大數據支持下的走班制教學質量評價
2018-06-05 01:28:15天津市天津中學賈永金
天津教育 2018年4期
■天津市天津中學 賈永金
隨著互聯網的快速發展,人類已悄然進入大數據時代。大數據也給教育帶來巨大的變革。
當下,在新高考改革下,教學要滿足學生的個性化選擇,最好的方式就是實行選課走班制。采用選課走班制,就要有與之相匹配的教學評價方式。教育大數據的發展,實現了教育過程的數字化,為我們探索新的教學評價方式提供了可能。
首先我們來了解大數據,大數據又稱巨量資料,信息社會里,各種信息都可稱為數據。數據信息可以劃分為兩大類:一類能夠用數據或統一的結構加以表示,我們稱之為結構化數據,如數字、符號;而另一類無法用數字或統一的結構表示,如文本、圖像、聲音、網頁等,我們稱之為非結構化數據。生活中產生的原始信息數據,絕大多數是非結構性數據。為了便于分析,提高數據分析的效率,常常把非結構性數據信息,部分轉化為結構性數據信息,從中發現問題,尋找規律。然后再回到原始的信息數據中,把發現的問題和規律,回歸到原始數據背景中對照,分析問題和規律的特殊性,達到應用全數據分析和解決問題的效果。
利用全數據的一般過程:收集數據,轉化數據,分析數據。下面以教學數據為例來說明。
一、收集數據
教學過程中的信息都應該收集,包括學生的作業,學生作答的試卷,教師的教案,以及師生活動的視頻等。
二、轉換為可用數字表示的結構性數據
在原始的非結構性數據上,加載上結構性數據的特征,例如考試命題時,教師根據學段需要學生學會的知識點框架匹配具體試題,賦予每道題具體的分數,這樣每道題就有了帶數字特征的知識點信息,從而把試卷的部分信息就轉化成了具有數字特征的結構性數據。
三、數據的統計與分析
(一)介紹幾種解讀數據的方法
1.確定學生在全體中的相對位置。
常見的方法有三種:
(1)名次法:利用考試的實際分數排名,結合總人數,確定學生的相對位置。
(2)等級法:例如天津新高考改革的錄取計分方案(高考3+3模式)。
(3)標準分法
①含義:越大,學生成績之間差距越大,兩極分化越大;越小,學生成績越集中在平均分附近,學生兩極分化越小。
②標準分它符合正態分布,函數圖像如圖:
每個學生的實際分數都可以換算為標準分Z,Z的范圍為-4≤Z≤4,每一個Z的值都有一個對應的百分比。
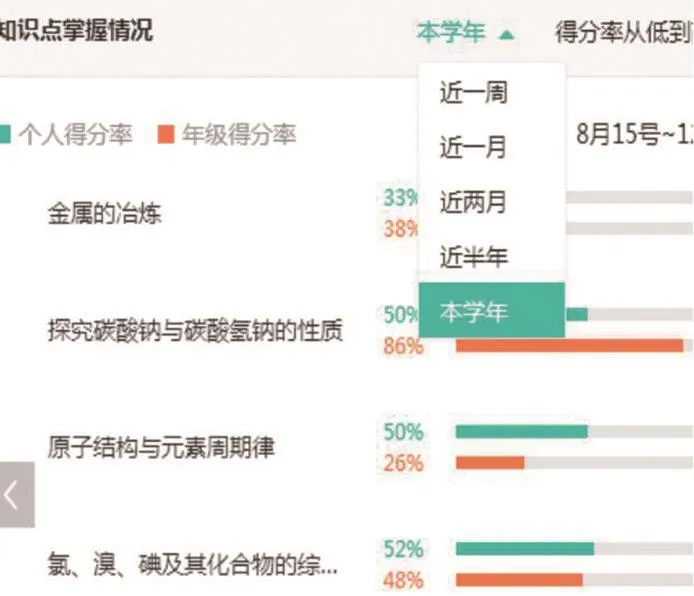
2.確定學生對知識的掌握程度。
正答率=。通常及格率,就是正答率為60%,對知識掌握了60%的程度。
(二)科學解讀數據
1.學生層面
(1)利用常模參照(增量參照)判斷自己各科和總分在群體中的位置。
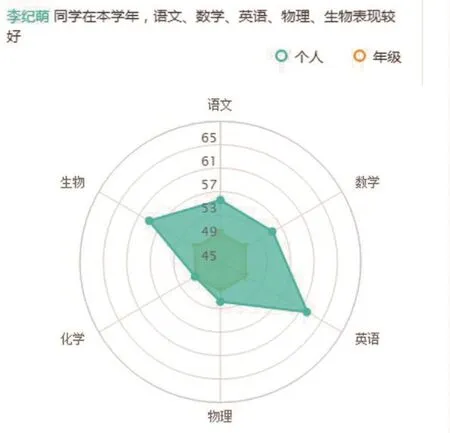
(2)確定自己對知識的掌握程度。
通過解讀數據化的學習過程,學生可以明確奮斗方向,制定合理的學習目標,科學調整學習策略,做出合理的生涯規劃。
2.教師層面
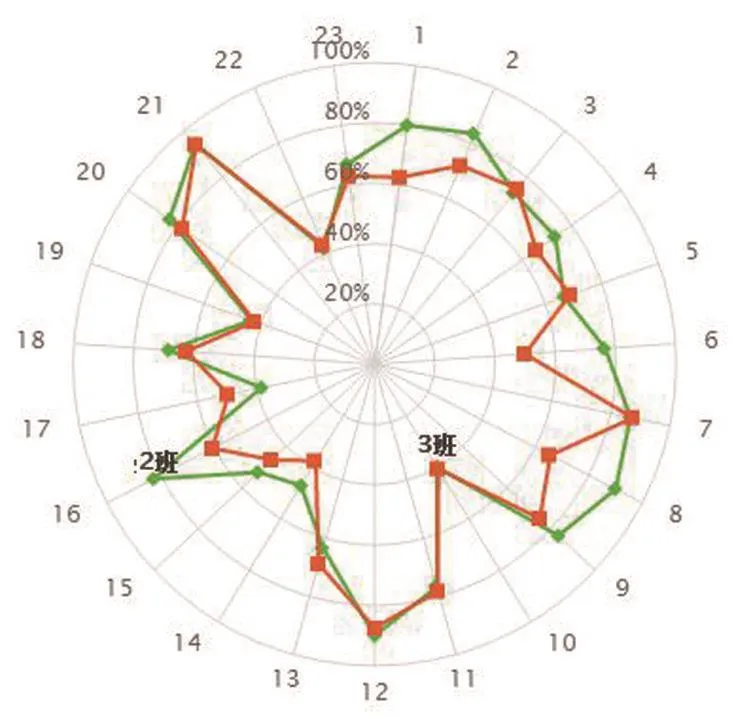
(1)判斷班集體在群體中的位置。
(2)確定班集體對知識的掌握程度。
教師通過解讀數據化的教學過程,了解學生的行為起點,明確教學改進方向,確定教學補救基點,合理制定教學方案,科學選擇教學策略。實現因材施教,成就學生夢想。
3.學校層面
(1)選課走班制下,對原始平均分差值的解讀。
選課走班制下的班級,不再會有學生程度相近的平行班級,各班的學生程度不再相同,考試時,班與班的平均分差距多少合理呢?再有,平均分的差值受到試題難易程度的影響,不同考試,差值無法固定。
由數理統計原理知道,兩個班級的平均分的差距由兩方面組成。一方面,主要由學生的智力因素決定的內因引起的,這是很難改變的;另一方面,主要由學生的學習狀態、應試技巧、教師的投入程度等外部因素引起的,通過師生的努力是可以改變的。
通過判斷內外因差距,合理地引導師生奮斗目標和努力方向,高效地為師生的工作和學習服務。
(2)有利判斷全校各班各科均衡發展情況。
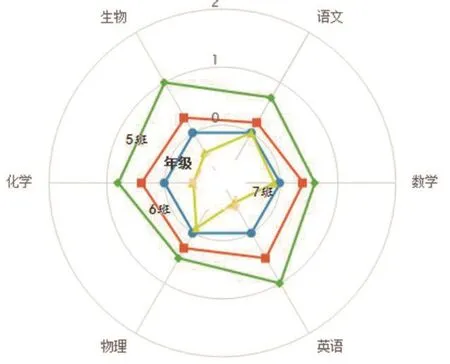
學校通過解讀數據化的師生教與學的過程,合理引導學生發展的方向,提高教師管理工作的科學性,適時監管教育目標和教育質量,強化過程管理,實現教育公平從機會公平向過程公平轉變,力爭實現教育的公平公正。
分析數據的目標不是為了評價,是為了更好地為教學服務。不能唯數據論,要讓數據聯系實際,分析數據產生的深層原因,才能作出科學合理的判斷。
猜你喜歡
快樂語文(2021年27期)2021-11-24 01:29:04
甘肅教育(2020年14期)2020-09-11 07:57:50
甘肅教育(2020年22期)2020-04-13 08:11:16
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
東方教育(2017年19期)2017-12-05 15:14:48
中華手工(2017年2期)2017-06-06 23:00:31
唐山文學(2016年2期)2017-01-15 14:03:59
中外會展(2014年4期)2014-11-27 07:46:46
吐魯番(2014年2期)2014-02-28 16:54:42
體育師友(2013年6期)2013-03-11 18:52:18
