基于子字單元的神經機器翻譯未登錄詞翻譯分析
2018-05-29 03:28:02李軍輝熊德意周國棟
中文信息學報 2018年4期
韓 冬,李軍輝,熊德意,周國棟
(蘇州大學 計算機科學與技術學院,江蘇 蘇州 215006)
0 引言
神經機器翻譯(NMT)采用一種新穎的解決機器翻譯問題的方法,并且最近幾年已經取得了極大的成功[1-3]。尤其是在翻譯的流利度方面,NMT系統與傳統的SMT系統相比,翻譯結果更加順暢。總的來說,NMT系統采用神經網絡結構,不需要存儲短語表,而是有著一個小規模的詞匯表,這大大減小了計算的復雜度。
但是,NMT系統也有自身的缺點。因為NMT系統為了能夠控制計算的復雜度,有著一個固定大小的詞匯表,通常會將詞匯表限制在30~80KB之間,這就導致了其在翻譯未登錄詞時有著嚴重的不足。由于限定詞匯表有大小限制,對于未出現在該詞匯表中的詞,NMT系統用UNK標記來替代。結果,NMT系統不僅無法將它們翻譯準確,而且破壞了句子的結構特征。為了解決NMT系統中存在的這一問題, Sennrich和Haddow[4]提出了一種BPE編碼[5]的解決方法。該方法將訓練語料中的單詞拆分成更為常見的小部分,這里把它叫做子字單元。通過這種方法,我們假設在同樣將詞匯表設置成30KB的情況下,由于很多單詞拆解的子字部分是相同的,所以30KB的子字單元實際上可以表示出遠遠超出30KB的以單詞為基礎的詞匯表。這樣,對于絕大多數未登錄詞,就可以通過子字單元的組合表示出翻譯的結果。
將單詞拆解為子字單元的方法對于未登錄詞問題確實是一種簡單的方法,但是對于其翻譯的效果我們依然持疑問的態度。因此,本文對BPE方法的翻譯結果進行了分析。分析BPE方法是如何翻譯未登錄詞的,在多大程度上解決了NMT系統對未登錄詞的翻譯問題。
通過對中英文翻譯的實驗結果分析,本文有如下發現:
(1) 驗證了BPE方法對未登錄詞確實是一種行之有效的方法,在對中英文雙向都拆解成子字單元的實驗中,實驗結果與不做處理的NMT系統相比,提高了1.02 BLEU值。
(2) 本文進行了四組實驗,對各個實驗中訓練語料中未登錄詞進行了統計,發現通過BPE方法的實驗在訓練語料中基本涵蓋了所有的訓練單詞。
(3) 統計了各測試語料中源端未登錄詞的個數,然后得出結論: 使用中英文端均做BPE的方法,測試源端語料基本不會出現未登錄詞。從翻譯結果看,目標端翻譯結果中不含有UNK標識符,從而可以說明通過BPE的方法確實極大程度上解決了未登錄詞的問題。
(4) 分析測試源端中未登錄詞的詞性和各組對比實驗的解決效果,發現NMT系統中未登錄詞的來源主要是名詞、動詞和數詞。
(5) 與SMT方法比較,BPE方法對未登錄詞的翻譯效果在精準度上基本上保持一致。對于測試源端語料中未登錄詞的翻譯均達到了45%左右的正確率。
1 神經機器翻譯系統
本節將簡要介紹本文的神經機器翻譯系統,該系統采用注意力機制,包含一個編碼器和一個解碼器[6],整體結構如圖1所示。
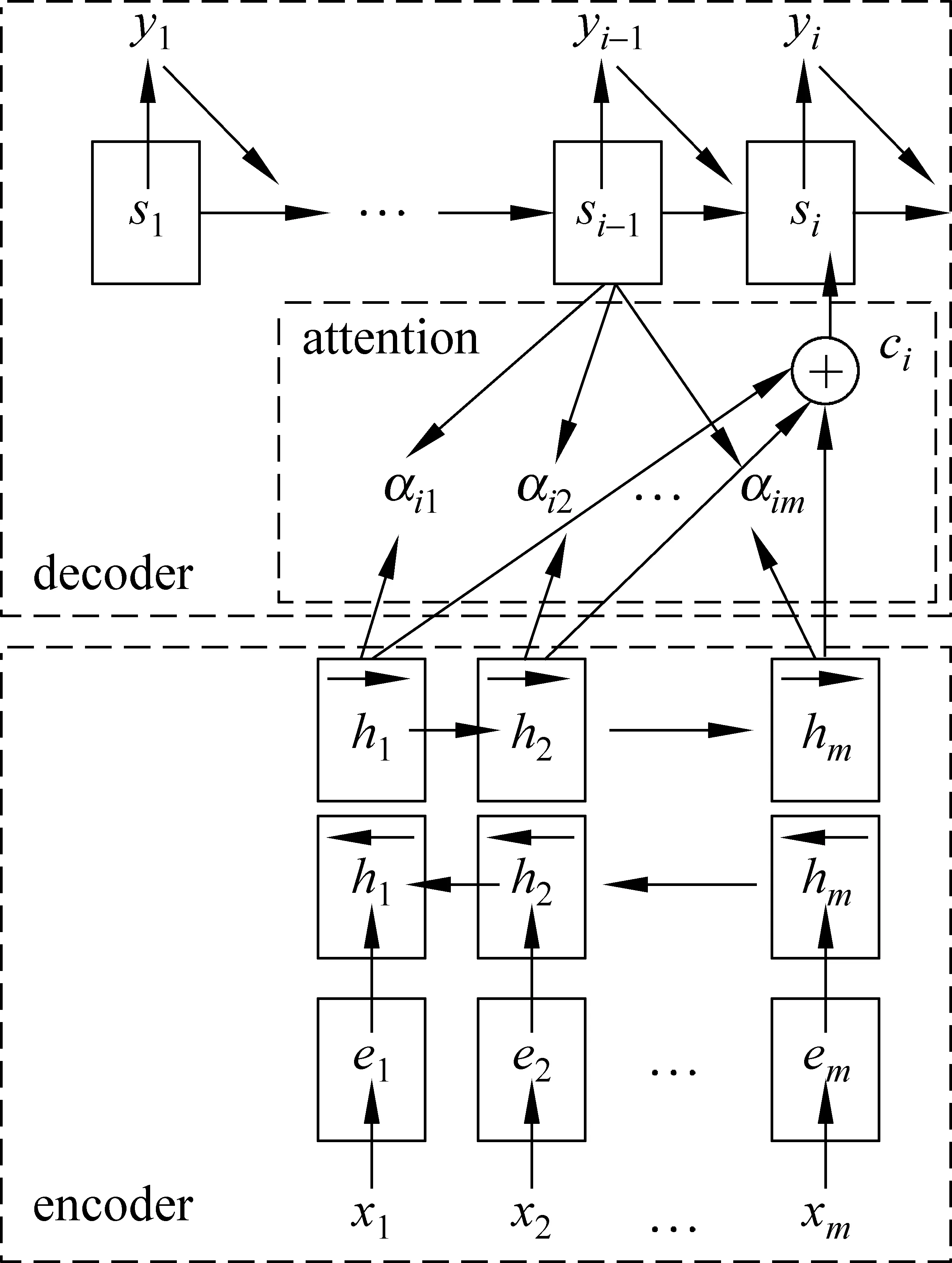
圖1 基于注意力機制的神經機器翻譯
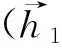
p(yi|y1,…,yi-1,x)=g(yi-1,si,ci)
(1)
si為循環神經網絡第i時刻的隱藏狀態,計算通過:
si=f(si-1,yi-1,ci)
(2)
ci也被叫作注意力向量,具體計算公式為式(3-5)。
其中,att(si-1,hj)是一個通過源端隱層狀態hj和目標端前一隱層狀態si-1計算出的匹配程度。
2 BPE*可以在http://aclweb.org/anthology/attachments/P/P16/P16-1162.Software.zip得到BPE方法使用的代碼編碼與子字單元
雖然有大量的工作用來不斷地優化神經機器翻譯系統,但是對于未登錄詞的解決仍然是當今神經機器翻譯系統的一大難題。
BPE的思想是將單詞拆解為更小、更常見的子字單元。對于原本不在詞表中的單詞,NMT系統一般會用UNK標示符替代。BPE方法將其拆解為常見的子字,通過翻譯子字部分將原有的UNK單詞進行了翻譯,從而極大地保存了句子的結構特征和流暢性。
BPE方法拆解成子字單元的具體效果可以通過下面的例子來進行說明:
例(a) he is a good boy
例(b) h@@ e is a g@@ o@@ o@@ d b@@ oy
假設例(a)出現在訓練語料中,傳統的NMT系統在形成詞匯表時,使用的是以單詞為基礎的劃分方式,然后取詞頻出現較高的單詞形成字典。但是BPE方法則是以一種介乎單詞和字母之間的子字單元形成字典,如例(b)所示,其將一個句子中的單詞拆分成了更小的部分 he→h@@ 和e。原本以he形成字典的方式轉變為h@@ 和e 兩個字典。更加詳細的說明可參見文獻[4]。
在中文語料中,假設“大學文憑”是一個中文未登錄詞,被標記為UNK,通過BPE的方法,將“大學文憑”拆解為“大學”和“文憑”兩個部分,而“大學”和“文憑”這兩部分恰恰是在詞匯表中的,可以準確翻譯,從而可以得到“大學文憑”的正確翻譯結果如下:
Eg.大學文憑→大學 文憑 →university diploma
3 實驗
本文針對中到英的翻譯任務分析BPE方法對未登錄詞的翻譯效果。為此,共準備了四組實驗,每組實驗的翻譯性能采用評測標準BLEU值[8]。
訓練集包含從LDC語料庫中抽取的1.25MB句對的中文到英文平行語料*該語料包括LDC2002E18,LDC2003E07,LDC2003E14,LDC2004T07,LDC2004T08和LDC2005T06。。選擇NIST MT 06數據集作為開發集,NIST MT 02, 03, 04, 05, 08作為測試集。
表1給出了本文進行的四組實驗及其描述,其中Baseline系統將所有的中英文端未登錄詞都替代為UNK標記,BPE_cn、BPE_en、BPE_all指分別在源端(即中文端)、目標端(即英文端)和兩端(即中英文端)進行BPE子字單元處理。
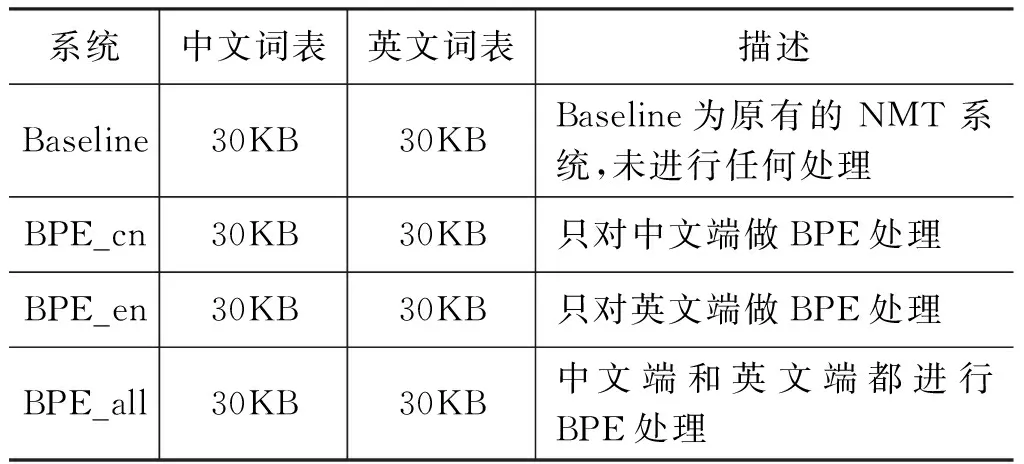
表1 四組實驗及其描述
在實驗中,設置隱層單元的個數為1 000,源端和目標端單詞詞向量(word_embedding)的維度為620維。神經網絡用Adadelta[9]模型更新參數。設置batch_size為80。我們使用GPU去運行實驗訓練部分,提高實驗運行的速度。
3.1 訓練語料中未登錄詞的統計
本文統計了上述四個實驗中未登錄詞的個數,如表2所示,從表中可以看出:
(1) 在相同的訓練語料下,通過BPE方法可以極大地減少未登錄詞的個數,系統中中文未登錄詞的個數從174 291(Baseline系統)減少到549(BPE_all系統),英文未登錄詞的個數從75 910(Baseline系統)減少到0(BPE_all系統)。
(2) 在測試語料中,因為測試語料單詞的個數要遠遠小于訓練中出現的單詞個數,所以我們有理由相信: 在中英文均做BPE處理的實驗中,在測試時,源端將產生極少的未登錄詞,英文翻譯結果中將會有極少的UNK標識符。這在我們之后的實驗結果中也得到了驗證。
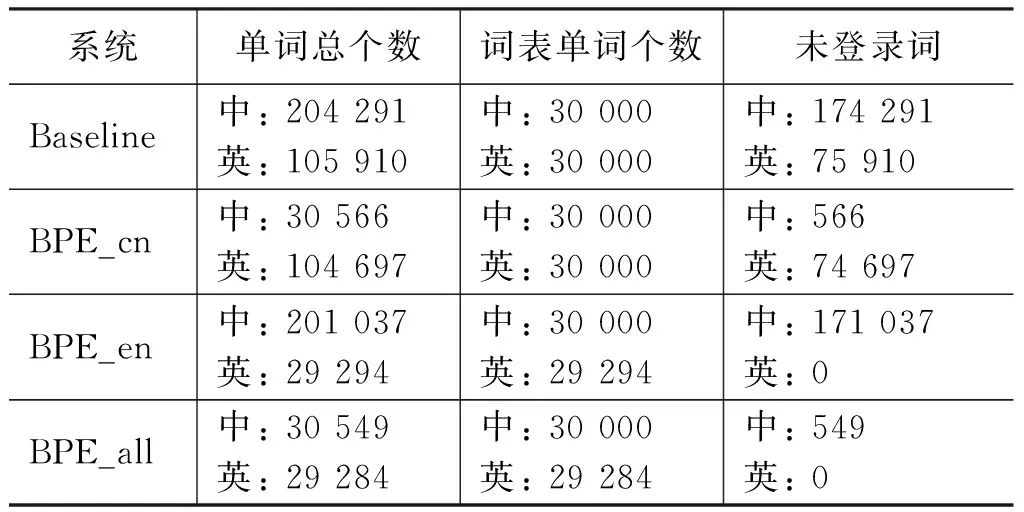
表2 四組實驗中在相同訓練語料下,單詞總個數、詞表單詞個數和訓練語料中未登錄詞的統計結果
其中,我們設置源/目標端句子最大長度為50,超過50個單詞的句子舍棄,BPE在拆解成子字單元的過程中,會增加句子的長度*原Baseline在最大句子長度設置為50時,實際用于訓練的語料行數為1 128 660。采用BPE_all方法也將最大句子長度設置為50的情況下,實際用于訓練的語料行數為1 119 600,兩種情況下訓練規模近似相同,僅僅減少了0.8%。。
3.2 測試集未登錄詞的統計
表3統計了各個測試集源端包含的中文未登錄詞的個數。

表3 測試集源端統計結果
注: ① 在對源端做BPE處理時,源端單詞個數會增多。
② S-W: 測試集中源端(中文端)單詞總個數,S-U: 測試集中未登錄詞個數。
表3的統計結果表明,在Baseline系統中,測試集源端存在5%左右的未登錄詞。我們把這部分詞稱為VBaseline_chn_UNK。
通過上表的統計結果可以發現,經過BPE處理的實驗與未經任何處理的Baseline實驗相比,其測試集中含有很少的未登錄詞。特別地,對于BPE_all系統,由于源端和目標端同時分別采用了BPE編碼,這樣就使得在翻譯時源端和目標端詞匯表中的單詞基本上完全覆蓋了測試集中的單詞,所以翻譯結果中將基本不會含有未登錄詞*如表3所示,在測試集中,源端仍存在極少數的未登錄詞,該未登錄詞基本上是特殊符號。。在 測 試 的 時候,雖然BPE_all系統中源端含有很少的未登錄詞,但是BPE_all是否可以將VBaseline_chn_UNK翻譯正確,翻譯的質量如何,我們在下一節將進一步討論。
3.3 Baseline系統測試集源端UNK分析
本節分析了BPE_all實驗對VBaseline_chn_UNK集合中單詞的翻譯效果。圖1給出了該集合中單詞按詞性的分布統計。不難看出,Baseline系統中源端未登錄詞主要是名詞(約占76%),然后是動詞(約占16%)和數詞(約占6%)。
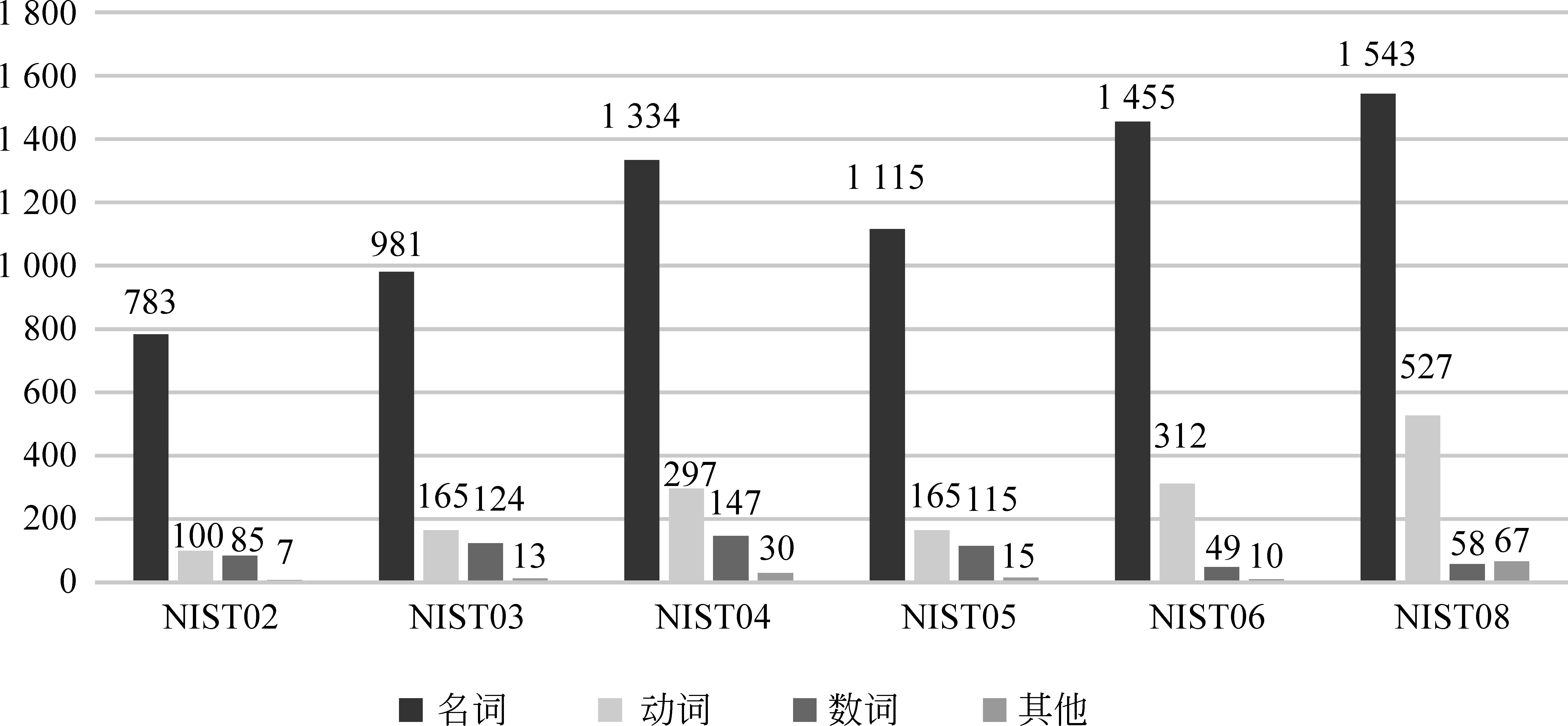
圖2 測試集VBaseline_chn_UNK的詞性分布
表4統計了在BPE_all實驗中,將VBaseline_chn_UNK集合中單詞正確翻譯的比率。根據參考數據集,以NIST06為例,人工分析了NIST06中VBaseline_chn_UNK共1 826個詞的翻譯準確率。以名詞為例,從表4可以看出,VBaseline_chn_UNK總共包含名詞1 455個,其中669個翻譯正確,占46%,說明BPE方法對源端未登錄詞具有一定的翻譯效果。

表4 在BPE_all系統中,NIST06開發集VBaseline_chn_UNK的翻譯正確統計
3.4 Baseline系統譯文UNK分析
本節分析在Baseline系統中,哪些源端詞翻譯為譯文的UNK。根據詞對齊信息,找到譯文中UNK所對應源端的單詞,稱源端的這些詞為VBaseline_to_eng_UNK。圖3統計了VBaseline_to_eng_UNK的詞性分布情況,該圖說明了導致譯文中出現UNK最多的是名詞(70%),緊接著是動詞(17%)和數詞(8%)。表5統計了VBaseline_to_eng_UNK中UNK是來自源端未登錄詞的個數(VBaseline_chn_UNK),以及源端在詞表中但最終翻譯為UNK的單詞個數。以NIST02為例,Baseline的譯文中共包含單詞25 394個,其中UNK的數量為636個。針對這636個譯文UNK,其中534個是由源端UNK翻譯所致,另外102個是由源端非UNK翻譯而來。這也說明了譯文中產生UNK的單詞大部分來自于源端的未登錄詞。
接著,由于目標端已消除UNK(BPE_all譯文中沒有UNK標示符),本節分析BPE_all系統又是如何翻譯VBaseline_to_eng_UNK中的詞,其翻譯質量又如何。以NIST06為例,本文人工分析了NIST06中VBaseline_to_eng_UNK共1 204個詞的翻譯準確率,如表6所示。以名詞為例,從表6可以看出,VBaseline_to_eng_UNK總共包含名詞881個,其中396個翻譯正確,占45%。

表5 測試集譯文中UNK的統計
注意:表中,UNK行指譯文中出現UNK的個數;Chn_UNK行表示多少數量的譯文UNK翻譯自源端UNK;Non_Chn_UNK行表示多少數量的譯文UNK翻譯自源端非UNK詞。

圖3 測試集VBaseline_to_eng_UNK的詞性分布

名詞動詞數詞其他詞性所有詞性總數正確數總數正確數總數正確數總數正確數總數正確數8813962079870464671204547(45%)
我們評測了各詞性下的UNK單詞在BPE翻譯結果下的正確數,發現最終使用BPE方法的實驗可以將45%的UNK單詞翻譯正確(其余單詞翻譯錯誤或漏翻),從而在一定程度上保障了句子的結構特征和流暢性。
3.5 BPE與SMT比較
從以上分析可以看出,BPE編碼可以在一定程度上解決未登錄詞的翻譯問題。但是,與SMT系統相比,BPE是否能夠更好地解決未登錄詞的翻譯仍未知。由于SMT并沒有限定詞匯表,對VBaseline_to_eng_UNK
中的詞的翻譯效果要比NMT Baseline系統好。本節主要比較SMT系統*本文的SMT系統采用cdec源碼實現的層次短語翻譯系統(https://github.com/redpony/cdec)。為公平起見,SMT系統與NMT系統使用相同的訓練集、開發集和測試集。與BPE_all系統,分析兩者對VBaseline_to_eng_UNK中的詞的翻譯效果。
以NIST06為例,本文人工分析了NIST06中VBaseline_to_eng_UNK共1 204個詞在SMT系統下的翻譯準確率,如表7所示。

表7 在SMT系統中,NIST 06測試集VBaseline_to_eng_UNK的翻譯正確統計
比較表6和表7不難看出,BPE方法和SMT系統在翻譯精準度上基本持平,最終對UNK單詞翻譯的精準度均達到了45%左右,從而可以說明BPE方法在一定程度上既具有傳統NMT系統的流暢性,又具有接近SMT系統的未登錄詞翻譯精準度。
3.6 主要結果
表8給出了Baseline系統和各BPE系統在測試集上的翻譯性能BLEU值。從表8中可以看出,僅對源端或目標端采用BPE編碼,能夠在一定程度

表8 使用和未使用BPE的系統在測試集上的翻譯性能BLEU值
注:表示在將顯著水平設置為0.01時,BPE_all系統比Baseline系統相比有顯著性提高[10]。
上提高翻譯性,兩端同時采用BPE編碼,能進一步顯著地提高翻譯的性能,例如BPE_all系統在測試集上比Baseline系統平均提高了1.02 BLEU值。
4 總結
在本文中,我們分析發現BPE編碼的方式確實在一定程度上解決了NMT系統中未登錄詞的翻譯問題。通過將原有單詞拆解為高頻子字單元的方法,擴展了原有系統中的詞匯表的大小,使在利用相同詞匯表大小的情況下,我們可以表示出更多的單詞,從而使系統中未登錄詞個數大大減少。
統計UNK單詞被正確翻譯的概率,我們又發現BPE方法在翻譯精準度上基本和SMT系統持平,從而可以說明BPE方法在原有NMT系統流暢性的基礎上又具有一定的翻譯精準度。
但是使用BPE的方法仍然有其自身存在的問題,例如單詞的漏譯現象。對于NMT系統中低頻詞和未登錄詞的問題仍然是一大難題,我們在人工智能的道路上依然任重道遠。
[1] Nal Kalchbrenner, Phil Blunsom.Recurrent continuoustranslationmodels[C]//Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle, Washington, USA: 2013: 1700-1709.
[2] IlyaSutskever, Oriol Vinyals, Quoc V.Le. Sequence to sequence learning with neural networks[C]//Proceedings of the Neural Information Processing Systems (NIPS 2014). Montreal, Canada: 2014: 3104-3112.
[3] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv, 1409.0473: 2014.
[4] Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units[J]. arXiv preprint arXiv: 1508.07909, 2015.
[5] Philip Gage. A new algorithm for data compression[J]. The C Users Journal, 1994, 12(2): 23-38.
[6] Minh-Thang Luong, Hieu Pham, Christopher D.Manning.Effective approaches to attention-based neural machine translation[C]//Proceedings of EMNLP 2015: 1412-1421.
[7] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre,et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv: 1406.1078, 2014.
[8] Papineni K, Roukos S, Ward T, et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 2002: 311-318.
[9] Mattew D Zeiler.ADADELTA: an adaptive learning rate method[J]. arXiv preprint arXiv: 1212.5701, 2012.
[10] Philipp Koehn.Statistical significance tests for machine translation evaluation[C]//Proceedings of the 2004 conference on empirical methods in natural language processing.


E-mail:dyxiong@suda.edu.cn
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
