共詞分析識別研究熱點的內容效度研究:基于自然語言處理*
2018-05-05 02:05:12李承晉周文杰
圖書與情報 2018年1期
李承晉 高 沖 周文杰
(1.西北師范大學商學院 甘肅蘭州 730070)
1 研究背景
研究熱點的識別是科學計量及相關領域長期關注的重要問題之一,共詞分析則是研究者用來進行研究熱點識別的基本工具之一。迄今為止,國內外研究者基于共詞分析在不同領域展開了大量旨在識別研究熱點識別的研究(如陳靜等,陳蘭蘭)。 檢索發現,截至2017年9月26日,僅在CNKI數據庫中,已收錄在主題、題名或關鍵詞中同時含有 “共詞分析”與“研究熱點”的文獻879篇,且此類研究的數量呈逐年上升的態勢(見圖1)。
雖然共詞分析已被廣泛用于研究熱點的識別,但現有研究中,很少對基于共詞分析而識別的研究熱點及用以識別這些研究熱點的各類指標、算法在何種程度上具有有效性進行專門檢驗。顯然,要使基于共詞分析而識別的研究熱點得到各領域研究者的普遍認可,須先證明共詞分析在研究熱點測量方面的效度。著眼于這一研究現狀,本文擬應用自然語言處理的方法,對共詞分析所識別研究熱點的內容效度進行檢驗,以期回答如下兩個研究問題:(1)不同的分析單元在研究熱點識別方面的有效性有何異同?(2)在不同量的文獻參與分析的情況下,共詞分析的有效性有何異同?
2 理論背景與相關研究回顧
2.1 效度與內容效度
效度是指一項測試是否真正測量了它所要測量的東西。其中,內容效度用來檢驗測量的內容與測量的領域相匹配程度。換言之,內容效度主要用來衡量測量內容被測量指標涵蓋的程度。
根據現有測量理論,確認內容效度的標準主要有兩個:一是項目的代表性;二是方法的敏感性。檢驗項目代表性最直觀的指標是對項目抽樣效率。從統計的角度看,完全隨機抽樣無疑是樣本對總體具有最高效率,從而能夠保障樣本對總體的代表性。但是,由于總體的未知性,因此進行完全隨機抽樣在現實的科學計量中幾乎總是不可行的。為此,在科學計量中,為保障項目的代表性,只能遵循現有科學計量研究的基本規律和通行做法,以詞頻的高低作為樣本抽樣的基本衡量標準。方法的敏感性主要用來衡量所選項目在擬測量事項上的穩定性。敏感性越高,測量的方法越不穩定。由于共詞分析中的測量用以確定研究熱點的指標通常是各種中心度指標,因此,可以通過不同方法(項目)之間均值的比較對其敏感性做出判斷。
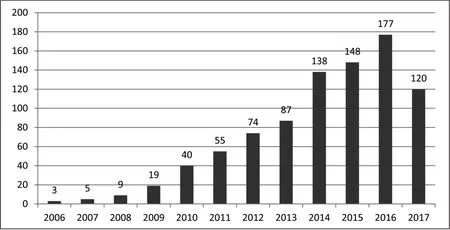
圖1 基于共詞分析而進行研究熱點識別的文獻量
總之,基于上述內容效度檢驗的相關理論,本研究對共詞分析內容效度檢驗基本思路是,選用多種統計方法對基于共詞分析而識別研究熱點的項目代表性和方法敏感性分別進行檢驗。具體而言,通過項目的代表分析,確認基于共詞分析而進行的研究熱點識別將待分析領域該有的熱點都識別出來了;通過方法的敏感性分析,確認所識別出來的熱點中排除掉了本領域的非熱點或非本領域的熱點的程度。
2.2 自然語言處理與研究熱點識別
自然語言處理 (Natural Language Processing,N LP)是一種以文本內容進行識別、分析對象的技術。由于研究熱點的識別在很大程度上依賴于對科學研究文獻的主題的提煉,因此,自然語言處理方法在研究熱點的識別方面具有極大的應用潛力。具體而言,在科學計量領域,通過應用自然語言處理技術,在對文本進行切詞、詞性識別、詞頻統計及詞與詞之間關系進行挖掘的基礎上,可有效實現對于研究主題、熱點及前沿等科學計量問題的提煉。
如前文所述,研究熱點的識別已經成為科學計量領域的研究者關注的焦點,而共詞分析已經成為研究熱點識別的通用工具。就分析樣本的選擇而言,科學計量領域普遍基于高被引文獻而進行研究熱點的識別。為此,本研究擬在特定學科領域選擇不同層次的高被引文獻,通過自然語言處理方法,提取這些文獻中的高頻詞,制成共詞矩陣,并計算所識別詞語的中心度。進而通過比較不同樣本與總體在所識別的熱點之間的相似度與相異度,對基于共詞分析識別研究熱點的內容效度進行檢驗。
3 研究設計
3.1 主要變量及其操作性定義
檢驗基于共詞分析而識別的研究熱點的內容效度是本研究的主要目標。達成這一研究目標的基本路徑在于,對共詞分析用以識別研究熱點的指標及樣本語料進行清晰地界定。本研究仍然沿用科學計量領域的通用做法,以共詞網絡作為識別研究熱點的基本工具,以不同詞語在共詞網絡中的中心度作為研究熱點的表征。同時,由于高被引文獻對于本領域研究問題具有更好的代表性,因此,本研究以不同層次的高被引文獻作為分析語料。
綜上所述,本研究主要涉及兩類核心變量:熱點研究問題和語料的數量。這兩類核心變量大體可被操作化定義如下:研究熱點指共詞網絡中基于單項或綜合中心度指標/算法而析出的高得分詞語所表征的研究問題。語料的數量指基于五種不同數量層級(包括前 5%、10%、15%、20%、25%等)的高被引文獻的題名、摘要、關鍵詞和全文而構建的語料。
3.2 分析流程
本研究的分析流程為:
第一,選定CNKI有“文獻分類目錄”下,對入選各學科的文獻進行探查,以確定一個文獻數量較適合總體分析,且與其他學科之間邊界清晰的領域為擬分析對象。最終發現“基礎科學”子目下“生物學”的二級子目“動物學”符合分析要求,從而選定其為擬分析的領域。
第二,針對“動物學”領域,下載了1988-2017年的全部文獻,形成了總體語料庫。
第三,針對總體語料庫,按不同的分析單元(題名、摘要、關鍵詞和全文)進行高頻詞的提取,并根據高頻共現情況制作了共詞矩陣。具體而言,針對題名、摘要和全文,應用Python作為自然語言處理的工具,首先進行了切詞,識別了詞性,提取了其中的高頻名詞,然后會同關鍵詞一起識別了這些詞的共現情況。
第四,基于總體語料庫,分別應用Pajek和Sci這兩款科學計量領域常用的分析工具,針對上述共詞矩陣進行了研究熱點的識別。具體而言,本研究對于研究熱點的識別在單項指標和綜合指標兩個層面上進行。就單項指標而言,本研究分別應用Pajek中常用的4項中心度指標/算法(包括點度中心度、權重中心度、緊密度中心度、中介中心度)和Sci中的4項算法(包括 authority_score_hits、Page_rank、authority_hits、eigen_centrality)計算了熱點詞的得分。在上述單項指標的基礎上,計算了每個單項的Z-分數并求和,形成了兩個軟件工具下識別研究熱點的綜合得分。
第五,仍然以1988-2017年“動物學”領域語料為檢索對象,按照這三十年間動物學領域所發表的學術論文被引次數進行排序,以500篇最高被引論文作為語料,下載了這些論文的題名、摘要、關鍵詞和全文,形成對比語料庫。
第六,依次針對對比語料庫中最高被引的前5%、10%、15%、20%、25%的文獻,仍然按照上述過程,建成了基于題名、摘要、關鍵詞的全文的共詞矩陣,分別計算了題名、摘要、關鍵詞和全文在總體語料與對比語料庫中前5%、10%、15%、20%、25%的高被引文獻上的相關系數,對研究問題做出回答。
4 研究結果與討論
4.1 高頻詞的析出
根據研究設計,本研究擬對題名、摘要、關鍵詞和全文四個分析單元在5%、10%、15%、20%、25%的高被引文獻上的研究熱點分別進行識別。抽取了不同比例高被引文獻時的語料篇數與這些文獻中析出的詞語數量 (見表1)。篩選前的詞語數量指針對題名、摘要和全文經過自然語言處理后,提取的總詞數(關鍵詞由于毋須分詞,因此,篩選前的關鍵詞是全部語料關鍵詞的累計)。針對篩選前的全部名詞,本研究根據齊普夫第二定律,按照周文杰的方法,以詞頻與詞序乘積的均值與0.1無顯著差異為標準,對高、低頻詞進行了分界,確定了篩選后的詞作為待分析的高頻詞。基于所析出的高頻詞,本研究進行制作了共詞矩陣,并展開了后續分析。
4.2 不同分析單元下內容效度的分析
為了對共詞分析識別研究熱點的內容效度做出全面檢驗,根據預先的研究設計,本研究應用了Pajek和Sci兩個科學計量工具進行研究熱點的識別。之所以同時使用兩個計量工具進行分析,一方面是由于本研究關注的是測量效度問題,因此,需要比較兩個工具在所識別研究熱點上的一致性;另一方面,則是由于這兩個工具采用的研究熱點識別代表著當前科學計量領域研究熱點識別的兩種不同風格——Pajek所采用的研究熱點識別指標更偏重于常規的網絡中心度指標,而Sci的識別則更偏重于研究者所識別的算法。因此,同時使用兩個工具進行計量分析,不僅有利于確定研究結論的可靠性,而且也有助于對不同風格的單項計量指標進行對比分析。
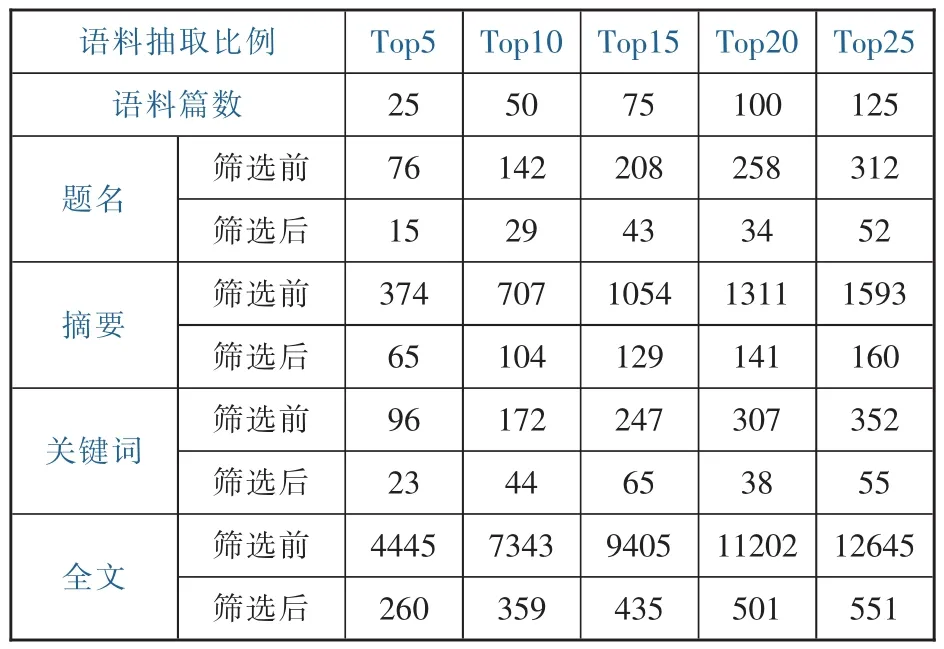
表1 不同數量語料析出的高頻詞
本研究對研究熱點識別的內容效度進行檢驗的基本思路是,基于不同分析單元抽取不同數量的高被引文獻進行研究熱點的識別,然后與基于總體語料而識別的研究熱點進行相關分析。根據內容效度的定義,相關系數越高,則內容效度也越高。
4.2.1 基于題名所識別的研究熱點的內容效度
本研究首先對題名在研究熱點識別中的內容效度進行了分析得出了綜合指標和單項指標上內容效度的分析結果(見表2),具體分析如下:
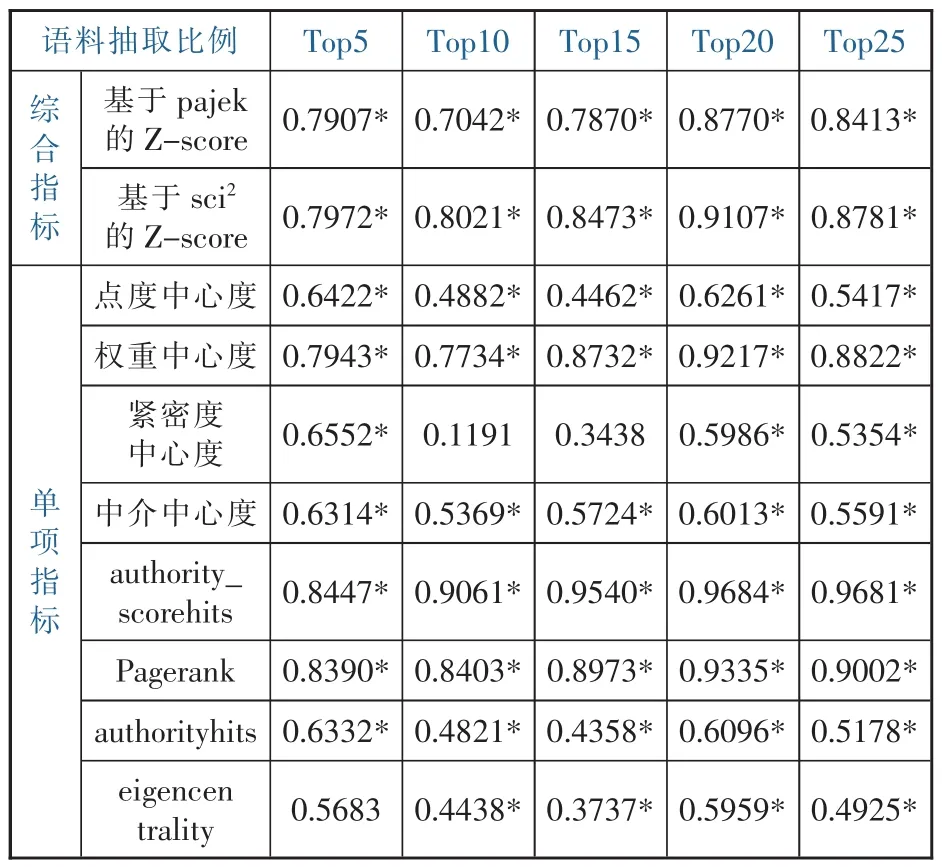
表2 不同數量語料中基于題名所識別研究熱點的內容效度
(1)就綜合指標而言,無論是在Pajek還是在Sci上,top 20的高被引文獻所識別的研究熱點與總體語料相關系數均最高。可見,當以題名為分析單元進行研究熱點的識別時,基于前20%的高被引文獻所識別的研究熱點的內容效度最高。當抽取的文獻量進一步擴大時,熱點識別的內容效度有所下降。
(2)就Pajek所使用的4個單項指標而言,點度中心度在對前5%的高被引文獻進行分析時,內容效度最高,但在不同數量的高被引文獻之間,內容效度略有波動但幅度不大。這表明,以點度中心度為標準識別研究熱點時,高被引文獻數量的選擇對內容效度影響有限。權重中心度指標同樣在不同數量的高被引文獻之間呈現出相對穩定的內容效度,但在前20%的高被引文獻上的內容效度最高。相對而言,緊密度中心度的內容效度呈現出高度的不穩定性。表現在,雖然前5%高被引文獻所識別的研究熱點與總體語料相比相關系數最高,但當語料數量擴大到前10%和15%時,發現其相關系數并不顯著。這表明,緊密度中心度并不是一個適用于單獨進行內容效度測量的理想指標。中介中心度指標內容效度相對穩定,在前5%高被引文獻上的內容效度最高。由此可見,中介中心度作為單一指標在進行研究熱點的識別中具有較高的應用價值。
(3)就Sci所使用的4個單項指標(算法)而言,authority_scorehits、Pagerank和eigencentrality均在前20%的高被引文獻上的內容效度最高,而且在不同數量的語料上也都具有比較顯著的相關系數。相對而言,authority_scorehits和Pagerank兩個算法的內容效度高于eigencentrality。這表明,authority_scorehits和Pagerank適宜于作為單項指標應用于研究熱點的識別。與此明顯不同的是,authorityhits算法在前5%的語料上內容效度最高,但在其他數量的語料上,也都具有一定的內容效度。可見,如果以研究熱點識別的效率來計,authorityhits算法具有一定的優先性。
4.2.2 基于摘要而識別的研究熱點的內容效度
以摘要為分析單位,在不同數量的高被引論文加入分析的情況下,得出所識別的研究與基于總體語料而識別的研究熱點之間的相關系數(見表3)。
(1)就綜合指標而言,Pajek和Sci兩個工具具有較高的一致性,都表現為同樣的趨向:所選語料越多,所識別研究熱點的內容效度越高。同時,對兩個工具綜合指標的檢驗也表明,從前5%的高被引論文開始,摘要在認識研究熱點中就都具有內容效度,只是納入分析的摘要范圍越廣,研究效度就越高。
(2)就Pajek的單項指標來看,4項傳統中心度指標在研究熱點的識別方面都具有較穩定的內容效度。相對而言,權重中心度的內容效度最高,而中介中心度的內容效度較低。從使用的文獻量來看,點度中心度和權重中心度在前20%的高被引文獻上的內容效度最高,而緊密度中心度和中介中心度的內容效度隨著文獻量增加而有遞增的趨勢,在本研究的抽樣范圍內,這兩項指標在前25%的高被引文獻上內容效度最高。
(3)就Sci的單項指標來看,該工具所使用的4項算法具有不同的內容效度。其中,authority_score_hits和Page_rank兩種算法內容效度比較高,且在不同數量的語料上都較為穩定。Authorityhits算法在前15%以上的高被引文獻中的內容效度最高,但在前5%-10%的文獻上的內容效度偏低。eigencentrality算法呈現出來了與以上三種算法不同的特征。Eigencentrality算法在前5%的高被引文獻上與識別的研究熱點與基于總體語料而識別的研究熱點之間沒有顯著的相關關系,據此可以認為,在文獻只有5%的情況下,利用eigencentrality進行研究熱點識別是沒有內容效度的。隨著文獻量的增加,eigencentrality所識別的研究熱點的內容效度明顯增強,在20%的高被引文獻參與識別時,其內容效度達到最高。

表3 不同數量語料中基于摘要所識別研究熱點的內容效度
4.2.3 基于關鍵詞而識別的研究熱點的內容效度
通過關鍵詞進行研究熱點的識別是當前科學計量比較盛行的方法。然而,基于關鍵詞進行研究熱點的識別存在極大的內容效度風險。具體表現在如下兩個方面(見表4):
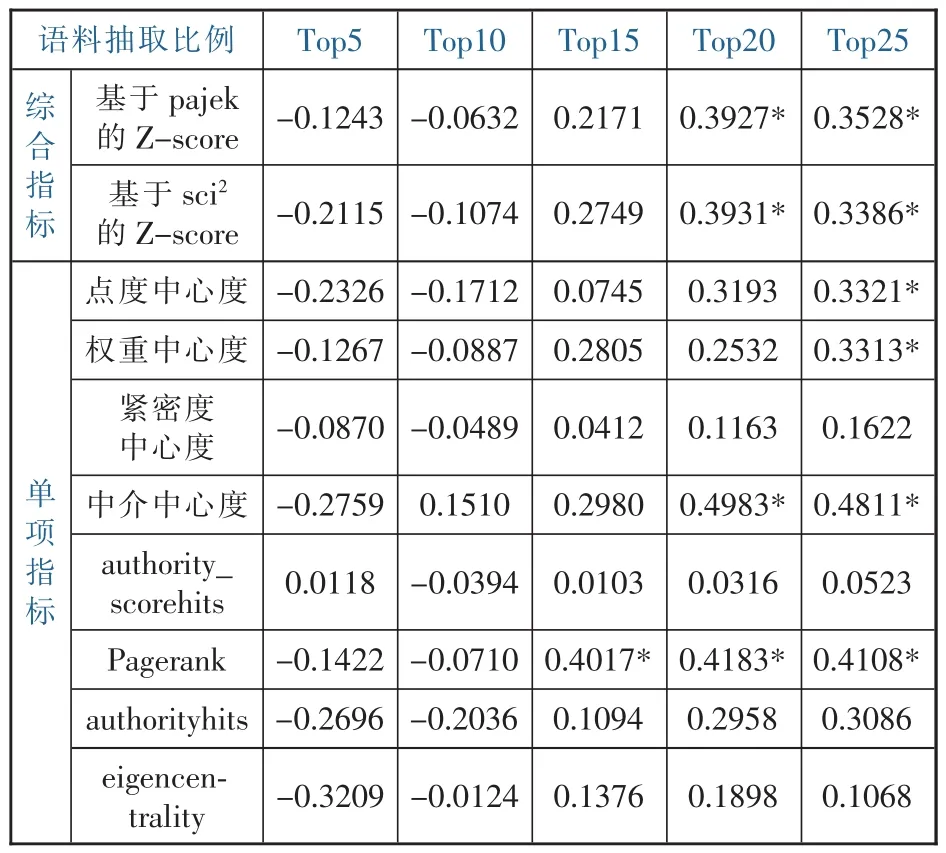
表4 不同數量語料中基于關鍵詞所識別研究熱點的內容效度
(1)整體而言,當以前15%的高被引文獻為分析對象時,所識別的研究熱點與基于總體語料而識別的研究問題之間的相關系數均不顯著,這表明,在高被引論文語料數量少于15%的情況下,兩個軟件的綜合得分和除Page_rank外的單項指標在研究熱點識別方面基本都沒有內容效度。就本研究所涉及的語料范圍來看,基于關鍵詞識別的研究熱點與實際研究熱點之間存在著相當大的差異,以關鍵詞為基礎進行研究熱點的識別在很大程度上是有偏差的。
(2)從Pajek和Sci兩個工具用來進行研究熱點識別的8個單項指標(算法)來看,基于關鍵詞進行研究熱點的識別同樣存在內容效度低的問題。在表4中,Pajek所使用的4項中心度指標上,多數情況下基于高被引文獻而識別的研究熱點與基于全文而識別的研究熱點之間并不存在顯著相關。只有在前25%的高被引文獻納入分析的情況下,點度中心度和權重中心度與在兩類語料上的相關系數是顯著的,而中介中心度在20%以上的高被引文獻納入分析時相關系數是顯著的。然后,即使這些相關系數具有統計意義上的顯著性,但值都比較小。由此可見,基于關鍵詞使用Pajek的各單項指標進行研究熱點的識別時,存在明顯的不足。進而比較分析Sci用以識別研究熱點四種算法可以看出,authority_scorehits、authorityhits和eigencentrality三種算法基本上完全沒有內容效度,只有Pagerank在前20%以上的高被引文獻納入分析時,才具有了較低的內容效度。
綜上所述,由本研究所獲取的數據來看,通過對高被引文獻的關鍵詞進行研究熱點的識別,存在著諸多效度問題。這一發現,無疑對現有科學計量領域大量基于關鍵詞而展開的熱點識別相關研究是一個警示。
4.2.4 基于全文而識別的研究熱點的內容效度
文獻調查發現,迄今為止科學計量領域的研究很少基于全文展開研究熱點識別。本文應用自然語言處理的方法,對全文進行分詞和詞性識別,并據此而構建了共詞矩陣進行研究熱點的識別,這正是本研究的特色之一。基于全文識別而識別的研究熱點具有較高的內容效度(見表5)。
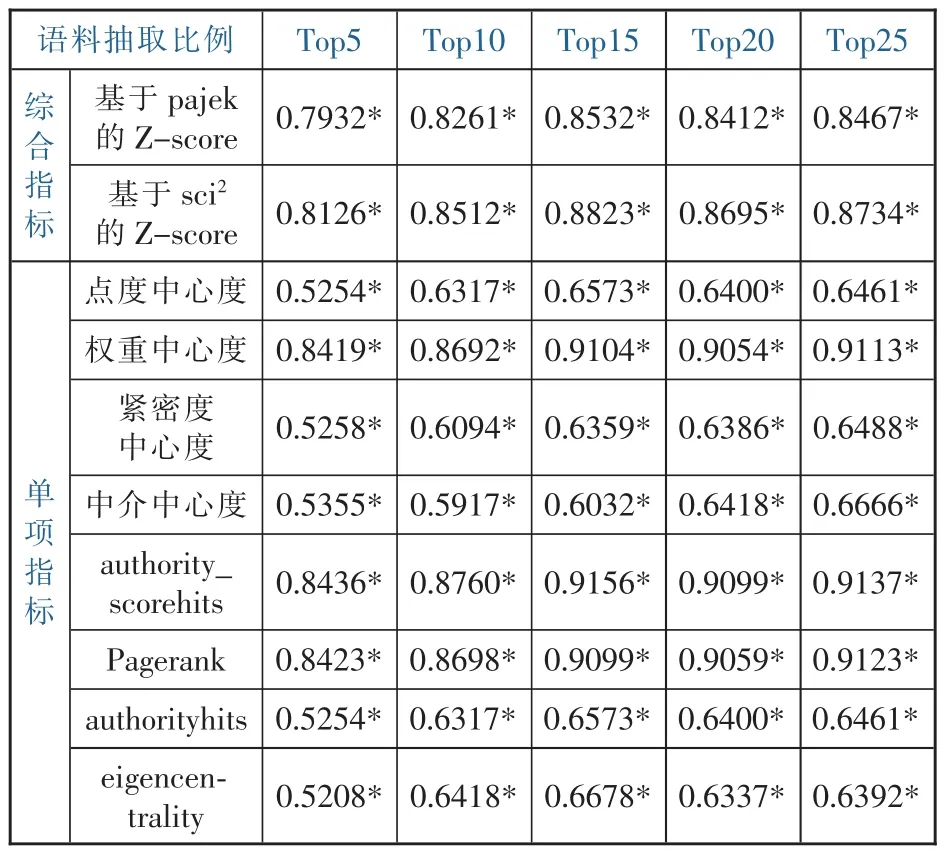
表5 不同數量語料中基于全文所識別研究熱點的內容效度
從綜合指標來看,在前15%的高被引文獻納入分析范圍時,在Pajek和Sci兩個工具上所識別的研究熱點內容效度都達到最高,且相關系數都在0.85以上。可見,綜合來看,以全文作為語料而進行研究熱點的識別具有明顯的優越性。
從單項指標來看,點度中心度、authority_score_hits和Pager_rank在研究熱點識別方面的效度都很高,在前15%的語料納入分析的情況下,兩類語料的相關系數已達到0.9以上。而對于其他幾項指標(算法)而言,其相關系數也都具有統計意義上的顯著性。由此可見,與綜合指標類似,以全文為對象應用單項指標進行研究熱點的識別同樣具有較高的內容效度。
4.3 不同分析單元內容效度的綜合比較
4.3.1 四種分析單元按內容效度高低排名
為更清晰地顯示在不同指標上內容效度的高低,本研究進行對四種分析單元上的相關系數進行了對比分析(括號中是相關系數):
從Pajek的綜合指標來看,內容效度的排名:題名(0.877)最高,全文(0.8532)和摘要(0.8446)次之,關鍵詞(0.3927)最低。
從Sci的綜合指標來看,內容效度的排名:題名(0.9107)最高,全文(0.8823)和摘要(0.872)次之,關鍵詞(0.3931)最低。
從點度中心度指標來看,內容效度的排名:全文(0.6573)最高,摘要(0.6555)和題名(0.6422),關鍵詞(0.3321)最低。
從權重中心度指標來看,內容效度的排名:題名(0.9217)最高,全文(0.9113)和摘要(0.8881)次之,關鍵詞(0.3313)最低。
從緊密度中心度指標來看,內容效度的排名:題名(0.6552)最高但在不同語料數量上表現不穩定,全文(0.6488)和摘要(0.6129)次之,關鍵詞(相關系數都不顯著)基本沒有內容效度。
從中介中心度指標來看,內容效度的排名:全文(0.666)最高,題名(0.6314)次之,關鍵詞(0.4983)再次之,摘要(0.3033)最低。
從authority_scorehits算法來看,內容效度的排名:題名(0.9684)最高,全文(0.9156)和摘要(0.9036)次之,關鍵詞(相關系數都不顯著)基本沒有內容效度。
從Page_rank算法來看,內容效度的排名:題名(0.9335)最高,全文(0.9123)和摘要(0.892)次之,關鍵詞(0.4183)最低。
從authorityhits算法來看,內容效度的排名:摘要(0.6466)最高,全文(0.6461)和題名(0.6332)次之,關鍵詞(相關系數都不顯著)基本沒有內容效度。
從eigencentrality算法來看,內容效度的排名:摘要(0.6729)最高,全文(0.6678)和題名(0.5959)次之,關鍵詞(相關系數都不顯著)基本沒有內容效度。
4.3.2四種分析單元按識別效率高低排名
本研究將前5%、10%、15%、20%、25%的高被引文獻分別納入分析。這一設計是基于兩方面的考慮:一方面,總體來看,文獻被引的量服從嚴重右偏的長尾分布。即高被引文獻占總體文獻量的少數但卻占總被引次數的多數。因此,在全部文獻中,真正具有引文分析意義的代表性文獻只能是一部分而不是全部;另一方面,在基于高被引文獻而識別研究熱點的過程中,在效度有保障的前提下,所使用的文獻量越少,則識別效率越高,這種識別的應用前景越廣泛。換言之,基于高被引文獻而識別研究熱點所遵循的一個基本原則是,應用少量最高被引文獻進行研究熱點的識別,從而實現效度的最大保障和效率的最大優化。基于此,本文進而對不同分析單元在研究熱點識別上的效率進行了比較分析 (括號中的最高相關系數時所包括的高被引文獻比例)。
從Pajek的綜合指標來看,識別效率的排名:全文(top15)最高,題名(top20)和關鍵詞(top20)次之,摘要(top25)最低。
從Sci的綜合指標來看,識別效率的排名:全文(top15)最高,題名(top20)和摘要(top25)次之,關鍵詞(top20)最低。
從點度中心度指標來看,識別效率的排名:題名(top5)最高,全文(top15)次之,摘要(top20)再次之,關鍵詞(top25)最低。
從權重中心度指標來看,識別效率的排名:題名(top20)和摘要(top20)較高,關鍵詞(top25)和全文(top25)較低。
從緊密度中心度指標來看,識別效率的排名:題名(top5)最高,摘要(top25)和全文(top25)次之,關鍵詞沒有檢驗出內容效度。
從中介中心度來看,識別效率的排名:題名(top5)最高,關鍵詞(top20)次之,摘要(top25)和全文(top25)最低。
從authority_score_hits算法來看,識別效率的排名:全文(top15)最高,題名(top20)次之,摘要(top25)再次之,關鍵詞沒有檢驗出內容效度。
從Page_rank算法來看,識別效率的排名:題名(top20)和關鍵詞(top20)較高,摘要(top25)和全文(top25)較低。
從authority_hits算法來看,識別效率的排名:題名(top5)最高,摘要(top20)次之,全文(top25)再次之,關鍵詞沒有檢驗出內容效度。
從eigen_centrality算法來看,識別效率的排名:全文(top15)最高,題名(top20)和摘要(top20)次之,關鍵詞沒有檢驗出內容效度。
5 結論
本研究對不同分析單元下基于共詞分析而識別的研究熱點的內容效度進行了全面檢驗,結論如下:
首先,關鍵詞在研究熱點識別中存在著很大的效度風險,具體表現在:從綜合指標來看,基于關鍵詞而識別的研究熱點內容效度最低;從單項指標來看,部分單項指標上關鍵詞沒有檢驗出內容效度。
其次,從綜合指標來看:基于題名而識別的研究熱點內容效度最高,基于全文、摘要而識別的研究熱點也具有較高的內容效度。從單項指標(算法)來看,基于題名和全文而識別的內容效度在多數指標上相對較高。
第三,從四種分析單元在研究熱點識別方面的效率來看:在綜合指標上,全文效率最高;在多數單項指標上題名效率最高。
本研究對于揭示認識共詞分析的有效性和科學性具有一定價值。本研究的發現,有望為科學計量及相關領域的研究者在計量指標的選擇、分析工具的設計和計量結果的評價等方面提供啟示。
參考文獻:
[1]陳靜,呂修富.基于 CSSCI(2000~2011)的我國統計學學科知識圖譜研究[J].圖書與情報,2014(2):94-101.
[2]陳蘭蘭.基于社會網絡分析和共詞分析的國內關聯數據研究[J].圖書與情報,2013(5):129-132.
[3]Weir C J.Language Testing and Validation:An Evidence-based Approach[M].New York:Palgrave Macmillan,2005:79.
[4]張洪秀.教育測量與評價方法[M].長春:吉林大學出版社,2014:59.
[5]Nunnally J C,Bernstein I.H.Psychometric Theory(Third edition)[M].New York:McGRAW-Hill.INC,1998:126.
[6]Pedhazur E J,Schmelkin L P.Measurement,design,and analysis:An integrated approach[M].Psychology Press,2013.
[7]胡昌平,陳果.科技論文關鍵詞特征及其對共詞分析的影響[J].情報學報,2014,33(1):23-32.
[8]傅柱,王曰芬.共詞分析中術語收集階段的若干問題研究[J].情報學報,2016,35(7):704-713.
[9]李樹青,孫穎.基于加權關鍵詞共現時間元的個性化學術研究時序路徑發現及其可視化呈現方法[J].情報學報,2014,33(1):55-67.
[10]Ding Y,Rousseau R,Wolfram D.Measuring Scholarly Impact[M].Springer International Publishing Switzerland,2014:261.
[11]Small H U,Pham P.Citation Structure of an Emerging Research Area on the Verge of Application [J].Scientometrics,2009,79(2):365-375.
[12]Zhou W.Exploring the Constant of Zipf’s Law:Evidence fromAbstract
s of Bibliometric related Research Articles in LISTA[J].Geomatics and Information Science of Wuhan University,2012(37):100-106.猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
