小型英語學習者語料庫與錯誤分析
2018-03-14 08:36:32韓國全汶基
山東理工大學學報(社會科學版) 2018年1期
于 建,[韓國]全汶基
(1.山東理工大學 外國語學院,山東 淄博 255000;2.韓國建國大學 英語系,韓國 首爾05029)
一、引言
學習者在語言學習過程中經常會出現語言使用方面的錯誤。20世紀五六十年代,對比分析理論(contrastive analysis)在第二語言習得研究中占據主導地位。在對比分析理論體系中,錯誤通常被認為是學習者語言能力欠缺的標志,因而是應該嚴格避免的。錯誤的根源在于語言間的差異性,所以語言學家及語言教師的任務是比較學習者的母語與他們學習的目標語言的差異,從而對學習者可能出錯的領域做出預測,以此來幫助他們盡可能地避免這些錯誤[1]1-3。20世紀60年代后期,由于對比分析理論固有的理論及實證缺陷,比如無法預測所有可能的錯誤,有些預測的錯誤從未實際發生等,它很快淪為一種過時的理論,轉而被錯誤分析理論(error analysis)所取代。在錯誤分析理論體系中,語言錯誤被認為是學習者必須經過的發展階段,與兒童習得母語的過程類似[2]161-170。錯誤不是語言能力欠缺的標志,它們的存在恰恰表明學習者正在努力探索所學習的語言,不斷歸納與總結,并試圖形成與之相關的規則和認識。從這個角度來看,學習者的語言錯誤不應該被視為問題;相反地,經過詳盡的分析,它們可以為認識學習者語言的發展過程提供有價值的信息[3]102。
然而,傳統的錯誤分析理論也有其局限性。 Dagneaux,Denness & Granger將它們總結如下。第一,錯誤分析經常基于差異化的學習者語料。第二,錯誤類別間的界限不明晰。第三,錯誤分析無法解釋有些語言現象,比如學習者為何避免使用某種語言結構。第四,錯誤分析僅局限于分析學習者之力所不能及,而無視學習者之力所能及。第五,錯誤分析把第二語言學習看作是一個靜態靜止的過程[4]164。
第一個局限性表明了錯誤分析中語料收集的重要性,參見Ellis(1994)[5]68-70。Corder也指出,只有學習過程中產生的系統性錯誤才具有收集分析的價值[2]170。第二個局限性與錯誤分類的標準有關。這些標準通常缺乏客觀性,定義較為模糊,會直接影響錯誤分析的結果及有效性。其他三個局限性則表明,在錯誤分析中使用正確、使用避免以及使用不足等現象也應該納入到分析的范疇中來。同時,學習者的學習過程也不應被視為是靜態的,而應視為一個動態發展、不斷修正、逐步提高的過程。
20世紀90年代,隨著計算機技術的發展以及語料庫分析方法的廣泛使用,學習者語料庫開始在語言習得研究中興盛起來。作為語料庫的一種重要類型,學習者語料庫中收集的是語言學習者在實際使用語言過程中的口語或書面語的語料。基于語料庫語言學的理論與分析方法,學習者語料庫可以為語言習得研究提供更好的手段,同時也能夠滿足更廣的研究需求[6]22。在此背景下一種新的錯誤分析方法應運而生,即計算機輔助錯誤分析(computer-aided error analysis)[4]163。
與傳統錯誤分析所使用的語料相比,學習者語料庫中的語料具有幾個顯著的優點。其一,學習者語料庫的體量可以比較龐大,規模龐大的語料能夠更全面地反映學習者語言的使用特征,同時也有利于形成更具規律性的分析結果。其二,學習者語料庫在建庫之初就能夠較好地控制各種相關變量,比如學習時長、語言水平、任務類型、母語背景等。其三,學習者語料庫中的語料既包含各種錯誤使用形式,同時也包含各種正確使用形式,因此學習者的語言成就和語言不足都可以得到客觀反映。從語言不足的角度來講,通過相關語料,研究者可以試圖找到錯誤的源頭;而且借助于語料庫語言學的定量分析方法,錯誤頻率及分布規律也可以得到量化分析。其四,學習者語料庫可以收集相同學習者在不同學習階段的語料,從而可以進行縱向研究(longitudinal study),比如學習者在哪個階段更易出現哪些錯誤或哪些使用不足。最后,大量相關軟件可以實現語料收集、標記及數據分析的自動化,從而減輕研究者的負擔。借助于這些工具,研究者可以對語料進行更全面的分析,例如利用類符形符比例(type-token ratio)來分析詞匯豐富度(lexical richness),利用詞匯分布率(word range)來分析詞匯復雜度(lexical complexity)等[7]123-138。
基于上述優點,學習者語料庫非常適合對學習者語言進行基于使用頻率的各項研究。例如,International Corpus of Learner English(ICLE)收集了不同母語背景的英語學習者語料,研究者已開展了基于這些語料的多維度研究,如補語從句、時態、高頻動詞、習慣用語等。 依托這個語料庫,Liu發現一般現在時、一般過去時、以及過去完成時是中國英語學習者經常出現的時態錯誤[8]16。這些錯誤可能與漢語缺乏時態系統有關。Milton & Tsang比較了中國英語學習者與英語母語使用者的語料。他們發現前者傾向于過度使用某些邏輯連詞,比如,moreover 在學習者語料中出現的頻率是其在布朗語料庫(Brown Corpus) 中的10倍;therefore 出現的頻率是6.9倍。他們認為教材設計及寫作教學導致了這些使用過度[9]227-240。
學習者語料中的錯誤能夠標記出來并加以定性或定量分析的話,分析結果對課堂教學及學生學習會具有一定的借鑒意義。教師可以根據分析結果對大綱設計和課堂教學做出相應的調整,也可以將學習者語料庫中提取的索引行(concordance lines)作為教學材料呈現給學生,并鼓勵學生利用語料庫和檢索工具主動進行相應檢索,從而促進學習。這種數據驅動的學習和教學(data-driven learning & teaching)方法要比傳統的以教材為中心的方法效率更高,尤其適用于口語和寫作課堂[10]134-144。Schmidt提出的注意假說(Noticing Hypothesis)認為,學習者在學習過程中需要對輸入信息(input)保持一定程度的注意。如果注意的程度較高,輸入信息就更容易轉化成內化(intake)[11]1-48。在語音學習過程中,研究者已經發現注意力導向確實能夠促進語音習得[12]54-59。包含錯誤標記的索引行如果作為教學材料,就能把錯誤更直觀系統地呈現給學習者,從而提高他們對錯誤的注意,提高學習效果。
以英語的冠詞系統為例。學習者的母語中如果缺乏冠詞系統,那么他們在學習過程中可能會產生較多與冠詞有關的錯誤。Master做了冠詞學習相關的實證研究。在教師系統地講述了英語冠詞之后,相比較于對照組,他的實驗組在后續測試中冠詞使用的準確率得到大幅度提升。Master認為系統地呈現英語冠詞一方面減輕了學習過程中的疑惑,另一方面,英語冠詞系統的形式特征及語法功能的共同呈現也有助于學習者的掌握[13]242-247。
基于前人的研究,我們提出了如下兩個假設。
其一,中國英語學習者可能會出現較高頻率的時態錯誤,尤其是一般現在時、一般過去時、以及諸如現在完成時的復合時態。
其二,由于漢語中缺乏冠詞系統,中國英語學習者可能出現較多冠詞相關的錯誤。
二、數據
(1)語料庫數據
論文涉及的語料來自于《中國學生英語口筆語語料庫》[14]11-29。語料收集是按大學年級順序,每個年級隨機抽取10篇英語作文,總共40篇 (平均長度=255.1, 標準差=73.9),然后按年級分成四個子庫 (C1-C4,每個子庫10篇作文)。 表1列舉了這四個子庫的相關信息。
表1 語料庫字數及錯誤信息
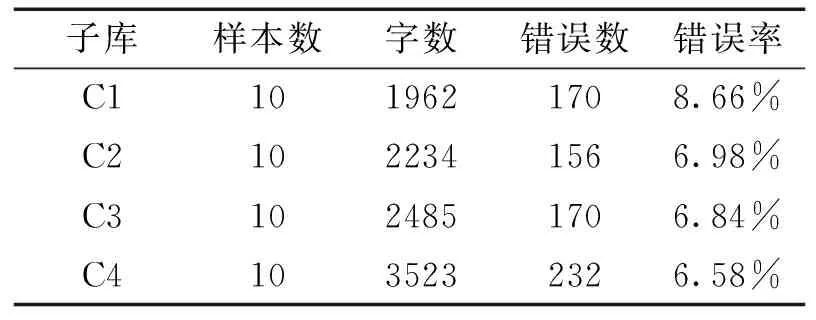
子庫樣本數字數錯誤數錯誤率C1C2C3C41010101019622234248535231701561702328.66%6.98%6.84%6.58%
(二)錯誤標記
四個子庫中的語料隨后進行手工錯誤標記,標記參考使用的是Cambridge Learner Corpus(CLC)錯誤標記集,具體參見 Nicholls (2003)[15]572-576。下面是錯誤標記的示例,表2 則列舉了幾類主要的錯誤及標記代碼。
<#CODE>wrong form|corrected form<#CODE>
“CODE” 指錯誤的標記代碼,“wrong form”指原來的錯誤形式,“corrected form”指修正后的正確形式,兩者之間用“|”加以分割便于區分。
表2 常見錯誤及標記形式
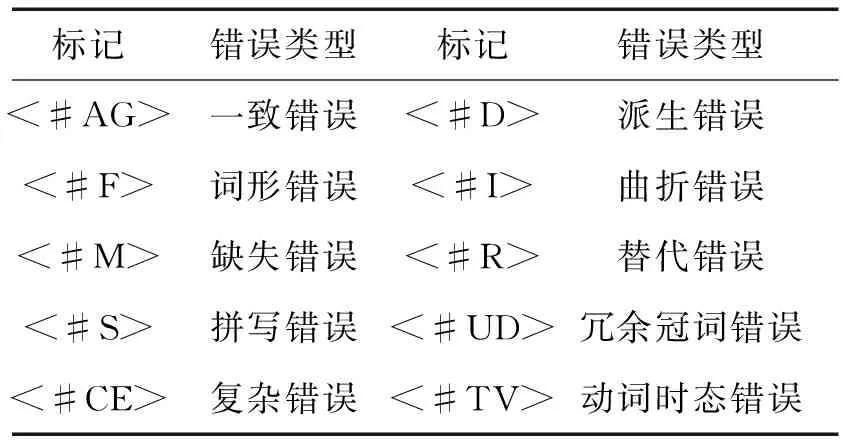
標記錯誤類型標記錯誤類型<#AG>一致錯誤<#D>派生錯誤<#F>詞形錯誤<#I>曲折錯誤<#M>缺失錯誤<#R>替代錯誤<#S>拼寫錯誤<#UD>冗余冠詞錯誤<#CE>復雜錯誤<#TV>動詞時態錯誤
論文著重關注三類錯誤。第一類是冗余冠詞錯誤,是學習者在無需使用冠詞的時候使用了而產生的錯誤。在語言習得研究中,這類錯誤通常被認為是過度概括化(overgeneralization)的結果。論文涉及的冗余冠詞錯誤幾乎全部與定冠詞 the 相關。 例1中包含了一個典型的冗余冠詞錯誤。
例1.Some people think the <#UD>the|<#UD> university education is to prepare students for employment. (C1_01.txt)
第二類錯誤是動詞時態錯誤,主要是學習者錯誤使用了標記時態的動詞曲折變化形式而產生的。第三類錯誤是復雜錯誤。有時一個短語或句子中可能包含兩個或更多的錯誤,而當修正這些錯誤時,會極大地改變原有形式的結構或意義,這種錯誤就被標記為復雜錯誤。例2包含了兩個復雜錯誤。
例2.They may be more helpful and warmhearted, instead of becoming a silfish person a silfish person|selfish persons, who will consider his benifit <#CE>consider his benifit|consider their own benefit as the most important thing. (G1_05.txt)
學習者語料中的錯誤加以標記后,利用語料庫檢索程序,包含某種特定錯誤標記的形式就可以從語料庫中檢索出來,方便做進一步分析處理。
三、數據分析
(一)錯誤標記的數據分析
錯誤標記搜索及統計是通過語料庫檢索軟件AntConc來完成的[16]。首先,利用AntConc載入全部40篇錯誤標記過的樣本,利用錯誤標記代碼檢索即可獲得特定錯誤,軟件會自動統計頻次。檢索結果如表1所示,四個子庫中共有728處錯誤。從字數來講,從C1到C4樣本字數呈逐漸增加的趨勢,表明隨著學習時長的增加,學生英文作文長度也隨之增加。從錯誤表面數量來看,二年級大學生所犯錯誤最少,為156個。一年級跟三年級的錯誤數相同,為170個。大學四年級學生錯誤最多,為232個。然而,當統計錯誤率時(錯誤率 = 錯誤總數/語料庫字數*100%),一年級大學生錯誤率最高,為8.66%,二年級為6.98%, 三年級為6.84%,而四年級為6.58%。錯誤率總體上呈現隨年級增加逐漸下降的趨勢。這種錯誤率總體下降的趨勢與樣本長度總體上升的趨勢正好相反,表明隨著學習時長的增加,以及語言能力的逐漸提高,錯誤頻率也隨之減少。四個子庫中每個樣本的錯誤總數以及冗余冠詞錯誤信息可見如下兩圖。
為了進一步驗證錯誤與年級差異以及文本長度的關系,利用SPSS 24.0統計軟件中的線性回歸、方差分析等模塊對所獲取的數據做了進一步的統計分析。首先是線性回歸分析, 用來驗證數據間的關聯性。線性回歸分析表明, 當利用樣本長度(樣本數=40)來預測錯誤頻率時,一個具有顯著意義的相關性確實存在,F(1,38)= 5.665,p=0.022;R2=0.130。這表明在語料庫中,樣本長度跟錯誤率具有關聯性,即無論語言能力如何,當寫作長度增加時,學習者同時也會犯更多的錯誤。為了確定樣本長度與冗余冠詞錯誤間的關聯性,第二個線性回歸分析利用樣本長度(樣本數=40)來預測冗余冠詞錯誤頻率, 分析結果并未表明兩者之間有顯著的相關性:F(1,38) =0.210,p= 0.650;R2=0.005。這表明隨著文本長度的增加,冗余冠詞錯誤并未相應增加。第三個線性回歸分析利用樣本中的總體錯誤數(樣本數=40)來預測冗余冠詞錯誤數。分析結果表明樣本中的錯誤總數與冗余冠詞錯誤數具有顯著的相關性:F(1,38)=11.521,p=0.002;R2=0.233。這表明當錯誤總數增加時,冗余冠詞錯誤數也會相應增加,考慮到冗余冠詞錯誤在總體錯誤中所占比例最大(21.56%),這種相關性的存在也確實有其基礎。其次是方差分析,兩個方差分析分別用來驗證總體錯誤數量和冗余冠詞錯誤是否有子庫效應(子庫數=4)。第一個單因素方差分析結果表明四個子庫中的總錯誤數并無顯著差異,F(3,36)=1.820,p=0.161。 第二個單因素方差分析表明四個子庫中的冗余冠詞錯誤也無顯著差異,F(3,36)=1.820,p=0.162。這兩個方差分析的結果表明四個子庫之間無論是就總體錯誤數還是冗余冠詞錯誤數而言并無顯著差異。這證明學生學習能力的提高并沒有顯著降低錯誤頻率。
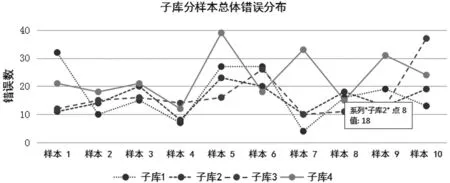
圖1 子庫中分樣本總體錯誤分布狀態
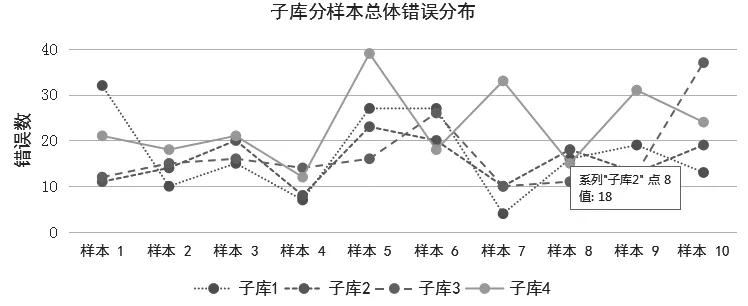
圖2 子庫中分樣本冗余冠詞錯誤分布狀態
由于所選樣本寫作有限時與不限時的區別,兩個獨立樣本T檢驗用來確定時限區別是否對總體錯誤數及冗余冠詞錯誤數有影響。兩個T檢驗的結果表明限時樣本中的總錯誤數與不限時樣本中的總錯誤數并無顯著差異,t(36) =0.416,p=0.678。同時,限時樣本中的冗余冠詞錯誤數與不限時樣本中的冗余冠詞錯誤數亦無顯著差異,t(36) =-1.088,p=0.285。這表明時限要求對總體錯誤數以及冗余冠詞錯誤數并無顯著影響。當時限性這個可能的影響因素被剔除后,語料庫中的錯誤更有可能是由于語言能力發展的因素或學習者學習的因素而導致的,比如過度概括化等學習策略的影響。
(二)時態錯誤與復雜錯誤分析
在所有的錯誤類型中,時態錯誤共出現17次,占錯誤總數的2.33%。復雜錯誤共出現63次,占錯誤總數的8.65%。與其他研究,如Liu(2012)[8]11-23相比,論文所涉及樣本的時態錯誤出現頻率較低。論文提出的第一個假設并沒有得到驗證。造成這個結果的可能性有兩個:一是本語料庫中收集的樣本多用一般時態,比如一般現在時與一般過去時。這可能與測試中國學生英語寫作能力的方式有關。在英語測試中,作文部分一般的體裁都是論說文,而這類體裁對時態多樣化的要求不高,所以時態的使用會較為單一。時態單一的另一個益處是可以避免時態多樣化帶來的錯誤率增大的問題,作為預防措施,學生在寫作時也可能有意識地減少多種時態的使用。二是樣本的差異性,論文所涉及樣本的寫作者對英語簡單時態的掌握可能要好于Liu(2012)[8]11-23研究中的寫作者。
除了時態錯誤以外,另外一種應該引起注意的是復雜錯誤。例3中就包含了這樣的復雜錯誤。
例3.Now of socity call for a good deal have a lot of knowledge of talent <#CE>Now of socity call for a good deal have a lot of knowledge of talent|Now our society calls for a lot of talented people<#CE>. (C1_01.txt)
這個只有十幾個單詞的句子,包含了五處錯誤。首先,英語中并不存在“now of”這個表達方式,因此最有可能的錯誤是拼寫錯誤,比如把“our”誤拼成“of”。其次,單詞“society”被誤拼成了“socity”,這更加增加了前面“of”是誤拼的可能性。再次,“a good deal”后面缺失被修飾成分,這是一個缺失錯誤。隨后, “have a lot of knowledge of talent”前面缺失一個做從句主語的關系代詞 who。最后“a lot of knowledge of talent”并不是一個符合英語語法的結構。這句話可以修改為“Now our society calls for a lot of talented people.”之所以這樣修改,是因為劍橋學習者語料庫在進行錯誤標記時遵從這樣一個原則:盡量減少不必要的錯誤。基于這個原則,在修正句子時,上面列舉的第四個錯誤就不做修改,同時句子的順序做了調整,句子成分也做了簡化處理,從而使得修正后的句子更簡潔通順。在錯誤分析中我們應該關注這樣的復雜錯誤,它們包含了豐富的信息,表明學習者尚未完全掌握英語句子相關的基本知識,比如詞性、句子成分、語序等;同時復雜錯誤也表明學習者缺乏對英語句子成分間及句子間邏輯關系的認識。
(三)邏輯問題
除了樣本中標記的語法詞匯錯誤之外,邏輯關聯方面的問題,比如語篇銜接與連貫的問題,也值得引起關注。除少數連詞缺失錯誤以外,語料庫中并沒有系統標記這類問題,因為這類問題一般跨度較大,容易造成標記困難或者無法標記。漢語是一種意合語言(paratactic language),它主要依賴于句子間隱性的、語義的關系作為銜接連貫的手段。而英語則是一種形合語言(hypotactic language),它更多地依賴顯性的手段,比如連詞和副詞,以及句子間的從屬關系來作為句子銜接連貫的手段。例4中包含了多個邏輯問題,為了閱讀的方便,例子中的錯誤標記已經移除,錯誤處加了下劃線用來標示。
例4.The young people are not having a correct concept of the world. They may easily make criminal, this will be a terrible things. Nobody will hope it happens. At this time the parents should have a wise thought. It is silly to indulge the children. This is not to love them but to induce them to do bad things. They should ask the children to demand themselves everyday. (C4_07.txt)
除詞匯語法錯誤以外,這段話里還有非常嚴重的邏輯問題。首先,“沒有正確的世界觀的人”并不一定“可能很容易地”就變成 “罪犯”,盡管寫作者用了一個表達確定意義并不強烈的“可能”(may)來試圖弱化這種因果關系,但這仍是一個極其夸大的說法。其次,這段話里面的句子之間缺乏連詞,作者只是把一些簡單句機械地堆砌在一起,使得最后的行文既不通順,又表意不清,閱讀起來非常困難。再次,寫作過程中的母語影響非常明顯,比如“demand themselves”就是漢語中“要求自己”直譯的結果,而英語中并沒有這樣的表達方式。這種行文邏輯等方面的問題也提醒我們,在對學習者的語言使用進行分析時,既要有微觀的分析,比如具體的詞匯語法錯誤分析,也要有宏觀的分析,比如銜接連貫、邏輯推理、甚至體裁特征等方面的分析,只有這樣才能獲得對學習者語言較為全面的認識,同時也能給課堂教學提供更豐富的借鑒。
四、討論
論文的結果表明小型語料庫在分析學習者語言特征方面具有重要的價值。雖然作為先行研究,論文所使用的語料庫樣本數較少,但是卻為后續的基于大規模學習者語料庫的研究提供了極有價值的參考。
首先,論文中提出的第一個假設并沒有得到實證支持。在所有的40篇樣本中,只有17例時態錯誤,這一結果與前人研究的結果非常不同。由于語言間的差異性,如果母語中缺乏時態系統,學習者在學習時態語言時可能會遇到較多與時態有關的困難。造成本語料庫樣本中時態錯誤較少的原因已在前文表述過。從學習者的角度來講,語料庫中樣本的寫作者都是大學生,他們在進入大學之前已經至少有六七年的英語學習經歷,對于簡單時態的掌握已經相對熟練,所以在簡單時態方面的表現會相對較好。這種語言能力影響語言使用的現象也提醒我們,如果想要獲得更多時態相關的錯誤,最好收集英語能力相對較低的學習者語料。
其次,論文中提到的第二個假說得到了實證數據的支持。樣本中出現了頻率較高的冗余冠詞錯誤,共117例,外加11例冠詞缺失錯誤,使得冠詞相關的錯誤占全部錯誤總數的17.6%。這種高頻錯誤可能與冠詞本身的結構無關,而更可能與學習者的學習策略有關,比如是過度規范化的結果。Dulay & Burt指出,冠詞系統是第二個被中國英語學習者習得的語法系統,而這個系統本身的三個成員盡管在形式上并不復雜,但是在使用上卻極為繁瑣[17]51。因為英語定冠詞的使用頻率非常高,所以學習者會誤認為英語定冠詞是廣泛適用的,而其母語中又沒有冠詞系統作為使用參考,因而會造成過度規范化的錯誤。
五、結論
論文論證了利用錯誤標記的小型語料庫來研究學習者語言的可行性。當學習者語料收集科學,錯誤標記標準統一的情況下,即使是小型學習者語料庫也能提供豐富的信息,能夠較為系統地反映學習者語言使用的規律和特征。這對大型學習者語料庫研究及語言教學都具有一定的借鑒意義。
[1]Lado R. Linguistics across cultures: applied linguistics for language teachers[M].Ann Arbor: University of Michigan Press, 1957.
[2]Corder S P. The significance of learners’ errors [J]. International Review of Applied Linguistics, 1967,(5).
[3]Gass S M, Selinker L. Second language acquisition: An introductory course (3rd ed.) [M].New York: Routledge/Taylor Francis, 2008.
[4]Dagneaux E, Denness S, Granger S. Computer-aided error analysis [J]. System,1998,(26).
[5]Ellis R. The study of second language acquisition [M]. Oxford: Oxford University Press, 1994.
[6]Granger S. A Bird’s-eye view of learner corpus research [M]// Granger S, J. Huang, Petch-Tyson S. Computer Learner Corpora, Second Language Acquisition and Foreign Language Teaching. Amsterdam: John Benjamins, 2002.
[7]Granger S. Computer learner corpus research: Current status and future prospects [M]// Connor U, Upton T A. Applied corpus linguistics: A multidimensional perspective. Amsterdam & Atlanta: Rodopi, 2004.
[8]Liu Juan. CLEC-based study of tense errors in Chinese EFL learners’ writings [J].World Journal of English Language 2012, (4).
[9]Milton J, Tseng S C. A Corpus-based Study of Logical Connectors in EFL Students’ Writing: Directions for Future Research [M]// Pemperton R, Tseng S C. Studies in Lexis. Hong Kong: HKUT, 1993.
[10]Nesselhauf N. Learner corpora: Learner Corpora and Their Potential for Language Teaching [M]// Sinclair J M. How to Use Corpora in Language Teaching.Amsterdam: John Benjamins Publishing Company, 2004.
[11]Schmidt R. Consciousness and Foreign Language Learning: A Tutorial on Attention and Awareness in Learning [M]// Schmidt R. Attention and Awareness in Foreign Language Learning. Honolulu, HI: University of Hawaii, 1995.
[12]Pederson E, Guion S. Orienting Attention During Phonetic Training Facilitates Learning [J]. Journal of Acoustic Society of America,2010, 127 (2).
[13]P. Master. The Effect of Systematic Instruction on Learning the English Article System [M]// Odlin T. Perspectives on Pedagogical Grammar. Cambridge: Cambridge University Press, 1994.
[14]文秋芳,王立非,梁茂成. 中國學生英語口筆語語料庫 [M]. 北京:外語教學與研究出版社,2005.
[15]Nicholls N. The Cambridge Learner Corpus - error coding and analysis for lexicography and ELT [C]// Archer D, Rayson P, Wilson A, McEnery J. Proceedings of Corpus Linguistics 2003, Lancaster, UK: Lancaster University, 2003.
[16]L.Anthony.AntConc(3.4.4)[CP/OL].(2015-06-26)[2017-06-15]. http://www.laurenceanthony.net/software/antconc/releases/AntConc344/.
[17]H. Dulay, M. Burt. Natural Sequences in Child Second Language Acquisition [J].Language Learning, 1974,(24).
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
新東方英語·中學版(2017年9期)2017-09-25 20:25:46
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學生導刊(低年級)(2016年2期)2016-02-24 23:02:11
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
小天使·五年級語數英綜合(2014年5期)2014-06-25 05:22:42
語文知識(2014年10期)2014-02-28 22:00:56
