支持告警序列差分隱私保護的網絡入侵關聯方法
2018-05-30 01:37:21李洪成吳曉平
計算機工程 2018年5期
李洪成,吳曉平
(海軍工程大學 信息安全系,武漢 430033)
0 概述
隨著網絡攻擊的復雜性、持續性和針對性不斷提高,網絡攻擊的檢測工作越來越困難。目前高級網絡攻擊往往采用逐層滲透的方式達到攻擊目的[1-3],因此,現有的高級網絡攻擊檢測工作大多建立在各個安全機構對威脅告警信息進行協同共享的基礎上[4-5],進而通過告警信息的關聯分析來識別入侵軌跡,為有針對性的網絡安全防御工作提供鋪墊[6-7]。
然而,網絡威脅告警中可能包含被攻擊者的網絡拓撲、安全配置和服務等敏感信息,同時遭受網絡攻擊的企業部門往往不希望將針對自己的攻擊事件完全公之于眾[8]。因此,隱私保護是網絡安全數據共享和協同檢測急亟需突破的瓶頸,需要采用滿足隱私保護的網絡告警協同關聯分析方法,在有效檢測網絡攻擊行為的同時,保護共享的告警隱私信息。
在滿足隱私保護的告警關聯研究方面,有很多學者做了卓有成效的研究工作。文獻[9]利用概念層次法對告警數據進行泛化,將告警信息中的離散屬性值用更高層次的概念代替(例如用網絡地址代替IP地址),并將連續屬性值用間隔代替,然后設計了利用泛化告警進行因果關聯的方法,在告警關聯分析時采用樂觀策略,將可能建立關聯的告警構成關聯圖,并計算關聯成功的概率,利用概率閾值和時間約束對關聯圖進行聚合,進而降低泛化告警關聯的誤差。該方法的缺點是告警的因果關系過分依賴于預定義的謂詞知識。針對此問題,文獻[10]提出了基于頻繁序列挖掘的隱私保護告警關聯方法,利用k-匿名算法對告警進行泛化,設計了類Apriori方法挖掘泛化后的頻繁告警序列,并通過支持度評估優化了候選序列生成方法,在關聯效率和隱私性之間實現了較好的折中。然而,基于概念層次法和k-匿名的隱私保護模型在應對基于背景知識的惡意分析時存在較大隱患,惡意分析者可利用再識別攻擊和Link攻擊[11-12]等手段發現告警中的隱私信息。在大數據時代,分析者所擁有的背景知識越來越多,給數據隱私保護帶來了巨大挑戰。為應對任意背景知識下的惡意分析,文獻[13]提出了差分隱私保護模型,該模型在最大背景知識假設下,提供了嚴格且可證明的隱私保護定義。
本文提出一種支持差分隱私保護的網絡告警關聯分析方法,一方面最大程度地保護告警序列的隱私信息,另一方面利用頻繁告警序列挖掘關聯網絡告警,為網絡告警協同安全分析問題提供一種有效的解決方案。
1 差分隱私保護
差分隱私保護技術屬于一類基于信息干擾的隱私保護技術,對離散型和連續型數據分別采用隨機響應和隨機噪聲添加機制來完成干擾,同時使經過處理后的數據仍可以完成一定的統計、查詢或挖掘任務,并保證一定程度上的可用性[14]。
差分隱私保護算法的設計要求是刪除或更改數據集中任何一條記錄對于查詢結果幾乎不產生影響,即使惡意分析者掌握除敏感記錄之外的其他所有記錄,仍不能獲取該敏感記錄的信息。因此,差分隱私保護能夠抵御任意背景知識下的分析行為[15]。該算法的原理如下:
設分析者的數據分析操作為算法F,算法A對算法F的分析結果進行隱私泛化處理,使之滿足差分隱私保護要求。
定理1設數據集D和D′是最多只差一條記錄的2個數據集,Range(A)為泛化算法A的值域,Pr[X]是事件X出現的概率,如果對于所有S∈Range(A)都滿足:
Pr[A(D)?RA]≤eε×Pr[A(D′)?RA]
(1)
那么泛化算法A提供ε-差分隱私。在式(1)中,ε表示隱私保護預算。
全局敏感度是數據分析函數的一項固有屬性,表示某一記錄刪除或改變對分析結果的影響,其定義如下:
定義1數據分析函數F的全局敏感度為:
(2)
其中,‖·‖1為向量的1-范數,即所有元素的絕對值之和。
在具體的實現方法上,差分隱私保護利用Laplace機制實現連續型數據的隨機噪聲添加,并利用指數機制實現離散型數據的隨機相應。下面對本文中使用到的Laplace機制進行介紹。
定理2若數據集D的分析結果表示為F(D),其全局敏感度用ΔF表示,那么泛化算法A(D)=F(D)+Y支持差分隱私保護,當且僅當隨機數Y服從尺度為ΔF/ε的Laplace分布,其概率密度函數為:
(3)
在設計滿足差分隱私的數據分析方法時,需要分配隱私預算并對隱私性進行證明,在這個過程中,需要用到差分隱私保護的2條重要性質,即序列組合性和并行組合性。

性質2若泛化算法Ai支持εi-差分隱私,則泛化算法在數據集上的一系列獨立的處理過程支持max(εi)-差分隱私保護。
2 保護差分隱私的入侵告警關聯方法
網絡入侵檢測系統、防火墻等安全設備檢測出的威脅信息主要以告警的形式出現。在入侵軌跡識別過程中,定義網絡告警數據類型為alert={Time,S_IP,D_IP,AttackType},其中,Time表示告警時間,S_IP表示源IP,D_IP表示目的IP,AttackType表示對應的攻擊類型。
在差分隱私保護的實現機制上,本文不采用直接對每個序列的計數添加隨機噪聲的方法,而是在原始告警序列數據集的基礎上,利用Laplace機制構建噪聲前綴樹。由于前綴樹中節點的計數比每個序列的計數要大,在前綴樹節點上添加噪聲對于數據集的可用性影響較小,因此可以在隱私保護預算一致的情況下,應盡可能降低對算法準確性的影響。
本文告警關聯方法的具體過程如圖1所示。

圖1 本文告警關聯方法流程
2.1 噪聲告警序列前綴樹構建
在構建噪聲前綴樹之前,首先對前綴樹進行定義。
定義2告警序列前綴:告警序列S=
定義3告警序列前綴樹:原始告警序列數據集D的前綴樹PT是一個三元組PT=(V,E,Root(PT)),其中:Root(PT)是PT的虛擬根節點;V是用告警記錄標記的節點集合,每個節點v對應著D中某個特定的前綴prefix(v,PT),即從Root(PT)到v的序列;E是連接各節點的連邊集合。
在告警序列前綴樹中,節點v以二元組(tr(v),c(v))的結構存儲,其中,tr(v)表示告警序列數據集D中以prefix(v,PT)為前綴的序列記錄的集合,c(v)是對|tr(v)|添加噪聲后的結果。此外,記前綴樹中深度為i的節點組成的集合為level(i,PT),Root(PT)的深度為0。
為使原始數據集D中的告警序列滿足差分隱私保護的要求,需要保證所有可能的告警記錄均以一定的概率出現在泛化后的數據集中。噪聲前綴樹的構建過程如算法1所示。
算法1噪聲告警序列前綴樹構建
輸入原始告警序列數據集D,隱私保護預算ε,前綴樹深度h,可能的告警記錄集合U

1.i=0;
3.ε-=ε/h;
4.while i 6. for each u∈U do 7. 將u作為v的候選子節點; 9. c(u)=NoisyCount(|tr(u)|,ε-); 10. if c(u)≥θ then 12. end if 13. end for 14. end for 15. i++; 16.end while 算法第6行~第13行是關鍵,即判斷新的子節點u是否應加入樹中,并計算tr(u)和c(u)。核心的步驟是判斷c(u)是否達到閾值θ,若達到則將節點u加入樹中。 利用噪聲前綴樹發布泛化告警序列數據的基本思路是從葉子節點依次向上進行一次遍歷,計算在每個節點處v終止的告警序列數量count(v),并將count(v)個prefix(v,PT)加入到泛化告警序列數據集D中。count(v)的計算公式為: (4) 泛化告警序列數據的發布過程如算法2所示。 算法2泛化告警序列數據發布 2. if children(v)=?//如果v是葉子節點 6.end for 在識別頻繁入侵軌跡過程中,需要挖掘出頻繁告警序列。傳統的基于類Apriori的頻繁序列模式挖掘方法需要生成候選序列集,需要遍歷數據集的次數過多,而PrefixSpan算法可以在不生成候選序列的情況下高效挖掘頻繁序列,有效減少了遍歷次數和挖掘時間。因此,本文提出基于PrefixSpan的入侵軌跡序列挖掘方法,算法的具體步驟如下: 步驟3輸出滿足min_sup的 步驟4在各后綴數據庫內,重復步驟1~步驟3,對于新生成的頻繁告警序列,加上其前綴作為長頻繁序列輸出,直到生成的后綴數據庫為空為止。 在泛化告警序列數據發布和頻繁入侵軌跡序列挖掘過程中,僅僅是使用了加噪前綴樹作為輸入,并沒有在發布和挖掘中對數據集進行隱私保護操作,因此,這兩部分過程不占用隱私保護預算。 綜上,第2.1節~第2.3節提出的告警關聯過程滿足ε-差分隱私保護要求。 實驗計算機配置如下:操作系統為Ubuntu 16.04,CPU為3.30 GHz,內存為2.99 GB。使用LLDoS1.0攻擊場景中inside內網的流量數據。該攻擊場景數據取自一個典型的分布式拒絕服務攻擊案例,該攻擊場景的具體過程已通過官方文檔給出。實驗通過將得到的攻擊軌跡與官方文檔描述進行對比來驗證本文方法的有效性。 利用入侵檢測系統Snort處理LLDoS1.0 inside攻擊場景數據,并激活Snort的全部rules規則,得到的攻擊告警數據記錄共1 820條。實驗中各告警類型代表的主要攻擊行為及其在DDoS中對應的攻擊階段如表1所示,其中,告警類型和主要攻擊行為的信息均由Snort提供。 表1 告警類型、攻擊行為及攻擊階段間的對應關系 在以上的告警數據庫中,將特定時間窗內的告警按時間順序排序,生成原始的告警序列數據庫。在不同隱私保護預算下,利用第2.1節提出的方法構建噪聲前綴樹,并在此基礎上利用第2.2節方法生成泛化后的告警序列數據集。不同隱私保護預算下,泛化數據集中告警序列的數量如表2所示,其中結果取10次實驗的平均值。 表2 泛化數據集中告警序列的數量 在泛化告警序列數據集中,利用第2.3節提出的頻繁告警序列挖掘算法挖掘頻繁告警序列,通過反復實驗,當時間窗口取120 s、支持度閾值min_sup取0.01時,關聯準確度最高。此時,不同隱私保護預算下得到的告警關聯結果如表3所示,其中結果為取10次實驗的平均值。 表3 不同隱私保護預算下的告警關聯結果 考慮到在特定時間窗內相鄰攻擊步驟間的關聯為正確關聯,由表1中各攻擊步驟之間的遞進關系可知,在表3中,type1→type2、type2→type3、type3→type4和type4→type5為正確關聯,type2→type5和type1→type4為誤關聯。關聯準確率的計算公式為: (4) 其中,NCOR_T為正確關聯數,NCOR為所有關聯數。因此,原始數據集和泛化數據集的關聯準確率如圖2所示。 圖2 原始數據集和泛化數據集的關聯準確率 由圖2可以看出,當隱私保護預算ε>0.5時,本文算法的關聯結果準確率達到較高水平。因此,本文算法可以在實現隱私性的情況下,保證告警關聯結果具有較好的準確性。另外,圖2中當隱私保護預算ε較小時,關聯準確率隨著ε的增加而顯著增加,當ε增大到一定值時,關聯準確度的增加速度趨于平緩,而考慮到隱私保護預算ε與添加噪聲的尺度參數成反比,因此用在處理LLDoS1.0 inside攻擊場景對應的告警序列數據集時,隱私保護預算ε取0.5~1.0有利于實現算法隱私性和可用性的平衡。 本文利用基于Laplace機制的噪聲前綴樹對告警序列數據進行泛化,使其滿足差分隱私保護要求,并利用頻繁序列挖掘完成告警關聯分析,實現了告警序列隱私性和告警關聯準確性的折中。下一步將利用告警關聯分析的結果識別網絡攻擊軌跡,并獲取關鍵網絡節點和網絡安全態勢信息。此外,為更好地緩解告警序列隱私性和告警關聯準確性之間的矛盾,在保證隱私保護水平的前提下,將綜合利用Laplace機制和指數機制減少隨機噪聲的添加量。 [1] FRIEDBERG I,SKOPIK F,SETTANNI G,et al.Combating advanced persistent threats:from network event correlation to incident detection[J].Computers & Security,2015,48(7):35-57. [2] 張小松,牛偉納,楊國武,等.基于樹型結構的APT攻擊預測方法[J].電子科技大學學報,2016,45(4):582-588. [3] 胡 彬,王春東,胡思琦,等.基于機器學習的移動終端高級持續性威脅檢測技術研究[J].計算機工程,2017,43(1):241-246. [4] ALI A R,MORTEZA A,REZA E A.RTECA:real time episode correlation algorithm for multi-step attack scenarios detection[J].Computer & Security,2015,49:206-219. [5] KAYNAR K,SIVRIKAYA F.Distributed attack graph generation[J].IEEE Transactions on Dependable and Secure Computing,2015,5(1):12-23. [6] MODAMMAD G,ABBAS G B.E-correlator:an entropy-based alert correlation system[J].Security and Communication Networks,2015,8(5):822-836. [7] 劉 敬,谷利澤,鈕心忻,等.基于神經網絡和遺傳算法的網絡安全事件分析方法[J].北京郵電大學學報,2015,38(2):50-54. [8] CHEN R,FUNG B,DESAI B C.Differentially private trajectory data publication[EB/OL].(2011-12-09)[2017-01-21].http://arxiv.org/abs/1112.2020. [9] XU D B,NING P.Privacy-preserving alert correlation:a concept hierarchy based approach[C]//Proceedings of the 21st Annual Computer Security Applications Conference.New York,USA:[s.n.],2005:53-62. [10] 馬 進,金茂菁,楊永麗,等.基于序列模式挖掘的隱私保護多步攻擊關聯算法[J].清華大學學報(自然科學版),2012,52(10):1427-1434. [11] 盧國慶,張嘯劍,丁麗萍,等.差分隱私下的一種頻繁序列模式挖掘方法[J].計算機研究與發展,2015,52(12):2789-2801. [12] 柴瑞敏,馮慧慧.基于聚類的高效(K,L)-匿名隱私保護[J].計算機工程,2015,41(1):139-142. [13] DWORK C.A firm foundation for private data analysis[J].Communications of the ACM,2011,54(1):86-95. [14] 宋 健,許國艷,夭榮朋.基于差分隱私的數據匿名化隱私保護方法[J].計算機應用,2016,36(10):2753-2757. [15] 張嘯劍,孟小峰.面向數據發布和分析的差分隱私保護[J].計算機學報,2014,37(4):927-949.


2.2 泛化告警序列數據發布
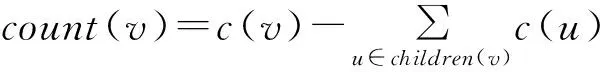






2.3 頻繁入侵軌跡序列挖掘

2.4 算法隱私性分析


3 實驗與結果分析




4 結束語
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
當代陜西(2021年17期)2021-11-06 03:21:36
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
電子制作(2018年18期)2018-11-14 01:48:24
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
山東工業技術(2016年15期)2016-12-01 05:31:22
