基于餐飲業網絡評論的消費者情感極性分析①
2018-08-17 12:06:18楊博文
計算機系統應用 2018年8期
楊博文
(南京財經大學 經濟學院 統計系,南京 210023)
1 引言
1.1 研究背景
在電子商務蓬勃發展的信息化時代,越來越多的互聯網用戶在線評價自己的消費,這些文本的評論信息作為消費者親身體驗的反饋,涵蓋了大量的有用信息.一方面以往消費者對產品的評價可以幫助潛在消費者事前對產品有所了解,便于消費者根據自身需要做出消費決策;另一方面也可以作為反饋信息幫助商家了解消費者的購買意愿、跟蹤商品的售后服務等,進而不斷改進、提高自身競爭力.
消費者情感極性分析[1–3](Sentiment Polarity Analysis)是文本分析的一大分支,一般可以分為積極(Positive)和消極(Negative)兩類,只有準確地把握了消費者的情感極性才能做好客戶的維護、挖掘潛在客戶、彌補欠缺進而提升自身的市場競爭能力.本文旨在運用高維數據變量選擇方法[4]關注兩方面的核心內容,一方面尋求較好的消費者情感極性預測模型;另一方面,以往的研究重在分類預測,而對評論背后隱含的商業價值很少深入探究,本文希望借助Lasso算法的變量選擇優勢挖掘出影響消費者情感極性的關鍵因素.
1.2 研究現狀
從國內外研究現狀來看,目前對文本數據的分析主要涉及提取文本特征、文本特征關聯分析、文本內容識別,以及文本情感極性分析等方面.其中提取文本特征是對文本信息進一步分析的基礎,所謂特征提取就是根據評論文本的分詞結果,選擇對文本具有代表性的關鍵詞.特征選取主要有兩種不同的思路,一種是構造評估函數法[5,6],另一種是在事先挑選的初始種子集為起點,對候選特征集合采用不斷迭代的方法確定最終的特征集合[7].
以往對特征提取和文本情感極性的分析,大都以詞頻和語義分析為主.Hu用形容詞作為觀點詞分析英文評論的情感極性,借助WordNet將要判斷情感傾向的詞條與給定情感傾向的同義詞或反義詞詞網相匹配,詞條的情感傾向與同義詞具有相同的情感傾向,與反義詞具有相反的情感傾向[8].Turney以形容詞和副詞為分析對象,運用PMI方法分別計算給定詞與“excellent”、“poor”的點互信息(PMI),兩者相減,若為正值則情感極性為正,反之為負.近年來,部分學者在對詞的分析上做了進一步延伸,如根據詞條在不同文本類別間分布不均的情況,提出了對特征項加權的方法判斷情感極性[9].隨著大數據時代的到來,相關的機器學習方法在情感極性分析中也越來越受歡迎[10–12].Pang等根據事先既定的有關形容詞的積極詞料集和消極詞料集,分別運用樸素貝葉斯(Naive Bayes)、最大熵(Maximun Entropy)和支持向量機(Support Vector Machines)三種方法進行文本的情感極性分析并在不同的情況下進行了對比[13].王健等基于主題概率模型(LDA)實現了文本分類,并取得較好的分類效果[14].
1.3 研究思路
以上研究對文本情感極性的預測,主要有兩種思路,第一種是由特征詞或特征項的情感極性加權進行預測;第二種是運用機器學習方法對文本的情感極性進行預測,主要包括支持向量機、樸素貝葉斯、最大熵等方法等.除此之外,鑒于L1-正則項對高維數據良好的懲罰特性,Lasso稀疏模型已經被成功的應用于文本分類領域[15–19].鑒于此,本文運用Lasso-Logistic和Lasso-PCA模型[20–22]對餐飲業文本評論的情感極性進行分析.一方面,作為對比找到更好的分類模型;另一方面,筆者借助Lasso-Logistic較好的模型解釋能力對影響消費者情感極性的關鍵因素深入分析.相比于Lasso-Logistic模型,目前鮮有對Lasso-PCA模型的應用文獻,基于稀疏數據的主成分模型在解決數據稀疏性的同時,保留了較多的變量信息,但該方法對文本的情感極性預測效果有待于探討.
根據以上文獻綜述,本文提出以下研究思路:(1)對數據進行預處理,包括提取評論樣本、分詞等.(2)運用TF-IDF算法初步提取關鍵詞.(3)分類預測.以消費者情感極性為被解釋變量,以高維稀疏關鍵詞詞頻矩陣為解釋變量,結合Lasso算法,運用帶懲罰的Logistic和PCA兩種方法對消費者情感極性進行預測.(4)借助Lasso的變量選擇結果,運用Logistic模型對顯著影響消費者情感的因素做進一步的分析.
2 數據來源與處理
2.1 數據來源
本文數據來源為大眾點評網上某餐廳的消費者評論的文本內容和評分等級,共2293條評論記錄.因變量是評論者對消費情況的總體評價的星級數據,分為5個等級,1顆星代表最低評價,5顆星代表最高評價.考慮到實際情況,消費者一般傾向于給出較高的星級指數,在評分為3的樣本中大都帶有消極的情緒,如表1所示.因此,在分析過程中將1顆至3顆星的樣本視為情感極性為負;將4顆星和5顆星的樣本視為情感極性為正.這里隨機抽取了400條積極樣本和400條消極樣本,作為對消費者情感極性分析的總樣本.

表1 部分樣本信息
首先提取1000個關鍵詞作為初始特征集,然后遍歷每一條評論的分詞結果,分別統計特征詞在每條評論中出現的頻數,以由此得到的稀疏矩陣作為解釋變量.不失一般性,在分析過程中選用樣本的80%作為訓練集,20%作為測試集進行樣本外預測.
2.2 數據處理
數據處理的第一階段是利用R軟件的加載包jiebaR對網絡評論文本進行分詞,首先在分詞的過程中去除常用停用詞(stop words,如介詞、冠詞、限定詞等);同時考慮到分詞結果會產生數值型的分詞結果,所以在數據的預處理過程中刪除了數值型的分詞結果;最后運用該軟件包提供的詞頻-逆向文本頻率算法(TF-IDF)提取關鍵詞,作為備選特征詞集合.
TF-IDF算法是提取文本關鍵詞常用的統計方法,用以評估一字詞對一個文本的重要程度.其基本思想是如果一個詞比較少見,但是它在這個文檔中出現多次,那么它很可能就反映了這個文檔的某方面特性,可以作為該文檔的關鍵詞.該算法分為詞頻(Term Frequency,TF)和逆向文本頻率(Inverse Document Frequency,IDF)兩部分.TF即一個詞在目標文本中出現的頻率,見式(1).IDF是對該詞代表的信息量的衡量,IDF值的計算需要一個詞料庫,由詞料庫中總文件數除以包含該詞的文檔數,再將商取對數得到,見式(2).TF - IDF值即TF與IDF的乘積,見式(3).這里選用的是R軟件jiebaR包自帶的詞料庫.
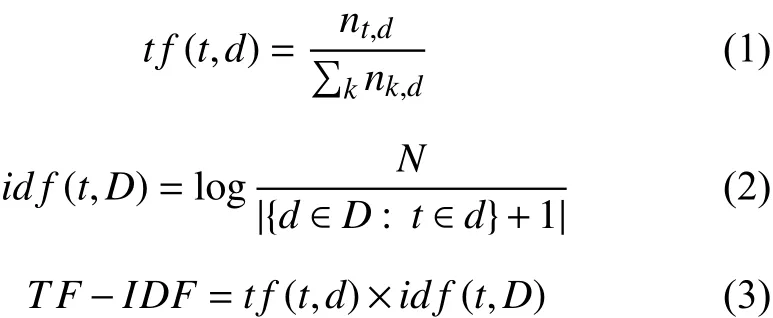
其中,nt,d是詞t在文檔d中出現的頻率;N代表詞料庫中的文件數,N= |D|;|{d∈D:t∈d}|代表詞料庫中包含詞t的文檔數,為避免該詞不在詞料庫中的情況,將|{d∈D:t∈d}|+1作為分母.
運用TF-IDF算法可以得到對文本內容具有代表性的關鍵詞,根據文本的分詞結果統計出1000個關鍵詞的詞頻矩陣,如表2所示.從表中可以看出,TFIDF值較大有“水煮魚”、“川菜”、“味道”和“毛血旺”、“宮保雞丁”等名詞性詞匯,以及“不錯”、“好吃”和“喜歡”等帶有情感極性的形容詞、副詞和動詞.

表2 部分關鍵詞詞頻矩陣
此外,從詞頻的角度來看,“味道”、“不錯”的頻率明顯高于“水煮魚”和“川菜”;但是從IF-IDF值來看,“水煮魚”和“川菜”的值則高于“味道”、“不錯”.這是因為,“味道”和“不錯”出現的頻率雖然高,但是對文本內容的代表性不夠,“水煮魚”和“川菜”則直接反映出了文本的主題,具有更好的代表性.同時可以看出,“水煮魚”和“毛血旺”、“宮保雞”具有較高的頻數和TFIDF值,且“水煮魚”高于“毛血旺”和“宮保雞”,說明這三個菜品在該家餐廳中比較具有特色,尤其是“水煮魚”,建議作為餐廳的特色菜來打造.同時也說明了以表2的關鍵詞詞頻矩陣作為解釋變量對文本的情感極性進行預測和分析,既很好的將文本型數據轉化為數值型數據又不失對文本內容的代表性.
3 消費者情感極性的預測模型
3.1 Lasso-Logistic預測模型
從表2的關鍵詞詞頻矩陣可以知道,解釋變量具有明顯的高維性和稀疏性的特點.由于關鍵詞數目過多,且大部分數據為0,為解決自變量矩陣中存在的奇異問題,必須首先對數據進行降維,這也是將Lasso算法運用到Logistic回歸和主成分回歸的根本出發點.
Lasso算法加入的懲罰項為L1范數,即參數向量中各個元素絕對值之和,由兩部分構成,一部分為Logistic回歸的負對數似然函數,另一部分為L1-正則項,Lasso的目的是求得使f(β)最小的解,即式(4)所示.
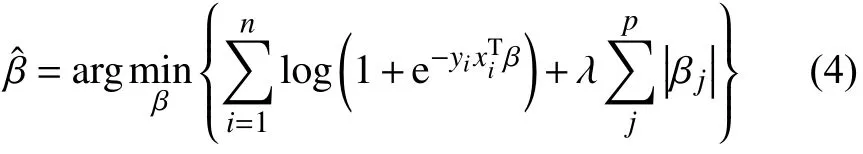
關于λ的選擇,這里運用的是10折交叉驗證的方法[23–25].本文借用R軟件中軟件包glmnet來實現Lasso算法,如需程序代碼,可向作者索取.
由于Lasso算法中λ的取值具有一定程度的隨機性,因此每次提取出的關鍵詞的個數并不相同,為了不影響預測結果,經過幾次實驗發現,在提取大于1000個關鍵詞時Lasso的稀疏解的個數沒有明顯增加,所以最終提取了TF-IDF值較大的前1000個關鍵詞詞頻作為初始解釋變量.由Lasso算法運用(4)式得到稀疏解,然后將得到的系數不為0的關鍵詞提取出來,作為最終Logistic回歸的解釋變量對消費者的情感極性進行預測.模型預測效果見表3和圖1.
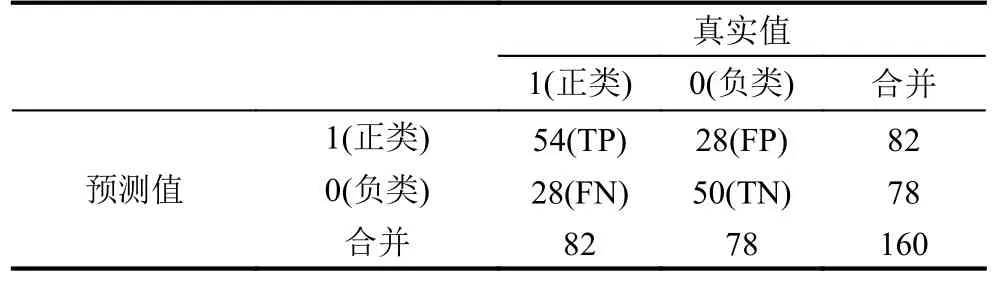
表3 Lasso-Logistic預測效果混淆矩陣
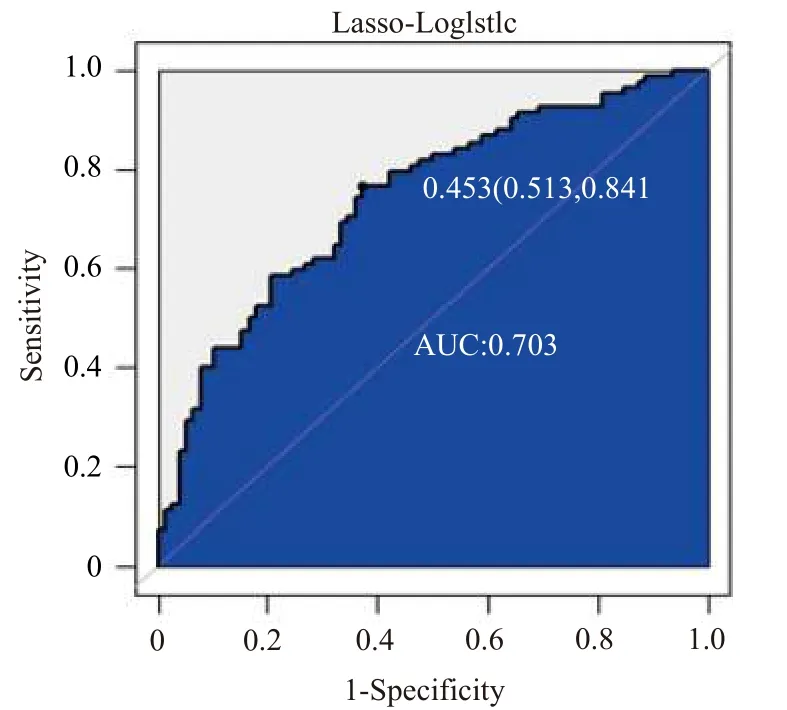
圖1 Lasso-Logistic預測結果的ROC曲線
表3列出了在分類閾值設為0.5時由Lasso-Logistic模型得到的測試集預測結果的混淆矩陣,根據混淆矩陣可以得到,模型對測試集預測精度為65%;同時由表3縱向比較結果可以得出,預測結果的敏感性(True Positive Rate,TPR)和特異性(False Positive Rate,FPR)分別為0.66和0.36,分別刻畫的是正確預測為正類占真實值中正類的比例、分類器錯認為正類的負實例占所有負實例的比例,如式(5),(6)所示.
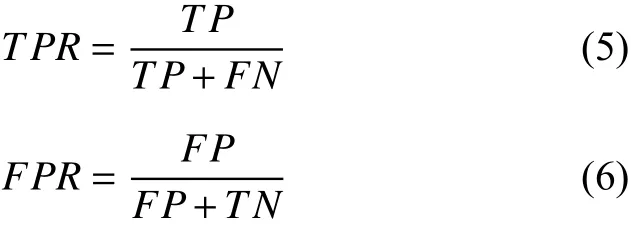
為了更好的體現出模型的預測效果,這里采用ROC曲線下面積(AUC)來評價模型的預測效果.從圖1中可以看出,模型預測得到的AUC值為0.703,Lasso-Logistic預測方法在基于文本評論的消費者情感極性的分析上是有效的.
3.2 Lasso-PCA預測模型
主成分分析(Principle Components Analysis,PCA)可以直接通過矩陣的奇異值分解(PMD)得到,如式(7)所示.具體來說,是通過對原始變量進行一個基的變換,實現變量的重新組合,組合后得到的p個新的變量稱為主成分,前r(r<p)個主成分攜帶了原始變量X的主要信息.主成分分析的優良特性使其在數據降維方面得到的廣泛的應用,然而在高維數據,尤其是稀疏的高維數據的情況下,傳統的主成分分析的求解受到挑戰.因此,本文借鑒文獻[22]提出的SPC方法,通過對V施加懲罰,L1-正則項,運用PMD(·,L1)來實現高維稀疏矩陣的主成分分析[22].
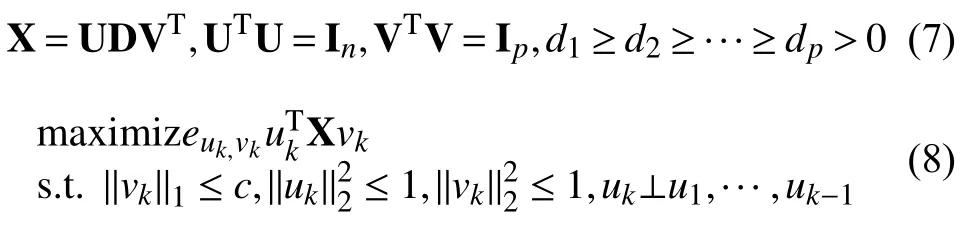
R軟件提供的PMA軟件包提供了很好的分析工具.為了使模型具有可比性,這里的主成分分析沿用上文中Lasso-Logistic預測模型抽取的測試集和訓練集,選取與Lasso-Logistic預測模型的變量相同數目的主成分,將Lasso-PCA得到的稀疏主成分作為解釋變量,運用Logistic回歸對消費者的情感極性進行預測,模型預測效果如表4和圖2所示.
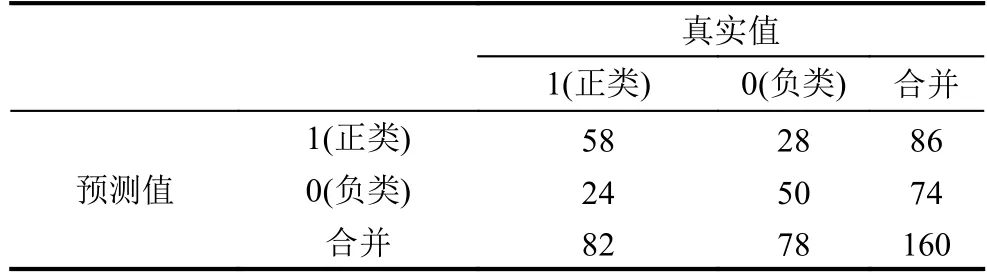
表4 Lasso-PCA預測效果混淆矩陣
同樣地,根據模型的預測結果可以得到Lasso-PCA對測試集預測混淆矩陣,如表4所示.根據表4可以得到,模型對測試集樣本預測的正確率為67.5%,靈敏性和特異性分別為0.71和0.36.因此,和Lasso-Logistic模型相比,Lasso-PCA模型具有更高的預測精度和靈敏性.仍然采用ROC曲線來進一步評價模型的預測結果,如圖2所示.本次抽樣得到的Lasso-PCA模型的AUC值為0.742,略高于Lasso-Logistic模型的AUC值0.703.綜合以上分析來看,Lasso-PCA模型對基于文本評論的消費者情感極性的預測是有效的,并且初步判斷Lasso-PCA模型比Lasso-Logistic模型具有更好的預測效果.
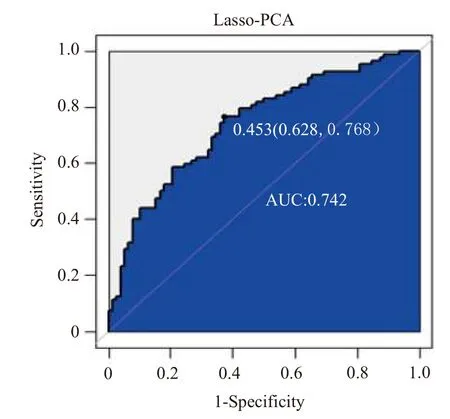
圖2 Lasso-PCA預測結果的ROC曲線
3.3 兩種預測模型的比較
以上關于Lasso-Logistic模型和Lasso-PCA模型的比較建立在一次抽樣的基礎上,由于每次抽樣都是隨機的,因此以上關于模型的比較也具有一定的隨機性,為了更好的比較兩個模型的預測效果,本文對以上研究過程重復100次,分別得到Lasso-Logistic模型和Lasso-PCA模型的100個AUC值,比較結果如圖3所示.
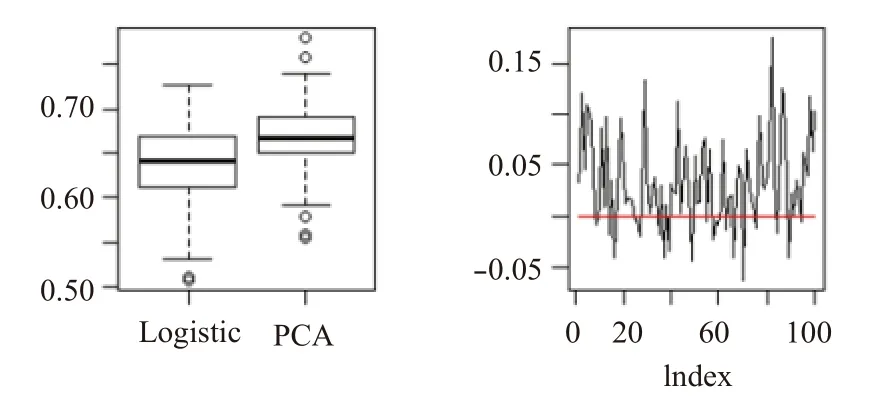
圖3 兩種預測模型預測效果比較
圖3 呈現出了100次實驗得到的預測結果的AUC值.由圖3(a)的箱線圖可以看到,Lasso-PCA模型的預測精度的平均值略高于Lasso-Logistic模型預測精度的平均值,其中Lasso-PCA模型得到的AUC的均值0.667,Lasso-Logistic模型得到的AUC的均值為0.635.對每次抽樣的預測精度求差,由Lasso-PCA模型的預測精度減去Lasso-Logistic模型的預測精度,兩者差值如圖3(b)所示.二者差值雖然在0的兩側都有分布,但上側明顯高于下側且上側的值的分布更密集,說明Lasso-PCA模型的預測精度相對高于Lasso-Logistic模型的預測精度.
4 消費者情感極性的影響因素分析
文本評論呈現了消費者對消費行為較為細致的評價,也是評分的根本依據,主要由評價對象和對評價對象的情感傾向兩部分組成.從餐飲業的角度來看,影響消費者情感極性的因素有很多,包括味道、服務、環境、地理位置、心理預期等等.探索這些因素是如何影響消費者評價的,對商家提高服務質量、改善營銷策略具有非常重要的意義.
Lasso-PCA模型雖有較好的預測效果,但模型的解釋能力欠佳,因此,考慮到Lasso-Logistic模型較強的解釋性,本文借助Lasso-Logistic預測模型變量選擇的結果進一步對影響消費者情感極性的影響因素進行分析.由于Lasso-Logistic模型中由Lasso算法得到的稀疏解具有一定的隨機性,本文進行了兩次回歸以減小隨機性對結果的影響.這里主要關注回歸結果中顯著的變量,結果如表5所示.

表5 兩個Lasso-Logistic回歸的結果
表5呈現出了回歸結果中顯著變量的相關信息,從表中可以看出,兩次回歸得到的顯著性變量存在很大的相似性.兩次回歸都得到了25個顯著變量,其中有23個變量在兩個回歸結果中同時顯著.此外,從回歸系數可以看出,所有在兩次回歸中同時顯著的變量具有相同的正負號,且系數大小相差不大,說明模型具有很好的穩健性.這些顯著的特征詞或特征項隱含了影響消費者情感極性的重要因素,按照屬性不同可以將其分成6類,如表6所示.
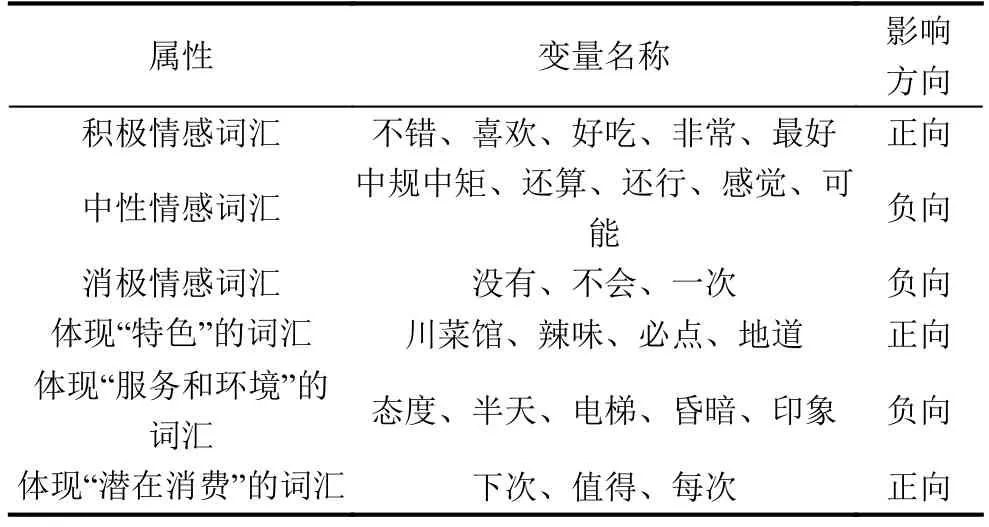
表6 顯著的回歸變量分類
三類帶有情感傾向的詞匯和三類表示特征屬性的詞匯分別從不同角度體現了消費者情感極性.從總體上來說,帶有情感色彩的詞匯最能直觀地表達消費者的情緒;雖然影響餐飲業消費者情感極性的因素眾多,但是餐廳“特色”、“服務和環境”卻是消費者最為關注的;通過關注含有“下次”、“值得”和“每次”的評論,可以有效識別潛在消費能力.具體地,從以下5個方面進行分析.
(1)從兩次回歸結果中可以看出,“不錯”、“喜歡”、“好吃”以及程度副詞“非常”和“最好”的系數在兩個回歸中的系數都顯著為正.相比之下,“沒有”、“不會”和“一次”這類含有負面情緒的詞匯,回歸系數顯著為負.這一結果也是符合常理的,好的評價對應高的評分;而對于沒有達到滿意的消費行為,消費者往往對不滿意之處吐槽,評分自然也低.
(2)“中規中矩”、“還算”和第一個回歸中“還行”的系數顯著為負,說明評論中出現“中規中矩”、“還算”這兩個詞匯的消費者對消費行為更加傾向于持負面的態度,服務中的美中不足之處很容易引起消費者的消極情緒.同時,這一結論對商家也具有一定的警醒作用,商家應該對此類評論加以重視,根據評論內容分析對應消費者的消費心理,撲捉到自身服務的欠缺之處,如果能夠彌補美中不足之處可能就會帶來意想不到的利潤.
(3)“必點”的系數在兩個回歸中的結果都顯著為正,體現出了消費者對某個菜品的青睞;“地道”和“川菜館”在兩個回歸結果中顯著為正,“辣味”也在回歸一中顯著為正,體現出了餐廳的獨特之處.這些都是最能體現出一個餐廳特色的詞匯,系數顯著為正的回歸結果說明餐廳特色菜是影響消費者評價的一個關鍵因素,說明餐飲業的商家在經營過程中要有能力打造出自己的特色,并且注重招牌菜的推廣,這在很大程度上有利于餐廳的經營,從而提升自身的市場競爭力.
(4)“態度”、“半天”、“電梯”以及第二個回歸中“昏暗”的系數顯著為負,說明服務態度和環境的好壞直接影響了消費者的心理,強調了餐廳服務態度和外部環境特征的重要性.現代人的消費觀念不斷轉換,對服務的要求也隨之提高,更是體現在方方面面.好的服務態度和就餐環境給消費者更加舒適、放松的感覺,直接影響消費者的情緒,對消費者的評分起到重要作用.
(5)“下次”、“值得”和“每次”的回歸系數顯著為正,體現出了顧客再次消費的潛質,說明這類消費者對消費行為的整體評價較高,再次消費的可能性很大.商家為提高顧客忠誠度、改善經營狀況,要時常關注這類消費者的消費動向,注意維護此類消費者的顧客忠誠度.
5 結論及啟示
本文將Lasso算法運用到網絡評論的文本分析中,首先建立了Lasso-Logistic和Lasso-PCA兩個模型對消費者情感極性進行預測.由分析結果可知,兩種預測模型都取得了一定的預測效果.根據100次隨機抽樣結果,Lasso-PCA預測模型的AUC平均值達到0.67,而Lasso-Logistic預測模型的AUC平均值為0.64.相比之下,Lasso-PCA模型整合了更多的變量信息,對文本的情感極性具有更好的預測效果;但是Lasso-PCA模型對變量的解釋能力較弱,尤其在解釋變量維度較高的情況下,Lasso-PCA模型很難分析出解釋變量對被解釋變量的影響.因此,文中第4節借助Lasso-Logistic模型分析了影響消費者情感極性的顯著性因素作為補充分析.結果表明,餐廳特色、餐廳的服務態度和外部環境等是影響消費者情感極性的主要因素.另外,“中規中矩”和“還算”兩個特征項的系數顯著為負也反映了消費者對消費行為的高標準、高期望,即使在市場逐漸細分的大環境下,商家要想維護顧客忠誠度以長期生存下去,也必須根據市場要求不斷完善自己.
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
今日農業(2020年20期)2020-12-15 15:53:19
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
瞭望東方周刊(2017年34期)2017-09-13 17:13:26
發明與創新(2016年16期)2016-08-21 13:56:16
發明與創新(2016年21期)2016-05-17 03:57:29
