基于標簽分組先來先服務的自適應幀時隙Aloha 防碰撞算法研究
2018-04-29 07:54:37董輝盛魁馬健姚宏亮
廣西科技大學學報 2018年1期
董輝 盛魁 馬健 姚宏亮

摘 要:為解決射頻識別系統中多標簽碰撞問題及提高系統性能,在綜合分析基于時隙Aloha協議多種防碰撞算法的基礎上,提出一種基于標簽分組先來先服務的自適應幀時隙Aloha防碰撞算法(TG-FCFS ADFSA).該算法通過對標簽分組和先來先服務及幀時隙預約策略,自適應分配成功時隙來快速識別標簽,極大地提高了RFID系統性能.MATLAB仿真結果證明:TG-FCFS ADFSA算法在標簽數量越多識別優勢越明顯,特別是標簽數量超過1 000時,該算法比DSFA,GDFSA算法標簽吞吐率提高1倍以上,時隙開銷降低50%以上,系統識別效率和穩定性明顯提高.
關鍵詞:射頻識別;防碰撞;幀時隙;分組序化
中圖分類號:TN911. 23 DOI:10.16375/j.cnki.cn45-1395/t.2018.01.011
0 引言
射頻識別(Radio Frequency Identification,RFID)技術是利用無線射頻方式進行非接觸雙向通信,以實現自動識別和遠程實時監控及管理[1],被廣泛應用于交通、物流、制造及公共安全及信息服務等領域[2].在RFID系統中,閱讀器以廣播方式發布的命令可被信號區內所有標簽監聽到,這種方式造成多個標簽可同響應閱讀器命令,產生彼此干擾,極易發生標簽碰撞[3].囿于技術實現、制造成本及功耗等諸多因素,當前RFID系統防碰撞算法主要采用時分多路訪問控制技術[4].防碰撞算法主要有3種:①基于搜索樹的防碰撞算法[5];②基于Aloha協議的防碰撞算法[6];③搜索樹和Aloha協議的混合算法[7].其中②類算法由于標簽內部電路設計、實現過程簡單而被廣泛應用,但會因標簽數的增多,出現標簽丟失和隨機后識別等不良現象[8],標簽碰撞的概率增加,導致RFID系統的識別率迅速下降.
通過對多種防碰撞算法的研究,提出了基于標簽分組先來先服務的自適應分配幀時隙Aloha(Tag-Group First Come First Service Adaptive Allocating Dynamic-Frame-Slotted Aloha,TG-FCFS ADFSA)算法,該算法在RFID系統識別標簽時首先采用Vogt算法估算標簽數,在一次識別任務中,當待識別標簽數目在355以內時,采用動態幀時隙(DFSA)算法識別標簽,當待識別的標簽數達到356以上時,在對標簽分組并序化,并采用先來先服務方式,結合動態幀長調整及幀時隙自適應分配等策略對標簽進行識別.
1 基于Aloha協議的算法
純Aloha協議算法由于信息發送的隨機性,導致極易發生信息碰撞,識別率和吞吐率都較低,吞吐率最高約為18.4%[9];時隙Aloha(SA)算法碰撞概率為純Aloha協議算法的一半,標簽吞吐率約為36.8%[10];幀時隙Aloha(FSA)防碰撞算法是把若干時隙組成幀,一個時隙唯一被一個標簽選中,則標簽被識別,否則即碰撞[11].FSA算法因識別速度快被廣泛采用,但缺點是若待識別標簽數遠小于或大于幀長,系統吞吐率則又會變得很低.動態幀時隙Aloha (DFSA )防碰撞算法是根據待識別標簽數量,動態調整幀時隙數與標簽數盡可能的接近,使算法的識別效率接近或達到最佳值,但如何估算出標簽數量又成為該算法的難點,為此,一些學者設計了相關估值方法,如有Vogt算法、Cratio算法、Schoute 算法和 Low Bound 算法等.
1.1 TG-FCFS ADFSA算法基礎
1.1.1 幾個基本概念
1) 標簽丟失率
RFID系統在一次標簽識別過程中,在有限的逗留時間內識別信號區未被閱讀器識別標簽數與待識別標簽總數之比即為標簽丟失率.標簽丟失率與RFID系統的吞吐率、識別效率等密切相關,是衡量RFID系統性能的一個重要指標.
2) 隨機后識別
基于Aloha協議的防碰撞算法,標簽隨機選擇時隙與閱讀器進行信息交互,可能造成先進入識別區的標簽被后識別,即隨機后識別現象[8].這種現象是導致標簽丟失的原因之一,但是如果通過增加標簽的逗留時間弱化這一問題又會影響系統的吞吐率,本文通過標簽分組序化操作,來弱化標簽識別的隨機性,降低標簽丟失率提高識別率.
3) 3種時隙及吞吐率
時隙僅被一個標簽選中請求識別即為成功時隙,時隙沒有被任何標簽選中響應即為空閑時隙,若一個時隙被2個以上的標簽選擇則為碰L撞時隙.根據文獻[12],一個時隙內標簽響應的概率為:
1.2 TG-FCFS ADFSA算法關鍵步驟
1)估算待識別的標簽總數
本文根據對幾種常見估算算法的進行比較分析,發現Vogt算法估算誤差較小且穩定[10],通過實測的與預期的3種時隙數的比較分析,估算誤差最小,所以本文采用該算法標簽數,Vogt公式如下:
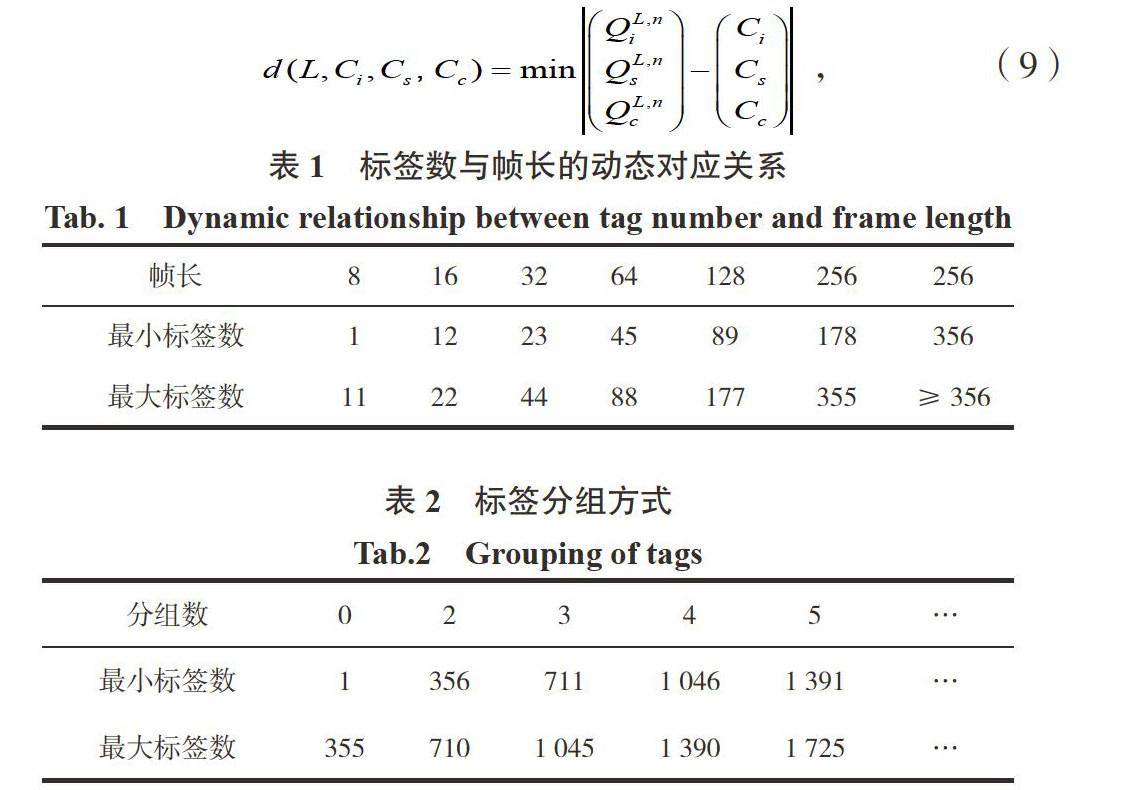
其中,Ci,Cs,Cc分別表示一幀的空閑、成功、碰撞時隙數,對d取最小值n,即是估算的待識別的標簽數.
2)標簽分組序化操作策略
① 標簽分組策略
如果n的值在355以內,使用動態幀時隙算法直接對標簽識別,無需分組,如表1所示.
在許多應用場景,信號區待識別標簽數目較多,因受到標簽存儲、成本等因素局限,幀長最大值通常取Lmax=256,若標簽數n≥356,則按進入識別區的時間先后分組,每個分組內標簽數最大值為355,以最大幀長對每組標簽進行識別,依據表2對標簽分組.
② 標簽分組序化相關概念
標簽分組序化是指在標簽進入信號區以后,根據進入的時間段順序按表2規則對標簽分組,每組賦予一個序列號(Serial Number,SN),同組內的標簽SN相同,非同組的SN不同,此過程稱之為標簽分組序化.間隔的時間段為分組序化周期(Period of Tag_Serialing, PTS).
③ 標簽分組的序化策略
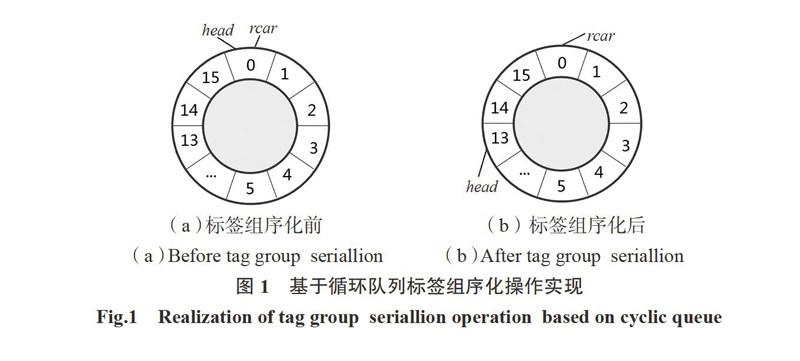
為提高RFID系統的吞吐率和識別率,本文算法采用循環隊列方法對標簽組序化.循環隊列的數據結構是一維數組空間S,有S[0]至S[15]16個元素,頭尾指針header、rear初值均為0,數組S的每個元素存儲相應時序標簽組的標簽數.當rear超過數組元素個數時,rear置0,重新開始循環隊列.
當信號區標簽數n≥356,以表2的方法對標簽進行分組,令新標簽SN=rear,之后rear=(rear+1)% 16(注:%為取模運算符,下同),經過此運算,得到可以反復使用的SN循環隊列{0,1,2,3,…,14,15}.通常情況下,RFID系統中一次識別任務通常不會多于2 000,把標簽組最多為16是合理的,若分組過多,幀時隙就不能有效利用.
標簽組的序化步驟如下:
Step 1 閱讀器開始工作,每隔一段時間發送序含參數head和rear的序化命令SC(Sequencing Command),head=rear=0,表示識別區內沒有分組被序化.
Step 2 識別區內標簽對響應SC命令分為2種情形:
A 若標簽的SN≠NULL,則表示該標簽已被序化,不再響應此命令,標簽SN值不變.
B 若標簽的SN=NULL,則說明該標簽是新進入識別區的,令SN=rear后,再rear =(rear+1) % 16,標簽加入最新標簽分組.圖1為標簽組序化操作實現示例.
標簽組序化偽代碼如下:
Reader:
Flag_point: If mod(Identity_Time,PTS)==0 //識別時間每過PTS
{Send SC(header,rear //閱讀器發送序化命令SC(head,rear)
Tag:If(not Receive SC) // 信號區內的標簽未收到SC(head,rear)命令
{ if (header == rear) {goto Flag_Point;} }
Else { If (tag' s SN==Null) { Tag' s SN =rear; Send Ack; }
//新進入識別區的標簽加入最新標簽分組, 標簽發送Ack確認信號
Else { Tag' s SN is unchanged;}
}
Reader:
If( Receive Ack ) { rear = (rear +1) % 16;} //經過取模運算, rear指針指向新的隊尾
Else { rear is unchanged; }
3) 標簽組先來先服務
在標簽分組序化操作策略中,信號區內的標簽被分成多組,當閱讀器發送查詢命令,若標簽組SN與命令參數相等可響應.標簽組先來先服務就是指擁有最早時間序列號的標簽響應閱讀器的指令.
標簽組先來先服務的步驟:
Step 1 閱讀器發送帶有參數header的標簽組識別命令IC(header) (Identify_Command,IC),識別具有最早時序號的標簽.
Step 2 每一幀循環結束后,IC (header)的執行情況如下:
A 若具有最早SN的標簽全被識別,header =(header +1)%16,即header指向下個標簽組;
B 若具有最早SN的標簽未全被識別,header值不變,下個幀循環繼續識別該組的標簽.
標簽組先來先服務偽代碼如下:
Reader: Send IC (head); // 閱讀器發送擁有最早標簽組序號的識別命令
Tag:Receive IC (head); //標簽收到識別命令
If (Tag' s SN =head) { Tag response to IC (head);} //標簽應答閱讀器的識別命令
Else {Tag no response to IC(head); }
Reader: If(a frame cycle is finished) //一次幀循環結束
{ if (there is unIdentityIdentitied Tag) //有未識別的出現碰撞
{Reader' s header is unchanged; }
Else { Reader' s header=(header +1)%16; } // head+1取模,指向下一個標簽組
2 TG-FCFS ADFSA算法實現步驟
TG-FCFS ADFSA算法流程如圖2所示,實現過程可分為以下幾個階段:
Step 1 標簽數量估算和分組序化
①簽數量估算: 在識別開始階段,用Vogt 算法估算出標簽的數目n.
②分組序化:
A 當n≤355時,直接調用DFSA算法識別標簽.
B 當n≥356時,閱讀器根據表2計算標簽分組數g,同時定義一個初值為0計數變量i,并發出時序命令SC(header,rear),對標簽分組序化,每個標簽分組獲得時序編號SN.
Step 2 判定最早時序標簽分組是否存在
閱讀器廣播一個時間組開始命令TC(header),確定最早時序分組是否還在識別區內.該命令執行的結果有2種情況:
①識別區內不存在標簽組SN與header相等,說明最早時序標簽組已不存在,閱讀器的header =(header+1)%16,即進入下一個時序標簽組識別過程,計數變量i=i+1.
②若識別信號區內存在標簽組SN=header,則表示最早時序標簽組仍在信號區內且組內還有被識別的標簽,此類標簽發出ACK信號.
Step 3 幀時隙分配
當閱讀器收到標簽的ACK后,立刻發送幀開始命令FSC(M),標簽收到命令其時隙計數器隨機生成①個時隙號,每個標簽都發送自己的時隙號,預約時隙.閱讀器根據標簽的預約,判斷出成功、空閑或碰撞的時隙,成功時隙標志位Flag =0,否則Flag =-1,根據時隙預約的情況,閱讀器發出Update( )命令,每個標簽知通過此命令可獲其他標簽預約時隙的情況.
Step 4 標簽識別階段
①閱讀器發送識別命令IC(header),擁有最早時序號SN =header的標簽才可響應,標簽向發送自己的ID,閱讀器直接對獲得成功時隙的標簽進行識別,即標簽組先來先服務,同時閱讀器發送Sleep( )指令,被正確識別的標簽變成靜默狀態,不以節省時隙開銷.
②閱讀器檢查當前幀是否結束
A 否,進入當前幀下一時隙,繼續識別最早時序標簽
B 是,檢查最早時序標簽組內是否有未識別的標簽,若有,則header指針不變,跳到Step 3,開始下一幀,再次進行時隙分配,直到將該時序組的標簽被識別完;若無,header= (head+1)%16,標簽組計算變量 i=i+1.
Step 5 判斷i值,若i≤g,則說明存在沒有被識別的標簽分組,下一組變為最早時序組,轉到Step 3,開始新的幀,進入下一組標簽的識別過程;若i>g,則所有標簽分組都被識別完,算法運行結束.
3 算法分析與仿真比較
本文提出的TG-FCFS ADFSA算法,最大為幀長256,標簽僅需8位二進制數電路,所需存儲空間為8bit,與EPC C1G2協議[12]需要20位隨機二進制數產生電路要簡單的多,所以TG-FCFS ADFSA算法得標簽電路更為簡單,減少了標簽制造成本.同時為了驗證TG-FCFS ADFSA算法的有效性,將本文提出的算法與DFSA及其改進GDFSA算法進行比較分析,仿真實驗環境為Windows7,4G DDR4,i5-7500 CPU,仿真軟件MATLAB 2016b.假設標簽空間分布相對平均,待識別的標簽數初值為20,結合實際情況,上限不超過1 600,為了更準確的分析與驗證,在同等環境下仿真結果取100次實驗的均值,對比三者標簽的吞吐率、時隙開銷及識別率情況.
3.1 標簽的吞吐率比較
在MATALAB上對DFSA,GDFSA和TG-FCFS ADFSA 這3種算法進行仿真,得到的吞吐率曲線如圖3.
TG-FCFS ADFSA算法采用了標簽的預估算法Vogt、標簽分組及先來先服務策略、動態幀調整策略、幀時隙自適應算法等,克服了DFSA算法在標簽數快速增多吞吐率急速下降的劣勢,同時相比GDFSA算法,TG-FCFS ADFSA算法在吞吐率、穩定性方面仍具有很大的優勢.在標簽數不多于355時,算法吞吐率曲線基本相同,當標簽數n≥356,DFSA算法的吞吐率持續下降,當標簽數n =1 600時,吞吐率下降到0.1以下,吞吐率極低;GDFSA算法先對對標簽分組,吞吐率可穩定36%左右,但基于標簽分組先來先服務動態幀時隙自適應算法,吞吐率可達到0.6左右,其性能曲線明顯最優,當標簽數n>1 000以上時,相比DFSA和GDFSA算法,TG-FCFS ADFSA算法效率分別提高約200%和99%,當標簽數量更多是,算法效率會更高.
3.2 時隙消耗總數分析
在標簽識別過程中,RFID系統消耗的時隙總消耗數愈少系統性能愈優秀.通過仿真實驗,3種算法所消耗的時隙總數如圖4所示,可以看出當標簽數增到1 000以后,DFSA算法指數增長,GDFSA和TG-FCFS ADFSA算法線性增長,但TG-FCFS ADFSA算法增長最慢,可見TG-FCFS ADFSA算法的優勢明顯,TG-FCFS ADFSA算法的效率遠遠高于DFSA 算法和 GDFSA 算法.
3.3 標簽的丟失率與識別率
通過仿真實驗,比較在不同標簽密度情況下,3種算法標簽的丟失率如圖5所示,從中可以看出相同密度的情況下,TG-FCFS ADFSA算法的標簽丟失率顯然比其他2種算法要低許多,相應的,TG-FCFS ADFSA算法標簽的吞吐率和識別率就為最高,可以看出,TG-FCFS ADFSA算法大幅度減少標簽碰撞的概率,該算法比DFSA和GDFSA算法識別率更高,可提高RFID識別系統的性能.
4 結論
本文提出一種基于標簽分組先來先服務的RFID電子標簽防碰撞算法,該算法首先對標簽數量進行預估,其次當標簽數大于355時對標簽分組并序化操作,然后采用標簽分組先來先服務及自適應分配幀時隙的策略,對標簽進行快速識別.通過仿真實驗表明隨電子標簽數量的快速增加,尤其是數量大于1 000時,系統的時隙開銷與其他算法相比較少,但標簽吞吐率仍保持在較高水平且穩定性較好,有效地提高了電子標簽的總的識別效率,而且通過上文的分析可知標簽電路復雜度又低,可降低標簽的生產成本,因此本文算法具有較好的應用前景.
參考文獻
[1]趙嘉,曾文波.一種用于智能交通系統標簽天線的設計與仿真[J].廣西工學院學報,2010 ,21(1):73-76,89.
[2]何維,張彥會,粟騰超,等.基于GPS/GPRS/RFID物流車載終端的設計[J]. 廣西科技大學學報,2014,25(4):59-62.
[3]QIAN Z H,WANG X.An Overview of anti-collision protocols for Radio frequency identification devices[J].China Communications,2014,11(11):44-59.
[4]陳紅琳.RFID 系統防碰撞算法研究[J].計算機技術與發展,2016,26(10):108-112.
[5]YANG G H,MA J C,CUI L,et al. Study on the improved recession binary tree algorithm[J]. Advanced Materials Research, 2014. 1006-1007:1076-1079.
[6]WANG Y P, SHENG H, WANG X L,et al. Anti-collision algorithm analysis of a LOHA-based RFID[J]. Applied Mechanics and Materials,2013,273(1):745-749.
[7]YAN X Q,YIN Z P,XIONG Y L.A hybrid collision resolution protocol for passive RFID Tag Identification[J]. International Journal of Distributed Sensor Networks,2010,5(1):84-90.
[8]李曉武.移動RFID系統標簽識別技術的研究[D].成都:西南交通大學,2014.
[9]單劍鋒,陳 明,謝建兵.基于ALOHA算法的RFID防碰撞技術研究[J]. 南京郵電大學學報(自然科學版),2013,33(1):56-61.
[10]陳榮征.改進的基于動態幀時隙 ALOHA 防碰撞算法[J].齊齊哈爾大學學報(自然科學版),2016,32(1):21-25,35.
[11]LI X W,WANG Z J,REN X,et al. A improved frame slotted aloha protocol with early end in mobile RFID systems[J].Sensors & Transducers,2013(7):82-86.
[12]王勇,李婷. 改進的基于 ALOHA 的 RFID 防碰撞算法[J].電信科學,2016,32(8):77-81.
Abstract:Based on the comprehensive analysis of various tag frame slotted Aloha tag anti-collision algorithms, the TG-FCFS ADFSA anti-collision algorithm is presented to solve the problem of collision between multi-tag and improve the efficiency in RFID system. The algorithm can quickly identify the tags by adaptively allocating the successful slots, which greatly improves the performance of the RFID system through the strategy of the tag groups FCFS (First Come First Service) and the reserved frame slots. Matlab simulation results show the identification advantage of the algorithm is obvious in the case of more tags, especially when the number of tags is over 1000, throughput of the algorithm is over doubled than the DSFA or GDFSA algorithm, but the slot consumption is reduced by more than 50%, the identification efficiency and stability of system are obviously improved.
Key words: RFID (radio frequency identification); anti-collision; frame slots; serialization of tag group
(學科編輯:張玉鳳)
