基于Logistic回歸模型的高鐵客運市場細分
2018-03-30 00:44:56李彥瑾羅霞劉悅朱海
交通運輸工程與信息學報 2018年1期
關鍵詞:分類
李彥瑾,羅霞,劉悅,朱海
(西南交通大學,交通運輸與物流學院,成都 610031)
0 引 言
市場細分有助于運輸企業快速高效地確定目標市場,對改善客運產品、提高運營效益具有積極意義。自市場細分概念提出以來,國內外學者對其進行了大量研究。國外研究方面,Tony指出目前市場細分的研究主要分為兩個方向:消費者導向型與產品導向型[1]。Tsai則提出以消費者的最近一次消費時間、消費頻率、消費金額3個變量進行細分并識別最有價值的客戶[2]。國內鐵路市場研究方面,趙娟等基于市場細分理論,運用因子和聚類分析方法對京滬高鐵旅客調研數據進行研究[3]。錢丙益等結合武廣客運專線旅客問卷調查數據,采用混合回歸模型,將市場細分為效率型、經濟型、休閑型、體驗型4個細分市場[4]。
從現有研究來看,目前國內對鐵路市場細分的研究以產品為導向的細分方法為主,變量一般包括安全、速度、準點和價格等,而從復雜的旅客出行特征角度出發,利用概率分類法進行市場細分的精確研究仍然較少。
在渝利鐵路開通運營之后,為使其具備優良的客運管理水平以及競爭實力,需要研究出一套科學的、可操作性強的客運市場細分方法,準確應對市場需求,設計合理的渝利鐵路運輸產品。因此,本文以渝利鐵路客運市場為實際案例,根據旅客出行行為特征,選取Logistic智能分類算法對渝利鐵路客運市場進行細分,并對各細分市場的旅客特征進行歸納總結,具有一定的應用意義。
1 調查概述
本次旅客出行調查分為預調查和正式調查兩個階段。預調查于2015年9月5日在重慶北站候車大廳進行,受訪者為高鐵乘客和動車組乘客,設計并采用了RP/SP組合的調查問卷。正式調查于2015年9月12日在重慶北站候車大廳和重慶—利川涼霧站方向的渝利高鐵列車上進行,并針對預調查存在的問題對問卷進行了改進。
本次調研包含2個工作日和1個休息日,涉及重慶北站、復盛站、長壽北站、涪陵北站、豐都站、沙子站和涼霧站7個車站。其中預調查在1個工作日內進行,正式調查分為1個工作日與1個休息日兩個階段進行。
選擇1個工作日(星期三)進行前期預調查,回收與處理問卷1 492份。各車站回收問卷數量如圖1所示。由圖1可以看出,各個車站的受訪者數量分布并不均勻,利川站的受訪比重過多。這將影響我們對調查結果的分析處理,因此本文通過優化問卷結構、簡化問題設置并選擇另一個工作日(星期二)開始進行正式調查。
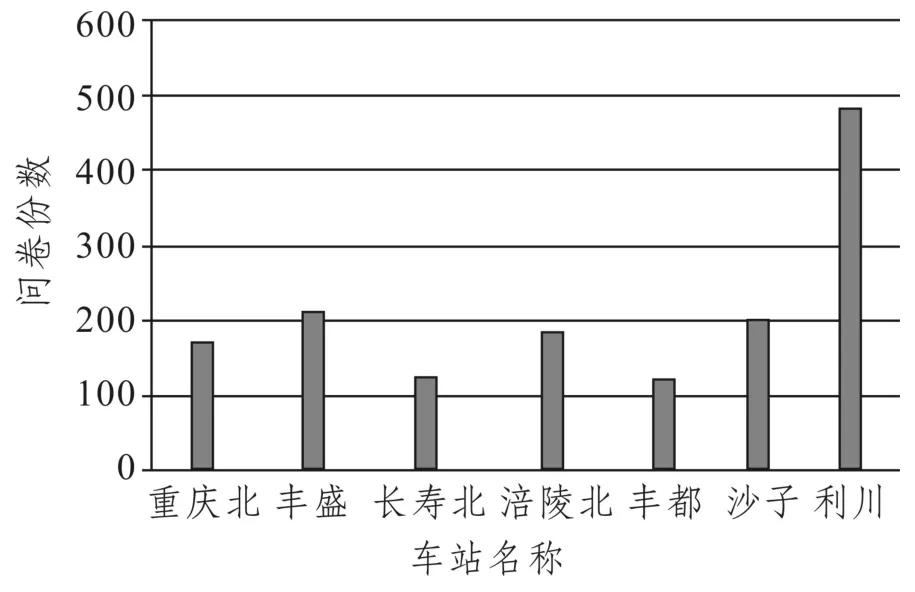
圖1 工作日內預調查各站點回收問卷數量Fig.1 Number of questionnaires collected at each station during weekdays
正式調查采用改進后的調查問卷,回收與處理問卷1 298份。由圖2可得,雖然各車站回收問卷數量較改進前更均勻,但利川站的回收份數依然是最高的。這表明可能有其他因素影響調查結果。因此,選擇1個休息日(星期六)再次進行正式調查,以此來判斷調查時間因素是否會對調查結果產生重要影響。
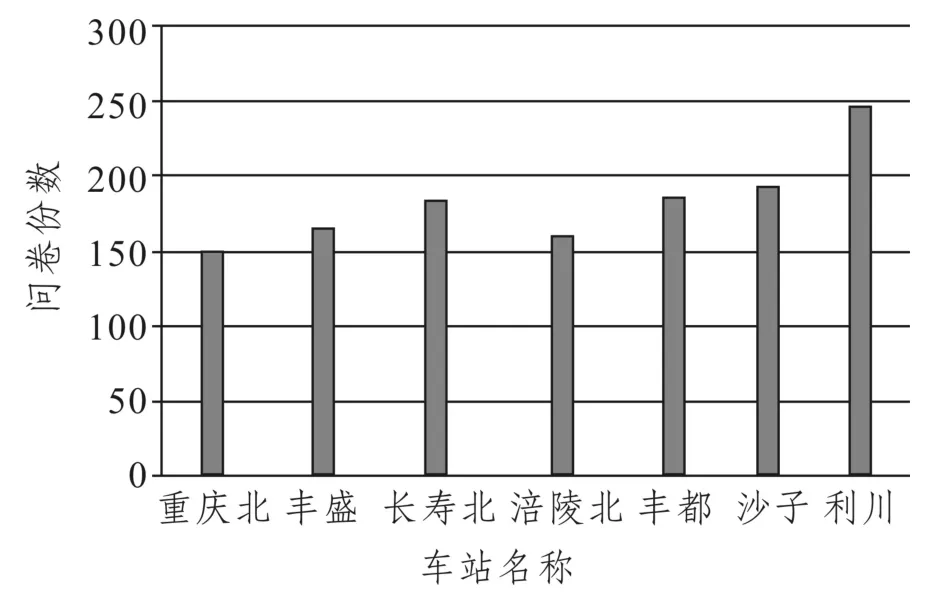
圖2 工作日內正式調查各站點回收問卷數量Fig.2 Number of valid questionnaires during weekdays
在1個休息日進行正式調查,回收與處理問卷1 374份,各車站回收的問卷數量如圖3所示。由圖3可得,在休息日內各站點回收數量基本均勻,表明調查時間確實為影響調查結果的主要因素。

圖3 休息日內正式調查各站點回收問卷數量Fig.3 Number of valid questionnaires during weekend
因此,本文采用分層抽樣的方法,分車次隨機選取旅客進行面對面問卷調查,內容包括年齡、職業、月收入、出行目的等旅客出行特征共計6個屬性。然后,分別選擇兩個數據集統計、處理來自工作日(星期二)與休息日(星期六)的調查數據。正式調查共回收4 890份調查問卷,篩選除去信息殘缺的調查問卷,得到4 164份有效問卷。
2 建模與算法
Logistic回歸分類作為概率分類法的常見類型,其分類標準為使后驗概率達到最大。通過這樣的分類方法,可以在樣本數據可信度較低的時候不進行強制分類,排除樣本中的“噪聲”干擾,從而避免分類錯誤。另外,這種基于概率的模式分類算法還能夠對多種屬性的樣本分類問題得到一個較顯著的分類結果[5]。因此,本文選用Logistic回歸分類進行市場細分。
2.1 基本原理
假設渝利鐵路旅客市場上存在N個旅客,第n(n=1,2,3,…,4 164)個旅客對樣本中第i個屬性xi(i=1,2,3,…,6)的評價為xni,對產品的總體評價為yn。假設存在c個細分市場,每個細分市場在整個客運市場的占比分別為θ1,θ2,…,θc,滿足(即滿足概率總和為1的約束條件)。
根據Logistic回歸,使用線性對數函數對分類后驗概率q(yj|xi)進行模型化:
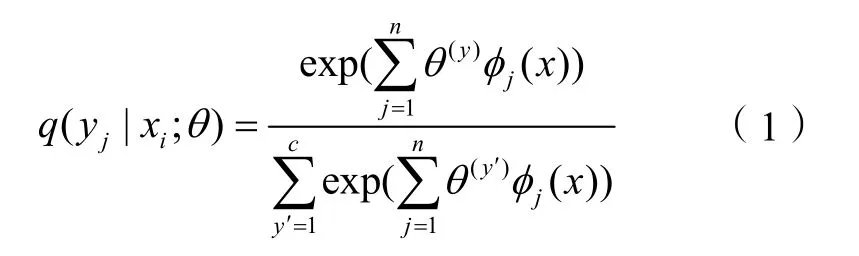
式中,q(yj|xi;θ)為第i(i=1,2,3,…,6)個屬性xi影響第j(j=1,2,3,…,n)個總體評價樣本yj的概率,θ為待優化參數,表示分類后的各個子市場比例;φj(x)為第j個樣本中各個屬性x的具體取值。
2.2 模型求解
利用對數最大似然函數法求解Logistic回歸分類模型。其中,似然函數是將當前樣本,i=1,2,…,6由式(1)分類的概率看作是一個關于參數θ的函數,而對數似然函數是指其對數。于是,作如下變換:似然→對數似然
因此,可將該分類問題等價為下式的最優化問題來定義:
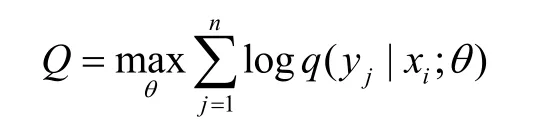
上述目標效用函數Q對于參數θ是可以微分的,故可利用概率梯度法來求解最大似然估計問題的解,具體算法如下:
①給定θ以適當地初值,本文取0.25(假定初始有4個子市場,所占市場份額均等為0.25),收斂精度η=0.01;
② 將隨機抽樣的有效樣本導入(xi,yj),i=1,2,3,…,6,j=1,2,3,…,4164;
③ 對于選定的訓練樣本,以梯度上升的方向對參數θ=(θ(1)T,…,θ(c)T)T,c=1,2,3,4按下式進行更新:
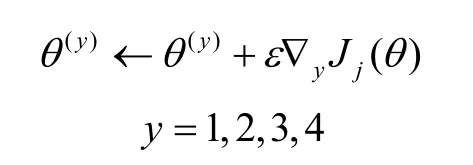
此處,ε為表示梯度上升幅度的正常數,取0.001。?yJj(θ)是指順序為j的訓練樣本所對應的對數似然函數Jj(θ)=logq(yj|xi;θ)關于θ(y)的梯度上升方向。
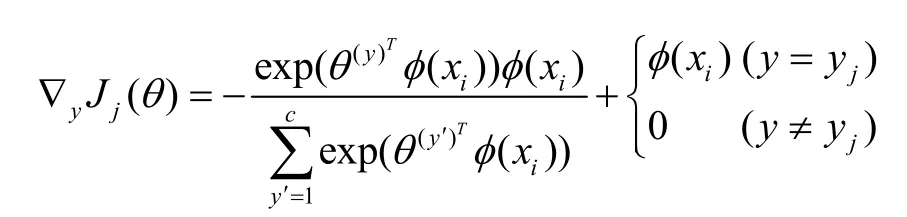
2.3 求解結果
本文將隨機抽樣獲取的4 164份有效調查問卷,通過將問卷中各個問題選項進行數據預處理并導入matlab中,采取Logistic回歸法進行市場細分,再利用概率梯度算法進行求解,得出算法收斂圖與市場細分圖如圖4、圖5所示。
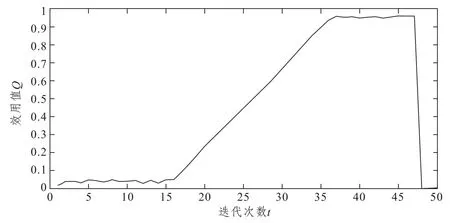
圖4 模型求解算法收斂圖Fig.4 Model convergence
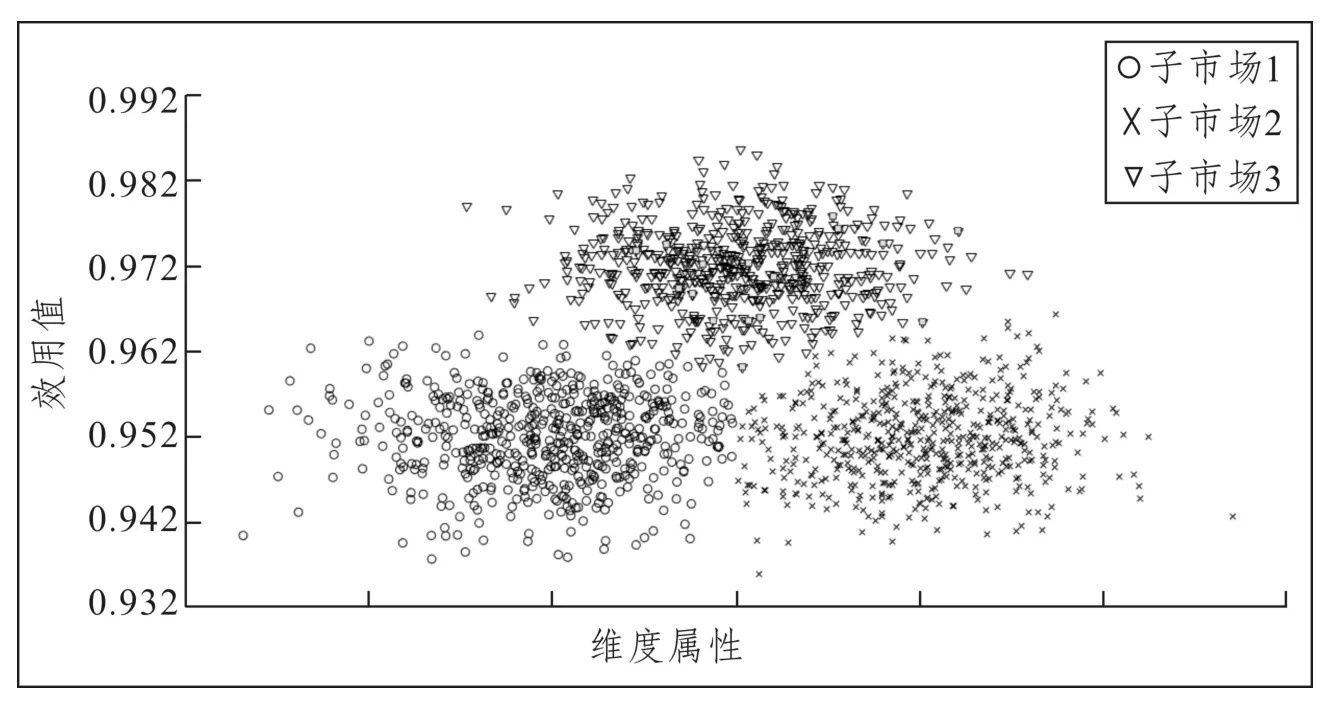
圖5 按旅客出行目的屬性維度方向投影的市場細分圖Fig.5 Market segments by trip purpose
由圖4可以看出:算法初始階段在各個方向搜索最優梯度,當迭代至12次時獲得可行的梯度方向并朝著效用函數值增大的方向收斂;當運行至第37次時開始平穩,并在迭代第46次時獲得平穩解,此時效用函數值為0.988。最后該平穩解滿足收斂精度要求,從而終止算法將效用值歸0。
由圖5可以看出:Logistic回歸分類法最終將容量為4 164的調查數據樣本分為了3類,且絕大部分樣本細分后的效用函數值在0.932以上并在0.988左右到達穩定極值點,反映出客運市場細分效果較好。
3 子市場描述
將分類后其效用函數值分布于[0.932,0.992]區間的樣本數據進行提取與計數,可以得到細分后三個子市場的樣本容量大小,分別為:子市場1(1 822)、子市場2(891)、子市場3(1 134)。其余樣本數據經分類后,未分布在效用顯著區間,故不予統計。
3.1 聚類中心識別
分別搜索各個子市場的類中心,并以類中心為圓心按子市場容量的55%為半徑,選擇各個子類的代表性樣本數據,如圖6所示。
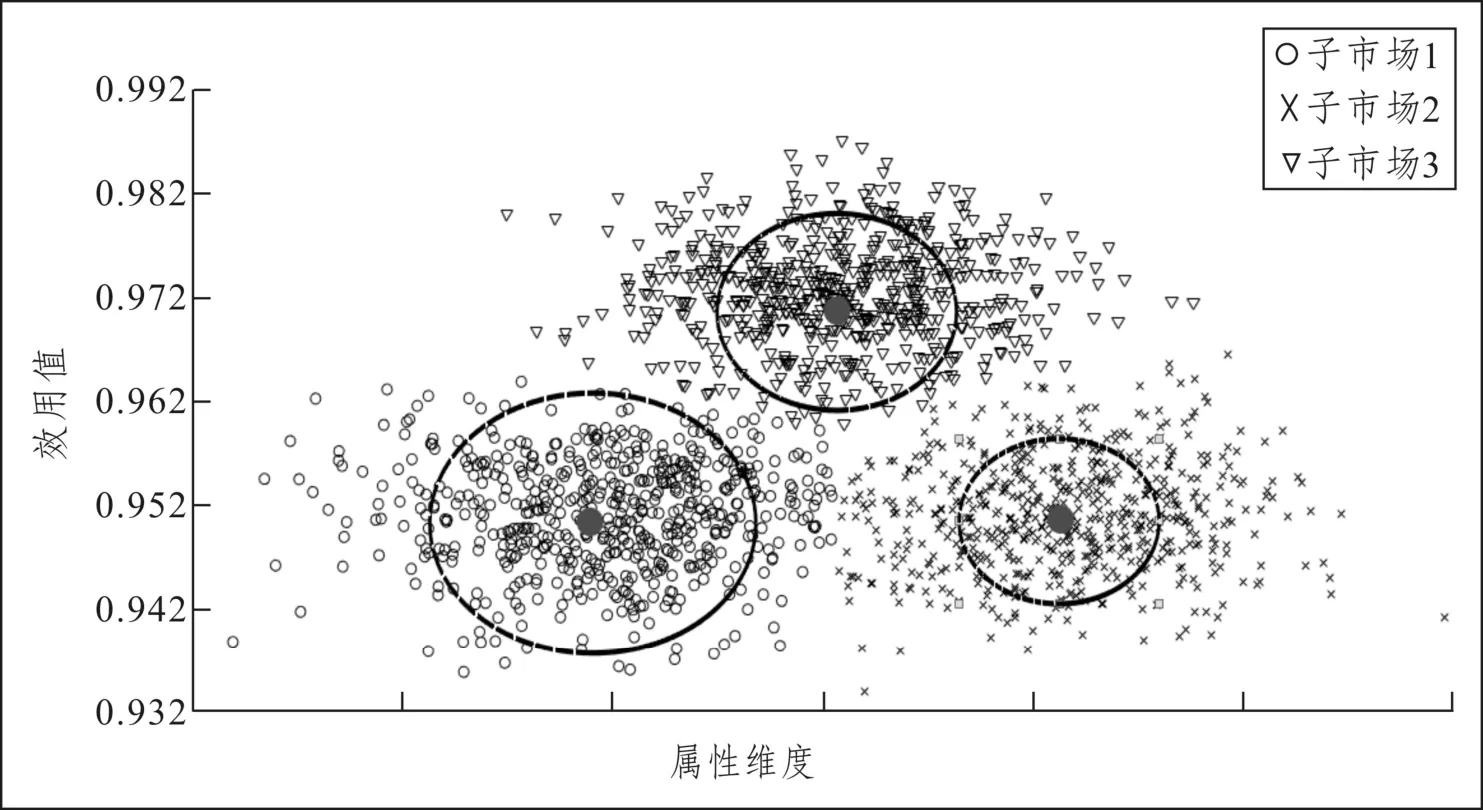
圖6 按代表性樣本數據的市場細分Fig.6 Clusters of the sub-markets
3.2 子市場劃分
將提取出的代表性樣本數據按出行目的進行歸納,可總結為:外出務工型(子市場1)、非經濟出行型(子市場2)、商務出行型(子市場3)。并按照年齡、月收入和職業3個旅客特征指標進行統計分析,分別對每個子市場進行細分,得到經濟實惠、中堅力量和出行品質注重三個子群體。故建立子市場細分模型,如表1所示。

表1 子市場旅客容量統計表Tab.1 Population statistics of the submarkets
3.3 子市場合并與描述
由于需求模式最終反映為出行行為模式,同時為了便于進行產品設計,需要對市場采取一定的規則進行合并,使之更貼合實際生產運營的需要。其中,合并規則包括以下兩個方面:①將市場容量明顯偏小的子市場合并;②合并性質類似的市場。故合并完成后的市場細分如表2所示。
由此可見,客運市場被細分為如表3所示的A-E共計5個子市場,且各個子市場具有顯著的差異化特征。

表2 合并后子市場旅客容量統計Tab.2 Population statistics of regrouped submarkets

表3 合并后子市場特征描述表Tab.3 Descriptive statistics of the regrouped submarkets
4 結 論
針對市場細分的旅客特征分析,本文得出如下結論:
(1)利用Logistic回歸分類法對隨機抽樣樣本數據分類處理,可在較少迭代次數內得到平穩解,利用出行目的維度投影得到的二維圖,表明該方法分類效果比較顯著。
(2)通過對子市場的合并,發現在各個子市場內旅客的年齡、月收入與出行目的是進行高鐵客運市場細分和市場特征描述的顯著影響指標。
(3)如何根據分析結果,對各細分市場的需求進行預測,并進而制定科學的產品定價實現高鐵運營收益最大化,將是下一步的研究方向。
[1] LUNN T. Segmenting and constructing markets[A].Robert Worcester and John Downham. Consumer market research handbook,Third revised and enlarged edition[C].Elsevier Science Pulishers B. V. ,1986,387-423.
[2] TSAI C Y,CHIU C C. A purchase-based market segmentation methodology[J]. Expert Systems with Applications,2004,27(2):265-276.
[3] 趙娟,任民. 京滬高鐵客運市場細分與客票營銷策略研究[J]. 鐵道經濟研究,2014(6):13-17.
[4] 錢丙益,帥斌,陳崇雙,等. 基于混合回歸模型的客運專線旅客市場細分研究[J]. 鐵道運輸與經濟,2014,36(1):60-65.
[5] TITTERINGTON D M,SMITH A F M,MAKOV U E.Statistical analysis of finite mixture distributions[M].New York:Wilcy,1985.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
