基于圖分析和支持向量機的企業網異常用戶檢測
2018-04-12 05:51:06郭淵博葉子維胡永進
計算機應用 2018年2期
徐 兵,郭淵博,葉子維,胡永進
(1.信息工程大學, 鄭州 450001; 2.數學工程與先進計算國家重點實驗室, 鄭州 450001)(*通信作者電子郵箱1214443035@qq.com)
0 引言
近年來,網絡安全威脅日益突出。如何保證網絡信息的安全是信息時代人們要共同面對的挑戰。在企業網絡中,用戶的身份認證是確認用戶身份的過程,用戶常常通過認證來得到對某種資源的訪問和使用權限,而用戶的身份認證安全正是眾多挑戰之一[1]。目前,身份認證可以有很多種不同的方式。傳統的身份認證方法基本可以分為以下三大類:基于用戶所知(what you know)、所有(what you are)、所是(what you are)。最簡單常用的用戶名和密碼的方式就是基于用戶所有的方式,還可以使用基于用戶所知的動態口令和基于用戶所是的生物特征的方式等[2]。基于生物特征的認證方式有不易丟失和被竊取的優點[3]。但專家指出,在可預見的未來,基于口令的認證方式仍無可替代,口令仍將是最主要的身份認證方式[4]。而這種方式的固有缺點是必須在服務端存儲這些敏感的驗證信息,而且這些信息容易被竊取[5]。在企業環境中,用戶通過網絡向很多計算機系統或應用發出認證[6],這種情況下,用戶的認證活動通常由一個統一的網絡身份認證機制所提供。這種機制就是集中式賬戶管理機制[7-8]。身份認證和集中式賬戶管理機制是現代信息技術管理的基石,在大量的系統中有著廣泛應用。然而用戶認證在方便的同時也存在著安全隱患。據賽迪網報道,某證券公司報案稱該公司發現多名客戶的股票賬戶被盜用,非法分子利用盜取的客戶密碼通過網上委托窗口賣出賬戶內股票后又全部買入某只股票,涉及資產上千萬。2016年8月,北京海淀公安分局海淀網安大隊收到百度網訊科技的報警。百度方面稱,該公司威脅情報部門監測到有大量百度賬號被成功登錄。同期百度用戶反饋后臺、郵件、官方微博、內網等各渠道陸續收到5 000名用戶反饋“賬號因被盜而封禁以及文件丟失”等,造成嚴重的個人利益的損失,也使得百度公司直接損失上千萬[9]。這些資源的未授權使用,個人或者組織的不正當活動,都可能使國家、社會以及各類主體的利益遭受嚴重損失。特別是攻擊者在取得合法的身份以及認證信息后,他的認證行為跟正常用戶就很難區分。著名的APT攻擊案例——Google極光攻擊正是利用這樣的機制,攻擊者盜用雇員的憑證成功滲透進入Google的郵件服務器,進而不斷地獲取特定Gmail賬戶的郵件內容信息[10]。傳統的檢測方法在這種情況下,基本喪失了檢測能力。如何在復雜的網絡環境中區分出這些被盜用或者濫用的賬戶,就顯得尤為緊迫。機器學習與數據挖掘技術的引入,使得這類檢測成為了可能。
本文在Kent等[11]用Logistic回歸研究用戶認證活動的基礎上作了改進,將圖分析和機器學習方法結合,同樣利用用戶的認證活動信息,建立正常用戶與異常用戶的分類模型,以此達到檢測異常的目的。將機器學習方法應用到用戶認證行為的異常檢測中,減少了人工參與,節約了人工成本。本文方法可以獨立應用在企業網絡中,用于異常用戶的識別與檢測;也可與傳統的安全防護方法結合,如加入到入侵檢測系統中,進一步提升入侵檢測系統的性能。本文使用了大型企業網絡的真實數據集來驗證文中所提出的檢測方法,分析了在用支持向量機(Support Vector Machine, SVM)模型進行檢測時各種懲罰參數和核函數的選擇對檢測結果的影響,最后用召回率、準確率、精確率、F1-score來評估實驗結果。結果顯示,當取得合適的參數之后,對異常用戶的檢測識別率能達到較高的水平,能構建較為高效的模型,也驗證了本文方法的可行性和有效性。
1 相關研究
集中式認證管理和控制是現代IT管理的基礎,也被應用在很多大型的IT企業網絡中。網絡身份認證是兩種典型的認證技術——Microsoft NTLM身份認證技術和MIT Kerberos身份認證技術的結合,這兩種認證方式也被廣泛地應用在桌面計算機和面向服務的操作系統中。這兩種認證方式都使用了證書緩存的方法,以方便證書的再次使用,因此也產生了很大的安全風險。當用戶的證書被惡意人員盜用時,他所發起的認證都將遵循身份認證技術的規則,沒有技術上的破綻。但惡意用戶的認證活動可能與正常用戶表現差異較大,如用戶短時間內發出大量的認證、向很少認證過的應用或系統發出認證等。Javed在文獻[12]中提出了檢測企業網異常認證被盜的系統。該文中針對暴力破解攻擊提出了一種利用自定義的方法標記信息源,當某些參數發生顯著變化時,則身份認證過程可能異常;還提出了一種基于特征工程的方法識別異常用戶,把正常用戶中很少發生的事件和異常用戶中大量發生的認證事件的特征提取出來進行建模,進而檢測異常認證行為。文獻[12]側重于攻擊前的檢測與防護,而本文側重于企業網絡中具有異常認證行為的用戶的檢測。針對證書被盜或被濫用的用戶,Kent等在文獻[6]首先提出了分析用戶認證行為的方法來檢測企業網絡中被盜的用戶。后來,Kent等在文獻[11]提出了利用“身份認證圖”的方法來識別企業網絡中的有特殊權限的管理員用戶和普通用戶,初步顯示了認證數據的價值。接著,Kent等[11]又在身份認證圖分類用戶類型的基礎上提出了基于Logistic回歸的異常用戶的檢測模型,但模型的召回率不高,只有28%,可以判定是模型本身的缺點所致,調節參數不能從根本上解決檢測效率低的問題。
基于機器學習的異常檢測通常應用在入侵檢測系統中,其中SVM作為一種非常活躍的機器學習方法經常用于正常與異常的分類。它是基于結構風險最小化(Structural Risk Minimization, SRM)原理,根據有限的樣本信息在模型的復雜性和和學習能力之間尋求最佳折中,以期獲得最好的泛化能力。早在2003年,饒鮮等[13]提出了SVM用于入侵檢測的模型,直到現在仍然是機器學習用于異常檢測的經典模型。2014年,Chitrakar等[14]提出一種用于增量SVM的候選支持向量方法,并實現算法CSV-ISVM,在實時網絡異常檢測中具有優勢。SVM以及SVM的改進方法獨立應用于異常檢測中已相當成熟,但將其與其他方法結合來進行檢測的案例不是很多。圖分析方法是一種新的檢測異常的思路,將圖分析與SVM結合能發揮兩種方法的優點,SVM難以在大規模樣本上實施的缺點也可以用圖分析中的信息轉化所彌補。從后文的實驗中可以看出,將兩種方法結合運用于異常的檢測取得了理想的檢測效果。
2 研究思路
圖論的研究已有一段歷史,發展到今天已經相當成熟[15]。用戶的認證活動顯示了計算機與計算機之間的相互關系,這種關系可以很自然地用圖的方式來表示。如圖1,一臺計算機可以用圖中的一個節點來表示,用戶之間的認證活動可以用節點之間的連線代替。圖1表示,在一段時間內,某用戶通過計算機C10分別向另外幾臺計算機發起過認證。表示在圖中就是節點C10向其他節點C20、C30、C40的有向連接。
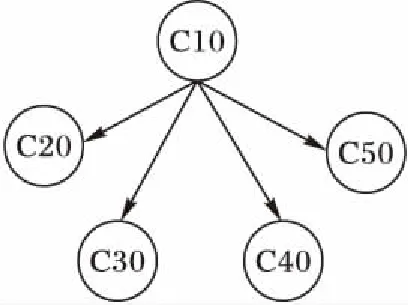
圖1 用戶身份認證圖Fig.1 User authentication graph
為了更具體地描述用戶認證圖,可以作如下約定:
用戶認證圖:Gu=(Vu,Eu),表示給定的一段時間內,用戶U的認證活動生成的有向圖。節點集Vu表示參與認證的計算機的結合,邊集Eu表示計算機之間的認證活動。
本文使用的數據集是洛斯阿拉莫國家實驗室(Los Alamos National Laboratory,LANL)所收集的兩個真實企業網絡安全數據集[16]。其中一個數據集收集了企業網絡中所有用戶58天的認證活動信息,稱為Authentication數據集;另一個數據集標注明確的紅隊事件,呈現明顯的惡意行為,稱為Red Team數據集。
Authentication數據集里有所有用戶58天內的認證活動。每一行代表一條認證記錄,包括認證時間、源認證用戶、目的認證用戶、源認證計算機、目的認證計算機、認證類型、登錄類型、認證方向、成功或失敗等九個方面的內容。原數據集中的兩條記錄示例如下:
91,U22@DOM1,U22@DOM1,C477,C2106,Kerberos,Network,LogOn,Success
91,U22@DOM1,U22@DOM1,C506,C457,Kerberos,Network,LogOn,Success
Red Team數據集中用戶的認證活動都是研究者特意制造并明確標注的異常,可以用作異常發現的對比,也可以用來與正常用戶認證活動一起構建分類模型。本文實驗中利用其中一部分數據作為訓練集,另一部分作為測試集來評估模型的性能。其中兩條原始數據記錄格式如下:
153792,U636@DOM1,C17693,C294
155219,U748@DOM1,C17693,C5693
Read Team數據集里每條記錄包含的信息比Authentication數據集里記錄的信息要少,但仍包含了必要的認證信息,如認證時間、源認證用戶、源認證主機和目的認證主機,而用戶認證圖的生成也正是利用這些信息。
這樣,為每一個用戶生成一個用戶認證圖,就可以利用用戶認證圖中的屬性來反映此用戶的某些性質。如用戶認證圖的稀疏與稠密可以用密度來度量,來反映此用戶與其他用戶的交互關系是簡單還是復雜。稀疏圖對應著簡單的交互關系,稠密的圖對應著復雜的交互關系。把用戶的認證活動以圖的方式表示,將用戶的認證性質濃縮到圖的屬性中,這樣就把對用戶含糊的性質分析,轉化為對圖的清晰的定量屬性分析,完成信息的轉換。識別和探索每個用戶的用戶認證圖的屬性能得出一些有用的結果。例如,大多數用戶所認證的計算機都是固定的,這樣反映了他們認證活動的固定。那些有特權的管理員用戶,有著比普通用戶更復雜的圖,也有著更復雜的屬性。如圖2是某兩個真實用戶的身份認證圖,可以看出真實的認證圖更復雜,也更能反映一些信息。之后可以根據所得用戶的間接信息作進一步的分析處理。
由前面認證數據的介紹可知,在企業網絡中經常有異常認證的情況,正是由于用戶的異常才導致異常認證的發生。所以,可以把對異常用戶的檢測轉化為區分正常用戶和異常用戶這樣一個二分類問題。由于SVM本身就是為二分類問題設計的,在二分類問題上有很好的分類效果,且具有較好的魯棒性,所以選擇SVM作為分類的模型。SVM的核心思想是把樣本映射到一個高維的特征空間,使其在高維的空間中達到線性可分,通過在高維空間里構造一個超平面來達到分類的目的[17]。但SVM所不足的是在大規模訓練樣本上難以實施,要借助二次規劃來求解支持向量。而圖分析方法恰好能克服SVM此方面的缺點,將大規模的用戶認證活動轉換為圖中的信息,數據規模將大大減小,訓練分類器時的計算開銷也大大減少。

圖2 某真實用戶的身份認證圖Fig. 2 A real user’s authentication graph
3 研究思路
本文的系統設計分為三個階段:數據準備、模型構建和結果檢驗。系統設計流程如圖3所示。

圖3 系統設計流程Fig. 3 System design flowchart
3.1 數據準備階段
數據準備階段由以下步驟來完成:數據預處理、信息提取和信息轉換。
3.1.1數據預處理
數據預處理的目的是把數據集預處理成只包含必要用戶認證活動信息的數據,以方便進行下一步的信息提取。此階段將Authentication數據集預處理成跟Red Team數據集相同的格式,刪除對本實驗無用的字段,完成數據的精簡。精簡后的數據只包含如下四個字段:認證時間、源認證用戶、源認證主機和目的認證主機。
3.1.2信息提取
當完成數據預處理后,兩個數據集的格式就變得相同。對兩個數據集分別進行如下的處理:提取數據集中的用戶,對每一個用戶提取其認證數據。
由于Authentication數據集中有全部用戶,包括正常和異常用戶,而Red Team數據集中只包含異常用戶,所以只需要提取Authentication數據集中的用戶即可,Red Team數據集中的用戶作為參考對比。提取完用戶后,再提取其所對應的認證記錄,生成用戶自己的用戶認證集。
3.1.3信息轉換
利用每一個用戶的認證集生成屬于此用戶的認證圖,將用戶認證數據集轉換為用戶認證圖,即完成了一次信息轉換。由用戶認證數據集生成認證圖的偽代碼如下:
For every user authentication dataset:
SAC=Source Authentication Computer
#SAC表示源認證計算機
DAC=Destination Authentication Computer
#DAC表示目的認證計算機
IF SAC!=DAC :
IF SAC is exist:
IF DAC is exist:
PASS
ELSE:
CREATE DAC
ADD Edge(SAC,DAC)
ELSE:
CREATE SAC
IF DAC is exist:
PASS
ELSE:
CREATE DAC
ADD Edge(SAC,DAC)
ELSE:
PASS
上述偽代碼表示:對于每一條認證,首先判斷源認證主機和目的認證主機是否相同,如果相同則屬于本地認證,再判斷源認證主機節點在圖中是否存在,若不存在,創建一個新節點;若存在,則跳過,不再重新創建。若源、目認證主機不同,再判斷源、目主機是否在圖中存在,不存在則先創建節點,再創建一條有向邊;若主機已在圖中存在,直接創建有向邊。
對于所有的用戶數據集重復以上操作,則可以得到轉換后的198個用戶認證圖,之后是對圖的分析與操作。從每個用戶圖提取出有效的認證屬性,生成用戶圖向量,就完成了又一次的信息轉換。由已定義過的圖Gu出發,再作以下定義:
在一段時間內,用戶U可能通過不止一臺計算機發起認證,定義VS為發起認證的源主機的集合,VD為認證的目的主機的結合,|VS|為用戶U的源認證主機數,|VD|為用戶U的目的認證主機數。
定義Cu為圖中連通組件,|Cu|為連通組件的個數。若用戶在給定的時間內,所有的認證活動由此一臺計算機發起,則圖中只有一個連通組件,也即是最大連通組件Cu_max。
Cu_max一般是用戶最常用的計算機以及最常認證的計算的結合。如圖2中所示某真實用戶的認證圖,中間一部分比較密集的連通圖就是最大連通組件。
Cu_min定義為最小連通組件,由于用戶認證圖是由用戶的認證生成的圖,所以最小連通組件至少有一個源認證主機和一個目的認證主機兩個節點,將其定義為孤立認證,|Cu_min|為獨立認證的數量。孤立認證表現在認證圖中是只有兩個節點的連通組件。如圖2中邊緣部分只有兩個節點的認證。表1列出本文用于分類的一些圖屬性。
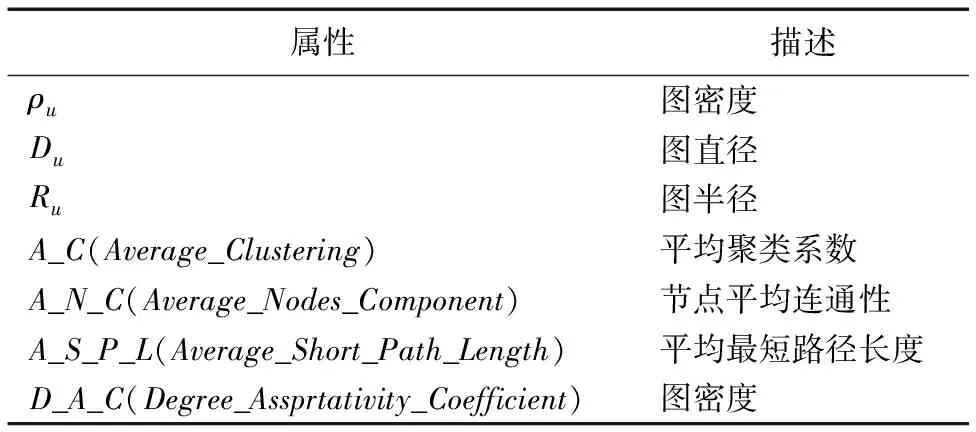
表1 屬性及描述Tab. 1 Attributes and description
對于每個用戶所生成的認證圖,都可以進行上述的信息轉換。轉換完畢后,將為每一用戶生成一個用戶認證圖向量。至此,第一階段完成。
3.2 模型構建
從原始的認證數據到用戶認證圖,再到用戶圖向量,經過這一系列的數據準備工作之后,便可以開始進行模型的構建。模型的構建過程即SVM決策函數求解的過程。把上階段準備好的用戶圖向量數據分為兩部分:一部分用于本階段模型的構建,另一部分用于下一階段模型的性能測試。模型構建過程如下:
1)將用于構建模型的測試集部分作為輸入樣本:T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,yi∈{+1,-1},i=1,2,…,N,每個xi表示一個用戶圖向量,yi為此用戶的標簽。
2)當樣本可分時,分類超平面的最優問題可表示為:
(1)
s. t.yi(w·xi+b)-1≥0,i=1,2,…,N
當樣本集線性不可分時,需引入非負松弛變量ξi(i=1,2,…,m),C為懲罰超參數,分類超平面的最優問題表示為:
(2)
s. t.yi(wTxi+b)≥1-ξi
由于此樣本集線性不可分,所以利用式(2)來求解最優超平面。
3)選擇合適的核函數K(x,xT)和懲罰參數C,構造并求解最優化問題:
(3)
(4)
5)最終求得決策函數:
(5)
經由上述一系列步驟訓練出檢測模型后,此模型便可以用于未知用戶類型的識別與檢測。
3.3 模型測試
此階段主要利用未知數據進行模型的性能測試,用準確率、召回率、精確率、F1-score幾個指標進行定量的評估。由于SVM模型中不同懲罰超參數參數C設置得不同,分類效果可能表現不同,核函數的選擇也對分類效果有一定的影響,所以,實驗環節主要調節這兩個參數以獲得更好的分類效果,構建出最優的模型。
4 實驗驗證與分析
為驗證本文方法的有效性,設計以下實驗。實驗所使用的數據集是LANL收集的β數據集的兩個子集——Authentication數據集和Red Team數據集。經過數據預處理后得到格式相同的數據集,數據集的相關信息統計如表2。

表2 實驗數據集的相關信息Tab.2 Information of the experimenatl dataset
如表2所示,Authentication數據集共提取12 418個用戶,Red Team數據集共提取98個用戶,其中Red Team中的98個用戶包含在Authentication數據集中的12 418個用戶之中。剔除這98個標注異常的用戶,剩下12 320個用戶即為正常用戶,所發出的認證也為正常認證。由于正負樣本不平衡,可以采取從大類樣本中隨機抽取與小類相同的樣本個數的方法進行不平衡數據的降采樣。本文隨機從12 320個用戶中提取100個用戶參與實驗。對這198個用戶分別提取屬于此用戶的所有認證記錄,這樣對于每一個用戶,都會生成一個屬于自己的認證數據集。對于處理后的數據經過第一次信息轉換之后可以得到198幅用戶認證圖,其中每一張認證圖隸屬于一個真實用戶。圖2和圖4分別是其中兩個真實用戶的認證圖:圖2的用戶認證圖稍微簡單,但已經到了人所不能分辨的地步,而圖4的辨識度則更差。

圖4 另一真實用戶認證圖Fig. 4 Another real user’s authentication graph
雖然人對用戶圖幾乎沒有辨識度,但可以將圖中的重要屬性提取出來以了解圖的性質。將198張圖進行第二次的信息轉化,得到198個圖向量。每個向量對應一張用戶認證圖,每張用戶認證圖對應一個用戶。其中10個用戶圖向量以及每個維度表示的含義如表3所示。
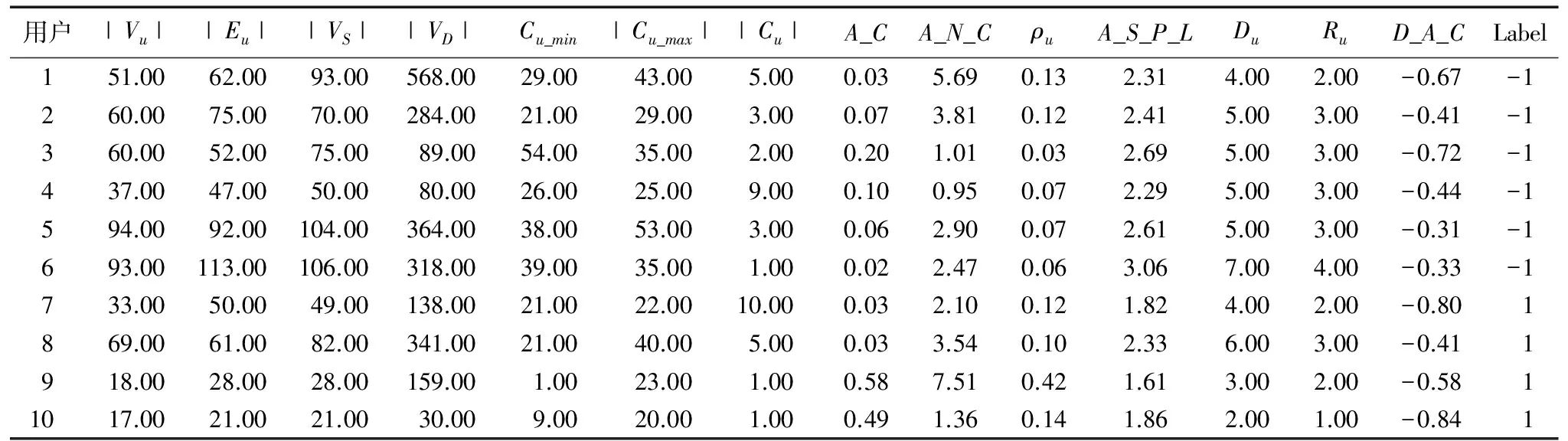
表3 10個用戶的用戶圖向量Tab. 3 User graph vector of ten users
將此階段得到的298個圖向量按比例隨機分成訓練集和測試集,用訓練集構建模型,用測試集來驗證模型的性能。
結果的評價指標要求其能充分反映出模型對問題的解決能力,好的評價指標有利于對模型進行優化。目前,常用的幾個評價指標有:準確率(Accuracy)、精確率(Precision)、召回率(Recall)、F1-Score。在正負樣本不平衡的情況下,準確率評價指標有很大的缺陷,所以需要其他幾項指標一同來進行衡量;F1-Score是精確率和召回率的調和均值,通常情況下,在精確率和召回率都很高的時候,F1-Score也會很高。
有了以上的評價指標,隨機按比例選取一部分正常和異常用戶的用戶圖向量作訓練集,剩下的作測試集,以此來檢驗SVM模型的分類效果,每組實驗做10次,取其平均值。固定懲罰參數和核函數為默認值,調節不同比例的測試集,實驗結果如表4所示。由表4可以看出:精確率和召回率互相影響;根據F1-score可以看出當測試集與訓練集分別取80%和20%時,模型能達到較好的分類結果,此時,F1-Score為0.74。
當固定訓練集與測試集的比例80%和20%、選擇默認核函數,調節不同的懲罰參數,實驗結果如表5所示。由表5可知,設置懲罰參數分別為0.001、0.1、1、10、100,當懲罰參數設置為1時,能取得較好的分類結果。
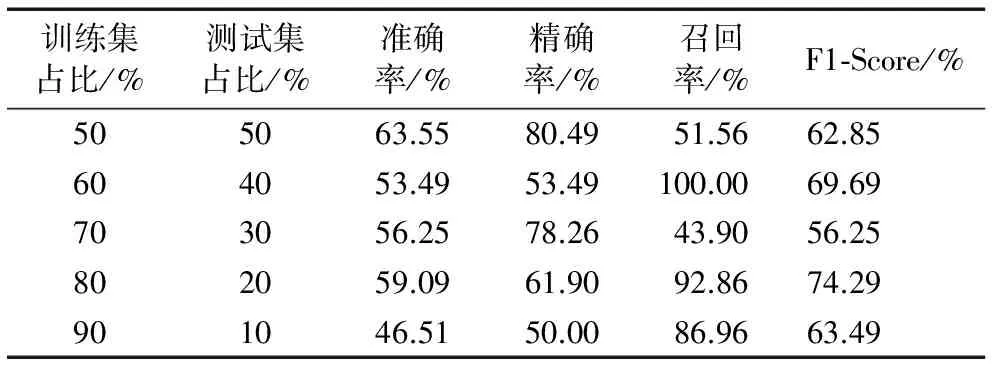
表4 不同比例的訓練集和測試集的實驗結果Tab. 4 Experimental results for different proportions of training sets and test sets
當固定訓練集測試集比例分別為80%和20%、取懲罰參數C=1,選取不同的核函數時,各種核函數對分類結果的影響如表6。由表6可以看出,線性核函數表現良好,徑向基核函數分類效果較差。所以,應選擇線性核函數作為SVM的核函數,這樣能達到最佳的分類效果。
綜上,本文提出的方法調節合適的訓練比例、選擇合適懲罰參數和最優的核函數之后,最終模型的精確率能達89.67%,召回率達到92.86%,兩者的加權調和F1-score也有0.89,都比文獻[11]中所提方法的28%的召回率高出兩倍之多。
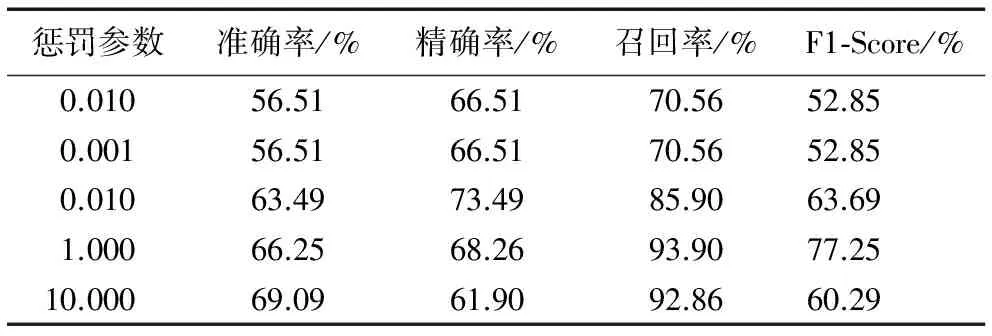
表5 選擇不同懲罰參數對實驗結果的影響Tab. 5 Experimental results of selecting different penalty parameters
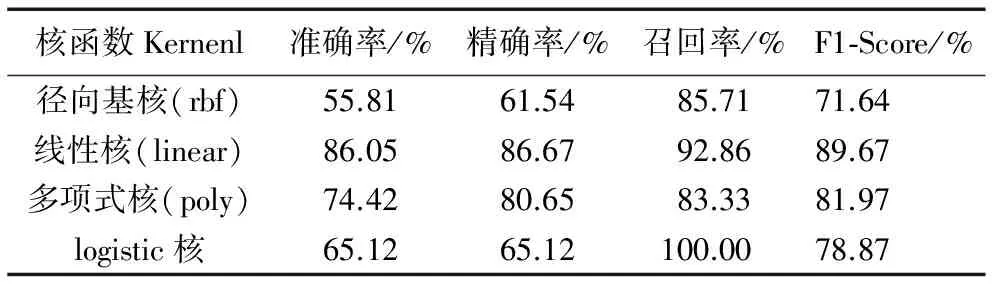
表6 選擇不同核函數的實驗結果Tab. 6 Experimental results of different kernel functions
5 結語
本文提出了在集中式認證系統和企業內部網絡中,通過分析用戶的認證行為來檢測、識別系統或網絡中的異常用戶的方法。通過將用戶的認證活動信息轉化為用戶認證圖,再提取圖中的屬性來得到更為濃縮的用戶認證圖向量,之后對用戶認證圖向量進行建模,間接地對網絡中的異常用戶進行檢測與識別。實驗結果表明,該模型能有效對企業網絡中正常與異常用戶進行分類,相比Kent等[11]所使用的Logistic模型28%的召回率,本文的檢測效果更好,模型更優。本文的不足之處是模型中所提取的特征雜亂,沒有對特征的重要性進行區分。下一步的工作計劃是進行特征的篩選,提取一些對于檢測異常更優質的特征,即用更少的特征獲得更優的效果;再結合β數據集中的其他幾個數據集,來進行進一步的研究。
參考文獻:
[1]JIANG P, WEN Q, LI W, et al. An anonymous and efficient remote biometrics user authentication scheme in a multi server environment [J]. Frontiers of Computer Science, 2015, 9(1): 142-156.
[2]王英,向碧群.基于用戶行為的入侵檢測系統[J].計算機工程,2008,34(9):167-169. (WANG Y, XIANG B Q. Intrusion detection system based on user behavior[J]. Computer Engineering, 2009, 34(9): 167-169.)
[3]王平,汪定,黃欣沂.口令安全研究進展[J].計算機研究與發展,2016,53(10):2173-2188. (WANG P, WANG D, HUANG X Y. Advances in password security [J]. Journal of Computer Research and Development, 2008, 34(9): 167-169.)
[4]HE D, WANG D. Robust biometric-based authentication scheme for multiserver environment [J]. IEEE Systems Journal, 2015, 9(3): 816-823.
[5]WANG D, WANG P. Two birds with one stone: two-factor authentication with security beyond conventional bound [J]. IEEE Transactions on Dependable and Secure Computing, 2016(99): 1-22.
[6]KENT A D, LIEBROCK L M. Differentiating user authentication graphs [C]// SPW ’13: Proceedings of the 2013 IEEE Security and Privacy Workshops. Washington, DC: IEEE Computer Society, 2013: 72-75.
[7]JOHNSON A, DEMPSEY K, ROSS R, et al. Guide for security configuration management of information systems [EB/OL]. [2017- 03- 06]. http://www.gocs.eu/pages/fachberichte/archiv/045-draft_sp800-128-ipd.pdf.
[8]AGARWAL N, SACHS E, KONG G, et al. Central account manager: US, US8789147 [P]. 2014- 07- 22.
[9]賽迪網.2016網絡安全大事件[R/OL]. [2018- 08- 01]. http://www.ccidnet.com/2016/0801/10162993.shtml. (CCIDNET. Network security big event of 2016. [R/OL]. [2016- 08- 01]. http://www.ccidnet.com/2016/0801/10162993.shtml.)
[10]啟明星辰 yepeng.八大典型APT攻擊過程詳解[R/OL]. (2013- 08- 27) [2017- 01- 15]. http://netsecurity.51cto.com/art/201308/408470.htm. (YE P. 8 typical APT attack process analysis in detail [R/OL]. (2013- 08- 27) [2017- 01- 15]. http://netsecurity.51cto.com/art/201308/408470.htm.)
[11]KENT A D, LIEBROCK L M, NEIL J C. Authentication graphs: analyzing user behavior within an enterprise network [J]. Computers & Security, 2015, 48: 150-166.
[12]JAVED M. Detecting credential compromise in enterprise networks [D]. Berkeley: University of California, Electrical Engineering and Computer Sciences, 2016.
[13]饒鮮,董春曦,楊紹全.基于支持向量機的入侵檢測系統[J].軟件學報,2003,14(4):798-803. (RAO X, DONG C X, YANG S Q. An intrusion detection system based on support vector machine [J]. Journal of Software, 2003, 14(4): 798-803.)
[14]CHITRAKAR R, HUANG C. Selection of candidate support vectors in incremental SVM for network intrusion detection [J]. Computers & Security, 2014, 45: 231-241.
[15]何大韌,劉宗華,汪秉宏,等.復雜網絡與系統[M].北京:高等教育出版社,2009:148. (HE D R, LIU Z H, WANG B H, et al. Complex Networks and Systems [M].Beijing: Higher Education Press, 2009: 148.)
[16]KENT A D. Cyber security data sources for dynamic network research [M]// Networks and Cyber-Security. River Edge, NJ: World Scientific Publishing Company, 2016: 37-65.
[17]周志華,楊強.機器學習及其應用[M].北京:清華大學出版社,2011:95. (ZHOU Z H, YANG Q. Statistical Learning Method [M]. Beijing: Tsinghua University Press, 2011: 95.)
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
