基于科研本體的國防科技知識圖譜構建
2018-03-22 03:53:10,
中華醫學圖書情報雜志 2018年7期
關鍵詞:信息
,
2012年5月17日,谷歌正式推出知識圖譜(Knowledge Graph)項目,針對互聯網上的網頁信息世界,試圖通過真實世界中存在的各種實體和概念進行知識描述和檢索,從而代替傳統的字符串匹配檢索,創造全新的信息檢索模式[1]。國內外的互聯網搜索引擎公司緊隨其后紛紛構建了自己的知識圖譜,如微軟的Probase、搜狗的“知立方”、百度的“知心”等,知識圖譜已經成為構建下一代智能化搜索引擎的基礎。
盡管在學術界和工業界,有關知識圖譜的研究與應用不斷升溫,并且出現一些知識圖譜產品,但在國防科研領域尚缺乏知識圖譜構建的成熟解決方案。本文在研究知識圖譜的概念和現有構建技術的基礎上,結合國防科技文獻特點,提出了從科研本體模式構建知識圖譜的思路,并以權威科技文摘數據為對象開展了知識圖譜構建實踐。
1 知識圖譜概念及構建技術框架
1.1 知識圖譜概念
知識圖譜(Knowledge Graph)是結構化的語義知識庫,用于以符號形式描述物理世界的概念及其相關關系,其基本組成單位是“實體-關系-實體”三元組,以及實體及其相關“屬性-值對”,實體間通過關系相關聯結,構成網狀的知識結構[2]。
一般來說,知識圖譜是由具有屬性的實體通過關系鏈接而成的網狀知識庫,可以看作是一張巨大的圖,圖的特征更明顯一些,譜的特征相對較弱。這張圖中的節點表示實體或概念,圖中的邊則構成關系,是一種有效的知識表達形式。
知識圖譜和本體結構非常類似,但將其與本體概念進行比較后可以發現,知識圖譜并不是本體的替代品,相反它是在本體的基礎上進行了豐富和擴充,這種擴充主要體現在實體(Entity)層面。本體中突出和強調的是概念以及概念之間的關聯關系,描述的知識圖譜的數據模式(Schema),即為知識圖譜構建數據模式相當于為其構建本體;而知識圖譜則是在本體的基礎上,增加了更加豐富的關于實體的信息。
1.2 知識圖譜構建方法
知識圖譜在邏輯上分為數據層和模式層,模式層是知識圖譜的核心,主要對圖譜中的知識節點進行定義和規范,同時對知識節點之間的關系定義描述和約束;數據層則是在模式層約束下,對大數據資源進行“實體-關系-實體”或者“實體-屬性-屬性值”描述,最終形成龐大的知識網絡。知識圖譜構建主要是利用現有大數據資源和知識抽取等技術,獲取知識圖譜模式結構并構建關聯網絡,最終完成知識圖譜構建。有學者[3]給出了知識圖譜的構建和維護流程(圖1)。

圖1知識圖譜構建與更新流程
國內有學者[3]把知識圖譜構建過程分為自頂向下和自底向上兩種模式。其中,自頂向下構建是指借助已有權威知識,在專家干預之下獲取模式信息,按照模式信息對數據資源進行加工,形成知識圖譜;自底向上構建則是指借助一定技術手段,從數據資源中獲取實體/概念及關系,利用統計學原理選擇其中置信度較高的新模式,經人工審核之后形成知識庫。總之,隨著大數據時代的到來,知識抽取和知識加工技術的不斷成熟,知識圖譜構建基本是由專家、數據、技術結合而進行的螺旋式進化和迭代式更新的過程,已經很難區分是從自頂向下還是自底向上。
1.3 知識圖譜構建關鍵技術
大數據信息環境為知識圖譜構建提供了豐富的資源基礎,大數據技術的迅速發展不斷推動知識圖譜構建工作向工程化和自動化發展,其中信息抽取、知識融合、知識推理等是影響知識圖譜構建的關鍵技術[3]。
信息抽取是自然語言處理研究中的一個重要領域,主要實現從半結構化、無結構化的自由文本或其他信息資源中抽取出結構化的、無二義性信息。在知識圖譜構建中主要完成從半結構化和無結構數據中抽取實體、關系以及實體屬性等結構化信息,主要涉及命名實體識別、關系抽取、屬性抽取等技術。命名實體識別是指從文本中自動識別并抽取出特定的實體信息[3],如人物、地點、機構、時間等;關系和屬性抽取則是根據已經識別出的實體,按照一定句法和句式自動識別出實體與實體之間的關系,以及實體自身附著的特性信息。
知識融合是將不同來源的事實知識準確、有效地合并到知識倉儲中,并保證知識描述的一致性。為此,知識融合過程要準確識別待合并事實知識與已有知識重復和相矛盾的部分,并采取適當的措施進行處理,保證知識的一致性、無冗余、無矛盾。在知識圖譜構建過程中主要是對抽取出的實體、關系以及屬性信息進行概念消歧、冗余剔出和知識準確性檢查,主要涉及實體消歧、共指消解、知識合并等技術[3]。
知識推理是在知識表達的基礎上,進行機器思維求解問題,實現知識推理的智能操作過程,是目前的技術難點[3]。在知識圖譜構建過程中,主要通過干預和機器學習實現知識圖譜的更新和自我進化,是目前知識圖譜工程化和自動化的難點,涉及到的技術包括自然語言學習、機器學習和深度學習等技術。
2 科研本體
本體是對概念進行建模的規范,是描述客觀世界的抽象模型,旨在以形式化方式對概念及其之間的關系給出明確定義。科研本體目前沒有統一的定義,通常是以科研信息活動為描述對象,揭示和反映領域科研活動主體及各科研對象之間的聯系,如科研人員、科研機構、科研成果、科學會議、科研設備等各種對象屬性及其相互之間的本質聯系,是支持科研人員從海量科技文獻中進行知識發現的基礎。
2.1 書目本體
從科技文獻入手進行科研本體構建最早來源于書目本體。20世紀90年代初,斯坦福人工智能研究的著名學者Tom Gruber用LISP語言定義了書目數據的本體模型[4]。很多學者都嘗試利用語義網技術實現書目信息的本體化[5-6]。國內學者王軍采用了SKOS Core的所有類和關系構建了KVision書目本體,并提供了主要類和關系如圖2(圖片素材來自于文獻[7])。
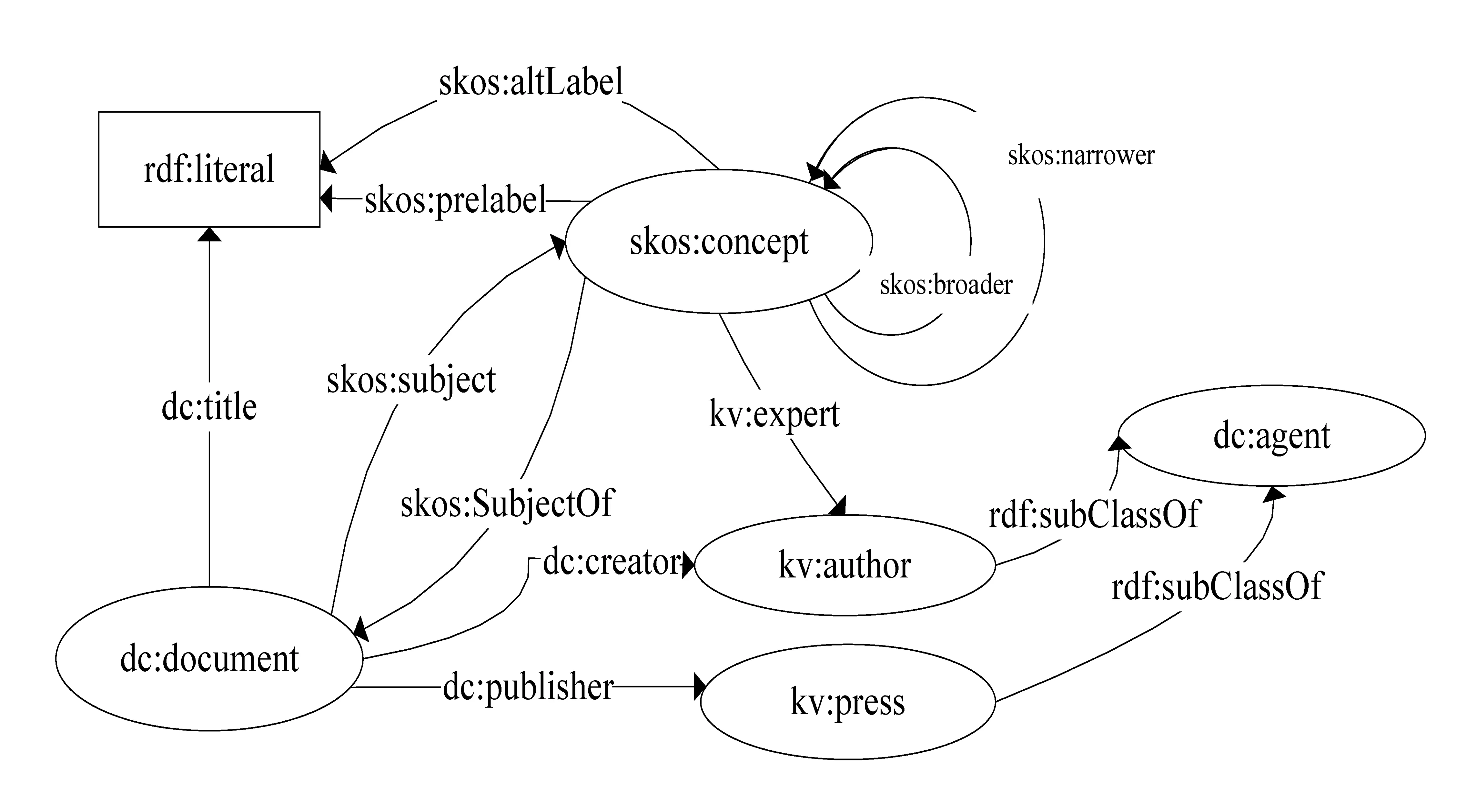
圖2 KVision本體
該本體中定義了文獻(Document)、概念(Concept)、作者(Author)、出版機構(Press)等實體類型。在關系的定義中,主要包括兩個方面,一是繼承主題詞表中概念間用代屬分參關系,二是利用文獻與概念、文獻與作者、文獻與出版社之間形成的固有關系進行定義。本體實例則是通過海量的文獻元數據進行填充。KVision最終用于概念瀏覽和簡單語義檢索支持。總之,書目本體更關注于文獻這個核心,通過與文獻與文獻附屬的科研實體之間的關系進行關聯擴展,相對簡單,因而對語義檢索的支持相對較弱。
2.2 VIVO科學家本體
VIVO是康奈爾大學圖書館于2004年啟動的項目,后期利用RDF、OWL、Jena和SPARQL等技術進行改造,最終形成了面向科學和學術交流的科學家語義網絡,即VIVO科學家本體,主要用來促進科研人員的科研網絡化協作[8]。該本體結構以歐美教育體系為原型,以促進科研人員的科研網絡化和協作為目標,描述內容覆蓋康奈爾大學所有院系的教員、科研人員和學科信息,分為人員、機構、學術活動和科研。VIVO本體由核心本體(VIVO Core)和一些大眾本體(BIBO,FOAF,SKOS等)構成,內容重點關注科學家的學術、教育與服務等方面。如學術方面的教育背景、出版物、專業領域、資助,教育方面開設的課程、報告會、培訓等,服務方面的組織會議、參加編委會、學術社團服務等。
VIVO集成了不同本體中大量的類,圍繞學術這個中心進行數據建模,主要實體類型除了傳統的機構(Organization)、概念(Concept)、學者(Person)、期刊(Journal)外,還包括與學者相關的教學(Teaching)、教育培訓(Education and Training)、獲獎(Award)、資助(Grant)等[9]。這些類之間通過對象類型屬性形成了復雜的學術知識網絡。
2.3 科研本體
隨著文獻數據量的大幅提升,特別是文獻計量方法和社會網絡分析方法的廣泛應用,科學研究活動中學者的關注點逐漸從獲取全文文獻轉變為文獻引證分析和科研主體實例分析。在這樣的背景下,各大出版商、服務商和信息服務科研機構迅速推進知識服務創新,圍繞科研信息活動中涉及的對象與關系,按照自身服務需求構建科研本體,在創新文獻檢索服務的基礎上開展科研實體分析服務。
信息出版和服務主要圍繞所占有的海量文獻開展服務,因此在科研本體建設方面仍然圍繞文獻這個核心實體,從文獻元數據中所描述的作者、作者單位、基金、文獻出處、主題概念、文獻分類、引文、共被引文獻、共引文獻等方面進行知識對象定義,利用文獻及其之間的關系將知識對象關聯形成知識網節,提高用戶在相關知識對象之間跳轉的友好性;通過檢索結果中對知識對象的統計分析幫助用戶快速獲取情報信息,從定量情報分析角度運用文獻信息,并輔以可視化展示。
國外以EI、SCI等權威數據庫服務為代表,國內則以清華同方、萬方數據、維普三大數據服務商為龍頭。其中萬方公司圍繞學科、主題、人物、機構、基金五要素構建檢索服務體系的脈絡,以科學為紐帶,組成各個要素之間的相互關聯關系,構成知識關聯網絡,各知識庫詳細描述各要素信息,形成知識節點,每個節點與所有放射狀箭頭所指的節點形成“以點帶面”的知識庫(圖3)[10]。
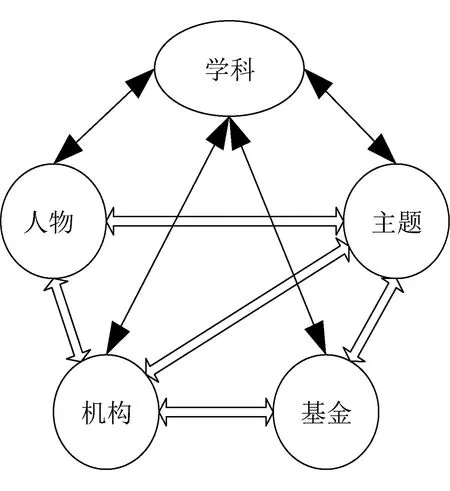
圖3 知識關聯“五要素”
信息服務科研機構以支撐科研活動為使命,在科研本體建設方面側重于結合自身科研活動特征需求進行科研本體設計。科技部組織的“面向外文科技文獻信息的知識組織體系”項目中,科技知識組織系統(Science& Techology Knowledge Organization System,STKOS)科研本體以國外重要科技機構、核心科技人員、主要科技期刊、國際重要會議為主體構建,涵蓋理工農醫四大領域,包括科研人員本體、科研機構本體、科研項目本體、科技會議本體、科研基金本體、科研成果本體等,揭示和反映了領域科研活動主體及各科研對象之間的聯系。中國醫學科學院醫學信息研究所開展了衛生政策科研本體建設,圍繞衛生政策研究過程設計了活動、機構、成果、人員、項目、研究主題、信息來源7個類[11]。中國科學院國家科學圖書館利用protégé構建了用于項目目標的科研本體,主要概念包括科研活動、科研產出、科研主體、科研設施和基本概念五大范疇。圖4是該本體部分關系描述示例[12],圖中粗箭頭是類層次關系,細箭頭是類之間邏輯關系。

圖4 科研本體部分關系描述示例
3 基于科研本體的國防科技知識圖譜
傳統的國防科技知識組織體系以國防科技敘詞表、分類表為基礎,通過不同來源詞表之間的概念映射形成較為完備的知識概念網絡,國防科技科研本體是對傳統國防科技知識組織體系的拓展和深化。
國防科技科研活動具有明顯的領域特色,國防科技科研本體緊緊圍繞其領域特色,在國防科技主題概念網絡的基礎上,對各種信息資源進行本地化處理與集成,形成近億條科技文獻元數據作為樣本進行建設。在知識描述廣度上,從主題概念單維度拓展到與科研活動息息相關的各種實體,包括科研機構、科研人員、出版物、學術會議活動、國防產品等多維度;在實施描述深度上,突破傳統“用代屬分參”敘詞關系,為每個實體定義屬性,并在實體自身維度內和跨實體之間構建多種關系,從而使整個知識組織體系從單維度簡單關系構成的知識網絡,全面轉變為多維立體的復雜關系網絡。而國防科技知識圖譜則依據國防科技科研本體中定義的包含實體概念、實體屬性和實體關系的數據模型,利用海量國防科技文獻元數據中所描述的信息,圍繞內容相似、文獻引用、用戶瀏覽、社會網絡關系等文獻之間客觀存在的顯性關系,完成知識單元填充之后形成的包含了隱性知識的關聯網絡。其示意圖如圖5所示。

圖5基于科研本體的國防科技知識圖譜
4 國防科技文獻知識圖譜構建與服務實踐
4.1 知識圖譜構建
基于科研本體的國防科技知識圖譜是以國防科技科研活動中的實體為節點,以實體關聯關系為邊,在時間流的驅動下形成譜系。而國防科技海量文獻元數據中包含了大量的科研實體信息,分別對作者、機構、期刊和會議活動等實體基本信息進行了描述。其中,作者是專業知識的研究或者傳播主體,發文量、引文量多的作者是重要的學科帶頭人、領域影響者;機構是作者所在的團體,影響力強的作者聚集機構一般是領域學科的重要發現源;期刊和會議是科研成果的聚集點,是科研創新和變革的重要陣地。這些實體之間彼此關聯,環環相扣,可以通過元數據從任何一個實體關聯到其他實體。本文構建的國防科技知識圖譜則以權威的國防科技文獻元數據為素材,采用面向對象的思想,通過數據清洗、實體歸一、關聯抽取等方法,最終完成圖譜構建。
4.1.1 實體模型定義
實體是以對象的形式存在的,每個實體都是一個對象。所抽象出的類包括各種屬性,有些是主要屬性,有些是次要屬性。對實體信息的模型定義需要分析它在元數據中的描述特征。
機構名稱在不同來源的元數據中描述有所不同,可能是因為歷史變遷導致名稱多次變動,也可能是長期以來學術界約定俗稱的說法,或者是描述規則不同形成不同寫法等。還有一種情況是描述相同,但不是一個機構,如每個國家都有科學院,相同的大學可以在不同地區建立分校。為此,明確所屬地相同的機構作為一個類,該類所屬的對象則是各種不同描述信息,以此為前提,定義如下的機構模型。
Organization = {Country*,City,Name*,Frelation,Fsub }
機構類包括國家、城市、名稱屬性和不同名稱的關聯函數、父子函數,其中國家和名稱是必要屬性。基于此模型,需要建立包括國家同義表、城市同義表,在此基礎上建立機構名稱規范系統,以及不同機構描述的關系(曾用名、簡稱、別名、錯拼等)對應表和父機構與子機構的對應關系表。
采用相同的思想,定義如下的作者、期刊、會議模型。
Author = {Organization*,Surname*,Firstname*,Email }
作者類包括所屬機構、姓、名、電子郵件地址,其中機構、姓和名是必要屬性。
Journal = {ISSN*,Coden,Publisher*,Name*,Frelation }
期刊類包括ISSN、CODEN、出版機構、期刊名稱和不同名稱的關聯函數,其中ISSN、出版機構、期刊名稱是必要屬性。
Conference = {Confername*,Conferdate*,Conferlocation*,Sponsor,Frelation }
會議類包括會議名稱、會議召開時間、會議召開地點、會議主辦者和不同名稱的關聯函數,其中會議名稱、會議召開時間、會議召開地點是必要屬性。
4.1.2 實體歸一化
長期以來,信息服務機構的海量文獻元數據是科研人員檢索文獻、全文獲取的重要來源。Web of Science、Dialog、EI等元數據庫是開展科學研究的基礎素材。隨著大數據分析技術的發展,基于科研實體等要素的學術文獻產出分析成為重要需求。圍繞文獻檢索和獲取的元數據存在描述不規范統一、各家自成一體的現象,嚴重影響了數據分析結果,實體歸一成為提高分析準確性的重要需求。
由于海量文獻元數據中包含實體眾多,很難對所有實體進行歸一。因此,為了遵循科研活動的基本規律,筆者只針對具有國防科技特色的、高價值數據庫,包括美國政府四大報告、AIAA、IEL等全文數據庫和EI INSPEC等文摘數據庫抽取其中學術產出較高、學術影響力大的科研實體進行歸一處理。具體實現中,采用短文本匹配、高頻次優先等方法進行,具體步驟如下:選取元數據庫并進行數據預處理,定義實體模型并抽取相關屬性,對實體屬性的可辨識性(可以表征實體區別于其他實體的辨識度)進行權值分配,定義不同類型實體的選取閾值(在元數據中出現頻次表征其學術重要度),通過短文本匹配算法對實體屬性進行權值計算獲得匹配的不同實體并給出唯一標識,對于一個實體的屬性信息選取該唯一標識下出現頻次最多的文本信息(如對期刊實體具有識別性價值的屬性值,ISSN、刊名完成短文本匹配后,出版社、CODEN等屬性值則選取出現頻率最高文本值)。
實體歸一是一個不斷迭代更新的過程,需要定期計算。在短文本匹配處理中,采取去停用詞、詞干抽取和忽略詞順等方法過濾噪聲信息,獲取到具有實際意義的關鍵詞集合。假設文本A形成的集合是S(A),|S(A)|表示包含的關鍵詞數量,兩個文本形成的集合A和B之間的相似度可以計算為:D(A,B) = |S(A)∩S(B)|/|S(A)∪S(B)|。
為上述的相似度設置一定閾值,有一部分可以由計算機直接處理,完成短文本匹配;有一部分需要人工核查;有一部分則不可能相同,直接過濾。
4.1.3 關聯網絡構建
所有科研實體信息通過處理后,形成了由唯一標識符標識的對象及其關系表,結合國防科技分類主題一體化詞表,與國防科技文獻元數據庫進行實體關聯和概念,所有實體采用唯一標識符進行連接,完成圖譜中各節點的邊建設。具體的數據表關系如圖6所示。
4.2 知識圖譜服務實踐
國防科技知識圖譜是以文獻元數據中客觀存在的科研實體關系為基礎的,知識圖譜構建后存儲在后臺關系型數據庫中。構建不是知識圖譜的目標,開展基于知識圖譜的服務和推進基礎文獻獲取服務向科研實體分析型服務轉型,才是知識圖譜構建的核心。筆者以構建的知識圖譜為基礎,從科研實體和科技論文等方面提供知識導航和檢索服務,并借助可視化技術進行圖譜關聯關系展示,實施了服務模式的實踐。
服務系統以已經構建完成的知識圖譜存儲數據庫為輸入,整個架構分上、下兩層,如圖7所示。圖7中間的下面一層為引擎層,主要完成對提供數據的存儲處理、索引構建和可視化引擎,其中數據庫待用CASS,索引采用Solr完成;上面一層是服務層,主要面向知識服務用戶需求提供多維度的導航、檢索、關聯展示和數據分析,主要實現以元數據、科研作者、科研機構、期刊、會議、概念為用戶查閱入口,在提供基本文獻檢索和獲取的同時,重點推出實體的導航、瀏覽、檢索和學術成果統計分析等,主要利用引擎層提供的功能進行分析結果數據輸出和可視化展示。

圖6關聯網絡數據表關系

圖7 國防知識圖譜服務系統架構
知識圖譜由不同類型的節點構成,服務系統面向各種節點類型設計了特色化的用戶服務界面。對于科研機構部分,主要提供了按照機構名稱首字母、機構類型、機構所屬區域等進行信息導航與發文統計,并利用地圖的形式提供發文數據的直觀瀏覽;對于主題概念,則主要以其范疇分類、概念關系為主要導航點,為用戶提供囊括中英文、融合多領域詞表的知識體系;對于論文,作為所有科研實體關聯的基礎,在提供基礎的專業分類導航外,則主要以檢索結果中的實體、概念及其之間的關系挖掘為主要展示內容,為用戶提供所檢索論文內容的同時,還提供對結果數據量化的分析情況。圖8是檢索“航空發動機”之后對結果進行分析后的知識圖譜可視化展示和文獻列表。
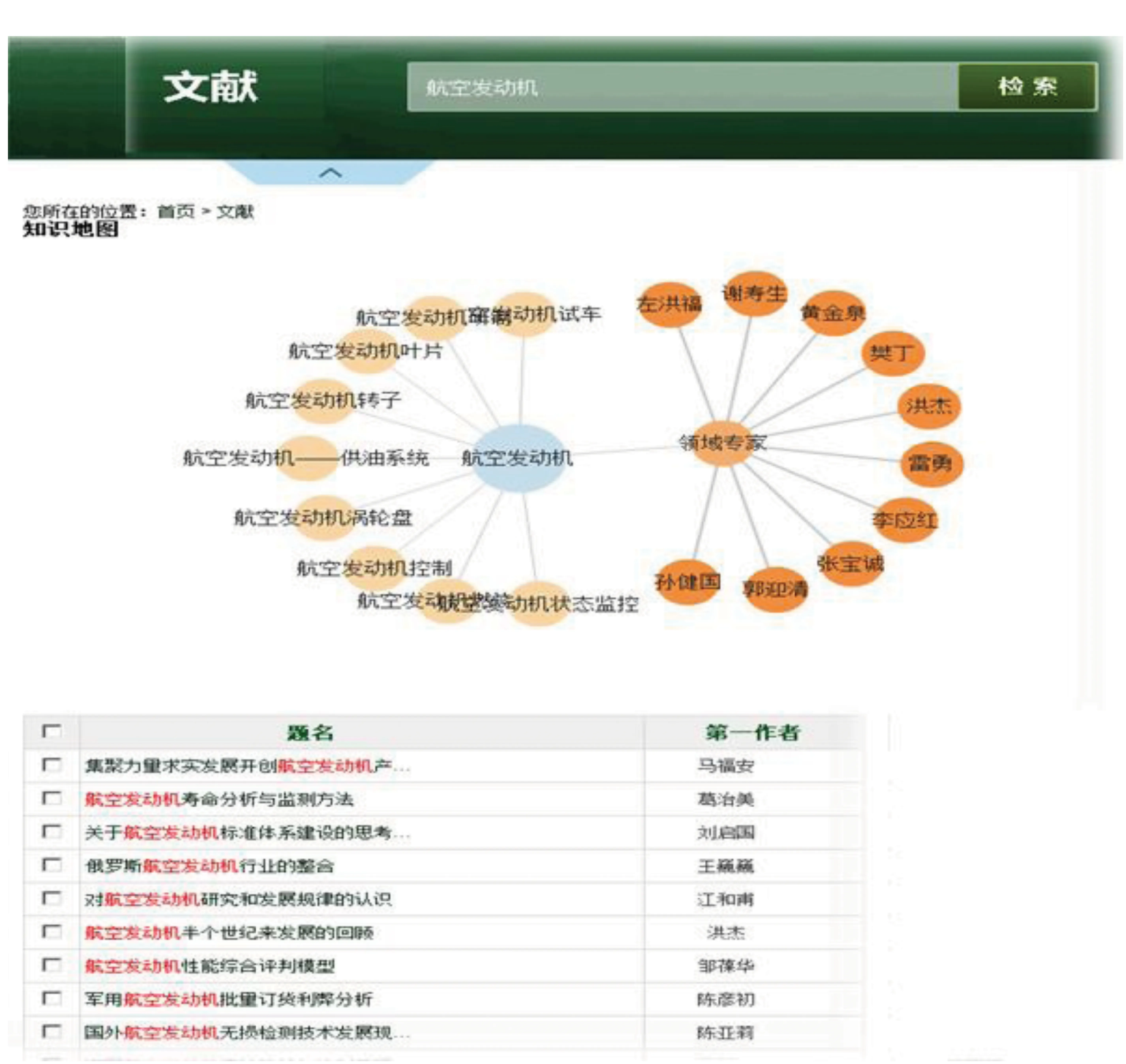
圖8國防知識圖譜服務系統界面截圖
5 結語
大數據分析技術的迅猛發展促進了海量文獻的量化分析,而知識圖譜構建又是開展量化分析的重要基礎。筆者從國防科研活動出發試圖構建國防科技知識圖譜,探索基于知識圖譜服務的新模式。在整個研究和試驗過程中,也發現了一些問題,主要有兩類。一是信息服務機構業務轉型問題。傳統的組織加工不再是核心工作,其重點應該轉向研究各領域間知識圖譜構建所依賴的本體模型。二是智能化處理技術需求強烈。由于數據量的指數級增長,未來大部分文獻處理工作需要計算機完成,因此實體識別、知識抽取、知識標注等技術還需要深入研究。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
