基于可穿戴傳感器的人體活動識別研究綜述
2018-07-25 07:41:08鄭增威杜俊杰霍梅梅吳劍鐘
計算機應用 2018年5期
鄭增威, 杜俊杰,2,霍梅梅*,吳劍鐘
(1.浙江大學城市學院杭州市物聯網技術與應用重點實驗室,杭州310015; 2.浙江大學計算機科學與技術學院,杭州310015)(*通信作者電子郵箱huomm@zucc.edu.cn)
0 引言
近十幾年來,物聯網行業快速發展,隨著各種傳感器、電子設備體積的縮小,性能的提高,成本的降低,這些電子元件在生活中得到更加廣泛的應用。特別是可穿戴智能設備的研發以及人體活動識別在人體健康監控、娛樂、運動等方面的良好應用前景,使得基于傳感器的人體活動識別成為研究熱點之一。相比部署外部設備來識別人體活動狀態方式成本昂貴、可移植性差的缺點,可穿戴傳感器可以方便地通過集成傳感器采集人體的各項行為數據,以此識別人體的活動狀態。
實際上,人體活動識別的研究早在20世紀90年代末就已經展開:Foerster等[1]的實驗結果表明人體的行為活動與運動學之間存在緊密聯系,使用三軸加速度計采集行為數據來判斷人體的姿態和動作是切實可行的;Mantyjarvi等[2]使用主成分分析(Principal Component Analysis,PCA)和小波變換從原始傳感器數據中提取特征,在簡單人體活動(站立、上下樓梯、行走)識別中使用多層感知器使得識別精度達到了83% ~90%;Olguin等[3]使用了隱馬爾可夫模型(Hidden Markov Model,HMM)作為分類模型,對比了不同傳感器位置對最終分類結果的影響,實驗結果表明增加傳感器數量能提高分類精度;Wang等[4]提出了耦合HMM來識別智能家居環境中的多用戶行為,并開發了一個多模態傳感平臺來區分單用戶和多用戶的活動;Kwapisz等[5]提出了使用智能手機自帶傳感器來進行人體活動識別,在將上下樓梯視為同一動作時,分類精度達到了90%以上;Altun等[6]從計算成本、分類精度等方面對比了貝葉斯決策、最小二乘法、K最近鄰等多種分類方法在體育活動上的分類效果,實驗結果表明貝葉斯決策在計算復雜度最小的同時達到了最好的分類精度。
目前,典型的人體活動識別過程如圖1所示。首先數據采集系統從人體各處傳感器獲取運動數據,其中傳感器位置與具體的活動緊密相關;然后將傳感器數據進行去噪、平滑處理;接著對數據進行分段并提取出特征,其中最常見的分段技術的是滑動窗口技術,特征選擇的目的是為了降維,選擇與特定運動相關性比較強的特征,減少后續的計算量,提高分類精度;最后通過特征樣本訓練得到的分類器來識別出當前的人體活動。

圖1 典型的人體活動識別框架Fig.1 Framework of typical human activity recognition
1 原始數據的獲取
1.1 公開數據庫
人體活動識別的最終結果與數據集密切相關,在不同數據集上的實驗方法無法互相比較,目前已有的基于傳感器的公開數據庫如表1所示,這些數據集包含人體日常的幾個基本活動:站立、行走、坐、上下樓梯。
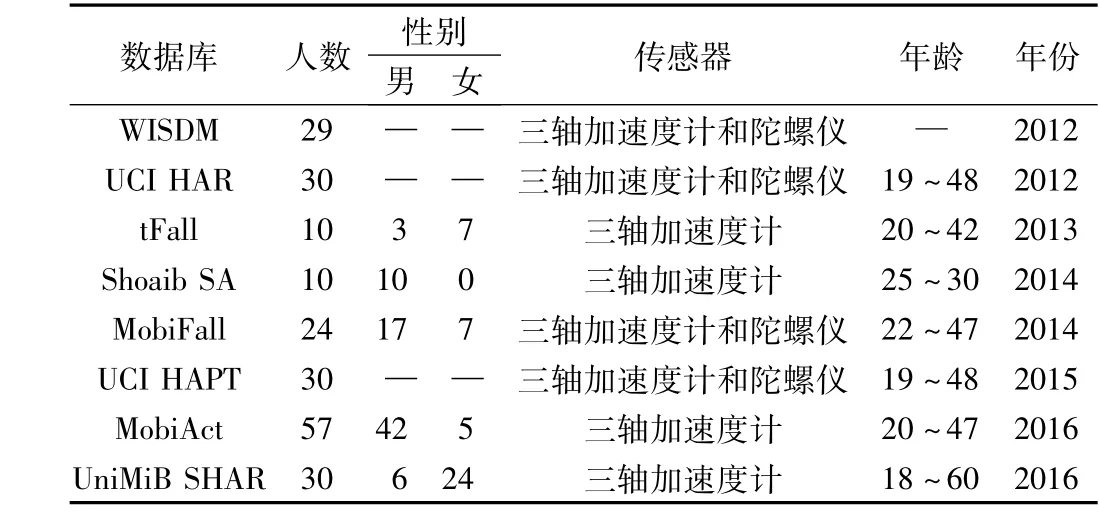
表1 公開數據集Tab.1 Public datasets
WISDM數據集[5]由使用三種不同手機上的傳感器在29個人身上測得的日常基本行為數據所構成;UCI HAR數據集[7]由戴在30個年齡在19~48歲的志愿者手腕上的智能手機傳感器采集得到,包括了三軸加速度計數據以及陀螺儀數據;tFall數據集[8]也由手機傳感器采集,不僅包括跌倒數據,也包含了人體日常行為數據,這些數據包括了志愿者一個星期的行為數據;Shoaib SA數據集[9]從10位男性志愿者身上采集得到,傳感器置于5個位置:左、右側的褲袋,右臂,右腕,腰部;MobiFall數據集[10]包含跌倒數據和日常行為數據,也采用手機中的傳感器來采集行為數據;UCI HAPT數據集[11]由從30個志愿者身上采集了5 h的運動數據構成,其運動類型還包括了過渡性的行為,比如從躺到坐的過程;MobiAct數據集[12]由MobiFall數據集擴展而來,包括57個志愿者的行為數據;UniMiB SHAR數據集[13]也使用手機傳感器作為數據采集裝置,手機位于志愿者左右褲袋,各占一半采集時長。
1.2 傳感器位置
對于人體行為活動,身體不同部位所傳遞出運動數據不同,這些數據對于識別精度的影響也不同。例如,在識別人體日常活動時,來自頭部的傳感器數據重要性相對來說比較低,然而在泳姿識別中卻十分重要,因此,對于特定的活動識別,尋找出具有最好識別效果的數據源十分有意義。
Kefer等[14]進行了動態手勢識別的最佳傳感器位置的研究,他們使用了手腕、手肘兩個不同位置的運動數據,實驗結果表明由于動態手勢在手腕上有著更大的運動半徑,位于手腕的傳感器數據的識別精度要明顯高于手肘;Cleland等[15]研究了不同傳感器數據組合對人體日常行為(Activities of Daily Living,ADL)(包括行走、站立、上下樓梯、躺、坐等日常行為)的識別效果,傳感器分別位于胸部、腕部、背部、臀部、大腿以及腳踝,實驗結果表明在使用單一傳感器的時候,使用位于臀部的傳感器表現出的識別效果最好,識別精度達到了97.8%;Pannurat等[16]在兩組不同年齡段數據集上研究了傳感器位置對識別精度的影響,傳感器位置分別位于頭部、手腕、胸部、手臂、腰部、大腿以及腳踝,實驗結果表明大腿、胸部、手腕部位的傳感器數據對于活動識別有著較好的效果,識別精度達到了96%以上。
以上研究表明,由不同人體部位運動數據訓練得到分類器的識別效果差異非常大,因此,針對具體的行為活動識別,尋找出最具識別能力的傳感器數據是達到最好識別精度的前提。
2 特征提取及處理
2.1 特征類型
特征工程是人體活動識別中的關鍵,對后續識別結果有直接的影響。而對于不同的人體活動識別,特征的選擇不是明確的。特征的數量十分多,簡單來說,可以分成時域特征、頻域特征以及時頻域特征。
1)時域特征。時域特征通常直接從原始數據中提取,是原始數據的統計量。常用的時域特征如表2所示。
2)頻域特征。時域特征在行為識別中使用十分廣泛,但是,時域特征對噪聲、測量誤差不夠魯棒,受噪聲數據的影響較大,而頻域信息能夠很好地規避這一點。將時域信息轉換到頻域可以將這些噪聲數據過濾,并提取出有效的頻域特征來識別時域特征不能很好區分的行為活動。從時域轉換到頻域的過程中,使用較多的技術是快速傅里葉變換(Fast Fourier Transform,FFT)[17]。常用頻域特征包括光譜能量、頻率范圍、平均頻率、光譜熵、光譜質心等。
3)時頻域特征。小波變換[18]是提取時頻域特征的常用方法,是時域到頻域的局部變換,可以同時顯示信號的時間與頻率特征。Preece等[19]在實驗中對比了不同特征類型對分類結果的影響,研究表明時頻域特征能有效區分不同行為活動。
2.2 噪聲去除
由于加速度計本身的測量誤差、電噪聲以及外界的因素干擾,采集得到的傳感器數據總是夾雜著一些噪聲數據,這些噪聲會使得分類器產生分類偏差,因此,需要對數據進行濾波。常見的濾波方法包括均值濾波、高斯濾波、滑動平均濾波、小波濾波[25]等。
滑動均值濾波 滑動均值濾波是一種低通濾波器,對于高頻噪聲信號以及隨機誤差有較好的過濾效果。Xiao等[23]在泳姿識別研究中使用了三種不同的濾波器,分別是均值濾波、滑動均值濾波以及Prewitt邊緣濾波器,實驗結果證明滑動濾波器的效果最佳。滑動均值濾波如式(1)所示:

其中:G為原始數據,M為滑動窗口大小,Gfilter為濾波之后的數據。
三次平滑算法 在去除噪聲的過程中,不僅要考慮去噪效果,也要考慮計算代價,例如卡爾曼濾波器[24],它是一種遞推的純粹時域濾波器,濾波效果好,但是它的缺點是計算復雜度高,在計算資源有限的環境中難以應用。Chen等[21]同時考慮到去噪效果及計算復雜度,使用五點三次平滑算法來去除噪聲數據并取得了較好的結果,如式(2)所示:
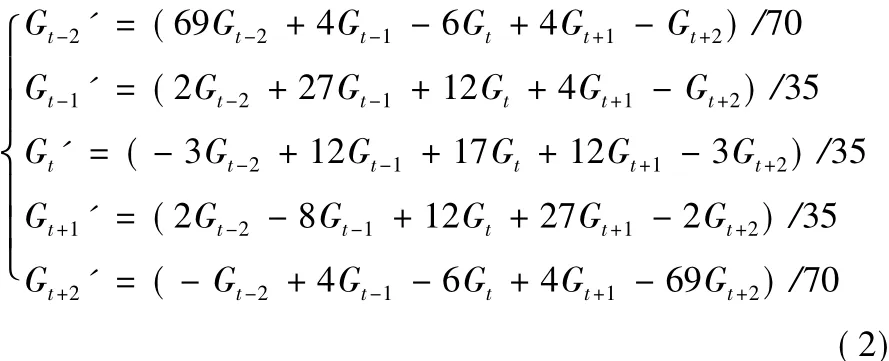
其中:(Gt-2,Gt-1,Gt,Gt+1,Gt+2) 為原始數據中相鄰的 5 個點,(Gt-2',Gt-1',Gt',Gt+1',Gt+2') 為過濾之后的數據。
小波濾波 小波濾波的基本思想是利用小波對原始數據在不同尺度上進行分解,有效信息的小波系數在不同尺度下相關性較強,而噪聲的系數相關性較弱,利用這點特性將噪聲數據從原始數據中去除。
2.3 滑動窗口技術
在人體活動識別中,傳感器數據是時間序列數據,難以將這些數據直接進行特征提取。目前,大多數活動分類方法都會使用分段方法將傳感器信號分成更小的時間段,對每個時間段進行特征提取,然后使用分類算法進行訓練,其中最常用的分段技術是滑動窗口技術。由于不同的行為活動中動作的持續時間不同,因此確定合適的滑動窗口的大小以及每次的滑動長度是該技術的關鍵。Chen等[21]在基于手機傳感器的人體活動識別研究中使用了窗口大小為1 s,窗口重疊率為50%(即每次向前滑動0.5 s)的滑動窗口,并根據峰值點來劃分不同的動作段。Xiao等[23]在泳姿識別中使用窗口大小2 s,滑動長度0.5 s的滑動窗口技術來獲取傳感器的數據(采樣頻率100 Hz)。Sztyler等[26]使用了窗口大小為1 s,滑動長度為0.5 s的窗口技術來對數據進行劃分(數據采樣頻率為50 Hz)。

表2 常用時域特征Tab.2 Time-domain features
以上研究工作使用的窗口大小均是固定不變的,但在實際中對于不同的動作,它們的信號特性是不同的。在一個完整活動過程中,固定大小的時間窗口無法對所有的動作做到良好的分割。因此,Noor等[27]提出了一種窗口大小可變的滑動窗口技術來適應不同動作的信號特性。該方法的基本思想是首先使用一個固定大小的窗口,并在劃分的過程中不斷通過概率密度函數來判斷是否需要調整窗口大小,以此來最終得到最佳的窗口大小,實驗結果表明,可變大小的窗口技術有效提高了活動識別精度。
2.4 特征選擇
原始數據經過特征提取可以得到一個特征集,這個特征集有可能十分龐大,其中存在某些冗余的,甚至會對識別精度造成負面影響的特征,同時也會增加不必要的計算。為了更精準地分類,確定一組具有較高辨別能力的特征集極其重要,一個好的特征集應該在相同行為之間顯示出很小的差異,同時在不同行為之間具有較大差異。
從評價準則的角度,特征選擇方法可以大致分成3大類,分別是過濾式(Filter)方法、封裝式(Wrapper)方法以及嵌入式(Embedded)方法[28]。其中:Filter方法的選擇過程僅僅與當前的特征集相關,它直接利用某種評價準則從特征集中選擇出最合適的特征子集,因此,這類方法的效率普遍較高。而Wrapper特征選擇過程還與后續學習分類的結果相關,它需要后續的學習結果作為反饋來調整特征集,因此這種方法效率相比來說不是很高,但是它的精度相對較高。Embedded方法是結合上述兩者方法優點的方法。目前在人體活動識別研究中,Filter方法使用得更為廣泛,按照評價函數,可以分為距離度量、信息度量、相關系數度量[29]等方法。
2.4.1 距離度量
距離度量的基本思想是使用距離來評價樣本之間的相似度,常用的距離包括歐氏距離、馬氏距離、平方距離[29]等。Relief算法[30]是一種經典的基于距離度量的特征權重迭代算法,它的運行效率非常高,與樣本的采樣次數以及特征集的大小成線性關系,因此應用十分廣泛。它的基本思想是根據式(3)對特征進行權重更新,權重越大,該特征的分類能力越強,當該特征的權重大于預先給定的閾值時,則將其加入特征子集。但是,Relief算法沒有將特征之間的關系考慮在內,因此該算法無法去除冗余的特征。其中:W(i)是特征i的權重值,diff(i,R,H)是與相同類別H中樣本的最近距離,diff(i,R,M)是不同類別M中樣本的最近距離。

Pannurat等[16]使用Relief-F對身體不同部位的行為數據進特征選擇排序,Relief-F是Relief算法的擴展,適用于多類別的情況。實驗結果表明不同部位的不同特征對于區分活動的重要程度也不盡相同。
2.4.2 信息度量
基于信息度量的特征選擇方法一般使用信息增益或者互信息[28]來衡量特征的作用,它的基本思想是篩選出具有最小不確定性的特征來進行訓練分類工作。mRMR算法[31]是典型的基于互信息的特征選擇方法,在考慮特征區分類別能力的同時,將特征之間的關系考慮在內,因而能去除冗余特征。mRMR算法的基本思想是使用互信息作為度量標準來計算特征子集與類別之間的相關性以及特征之間的冗余度,如式(4)所示。但是該算法未考慮特征的權重,無法體現不同特征的重要程度。
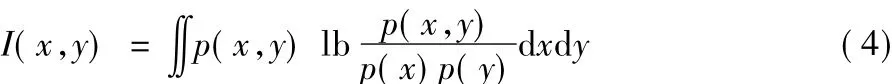
I(x,y)越大,說明x和y的相關性越高。利用這點特性,mRMR算法使用了最大相關性D和最小冗余度R的度量標準,并選擇使得D-R達到最大值的特征子集作為最終選擇出的特征集。
最大相關性:

最小冗余度:

其中:S是特征子集,x是某個具體的特征,c是類別。
Atallah等[20]在實驗中對比了 Relief-F、Simba Feature Selection、mRMR三種特征選擇方法,實驗結果表明根據不同語義層次的活動識別,選擇恰當的特征對于提高分類精度十分重要。
2.4.3 相關系數度量
皮爾森相關系數[32]是Pearson提出的用于衡量隨機變量X、Y之間的線性相關程度的指標。相關系數r的計算方法如式(7)所示:

其中:Cov(X,Y)為隨機變量X與Y之間的協方差,σx和σy分別是X和Y的標準差。
在特征選擇中,通常使用相關系數來計算特征之間、特征與類別之間的相關程度,從而完成特征的選擇。
3 分類方法
人體活動識別從本質上可以被認為是一個分類問題,即每個類別對應一個活動。目前,機器學習是構建分類器最常用的方法,按照模型的訓練類型可以分成為有監督學習、半監督學習、無監督學習、強化學習[33]。在有監督學習方法中,輸入數據是帶有標簽的訓練樣本集,訓練的目的是根據某種評價準則來獲得一個最優的分類器。根據分類原理的不同,有監督學習模型又可以分成生成模型、判別模型等。半監督學習是有監督學習和無監督學習的結合,它同時使用了未標記數據以及有標記數據來進行訓練,在降低訓練成本的同時保證了分類效果。無監督學習方法不需要有事先標記好的數據作為訓練樣本,它能自動根據數據之間的性質并對其進行聚類操作,但是由于人體活動的復雜多樣性,因此,在完全無監督的學習下識別不同的行為活動還比較困難。強化學習是一種邊獲得樣例邊學習的方式,每次使用獲得的樣例來更新現有模型,并根據該模型來指導下一步的行動,不斷重復迭代直至模型收斂。深度學習本質不是一種分類模型,而是一種學習方式,它能挖掘出更深層次、更具區分能力的特征,因此在模式識別中,深度學習成為研究的熱點。
3.1 判別模型
判別模型的思想是直接從有限的樣本中學習到決策函數Y=f(x)或者條件概率分布函數P(Y|X)。它并不關注輸出X與輸出Y之間的生成關系,學習的是不同類別Y之間的特征差異,利用這種差異來對X進行分類。典型的判別模型算法包括支持向量機、決策樹、人工神經網絡等。
3.1.1 支持向量機
支持向量機(Support Vector Machine,SVM)[20]是一種目前廣泛使用的分類器。它的思想是通過非線性的算法將數據從輸入空間映射到另一個特征空間,使得數據在這個空間中線性可分:Altun等[6]在19個不同人體日常行為識別的研究工作使用了7種不同的分類方法,在留1驗證法中,SVM分類器獲得了最好的結果,識別精度為87.6%;Beily等[34]使用了SVM模型來區分網球運動中四種活動(跑步、正手擊球、反手擊球、發球),在離線的訓練以及10折的交叉驗證實驗中,該分類方法的準確度為100%,在線分類實驗中,SVM分類器也達到了96.25%的準確度。
3.1.2 決策樹
決策樹構建一個樹狀的層次決策圖,是一種十分直觀便于理解的統計概率模型,其中每一個非葉子節點表示特征屬性的判斷條件,每一個分支表示在其父節點上特征屬性分類的結果,葉子節點表示最終的每一個類別[35]。由于其樹型的結構,每次分類的計算量不會超過樹的深度,因此決策樹具有計算量小的特點。決策樹的深度與特征的選擇密切相關,合適的特征作為屬性判斷節點可以減少決策樹的深度,從而提高分類效率。常用的決策樹算法主要包括ID3、C4.5、分類回歸樹(Classification and Regression Tree,CART)。Ohgi等[36]在蝶泳、蛙泳、仰泳自由泳4種泳姿識別中使用決策樹算法C4.5構建了深度為5的決策樹,最終的分類精度達到了91.1%。隨機森林是基于CART的一種分類器,本質上由多棵決策樹組成,這些決策樹相互獨立,即采用不同的樣本集訓練得到,最終根據多棵決策樹的投票結果來進行分類。Lombriser等[37]采用了隨機森林的方法來對8種不同的行為(上下樓梯、跳、躺、站立、坐、跑步、行走)進行識別分類,達到了89%的分類精度。
3.1.3 人工神經網絡
人工神經網絡是20世紀80年代興起的研究熱點,它的基本思想是模仿生物學上的神經網絡來構建大量神經元實現信息的處理[38],人工神經網絡的基本結構如圖2所示。

圖2 人工神經網絡結構Fig.2 Structure of artificial neural network

每個神經元Uk的輸出如式(9)所示,其中θ為神經元內部閾值,一般會隨著神經元的興奮程度而變化。

人工神經網絡在模式識別、智能控制等領域有著廣泛的應用,目前針對神經網絡的研究主要集中在網絡的構建和網絡參數的學習。神經網絡能自動從復雜數據中學習有用的特征、模式,因此在方法在人體活動識別應用十分廣泛。Panhwar等[39]使用了兩層的前饋神經網絡來識別5種不同的行為活動,在對比實驗中,神經網絡模型的識別效果要遠遠好于SVM;Kharrat等[40]在神經網絡模型中訓練了20個隱藏神經元,在溺水行為識別研究中,達到了100%的準確率。
3.2 生成模型
生成模型是相對判別模型的另一種有監督學習算法,與判別模型直接求解決策函數或者條件概率分布不同,生成模型是通過數據建立聯合概率密度分布函數P(X,Y),然后根據式(10)來求解后驗概率P(Y|X),從而完成分類,因此,生成模型關注的是數據生成過程。

其中,X是輸入信號,U是神經元,Wn,k是輸入信號n與神經元k之間的連接權重值,φ(i)為激活函數。每一個神經元Uk的輸入是輸入信號之間的加權和,如式(8)所示:n
常用的生成模型包括樸素貝葉斯模型、隱馬爾可夫模型[41]等。
3.2.1 樸素貝葉斯模型
樸素貝葉斯模型是一種基于統計的分類方法,它的基本思想是根據給定的待分類數據,分別求解在該數據屬于各個類別的概率,概率最大的類別即為最終的類別,如式(11)所示:
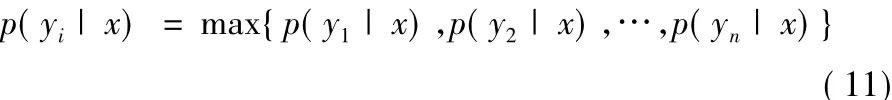
其中y是類別,x是待分類項。在樸素貝葉斯中,特征屬性之間相互獨立的,因此p(yi|x)可以通過式(12)進行求解。
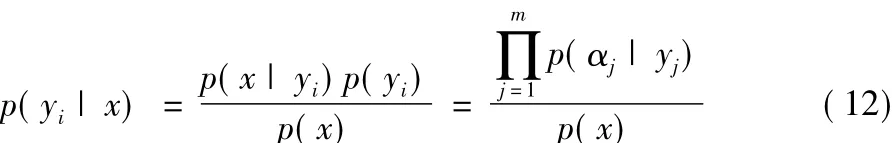
其中a是x的各項特征屬性。
Pannurat[16]在人體日常行為的識別研究中根據不同位置的傳感器數據使用了7種不同的分類方法,從整體分類效果而言,樸素貝葉斯模型要明顯好于其他幾種分類算法。
3.2.2 隱馬爾可夫模型
隱馬爾可夫模型是一種統計模型,是一個由隱含狀態、可見狀態、轉換概率、輸出概率來描述隱含位置參數的馬爾可夫過程,如圖3所示,其中Xi表示隱含狀態,Yi表示可見狀態,a表示隱含狀態間的轉換概率,b表示隱含狀態到可見狀態的輸出概率。

圖3 隱馬爾可夫鏈Fig.3 Hidden Markov chain
在人體活動識別中,隱含狀態即活動的類別,可見狀態即測得的傳感器數據。Cheng等[42]在人體活動識別研究中對每一個活動類別分別建立一個隱馬爾可夫模型,并對待識別活動的傳感器數據使用這些模型計算概率,概率最大的模型類別即為最終識別結果。
3.3 強化學習
強化學習的基本原理是通過Agent與環境進行交互,并獲得反饋信息,這個反饋信息有可能是強化Agent的對應行為,也有可能是抑制Agent的對應行為,它的最終目標是使得Agent選擇的行為能獲得環境的最大獎賞。強化學習的基本框架如圖4所示,其中有4個非常重要的概念:策略(policy)、獎懲反饋(reward)、值函數(value function)以及環境模型(environment model)[33]。

圖4 強化學習基本框架Fig.4 Framework of reinforcement learning
其中:t是時間點,A(t)是t時刻Agent的行為,S(t)是t時刻的狀態,R(t)是t時刻環境模型的獎懲反饋。
策略 規則是狀態到行為的映射,定義了Agent的行為方式,可以分成確定策略和隨機策略。
獎懲反饋 獎懲反饋是Agent執行相關動作后從環境中獲得的反饋信號。這個信號反映了在當前情景下,執行該動作的好壞,Agent根據這個反饋信號來調整自己的策略。
值函數 獎懲反饋反映當前動作的即時收益,而值函數定義了從開始狀態到達到目標所能得到最大獎懲反饋。
環境模型 環境模型定義了動作轉移概率以及動作的獎懲,即環境根據Agent的行為生成下一時刻的狀態和獎懲。
3.4 深度學習
深度學習作為最近幾年的研究熱點得到了快速的發展,在圖像識別、行為識別等領域得到了非常好的應用。深度學習的實質是構建具有很多隱含層的學習模型從海量的數據中學習到更相關、更有意義的特征,因此許多研究者將其應用到人體活動識別的特征學習中。Ronao等[43]使用卷積神經網絡(Convolutional Neural Network,CNN)來挖掘人體活動行為的內在聯系,并提出了一種自動提取魯棒特征的方法,實驗結果表明卷積神經網絡在對于傳統方法難以分辨的相似行為有著很好的區分能力,在6種不同日常行為活動的識別中達到了95.75%的分類精度。Hammerla等[44]在基于傳感器的人體活動識別中對比了三種不同的深度學習方法,分別是深度神經網絡(Deep Neural Network,DNN)、卷積神經網絡(CNN)以及長短期記憶網絡(Long Short-Term Memory,LSTM)。實驗結果表明:在大型的基準數據集上以及短時活動的識別上,LSTM相對來說具有最好的識別效果;而CNN更適用在重復性行為活動的識別。

表3 不同分類方法的比較Tab.3 Comparison of different classification methods
4 存在問題及展望
目前,盡管基于可穿戴傳感器的人體活動識別研究已取得較好的實驗結果,分類精度令人滿意,但是仍然存在以下問題值得進一步的研究。
第一,由于可穿戴傳感器本身的局限性以及外界環境的干擾,使得采集到的傳感器數據往往含有許多噪聲,目前存在滑動均值濾波、小波濾波等濾波技術只能在一定程度上去除噪聲,如何有效去除噪聲仍是待解決的難點。
第二,可穿戴設備在日常生活中的使用比較隨意,然而目前現有算法與設備擺放的位置、方式緊密聯系,因此,提取出與設備放置無關,能有效區分各種不同行為活動的特征仍是目前的研究熱點與難點之一。
第三,個體之間行為活動的差異性導致傳統靜態模型識別精確度不高,如何有效消除個體的差異,使得分類模型更具有廣泛適用性也是待解決的難點[45]。
第四,人體日常行為活動復雜多樣,目前人體活動識別大都集中在簡單活動的識別,比如:行走、跑步、上下樓梯等,如何結合情景環境信息(例如:全球定位系統信息)進行更高語義上行為上的識別[46]也是待研究的方向。
5 結語
本文從4個方面對基于可穿戴傳感器的人體活動識別進行了分析總結。人體活動識別流程一般經過數據采集,特征提取,特征選擇以及分類器的構建。人體不同部位的數據與行為活動緊密相關,針對區分不同行為,選擇合適數據源十分重要。特征工程是人體活動識別中的關鍵,提取的特征類型、處理方式直接影響后續的識別精度。特征選擇一方面降低后續計算量,另一方面有利于提高分類精度。在分類器方面,傳統的機器學習算法應用十分廣泛并取得了一定的識別效果,深度學習作為新的研究熱點也在活動識別中得到應用。最后分析了人體活動識別中各個環節還存在的問題并展望了基于可穿戴傳感器的人體活動識別的發展方向。
猜你喜歡
少先隊活動(2022年5期)2022-06-06 03:45:04
家庭科學·新健康(2022年3期)2022-05-10 00:32:13
中老年保健(2021年2期)2021-08-22 07:31:10
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
海峽姐妹(2018年3期)2018-05-09 08:20:40
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
