復雜高維數據中異常點挖掘算法研究*
2018-06-01 06:54:51徐曉丹
浙江師范大學學報(自然科學版) 2018年2期
徐曉丹
(浙江師范大學 數理與信息工程學院,浙江 金華 321004)
0 引 言
異常點挖掘是數據挖掘領域的一個重要分支,其目的是在數據集中找出那些明顯偏離常規數據對象的點,這些點往往表現為由不同的機制產生[1].目前對異常點沒有統一的定義,一般是指那些行為模式明顯區別于普通數據的點.在某些文獻[1-4]中,異常點也被稱為離群點、不一致點(discordant object)、例外點(exception)、 差錯點(aberration)、特色點(peculiarity)和驚奇點(surprise)等.不同的術語反映了在不同的情形下,研究者對待這類數據的不同方式.
隨著數據挖掘需求的深入,那些包含重要信息的異常點正受到越來越多的重視.實際上,在很多應用中,人們更關注的是那一小部分表現異常的數據,因為這些數據中往往包含著重要信息.例如,異常網絡傳輸行為預示著黑客或病毒入侵,異常的地質活動有可能是地震或海嘯的前兆,異常的天氣數據有可能預示著極端天氣的發生等等.這些偏離常規的數據,可能正是某種規律的真實反映,往往比正常數據更有價值.因此,對異常點的檢測研究在信用卡欺詐、網絡入侵檢測、疾病診斷、突發事件檢測、時空數據異常等領域已成為數據分析的主要對象,越來越彰顯其價值[4-9].
傳統的異常點檢測算法面對高維復雜數據時效率明顯降低,為了解決這個問題,出現了很多新的算法,這些算法能有效地處理高維數據.這些最新算法主要包括基于近鄰的方法、基于子空間的方法和基于集成的方法.
基于近鄰的方法主要是根據一個點在其近鄰的排序值來獲得異常度值,這些近鄰包括k近鄰[10]、反向近鄰[11]和共享近鄰[12].在k值的選擇上,文獻[13]提出了一種基于迭代隨機采樣策略的排序算法,該方法定義了一個可觀測因子(observability factor,OF)來衡量一個點的異常值,為了確定最佳的k值,該方法還定義了OF的信息熵,使OF的熵值達到最大的k值,就是最佳的k值,因為此時OF值的區分性最大,即每個點的Outlier的排序能力最大.基于近鄰方法都是在所有的維度空間中進行計算,然而隨著維度的不斷增加,很多異常現象只在由少部分維度組成的子空間中體現,如果在所有維度中進行計算,那么那些不相關的維度就會干擾計算結果,影響算法的效率.因此,查找和異常特性相關的有效子空間,是高維空間異常點檢測的一個關鍵,也是當前研究的一個熱點.
基于子空間的異常點檢測方法主要可以歸納為兩類:一是基于稀疏子空間查找方法[14-16];二是相關子空間查找方法[17-23].基于稀疏子空間方法根據用戶給定的稀疏系數的閾值,將整個數據集映射到稀疏子空間中,那些在子空間中出現的數據被認定為異常點.基于相關子空間方法的基本原理是找到和異常特性相關的子空間,在這些子空間中計算點的異常值.基于相關子空間的異常點檢測算法是一種精確查找策略,為了得到算法最優需要遍歷所有可能的子空間,就不可避免地存在子空間組合爆炸問題.隨機采樣子空間的方法不需要遍歷所有的子空間,但由于采樣的不完整性可能會造成一些異常點不能被識別出來.
基于集成的方法是對現有的這些算法進行有效集成.目前,在合適的子空間上集成異常點算法越來越受到研究者的關注[24].隨機子空間集成方法[25]的原理是每次隨機選擇d維數據生成子空間,在子空間內使用LOF算法得到異常點值,將這些異常點值合成后得到最終的結果.該方法存在的一個問題是對算法的選擇順序較為敏感,導致算法的穩定性得不到保障.文獻[26]提出的方法不是采樣特征維度,而是通過隨機采樣數據集中的數據對點進行局部密度估計,以減少集成算法的時間開銷.為了提高算法的準確率并降低時間開銷,文獻[27]提出了一種基于特征集成和數據采樣的異常點檢測方法,該算法是對文獻[25-26]提出方法的綜合:使用文獻[25]提出的Feature Bagging獲得集成算法中每次迭代的子空間,在計算異常點時使用文獻[26]的子采樣Subsample方法獲取計算所需要的數據.此算法中每次迭代使用隨機采樣特征得到子空間的方法提供了集成算法部件的多樣性,在獲取一個點的局部區域時添加Subsample方法可以有效提高算法的精度并節省計算時間.
為了更好地分析上述算法的特性,本文對上述算法進行了深入的分析,相較于以往文獻[3-9]中只提供部分算法比較而言,本文通過一系列實驗,使用不同評價指標提供了較為全面、系統的算法比較,同時,本文采用的10種算法是上述這3類最新算法的典型代表,更能綜合地分析算法的性能,以期為新算法的研究提供一定的參考.
1 實驗結果及分析
本文在ELKI[28]提供的平臺上對10種代表性算法在8個數據集上進行測試比較,這些算法包括基于統計的方法GUMM[29]、k近鄰相關算法(kNN,kNNW,ODIN,LOF,FASTABOD,LoOP)、基于子空間的方法(COP,SOD)和基于集成的算法(HiCS).本實驗采用的數據集來源于UCI數據集,異常點的預處理采用文獻[30]的方法.表1列出了實驗中使用的數據集,每個數據集包括數據集名稱、數據大小、異常點的個數、屬性值及異常點的類別.例如,SpamBase數據集中包含4 601個數據,其中異常點的個數有1 813 個,實驗中把non-spam這一類作為異常點處理.
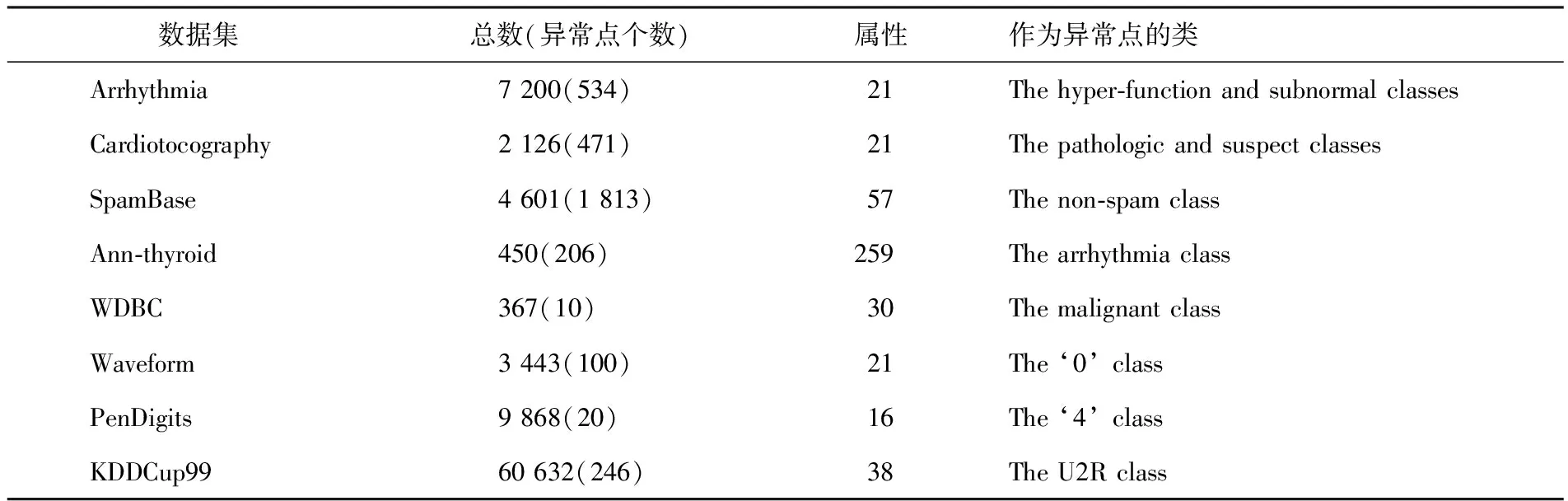
表1 實驗用數據集
精度是衡量異常點檢測算法的一個常用指標.圖1列出了10種算法在8個數據集上的精度r-precision[31](下文用r表示)的比較結果.
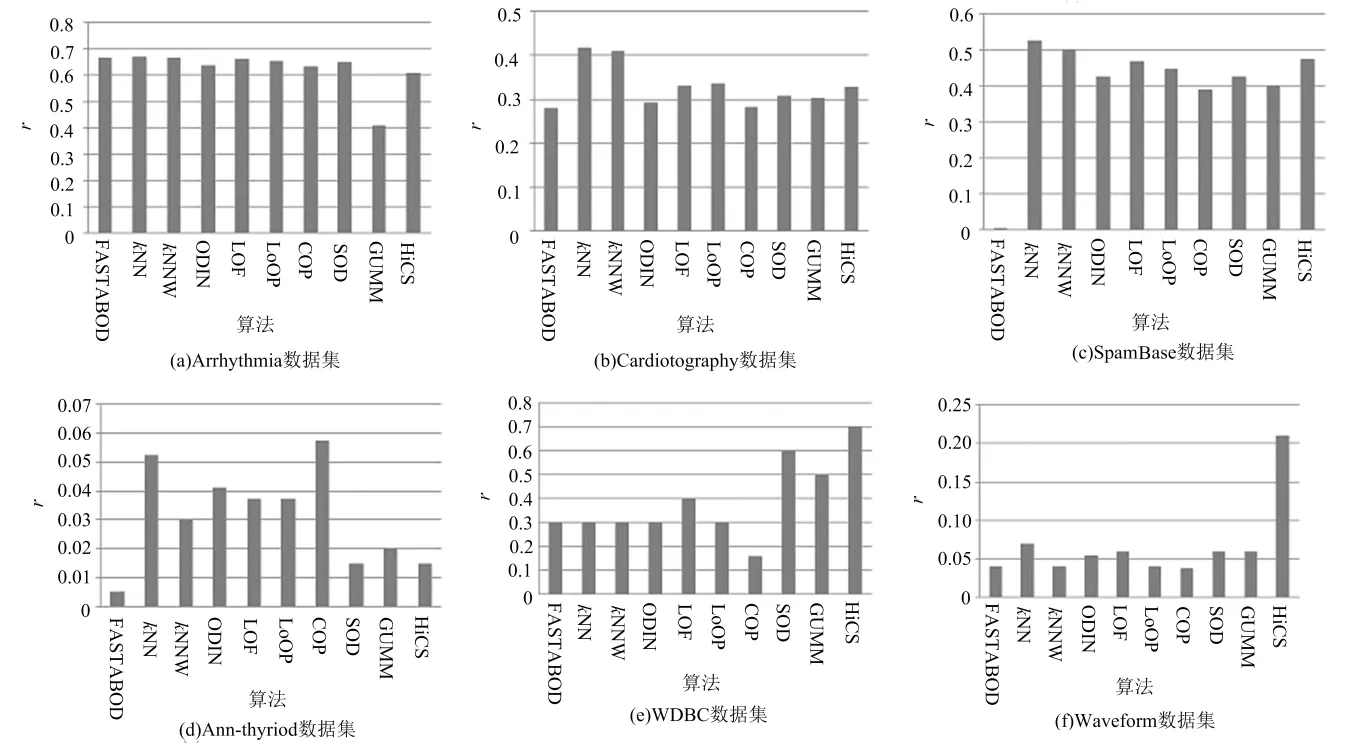
圖1 不同數據集上精度r值比較
從圖1可得到,基于近鄰的算法在各個數據集中的結果較為穩定,在Arrhythmia,Cardiotography,SpamBase和Ann-thyriod這4個數據集中精度r的值為最優.而HiCS算法和FASTABOD算法在不同的數據集上差異較大,例如,HiCS算法在WDBC和Waveform中效果最好,在PenDigits,KDDCup99和Ann-thyroid 這3個數據集中效率最低;對FASTABOD算法來說,在 PenDigits數據集上得到了最優值,而在SpamBase 和 Ann-thyroid 上的值最低,其部分原因在于這些數據集中異常點的個數相對于正常點來說比例太低,從而導致r值偏低.
另一個值得注意的是,在PenDigits數據集中,FASTABOD算法要顯著高于其他算法,其原因在于該數據集的屬性描述的是0~9的數字信息,這些屬性是相關聯的,因此,采用余弦相似度計算的FASTABOD算法能夠得到較好的效果,而對于WDBC 和 Waveform等包含較多不相關的屬性的數據集來說,基于子空間的方法SOD及子空間集成方法HiCS表現突出.
基于高斯的異常點檢測算法主要依賴于數據的分布,因此,在WDBC數據集上獲得了較好的效果,而在Arrhythmia,Ann-thyriod等數據分布無規律性的數據集上效率較低.
除了精度值r外,AUC(area under the corresponding curve)[8]是評價異常點檢測算法的另一個常用指標,它計算的是ROC(receiver operating characteristic)曲線的面積,ROC曲線的每個點是不同概率下真正類率(true positive rate)和負正類率(false positive rate)的比值.圖2給出了FASTABOD,kNN,kNNW,ODIN,LOF,LoOP和HiCS這些算法在AUC上的值,同時為了分析k值對算法的影響,給出了k從3變化到50的曲線.
從圖2可以得到,kNN,kNNW算法在各個數據集上的AUC值普遍較好,而HiCS算法在各個數據集上的差異較大.例如,在WDBC和Waveform數據集上,HiCS的值要明顯優于其他算法,而在Arrhythmia數據集上效率最低.值得注意的是,FASTABOD算法在SpamBase數據集上的AUC值異常低,幾乎為0,部分原因是數據集中異常點個數比例偏小,還有部分原因和數據集本身的特點相關:SpamBase數據集描述的是電子郵件文檔中單詞和字符出現的頻率,這些數字化的頻率信息幾乎沒有組的屬性,并且本質上沒有相似的性質.因此,FASTABOD算法不適合這樣的數據集,因為它是通過余弦來計算對象的相似性.
為了分析k值對算法的影響,圖2給出了k值取3到50時,各個基于k近鄰算法的AUC值比較結果.由于HiCS在高維數據和較大數據集上運行較慢,所以該算法在Ann-thyriod和KDDCup99中的運行結果在圖2中不顯示,FASTABOD算法在數據集KDDCup99運算中由于內存不足問題終止了計算,其計算結果也沒有在圖2中顯示.
從圖2可以看出,受k值影響最小的是FASTABOD算法,它在這些數據集中的值隨k值的變化非常小;受k值影響最大的是HiCS算法.就基于距離的算法而言,kNNW由于進行了加權調整比kNN更加穩定,而對基于密度的算法來說,采用局部密度統計的算法LoOP受k值的影響比LOF算法要小得多.
同時可以觀察到的另一個現象是,所有的算法在KDDCup99 和 PenDigits這2個數據集上的AUC值變化幅度明顯要高于其他數據集.這是由于這2個數據的異常點比例值要明顯小于其他數據集(其中KDDCup99為0.4%,PenDigits為0.2%).同理,對SpamBase(39.4%的異常點)和Arrhythin (45.7%的異常點)這2個數據集來說,由于包含的異常點比例較高,因此,這2個算法受k值的影響相對小一些.
算法效率是衡量異常點檢測方法實際應用的一個重要方面,表2給出了這10種算法在不同數據集上的運行時間.由于KDDCup99數據集包含6萬多條數據,因此,其運行時間明顯大于其他數據集,本次不列入表2進行比較.從表2可以看出,基于近鄰的方法(kNN,kNNW,ODIN,LOF,LoOP)的效率明顯高于其他算法,另外,HiCS算法在每一個數據集上的時間復雜度都高于其他算法,這是因為算法本身需要遍歷所有可能的子空間.
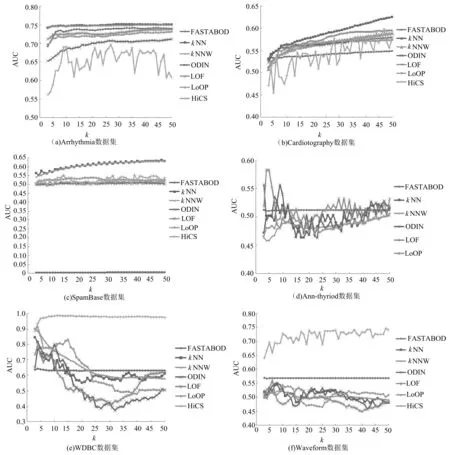

圖2 不同數據集上AUC值比較(k從3到50)
2 結 語
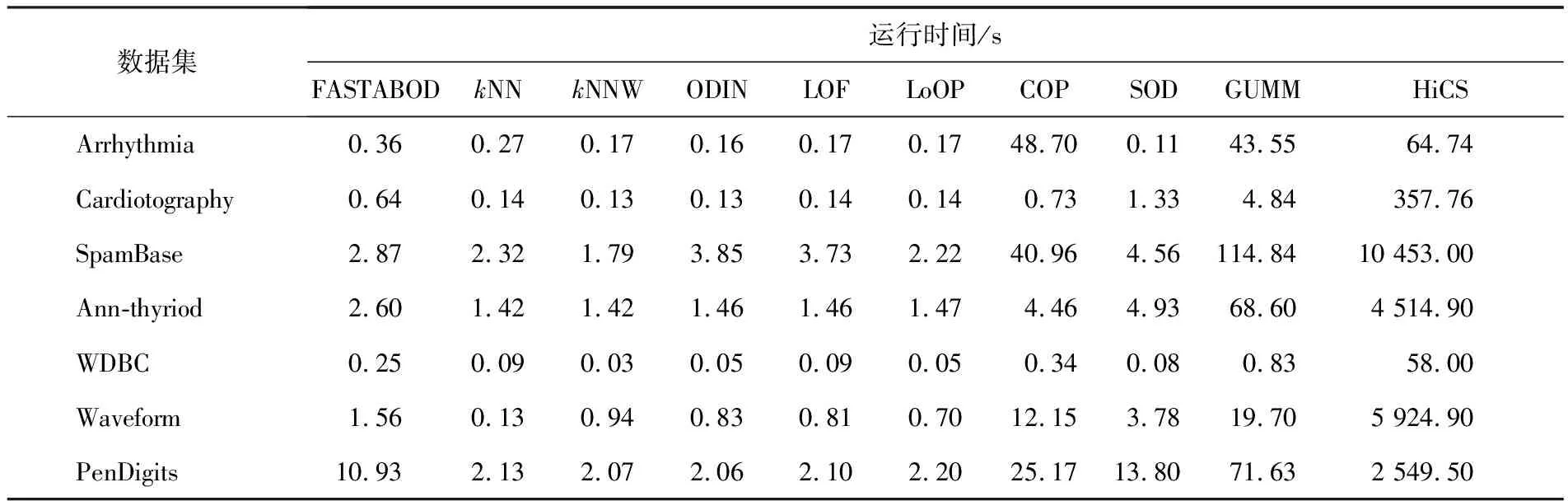
表2 異常點檢測算法在各個數據集上的運行時間
在以上分析中給出了最新的高維數據異常點檢測方法的實驗分析比較及算法特性分析.在異常點檢測領域,面對日益復雜的數據,新的問題不斷涌現,主要體現在以下幾個方面:
1)基于近鄰的異常點檢測算法通常對鄰居數目k值的選擇較為敏感,如何找到最合適的k值是基于近鄰算法的一個難題.
2)異常點(離群值)往往表現出局部的異常行為.然而,在高維空間中對特征進行局部相關性分析并非一件易事,同時,如何準確測量相關性便成為更具挑戰性的問題.
3)集成算法是提高算法效率的有效途徑,而高維數據中部分維度與異常點的檢測任務無關,因此在子空間上作特征的集成是一種較為有效的集成方法.利用窮舉法獲取的子空間雖然精度高但存在組合爆炸的問題,使用隨機子空間的方法,如何保證隨機子空間方法的精度是目前面臨的一個問題;此外,集成方法中一個關鍵是如何針對異常特性選擇準確率高的算法,如何來評價這些算法的優劣,對這些問題的深入研究值得期待.
4)由于異常點在數據集中所占的比例非常低,缺乏評價的統一標準,因此,如何對異常點檢測算法進行有效的評價也是一個懸而未決的問題.
異常點挖掘作為數據挖掘領域的一個熱門分支已在越來越多的領域展開研究.本文針對當前異常點挖掘所面臨的數據高維和復雜問題展開深入分析,通過實驗詳細分析了當前最新的相關技術的特性,并對當前面臨的主要問題及進一步研究方向進行了有效探討.
參考文獻:
[1]Chandola V,Banerjee A,Kumar V.Anomaly detection:A survey[J].ACM Computing Surveys,2009,41(3):1-58.
[2]Hodge V,Austin J.A survey of outlier detection methodologies[J].Artificial Intelligence Review,2004,22(2):85-126.
[3]Zhang Y,Meratnia N,Havinga P.Outlier detection techniques for wireless sensor networks:A survey[J].IEEE Communications Surveys and Tutorials,2010,12(2):159-170.
[4]Gogoi P,Bhattacharyya D K,Borah B,et al.A survey of outlier detection methods in network anomaly identification[J].Computer Journal,2011,54(4):570-588.
[5]Kaur G,Saxena V,Gupta J P.Anomaly detection in network traffic and role of wavelets[C]//International Conference on Computer Engineering and Technology.Chengdu:IEEE,2010:46-51.
[6]Phua C,Lee V,Smith K,et al.A comprehensive survey of data mining-based fraud detection research[J].Artificial Intelligence Review,2010,21(3):60-74.
[7]Gupta M,Gao J,Aggarwal C C,et al.Outlier detection for temporal data:A survey[J].IEEE Transactions on Knowledge and Data Engineering,2014,26(9):2250-2267.
[8]Zimek A,Schubert E,Kriegel H P.A survey on unsupervised outlier detection in high-dimensional numerical data[J].Statistical Analysis and Data Mining the Asa Data Science Journal,2012,5(5):363-387.
[9]Aggarwal C C.Outlier analysis[M].New York:Springer,2013:50-89.
[10]Huang H,Mehrotra K,Mohan C K.Rank-based outlier detection[J].Journal of Statistical Computation and Simulation,2013,83(3):518-531.
[11]Radovanovic M,Nanopoulos A,Ivanovic M.Reverse nearest neighbors in unsupervised distance-based outlier detection[J].IEEE Transactions on Knowledge and Data Engineering,2015,27(5):1369-1382.
[12]Pan Z M,Chen Y L.Local outlier detection algorithm based on shared reversek-nearest neighbor[J].Computer Simulation,2013,30(2):269-273.
[13]Ha J,Seok S,Lee J S.A precise ranking method for outlier detection[J].Information Sciences and International Journal,2015,324(S):88-107.
[14] Zhang J F,Zhang S L,Chang K H,et al.An outlier mining algorithm based on constrained concept lattice[J].International Journal of Systems Science,2014,45(5):1170-1179.
[15]Aggarwal C C,Yu S.An effective and efficient algorithm for high-dimensional outlier detection[J].The VLDB Journal,2005,14(2):211-221.
[16]Zhang J,Jiang Y,Chang K H,et al.A concept lattice based outlier mining method in low-dimensional subspaces[J].Pattern Recognition Letter,2009,30(15):1434-1439.
[17]Dutta J,Banerjee B,Reddy C K.RODS:Rarity based outlier detection in a sparse coding framework[J].IEEE Transactions on Knowledge and Data Engineering,2016,28(2):483-495.
[18]Kriegel H P,Kroger P,Schubert E,et al.Outlier detection in axis-parallel subspaces of high dimensional data[C]// Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining.Berlin:Springer-Verlag,2009:831-838.
[19]Emmanuel M,Schiffer M,Seidl T.Adaptive outlierness for subspace outlier ranking[C]//ACM Conference on Information and Knowledge Management.Toronto:ACM, 2010:1629-1632.
[20]Emmanuel M,Schiffer M,Seidl T.Statistical selection of relevant subspace projections for outlier ranking[C]//Proceedings of the 27th International Conference on Data Engineering.Hannover:IEEE Computer Society,2011:434-445.
[21]Keller F,Emmanuel M,Bohm K.HiCS:High contrast subspaces for density-based outlier ranking[C]//Proceedings of the 28th International Conference on Data Engineering.Arlington:IEEE,2012:1037-1048.
[22]Stein B V,Leeuwen M V,Back T.Local subspace-based outlier detection using global neighbourhoods[C]//International Conference on Big Data.Washington:IEEE,2016:43-53.
[23]Zhang J,Yu X,Li Y,et al.A relevant subspace based contextual outlier mining algorithm[J].Knowledge-Based Systems,2016,99(S):1-9.
[24]Aggarwal C C.Outlier ensembles[J].Acm Sigkdd Explorations Newsletter,2017,14(2):49.
[25]Lazarevic A,Kumar V.Feature bagging for outlier detection[C]//Proceedings of the 17th International Conference on Knowledge Discovery and Data Mining.Chicago:ACM,2005:157-166.
[26]Zimek A,Gaudet M,Campello R J G B.Subsampling for efficient and effective unsupervised outlier detection ensembles[C]//Proceedings of the 19th International Conference on Knowledge Discovery and Data Mining.Chicago:ACM,2013:428-436.
[27]Pasillas-Diaz J R,Ratte S.Bagged subspaces for unsupervised outlier detection[J].Computational Intelligence,2016,33(3):507-523.
[28]Achtert E,Kriegel H P,Reichert L,et al.ELKI data mining[EB/OL].(2010-03-01)[2010-08-10].https://elki-project.github.io/releases/.
[29]Eskin E.Anomaly detection over noisy data using learned probability distributions[C]//Proceedings of the 17th International Conference on Machine Learning.San Francisco:ACM,2000:255-262.
[30]Campos G O,Zimek A,Campello R J,et al.On the evaluation of unsupervised outlier detection:Measures,datasets,and an empirical study[J].Data Mining and Knowledge Discovery,2016,30(4):891-927.
[31]Craswell N.Encyclopedia of database systems[M].Berlin:Springer,2009:2453-2455.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
