關系數據庫SQL代碼的自動評分算法研究
2018-04-13 01:07:01吳嬌嬌何小衛
計算機技術與發展 2018年4期
關鍵詞:語義
吳嬌嬌,何小衛,趙 洋
(浙江師范大學 數理與信息工程學院,浙江 金華 321004)
0 引 言
隨著計算機技術與應用的快速發展,數據成為所有計算機應用的操作對象。在進行各種信息處理的過程中,數據占據著不可取代的地位[1]。由此可見,在計算機處理的背后,數據庫體系發揮著重大作用,對數據庫的學習也成為掌握計算機技能必不可少的條件。在數據庫的初級學習過程中,最重要的莫過于學習SQL(structured query language,結構化查詢語言)。SQL語言結構清晰,但是編碼有著多樣性及結果不易觀察的特點,使得代碼的評分標準變得界限模糊,人工評判工作愈加繁重[2]。為減輕人工評測負擔,構建自動評分模型及系統刻不容緩。而科學合理地評測SQL代碼,也成為構建模型的一個重要問題。
目前,代碼的自動評分技術主要分為動態測試和靜態分析[3]。動態測試是通過代碼執行的結果判定代碼的正確性;而靜態分析主要是通過分析代碼的結構特征及語義信息評判代碼。采用動態測試的評分系統,主要用于檢測VB程序,如段漢周等[4]提出的自動評分系統,以及檢測Java程序的BOSS系統[5];采用靜態分析的評分系統發展得較為成熟,比如用系統依賴圖分析語義相似度的基于語義相似度比較的編程題自動評分方法[6]和基于程序理解的編程題自動評分方法[7];當然,也有結合了動態測試和靜態分析的Course Master系統[8]。
文中借鑒程序代碼的自動評判技術,針對SQL代碼的特殊性,采用靜態分析方法構建自動評分模型,并通過實驗對其進行驗證。
1 自動評分模型
自動評分模型采用靜態分析的方法,總體流程如圖1所示。預處理刪除及處理了一些語句,使SQL語句表達統一化與規范化;對SQL代碼進行詞法分析,對SQL代碼每一部分進行分類,提取出特征結構,并進行分詞處理,獲得片段代碼;構建同義庫,對SQL片段代碼的相似語句向操作符少的語句轉化;利用LCS算法對參考片段代碼與要測評的片段代碼進行相似度比較,得到片段代碼的相似度;對代碼片段賦予相似度影響因子,計算出兩SQL代碼總的相似度;統計人工評審數據,用多項式擬合出相近數據,據此制定相應的評分策略。

圖1 自動評分模型總流程
1.1 預處理
由于書寫SQL語句時的不規范性和SQL語句表達的多樣性,為更好地識別SQL代碼,首先需要對SQL代碼進行規范化預處理,預處理流程見圖2。
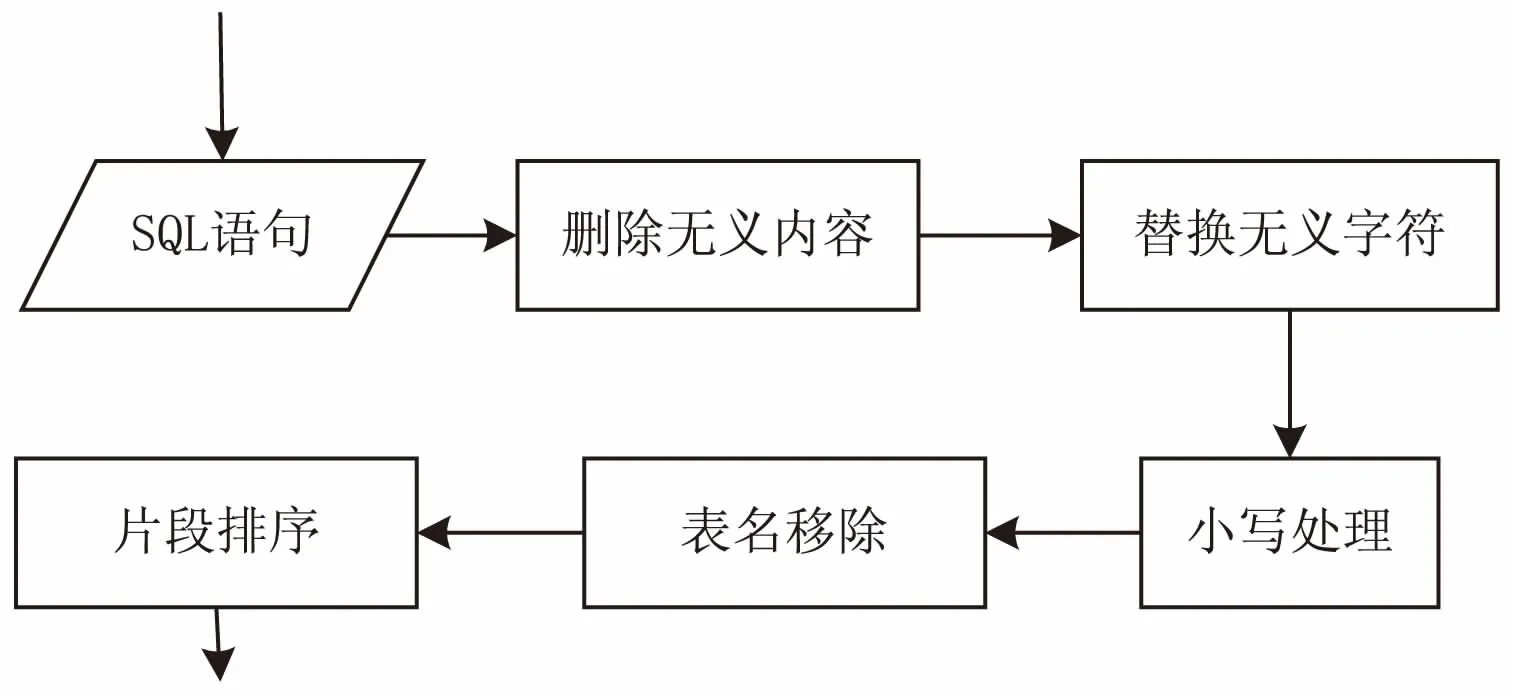
圖2 預處理流程
(1)刪除注釋以及與SQL代碼語義無關的內容;SQL代碼中的注釋可以隨意敲入而不影響代碼結構及語義,這對特征提取無用,因此,移除一切與語義無關的代碼。
(2)用空格代替SQL語句中的回車符,以及移除多余的空格[9];在敲寫代碼的同時,可能無意地敲入一些空格、回車符等無義字符,使得代碼愈加繁瑣,需要移除,使得代碼簡潔明了。
(3)將SQL代碼全部變成小寫形式;統一規范大小寫,也可以全部轉化為大寫形式。
(4)對于表名加字段名的代碼,將表名移除,留下“.+字段名”。為體現代碼中帶有表名,保留“.”,但為了代碼的易于識別,移除會給相似度帶來較大誤差的表名。例如:“select table1.ename, table2.ename from emp table1, emp table2 where table1.mgr=table2.empno;”進行處理后可轉化為“select .ename, .ename from emp table1, emp table2 where .mgr=.empno;”。
(5)對SQL代碼的各個關鍵詞之間的字段以及子句按ASCII值先后順序排序。其目的是保證相似語義的代碼片段相似度匹配時能獲得最大相似度[10]。例如:“select c1,a2,b3 from t1,t3,t2 where condi3=3 or condi1=1 order by o6,o2”進行排序處理后,可以轉化為“select a2,b3,c1 from t1,t2,t3 where condi1=1 condi3=3 or order by o2,o6”。
1.2 特征提取
對SQL代碼的特征提取及分詞,首先對代碼進行詞法分析,然后將代碼轉化為可識別的含結構和語義信息的字符串序列。
由分析可知,SQL語句有其特有的語法規則以及明確的關鍵字,在評分時,關鍵詞占據較大的比重,先查詢到關鍵詞的正確率,才會逐步分析關鍵詞之后的字段差異。因此在提取結構時,首先按照關鍵詞提取SQL的結構特征。將SQL代碼進行分類標識,分為關鍵詞和關鍵詞之后的字段,并分別為此分配不同的類型,作標記為:keyword,body。可將SQL語句表述為:
SQL={ (Word1,C1) … (Wordi,Ci)|i∈N+}
(1)
其中,Wordi為SQL代碼的關鍵詞或關鍵詞之后的字段;Ci為標記keyword或body。
給定如下SQL代碼:update emp set sal=newsal where eid=id;可轉化為(update,keyword)(emp,body)(set,keyword)(sal=newsal,body)(where,keyword)(eid=id,body)。
1.3 同義轉換
在評分過程中,兩段不同代碼實現的功能及得到的結果一致,就可以認為這兩段代碼是相同的。SQL語句中存在一些相似句,雖然表現形式不一,但可以得出相同的結果,這些句子可稱之為相似句。判斷字段:sal between 3 000 and 5 000,它相當于sal>=3 000 and sal<=5 000;sal in (3 000,5 000)相當于sal=3 000 or sal=5 000,某些情況下的連接字段:from a1 left outer join a2 on a1.name=a2.name,和from a2 right outer join a1 on a1.name=a2.name。
相似度比較并不能很好地識別相似句,因此為提高匹配的精確度,對代碼進行相似句轉化很有必要。為精簡轉化,對相似的語句建立語句同義庫,常用等價語句如表1所示。轉化的過程向同義庫規則靠攏。文中規定,將操作符多的向操作符少的轉化,如前段判斷字段所述,相同操作符的按ASCII值從大向小轉化。

表1 常用等價語句表
1.4 基于LCS的相似度比較
計算相似度本質上是對要比較的字符串與標準字符串之間進行字符串匹配。對于字符串匹配研究,現今已發展到較為成熟的水平,尤其在相似度檢測方面。字符串匹配算法大體上分為精確匹配與近似匹配,近似匹配就是在匹配時允許字符串出現一些誤差。精確匹配主要應用于文本查找、網絡安全等方面,近似匹配的應用域較為廣泛,包括信號處理、生物DNA信息檢測、語音識別、信息查詢、相識度檢測、查重等。字符串相似度匹配算法有簡單字符串匹配,基于字符距離的算法[11],基于GST算法[12]或局部過濾的字符串比較。
經過特征提取,抽取出了keyword以及body。由于對SQL進行分詞過程相當于對關鍵詞進行抽取匹配,因此相似度比較只需比較關鍵詞之后的字段即body字段,也可稱之為body代碼片段。body代碼片段有其特有的規則和約束,有一定的規律和固定的表現形式。文中采用一種經典的簡單字符串比較算法-最長公共子串算法進行相似度比較。LCS的經典算法有兩種:動態編程(DP)或者后綴數組(suffix array)。文中采用DP求解最長公共子串。
針對該模型的最長公共子串問題可表述為:給定兩個代碼串,即參考代碼的body片段S1,評測代碼的body片段S2;求解S1,S2兩代碼串之間最長的相同字符串的長度。
定義1:
(1)兩個字符串:參考body代碼片段S1=[a1,a2,…,am],評測body代碼片段S2=[b1,b2,…,bn],m,n∈N+,a1,a2,…,am為body代碼片段S1中的每個字符,b1,b2,…,bn為body代碼片段S2中的每個字符;
(3)由SL[i][j]可得對應的最長公共子串,標記為:LCS(S1,S2);
(4)最長公共子串的長度為max(SL[i][j]),i∈{1,2,…,m},j∈{1,2,…,n}。
若S1[i+1]和S2[j+1]不同,那么SL[i+1,j+1]就應該為0,因為任何以它們為結尾的子串都不可能完全相同;而如果S1[i+1]和S2[j+1]相同,那么只要在以S1[i]和S2[j]結尾的最長相同子串之后添上這個字符即可,這樣就可以讓SL增加一位;值得注意的是,若S1,S2中任何一個是空字符串,那么最長公共子串的長度SL就為0。這是一個遞歸問題的求解,為了更直觀形象地表述,可以得到狀態轉移方程:
(2)
通過SL[i][j]可以得到對應的最長公共子串LCS。
定義2:參考和評測body代碼片段的相似度為:
(3)
其中,S1.length和S2.length分別為字符串S1和S2的長度。
定義了以上兩條,就可以對body代碼片段進行相似度計算。編寫代碼,經過整合,可以得到一個相似度集合,將該集合表達成一個向量,以便觀察。相似度集合表示為:
Similar=(sim1,sim2,…,simN),N∈N+
(4)
例1,現有兩個SQL代碼:S1={select count(ename), avg(sal), floor(sysdate-hiredate/365) from emp, info where ename='li' group by(deptno);};S2={select count(ename),floor(sysdate-hiredate/365) from emp where ename='li' group by(deptno);};根據定義1、定義2及式(4),可得到相似度集合similar=(1,0.83,1,0.43,1,0.92,1,1)。
(2)金標記BLI檢測。將光纖傳感器末端置于奶液中(200μL牛乳+50μL緩沖液+5μL金標BSA)中平衡120 s;然后,將光纖傳感器末端沒入待測奶液(200μL待測牛乳+50μL緩沖液+5μL金標氯霉素素單克隆抗體)中700 s。檢測牛乳中氯霉素殘留量。
1.5 相似度調整及評分策略
SQL評分時各個部分所占評分比重的不一致,使得對各個部分的相似度增加影響因子的處理很有必要[13-14]。又因為SQL評分時關鍵詞對評分結果的影響較大,所以需賦予關鍵詞較大的影響因子。為了使自動評分的結果更接近人工評審的結果,通過實驗將影響因子定為:(α1,α2,…,αN),N為字段的個數,有以下約束關系:
(5)
賦予影響因子后的總相似度為:
SQLSim=sim1*α1+sim2*α2+…+simN*αN
(6)
從例1中可以得到總的相似度SQLSim=1*1/6+0.83*1/12+1*1/6+0.43*1/12+1*1/6+0.92*1/12+1*1/6+1*1/12=0.93。
為使自動評分更貼近人工評審,根據人工評判結果制定了評分策略。據人工評判數據統計,得到相似度sim和分數score的關系圖(見圖3)。由圖3可知,score和sim之間存在某種映射關系,通過多項式擬合,得到函數為:f(x)=-47.5x2+121.8x+21.8,波形如圖4所示。
最終得到分數與相似度之間關系:score=-47.5 sim2+121.8sim+21.8,擬合誤差∑Δx2=251.08。
可以評定出例子1的分數為94分。
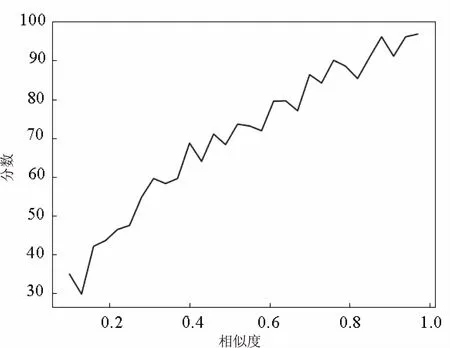
圖3 人工評審得到的關系圖
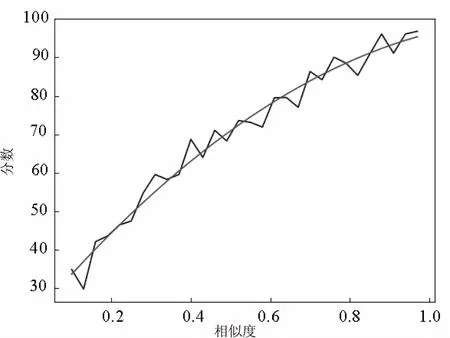
圖4 擬合后的關系圖
2 實驗結果與分析
從圖4可以看出,折線波動較大,是由于人工評審時誤差較大,容易受到主觀因素的影響,存在誤判的概率。而對于自動評判,客觀評分減小了誤判的概率。
2.1 人工評分和自動評分數據分析
由于評分策略采用人工數據擬合的方法,對于相似度已知的代碼,自動評分已貼合人工評判給出的分數。除去計算相似度之后的影響,整體評測人工評分和自動評分的數據。
現有測試集:A班作業SQL代碼,共計200條數據。對該測試集進行自動評分測試,統計準確率,如圖5所示。
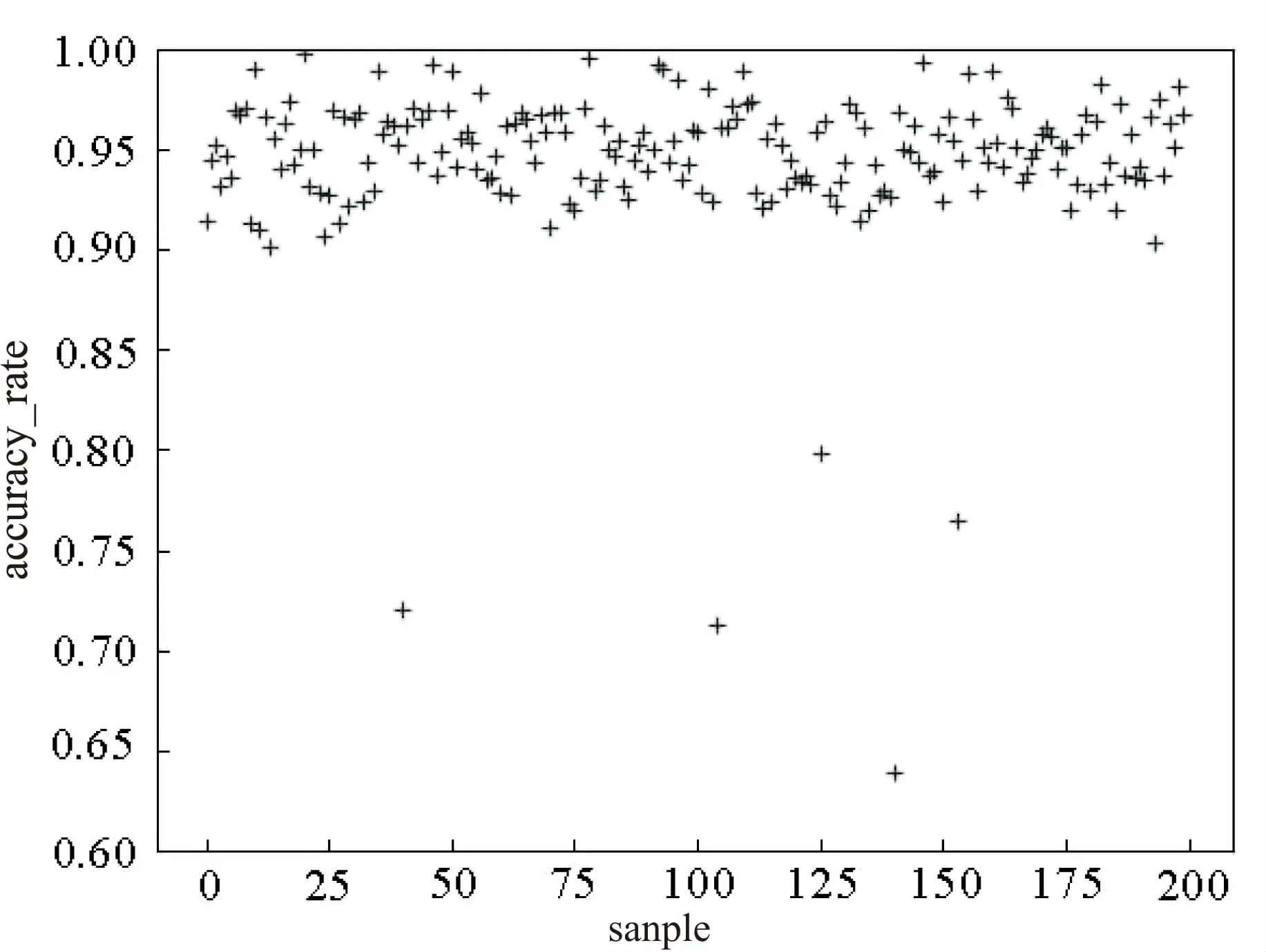
圖5 樣本的準確率
由圖5可看出,樣本的準確率區間大體在[0.92,0.98]之間,零星散落部分點在其他準確率較高和較低部分。據分析發現,較低部分的準確率是作業中出現了將關鍵詞拼錯,但是關鍵詞之后的字段出錯地方較少的情況。因此,除去關鍵詞出錯的情況,該自動評分模型對SQL代碼的評分準確率高且穩定,總的來說可以達到較好的效果,因此可以定性地評判SQL代碼。
2.2 相似度參數數據分析
SQL評分時關鍵詞和body所占評分比重不同時,即影響因子不同,對評分準確率的影響也有差別[15]。為確定最精確的影響因子,實驗統計了兩個參數:關鍵詞所占整個SQL代碼的比重記為α,以及評分的準確率accuracy_rate;調整參數α,統計準確率。統計結果如圖6所示。
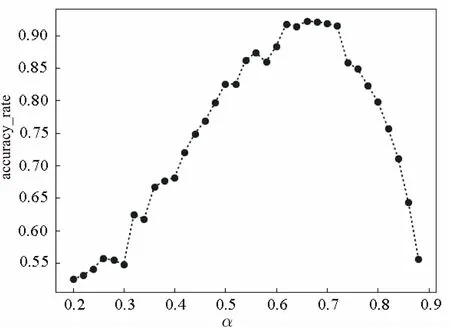
圖6 α與accuracy_rate關系圖
從圖6可以看出,關鍵詞的影響因子對評分的準確率有一定影響。在到達臨界點之前,折線圖大體隨著α的增加而增加,臨界點之后,準確率隨α的減少而劇烈下降。經分析可知,這是由于SQL代碼的結構性特點,評分時關鍵詞需要占據一定的比重,如果比重過低體現不出SQL代碼的結構,如果比重過高,難以體現細節之處。經過分析衡量,臨界點大約在0.62~0.69之間,為便于計算,將關鍵詞的影響因子定為總代碼的2/3。
經過實驗與數據統計,該模型可以對較長的SQL代碼進行相似度匹配。采用同義庫以及最長公共子串的算法,有效提高了自動評分的正確性。但是經過分析發現,自動評分也存在語義正確但是評分低的狀況,如關鍵詞錯誤。因此,對于關鍵詞錯誤的情況,應該另行分析。
3 結束語
針對數據庫SQL代碼的評分,提出了新的SQL代碼的自動評分模型。該模型借鑒了代碼的靜態分析方法,對相似語義構建了SQL代碼的同義庫,運用最長公共子串的算法對代碼片段進行相似度匹配,又根據人工評判數據進行多項式擬合,制定了貼合實際的評分策略,并為此開發了原型系統。實驗結果表明,該模型有效提高了SQL代碼的評分效率及正確率,因此可以定量地衡量SQL代碼的水平。但是,該模型存在一些問題,比如關鍵詞出錯的處理,尚需進一步深入,可作為未來工作的研究點。
參考文獻:
[1] 解 萍.《數據庫》課程在學生軟件能力培養中的作用分析[J].科技視界,2012(15):101-102.
[2] 楊鶴標,劉 玲,楊立凡.基于結構相似匹配的SQL程序自動評估模型研究[J].計算機工程與科學,2010,32(11):92-96.
[3] 鄭燕娥.Java編程題自動評分技術的研究與實現[D].泉州:華僑大學,2013.
[4] 段漢周,凌 捷,鄭衍衡.VB程序設計考核自動評閱系統中若干問題的研究[J].計算機工程,2001,27(4):167-168.
[6] 王甜甜.基于語義相似度的編程題自動評分方法的研究[D].哈爾濱:哈爾濱工業大學,2005.
[7] 馬培軍,王甜甜,蘇小紅.基于程序理解的編程題自動評分方法[J].計算機研究與發展,2009,46(7):1136-1142.
[8] 牛永潔,張曉光.關于程序設計題自動評分方法的研究[J].信息技術,2010(11):155-156.
[9] CHEN Yaofei,CHEN Huantong.Research of automatic ma-rking on SQL server skill assessment based on XML[C]//International conference on web information systems and mining.Washington DC,USA:IEEE Computer Society,2010:8-12.
[10] HINKKA M,LEHTOAND T,HELJANKO K.Assessing big data SQL frameworks for analyzing event logs[C]//24th Euromicro international conference on parallel,distributed,and network-based processing.Washington DC,USA:IEEE Computer Society,2016:101-108.
[11] 王小鳳,周明全,耿國華,等.一種基于字符距離的特征字符串近似匹配算法[C]//圖像圖形技術與應用學術會議.北京:北京師范大學出版社,2008.
[12] 徐黎明.基于GST字符串近似匹配算法的研究[J].內蒙古科技與經濟,2016(7):87-89.
[13] KLEINER C,TEBBE C,HEINE F.Automated grading and tutoring of SQL statements to improve student learning[C]//Proceedings of the 13th Koli calling international conference on computing education research.New York,NY,USA:ACM,2013:161-168.
[14] 馮君遠,賴明欽,李啟良.C語言源代碼抄襲識別的研究[J].福建電腦,2013,29(5):34-36.
[15] POHUBA D,DULIK T,JANKU P.Automatic evaluation of correctness and originality of source codes[C]//10th European workshop on microelectronics education.Washington DC,USA:IEEE Computer Society,2014:49-52.
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
