基于深度學習的生物醫(yī)學英文文獻中中國學者的身份識別
2018-05-07 01:45:02
中華醫(yī)學圖書情報雜志 2018年11期
建立機構知識庫,收集整理科研成果,已成為很多單位科研部門近年來的一項重要工作。建立機構知識庫最關鍵、最難的環(huán)節(jié)是清洗機構科研成果數據,特別是清洗學者英文成果的數據最為繁瑣,其中相當一部分需要人工辨認。據中科院機構知識庫項目組統計,目前很多單位雖然建設了機構知識庫,但因數據清洗不徹底而導致數據無法使用,其原因就是中國學者發(fā)表英文文獻時,學者名稱著錄格式多樣、機構和科室的英文名稱書寫不規(guī)范。如我國著名的呼吸疾病專家鐘南山在SCI和PubMed數據庫中的科研成果,作者名稱標注有zhong nanshan、zhong nan-shan、zhong n-s、zhong NS、zhong N等形式,所在單位附屬第一醫(yī)院的英文寫法有:first hospital、1st hospital、hospital 1、First Affiliated Hospital等形式。著錄格式的多樣化造成自動化程度不高,大量成果需要人工清洗,而學者自行認領個人成果的模式因沒有行政命令和利益驅動導致無法進行,最終科研管理部門只能通過人工辨認學者成果,費人費時費力。
人工智能時代的到來,醫(yī)學數據、圖像、信號等各種形式的數據日益增多,醫(yī)療大數據的智能化處理變得越來越重要,其巨大的潛力引起了很多專家學者和高科技公司的關注[1]。深度學習是最近幾年人工智能領域發(fā)展起來的一項新技術,是一種基于大數據的新型機器學習方法,具有分布式、并行信息處理及智能計算的功能[2]。它通過調整內部大量節(jié)點之間相互連接的關系,達到處理信息的目的,并具備學習、自組織、泛化及訓練的能力。本文探索利用人工智能的深度學習技術,模擬人工辨認學者身份,進而解決英文文獻中中國學者身份的智能化識別問題。
1 探索識別學者身份的深度學習模型
深度學習技術主要有徑向基函數網絡(Radial Basis Function,RBF)、卷積神經網絡(Convolutional Neural Network,CNN)、循環(huán)神經網絡(Recurrent Neural Networks,RNN)等幾種類別[3]。徑向基函數網絡通常只有輸入層、中間層和輸出層3層,中間層計算輸入矢量與樣本矢量歐式距離的徑向基函數值,輸出層計算它們的線性組合。循環(huán)神經網絡的目的是用來處理序列數據,但處理速度比較慢。卷積神經網絡不但用于圖像識別,還可對自然語言處理,能夠有效地從原始輸入中學習到高階不變性的特征,廣泛應用于圖像識別、人臉檢測、語音識別和語義分析等領域。
1.1 卷積神經網絡
卷積神經網絡主要結構為一個多層的感知器,每層由多個二維平面組成,而每個平面由多個獨立神經元組成。網絡中包含一些簡單元和復雜元,分別記為C元和S元,C元聚合在一起構成卷積層。卷積層是卷積神經網絡的核心層,用它來進行特征提取。如圖1中輸入數據通過一組卷積核進行卷積運算,在C層產生N個特征圖,通常會使用多層卷積層來得到更深層次的特征圖S元聚合在一起構成池化層,實現對特征圖的壓縮。然后,特征圖通過激活函數( Logistic、Softmax等函數)得到S層的特征圖。根據設定的C層和S層的數量,以上過程依此循環(huán)。最終對最尾部的卷積層和輸出層進行全連接,然后將輸出值送給分類器[4]。
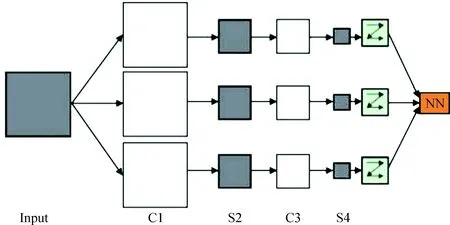
圖1 CNN原理示意圖
鑒于單一類型信息處理的身份識別效果很難達到理想的要求,而現實生活中人們在識別英文文獻的學者身份時,總是結合不同類別的學者特征信息如單位名稱、院系名稱、合作關系等,人腦是對多種特征信息綜合分析的基礎上進行最終的辨別確認。所以,筆者從融合多種特征信息的觀點出發(fā),提出了融合學者名稱、學者機構、學者院系/科室、合作關系等特征信息的身份識別神經網絡模型[5](圖2)。
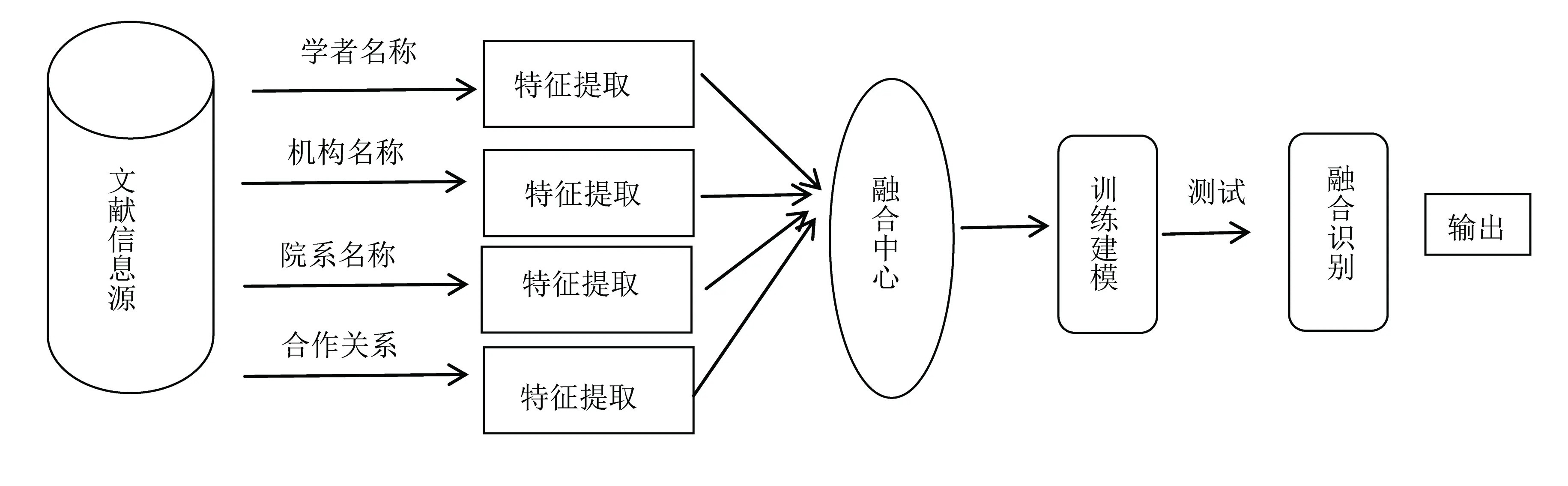
圖2 學者身份識別神經網絡模型
該模型的計算過程為:輸入初始數據給CNN的初始層,各層依次計算出輸出值;每一層的輸入值都是由上一層的輸出值乘以當前層的權值向量,取得加權數組成;應用非線性函數如修正線性單元(ReLU)或雙曲正切函數加權總數計算輸出層。
1.2 數據采集
利用北京唯博賽科技公司開發(fā)的網絡爬蟲軟件從Web of Science數據庫采集2000年以來國內6所知名醫(yī)學高校(首都醫(yī)科大學、哈爾濱醫(yī)科大學、南方醫(yī)科大學、南京醫(yī)科大學、北京協和醫(yī)學院、天津醫(yī)科大學)的數據共95 364條,采集到的SCIE數據的著錄字段包括標題、作者、地址信息、年代、期刊名、WOS號等。
1.3 方法與測試
當前主要解決多分類問題,本文選用Softmax函數作為分類函數。Softmax函數其實就是一個歸一化的指數函數,其定義如下:
通過Softmax函數,可以使P(i)的范圍在0~1。在回歸和分類問題中,通常θ是待求參數,通過尋找使得P(i)最大的θ作為最佳參數。
CNN中最重要的部分是“學習規(guī)則”,即類似人類大腦,需要很長時間來訓練模型,通過訓練過程調整網絡中運算單元間連接的權重,以期達到最理想的結果[6]。隨著CNN模型訓練次數的增加,根據輸出的結果不斷調整CNN的連接權重,使目標值與CNN輸出值的誤差逐漸減小直至為零,此時稱CNN已收斂,訓練完成。CNN的工作性能與樣本也有直接關系,若訓練集樣本數量少或太相似,則模型的工作能力將大大降低[7]。因此,樣本量越大,樣本差異性越強,則CNN模型的能力越強。而測試樣本選取值與訓練樣本值越相近,其輸出值與實際值的差異就越小,模型準確度也會增加[8]。
為避免樣本數據差異化對識別結果的影響,對這6所知名醫(yī)學高校從1到6進行標號,從每個高校的數據池中隨機挑選兩段為訓練樣本,每段選出5 000條數據,最終得到60 000條訓練集。其余35 364條數據為測試樣本,訓練數據與測試數據之間不重疊。
模型采用前期無監(jiān)督訓練和后期微調兩個階段。4個特征信息的原始權值可設置同等比例,輸出數據的閾值設置為0.8,若輸出數據的權值超過閾值即完全匹配,可判定為該學者的成果。閾值在0.5~0.8為高匹配度,閾值低于0.5為低匹配度。通過CNN的訓練優(yōu)化權值向量,從而獲得更加準確的輸出值。
CNN訓練結束后,還需要用另幾組與訓練集不同的樣本,測試其輸出是否與所要求的相近,從而驗證模型的推廣性[9]。通過對已有樣本的學習,將所提取樣本的非線性映射關系存儲在訓練的權重矩陣中,即使向模型輸入訓練時未曾見過的非樣本數據時,網絡也能完成由輸入層向輸出層的正確映射[10]。
從每個學校的測試數據結果中隨機選出1名學者進行查驗,將測試數據結果分別標記為完全匹配、高匹配度、低匹配度3種,并以人工確認該學者SCIE成果數為基數。每個學者以深度學習模型識別的準確成果總數與該學者全部SCIE成果數中的比值來算出準確率(表1)。
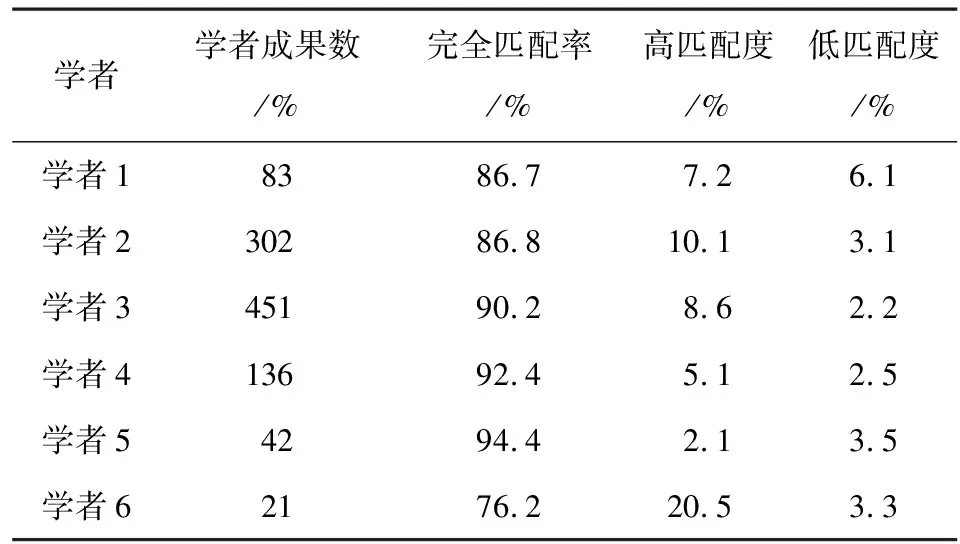
表1 CNN模型檢測匹配結果
1.4 與傳統檢索方法比較
本文的學者身份識別是典型的文獻檢索問題,利用標準的“學者全拼+學者機構”查詢學者的數據,以保證此數據絕對是該學者的。如在Web of Science數據庫中查詢學者,檢索式如下:AU=Zhong Nanshan SAME AD=Guangzhou medical univ,因學者名稱著錄格式多樣、機構和科室的英文名稱書寫不規(guī)范,查詢結果遠不及利用模型識別的數據全面,且傳統檢索方式必須需要人工設置檢索式進行查詢,耗時時間長。利用深度學習模型進行識別的方式不但精準度高,且節(jié)省了大量的人工工作量[11]。
2 深度神經網絡模型效果分析
使用訓練集樣本訓練網絡模型,當訓練次數到10次時,網絡代價函數收斂較佳。然后再用測試樣本集中的35 364條數據對網絡進行驗證,結果如表1所示。網絡有較高的可靠性識別出學者的身份(識別率為:86.7%、86.8%、90.2%、92.4%、94.4%和76.2%),且每條數據平均耗時約2秒。可見,利用深度學習模型解決生物醫(yī)學英文文獻的學者身份識別問題,不但識別效率與準確性較高,而且速度已經大大快于人工辨別,能滿足快速識別海量數據的要求。
從結果中還可以發(fā)現,相對于學者名是兩個字(如學者1、2),當學者名字為3個字時(如學者3、4、5)網絡識別的效果更好。利用訓練過的神經網絡模型對中國學者的英文文獻進行辨別的整體識別率達到85%以上,而且凡是模型識別的文獻均準確[12]。
但如果兩個學者名字是同音,而且又在同一院系,如李君如和李俊茹,他們的英文名稱均為li,junru或li,jr,通過以上模型無法進行區(qū)分辨別,只能進行人工辨認。而學者名字是兩個字的,同時只寫了名字的縮寫,如李軍,li,j,這種情況容易和li,js;li,jb;li,ja等名字的縮寫混淆,相對于名字是3個字的成果辨別度要低一些,如表1中的學者6。另外,學者發(fā)生遷徙后,學者的成果署名單位變更,成果識別度也會降低,這些問題有待進一步研究。
3 結語
綜上所述,通過學者多元特征建立的基于深度學習的神經網絡模型,對學者英文文獻中的身份能夠自動精準識別,可在很大程度上解決中國學者的英文文獻人工辨別的麻煩,大大提高了工作效率,對目前很多單位建立機構學者庫中存在的數據清洗難題具有很好的實際意義。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
鄱陽湖學刊(2016年6期)2017-01-16 13:05:41
中國遠程教育(2016年6期)2016-12-07 10:07:02
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年19期)2016-08-11 08:17:03
中國遠程教育(2016年5期)2016-06-29 10:13:42
中國遠程教育(2016年2期)2016-03-21 10:31:21
中國遠程教育(2016年1期)2016-02-26 10:37:15
