是評論者針對所有產品維度所表現出的群體偏好分布特征,用W=<w1,w2,…,wA>表示。其中,wx是ax屬性維度的權重,它與維度ax在全體評論中被談及的次數以及ax的維度情感與評論整體情感的一致性有關。
根據上述定義,本文研究的問題是:
(1)提出維度挖掘函數F,對于任意評論ri,挖掘ri的產品維度向量,形式化描述為F:ri→Vi;
(2)提出維度情感判定函數G,在(1)的基礎上,確定ri的維度情感向量,形式化描述為
(3)確定W=<w1,w2,…,wA> ,根據(2)的維度情感向量,計算評論ri的整體情感值Si。
4 算法描述
下面詳細介紹評論維度抽取、維度情感計算、維度權重計算以及評論整體情感計算。首先,給出本文工作的前提條件或假設:
(1)只針對有效評論展開,有效評論是指評論內容中至少涉及到了產品的一個屬性維度;
(2)如果評論中涉及到了某一個產品維度,則一定包含相應的維度情感;
(3)評論的整體情感依賴于評論所描述的維度及其情感,以及維度的權重,維度權重越大,對評論的整體情感影響越大。
4.1 維度挖掘
如前所述,本文在維度挖掘方面,采用的是基于詞典的規則匹配方法。基本思想是:首先根據人工分析確定產品評論的維度,然后為每一個維度確定維度詞典,即描述一個具體產品維度的常用詞集合。這里需要注意的是,很多詞語可能出現在多個維度詞典中,比如說“便宜”,如果評論文本為“東西真便宜”,那么它指的是“產品價格”維度;如果評論文本為“比超市便宜”,那么它指的是“購物渠道價格”維度。為解決這個問題,在維度詞典中引入了詞與詞之間的搭配關系。詞語以及詞語之間的搭配關系共同構成了維度挖掘詞典。
基于詞典的維度抽取方法的具體執行過程是:首先,對評論文本根據標點符號分割成子句;然后,針對每個子句,使用包含有詞語搭配關系的維度詞典進行匹配。評論子句的維度就是與其匹配次數最多的維度[21]。
顯然,維度詞典的完整性直接影響到維度抽取的準確性。維度詞典的構造過程是:首先,為產品的每個維度預先設定種子詞語;然后,計算評論子句中的每個詞與各維度種子詞語的卡方統計值,并將卡方值最大的詞語加入到相應的維度詞典中,從而實現維度詞典的擴充。詞語t和維度ax相關性的卡方統計值計算公式如式(3)所示:
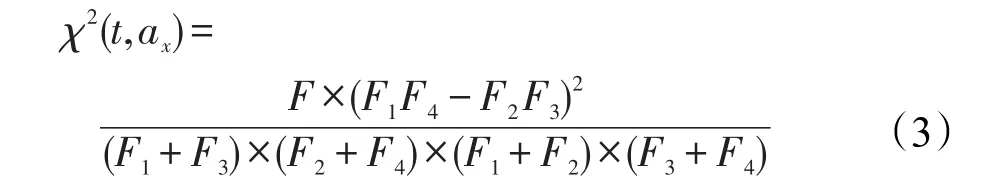
其中,F1是t出現在屬于維度ax的評論子句中的次數;F2是t出現在不屬于維度ax的評論子句中的次數;F3是屬于維度ax但不包含t的評論子句的個數;F4是既不屬于維度ax,又不包含詞t的評論子句的個數;F是詞t出現的總次數。
4.2 維度情感計算
維度抽取后已得出每條評論子句的維度,且每個維度對應著一種情感,因此維度情感分析是一個傳統的單標簽多分類問題。另外,絕大多數評論子句中針對同一維度的情感詞具有方向一致性,因此選擇使用監督學習方法對評論子句進行情感分類,具體采用決策樹分類算法。
決策樹是一個樹形結構,它從根節點開始對數據樣本進行測試,根據不同的結果將數據樣本劃分成不同的數據樣本子集。它是通過一系列規則對數據進行分類的過程。構造決策樹的關鍵性內容是進行屬性選擇度量。屬性選擇度量算法有很多,不同的決策樹實現方法有不同的選擇度量算法。本文采用CART(classification and regression tree)算法實現決策樹。CART算法采用最小Gini系數選擇分裂屬性[22]。Gini系數的定義如式(4)所示:

其中,E表示訓練樣本的集合;G表示維度情感類別的集合,文中G={1,3,5};pi=|Gi|/|E|為樣本集中樣本屬于Gi的概率。
使用決策樹方法判斷維度情感的具體步驟是:首先,在評論數據集中隨機選擇一定量的評論數據,使用維度抽取方法確定有效子句;然后,人工標注每條評論子句的情感,形成訓練數據集;使用訓練數據集訓練分類器;最后,對未標注評論子句進行分類預測,得出維度情感。注意,評論的維度情感是一個向量,向量中的每個元素對應于一個產品維度的情感值。評論中未出現的產品維度,其維度情感標注為0。
4.3 維度權重及整體情感的計算
不同產品的主要功能不同,因此用戶對于產品各個屬性維度的關注度也不盡相同。用戶對于產品的評論的總體情感,既與其對各個維度的維度情感有關,也與各個維度的維度權重有關。如果消費者群體對某個維度關注度較高,那么該維度對評論的整體情感影響也會較大。維度ax對于整體情感的影響權重與兩方面因素有關:維度ax在全體評論中被談及的概率,以及ax的維度情感與評論整體情感的一致性。本文綜合考慮了上述兩點來計算維度權重,為此隨機地選擇了評論子集R??R,并人工標注了維度、維度情感和整體情感。
維度ax在評論中被談及概率由式(5)計算:

維度ax的維度情感和評論的整體情感一致性計算如式(6)和式(7)所示:

則維度ax的綜合權重計算如式(8)所示:

式(8)說明,維度ax在評論中被談及的概率越大,則消費者對此的關注度就越大。同時,ax的維度情感與評論的整體情感一致性越高,說明ax對整體情感的決定性越強。
到此,已經通過維度挖掘獲取了一條評論中談及的產品維度,并使用決策樹算法判定了維度情感。在綜合考慮了維度在評論中的出現概率以及維度情感與整體情感一致性的情況下,計算了產品各個維度的維度權重。在此基礎上,評論的整體情感則是評論的維度情感向量與維度權重向量的內積,如式(9)所示:

5 實驗
5.1 實驗數據集及環境介紹
本文選取了32 000條的京東商城洗衣液產品評論作為實驗數據集,并對這些評論進行了人工標注作為訓練數據和測試數據。標注內容包括產品維度、維度情感和總體情感。領域專家指定了產品維度表,共分為10個大類,分別是“方便性”、“品牌”、“包裝”、“產品”、“性價比”、“價格”、“香味”、“快遞”、“購物渠道”和“產品功效”。每個大類下又細分為若干個二級維度,總共有69個二級維度。本文的工作,包括實驗,都是針對二級維度進行的。
本文均采用Python 3.5語言實現。評論數據采用MongoDB存儲。實驗物理機硬件配置如表3所示。
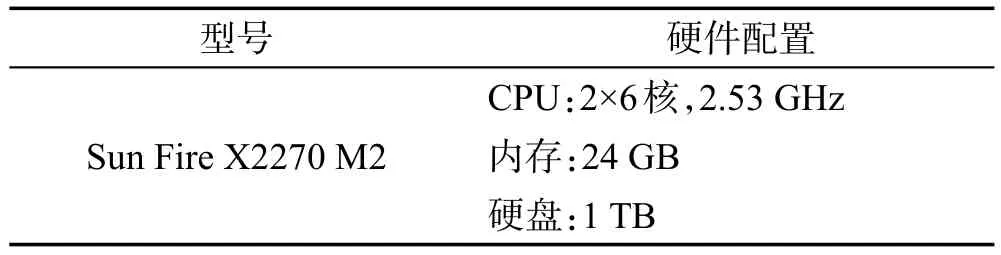
Table 3 Hardware environment in experiments表3 實驗物理機配置
為提高處理效率,在3臺物理機上構建了9個虛擬計算節點,平均分配數據以實現均衡的并行處理。
5.2 實驗結果
5.2.1 維度抽取
在維度抽取實驗中,以人工標注的32 000條評論數據的維度標注結果作為標準測試數據集。實驗過程是:針對一條評論數據,首先使用標點符號對評論進行分割,每條評論都被分割為若干子句;然后,使用維度詞表中的詞語及其搭配關系對子句進行匹配,并輸出該子句的維度挖掘結果。
如前文所述,維度挖掘本質上是一個多標簽分類問題,因此挖掘結果的正確性需要通過集合比較來進行評價。本文采用基于樣本的評價指標[1]。假設評論ri的事實標簽集為Vi,則維度抽取的評價指標定義如式(10)所示:

其中,p為測試樣本數量,即32 000條;β取通常值1。維度抽取實驗結果如表4所示。

Table 4 Result of dimension mining表4 維度抽取實驗結果
實驗結果表明,本文維度抽取準確性較高,說明本文方法能夠較好地識別評論所談及的產品屬性。實驗中使用標點符號把評論文本分隔成子句。一般情況下評論中每個子句談及的產品維度比較單一,這是維度抽取結果性能較好的基本原因。另外,本文方法的維度詞典規模較大,搭配關系超過10萬,這也是維度抽取準確性較好的原因。在實驗中還發現,有些維度在所有的用戶評論中很少涉及,例如“包裝開啟方便性”、“生產工藝”等,說明消費者對這些產品維度關注度低。
5.2.2 維度情感分析
維度情感分析的本質是傳統的單標簽分類問題。本文工作的情感分為3類:1-負面,3-中性,5-正面。維度情感分析實驗的目的是評估使用決策樹分類算法實現評論子句情感分類的效果。人工標注的32 000條數據作為事實數據集,從中隨機選取了數據總量的60%作為訓練集,其余的40%數據作為測試數據集。實驗評價指標與傳統的機器學習分類算法評價指標相同。實驗發現,使用卡方統計測量特征與類別之間的依賴性來進行特征選取,且特征數為2 000時,決策樹分類效果最佳。實驗結果如表5所示。

Table 5 Result of dimensional-level sentiment analysis表5 維度情感分析結果
實驗結果表明,使用決策樹分類算法進行維度情感分析的效果良好。在實驗中,把包含維度信息的子句作為情感分析的語料,而子句是通過標點符號切割的,因此實驗結果的準確性嚴重依賴于評論中標點符號使用的規范性。通過實驗發現,絕大多數評論中都有標點符號分割,且絕大多數維度情感特征詞都和維度信息位于同一個子句中,這是維度情感分類結果較好的原因。
5.2.3 整體情感分析
在整體情感分析實驗中,首先使用32 000條人工標注數據集計算維度權重,然后使用式(9)計算評論的整體情感,并與人工標注的評論整體情感進行比較。實驗結果如表6所示。

Table 6 Result of overall sentiment analysis表6 整體情感分析結果
實驗結果表明,本文的權重計算方法有效。實際上,按權重對維度進行了排序輸出,發現權重較高的前5位產品屬性依次是“價格”、“購物渠道價格”、“物流/快遞速度”、“快遞服務態度”、“清潔效果”。這與人們默認的選購洗衣液產品的情感傾向稍微有些差別。一般認為,洗衣液產品最為關鍵的屬性應該是“清潔效果”,但在本文的計算結果中,“清潔效果”僅位于第5位。為此,按照維度標簽提取了相應的評論進行了分析,發現了其中的邏輯:網購行為往往帶有很強的目的性,即用戶已經在線下確定了目標商品,因此網購行為更多關注的是價格和物流速度;很多評論中提到了“快遞服務態度”,相應的評價內容主要是快遞員是否送貨上門。產生這一現象的主要原因是,很多消費者因為電商的促銷活動購買了很多洗衣液,重量較大,而且購買者往往是女性,因此她們比較重視快遞員是否能夠送貨上門。通過這些深入觀察,也能反映出本文維度權重計算方法是正確的。
6 總結與展望
本文針對電商平臺的產品評論信息,完成了維度抽取、維度情感分析和整體情感分析工作。首先,構建維度詞典,采用了基于詞典的維度抽取方法;然后,使用決策樹的方法對維度情感進行分類;通過對評論數據的統計,確定了維度權重,并基于維度情感和維度權重計算評論的整體情感。基于真實的評論數據集的實驗結果表明,本文提出的維度挖掘方法、維度情感計算方法、維度權重計算方法,以及評論整體情感分類技術均具有很好的性能。
下一步將針對如下兩個問題展開研究:第一,當前的維度信息是領域專家基于經驗設定的,缺乏科學性依據,因此計劃根據采集的數據,使用聚類算法,自動推薦維度標簽;第二,生產企業為了提升產品的競爭力,會經常向產品中添加新功能,這會導致新維度的產生,那么用戶評論中一定會有提及,如何自動感知評論中的新維度信息也是一個很有挑戰性的問題。
[1]Zhang Minling,Zhou Zhihua.A review on multi-label learning algorithms[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(8):1819-1837.
[2]Boutell M R,Luo Jiebo,Shen Xiping,et al.Learning multilabel scene classification[J].Pattern Recognition,2004,37(9):1757-1771.
[3]Zhang Minling,Zhou Zhihua.ML-KNN:a lazy learning approach to multi-label learning[J].Pattern Recognition,2007,40(7):2038-2048.
[4]Clare A,King R D.Knowledge discovery in multi-label phenotype data[C]//LNCS 2168:Proceedings of the 5th European Conference on Principles of Data Mining and Knowledge Discovery,Freiburg,Sep 3-5,2001.Berlin,Heidelberg:Springer,2001:42-53.
[5]Fürnkranz J,Hüllermeier E,Mencía E L,et al.Multilabel classification via calibrated label ranking[J].Machine Learning,2008,73(2):133-153.
[6]Elisseff A,Weston J.A kernel method for multi-labelled classification[C]//Proceedings of the 14th International Conference on Neural Information Processing Systems:Natural and Synthetic,Vancouver,Dec 3-8,2001.Cambridge:MIT Press,2001:681-687.
[7]Ghamrawi N,McCallum A.Collective multi-label classification[C]//Proceedings of the 14th ACM International Conference on Information and Knowledge Management,Bremen,Oct 31-Nov 5,2005.New York:ACM,2005:195-200.
[8]Read J,Pfahringer B,Holmes G,et al.Classifier chains for multi-label classification[J].Machine Learning,2011,85(3):333-359.
[9]Tsoumakas G,Vlahavas I.Random k-labelsets:an ensemble method for multilabel classification[C]//Proceedings of the 18th European Conference on Machine Learning,Warsaw,Sep 17-21,2007.Berlin,Heidelberg:Springer,2007:406-417.
[10]Zhang Lei,Liu Bing.Aspect and entity extraction for opinion mining[M]//Chu W W.Data Mining and Knowledge Discovery for Big Data.Berlin,Heidelberg:Springer,2014:1-40.
[11]Read J,Perez-Cruz F.Deep learning for multi-label classification[J].Machine Learning,2014,85(3):333-359.
[12]Tong R M.An operational system for detecting and tracking opinions in online discussions[C]//Proceedings of the ACM SIGIR Workshop on Operational Text Classification,New Orleans,2001.New York:ACM,2001:1-6.
[13]Hu Minqing,Liu Bing.Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Seattle,Aug 22-25,2004.New York:ACM,2004:168-177.
[14]Shen Yang,Li Shuchen,Zheng Ling,et al.Emotion mining research on micro-blog[C]//Proceedings of the 1st IEEE Symposium on Web Society,Lanzhou,Aug 23-24,2009.Piscataway:IEEE,2009:71-75.
[15]Pang Bo,Lee L,Vaithyanathan S.Thumbs up?:sentiment classification using machine learning techniques[C]//Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing,Philadelphia,Jul 6-12,2002.Stroudsburg:ACL,2002:79-86.
[16]Hassan A,Qazvinian V,Radev D.What's with the attitude?:identifying sentences with attitude in on-line discussions[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing,Cambridge,Oct 9-11,2010.Stroudsburg:ACL,2010:1245-1255.
[17]Liu Zhiming,Liu Lu.Empirical study of sentiment classification for Chinese microblog based on machine learning[J].Computer Engineering andApplications,2012,48(1):1-4.
[18]Basari A S H,Hussin B,Ananta I G P,et al.Opinion mining of movie review using hybrid method of support vector machine and particle swarm optimization[J].Procedia Engineering,2013,53(7):453-462.
[19]Wang Hongning,Lu Yue,Zhai Chengxiang.Latent aspect rating analysis without aspect keyword supervision[C]//Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,San Diego,Aug 21-24,2011.New York:ACM,2011:618-626.
[20]Wang Feng,Chen Li.Review mining for estimating users'ratings and weights for product aspects[J].Web Intelligence,2015,13(3):137-152.
[21]Wang Hongning,Lu Yue,Zhai Chengxiang.Latent aspect rating analysis on review text data:a rating regression approach[C]//Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Washington,Jul 25-28,2010.New York:ACM,2010:783-792.
[22]Zhang Liang,Ning Qian.Two improvements on CART decision tree and its application[J].Computer Engineering and Design,2015,36(5):1209-1213.
附中文參考文獻:
[17]劉志明,劉魯.基于機器學習的中文微博情感分類實證研究[J].計算機工程與應用,2012,48(1):1-4.
[22]張亮,寧芊.CART決策樹的兩種改進及應用[J].計算機工程與設計,2015,36(5):1209-1213.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2015年1期)2015-08-13 02:23:50
玩具(2009年10期)2009-11-04 02:33:14
