基于經(jīng)驗?zāi)B(tài)分解-自回歸組合模型的網(wǎng)絡(luò)輿情預(yù)測
2018-05-21 00:59:10黃艷瑩
計算機應(yīng)用 2018年3期
關(guān)鍵詞:模型
莫 贊,趙 冰,黃艷瑩
(廣東工業(yè)大學(xué) 管理學(xué)院,廣州 510520)
0 引言
隨著網(wǎng)民規(guī)模的不斷擴大,互聯(lián)網(wǎng)已成為除報紙、廣播、電視等傳統(tǒng)媒體外的又一信息傳播的重要途徑。目前,國內(nèi)的微信、微博、論壇、貼吧和新聞網(wǎng)站等借助互聯(lián)網(wǎng)平臺的社交媒體或網(wǎng)站已成為信息傳播的重要戰(zhàn)場。日益增多的網(wǎng)民接收著來自現(xiàn)實世界和虛擬世界的各種信息,并在社交媒體等上暢所欲言,發(fā)表對于社會事件的看法和意見。當(dāng)突發(fā)的網(wǎng)絡(luò)事件或社會事件引起網(wǎng)民廣泛關(guān)注時,它將演化為網(wǎng)絡(luò)輿情,并對社會公共安全和長期發(fā)展造成重大影響[1-3]。此外網(wǎng)絡(luò)推手幕后炒作、網(wǎng)絡(luò)暴力和網(wǎng)絡(luò)謠言會影響并導(dǎo)致網(wǎng)絡(luò)輿情事件失控變質(zhì),影響社會安全穩(wěn)定和長期發(fā)展[4-5]。因此,網(wǎng)絡(luò)輿情的演化規(guī)律研究和預(yù)測對于輿情工作的開展和管控具有重要意義,有助于政府部門和企業(yè)以積極主動的方式面對輿情工作。
處于大數(shù)據(jù)時代之中,輿情信息工作需要采集的數(shù)據(jù)量龐大,同時,社交媒體、新聞媒體、搜索引擎等網(wǎng)絡(luò)平臺使得網(wǎng)絡(luò)傳播呈現(xiàn)一種“蜂窩狀”的發(fā)散性結(jié)構(gòu),致使分析預(yù)測網(wǎng)絡(luò)輿情的難度加大;而且預(yù)警時間隨著輿情事件的爆發(fā)而呈現(xiàn)不穩(wěn)定的狀態(tài),這些問題使得網(wǎng)絡(luò)輿情的應(yīng)對工作面臨更大的挑戰(zhàn)[6]。
網(wǎng)絡(luò)輿情通常是通過時間序列的方式進行記錄。網(wǎng)絡(luò)輿情數(shù)據(jù)一般是來自于短期內(nèi)輿情萌芽、爆發(fā)、消亡等過程,所以輿情數(shù)據(jù)一般具有非線性、非平穩(wěn)、動態(tài)等特征[7]。采用數(shù)據(jù)挖掘方法和相關(guān)科學(xué)理論預(yù)測輿情時間序列,能更好地解決這一問題,常用的方法主要有貝葉斯網(wǎng)絡(luò)模型[8]、灰色理論[9]等。然而這些單一模型的預(yù)測能力有限,面對復(fù)雜的輿情數(shù)據(jù)時不能有效地進行預(yù)測。常用的處理方式是將時間序列模型與數(shù)據(jù)挖掘模型相結(jié)合,構(gòu)建更準(zhǔn)確的組合預(yù)測模型[10]。組合預(yù)測模型克服了單一預(yù)測算法的缺點, 能發(fā)揮各個單一預(yù)測模型的優(yōu)勢,進而提高模型整體的預(yù)測精度。本文提出了一種新的組合預(yù)測模型——EMD-ARXG(Empirical Mode Decomposition-AutoRegression based on eXtreme Gradient boosting)模型,用于復(fù)雜網(wǎng)絡(luò)輿情的預(yù)測。
1 相關(guān)理論
網(wǎng)絡(luò)輿情時間序列是非平穩(wěn)的時間序列,難以用經(jīng)典的時間序列方法預(yù)測未來序列。來自于信號處理領(lǐng)域的經(jīng)驗?zāi)B(tài)分解(Empirical Mode Decomposition, EMD)算法,為非平穩(wěn)的時間序列提供了新的分解變換思路。EMD的基函數(shù)是由數(shù)據(jù)本身分解得到,是后驗的;又由于分解是基于信號序列時間尺度的局部特性,因此EMD算法具有自適應(yīng)性,不需要人為設(shè)定基函數(shù),更便于預(yù)測建模[11]。
復(fù)雜的時間序列通過EMD分解成數(shù)目有限的本征模態(tài)函數(shù)(Intrinsic Mode Function, IMF)之和。分解得到的IMF序列能夠很好地刻畫原始時間序列在每個局部的振蕩,具有性能良好的Hilbert變換,從而得到Hilbert譜。IMF需滿足兩個條件:
1)在數(shù)據(jù)集中,極值點的數(shù)量與過零點數(shù)量必須相等或最多相差一個。
2)在任一點上,由所有局部極大值點確定的上包絡(luò)線和所有局部極小值點確定的下包絡(luò)線的均值為零。
依據(jù)IMF的定義,分解得到時間序列的上包絡(luò)和下包絡(luò)是關(guān)于時間軸對稱的(簡稱包絡(luò)對稱)。分別通過對序列的極大值點和極小值點進行三次樣條插值產(chǎn)生時間序列的上包絡(luò)和下包絡(luò)。如果分解得到的序列不是IMF,則上下包絡(luò)是不對稱的。用emax(i)表示第i個時間數(shù)列數(shù)據(jù)的上包絡(luò),emin(i)表示下包絡(luò),若包絡(luò)不對稱,則有如式(1)所示:
emax(i)+emin(i)≠0
(1)
據(jù)此得到包絡(luò)均值,如式(2)所示:
(2)
當(dāng)包絡(luò)對稱時m(t)等于0,否則m(i)不等于0。為滿足包絡(luò)對稱,一種基于經(jīng)驗的做法是將不為零的m(t)從時間序列中剔除,若得到的時間序列仍不關(guān)于時間軸對稱,則重復(fù)上述過程,直到滿足IMF的兩個必要條件。IMF的計算過程就是EMD對時間序列進行篩分的過程。篩分過程產(chǎn)生的IMF是基于經(jīng)驗的,目前還未有嚴格的數(shù)學(xué)理論進行推理支撐,故該方法稱為經(jīng)驗?zāi)B(tài)分解。
對于分解后的輿情數(shù)據(jù),需要利用一定的預(yù)測模型進行預(yù)測。自回歸(AutoRegression, AR)模型是經(jīng)典的時間序列預(yù)測模型之一[12],用以描述當(dāng)前預(yù)測值與歷史值之間的關(guān)系,適合短期預(yù)測,主要以時間序列本身的特性進行預(yù)測,所以AR模型適于對EMD分解后的時間序列進行建模預(yù)測。
對于時間序列{x(i),i=1,2,…,N},在利用自身作為回歸變量時,一般形式的數(shù)學(xué)模型如式(3)所示:
xi+1=φ1xi+φ2xi-1+…+φpxi-p+1+ξi+1
(3)
其中:N表示時間序列的數(shù)據(jù)總量,{φj=φ1,φ2,…,φp}是回歸模型的參數(shù),ξi+1是均值為0、方差為σ的白噪聲序列。p為組成線性模型的自變量個數(shù),p階自回歸模型即為含有p個滯后量的線性組合。
AR模型在建模和預(yù)測中難免存在一定誤差,對于復(fù)雜的輿情數(shù)據(jù),更需要一定措施避免較大誤差。Friedman等[13]提出極限梯度提升(eXtreme Gradient Boosting, XGBoost)算法用于時間序列預(yù)測的思想。XGBoost算法作為梯度提升算法的一種,內(nèi)置交叉驗證,并具有訓(xùn)練速度快、模型交互性好等優(yōu)點[14],可對AR預(yù)測模型的殘差進行學(xué)習(xí),降低AR模型的預(yù)測誤差[15-16]。
XGBoost算法在用于殘差學(xué)習(xí)過程中需要設(shè)定目標(biāo)函數(shù)如式(4)所示:
(4)

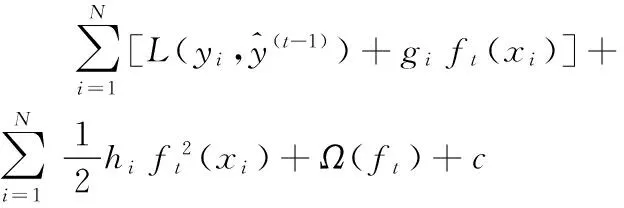
(5)
其中t表示第t輪訓(xùn)練,gi和hi為:
(6)
(7)
XGBoost 算法使得求解的目標(biāo)函數(shù)只依賴于每個數(shù)據(jù)點在誤差函數(shù)的一階導(dǎo)數(shù)和二階導(dǎo)數(shù),可以高效針對這種情況。
EMD-ARXG模型結(jié)合EMD算法和AR模型的各自特點和優(yōu)勢,首先使用EMD算法對時間序列進行分解;再利用AR模型對各個子時間序列的進行趨勢擬合,建立子模型;最后再對各個子模型進行EMD重構(gòu)。
2 EMD-ARXG模型
復(fù)雜的時間序列的影響因素較多,難以量化和趨勢預(yù)測。在AR建模過程中,結(jié)合XGBoost算法,對AR模型的預(yù)測誤差進行學(xué)習(xí),并獲取模型損失函數(shù)值。結(jié)合損失函數(shù)值對AR模型進行迭代更新,最終獲取高精度EMD-ARXG預(yù)測模型。EMD-ARXG模型框架如圖1所示。具體模型建立流程如下。
步驟 1 執(zhí)行EMD算法,對時間序列{x(i),i=1,2,…,N}進行分解。
1)找出時間序列中的極大值emax(i)和極小值emin(i)。
3)將m(i)從時間序列中剔除,得到差序列:
h(i)=x(i)-m(i)。
4)求解差序列h(i)的限值標(biāo)準(zhǔn)差SD值:
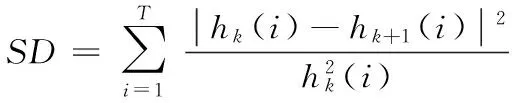
(8)
其中:T為當(dāng)前篩選序列長度,hk(i)為第k次篩選得到的數(shù)據(jù)序列。
5)判斷hk(i)是否為IMF分量。若SD值符合預(yù)定值,一般為0.2~0.3,則是IMF分量。若不是,重復(fù)子步驟1)~4)直到所得到的平均曲線趨于零為止。
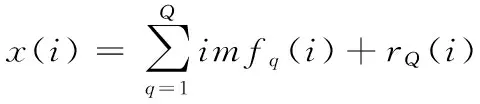
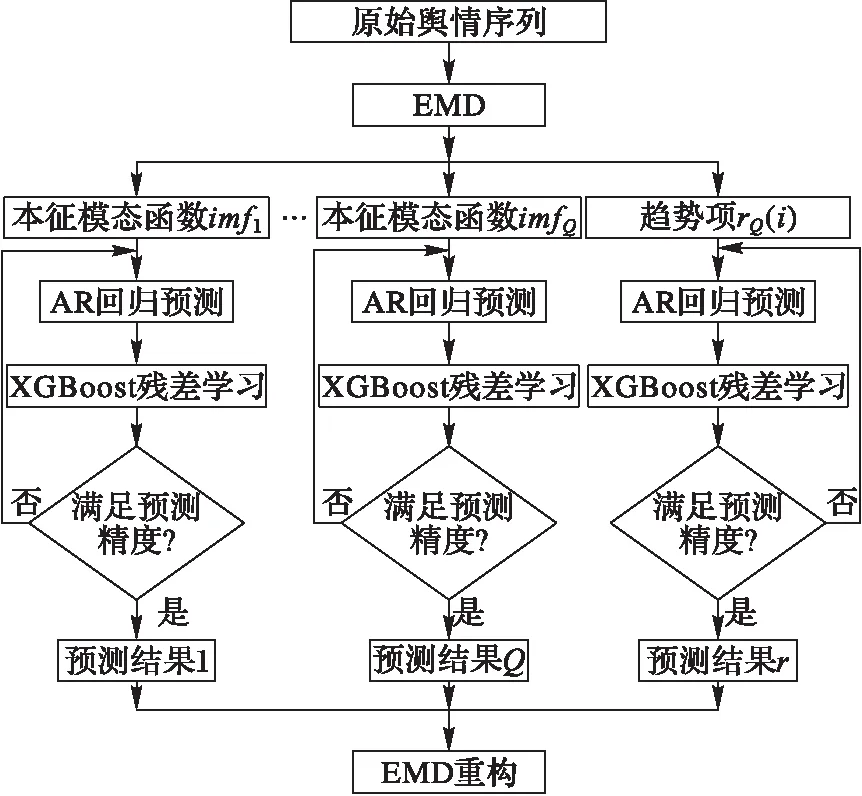
圖1 EMD-ARXG模型框架 Fig. 1 Framework of EMD-ARXG model
步驟2 基于XGBoost對分解后的時間序列建立各個子AR模型。
1)對各個子時間序列進行建立AR模型。
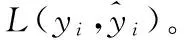
3)通過比較目標(biāo)函數(shù)的目標(biāo)值與設(shè)定誤差值的大小,從而判斷是否達到模型的預(yù)測效果。若滿足進行下一步,若不滿足,則更新AR。
步驟3 對各個子AR模型進行EMD重構(gòu),完成建模。
3 實驗研究
3.1 實驗數(shù)據(jù)
本文研究兩個不同的輿情熱點事件為2016年里約奧運會和2017年一帶一路,使用兩個輿情事件的關(guān)鍵詞“里約奧運會”和“一帶一路”獲取各自的百度指數(shù)和微指數(shù)。對于里約奧運會,輿情時間段為2016年08月01日至2016年08月31日,共31天。對于一帶一路,輿情時間段為2017年04月29日至2017年05月29日,共31天。兩個事件的輿情趨勢如圖2、3所示。本文預(yù)測采用滾動式方法, 即 5 天為一個周期,用前 5 天的時間序列進行第 6 天的預(yù)測。對于每個事件中的每個指標(biāo),最終獲得26組數(shù)據(jù),取前16組數(shù)據(jù)用于訓(xùn)練模型,后10組數(shù)據(jù)用于預(yù)測。
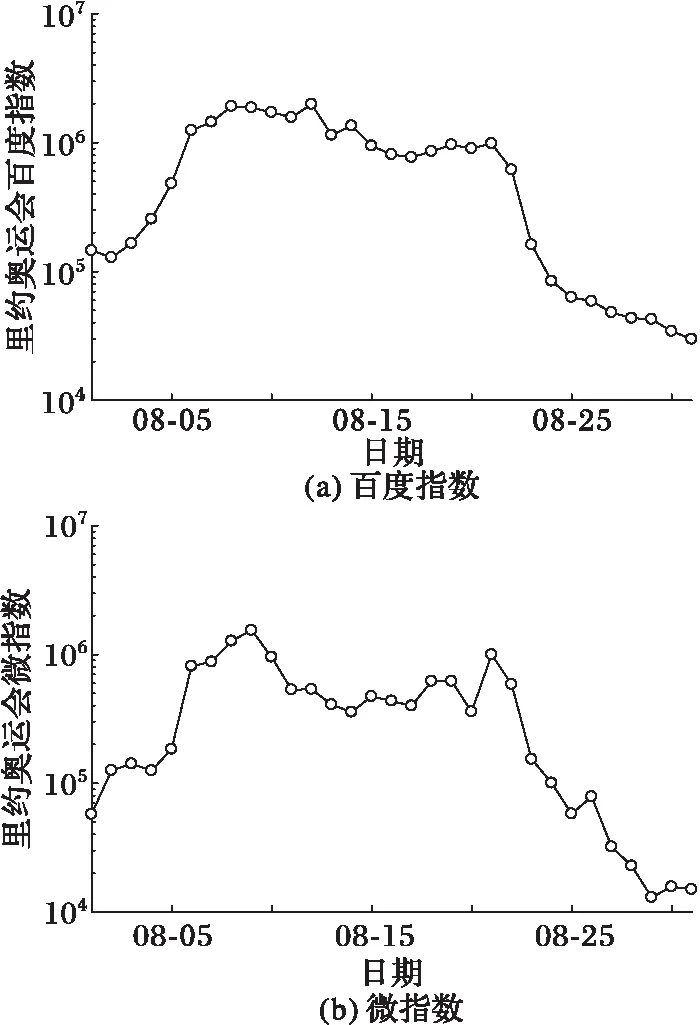
圖2 2016年里約奧運會走勢 Fig. 2 Trend of Rio Olympic Games in 2016
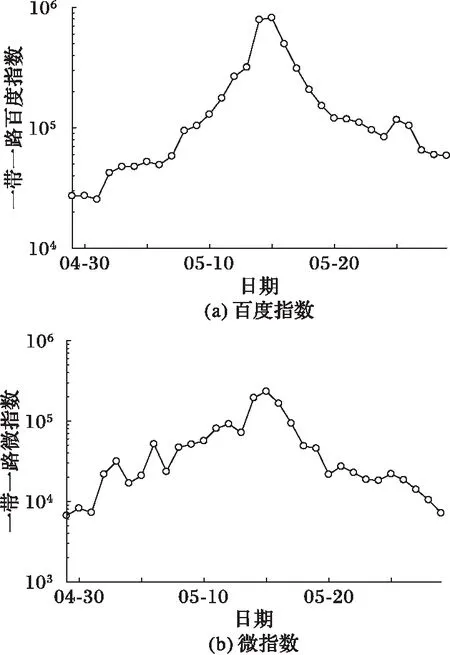
圖3 2017年一帶一路走勢 Fig. 3 Trend of the Belt and Road in 2017
兩個指數(shù)的計算方式不一致,導(dǎo)致指數(shù)大小差異較大,因而,對輿情數(shù)據(jù)進行規(guī)范化處理。規(guī)范化可以提高預(yù)測模型中梯度下降的最優(yōu)求解速度,利于算法收斂。規(guī)范化的方法是將時間序列數(shù)據(jù)的值限定在區(qū)間[0,1]內(nèi),對于時間序列采用最小最大標(biāo)準(zhǔn)化公式:
(9)
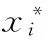
3.2 實驗對比分析
為驗證EMD-ARXG模型對復(fù)雜輿情趨勢的預(yù)測效果,用小波神經(jīng)網(wǎng)絡(luò)(Wavelet Neural Network, WNN)和基于經(jīng)驗?zāi)B(tài)分解的BP神經(jīng)網(wǎng)絡(luò)模型(Back Propagation Neural Netork based on Empirical Mode Decomposition, EMD-BPNN)模型同時對以上輿情進行預(yù)測。其模型設(shè)置如下:
1)WNN模型參數(shù)設(shè)置。模型進行隨機初始化,采用小波基作為激活函數(shù),神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)率分別設(shè)置為0.01和0.001,最大迭代次數(shù)設(shè)置為1 000,隱含層神經(jīng)元個數(shù)設(shè)置為測試效果較好的4。
2)EMD-BPNN模型設(shè)置。因所研究輿情事件時間長度較短,初始時間序列用EMD分解為3個本征模態(tài)函數(shù)imf和一個趨勢項r。另外,隱含層神經(jīng)元個數(shù)設(shè)置為測試效果較好的16。
3)EMD-ARXG模型參數(shù)設(shè)置。與EMD-BPNN模型相同,初始時間序列用EMD分解為3個本征模態(tài)函數(shù)imf和一個趨勢項r。另外,XGBoost算法采用的梯度提升模型為線性函數(shù),學(xué)習(xí)率為采用默認值0.3,算法學(xué)習(xí)目標(biāo)為線性回歸,XGBoost算法的其他相關(guān)參數(shù)采用默認值。
采用3個預(yù)測模型對4組輿情數(shù)據(jù)進行擬合預(yù)測,擬合結(jié)果如圖4、5所示。可以看出:WNN的各擬合線明顯偏離真實趨勢線,EMP-BPNN擬合結(jié)果較為接近真實趨勢線;但是,相比前兩個模型,EMD-ARXG模型的擬合線可以更好地逼近真實趨勢線。從最后一天的指數(shù)預(yù)測可以明顯看出,相比WNN和EMD-BPNN模型,EMD-ARXG模型的預(yù)測值總體更接近于真實值。
本文對預(yù)測結(jié)果進行相應(yīng)的均方根誤差(Root Mean Square Error, RMSE)、平均絕對百分誤差(Mean Absolute Percentage Error, MAPE)和希爾不等系數(shù)(Theil Inequality Coefficient, TIC)指標(biāo)進行統(tǒng)計,其結(jié)果如表1所示,并對各個指標(biāo)數(shù)據(jù)進行分析,如下:
1)RMSE指標(biāo)分析。由于本文采用的輿情數(shù)據(jù)值較大,因此對應(yīng)的均方根誤差也相對較大。除一帶一路的百度指數(shù)外,EMD-ARXG模型的RMSE值在其余5組實驗中全是最小的,表明該模型的預(yù)測效果較好。而WNN模型所有的RMSE值都高于EMD-BPNN模型和EMD-ARXG模型的RMSE值。
2)MAPE指標(biāo)分析。 除一帶一路的百度指數(shù)外,EMD-ARXG模型的MAPE值在其余5組實驗中是最小的,但是在 一帶一路的百度指數(shù)對比中,EMD-ARXG模型的MAPE值與EMD-BPNN模型的MAPE值相近。總體而言,WNN模型與EMD-BPNN模型的MAPE值較高,說明預(yù)測精度低于EMD-ARXG模型。
3)TIC指標(biāo)分析。從TIC值可以看出,EMD-BPNN模型僅在一帶一路的百度指數(shù)上取得TIC值最小值,其余都是EMD-ARXG模型取得最小值。所以相比WNN和EMD-BPNN模,EMD-ARXG模型更適于輿情事件的趨勢預(yù)測。
綜合分析,EMD-ARXG模型的各個預(yù)測模型評價指標(biāo)是3個模型中最佳的,擬合效果和預(yù)測精度都高于WNN和EMD-BPNN模型。
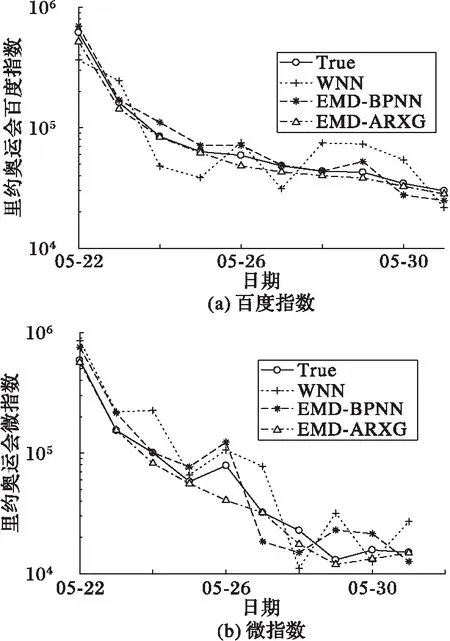
圖4 2016年里約奧運會預(yù)測 Fig. 4 Prediction of Rio Olympic Games in 2016
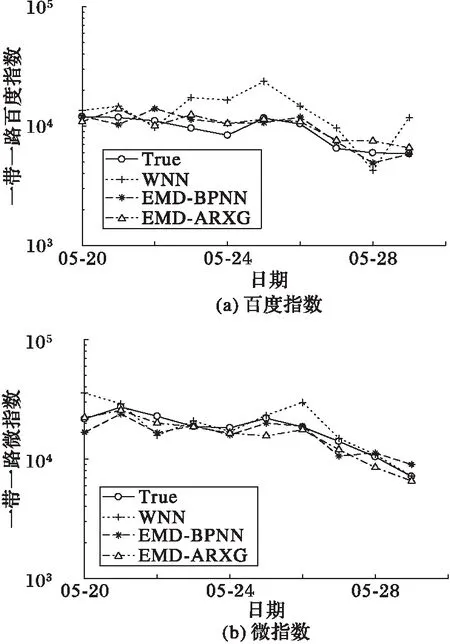
圖5 2017年一帶一路預(yù)測 Fig. 5 Prediction of the Belt and Road in 2017
4 結(jié)語
本文以復(fù)雜網(wǎng)絡(luò)輿情的預(yù)測模型為研究對象,提出一種新的組合模型EMD-ARXG模型,并通過實例對比了EMD-ARXG模型與WNN和EMD-BPNN模型的預(yù)測效果。從實驗結(jié)果可以看出,在RMSE、MAPE和TIC三項評價指標(biāo)上,EMD-ARXG模型整體均優(yōu)于WNN和EMD-BPNN模型,說明提出的EMD-ARXG模型較適合于輿情趨勢的預(yù)測。綜合兩個領(lǐng)域?qū)嵗念A(yù)測結(jié)果,EMD-ARXG模型均能夠得到較為準(zhǔn)確的預(yù)測值,說明此模型適合于復(fù)雜輿情的趨勢預(yù)測。

表1 三種預(yù)測模型的預(yù)測指標(biāo)統(tǒng)計結(jié)果Tab. 1 Statistical result of prediction indexes for three prediction models
參考文獻(References)
[1] CERON A, NEGRI F. The “social side” of public policy: monitoring online public opinion and its mobilization during the policy cycle [J]. Policy & Internet, 2016, 8(2): 131-147.
[2] LEEPER T J, SLOTHUUS R. Political parties, motivated reasoning, and public opinion formation [J]. Political Psychology, 2014, 35(S1): 129-156.
[3] 陳福集,李林斌.G(Galam)模型在網(wǎng)絡(luò)輿情演化中的應(yīng)用[J].計算機應(yīng)用,2011,31(12):3411-3413.(CHEN F J, LI L B. Application of G (Galam) model in network public opinion evolution [J]. Journal of Computer Applications, 2011, 31(12): 3411-3413.)
[4] URBAN J, BULKOW K. Tracing public opinion online — an example of use for social network analysis in communication research [J]. Procedia — Social and Behavioral Sciences, 2013, 100(7): 108-126.
[5] 方薇,何留進,孫凱,等.采用元胞自動機的網(wǎng)絡(luò)輿情傳播模型研究[J].計算機應(yīng)用,2010,30(3):751-755.(FANG W, HE L J, SUN K, et al. Study on dissemination model of network public sentiment based on cellular automata [J]. Journal of Computer Applications, 2010, 30(3): 751-755.)
[6] JAMALI S, RANGWALA H. Digging Digg: comment mining, popularity prediction, and social network analysis [C]// Proceedings of the 2009 International Conference on Web Information Systems and Mining. Washington, DC: IEEE Computer Society, 2009: 32-38.
[7] 魏超.新媒體技術(shù)發(fā)展對網(wǎng)絡(luò)輿情信息工作的影響研究[J].圖書情報工作,2014,58(1):30-34.(WEI C. Study on the impact of new media technology development on Internet public opinion information work [J]. Library and Information Service, 2014, 58(1):30-34.)
[8] 柯赟.基于動態(tài)貝葉斯網(wǎng)絡(luò)的輿情預(yù)測模型研究[J].統(tǒng)計與決策,2016(20):26-28.(KE Y. Research on network public opinion prediction model based on dynamic Bayesian network [J]. Statistics and Decision, 2016(20): 26-28.)
[9] 李文杰,化存才,何偉全,等.網(wǎng)絡(luò)輿情事件的灰色預(yù)測模型及案例分析[J].情報科學(xué),2013(12):51-56.(LI W J, HUA C C, HE W Q, et al. Gray prediction model of network public opinion event and analysis of examples [J]. Information Science, 2013(12):51-56.)
[10] 滕文杰.時間序列分析法在突發(fā)公共衛(wèi)生事件網(wǎng)絡(luò)輿情分析中的應(yīng)用研究[J].中國衛(wèi)生統(tǒng)計,2014,31(6):1071-1073.(TENG W J. Application of time series analysis in public opinion analysis of public health emergencies [J]. Chinese Journal of Health Statistics, 2014, 31(6): 1071-1073.)
[11] CHOI B S. A recursive algorithm for solving the spatial Yule-Walker equations of causal spatial AR models [J]. Statistics & Probability Letters, 1997, 33(3): 241-251.
[12] 黃遠,沈乾,劉怡君.微博輿論場:突發(fā)事件輿情演化分析的新視角[J].系統(tǒng)工程理論與實踐,2015,35(10):2564-2572.(HUANG Y, SHEN Q, LIU Y J. Microblog public opinion field: a new perspective for analyzing evolution of emergency opinion [J]. System Engineering — Theory & Practice, 2015, 35(10): 2564-2572.)
[13] FRIEDMAN J, HASTIE T, TIBSHIRANI R. Additive logistic regression: a statistical view of boosting [J]. Annals of Statistics, 2000, 28(2): 337-374.
[14] CHEN T, GUESTRIN C. XGBoost: a scalable tree boosting system [C]// KDD ’16: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 785-794.
[15] ESHEL G. The Yule Walker equations for the AR coefficients [EB/OL]. [2017- 04- 01]. http://www-stat.wharton.upenn.edu/~steele/Courses/956/ResourceDetails/YWSourceFiles/YW-Eshel.pdf.
[16] 游丹丹,陳福集.基于改進粒子群和BP神經(jīng)網(wǎng)絡(luò)的網(wǎng)絡(luò)輿情預(yù)測研究[J].情報雜志,2016,35(8):156-161.(YOU D D, CHEN F J. Research on the prediction network public opinion based on improved PSO and BP neural network [J]. Journal of Intelligence, 2016, 35(8):156-161.)
This work is partially supported by the National Natural Science Foundation of China (711710); the “Twelfth Five-Year” National Science and Technology Support Program Major Issues (2011BAD13B11); the Guangdong Provincial Regional Demonstration Project for Marine Economic Innovation and Development (GD2013-D01- 001).
MOZan, born in 1962, Ph. D., professor. His research interests include e-commerce,information management system.
ZHAOBing, born in 1993, M. S. candidate. Her research interests include machine learning, data mining.
HUANGYanying, born in 1991, M. S. candidate. Her research interests include machine learning, data mining.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
