基于視覺顯著性與膚色分割的人臉檢測
2018-04-13 01:07:00鮑小如曹雪虹焦良葆
計算機技術與發展 2018年4期
鮑小如,陳 瑞,曹雪虹,焦良葆
(1.南京郵電大學 通信與信息工程學院,江蘇 南京 210003;2.南京工程學院 通信工程學院,江蘇 南京 211167;3.南京工程學院 康尼機電研究院,江蘇 南京 211167)
0 引 言
人臉檢測一直是圖像處理與模式識別中的研究熱點,現已廣泛應用于智能監控、手機拍照、個人身份識別等領域。人臉檢測算法層出不窮,大致可分為以下3大類[1]:膚色分割法、提取幾何特征法和統計理論的方法。基于膚色分割[2-5]的人臉檢測算法利用的是彩色圖像中人臉膚色與非人臉之間的差別。該類算法雖然因其原理簡單而較容易實現,且可以滿足實時檢測的要求,但是檢測效果易受光照和類膚色的影響。基于幾何特征的方法中最常用的是基于模板匹配的人臉檢測方法[6-8]。它從大量的人臉圖像中訓練出統一的人臉模板,然后在檢測區域中尋找與該模板最相似的區域,即確定為人臉區域。但精確的人臉模板較難實現,因為人臉間的差異頗大,另一方面人臉姿態的不統一也使得檢測效果不理想。基于統計理論的人臉檢測算法中應用最廣的是Viola-Jones提出的AdaBoost方法[9]。該方法的特征選擇是在積分圖像上完成的,首先選擇特征構建弱分類器,采用“級聯”的方式一步步地構建強分類器。該算法推出了一種人臉檢測框架,極大地提高了人臉檢測的速度和準確率,但對不端正人臉檢測時,檢測率不高。
近年來視覺顯著性發展相當迅速,自Koch和Ullman[10]提出所謂的生物啟發模型后,學者們開啟了視覺顯著性的研究與探索。其中,Itti等[11-12]提出了一種基于視覺注意的顯著性檢測模型,接著Harel等使用文獻[11]中特征選擇的方法,并結合馬爾可夫鏈的原理,用以計算特征之間的差異,最后將其正則化處理后,生成基于圖的視覺顯著模型(graph-based visual saliency,GBVS)[13]。之后還有Goferman等提出的基于上下文的顯著性分析方法等等[14]。在國內,清華大學的程明明等[15]提出了基于直方圖對比度(histogram contrast,HC)的顯著性分析算法與結合區域對比(region contrast,RC)的顯著性分析方法等等。
文中提出一種基于視覺顯著性與膚色分割的人臉檢測算法。由于利用GBVS算法生成的顯著性圖中顯著性區域比較集中,可以更好地提取人臉目標,而其他視覺顯著性算法提取的顯著性區域比較分散或者顯著性區域細節文理太清晰,這兩種情況都會影響顯著圖的閾值分割并得到模板的進程,所以文中使用基于圖論的顯著性檢測算法獲取人臉區域的顯著圖。可以先利用視覺注意機制[16],從一幅復雜背景圖中快速定位出包含人臉的大致區域,再利用人臉膚色在L*a*b*空間[17]的a,b分量確定人臉中心位置。
1 基于圖論的視覺顯著性(graph-based visual saliency,GBVS)
國內外學者一般認為對于一幅圖像,人們視覺第一時間注意到的區域,或者局部視覺特征突出的區域為圖像顯著性區域。鑒于GBVS生成的顯著圖主要集中在一塊區域且有利于閾值分割,文中采用GBVS算法進行前期處理,GBVS在特征提取上沿用了Itti等提出的方法,并在計算特征之間的差異時引入馬爾可夫鏈得到顯著性值,最終歸一化顯著值生成視覺顯著圖。
視覺顯著圖獲取步驟如下[18]:
(1)輸入一幅大小為250×250的灰度圖片,利用高斯核函數平滑圖像,每次將分辨率降低為原來的1/2,下采樣4次,實驗中只用第2,3,4次采樣得到的圖像。分別提取這3幅圖像的亮度特征和方向特征,其中方向特征是提取的0°,45°,90°,135°方向的信息,最后可得到15幅底層特征圖(圖像尺寸32×32)。
(2)把這15幅特征圖依次作為輸入,計算每幅圖的激活圖。對每一幅特征圖,以圖中的每一個像素點為節點,根據像素點間的灰度值相似度和像素點位置間的距離(歐氏距離)作為連接權值,建立一個全連通的有向圖GA,從節點(i,j)到節點(p,q)的有向邊會賦予一個權值,定義為:
W((i,j),(p,q))=d((i,j)‖(p,q))·
F(i-p,j-q)
(1)
其中,d((i,j)‖(p,q))表示節點(i,j)和節點(p,q)之間像素值M(i,j)和M(p,q)的相異程度,計算公式為:
(2)
F(a,b)表示節點(i,j)與節點(p,q)位置間的歐氏距離,計算公式為:
(3)
(3)連接權值矩陣(1 024×1 024),并歸一化權值矩陣,使矩陣每列之和為1,形成馬爾可夫狀態轉移矩陣。
(4)對馬爾可夫轉移矩陣進行多次迭代,直到馬爾可夫鏈達到平穩分布。馬爾可夫鏈的平穩分布反映了隨機游走者在每個節點/狀態消耗時間的積累。節點視覺特征越不相似,權值越大,轉移概率就大,在這個節點積累的時間就長;反之就短。視覺特征越不相似的點越顯著。
(5)找到馬爾可夫矩陣的主特征向量(1 024×1),主特征向量是主特征值對應的向量,矩陣的多個特征值中模最大的特征值叫主特征值,對應圖像的顯著節點。把主特征向量重新排列成兩維(32×32)的形式,就得到了激活圖,并對其進行歸一化。
(6)按以上方法得到每個特征通道的特征圖的激活圖,再把各個特征通道內激活圖相加,最后把亮度和方向特征通道激活圖都疊加起來,得到視覺顯著圖。
2 L*a*b*色彩空間
CIEL*a*b*色彩空間(簡稱L*a*b*色彩空間)是用L*,a*,b*三個不同的坐標軸指示顏色在空間中分布的一個三維體系。當用CIEL*a*b*表示某一顏色時,L*軸表示顏色的明暗程度,黑在底端,白在頂端;+a*表示紅色,-a*表示綠色;+b*表示黃色,-b*表示藍色;如圖1所示。顏色的色彩變化可以用a*,b*的數值來表示,顏色的亮度變化可以用L*的數值來表示。
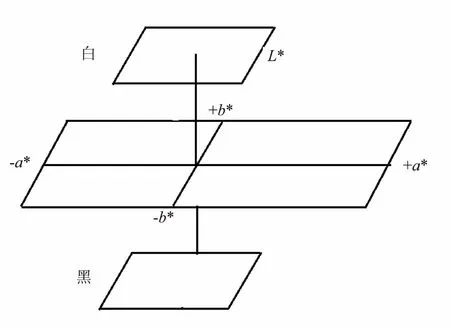
圖1 CIEL*a*b*色彩空間
將RGB色彩空間中的圖像信息轉換到L*a*b*色彩空間中,需要先對輸入圖像的RGB信息分量進行Gamma校正:R=g(r),G=g(g),B=g(b)。其中r,g,b(r,g,b∈[0,1))是輸入圖像的原始顏色分量信息,而R,G,B(R,G,B∈[0,1))分量則是經過Gamma校正后得到的顏色分量信息。
Gamma校正函數g(x)為:
(4)
然后將經過Gamma校正后的R,G,B分量轉換到XYZ空間:
[XYZ]=M*[RGB]
(5)
其中,轉換系數矩陣M為:

(6)
轉換后的X∈[0,0.950 6),Y∈[0,1),Z∈[0,1.089 0)。X,Y,Z經線性歸一化后得到X1,Y1,Z1∈[0,1),之后再進一步轉換到L*a*b*色彩空間:
L=116*f(Y1)-16
(7)
a=500*[f(X1)-f(Y1)]
(8)
b=200*[f(Y1)-f(Z1)]
(9)
其中,轉換函數f(x)為:
(10)
計算后可得到L,a,b分量值,L∈[0,100),a∈[-169,169),b∈[-160,160)。為了方便計算,可將3個分量都歸一化到[0,255]之間。
3 基于視覺顯著性與膚色分割的人臉檢測
文中算法的基本實現流程如圖2所示。

圖2 算法基本流程
開始輸入一幅含有人臉的復雜背景圖片,接著利用GBVS方法獲取圖片的視覺顯著性圖,然后對顯著圖進行閾值分割從而得到二值模板圖。但是該模板并不精確,內部可能存在少量干擾像素點或空洞,對其進行形態學操作之后就可以得到精確的模板了,模板中白色區域就是初步的人臉位置區域R1;接著計算原始圖像的R1區域在L*a*b*色彩空間中每個像素的a,b分量值與人臉膚色的a,b分量值的歐氏距離,并人為設定一個經驗閾值,排除一些相差很大的像素點;之后計算在閾值內的所有像素點的質心,將該質心作為人臉中心點,并按中心點到R1區域邊緣的最小距離的80%為半徑,截取準確人臉區域,即得到精確的人臉區域R2;最后在原始圖像上截取出人臉。
經過原理介紹,下面將給出算法的詳細實現步驟。該算法大致可分為三個部分:第一部分是從LFW數據庫中計算出人臉膚色在L*a*b*色彩空間的3個分量平均值;第二部分是使用視覺顯著性算法獲取圖像顯著圖并閾值化后得到初步目標人臉區域;第三部分是在得到的初步人臉區域中利用人臉膚色在L*a*b*色彩空間的a,b分量平均值進一步得到精確的人臉區域。算法具體的實現步驟如下:
(1)選取LFW數據庫中的部分標準圖像,截取圖像中的人臉膚色部分,并由RGB色彩空間轉換到L*a*b*色彩空間,計算L,a,b的分量值,最后取它們的平均值ave_L,ave_a,ave_b。
(2)輸入一幅彩色圖像I(x,y),通過GBVS算法生成該圖像的顯著性圖,記為S(x,y)。
(3)顯著性圖S(x,y)中每個像素的值即為該像素的顯著性值,將顯著性值歸一化到0~1之間,文中取0.6作為閾值對顯著圖S(x,y)進行分割,得到一個粗略的二值模板M(x,y)。
(4)對模板M(x,y)進行細化得到精確的模板M1(x,y)。具體操作如下:如果模板M(x,y)中存在一些由于閾值分割而殘留的像素點,則對其進行膨脹操作刪除干擾像素點;如果M(x,y)丟失信息過多,就對M(x,y)進行孔洞填充。最終得到模板M1(x,y)。
(5)通過模板M1(x,y)就可以得到人臉的初步區域,M1(x,y)中的白色區域就是目標人臉的大致區域R1了,接著將圖像I(x,y)從RGB色彩空間轉換至L*a*b*色彩空間,轉換后的圖像用IL(x,y)表示。對于IL(x,y)中R1區域的每個像素點計算出它們的a,b分量與第一步得到的ave_a和ave_b之間的歐氏距離dis_ave,考慮到光照因素的影響,除去了亮度分量ave_L。
(11)
(6)確定中心點。對于前面計算出的dis_ave,根據頻數直方圖統計的情況人為設定一個分割閾值s,除去R1區域內一些閾值之外的點。計算出中心點坐標cet_x,cet_y:
(12)
(13)
其中,p表示一個像素點;dis_ave_p表示像素點p的a,b分量與ave_a,ave_b之間的歐氏距離;count表示R1區域內在閾值s內的像素點的總數;p_x和p_y分別表示像素點p的橫坐標值和縱坐標值。
(7)確定目標人臉區域。對M1(x,y)進行邊緣處理,得到其區域邊緣的所有像素點集合,求出區域邊緣像素點到中心點最小距離r。最后以0.8r為半徑圍繞中心點作正方形,即該正方形區域就是最終要確定的目標人臉區域。
(8)在原始輸入圖像I(x,y)上截取之前得到的目標人臉區域,就完成了整個人臉檢測。
4 實驗仿真
實驗仿真是在LFW數據庫上進行的。該數據庫共收集了13 233張人臉圖片,圖片大小為250×250像素,圖片分屬5 749個不同的人,其中只有一張圖片的有4 096人,多于一張圖片的有1 680人,圖片中有些包含多個人臉,只考慮基本位于圖片中間位置的目標人臉。在MATLAB2012b平臺上進行程序編寫。
實驗對端正人臉和非端正人臉分別進行Viola-Jones的人臉檢測,視覺顯著性下的人臉檢測[18]和視覺顯著性下膚色導向的人臉檢測。Viola-Jones人臉檢測算法是目前最經典、使用最多的魯棒人臉檢測算法;文獻[18]是國內最新的一篇關于視覺顯著性的人臉檢測算法。與它們進行比較可以有效說明文中算法在人臉檢測中的有效性。端正人臉的測試結果如圖3所示,非端正人臉的測試結果如圖4所示。兩圖中的第一列表示輸入的原始圖像,第二列是Viola-Jones人臉檢測算法結果,第三列表示是文獻[18]中人臉檢測算法得到的結果,第四列是文中算法的實驗結果。

圖3 端正人臉

圖4 非端正人臉
由兩圖可知,在處理端正人臉圖像時,文中算法與Viola-Jones算法都能準確地檢測出人臉區域,且檢測效果基本一致。但是在處理非端正人臉圖像時,由于人臉姿態的變化,Viola-Jones算法過分關注眼睛、嘴巴等特征位置,檢測區域縮小,不能截取完整的目標人臉,損失了部分面部信息,有的甚至根本就不能看出原來人的模樣了;而文中算法是在視覺顯著性的基礎上確定目標大致位置,再利用人臉膚色確定檢測中心,更有利保護目標人臉的完整性,因此檢測效果要好于Viola-Jones算法。不管是在處理端正人臉還是非端正人臉,文獻[18]的算法與文中算法都能很好地檢測出人臉,但從兩幅圖中可以明顯看出文獻[18]中的算法檢測出的人臉區域包含大量背景,相比較之下文中算法檢測出的人臉區域所包含的背景則相對較少。此外,實驗還統計了三種算法檢測出人臉所消耗的時間與檢測率,如表1和表2所示。

表1 時間比較
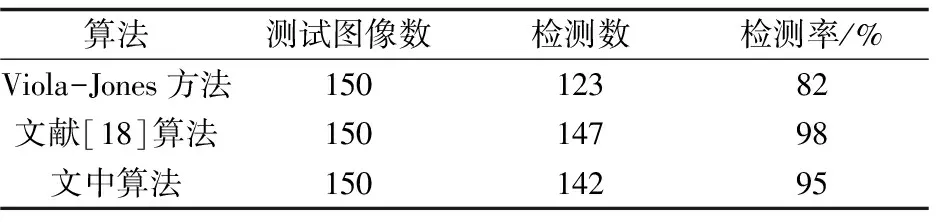
表2 檢測率比較
根據表1可知,在時間消耗方面,文中算法和其余兩種算法在時間上并無明顯差異,三者之間的最大差距僅為0.30 s,因此可以看出算法運行迅速,具備較好的實時性。從表2可以看出,文中算法在LFW人臉庫中的檢測率明顯高于Viola-Jones算法,基本能實現全檢測,而Viola-Jones算法對于臉部分辨率有一定要求,對于臉部分辨率較低的圖像,關鍵的特征提取變得困難,造成了一些檢測不出人臉的情況。綜上可得,文中算法是一種快速、自動、準確,且檢測率高的人臉檢測方法。
5 結束語
提出一種基于視覺顯著性與膚色分割的人臉檢測算法。首先通過GBVS算法獲得原始圖像的顯著性圖,接著選擇一個顯著性值作為閾值,分割該顯著圖得到二值模板,然后優化該模板得到初步的人臉區域,再根據人臉膚色在L*a*b*色彩空間中的a,b分量值與人臉初步區域中的像素點在L*a*b*色彩空間中的a,b分量的歐氏距離,確定人臉區域的中心,然后以初步區域邊緣到中心的最小距離的80%為半徑,在原圖中截取出矩形人臉區域,實現了復雜環境下的人臉目標檢測。與其他方法相比,該算法不僅準確度高,而且運行快速,可以很好地適用于智能手機前置拍照的人臉定位與人臉識別前期的預處理工作。
參考文獻:
[1] 鄭青碧.基于圖像的人臉檢測方法綜述[J].電子設計工程,2014,22(8):108-110.
[2] YANG Y,XIE C,DU L,et al.A new face detection algorithm based on skin color segmentation[C]//Chinese automation congress.Washington DC,USA:IEEE Computer Society,2015:523-526.
[3] DONG C,WANG X,LIN T,et al.Face detection under particular environment based on skin color model and radial basis function network[C]//IEEE fifth international conference on big data and cloud computing.Washington DC,USA:IEEE Computer Society,2015:256-259.
[4] ALABBASI H A, MOLDOVEANU F. Human face detection from images,based on skin color[C]//18th international conference on system theory,control and computing.Washington DC,USA:IEEE Computer Society,2014:532-537.
[5] MAHADEVI M,SUMATHI C P.Face detection based on skin color model and connected component with template matching[C]//International conference on information communication and embedded systems.Washington DC,USA:IEEE Computer Society,2014:1-4.
[6] DUTTA P,BHATTACHARJEE D.Face detection using generic eye template matching[C]//2nd international conference on business and information management.Washington DC,USA:IEEE Computer Society,2014:36-40.
[7] TEJA M H.Real-time live face detection using face template matching and DCT energy analysis[C]//2011 international conference of soft computing and pattern recognition.Washington DC,USA:IEEE Computer Society,2011:342-346.
[8] YAN Siyang,WANG Haiying,FANG Zhao,et al.A face detection method combining improved AdaBoost algorithm and template matching in video sequence[C]//28th international conference on intelligent human-machine systems and cybernetics.Washington DC,USA:IEEE Computer Society,2016:231-235.
[9] VIOLA P,JONES M.Robust real-time face detection[C]//Proceedings of eighth IEEE international conference on computer vision.Washington DC,USA:IEEE Computer Society,2001:137-154.
[10] KOCH C,ULLMAN S.Shifts in selective visual attention:towards the underlying neural circuitry[J].Human Neurobiogy,1985,4(4):219-227.
[11] ITTI L,KOCH C,NIEBUR E.A model of saliency-based visual attention for rapid scene analysis[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1998,20(11):1254-1259.
[12] ITTI L,KOCH C.Computational modelling of visual attention[J].Nature Reviews Neuroscience,2001,2(3):194-203.
[13] HAREL J,KOCH C,PERONA P.Graph-based visual saliency[C]//Advances in neural information processing systems.[s.l.]:[s.n.],2007:545-552.
[14] GOFERMAN S,LIHI Zelnik-Manor,TAL A.Context-aware saliency detection[C]//2010 IEEE computer society conference on computer vision and pattern recognition.Washington DC,USA:IEEE Computer Society,2010:2376-2383.
[15] CHENG M,ZHANG G,MITRA N J,et al.Global contrast based salient region detection[C]//CVPR 2011.Washington DC,USA:IEEE Computer Society,2011:409-416.
[16] 敖歡歡.視覺顯著性應用研究[D].合肥:中國科學技術大學,2013.
[17] 殷世瓊.基于視覺機制的圖像和視頻的顯著性檢測[D].合肥:合肥工業大學,2015.
[18] 陳 凡,童 瑩,曹雪虹.復雜環境下基于視覺顯著性的人臉目標檢測[J].計算機技術與發展,2017,27(1):48-52.
猜你喜歡
今日農業(2021年9期)2021-11-26 07:41:24
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
