基于改進誘導有序加權調和平均(IOWHA)算子的傳染病組合預測模型研究
2018-03-22 01:27:42,
中華醫學圖書情報雜志 2018年7期
,
在我國,疾病導致死亡的因素中傳染病占了很大的比重。而且傳染病的危害也越來越嚴重,因此在分析研究傳染病爆發規律的基礎上,及時采取科學有效的方法對傳染病的發病率及其發展規律進行預測,能夠為制定有效的預防措施和控制傳染病的發展提供科學的依據。隨著人們對健康越來越重視,對傳染病預測精度的要求也越高。然而傳染病存在大量復雜的不確定影響因素,因此不容易獲得高精度的預測結果。
目前,傳染病預測方法很多,不同的預測模型具有不同的適應特征[1]。組合預測模型在提高精度方面比單個模型有明顯的優勢,因此如何選取恰當的單個模型和采取哪種組合形式將直接影響最終的預測精度。單一模型如ARIMA模型[2]、支持向量機[3]、灰色模型[4]、神經網絡模型[5]等的應用最廣泛。蔡海洋[6]構建了一種ARIMA- LSSVM組合預測模型,并將這兩個模型的預測值采用LSSVM方法確定合適的權重,得出預測結果,預測值明顯優于這兩個單個模型;葉曉軍[7]建立了基于GRNN的組合預測模型,通過GRNN模型將殘差修正GM(1,1)和ARIMA季節模型擬合的肺結核月發病率賦予變化的權重系數進行組合預測,擬合結果理想;嚴薇榮[8]采用串聯的方式建立了兼有ARIMA和GRNN模型優點的組合預測模型,神經網絡因具有自學習和高度非線性逼近能力而被廣泛用于預測;周玲玲[9]構建了混合ARIMA-NARNN模型預測人類血吸蟲病的流行趨勢,為檢測和防控血吸蟲病感染提供依據;吳文博[10]構建了遺傳算法優化的ARIMA-BP組合預測模型對手足口傳染病進行預測。
組合預測模型最核心的問題在于如何確定權重系數,使組合模型更高效地提高預測精度。組合方法有神經網絡方法[7]、串聯組合[8]、遺傳算法[10]、非線性組合方法[11]、變權重組合方法[12]等。雖然上述組合預測模型在組合單個模型時,都提出了確定權重系數的行之有效的方法,但依然存在缺陷,不管是哪種組合方法賦予各單項模型的權重系數都只與第i種預測方法有關,而與時間t無關。實際上同一個單項模型在不同時刻的預測結果并不相同,在某一時刻預測精度高,在另一時刻可能低。為了克服組合預測模型賦權問題的缺陷,本文在誘導有序加權調和平均(IOWHA)算子[13]的基礎上,將Theil不等系數與IOWHA算子[14]相結合,提出了一種改進IOWHA算子的SARIMA-GM相結合的組合預測模型。該模型是依據每個單項模型在各個時間點的預測精度的高低按順序賦予權重,總體提高預測精度,同時通過實例應用證明了該方法的有效性。
1 基本理論
1.1 ARIMA季節模型
差分自回歸移動平均模型(ARIMA)是一種專門針對非平穩復雜時間序列模式的預測方法,綜合考慮了時間序列的周期變化、趨勢特征,是時間序列預測中常用且精度又高的一種方法。ARIMA差分自回歸移動平均模型記為ARIMA(p,q,d),常用于醫學領域[15]、計算機領域[16]及交通領域[17]。其中p和q表示時間序列的自回歸階數和移動平均階數,d表示時間序列成為平穩序列所做的差分次數。若時間序列存在季節性周期波動,則采用乘積季節性差分自回歸移動平均模型[18],消除季節性差分,估計季節參數。ARIMA乘積季節模型記為ARIMA(p,d,q)(P,D,Q),其中P、Q表示時間序列的季節自回歸階數和季節移動平均階數,D表示時間序列成為平穩序列所做的季節差分次數。
ARIMA(p,d,q)(P,D,Q)模型記為:

(1)
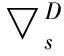
U(Bs)=1-Γ1Bs-Γ2B2s-…-ΓPBPs
(2)
V(Bs)=1-H1Bs-H2B2s-…-HQBQs
(3)
(4)
ARIMA模型的預測分為5個步驟。
數據的預處理:判斷原始數據的平穩性,并將數據進行平穩性處理。
模型識別:判斷時間序列服從的時序模型,根據其統計特征確定初步的模型結構,即判斷模型和確定階數p、q、d、P、Q、D的大小,通常采用AIC準則或BIC準則來確定選擇參數。
模型估計:對識別的模型進行參數估計及確定,參數估計的方法有最小二乘法、極大似然法和矩向量估計。
模型檢驗:模型的顯著性檢驗,即殘差序列是否為白噪聲序列,模型參數的顯著性檢驗,即參數是否有效。
模型應用:參數確定后以及模型檢驗能夠使用后,便可以用該模型對時間序列進行預測。預測流程如圖1 所示。
1.2 灰色預測模型理論
GM(1,1)模型是灰色模型中最基礎也是最常用的一種預測模型。因其建模過程簡單、易于求解、預測效率好且精度高等特性而被廣泛應用于各個領域的預測問題,如用電量預測[19]、建筑安全事故預測[20]和疾病預測[4]等。具體的建模過程如下:設原始序列X(0)為
X(0)=[X(0)(1),X(0)(2),…,X(0)(n)]
(5)
對X(0)做一次累加(1-AGO),累加的目的是為了弱化隨機序列的波動性和隨機性,得到新的序列:

圖1 ARIMA模型的預測流程
X(1)=[X(1)(1),X(1)(2),…,X(1)(n)]
(6)
對X(1)做鄰均值生成等權數列:
Z(1)=[Z(1)(1),Z(1)(2),…,Z(1)(n)]
(7)
根據灰色理論建立灰色模型GM(1,1)的微分方程模型為:
x(0)(k)+az(1)(k)=b
(8)
式中,X(0)(k)稱為灰導數;a為灰系數,表示X(0)的增長速度;b為灰作用量,表示序列X(0)的數據變化。對累加生成數據做均值生成B與常數項向量Y
(9)
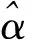
2 基于Theil不等系數的IOWHA算子組合預測模型
2.1 IOWHA算子和Theil不等系數
2.1.1 IOWHA算子


(10)
則函數fω被稱為u1,u2,…,un所產生的n維誘導有序加權調和平均算子,簡稱為IOWHA算子。ui為ai的誘導值,u-index(i)是u1,u2,…,un中按從大到小的順序排列的第i個大的數的下標。從公式中可以看出IOWHA算子是對誘導值u1,u2,…,un按從大到小的順序排列后所對應的a1,a2,…,an進行有序加權調和平均。權系數ωi與ai的大小及位置無關,而與其相對應的誘導值所在的位置有關。
2.1.2 Theil不等系數
Theil不等系數是一種衡量模型預測精度的評價指標,其計算公式為:

(11)

2.2 改進IOWHA算子的ARIMA-GM組合預測模型

(12)
式中,ait表示第i種單項預測方法在第t時刻的預測精度,且ait。∈[0,1]。我們把預測精度看作是預測值的誘導值,從而得到組合模型中n種單項預測方法在第t時刻的預測精度與其在樣本區間的預測值構成了n個二維數組(a1t,X1t),(a2t,X2t),…,(ant,Xnt)。設a-index(it)表示n種單項預測方法在第t時刻的預測精度序列按從大到小的順序排列后的第i個大的數的下標,則n種單項預測模型在第t時刻的預測精度序列的IOWHA組合預測值公式如下:

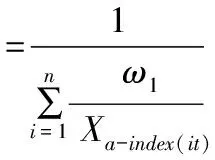
(13)
從式中看出,組合預測模型的權重系數與單項預測方法類別無關,而與各個單項預測方法在各個時刻點的預測精度大小密切相關。
結合上式(13)令
式中,et表示組合預測值在第t時刻與實際值之間的倒數誤差,i=1,2,...,n,t=1,2,...,N。

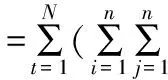
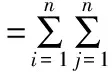
(15)
式中,F=(Fij)n×n表示n階IOWHA算子的組合預測協方差信息方陣。所以基于IOWHA算子的組合預測值倒數序列與實際值倒數序列的Theil不等系數τ可表示為:

(16)
上式表明基于Theil不等系數的IOWHA算子組合預測值序列與實際觀察值序列的Theil不等系數為組合預測方法的權重系數ω1,ω2,…,ωn的函數,τ(ω1,ω2,…,ωn),τ(ω1,ω2,…,ωn)越小,則組合預測模型的精度就越高。所以基于Theil不等系數的IOWHA算子組合預測模型表達式如下:


(17)
該模型實際上是一個線性規劃問題,可用MATLAB進行求解。只有當τ(ω1,ω2,…,ωn)<τmin,該組合預測模型的結果才是優性的,其中τmin表示n種單項預測倒數值序列與實際值倒數序列的Theil不等系數的最小值。
組合預測模型的基本步驟如圖2所示。

圖2 組合模型預測的基本步驟
3 實例應用
3.1 數據來源與評價指標
本文數據來源于公共衛生科學數據中心,它是國家人口健康科學數據共享平臺的主要數據中心之一。選取了2005-2015年河南省流行性感冒的月發病率為研究數據,共計132個樣本。其中選取前120個(2005-2014年)數據作為訓練樣本,其余12個(2015年)數據作為檢驗樣本,對其預測值與實際值進行比較分析,來判斷組合預測模型的精度。
為了評價預測模型的預測效果和驗證預測結果的精確度,通常選取均方誤差(MSE)、平均絕對相對誤差(MAE)、平均絕對百分比誤差(MAPE)等評價指標進行模型評價。指標表達式如下:
(18)
(19)
(20)
3.2 ARIMA預測模型的建立與預測
3.2.1 數據的平穩化
采用SPSS24.0件構建ARIMA預測模型。首先判斷數據序列是否具有季節性趨勢。根據序列圖(圖3)可以看出,2005-2014年流行性感冒的月發病率呈現出比較明顯的季節成分,周期長度為12個月,而且具有不平穩性,存在著一定的上升趨勢。對序列進行平穩化處理,經過一階季節差分(D=1)和一階差分(d=1)處理后,得到的新數據序列基本穩定(圖4)。

圖3原始數據的序列圖

圖4 一階季節差分和一階差分差分處理后的序列圖
3.2.2 模型識別
經過一階季節差分和一階差分處理后,差分序列基本均勻分布在0刻度線上下兩側,差分序列是平穩的,D=1,d=1,因此可建立ARUNA(p,1,q)(P,1,Q)12(圖5)。從月發病率的自相關圖(ACF)和偏自相關圖(PACF)可以看出,q=1,p=0、1或2,Q=0或1,P=0或1,采用BIC信息準則,即BIC值越小,模型精確度越高。各備選模型的正態化BIC值如表1所示。通過比較得出ARIMA(1,1,1)(0,1,1)12的正態化BIC值最小,即擬合效果最好。擬合效果如圖6所示。由圖6可以看出,實際發病率基本都在預測值95%置信區間內。

表1 模型比較
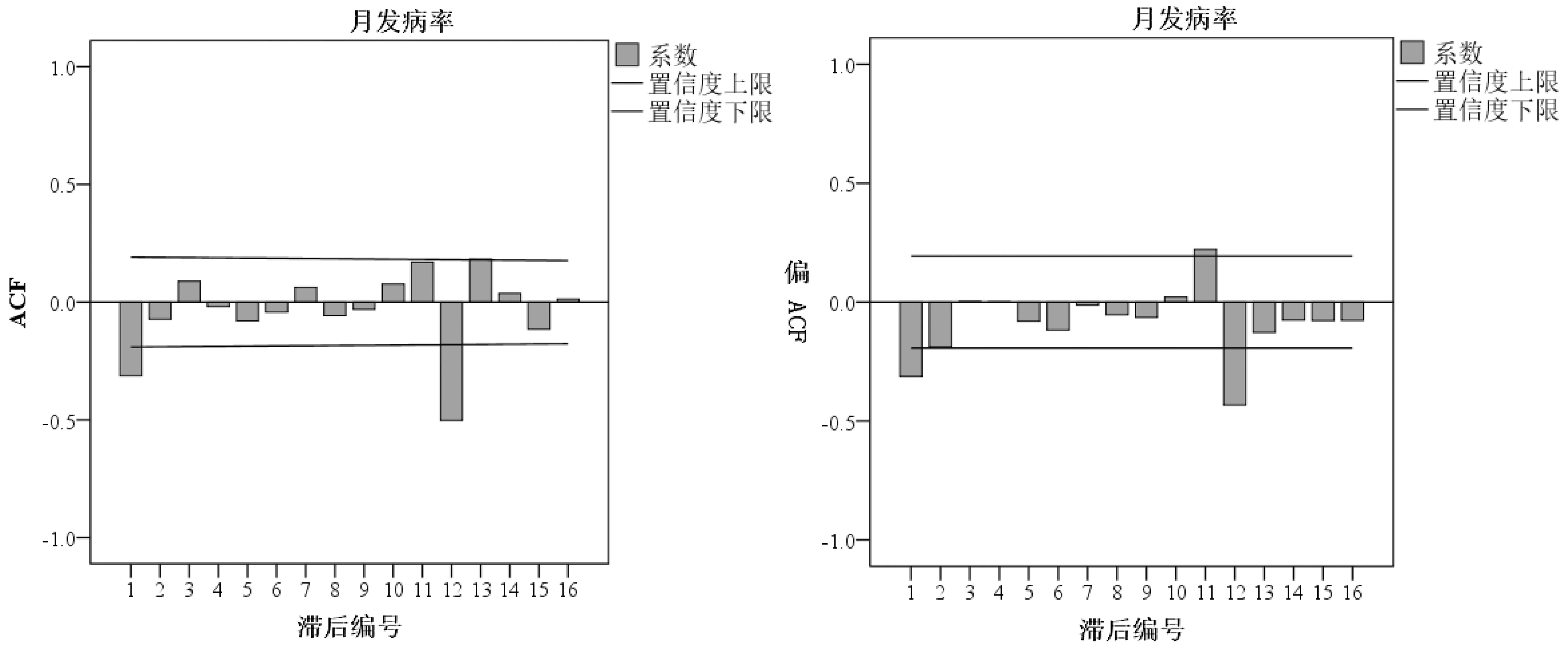
圖5 月發病率的自相關圖與偏自相關圖
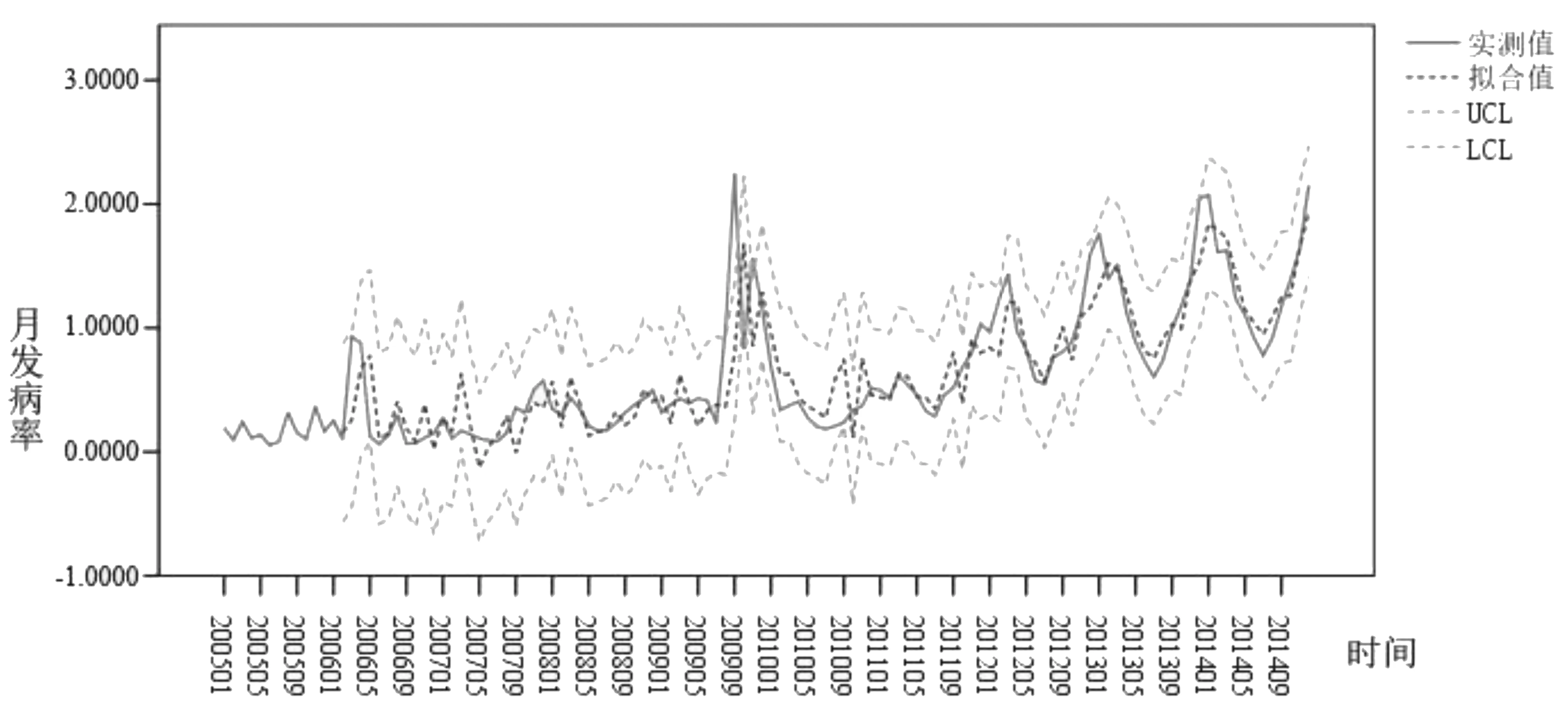
圖6 ARIMA(1,1,1)(0,1,1)12模型擬合效果圖
3.2.3 模型預測
利用ARIMA(1,1,1)(0,1,1)12模型預測2015年1-12月河南省流行性感冒的月發病率情況。模型預測值與實際值比較如表2所示。從表2中可以看出,實際值均落在預測值95%的置信區間內,12個月中有7個月的預測精度都在80%以上,2月、9月、10月的預測精度在70%多,只有6月、7月的預測精度在60%多。雖然預測值的波動情況和實際值相比存在差異,但總體來說,模型的預測效果較好。

表2 2015年河南省流行性感冒發病率實際值與ARIMA模型預測值(1/10萬)
3.3 GM(1,1)模型預測
采用MATLAB構建GM(1,1)模型,對河南省2005-2015年流行性感冒月發病率進行預測。由原始數據的序列圖可知,該序列具有較明顯的周期性趨勢,而灰色模型對波動大、周期型數據的預測效果并不好。我們根據周期性特征將原數據按月分為12組,即12組數據序列。根據灰色模型GM(1,1)的高預測精準性,分別對2005-2014年每月的流行性感冒發病率進行擬合,并預測出2015年每月的發病率。最后整體的擬合效果如圖7所示。

圖7 GM(1,1)模型擬合效果圖
從圖7可以看出,除個別峰值外,擬合效果良好,說明對于季節性數據序列,灰色模型采用這種方式也能得出很好的預測效果。灰色模型對2015年每月流行性感冒發病率的預測值與實際值如表3所示。從預測精度來看,除了2月和12月的預測精度在70%以下,其他月份的預測精度都在70%以上,其中有3個月達到90%多。因此預測效果較好,但從整體來看預測性不穩定。

表3 2015年河南省流行性感冒發病率實際值與GM(1,1)模型預測值(1/10萬)
3.4 改進IOWHA算子的組合模型預測值及各模型結果對比分析
根據ARIMA預測方法和為GM(1,1)預測方法,構建第t時刻預測精度與其對應模型的預測值的二維數組(a1t,X1t),(a2t,X2t),t=1,2,…,12,代入公式(13)中計算IOWHA算子組合預測值為:
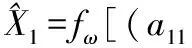

… …

式中,ω1,ω2表示兩種單項模型在組合預測模型中的加權向量。
分別算出每月基于IOWHA算子的組合預測值,將結果代入到基于Theil不等系數的IOWHA算子組合預測模型表達式中:


利用MATLAB求解得出組合預測模型的最優權重系數ω1=0.8564,ω2=0.1426,代入到IOWHA算子組合預測值表達式中計算得到2005年-2014年每月的流行性感冒發病率和整體的組合預測模型擬合效果(圖8)及預測的2015年河南省流行性感冒月發病率(表4)。


圖8 組合預測模型擬合效果圖
從圖8中可以看出,實際值與擬合值很相近,擬合效果更好。從表4中可以看出,使用改進的IOWHA算子組合預測模型的預測值與實際值最接近,精度都在70%以上,比單項預測方法穩定且預測效果好。為了更明顯地評價各種預測方法的預測效果和精確度,按照選取的預測方法評價指標,計算各種預測方法的預測效果評價結果(表5)。

表5 各種預測方法的預測效果評價指標體系
從表5可以看出,本文創建的基于改進IOWHA算子的組合預測模型的各項指標值都低于ARIMA模型和GM(1,1)模型的指標值,說明組合模型的預測精度高于單項模型及Theil不等系數與IOWHA算子結合的組合方法的有效性和可行性。從各項指標值的大小與文獻[7]中相應的各指標值相比,明顯偏小,進一步證明本文的方法在一定程度上優于該文的組合預測模型,預測效果更好。另外,改進IOWHA算子的組合預測模型可以有效提高流行性感冒發病率預測的精度,并且為實現傳染病發病率預測提供了可行性。
4 結語
針對傳染病發病率時間序列具有非平穩性及如何提高發病率的預測精度,本文提出了一種Theil不等系數與IOWHA算子結合的組合預測模型。該模型是依據每個單項模型在各個時間點的預測精度的高低順序賦予不同的權重,與每個時刻不同預測方法的預測精度密切相關,彌補了單項模型在預測時的缺陷。相比于目前使用的ARIMA預測模型、GM(1,1)預測模型等單項預測方法以及傳統組合方法和神經網絡組合方式,改進的IOWHA算子組合方式能更好地預測傳染病發病率的波動趨勢。通過對河南省流行性感冒發病率預測的實例,組合預測模型的預測效果評價值以及預測精度的穩定性與研究的ARIMA模型和GM(1,1)2單項模型相比,都相對更好,驗證了組合預測模型的實用性。文獻[7]中的ARIMA模型和GM(1,1)兩個單項模型,采用的是GRNN神經網絡的組合方法。從其效果評價指標MAE、MSE、MAPE的大小與本文相比可以看出,本文提出的改進IOWHA算子組合預測模型的預測精度更高,預測效果更好,可為傳染病預測模型的選擇提供參考。但在發病率波動較大的幾個月,組合預測模型的預測精度僅有70%多,這是由傳染病的隨機性和非平穩性導致的。本文只考慮了歷史數據中發病率的波動趨勢,如果能將影響傳染病的其他因素考慮在內,就可以進一步跟蹤發病率的波動趨勢,提高傳染病發病率的預測精度。
下一步將探索預測精度更高、效果更好的單項模型,然后采用本文提出的組合預測方法進行組合驗證最后的預測精度的有效性,并在本文研究基礎上進一步設計和實現傳染病預測系統,為傳染病的預測和防控提供幫助。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
