用于交通圖像識(shí)別的改進(jìn)尺度依賴池化模型
2018-05-21 00:59:41馮長(zhǎng)華
計(jì)算機(jī)應(yīng)用 2018年3期
徐 喆,馮長(zhǎng)華
(北京工業(yè)大學(xué) 信息學(xué)部,北京 100124)
0 引言
在智能交通系統(tǒng)中,車輛通過(guò)攝像頭等傳感器獲取自然場(chǎng)景下的交通標(biāo)志,用于車輛的輔助駕駛。智能交通標(biāo)志識(shí)別系統(tǒng)需要在較遠(yuǎn)距離下完成對(duì)交通標(biāo)志的檢測(cè)與識(shí)別,以盡早地規(guī)避風(fēng)險(xiǎn)、遵循提示,但是也導(dǎo)致獲取到的交通標(biāo)志尺寸較小、所含信息量不足,再加上背景復(fù)雜等原因,對(duì)交通標(biāo)志的檢測(cè)及識(shí)別帶來(lái)困難[1-3],所以需要對(duì)小尺度交通圖像作有效地處理,以提高檢測(cè)識(shí)別的準(zhǔn)確率。
在小尺度目標(biāo)體的識(shí)別領(lǐng)域中,傳統(tǒng)的方法有貝葉斯估計(jì)[4]、Top-Hat算子[5]等,這類方法應(yīng)用范圍廣,能有效地抑制噪聲干擾,增強(qiáng)圖像的對(duì)比度,但不能直接映射輸出小目標(biāo)體的特征信息。還有一些研究者通過(guò)最鄰近插值算法、雙線性插值法等[6-7]對(duì)圖像進(jìn)行放大處理,但是放大的圖像存在邊緣模糊、鋸齒效應(yīng)明顯、圖像失真嚴(yán)重等缺點(diǎn),導(dǎo)致最終的分類識(shí)別效果不佳。
近年來(lái),以卷積神經(jīng)網(wǎng)絡(luò)為代表的圖像處理技術(shù),在目標(biāo)識(shí)別、語(yǔ)義分割領(lǐng)域取得優(yōu)異的成績(jī),也成為智能交通領(lǐng)域研究的重點(diǎn)。卷積神經(jīng)網(wǎng)絡(luò)各層能對(duì)輸入圖像自適應(yīng)地提取所需特征,有效提高識(shí)別準(zhǔn)確率。基于此,許多學(xué)者探索有效的卷積層特征應(yīng)用于小尺度目標(biāo)的識(shí)別。Takeki等[8]將IMageNet[9]比賽中具有優(yōu)秀分類能力的深度學(xué)習(xí)模型直接應(yīng)用于小目標(biāo)體識(shí)別,但較深的網(wǎng)絡(luò)結(jié)構(gòu)在小目標(biāo)的處理中易因過(guò)多池化(Pooling)操作引發(fā)特征丟失問(wèn)題。Long等[10]提出層間特征融合的思想用于解決小尺寸目標(biāo)分割問(wèn)題,輸出結(jié)果對(duì)每一層進(jìn)行映射采樣易導(dǎo)致信息的過(guò)冗余,影響最終的分割效果。Yang等[11]提出尺度依賴池化(Scale Dependent Pooling, SDP)模型,實(shí)現(xiàn)了基于輸入圖片的尺度映射輸出不同卷積層的特征,對(duì)小尺度目標(biāo)體提取淺卷積層的特征。 這種對(duì)小尺度目標(biāo)體的處理方法,一定程度上避免了特征丟失問(wèn)題,較多地保留了圖像細(xì)節(jié),另一方面也不會(huì)造成輸出特征的過(guò)冗余,但是這種做法損失了深卷積層輪廓信息及類別特性。后續(xù)的學(xué)者在此方向上提出了改進(jìn)算法,Choi等[12]提出對(duì)各個(gè)卷積層使用級(jí)聯(lián)分類器,依據(jù)各卷積層的權(quán)重來(lái)決定最終的分類結(jié)果,雖然分類結(jié)果結(jié)合不同卷積層的特征的判定,但每一個(gè)分類器的提取特征都是單一特征。
將目前的小目標(biāo)識(shí)別算法應(yīng)用于小尺度交通圖像的識(shí)別中,應(yīng)根據(jù)交通圖像的特點(diǎn)有針對(duì)性地改進(jìn)。交通圖像用特定的字符向駕駛者傳達(dá)特定的信息,交通圖像有著顯著的輪廓信息及形狀特性[13-14]。Ruta等[15]通過(guò)提取方向梯度直方圖(Histogram of Oriented Gradients, HOG)特征獲得交通圖像的形狀信息,實(shí)現(xiàn)檢測(cè)識(shí)別。Zeiler等[16]通過(guò)可視化卷積神經(jīng)網(wǎng)絡(luò)各卷積層的特征,發(fā)現(xiàn)卷積神經(jīng)網(wǎng)絡(luò)隨著層數(shù)的加深,輪廓結(jié)構(gòu)的完整性及辨別性增強(qiáng)。如果SDP模型直接應(yīng)用于小尺度交通圖像的識(shí)別,會(huì)因直接提取淺卷積層的特征的做法損失交通圖像較好的輪廓特征。基于此,本文提出改進(jìn)尺度依賴池化模型應(yīng)用于小尺度交通圖像。首先,在原SDP的基礎(chǔ)上,提出了補(bǔ)充深卷積層特征信息的改進(jìn)SDP(Supplementary Deep convolution layer characteristic Scale-Dependent Pooling, SD-SDP);其次,為了補(bǔ)充小尺度交通圖像的邊緣信息,提出了多尺度滑窗池化(Multi-scale Sliding window Pooling, MSP)將融合后的特征處理到固定的維度;最后,將改進(jìn)的SDP模型應(yīng)用于交通標(biāo)志的識(shí)別。實(shí)驗(yàn)結(jié)果表明,本文算法在增強(qiáng)有效特征的基礎(chǔ)上,較好地提高了交通圖像的識(shí)別準(zhǔn)確率。
1 尺度依賴池化
尺度依賴池化方法通過(guò)輸入圖片的大小提取不同卷積層的特征。尤對(duì)小目標(biāo)的處理上,不再局限于按照卷積神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)提取最后一層特征,而是探索卷積神經(jīng)網(wǎng)絡(luò)的中間層,針對(duì)不同卷積層的特征,創(chuàng)建對(duì)應(yīng)分支,學(xué)習(xí)獨(dú)立的分類器。首先將圖像按照尺寸大小分到3個(gè)子區(qū)間中,劃分標(biāo)準(zhǔn)是[0,64)為小尺度圖像,[64,128)為中等尺度圖像,[128,+∞)為大尺度圖像;小尺度圖像選取卷積神經(jīng)網(wǎng)絡(luò)(Convolution Neural Network, CNN)的第3個(gè)卷積層的特征進(jìn)行Pooling處理(SDP_3),中等尺度圖像選取CNN的第4個(gè)卷積層的特征進(jìn)行Pooling處理(SDP_4),大尺度圖像選取 CNN的第5個(gè)卷積層的特征進(jìn)行Pooling處理(SDP_5);最后根據(jù)提取到的特征在conv3、conv4、conv5的每個(gè)獨(dú)立分支后,連接每個(gè)分支特有的全連接層及分類器。
2 改進(jìn)的尺度依賴池化
在對(duì)小尺度的交通標(biāo)志識(shí)別研究中,針對(duì)尺度依賴池化模型對(duì)小尺度的交通圖像只提取淺卷積層的底層特征,而忽略了較好的深卷積層的輪廓信息及辨識(shí)度較高的類別信息。為進(jìn)一步提高交通圖像的識(shí)別準(zhǔn)確率,本文改進(jìn)的尺度依賴池化模型過(guò)程如下:
步驟1 提取卷積神經(jīng)網(wǎng)絡(luò)的第3個(gè)卷積層的特征,并使用主成分分析(Principal Component Analysis, PCA)對(duì)特征進(jìn)行降維;
步驟2 提取卷積神經(jīng)網(wǎng)絡(luò)的第5個(gè)卷積層的特征,并與第3個(gè)卷積層的特征融合;
步驟3 使用MSP方法將融合后的特征池化固定的維度,完成特征的訓(xùn)練;
2.1 深卷積層特征補(bǔ)足型尺度依賴池化
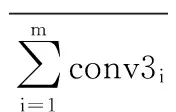
在對(duì)小尺度交通圖像的處理中,尺度依賴池化模型提取淺卷積層的特征的方式,在一定的程度上,能避免因卷積神經(jīng)網(wǎng)絡(luò)層數(shù)的加深導(dǎo)致的交通圖像特征丟失嚴(yán)重的問(wèn)題。然而文獻(xiàn)[16]通過(guò)對(duì)ImageNet上的1 000類物體作特征的可視化分析,使CNN的使用者逐漸清晰神經(jīng)網(wǎng)絡(luò)的每層提取特征的特點(diǎn),如淺層的顏色信息及深層的類別信息等。淺卷積層提取簡(jiǎn)單的顏色、邊緣等特征,存在特征信息對(duì)目標(biāo)物體理解不足的問(wèn)題,而通過(guò)增加卷積及Pooling的次數(shù),能逐漸提取復(fù)雜的輪廓結(jié)構(gòu)信息,且卷積神經(jīng)網(wǎng)絡(luò)的層數(shù)越深,信息的完整性及辨別性就較好。本文基于小目標(biāo)改進(jìn)的尺度依賴池化模型,結(jié)合不同卷積層的特征,使用豐富的特征信息實(shí)現(xiàn)交通圖像的分類識(shí)別。增強(qiáng)后的特征提取結(jié)果如下公式表示:
(1)
為了比較特征的增量,表1顯示不同尺度的交通圖像下,原尺度依賴池化模型與改進(jìn)的尺度依賴池化模型特征量的對(duì)比,關(guān)于特征總量的計(jì)算是基于本文使用的網(wǎng)絡(luò)結(jié)構(gòu)如表3所示,每層的特征量是由特征通道數(shù)與單層通道的特征量乘積的結(jié)果,結(jié)果發(fā)現(xiàn)改進(jìn)的SDP模型與原SDP相比特征總量有所增加,且通過(guò)映射深卷積層的信息,特征信息更加豐富,而關(guān)于增強(qiáng)后特征的有效性將在實(shí)驗(yàn)環(huán)節(jié)的準(zhǔn)確率的對(duì)比中展示。
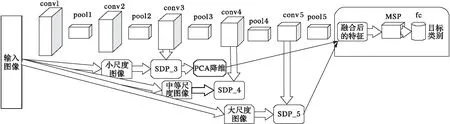
圖1 特征增強(qiáng)型尺度依賴池化模型的網(wǎng)絡(luò)結(jié)構(gòu) Fig. 1 Network structure diagram of modified feature-enhanced scale-dependent pooling model
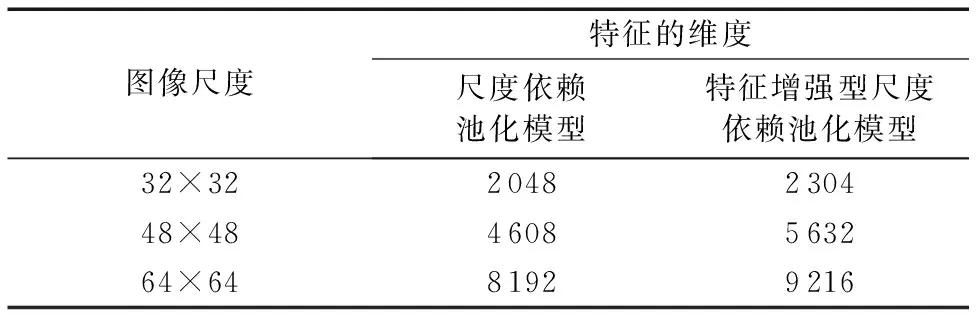
表1 不同算法下交通圖像特征量的對(duì)比Tab. 1 Comparison of traffic image feature quantities under different algorithms
2.2 多尺度滑窗池化
空間金字塔池化的提出是為了解決輸入圖片尺度多變性的問(wèn)題,通常用在網(wǎng)絡(luò)的倒數(shù)幾層,也就是我們即將與全連接層連接的時(shí)候,使用空間金字塔池化,使得任意大小的特征圖都能夠轉(zhuǎn)換成固定維度的特征向量 。將特征圖劃分成22*22個(gè)特征區(qū)域,然后利用三種不同大小的刻度(22×22,21×21,20×20),對(duì)特征區(qū)域進(jìn)行劃分,最后總共可以得到16+4+1=21個(gè)塊,使用最大池化方法求取每個(gè)區(qū)域的最大值,就可以得到固定的21維的向量。然而選擇固定的刻度將特征圖劃分為不重疊的塊區(qū)域,會(huì)損失圖像的邊緣信息,導(dǎo)致邊緣模糊,還易造成混疊效應(yīng),不利用整體輪廓信息的識(shí)別,在一定程度上,導(dǎo)致識(shí)別準(zhǔn)確率的下降。
本文提出了改進(jìn)的空間金字塔池化算法即MSP方法,用固定刻度對(duì)特征圖進(jìn)行劃分后,在劃分后的特征圖上使用多種尺度Pooling核進(jìn)行滑窗。如圖2所示,將特征圖劃分成4×4 的窗格區(qū)域,分別以Pooling 核大小為4×4,3×3,2×2,1×1,Pooling步長(zhǎng)為1,1,1,1 對(duì)劃分后的特征圖進(jìn)行滑窗池化操作,池化方法選擇最大值池化, 得到的對(duì)應(yīng)特征維度向量是分別是1,4,9,16,一共獲得30維的特征向量。MSP算法在用固定刻度劃分的特征圖上,使用多種尺度的Pooling核大小進(jìn)行池化操作,能夠有效適應(yīng)目標(biāo)物體的尺度多變性,靈活地提取目標(biāo)物體的邊緣信息,且有重疊的池化加強(qiáng)了邊界變量與相鄰區(qū)域的相關(guān)性,模糊了塊與塊之間的邊界,使得處在邊緣的像素點(diǎn)也能提供特征信息,有利于整體信息輪廓的提取及識(shí)別。因此在改進(jìn)的尺度依賴池化模型的基礎(chǔ)上,使用MSP方法,能夠進(jìn)一步補(bǔ)足小尺度交通圖像的特征。

圖2 多尺度滑窗池化的結(jié)構(gòu) Fig. 2 Network structure multi-scale sliding window pooling
3 實(shí)驗(yàn)
本文用原SDP模型以及改進(jìn)的SDP模型對(duì)交通標(biāo)志進(jìn)行識(shí)別,因?yàn)楦倪M(jìn)的SDP有補(bǔ)充深卷積信息的SDP(SD-SDP)及加入多尺度滑窗池化兩部分,因此,在原SDP模型基礎(chǔ)上分別加入SD-SDP及MSP作對(duì)比實(shí)驗(yàn),驗(yàn)證每一部分改進(jìn)的有效性,而后在相同的數(shù)據(jù)集上對(duì)網(wǎng)絡(luò)的準(zhǔn)確率及耗時(shí)作比較。因?yàn)榫W(wǎng)絡(luò)訓(xùn)練參數(shù)的隨機(jī)性,本文采取對(duì)每一類算法做10組實(shí)驗(yàn),并對(duì)實(shí)驗(yàn)結(jié)果求平均值, 且在每次實(shí)驗(yàn)時(shí),模型的卷積層共用一組相同的初始化參數(shù),以提高實(shí)驗(yàn)的穩(wěn)定性及增強(qiáng)說(shuō)服力。
實(shí)驗(yàn)中使用的交通標(biāo)志數(shù)據(jù)集是德國(guó)交通標(biāo)志識(shí)別數(shù)據(jù)集GTSRB,其中包含39 209張訓(xùn)練集和12 630張測(cè)試集,交通標(biāo)志的種類為43類,包含禁止、指示、警告等各類交通標(biāo)志,并且按照尺度依賴池化(SDP)模型的尺寸劃分準(zhǔn)測(cè),交通圖像的尺寸大小基本為小尺度圖片,圖3是數(shù)據(jù)集中的部分樣本。
SDP算法是基于模型VGG16[17]實(shí)現(xiàn)的,交通標(biāo)志識(shí)別任務(wù)并不像ImageNet數(shù)據(jù)集的分類那樣復(fù)雜,所以考慮在參考VGG16網(wǎng)絡(luò)架構(gòu)的基礎(chǔ)上減小網(wǎng)絡(luò)框架。本文所采用的網(wǎng)絡(luò)模型如表2,其中神經(jīng)網(wǎng)絡(luò)包含5個(gè)卷積,3個(gè)全連接,為了降低特征維度,每個(gè)卷積后都有相對(duì)應(yīng)的Pooling 層,但由于交通圖像多為小尺度圖像,卷積及Pooling的核及步長(zhǎng)也使用較小的值,第一個(gè)全連層的神經(jīng)元的個(gè)數(shù)分別是3 072,相比4 096有著更好的識(shí)別精度。激活函數(shù)采用了Relu函數(shù),避免反向傳播中的梯度消失問(wèn)題,能夠有效提高網(wǎng)絡(luò)訓(xùn)練的精度,因此卷積及Pooling的核大小及步長(zhǎng)也調(diào)整到一個(gè)較小值。為了驗(yàn)證網(wǎng)絡(luò)模型的有效性,將在接下來(lái)的實(shí)驗(yàn)中設(shè)計(jì)改進(jìn)的SDP算法在幾種不同模型下的準(zhǔn)確率及實(shí)時(shí)性的對(duì)比實(shí)驗(yàn)。為了使網(wǎng)絡(luò)具有更好的泛化能力。在網(wǎng)絡(luò)訓(xùn)練中我們使用AdaDelta[18]、Dropout[19]方法來(lái)盡量地抑制網(wǎng)絡(luò)過(guò)擬合問(wèn)題。

圖3 GTSRB交通標(biāo)志數(shù)據(jù)集中的部分樣本 Fig. 3 Part samples of GTSRB traffic sign dataset
表2對(duì)比了不同模型及不同方法在GTSRB數(shù)據(jù)集下準(zhǔn)確率及實(shí)時(shí)性,其中硬件平臺(tái)CPU:I7-6700,GPU:GTX-TITAN X,可以觀察到3種方法在不同模型下的比較結(jié)果。

表2 不同模型及不同方法在GTSRB數(shù)據(jù)集下準(zhǔn)確率及實(shí)時(shí)性的比較Tab. 2 Comparison of accuracy and real-time of different models and different methods in GTSRB dataset
SDP模型是基于模型VGG16實(shí)現(xiàn)的,交通標(biāo)志的識(shí)別任務(wù)不像ImageNet數(shù)據(jù)集的分類那樣復(fù)雜,所以考慮在參考VGG16網(wǎng)絡(luò)架構(gòu)的基礎(chǔ)上減小網(wǎng)絡(luò)架構(gòu)。本文所采用的網(wǎng)絡(luò)模型如表3,其中神經(jīng)網(wǎng)絡(luò)包含5個(gè)卷積。
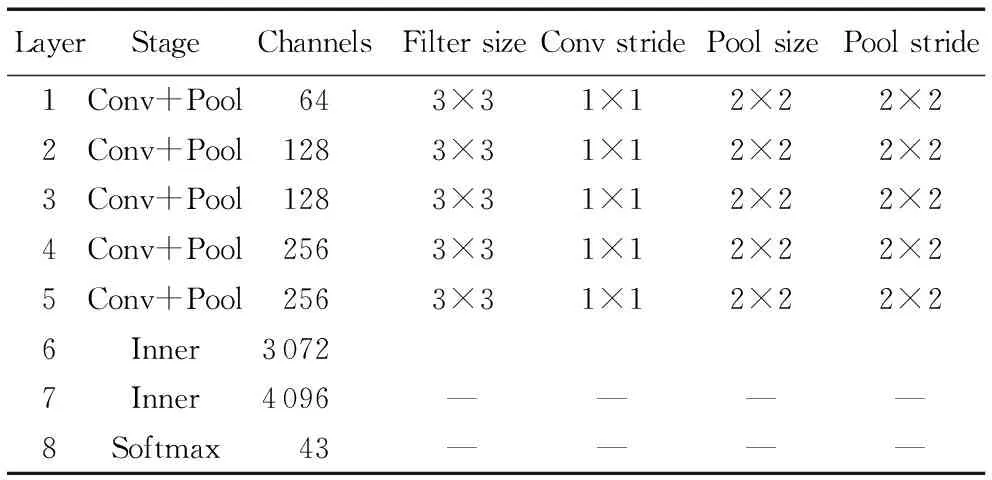
表3 本文使用的網(wǎng)絡(luò)模型說(shuō)明Tab. 3 Network model used in this article
一般來(lái)講網(wǎng)絡(luò)模型的加深會(huì)得到較好的分類識(shí)別結(jié)果,但針對(duì)不同的識(shí)別任務(wù),應(yīng)當(dāng)選擇合適的網(wǎng)絡(luò)模型,以實(shí)現(xiàn)準(zhǔn)確率及實(shí)時(shí)性的平衡。如交通標(biāo)志的識(shí)別任務(wù)中,本文使用的網(wǎng)絡(luò)模型與VGG16 相比,準(zhǔn)確率也有所下降,但實(shí)時(shí)性得到很好的提升。且通過(guò)改進(jìn)特征提取方式有效彌補(bǔ)了準(zhǔn)確率下降的缺點(diǎn),使用SD-SDP與原SDP相比,準(zhǔn)確率提升約3%,在SD-SDP中使用多尺度滑窗(MSP)又使準(zhǔn)確率得到了約1.2%,這種改進(jìn)通過(guò)提取對(duì)交通圖像分類較為重要的深卷積層的輪廓信息,增加了重要特征信息,使得交通圖像分類的準(zhǔn)確率得以提升。雖然改進(jìn)的SDP算法在VGG模型取得最好的分類效果,但綜合考慮實(shí)時(shí)性及準(zhǔn)確率的情況下,本文模型的結(jié)果相對(duì)而言,則更有可取性。
改進(jìn)的SDP模型也含有3個(gè)分支,分別對(duì)應(yīng)不同尺度輸入圖像的訓(xùn)練識(shí)別,GTSRB中的39 209張訓(xùn)練集,依據(jù)尺度大小,完成不同分支的參數(shù)訓(xùn)練。因改進(jìn)SDP模型主要改進(jìn)的是小尺度輸入圖像的特征提取方式,按照SDP的尺度劃分標(biāo)準(zhǔn),對(duì)小尺度交通圖像(尺寸為[0,64)及非小尺度的交通圖像的識(shí)別準(zhǔn)確率作了分別統(tǒng)計(jì)。表4對(duì)比了各種方法在不同尺度的交通圖像下分類準(zhǔn)確率的比較結(jié)果,可以看到小尺度交通圖像的準(zhǔn)確率得到有效提升,而非小尺度交通圖像準(zhǔn)確率不變,改進(jìn)的SD-SDP算法和原SDP算法相比,準(zhǔn)確率提升約3.8%,加入MSP方法的改進(jìn)SD-SDP模型,準(zhǔn)確率的提升在1.5%。另外當(dāng)驗(yàn)證集中部分樣本過(guò)小,可能使深卷積層的特征量過(guò)少。在此種情況下對(duì)融合后的特征向量模型的性能也做了獨(dú)立實(shí)驗(yàn),因此對(duì)GTSRB數(shù)據(jù)集中的寬和高度都小于等于32的這部分樣本進(jìn)行了實(shí)驗(yàn),這部分樣本的數(shù)量是399,在被劃分為小尺度交通圖像的10 140張圖片中,所占比例不大。 改進(jìn)的SDP相比原SDP算法中正確識(shí)別的正確率由79.7%提升至81.7%,因樣本尺寸偏小,所以識(shí)別準(zhǔn)確率整體偏低,通過(guò)改進(jìn)的SDP模型實(shí)驗(yàn),特征量融合對(duì)識(shí)別準(zhǔn)確率的提升也有限。而測(cè)試集總準(zhǔn)確率的計(jì)算是小尺度交通圖像及非小尺寸交通圖像占總樣本的比重與對(duì)應(yīng)的準(zhǔn)確率的相乘再相加的結(jié)果。在GTSRB的12 630張測(cè)試集中,其中的10 140張圖片都可按照SDP尺度劃分標(biāo)準(zhǔn)歸為小尺度圖像,小尺度在影響總準(zhǔn)確率時(shí)占較大的比重,因此基于小目標(biāo)改進(jìn)的SDP模型能較好地提升整體的準(zhǔn)確率。
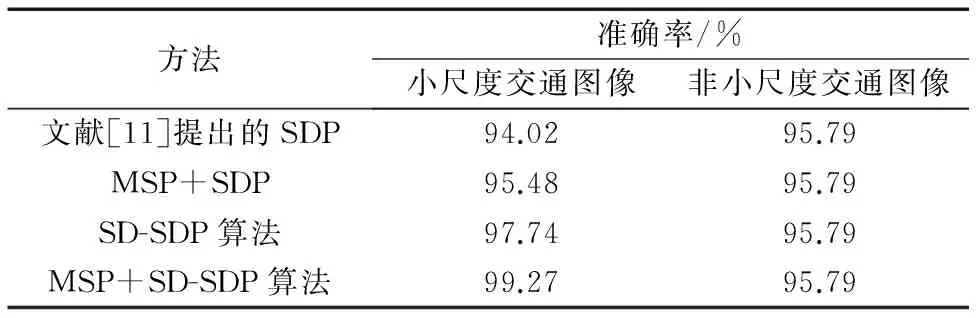
表4 各方法在不同尺度交通圖像下準(zhǔn)確率對(duì)比Tab. 4 Comparison of accuracies of different methods for traffic images with different scales
圖4是部分交通標(biāo)志樣本的輸出特征圖,可以觀察到,淺層的特征具有物體的簡(jiǎn)單邊緣信息,而隨著層數(shù)的加深,特征信息更加地抽象,非人眼可辨別的信息特征。文獻(xiàn)[16]在理解及可視化卷積神經(jīng)網(wǎng)絡(luò)過(guò)程中,通過(guò)對(duì)大量目標(biāo)體觀察神經(jīng)網(wǎng)絡(luò)每一層的輸出,分析了每一層提取特征的主要特點(diǎn),得出深卷積神經(jīng)網(wǎng)絡(luò)特征具有更好的類別信息及完整的輪廓特性點(diǎn)。這也是本文作改進(jìn)的原因。
為了客觀對(duì)本文算法進(jìn)行分析,將本文算法與其他交通標(biāo)志的識(shí)別算法進(jìn)行比較,有文獻(xiàn)[15]中使用HOG+SVM的交通標(biāo)志識(shí)別,以及目前在GTSRB數(shù)據(jù)集上取得最好結(jié)果的多列卷積神經(jīng)網(wǎng)絡(luò)[20],還對(duì)比了人類在交通標(biāo)志識(shí)別中的表現(xiàn)[21]。表5列舉了幾種不同方法在GTSRB數(shù)據(jù)集的識(shí)別準(zhǔn)確率與實(shí)時(shí)性的比較,可見(jiàn)相對(duì)于單一人工特征的識(shí)別分類,卷積神經(jīng)網(wǎng)絡(luò)自適應(yīng)特征有著更加優(yōu)異的表現(xiàn),尤其針對(duì)識(shí)別目標(biāo),設(shè)計(jì)一種優(yōu)秀的網(wǎng)絡(luò)模型,提取有效的特征層信息,其識(shí)別準(zhǔn)確率會(huì)大大提升。其中:文獻(xiàn)[20]使用的多列卷積神經(jīng)網(wǎng)絡(luò)是目前唯一超過(guò)人類表現(xiàn)的,但是也不可避免地因卷積神經(jīng)網(wǎng)絡(luò)的程度過(guò)于復(fù)雜,造成一張圖片的處理時(shí)間過(guò)長(zhǎng);文獻(xiàn)[22]提出一種去除神經(jīng)網(wǎng)絡(luò)冗余參數(shù)的網(wǎng)絡(luò)模型來(lái)提高交通圖像識(shí)別準(zhǔn)確率及實(shí)時(shí)性;文獻(xiàn)[23]提出二級(jí)級(jí)聯(lián)的神經(jīng)網(wǎng)絡(luò)進(jìn)行細(xì)微類別信息的提取,來(lái)提高分類的準(zhǔn)確率;文獻(xiàn)[24]提出多任務(wù)的卷積神經(jīng)網(wǎng)絡(luò)完成交通標(biāo)志感興趣區(qū)域(Region Of Interest, ROI)的提取及對(duì)提取的感興趣區(qū)域分類識(shí)別。而SDP作為一種探索不同卷積層的特征的小目標(biāo)識(shí)別算法,本文將其改進(jìn)應(yīng)用到小尺度交通圖像的識(shí)別中,雖然沒(méi)有人類的識(shí)別準(zhǔn)確率高,但前面的實(shí)驗(yàn)結(jié)果已經(jīng)證明,通過(guò)改進(jìn)的SD-SDP算法,有效完善了交通圖像的輪廓信息,提高了交通標(biāo)志的識(shí)別準(zhǔn)確率,本文算法在平衡實(shí)時(shí)性及準(zhǔn)確率方面,有一定的實(shí)用價(jià)值。

圖4 卷積網(wǎng)絡(luò)的各層可視特征圖 Fig. 4 Feature map of each layer of convolution network 表5 不同方法在GTSRB數(shù)據(jù)集識(shí)別結(jié)果對(duì)比 Tab. 5 Results comparison of different methods for traffic sign identification in GTSRB dataset

方法分類時(shí)間/ms準(zhǔn)確率/%文獻(xiàn)[15]的HOG+SVM算法17695.68MSP+SD-SDP+本文的網(wǎng)絡(luò)模型15298.57文獻(xiàn)[20]的算法45799.40文獻(xiàn)[21]的算法—98.84文獻(xiàn)[22]的算法21399.05文獻(xiàn)[23]的算法—97.94文獻(xiàn)[24]的算法27599.01
圖5是未被識(shí)別的交通標(biāo)志,交通標(biāo)志存在污損嚴(yán)重、運(yùn)動(dòng)模糊、過(guò)度曝光等因素,導(dǎo)致交通標(biāo)志的特征提取條件不利,因此不能正確識(shí)別交通標(biāo)志。

圖5 未被正確識(shí)別的交通標(biāo)志 Fig. 5 Not properly identified traffic signs
4 結(jié)語(yǔ)
將SDP模型直接應(yīng)用于小尺度交通圖像的識(shí)別,會(huì)損失較好的深卷積層輪廓信息及類別特性,而影響交通標(biāo)志識(shí)別的準(zhǔn)確率。本文提出的改進(jìn)SDP模型:首先,將深卷積層的特征與淺卷積層的特征進(jìn)行融合,增強(qiáng)特征的表達(dá)能力;其次使用MSP算法將融合后的特征向量池化到固定的維度,補(bǔ)充了識(shí)別目標(biāo)的邊緣信息;最后理論分析及實(shí)驗(yàn)證明,在特征量增加的基礎(chǔ)上,有效提高交通標(biāo)志的識(shí)別準(zhǔn)確率。但另一方面,小尺度交通圖像經(jīng)過(guò)需要更多的卷積及Pooling操作,導(dǎo)致耗時(shí)增加。接下來(lái)的研究,可以考慮在保證準(zhǔn)確率不下降的情況下,減少訓(xùn)練耗時(shí),使算法應(yīng)用于實(shí)時(shí)交通序列中。
參考文獻(xiàn)(References)
[1] YUAN X, HAO X, CHEN H, et al. Robust traffic sign recognition based on color global and local oriented edge magnitude patterns [J]. IEEE Transactions on Intelligent Transportation Systems, 2014, 15(4): 1466-1477.
[2] ZAKLOUTA F, STANCIULESCU B. Real-time traffic sign recognition in three stages [J]. Robotics and Autonomous Systems, 2014, 62(1): 16-24.
[3] SALTI S, PETRELLI A, TOMBARI F, et al. Traffic sign detection via interest region extraction [J]. Pattern Recognition, 2015, 48(4): 1039-1049.
[4] BRUNO M G S, MOURA J M F. Multiframe detector/tracker: optimal performance [J]. IEEE Transactions on Aerospace and Electronic Systems, 2001, 37(3): 925-945.
[5] HAN J, MA Y, ZHOU B, et al. A robust infrared small target detection algorithm based on human visual system[J]. IEEE Geoscience and Remote Sensing Letters, 2014, 11(12): 2168-2172.
[6] COLLATZ L. An image interpolation-based approach to the detection of small moving target [J]. Energy Procedia, 2011, 13(1): 2152-2157.
[7] 張阿珍,劉政林,鄒雪城,等.基于雙三次插值算法的圖像縮放引擎設(shè)計(jì)[J].微電子學(xué)與計(jì)算機(jī),2007,24(1):49-51.(ZHANG A Z, LIU Z L, ZOU X C, et al. Design of image scaling engine based bicubic interpolation algorithm [J]. Microelectronics and Computer, 2007, 24(1): 49-51.)
[8] TAKEKI A, TRINH T T, YOSHIHASHI R, et al. Combining deep features for object detection at various scales: finding small birds in landscape images[J]. IPSJ Transactions on Computer Vision and Applications, 2016, 8(1): 5-13.
[9] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2009: 248-255.
[10] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 3431-3440.
[11] YANG F, CHOI W, LIN Y. Exploit all the layers: fast and accurate CNN object detector with scale dependent pooling and cascaded rejection classifiers [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 2129-2137.
[12] CHOI W, YANG F, LIN Y. Cascaded neural network with scale dependent pooling for object detection: U.S. Patent Application 15/343,017[P]. 2016- 11- 03.
[13] HUANG Z, YU Y, GU J, et al. An efficient method for traffic sign recognition based on extreme learning machine[J]. IEEE Transactions on Cybernetics, 2017, 47(4): 920-933.
[14] LIU H, LIU Y, SUN F. Traffic sign recognition using group sparse coding [J]. Information Sciences, 2014, 266(10): 75-89.
[15] RUTA A, LI Y, LIU X. Real-time traffic sign recognition from video by class-specific discriminative features [J]. Pattern Recognition, 2010, 43(1): 416-430.
[16] ZEILER M D, FERGUS R. Visualizing and understanding convolutional networks [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8689. Berlin: Springer, 2014: 818-833.
[17] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [J]. Computer Science, 2014, 9(4): 1409-1556.
[18] ZEILER M D. ADADELTA: an adaptive learning rate method [J]. Computer Science, 2012, 11(2): 1212-1221.
[19] SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting [J]. The Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[20] CIRESAN D, MEIER U, MASCI J, et al. Multi-column deep neural network for traffic sign classification [J]. Neural Networks, 2012, 32: 333-338.
[21] STALLKAMP J, SCHLIPSING M, SALMEN J, et al. Man vs. computer: benchmarking machine learning algorithms for traffic sign recognition [J]. Neural Networks, 2012, 32: 323-332.
[22] AGHDAM H H, HERAVI E J, PUIG D. Toward an optimal convolutional neural network for traffic sign recognition [C]// Proceedings of the 8th International Conference on Machine Vision. Bellingham, WA: SPIE, 2015, 9875: 98750K.
[23] XIE K, GE S, YE Q, et al. Traffic sign recognition based on attribute-refinement cascaded convolutional neural networks [C]// Proceedings of the 17th Pacific-Rim Conference on Multimedia, LNCS 9916. Berlin: Springer, 2016: 201-210.
[24] LUO H, YANG Y, TONG B, et al. Traffic sign recognition using a multi-task convolutional neural network [J]. IEEE Transactions on Intelligent Transportation Systems, 2017, PP(99): 1-12.
XUZhe, born in 1968, Ph. D., associate professor. Her research interests include signal processing, adaptive control and intelligent instrument.
FENGChanghua, born in 1991, M. S.candidate. Her research interests include image processing, pattern recognition.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
