一種面向容災存儲系統的重復數據刪除方法
2018-04-10 01:46:22◆彭剛
網絡安全技術與應用 2018年4期
◆彭 剛
?
一種面向容災存儲系統的重復數據刪除方法
◆彭 剛
(四川大學計算機學院 四川 610065)
針對海量數據的存儲和備份存在大量的冗余數據,造成存儲空間的巨大浪費問題,本文分析了現有的重復數據檢測和刪除技術,提出了一種面向容災存儲系統的重復數據刪除方法——FWinnowing(Fast Winnowing )。FWinnowing采用改進后的Winnowing動態分塊算法對數據進行分塊,使用MD5計算各個分塊的數據指紋值,通過檢索指紋庫來判斷指紋值是否已經存在,從而判斷出該塊所對應的數據是否重復,最終達到重復數據檢測和刪除的目的。本文對FWinnowing進行了實驗驗證,結果表明該方法相比較現有的重復數據檢測和刪除方法,有效地降低了網絡傳輸流量并提高了重復數據檢測率。
容災備份;重復數據;FWinnowing
0 引言
市場調研機構IDC預計,未來全球數據總量年增長率將維持在50%左右,55%的數據需要進行容災備份并且應用系統中有60%的數據是冗余的[1]。為了節省存儲資源,降低網絡數據傳輸帶寬重復刪除技術已成為一個熱門的研究課題。基于目前該領域的研究成果,比較知名的重復數據刪除技術應用有基于全文件檢測的Windows2000單實例存儲系SIS、基于定長分塊檢測的歸檔存儲系統Venti、基于文件內容(不定長分塊)檢測的低帶寬網絡系統LBFS等[2]。以上各應用采取的文件分塊算法存在不同程度的缺陷。為此,本文設計并實現一種面向容災備份存儲系統的更為有效的重復數據刪除方法——FWinnowing。
1 方法應用場景
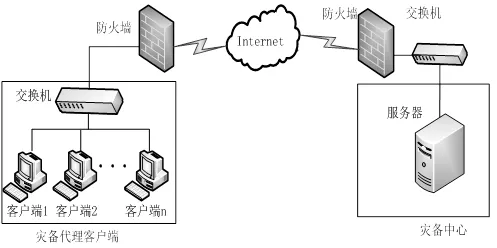
圖1 災備系統網絡拓撲圖
如圖1所示,該圖為災備系統網絡拓撲圖。當備份發起時,裝有災備代理的客戶端需要將不同時間點產生的備份文件進行分塊,并且計算各個分塊的MD5值作為各個分塊的指紋值,并將各個分塊指紋信息發送給服務器。服務器通過檢索指紋庫查找該指紋值是否存在。如果存在,表明該塊數據為重復數據,僅需要將該數據塊的索引記錄到文件的元數據信息中;如果不存在,則需要將該數據塊上傳至服務器,并更新文件的元數據信息和數據塊索引信息。當需要對文件進行恢復時,只需要找到文件的元信息,根據文件元信息并通過數據塊索引文件找到指定的數據塊進行文件重構即可恢復已經備份到服務器的文件。
2 方法采用的文件分塊算法
文件分塊算法按分塊粒度大小主要分為:定長分塊、可變長分塊和滑塊分塊。定長分塊算法對數據的插入和刪除非常敏感,不能解決比特偏移問題,冗余數據刪除率低;滑塊分塊算法會產生不定長的數據碎片[3]。因此,重復數據檢測和刪除技術通常采用可變長分塊算法,實際應用中主要有CDC(Content-Defined Chunking)和Winnowing兩種算法。
2.1CDC算法原理
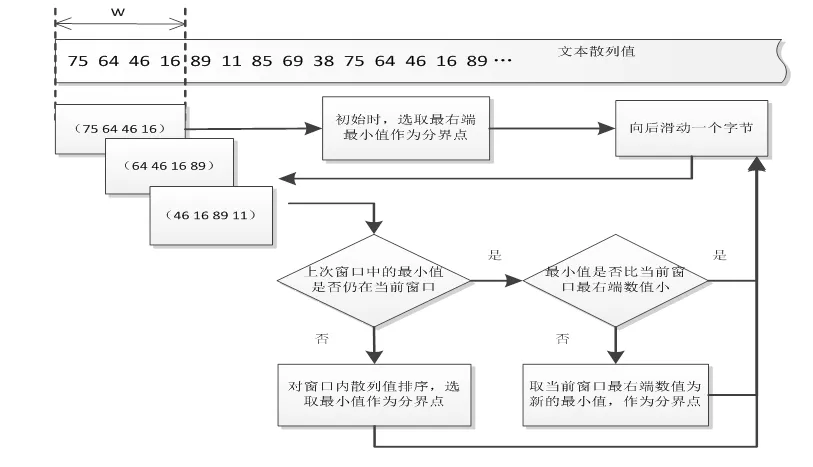
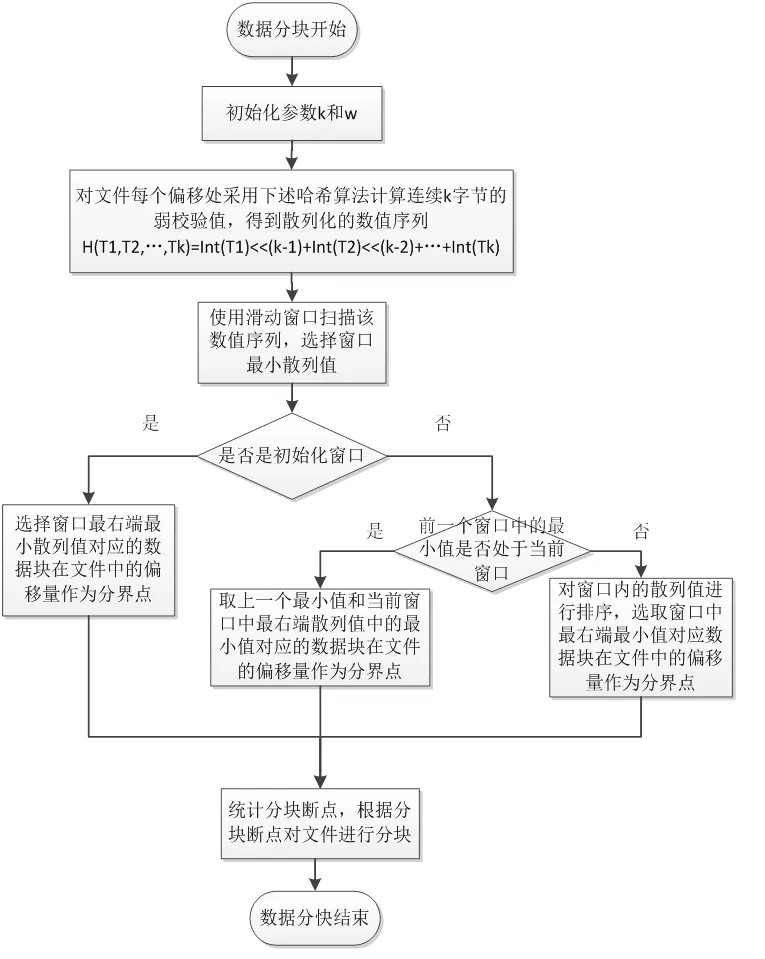
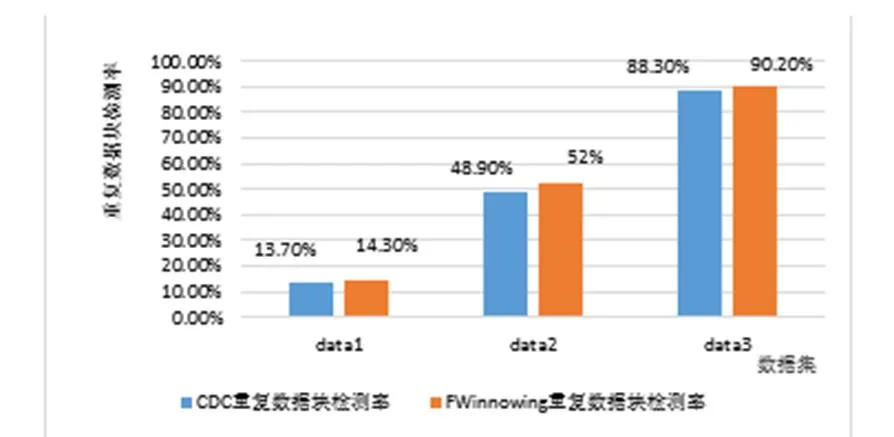
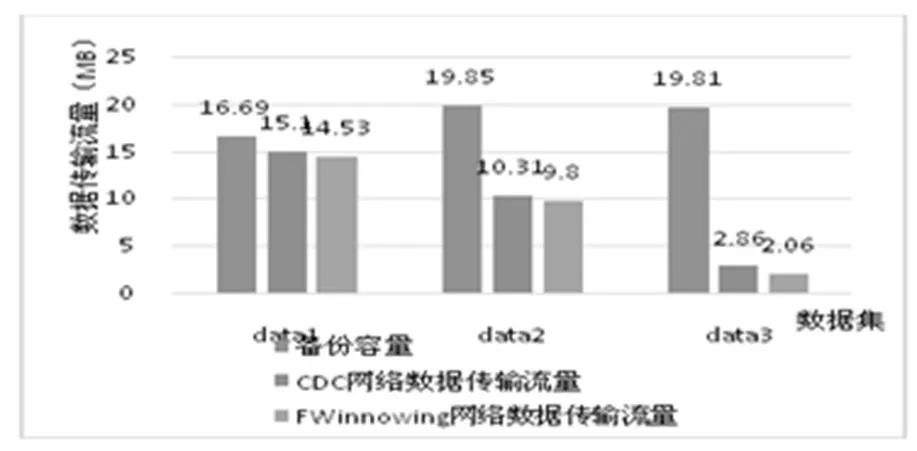
CDC是由麻省理工學院的BenjieChen等人發表的論文《A Low-Bandwidth Network File System》中提出,主要解決了固定長度分塊方法對插入位置敏感問題,并在重復數據刪除領域得到廣泛應用。CDC的定義:給定一個Rabin指紋算法f,選取滑動窗口長度為w,并選取兩個正整數d和r(d 圖2 CDC數據分塊示意圖 CDC可變分塊重復數據檢測技術已應用在P2P文件系統Pasta、Pastiche備份系統、Deep Store 歸檔存儲系統。但是,該算法存在一定的局限性:滑動窗口指紋值不符合條件時(f(w)mod d的值始終不等于r),會導致分塊過大,重復數據檢測率很低;d和r設置的太小,導致額外存儲分塊信息的開銷很大。 Winnowing算法在2003年由美國伊利諾斯大學的一位知名教授Saul Schleimer提出。該算法廣泛用于檢測兩個文件中是否有相同的內容和是否存在剽竊現象。Winnowing算法首先設定參數k和w(k指進行哈希的字節數,w指滑動窗口的大小)將文檔分成很多個長度為k的連續子串;其次,對文件每個子串通過公式(1)映射成一個整數,最終得到一個離散化的數值序列。 (b為基數,Tk表示滑動窗口中第k個字符,asc(Tk)表示該字符的ASCII值) 最后,使用滑動窗口掃描該數值序列,選取每個窗口內最小的哈希值,將其對應數據塊在文件中得偏移量作為文件的分割點。該算法的示例圖如圖3: 圖3 Winnowing算法示例圖 Winnowing有效地克服了對數據的插入敏感問題,并且相對于傳統的基于文件內容分塊算法具有較好的穩定性[3]。但是仍然存在一定的不足:當基數b取值偏大時,可能造成基本數據溢出,此時需要構建新的存儲結構,造成計算復雜度大降低計算性能;選取最小散列值時,如果選取策略不當可能會增加算法延時。 基于Winnowing算法的基礎上,本文對Winnowing算法所采用的哈希值計算和最小散列值選取策略兩方面加以改進,得到一種更加高效的FWinnowing算法,并應用于備份文件分塊中。具體改進如下: (1)哈希值計算方法的改進 首先對公式(1)加以改進,取基數b為2,并使用移位運算代替復雜乘法運算,提高算法運算效率,得到公式(2)如下: 根據哈希值計算規律發現,后一個子串哈希值計算可以在前一個哈希值的基礎上進行兩次移位運算和兩次加法計算得到,如公式(3)所示: 改進后的哈希值計算方法,在公式(1)的基礎上,大大降低了計算復雜度,節省了計算時間。 (2)最小散列值選取策略的改進 Winnowing算法中關于數據塊分界點的選取只是提到選取滑動窗口中最小值作為數據塊的分界點,但是對于每個滑動窗口中的數據都要經過整體排序找出最小值的話,這會增大時延,降低算法的執行效率。對此本文改進如下圖4所示: 圖4 FWinnowing最小散列值選取策略示例圖 經過對Winnowing算法在哈希值計算和散列值選取策略兩方面的改進后最終得到FWinnowing算法。FWinnowing的算法流程如圖5所示: 圖5 FWinnowing算法流程圖 本文實驗過程中,災備客戶端和災備服務端采用雙機直連的連接方式和100Mb/s網絡環境。實驗分別對多個相似數據集進行備份,通過統計不同重復數據刪除方法在數據分塊所消耗的時間以及數據傳送過程中所產生的流量大小來驗證方法的效能。實驗數據集采用不同版本的Tomcat源碼解壓后的文件集,并對該文件集進行處理(消除空白行、大量空格等),具體如表1所示: 表1 實驗數據集 本文對實驗數據集進行備份,通過統計將備份數據上傳至服務端所消耗的網絡流量來衡量各個方法的重復數據檢測和刪除的執行效率。 圖6是在設定備份文件分塊大小區間(介于128B和1024B之間)情況下,比較CDC方法和FWinowing方法的重復數據檢測率實驗對比數據數據,結果顯示FWinnow方法相比較CDC方法具有更好的重復數據檢測率。圖7是對備份數據經過CDC和FWinnowing兩種不同方法的重復數據檢測和刪除后上傳至災備中心產生的網絡流量對比數據。實驗結果顯示FWinnowing方法相對于CDC方法具有較低的網絡流量。 圖6 重復數據塊檢測率對比數據 圖7 數據傳輸網絡流量對比數據 本文從災備存儲系統對重復數據檢測的需求現狀出發,分析了現有的重復數據檢測方法存在的不足,將Winnowing算法改進后得到的FWinnowing算法并應用在文件分塊上,通過對比實驗驗證了FWinnowing方法相比較現有的方法擁有較低的網絡流量和較好的重復數據檢測率。因此,本文提出的重復數據刪除方法為后續該領域的研究提供了有益的探索和借鑒。 [1]敖莉, 舒繼武, 李明強.重復數據刪除技術[J].Journal of Software, 2010. [2]畢朝國, 徐小龍.一種云存儲系統中重復數據刪除機制[J].計算機應用研究, 2014. [3]許艷艷, 雷迎春, 龔奕利.基于可變長分塊的分布式文件設計與實現[J].體系結構與軟件技術, 2016. [4]馬曉旭.基于云存儲的災難備份與恢復技術研究[D].四川大學, 2012. [5]Bobbarjung DR, Jagannathan S, Dubnicki C. Improving duplicate elimination in storage systems. ACM Trans. on Storage, 2006.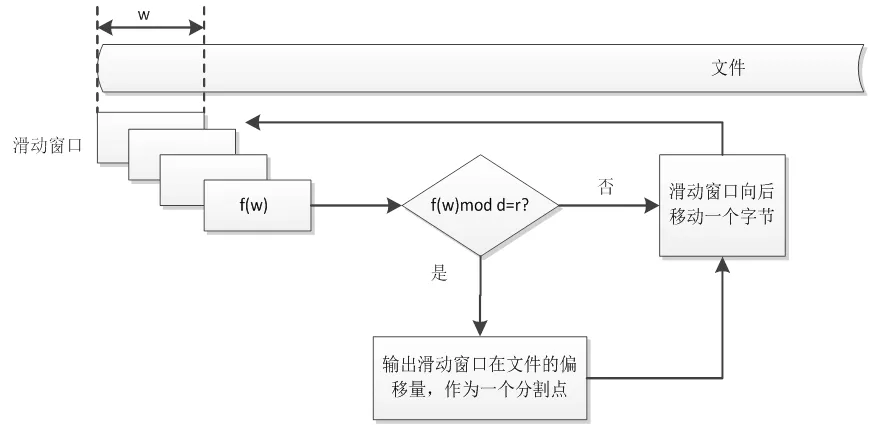
2.2 Winnowing算法原理
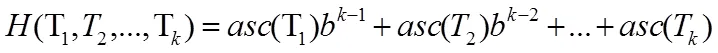

2.3FWinnowing算法原理
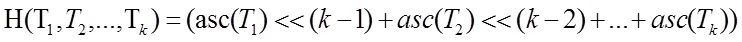
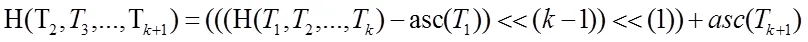
3 實驗分析
3.1實驗數據集

3.2實驗數據分析
4 結束語
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
