基于塊稀疏表示的行人重識別方法
2018-04-12 07:15:41孫金玉王洪元張文文
計算機應用 2018年2期
孫金玉,王洪元,張 繼,張文文
(常州大學 信息科學與工程學院,江蘇 常州 213164)(*通信作者電子郵箱hywang@cczu.edu.cn)
0 引言
行人重識別是計算機視覺領域的重要問題之一,其中行人重識別的任務是在非重疊攝像機拓撲結構下對同一行人的所有圖像實現匹配,從而實現行人的持續跟蹤。由于其在智能監控、多目標跟蹤等領域具有重要的意義,近年來引起了國內外研究者的廣泛關注。
行人重識別領域主要的問題在于同一個行人通常在不同時間被相互之間非重疊的攝像機所拍攝,導致拍攝到的圖像會因為不同的光照條件、不同的相機視角、不同的行人姿態甚至不同的行人衣著或外觀等原因,產生很大的變化。因此,行人重識別問題通常具有以下幾個特點:1)在實際的監控環境中,不能有效地利用臉部的有效信息,只能利用行人的外貌特征進行識別;2)在不同的攝像頭下,因尺度、光照和拍攝角度的變化,同一個行人的不同圖片中,外觀特征也會有一定程度的變化;3)行人姿態和攝像頭角度的改變,在不同攝像頭中,不同行人的外貌特征可能比同一個行人的外貌特征更相似。
基于以上問題,當前的行人重識別研究工作可以大致分為基于外貌的特征表示方法和基于距離度量學習方法兩類。首先,前者利用紋理和顏色直方圖等特征描述行人外貌。Gheissari等[1]提取行人外貌特征中不變的區域,在每個穩定不變的區域上提取多種顏色特征,采用三角形模型表示行人身體結構,通過模型匹配計算兩個行人圖像的距離;Farenzena等[2]提出基于對稱驅動的累積局部特征(Symmetry-Driven Accumulation of Local Feature,SDALF)的行人重識別方法,該方法將人體按照結構劃分成不同區域,分別提取加權HSV(Hue, Saturation, Value)直方圖和紋理特征,再分別對不同的特征采用不同的距離函數計算相似度,最終相似度按照不同的權重將不同特征的距離加權求和得到;Cai等[3]將位置信息融入到HSV顏色直方圖中,提出全局顏色背景(Global Color Context, GCC)方法。其次,基于距離度量學習的行人重識別方法則是通過對目標函數的訓練,找出有最大區分度的特征分量,再進行建模實現目標重識別。Weinberger等[4]提出大間隔最近鄰分類(Large Margin Nearest Neighbor, LMNN)距離測度學習算法;Zheng等[5]首次引入尺度學習算法的思想,僅采用LMNN中三元組形式的樣本對,提出基于概率相對距離比較(Probabilistic Relative Distance Comparison, PRDC)的距離測度學習算法;Zheng等[6]還提出將行人重識別視作一個相對距離比較(Relative Distance Comparison, RDC)的學習問題,在該方法中,各類特征并非一視同仁對待,目的也是正樣本的距離最小化及負樣本的距離最大化,該方法表現出對于外觀變化更大的寬容性;Zhao等[7]利用非監督學習方式來尋找目標的突出特征進行匹配;許允喜等[8]采用視覺單詞樹直方圖和全局顏色直方圖構建所跟蹤目標的人體外觀模型,并使用支持向量機(Support Vector Machine, SVM)增量學習進行在線訓練;Xiong等[9]提出了一種新的基于內核的距離學習方法,將歸一化成對約束成分分析(regularized Pairwise Constrained Component Analysis, rPCCA)方法用于行人重識別問題;Chen等[10]提出了一種相似性學習(Similarity Learning)算法,實質是基于顯示內核特征圖(Explicit Kernel Feature Map)計算特征相似性距離,提高算法魯棒性;You等[11]提出top-push距離學習(Top-push Distance Learning, TDL)方法,該方法基于視頻上的研究,主要思路即進一步增大行人圖像的類間差異、縮小類內差異。雖然這些行人重識別方法都能取得很好的效果,但都是基于全局行人特征基礎上的研究,加之行人重識別一直以來受遮擋、姿態變化、光照、視角等因素的影響,研究效果并不顯著,進一步提升仍然困難重重。
近年來,稀疏表示理論在計算機視覺領域發揮了重要作用,如目標跟蹤[13]以及圖像復原[14]等問題。特別是人臉識別問題中,稀疏表示理論得到了廣泛應用[12]。其中,稀疏表示分類(Sparse Representation-based Classifier, SRC)算法是一個比較有效的人臉識別算法[12]。基于SRC算法的主旨思想,本文假設任一張行人圖像都可以用同一行人訓練樣本的線性組合來表示,通過尋找測試樣本相對于整個訓練集的稀疏表示系數來發現測試圖像所屬的用戶身份[12]。借助于先進的高維凸優化技術(如1范數最小化[15]),稀疏表示系數可以被精確穩定地恢復出來,解的精度和魯棒性都有理論上的保證。與現有多數方法相比,SRC方法直接利用了高維數據分布的基本特性(即“稀疏性”)進行統計推斷,可以有效地應對維數災難問題。Yang等[16]在2011年的ICCV(International Conference on Computer Vision)上提出了Fisher Discriminative Dictionary Learning(FDDL)算法來學習一個結構化字典,因此可以采用基于重構的方法來對測試樣本進行分類。該算法不僅增加了字典的判別性,而且還考慮到了稀疏編碼的判別性。Fisher判別準則被應用到了稀疏編碼上,使得訓練樣本的稀疏編碼具有小的類內散度和大的類間散度,這可以進一步提高學習到的字典的判別性。
然而基于稀疏表示的分類方法并沒有考慮到字典的結構化。因此,Elhamifar等[17]使用稀疏表示技巧在多個子空間環境下進行分類任務。直觀上來說,所有訓練樣本組成的字典應該具有塊結構,并且來自同一個類別的訓練樣本組成了字典的某些塊。可以將分類歸結為結構化稀疏復原問題,目的是從字典中找到最少數量的字典塊來表示一個測試樣例。傳統的基于稀疏表示分類方法旨在找到一個測試樣本最稀疏的表示,但是這可能并不是最好的分類規則。
基于稀疏表示的分類方法在行人重識別問題上未曾受到廣泛關注,雖然有些方法采取稀疏表示[18-19],但并未利用到行人特征字典固有的塊結構[17]。
針對上述問題,本文提出一種新的方法用于行人重識別問題。將分類歸結為塊結構化稀疏復原問題,與傳統的基于稀疏表示的分類方法旨在找到一個測試樣本最稀疏的表示不同的是,本文方法目的是從字典中找到最少數量的字典塊來表示一個測試樣例。之后利用交替方向框架求解相關塊稀疏極小化問題,并且在公開的數據集PRID 2011[21]、iLIDS-VID[22]和VIPeR[23]上進行實驗,證實了該方法與同類方法比較時(特別是那些涉及復雜背景以及有遮擋的場景)的優越性與魯棒性。
1 塊稀疏模型構建
1.1 特征提取
在行人圖像特征描述中,顏色特征是最基本、最重要的圖像特征,而紋理特征描述圖像的結構特性,因此可以利用紋理特征對顏色特征進行補充。本文采用顏色特征與紋理特征結合的特征表示方法。首先將圖像歸一化為128像素×48像素大小,并且分塊為32像素×48像素大小,且每一小塊在水平和豎直方向上均有50%的重疊部分,因此就有7個分塊用于提取HS(Hue, Saturation)顏色直方圖、Lab特征和Gabor特征。其中HSV特征只提取色調(即H分量)、飽和度(即S分量)特征是因為在行人重識別研究中通常需要排除光照帶來的影響。Lab特征為顏色空間特征,提取的是直方圖特征,該特征是一種統計特征。在Lab顏色空間中,一種顏色由L(亮度)、a顏色、b顏色三種參數表征。由于行人重識別受亮度影響比較大,因此該特征僅提取a通道和b通道的顏色特征,并將這些待提取的特征全部分為16維直方圖統計特征。而Gabor特征是一種紋理特征,根據不同波長、方向、空間縱橫比、帶寬等分別取16組不同的Gabor濾波器。由圖像劃分方法可知,對于每一張行人圖像,其在水平方向有7個分塊,由上面特征提取的內容可知,每個塊中通道包括16個Gabor、2個HS和2個Lab,即有20(16+2+2=20)個特征通道,每個通道又被表示為16維直方圖向量。所以每幅圖像在特征空間中被表示為2 240維度的全局圖像特征向量。
針對行人的高維特征在識別過程中易造成維數災難問題,可以采用典型相關分析(Canonical Correlation Analysis, CCA)[20]對行人的高維特征進行轉換。它能對給定的兩組變量尋找一組線性映射,將多維數據投影到一個子空間中,使投影后的兩組數據間的相關性達到最大,能在一定程度上有效避免原本高維特征在運算中所引起的維數災難。CCA是一種簡單的用于求投影矩陣的方法,同時也是一種統計兩組隨機變量之間關系的數學方法,目前,CCA已被廣泛應用于行人重識別領域。因此采用CCA[20]對特征進行投影,使經過投影空間后的行人特征更具有匹配重識別的能力,能大幅提高重識別率。
1.2 基于塊稀疏表示的行人重識別
1.2.1問題描述
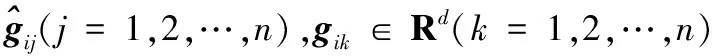
設帶有標記i行人的n幅圖像提取的特征數據形成字典Gi=[gi1gi2…gin]∈Rd×n。現給定一張待識別行人圖像p,假設其屬于第i個行人,則理論上只需用第i個行人的數據集圖像特征向量就能線性表示p[12],即:
p≈xi1gi1+xi2gi2+…+xingin
(1)
其中xij∈R(j=1,2,…,n)表示帶有標記i的第j個樣本的權重系數。該等式可以簡潔地記為:
p≈Gixi
(2)
然后構建所有數據集特征字典D∈Rd×N為:
D=[G1G2…GZ]
(3)
其中N=Z×n為所有在數據集中出現的圖像總數。顯然,該數據字典是由Z個獨立塊向量串聯而成,因此它具有塊結構[17]。這是多目標配準行人重識別問題的一大特點,本文就是利用該特點設計一個基于塊稀疏的行人重識別方法。
令x=[x1Tx2T…xZT]T因此,可以建立模型:
pij≈G1x1+G2x2+…+GKxZ
(4)
其中xi=[xi1xi2…xin]T∈Rn表示與帶有標記i的行人相對應的系數塊。由于p與行人i的字典Gi近似呈線性關系,且注意到向量塊xi要比向量塊xz(z=1,2,…,Z,z≠i)對最優解向量x的貢獻大,也就是模型的系數向量主要由系數塊xi所決定。
同時模型為:
p≈Dx
(5)
其中x∈RN是稀疏的。也就是當數據集字典D中的行人數量較多時,x中只會有少量的非零項,大部分的系數為0。本文所要尋找的即非零項集中在特定行人特征字典塊上的解向量,因此采用稀疏的目的就是求解稀疏系數矩陣X。
如文獻[12]中所述,本文所提的問題如下述L1/L2優化問題:
(6)
s.t.p=Dx
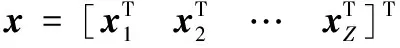
1.2.2遮擋造成數據損壞
從監控攝像機捕獲的行人圖像通常被其他人或者物體遮擋,所提取的行人特征數據因此被損壞,例如圖1所示的樣例圖像。由于行人遮擋、相機分辨率低等問題,會極大降低行人重識別的精度,并且該情況下的行人圖像處理會產生較大誤差,因此需要對遮擋物進行誤差建模處理,平衡由此產生的誤差。與其他相關多目行人重識別技術不同的是,本文的制定方法明確地建模遮擋物,即引入一個誤差項e∈Rd到式(5)里,則線性近似模型為:
p=Dx+e
(7)

圖1 在iLIDS-VID數據集里被遮擋的行人Fig. 1 Occluded people in iLIDS-VID dataset
式(7)的最小化問題可以表述如下:
(8)
s.t.p=Dx+e
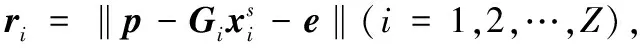
1.2.3使用交替方向的塊稀疏恢復
給定數據p和D,使用交替方向框架來計算式(7)的解。首先,引入松弛變量s∈RN,式(8)的問題可重新建模為:
(9)
s.t.s=x
p=Dx+e
現引入Lagrange乘數α∈RN,β∈Rd將式(9)的約束最小化問題轉換為下述無約束的最小化問題:
(η1/2)‖s-x‖2+(η2/2)‖Dx+e-p‖2
(10)
在損失函數中增加兩個二次懲罰項(η1/2)‖s-x‖2和(η2/2)‖Dx+e-p‖2來最小化目標。觀察到最小化該損失函數涉及到三個變量s,x和e,因此本文采用交替方向迭代框架,最小化單變量損失函數,即每次迭代僅與一個變量相關,其他兩個變量保持固定。
首先,固定s和e并最小化變量為x的損失函數:
(η1/2)‖s-x‖2+(η2/2)‖Dx+e-p‖2
(11)
該x的子問題是一個簡單的二次優化目標問題,其閉合解為:
x*=(η1I+η2DTD)-1(η2DT(p-e)+η1s+βTD-α)
(12)
其次,固定s和x,并最小化變量為e的損失函數:
(13)
x*是上述x子問題的最優解。同樣e的子問題也有一個閉式解,即:
e*=shrink(β/η2-Dx*-p,1/η2)
(14)
shrink(t,α)=sgn(t)?max{|t|-α,0},其中?表示矩陣之間的點乘。
最后,通過固定x和e并最小化變量為s的損失函數,得到:
(15)
該s子問題也有一個閉式解,并且該解對每個分塊的系數i=1,2,…,Z是由塊收縮[13]運算得到:
(16)
最后,更新拉格朗日乘數為:
α=α-η1(s*-x*)
(17)
β=β-η2(Dx*+e*-p)
(18)
對于以上變量s、e和x的具體求解,則通過初始化變量s=0,e=0,α=0,β=0進行迭代,實現如算法1所示。
1.2.4重識別

算法1迭代稀疏重識別算法。
Input:p∈Rd,D∈Rd×N;
Output: index of the correct peoplec。
Initialize:s=0,e=0,α=0,β=0,t←1,2,…。
1)
whileet<10-3do
2)
computextusing equation (12)
3)
computeetusing equation (14)
4)
computestusing equation (16)
5)
updateα,βusing equation (17), (18)
6)
end while
7)
xs=xt;es=et;
8)
computestusing equation (16)
9)
letR=0
10)
forj=1:n
11)
computepin equation (9) withxs,es
12)
compute residuals vector
13)
14)
R=R+rj
15)
end for
16)
c=index of the minimum value inR
2 實驗和結果分析
實驗在公開數據集PRID 2011[21]iLIDS-VID[22]和VIPeR[23]上進行,驗證了所提方法在多目標配準行人重識別下的效果。
iLIDS-VID:此數據集是從機場到達大廳的兩個非重疊相機視角中提取圖像創建而成。其隨機為300個行人采樣了600個視頻,每個行人均有來自于兩個攝像機視角的一組視頻。 每個視頻有23~192幀,平均73幀。在此數據集中所有圖像大小為128×64,圖像特點是受到極度光照、視角的變化、遮擋和雜亂的背景影響較嚴重。
PRID 2011:此數據集是由兩個相鄰攝像機捕獲室外場景所創建,主要涉及到視角、遮擋以及背景變化。其中攝像頭A有385個行人,攝像頭B有749個行人,其中有200個行人同時在攝像頭A和攝像頭B中;所有圖像大小歸一化為128×48大小。本文主要選擇200個同時在兩個攝像頭下出現的行人圖像作實驗。
VIPeR:此數據集是由在校園環境中錄制的視頻制作而成。其圖像包括兩個攝像頭下的632個行人的1 264張圖像,且全部歸一化為128×48大小。每個攝像頭下的每個行人有且僅有一張圖像;不同攝像頭下的同一行人的圖像受視角和光照影響,使得外貌存在明顯差異,其中視角不同是造成外貌差異的主要原因。
2.1 實驗過程
對每個數據集進行以下操作:1)隨機選擇行人圖像將之劃分為大小相等的訓練集和測試集。由于本文所選擇的數據集中每個行人有多張圖像,所以每一個行人在數據集視角和查詢集視角下都隨機選擇各5張圖像提取行人特征。2)將訓練集用于學習投影矩陣并將測試集行人特征投影到該投影空間。3)同一個相機視角下(camA)所有行人圖像特征形成數據集字典D,而另一相機視角下(camB)的行人圖像則作為查詢集。4)對查詢集里的每個行人圖像一一計算其與數據集里每張圖像的殘差,按照殘差大小對數據集進行排序,并記錄正確的目標所在的位置。為了得到穩定可靠的實驗結果并減少隨機因素所帶來的不可控影響,對上述過程重復10次,取其平均值作為最終結果。
本文關于行人重識別性能的評估主要采用累積匹配特征(Cumulative Matching Characteristic, CMC)曲線作為指標。CMC曲線在行人重識別算法的性能評測上應用廣泛[4,6-7,11], 曲線上的數值反映出在前i個搜索中匹配到正確目標的概率。Ranki表示第i個Rank值。
2.2 實驗結果分析
將本文方法與近年提出的幾種方法進行比較,包括LMNN[4]、RDC[6]、TDL[11]和SDALF[2]。首先,評估數據集上的CMC曲線如圖2所示。從圖2可以看到,本文方法的Rank1性能在三個數據集上分別達到40.4%、38.11%和23.68%;Rank5上的性能分別達到64.63%、60.13%和51.5%;Rank10的性能達到75.34%、70.31%和65.32%;Rank20的性能達到了84.08%,79.73%和77%,均處于領先水平。與其他同類方法相比,在數據集PRID 2011、iLIDS-VID和VIPeR上,本文方法在Rank1、5、10和20排名上得到了較好的性能。其中在Rank1性能上,本文方法匹配率遠大于LMNN算法;總體性能均優于經典的基于特征表示與度量學習的對比算法。
本文對行人特征的提取主要是針對多種特征進行融合以及對圖像進行分塊處理,因此提取不同種類的特征對實驗結果的影響較為顯著。實驗中所有對比方法均使用相同的、由本文方法所提取的特征,這些特征與各方法原文獻中是不同的,同樣具有說服力。如圖3所示,在PRID 2011數據集上,提取Lab、HS、Gabor特征以及對行人分塊后的效果要明顯好于其他幾種特征提取方式;同樣,在數據集iLIDS-VID和VIPeR上,本文所用的特征提取方式效果也明顯優于其他特征提取方式。
本文對行人特征進行轉換時主要是進行空間投影,因此對所提方法在投影空間與基礎空間的比較必不可少。此時在兩個空間中,對行人特征的提取均需保持一致,唯一不同之處在于特征投影空間是否轉換。如圖4所示,應用本文方法的投影空間,在PRID 2011、iLIDS-VID和VIPeR數據集上,Rank1的性能比基礎空間分別提升了24.74個百分點、21.97個百分點和10.23個百分點。從圖中也注意到當所提方法應用在投影空間與應用在基礎特征空間中相比時,在各等級排名中,投影空間中的結果始終比基礎空間的好。該實驗也驗證了本文提出的關于在投影空間里制定一個線性近似模型而不是基礎特征空間的原假設。
針對本文式(8)的模型,誤差項e主要用于避免數據損壞或者應對行人受遮擋問題,更好地建模遮擋物。如果不引入誤差項,則同樣條件下的行人重識別效果會受很大影響。表1為引入誤差項e與未引入誤差項e的效果比較,說明對遮擋物建模可以更好地對行人進行匹配。
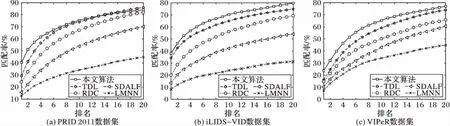
圖2 不同方法的CMC曲線Fig. 2 CMC curves for different methods
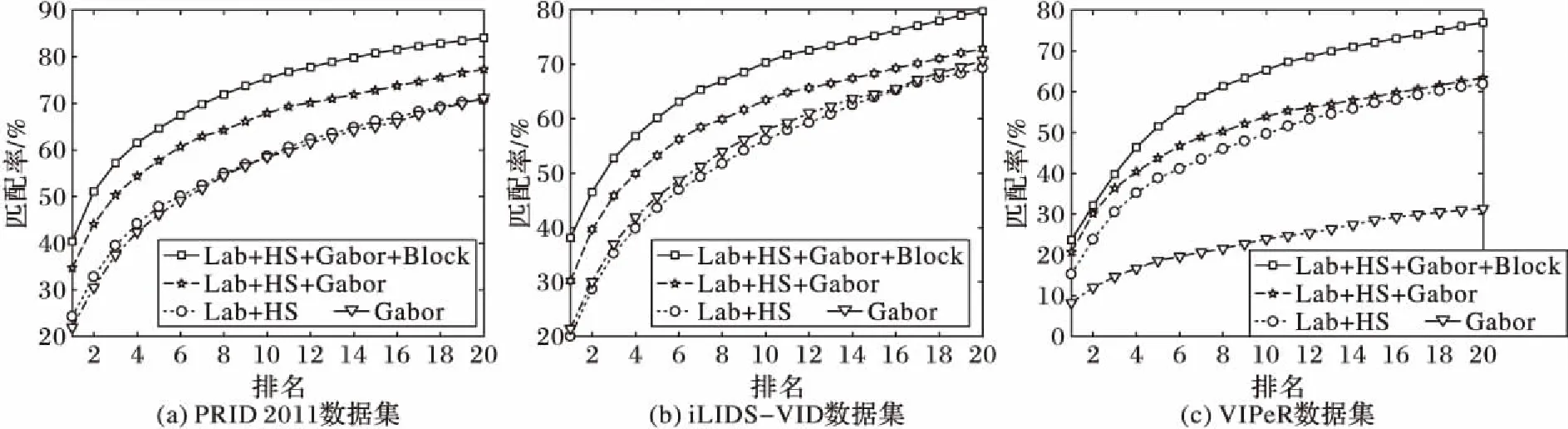
圖3 不同種類特征對行人重識別結果影響Fig. 3 Impact on different kinds of features on re-identification
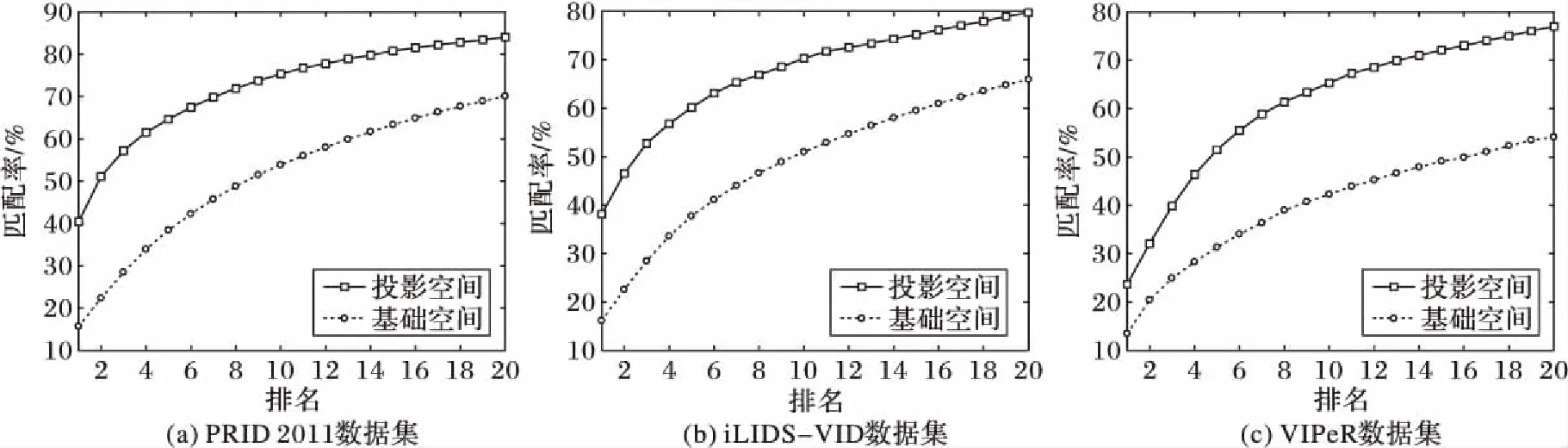
圖4 投影空間與基礎空間比較Fig. 4 Comparison of projected space and original space
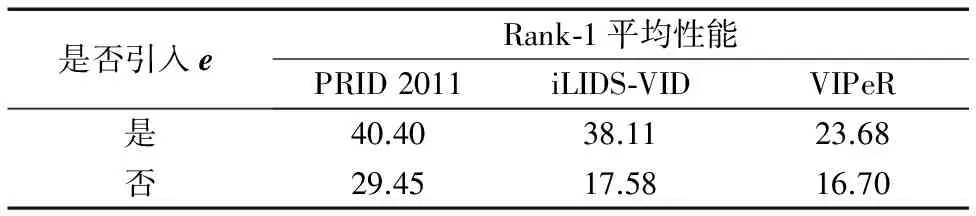
表1 誤差項e的引入對Rank-1平均性能的影響 %Tab. 1 Impact of the error term e on average Rank-1 performance %
3 結語
本文主要提出一種行人重識別的方法:首先利用CCA方法對高維的行人特征進行轉換,有效緩解高維特征運算帶來的維數災難問題;接著將查詢集圖像的特征向量投影到學習到的投影空間,使投影后查詢集行人特征向量與相應的數據集特征向量近似呈一個線性關系;最后構建一個關于數據集特征向量的字典D,將重識別作為一個塊的稀疏極小化問題并利用其內在結構,采用交替方向框架求解該極小化問題。對于行人身份判別問題,采用殘差項進行處理,最終的殘差項中最小值所對應的指標將作為重識別行人的識別標記。最后在公開的標準行人數據集PRID 2011、iLIDS-VID和VIPeR上評估所提方法,驗證了本文方法的優越性。但本文方法仍具有一定的局限性,正如在2.2節圖2(a)所示,由于TDL將行人重識別問題看作度量學習問題來解決,結合top-push約束模型,在匹配精度上更精準,導致本文方法在Rank-10之后的排名與TDL方法相仿,但這并不影響本文方法的整體性能。接下來的研究將與監督學習相結合,盡可能利用已知標簽信息的行人特征,提高行人重識別的匹配精度,為進一步研究提供了提升空間以達到更好的突破。
參考文獻:
[1]GHEISSARI N, SEBASETIAN T B, HARTLEY R. Person reidentification using spatiotemporal appearance [C]// CVPR ’06: Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2006, 2: 1528-1535.
[2]FARENZENA M, BAZZANI L, PERINA A. Person re-identification by symmetry-driven accumulation of local features [C]// CVPR ’10: Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 2360-2367.
[4]WEINBERGER K Q, SAUL L K. Distance metric learning for large margin nearest neighbor classification [J]. The Journal of Machine Learning Research, 2006, 10: 207-244.
[5]ZHENG W-S, GONG S, XIANG T. Person re-identification by probabilistic relative distance comparison [C]// CVPR ’11: Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 649-656.
[6]ZHENG W-S, GONG S, XIANG T. Re-identification by relative distance comparison [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(3): 653-668.
[7]ZHAO R, OUYANG W, WANG X. Unsupervised salience learning for person re-identification [C]// CVPR ’13: Proceedings of the 2013 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 3586-3593.
[8]許允喜,蔣云良,陳方.基于支持向量機增量學習和LBPoost的人體目標再識別算法[J].光子學報,2011,40(5):758-763. (XU Y X, JIANG Y L, CHEN F. Person re-identification algorithm based on support vector machine incremental learning and linear programming boosting [J]. Acta Photonica Sinica, 2011, 40(5): 758-763.)
[9]XIONG F, GOU M, CAMPS O, et al. Person re-identification using kernel-based metric learning methods [C]// ECCV 2014: Proceedings of the 2014 European Conference on Computer Vision, LNCS 8695. Cham: Springer, 2014: 1-16.
[10]CHEN D, YUAN Z, HUA G, et al. Similarity learning on an explicit polynomial kernel feature map for person re-identification [C]// CVPR ’15: Proceedings of the 2015 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1565-1573.
[11]YOU J, WU A, LI X, et al. Top-push video-based person re-identification [C]// CVPR ’16: Proceedings of the 2016 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 1345-1353.
[12]WRIGHT J, YANG A Y, GANESH A, et al. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 31(2): 210-227.
[13]ZHANG T, GHANEM B, LIU S, et al. Robust visual tracking via structured multi-task sparse learning [J]. International Journal of Computer Vision, 2013, 101(2): 367-383.
[14]MAIRAL J, SAPIRO G, ELAD M. Learning multiscale sparse representations for image and video restoration (PREPRINT)[J]. SIAM Journal on Multiscale Modeling and Simulation, 2008, 7(1): 214-241.
[15]YANG A Y, SASTRY S S, GANESH A, et al. Fast1-minimization algorithms and an application in robust face recognition: a review [C]// ICCP 2010: Proceedings of the 2010 17th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2010: 1849-1852.
[16]YANG M, ZHANG L, FENG X, et al. Fisher discrimination dictionary learning for sparse representation [C]// ICCV ’11: Proceedings of the 2011 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011: 543-550.
[17]ELHAMIFAR E, VIDAL R. Robust classification using structured sparse representation [C]// CVPR ’11: Proceedings of the 2011 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011: 1873-1879.
[18]HARANDI M T, SANDERSON C, HARTLEY R, et al. Sparse coding and dictionary learning for symmetric positive definite matrices: a kernel approach [C]// ECCV 2012: Proceedings of the 2012 European Conference on Computer Vision, LNCS 7573. Berlin: Springer, 2012: 216-229.
[19]KHEDHER M I, YACOUBI M A E, DORIZZI B. Multi-shot SURF-based person re-identification via sparse representation [C]// AVSS 2013: Proceedings of the 2013 10th IEEE International Conference on Advanced Video and Signal Based Surveillance. Washington, DC: IEEE Computer Society, 2013: 159-164.
[20]AN L, YANG S, BHANU B. Person re-identification by robust canonical correlation analysis [J]. IEEE Signal Processing Letters, 2015, 22(8): 1103-1107.
[21]HIRZER M, BELEZNAI C, ROTH P M, et al. Person re-identification by descriptive and discriminative classification [C]// SCIA 2011: Proceedings of the 2011 Scandinavian Conference on Image Analysis, LNCS 6688. Berlin: Springer, 2011: 91-102.
[22]WANG T, GONG S, ZHU X, et al. Person re-identification by video ranking [C]// ECCV 2014: Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Cham: Springer, 2014: 688-703.
[23]GRAY D, BRENNAN S, TAO H. Evaluating appearance models for recognition, reacquisition, and tracking [C]// PETS 2007: Proceedings of the 10th IEEE International Workshop on Performance Evaluation for Tracking and Surveillance. Piscataway, NJ: IEEE, 2007, 3: 41-47.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
