基于AHP的全文搜索算法優化
2018-05-02 06:30:18李臣龍竇易文
赤峰學院學報·自然科學版 2018年4期
李臣龍,陶 皖,竇易文
(安徽工程大學 計算機與信息學院,安徽 蕪湖 241000)
0 引言
隨著互聯網+時代到來,信息的高速增長,人們對信息獲取的要求越來越高.傳統的搜索引擎提供的搜索服務往往是基于廣度的,對個個行業領域的專業性搜索傳統的搜索引擎很難直接有效地滿足用戶需求.另外由于各部門對信息的保密性的個性化等要求,對于局域網內部資料的搜索,傳統搜索引擎的信息抓取也往往被禁止,因此企事業單位的內部信息資源搜索系統的設計,對于優化內部信息資源檢索顯得尤為重要.其主要應用是面向特定領域定向采集信息,對這些信息進行加工后再以用戶需要的形式快速地返回給用戶.
針對上述需求,本文設計并開發了針對企事業單位局域網的桌面搜索引擎.系統采用一款高性能的、可擴展的信息檢索(IR)工具庫Lucene[1],實現了對常見文本格式(word/pdf/txt)的分析轉換、索引查找和排序功能.通過分析Lucene默認文檔相似度排序算法存在的問題,重點優化了二次檢索排序算法,并通過SSH框架實現用戶管理、文檔索引管理和文檔搜索.
1 基于Lucene全文搜索引擎系統架構
基于Lucene全文搜索系統可架構在單機或分布式系統中,服務器端分為文件服務器、搜索服務器,本系統依據服務器性能,把搜索服務和文件服務架構在同一服務器,局域網客戶端可以通過SSH框架分權限實現對文檔索引存儲和搜索服務.其中索引服務根據用戶上傳文檔的實時動態,監控索引文檔路徑,定時抓取實現文檔的索引存儲,如圖1所示.

圖1 全文搜索引擎系統架構
系統采用Lucene實現文檔的索引存儲及搜索功能.Lucene是一套用于全文檢索和搜尋的開源程式庫,由Apache軟件基金會支持和提供.Lucene提供了一個簡單卻強大的應用程式接口,能夠做全文索引和搜尋.因此Lucene在近年來已經成為最受歡迎的開源信息檢索工具庫[2].Lucene主要的源碼子包和功能如表1所示.
Lucene實現檢索的過程如圖1,整個檢索系統可以分為信息的索引存儲、信息檢索兩大模塊.實現信息的索引存儲,首先檢索系統通過第三方工具包對原始文檔(word、pdf)轉換構造為 Document對象,然后通過org.apache.lucene.analysis包對Document語言分析與分詞,再次,org.apache.lucene.index包對所有文檔分析得出的語匯單元創建索引,最后通過org.apache.lucene.store實現存儲.信息檢索模塊的流程主要是,用戶輸入檢索表達式,org.apache.lucene.analysis實現語法分析與分詞;org.apache.lucene.Se-arch實現信息搜索;org.apache.lucene.Similarity完成檢索結果排序算法[3].Lucene檢索流程如圖2所示.

表1 Lucene開發子包功能

圖2 檢索流程圖
3 Lucene的檢索模型與文檔排序算法
使用Lucene框架能夠高效構建全文檢索系統,但在檢索文檔相似度的算法方面存在不足.Lucene的相似度算法采用向量空間模型.lucene的相似度計算公式如公式1所示,
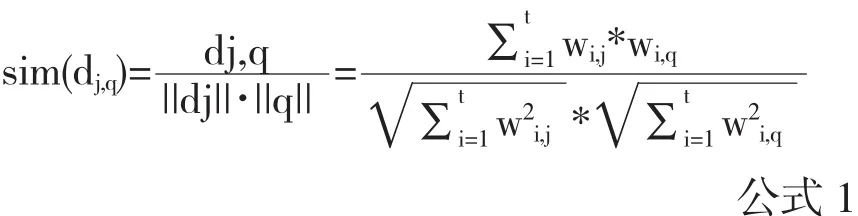
其中dj和q分別是文檔j和查詢矢量,Lucene相似度得分的核心是比較所有文檔集中每篇文檔矢量與查詢矢量相關度,依據文檔的相似度得分排序搜索結果集.對于文檔得分的實際計算公式如公式2[4][5]所示.
在中小型企事業單位,由于網絡信息資源的復雜性,對文檔的搜索排序要求,除了考慮Lucene文檔自身得分因素,還需要考慮以下因素:
1.搜索文檔的下載量與最后更新時間
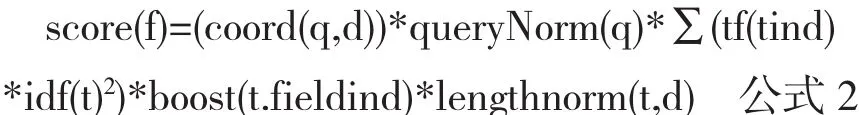
公式2中主要的參數因子含義如下[7]:q表示一個用戶查詢,通過分詞處理建立q矢量;f表示文檔,通過分詞索引建立文檔矢量;矢量由若干t詞項組成.
tf(t in d)表示詞項t在文檔d中出現的頻率數值,一般頻率高重要性大,但也存在詞頻過高的情況,如果詞頻過高則可能該詞普遍性強,則通過idf(t)(invert document frequency)即與文檔頻數成反比的值來降低該詞在文檔集中的重要性.boost指的是在對文檔建立索引時,賦予文檔的激勵因子.lengthNorm:長度歸一化(Length norm):基于域的一個歸一化因子.其值由給定域中Term的個數決定(在索引文檔的時候已經計算出來了,并且存儲到了索引中).域越的文本越長,因子的權重越低.這表明Lucene打分公式偏向于域包含Term少的文檔.
基于lucene的排序算法的特點是,文檔與查詢的相似度主要取決于詞頻重要性,與查詢q中的詞在文檔中出現的位置無關,如果一個文檔d中所包含的查詢q中的詞項越多,那么文檔d的排序得分就越高,反之得分越低,所以Lucene得分的主要缺點是僅僅考慮了文檔索引詞項的詞頻重要性,忽視了詞項的位置特征、語義特征以及網絡鏈接操作的重要性,不能體現專業個性化[6].
4 Lucene文檔排序算法優化
4.1 文檔排序算法得分因子
文檔的下載次數體現了文檔的查看和使用度,在全文搜索中,它的權值比查看率更為重要;另外,文檔的修改時間體現的是文檔的最新執行,往往對文檔質量有很大影響,所以結合兩種因素,采用Download-throughRank(DTR)算法,來提升文檔更新時間和下載數量對搜索結果的影響.Download-throughRank(DTR)算法公式 3:

其中f為檢索文檔,DTR(f)為文檔f的重要性得分,T(f)表示文檔f被檢索到的周期次數,1/T(f)越小說明文檔最新檢索;C(f)表示文檔上一周期檢索下載量;C(f)MAX表示上一周期文檔集中檢索下載最大量值.公式3較好的解決了下載量與更新時間的矛盾.
2.搜索文檔標題字段搜索詞的加權
一般情況下,文檔的標題是針對文檔具體內容的精準概括,文檔的詳細內容與標題必然相關,所以搜索詞在標題當中,應該比在文檔內容當中出現更為重要.
3.搜索文檔的查看率
搜索文檔的查看次數往往反應文檔的關注度和重要性,在搜索排序時應該考慮適當加權.
4.2 優化的排序算法
結合Lucene原有的向量相似度排序算法,修改后的文檔得分排序公式如公式4所示:
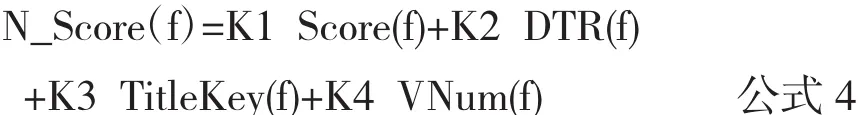
其中N_Score(f)為文檔f最終文檔排序得分,Score(f)為文檔f的Lucene向量空間算法得分,DTR(f)為文檔下載量和更新時間得分,TitleKey(f)為文檔f標題加權得分,VNum(f)為文檔f瀏覽量得分.K1,K2,K3,K4為每一項的權重系數.
2.基于AHP的權重系數設計
在多因素的綜合評估問題中,各個因素對評估目標的影響程度有大小之分,因此需要對不同因素賦予不同權重.層次分析法將定性與定量分析相結合,特別適應于系統中某些因素缺乏定量數據或者難以用完全定量分析方法處理的政策性較強或帶有個人偏好的決策問題[7].其基本思路是分析復雜問題所包含的因素及其相互關系,將問題分解為多個層次和多個要素,并在每一層次按照一定準則對該層元素進行比較,再按標度定量化形成判斷矩陣.通過計算判斷矩陣的最大特征值以及相對應的正交化特征向量,得出該元素對該準則的權重.本文采用AHP方法確定公式4中四個因子系數K1,K2,,K3,K4 的權重,具體步驟如下:
(1)分析系統各因素間的關系,建立遞階層次結構.如圖4.1
最高層設計成總目標的比重程度;準則層的準則分別設計為:Lucene向量空間算法得分Score(f),文檔下載量和更新時間得分DTR(f),文檔f標題摘要加權得分TitleKey(f),文檔f瀏覽量得分VNum(f).最低層為由4個準則而計算出來的的不同權重系數向量.

圖4.1 層次結構模型
(2)對同一層個元素關于上一層中某一準則重要性進行兩兩比較,構造判斷矩陣;根據表4.1的準則可以得到判斷矩陣A.

表4.1 倒數標度法

(3)由判斷矩陣計算被比較元素對于該準則的相對權重.方根法計算系數權重.第一,計算判斷矩陣每一行元素乘積
(4)一致性檢驗.一致性指標CI=(λmax-n)/(n-1)=0.0741.CI≤0.10所以判斷矩陣具有一致性.
5 測試環境及結果分析
本文實現的桌面搜索引擎系統,采用SSI(Struts2+Spring+ibatis)框架實現對用戶的登錄權限管理以及對搜索文檔的索引維護管理;數據庫采用mysql,主要實現用戶信息存儲以及文檔索引數據等信息存儲.檢索系統基于lucene版本為3.6開發工具包,實現索引以及檢索服務,文檔解析word采用POI,PDF采用Xpdf實現,中文分詞采用paoding,開發IDE為myeclipse10,開發java包為jdk1.6.檢索系統分為前臺一般、高級查詢;后臺功能主要包括索引初始化、pdf/word文檔索引.文檔以四篇包含 title、abstract、text、date、Download 等域進行索引查詢.
為了測試修改后的排序算法對搜索結果的影響,本文企業搜索系統中的pdf文檔為搜索集,在默認Lucene排序的前四篇文檔進行對比分析,如表5.1所示
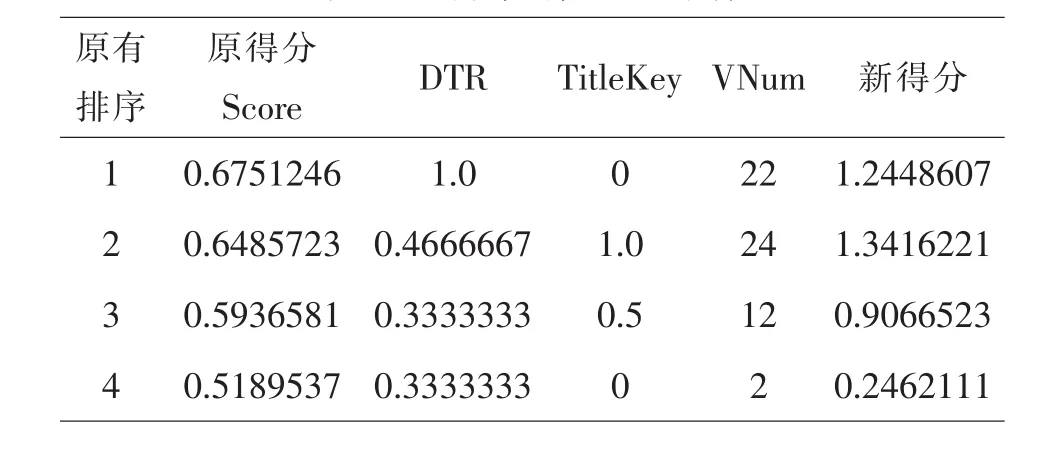
表5.1 排序得分主要指標
圖3中,score為Lucene vsm原排序算法得分,DTR(f)為用戶下載率評分,new_score為綜合得分.按照測試前文檔得分排序標記為f1/f2/f3/f4,加入用戶因子DTR(f)后new_score為綜合得分排序為f4/f2/f1/f3,其中對文檔設定的下載次數通過后臺數據庫修改,分別為 8、5、15、50;從圖 3 說明,改進后的算法對用戶下載量較大的文檔進行加權排名,排序結果因受到用戶點擊下載的影響提升了相關文檔的相似度,較以前有較大改善改進后的搜索結果.

圖3 兩種算法對搜索結果排序的對比
圖4為查詢反饋頁面,用戶搜索關鍵詞“搜索引擎”后,系統反饋的word文檔排序頁面,其中圖中文檔f4數據挖掘在只能搜索引擎中的應用由原來排名第4升為第1,排序達到了設計的預期目.

圖4 搜索排序結果
6 結論
本項目基于Lucene架構,結合第三方開發工具實現了對文檔的分詞、索引存儲與檢索功能,優化全文搜索引擎先建立磁盤文件索引再進行搜索的機制的同時,重點優化了結果排序算法,實現了基于B/S的全文搜索引擎系統,能滿足用戶對站內搜的個性化功能需求,對比測試表明,搜索系統比一般搜索引擎更具優勢.
參考文獻:
〔1〕葛帥.開放源代碼的全文檢索引擎Lucene[EB/OL].http://www.lucene.com.cn/abou.t htm_Toc43005313,2010-08-15.
〔2〕百度百科.Lucene[EB/OL].http://baike.baidu.com/view/371811.htm·fr=aladdin,2012-08-18.
〔3〕(美)MichaelMcCandless等.Lucene 實戰 (第二版)[M].北京:人民郵電出版社,2011.81-82.
〔4〕羅剛.解密搜索引擎技術實戰[M].北京:電子工業出版,2011.396-400.
〔5〕王知津.信息存儲與檢索[M].北京:機械工業出版社,2011.115-119.
〔6〕孫宏才,田平,王蓮芬.網絡層次分析法與決策科學[M].北京:國防工業出版社,2011,6-7.
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
中國衛生(2015年12期)2015-11-10 05:13:38
創業家(2015年5期)2015-02-27 07:53:25
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
