面向拓片信息的甲骨字網絡構建與分析
2018-08-17 08:38:50焦清局金園園劉永革
中文信息學報 2018年7期
焦清局,高 峰,金園園,熊 晶,劉永革
(1. 安陽師范學院 計算機與信息工程學院,河南 安陽 455000;2. 河南省甲骨文信息處理重點實驗室,河南 安陽 455000;3. 漢語海外傳播河南省協同創新中心,河南 安陽 455000)
0 引言
甲骨文是一種距今有3 500多年歷史的古漢字,其所記載的內容極其豐富,涉及商代社會生活的諸多方面,不僅包括政治、軍事、文化、社會習俗等內容,而且涉及天文、歷法等科學技術[1]。對甲骨文進行深入的研究與探討,可以對語言文字學、考古學、歷史學、社會人類學等學科產生深刻的影響,具有重要的文化價值和傳承意義。目前國內外共收藏的甲骨片約有15萬片[2](數字會隨時間的變化而變化,如新出土甲骨片及甲骨片的綴合),被發現的甲骨文單字約有4 378個[3](2010年前所見殷墟甲骨字),但其中可釋者僅為1 682個[3]。因此,考釋字是甲骨文研究的主要任務。一百多年來,經過幾代學者的努力,在甲骨文字的考釋方面取得了豐碩的成果[4]。如郭沫若是第一個運用歷史唯物主義研究古文字的人,善于將文字考釋與史料分析相結合,進而研究中國古代社會。他在甲骨文字考釋方面取得了令人矚目的成績。歷史學家唐蘭,他不但考釋出很多難以辨識的甲骨文字,還建立了各種較為完整和系統的研究方法,如對照法、推勘法、偏旁分析法等。其他如董作賓、徐中舒也在甲骨文考釋方面取得了豐碩的成果。然而,純人工地研究甲骨文也存在許多缺陷:①專家們對甲骨文的辨識和翻譯只能依賴于長期的學術鉆研和經驗累積,而且培養一名甲骨文專家是無法速成的,往往需要一二十年甚至更長的時間[1]; ②甲骨文字之間不是孤立存在的,它們之間相互聯系和作用,從而形成一個成熟的文字系統。然而,歷史學家研究甲骨文的考釋時,只是孤立的研究,并不能從系統的角度揭示甲骨文字的場景和語義。
隨著對甲骨文的深入研究和其材料的數字化,甲骨文的數據已體現出海量化和系統化[5],這為使用計算機技術研究甲骨文提供了數據上的保障。甲骨文的研究也漸漸進入了以計算機研究和人工研究相輔相成的時代。為了解決甲骨文資料庫的缺陷,2007年,劉永革開發了甲骨文字的編輯軟件[6]。甲骨文字編輯軟件對甲骨文字的可視化研究開創了一種資料編輯的新方法,也為國內外的甲骨文學者們之間的相互交流提供了一個新的平臺。2008年,顧紹通等人對計算機中如何輸入甲骨文字也做出重要研究[7]: 首先對甲骨文字形進行深入研究之后發現,甲骨文的字形具有一定的規律。通過對《殷墟甲骨刻辭類纂》中收錄的甲骨文字形的拓撲結構進行深入分析之后,整理出了569個甲骨文字的偏旁部首。再把這569個偏旁部首分別配置到標準鍵盤的26個英文字母上之后,通過拆分取碼和現代漢字的拼音方法,使用標準鍵盤即可輸入3 673個甲骨文字(包含異體字合文)。甲骨文字輸入法的問世對甲骨文字的數字化 、展示 、有效保護和方便使用,具有非常重要的現實意義。2013年,酆格斐等人通過對原始拓片的預處理,并結合數學形態學方法提出12項指標描述甲骨字特征,這些特征較好地反映了甲骨文字的筆畫形態和結構[8]。2014年,安陽師范學院的高峰對諸多甲骨文語義進行研究后,構建了一個甲骨文領域的語義詞典系統[9]。作者通過不斷地對國內外甲骨文語義詞典的對比研究后,從其特點出發,對甲骨文語料中的原材料進行了精細的加工處理,并在甲骨文語義分類的基礎上對實詞做出了很多屬性描述,并建立了計算機的半自動化輔助加工模塊,用來服務于甲骨文輔助機器的翻譯和考釋工作。2014年,熊晶以許多甲骨文學家建立的甲骨文字庫為基礎,提出一種計算機輔助翻譯甲骨文的方法[10]。2016年,中山大學、北京微軟研究院以及瑞士日內瓦大學的研究人員通過圖像處理的方式識別甲骨字[11]。2016年,德國馬克斯普朗克研究所和上海大學的研究人員構建了有關動物甲骨字的認知網絡[12]。雖然一些計算機學家在研究甲骨文方面取得了顯著的成績,但是還存在一些問題需要繼續深入研究。如現有的算法在研究甲骨文字時,并沒有從系統的角度研究,導致使用計算機方法預測未知甲骨文字的語義距離還很遠。不僅如此,現有的計算機方法研究甲骨文時,并沒有考慮甲骨字之間的聯系對場景和語義的影響。
復雜網絡是描述復雜系統的一種有效工具,語言系統的網絡化抽象為研究語言提供了新的視角和手段[13]。目前,人們已經構建了漢語的同現網絡[14]、句法網絡[15]、語義場網絡[16]等。語言網絡的構建及其特征的分析對研究語言系統背后的形成機制和演化規律具有重要的意義[13]。在本文中,我們使用甲骨拓片信息構建甲骨文字網絡,并對網絡的特性進行詳細分析。本文的研究結果能為歷史學家和網絡甲骨學家揭示未知甲骨字的語義提供新的數據和研究思路。
1 甲骨字網絡構建
本文以收集的72 151片甲骨文拓片為研究對象,進而通過建模構建甲骨字網絡。由于甲骨拓片歷史久遠,拓片的損壞比較嚴重。因此,在構建網絡之前,對其進行相應的處理。第一,如果在一個拓片中,字和字之間有殘缺的情況,用省略號代替;第二,除去沒有甲骨字的拓片;最后共得到71 455片甲骨文拓片、6 199個已識和未識甲骨字。
由于甲骨文系統是中國最早的文字系統,語言特性還處于萌芽的狀態。因此,它和現有的成熟文字系統有很大的區別: 第一,在甲骨文系統中,同一拓片的甲骨字描述了同一個場景(或稱語義單元),如,戰爭、天象、婚娶等,但也有可能不同拓片中的甲骨字描述不同時段的場景。第二,在甲骨文系統中,單音節詞較多,而復音節詞較少。這也是古文字系統特有的屬性。
為了構建甲骨字網絡,需要定義甲骨字和甲骨字之間的相似性距離。由于甲骨文系統的同一場景或語義單元是以拓片為單位,所以,如果在一個拓片中,兩個甲骨字之間在n階Markov鏈的條件下同時存在,則認為這兩個甲骨字之間應存在一條邊。與劉知遠構建漢語網絡不同[14],本文中,在兩個甲骨字之間定義了相應的權重。對于同一拓片上的兩個甲骨字(這兩個甲骨字可以是已識或未識),它們分別用i和j表示,那么這兩個字之間的距離為wij(見公式1)。不僅如此,在n階Markov鏈中n在現代漢語中經常取值為2[14],因為現在的文字系統有大量的詞語。而在甲骨文系統,很少有詞組的出現。因此,在構建網絡時,對于不同拓片,n值選擇為拓片上甲骨字的個數。
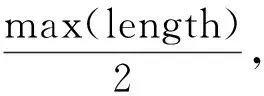
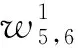

圖1 甲骨字之間距離計算圖
本文使用的構建甲骨字網絡方法具有三個創新點: 一是在構建網絡的過程中,充分利用了拓片在甲骨文系統中作為語義單元的信息,即拓片中的甲骨字不論是已識或未識,根據式(1)~(2)都可以構建它們之間的距離。因此,未識和已識的甲骨字出現在同一個網絡中,這種現象為我們依據已識的語義信息破譯未識甲骨字提供可能;二是構建網絡的方法體現了甲骨文系統中復音節詞較少的古文字特征;三是在構建網絡的過程中賦予甲骨字之間相應的權重,利于分析甲骨字之間的同現信息。
2 甲骨字網絡特性分析
為了驗證甲骨字網絡是否具有真實網絡的特性,本文對構建網絡的度分布、局部連接比率、聚類系數、模塊度等特性進行分析。
2.1 度分布
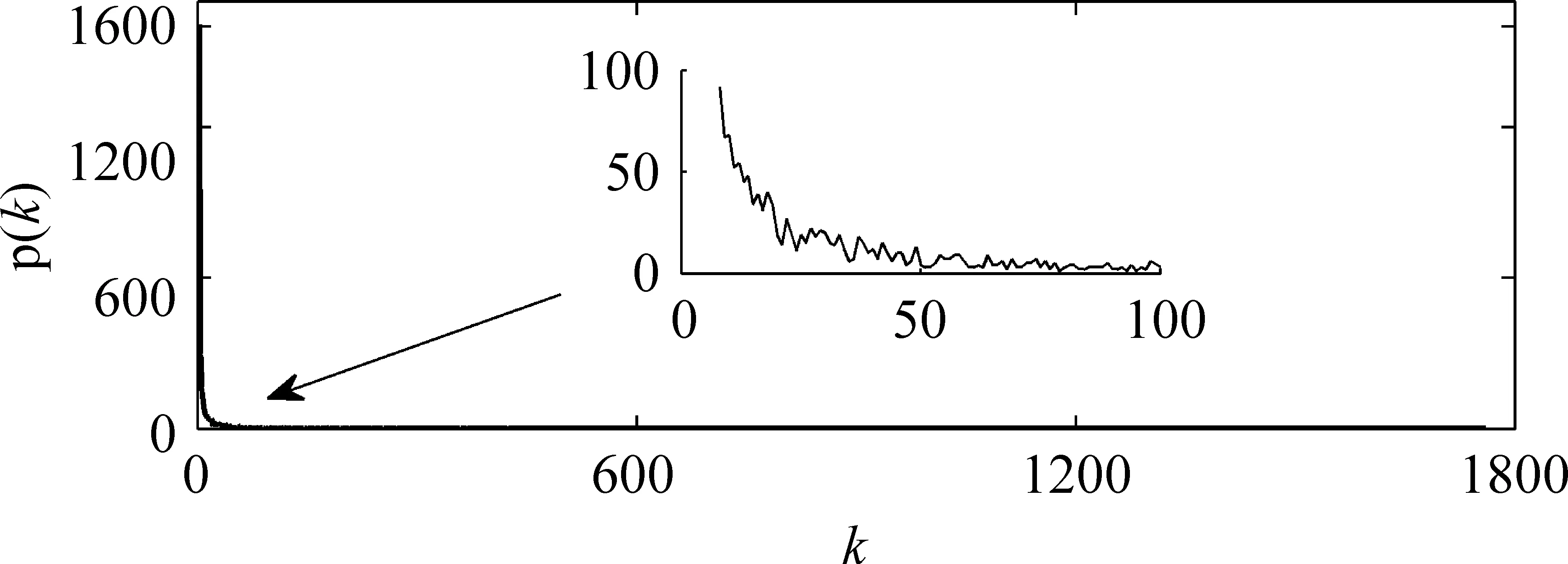
圖2 甲骨字網絡的度分布
一個節點的度是此節點的鄰接節點的個數或者是節點連接邊的個數。如果我們把節點度為k的數目占網絡節點總數目的比例記為pk,那么網絡中不同度的統計分布即為度分布[17]。為了方便推斷一個甲骨字在71 455片拓片中同時出現的信息,即一個甲骨字和其鄰接甲骨字共同描述同一個場景或語義單元信息,我們把構建的權重網絡簡化為無權重的網絡,然后計算度分布。在本文構建的網絡中,甲骨字的度表現為甲骨字之間的權重值(或連接邊的個數),而甲骨字之間權重分布表現為網絡的度分布。圖2給出了未識和已識甲骨字網絡的度分布圖,從圖中我們可以看到甲骨字網絡的度分布符合無標度分布[18](scale-free distribution),無標度分布意味著網絡中大部分節點度的取值較小,但是會有少數節點度的取值非常大。在甲骨字網絡中的度分布說明: 一方面大部分甲骨字的度值比較小,比如,度值小于10的甲骨字(即此甲骨字有10個相鄰甲骨字)占總甲骨字的比例為76.6%,而度值小于17、50的甲骨字占總甲骨字的比例分別為82.1%、91.1%。在甲骨文字系統中,較小的度值代表描述同一個場景或語義單元所需的甲骨字也較少。另一方面,有少數的甲骨字有很大的度值,如甲骨字“卜”和“貞”字之間的權重高達203 756,如果假設這兩個甲骨字直接相連,那么“卜”和“貞”在71 455個拓片中至少出現20 375次。不僅如此,“卜”和其他甲骨字的度值也較大。通過相關的文獻我們得知[1]: 在甲骨字系統中,單音節名詞占大多數;而動詞占少數,并且在動詞中,祭祀動詞占多數。“卜”字是常用的動詞,經常和其他名詞相連使用,因此,“卜”字具有較大的度值。以上分析也說明我們構建的甲骨字網絡能充分反映甲骨文系統的語言信息。
2.2 局部連接比率
局部連接比率(local-links-rate,LLR)是一種衡量網絡局部特性的指標[19],如式(3)所示。由于網絡中的邊信息比節點信息更能反映網絡的各種特性。因此,LLR的定義是基于網絡的連接信息,而不是節點信息。對網絡中任意一條邊e,被它連接的兩個節點為n1和n2。首先計算這兩個節點的共同鄰接節點(common node,CN),然后統計共同鄰接節點之間存在的邊數(local-links)。最后,計算局部連接比率LLR。圖3給出了計算LLR的實例圖。對于圖3中的一條實線邊,連接它的兩個節點(中空結點)共享四個節點(實心節點),這四個節點之間存在三條邊(點形邊)。因此,實線邊的LLR值為3/4。如果一個網絡的平均LLR大于2,那么這個網絡有較強的局部特性[19]。通過計算,甲骨字網絡的LLR值高達26.678 7,說明甲骨字網絡具有很強的局部特性,即描述同一個場景(或語義單元)的甲骨字在甲骨字網絡中相互之間連接的邊較為稠密。
LLR=local-links/CN
(3)
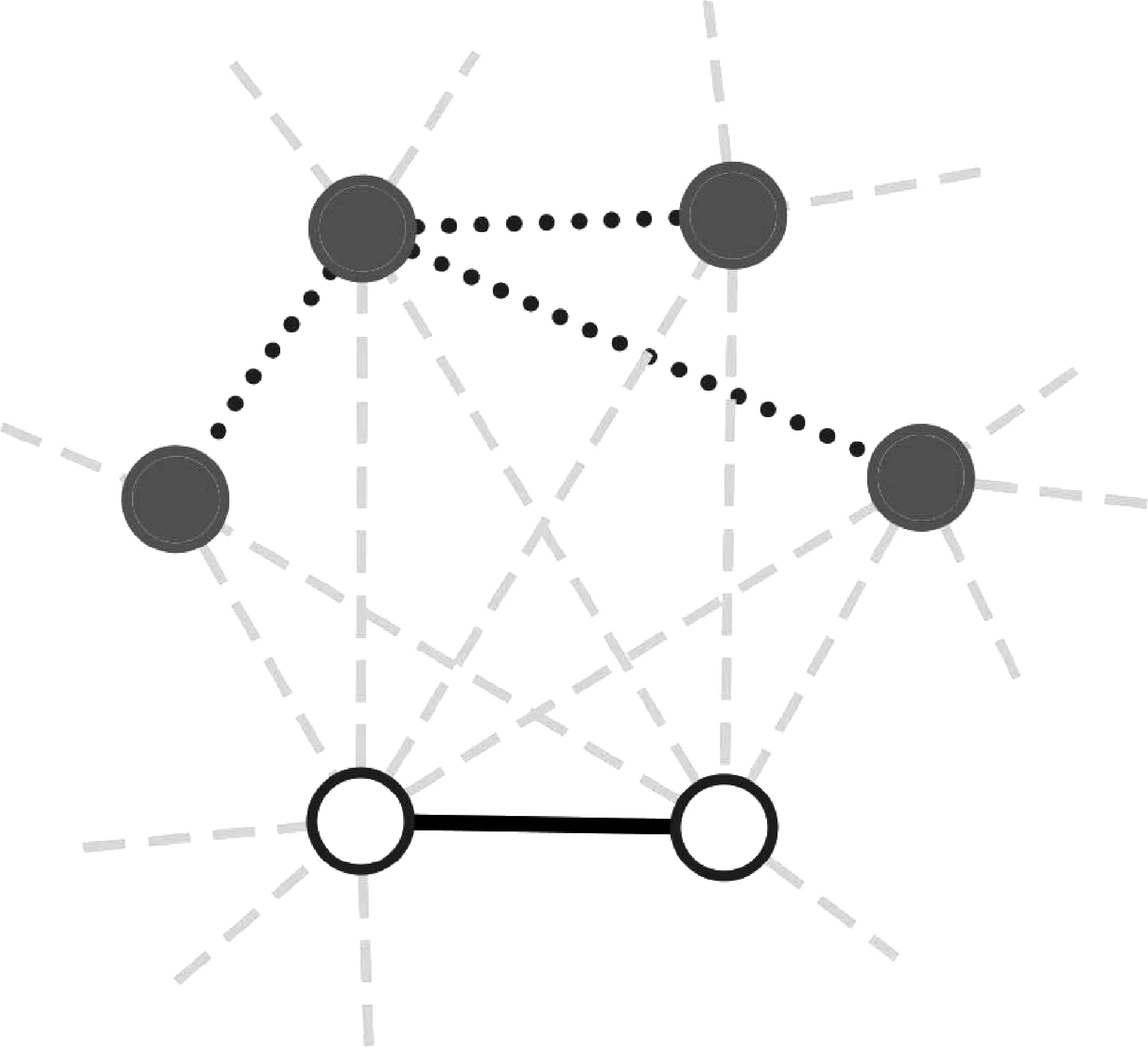
圖3 局部連接比率計算示意圖[19]
2.3 聚類系數
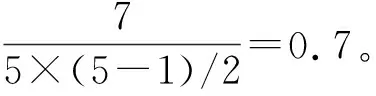
一個網絡的聚類系數是網絡中所有節點聚類系數的平均值。通過計算,甲骨字網絡的聚類系數為0.594 4。較高的聚類系數意味著節點的鄰接節點之間存在更高程度的交互關系,即這個節點和其鄰接節點更穩固地聚集成模塊結構[22]。在甲骨字網絡中,較高的聚類系數意味著一個甲骨字和其鄰接的甲骨字參與描述同一場景或語義單元的概率較高。
(4)
Ui表示節點i的鄰接節點數,ei表示Ui個鄰接節點之間存在的邊數。
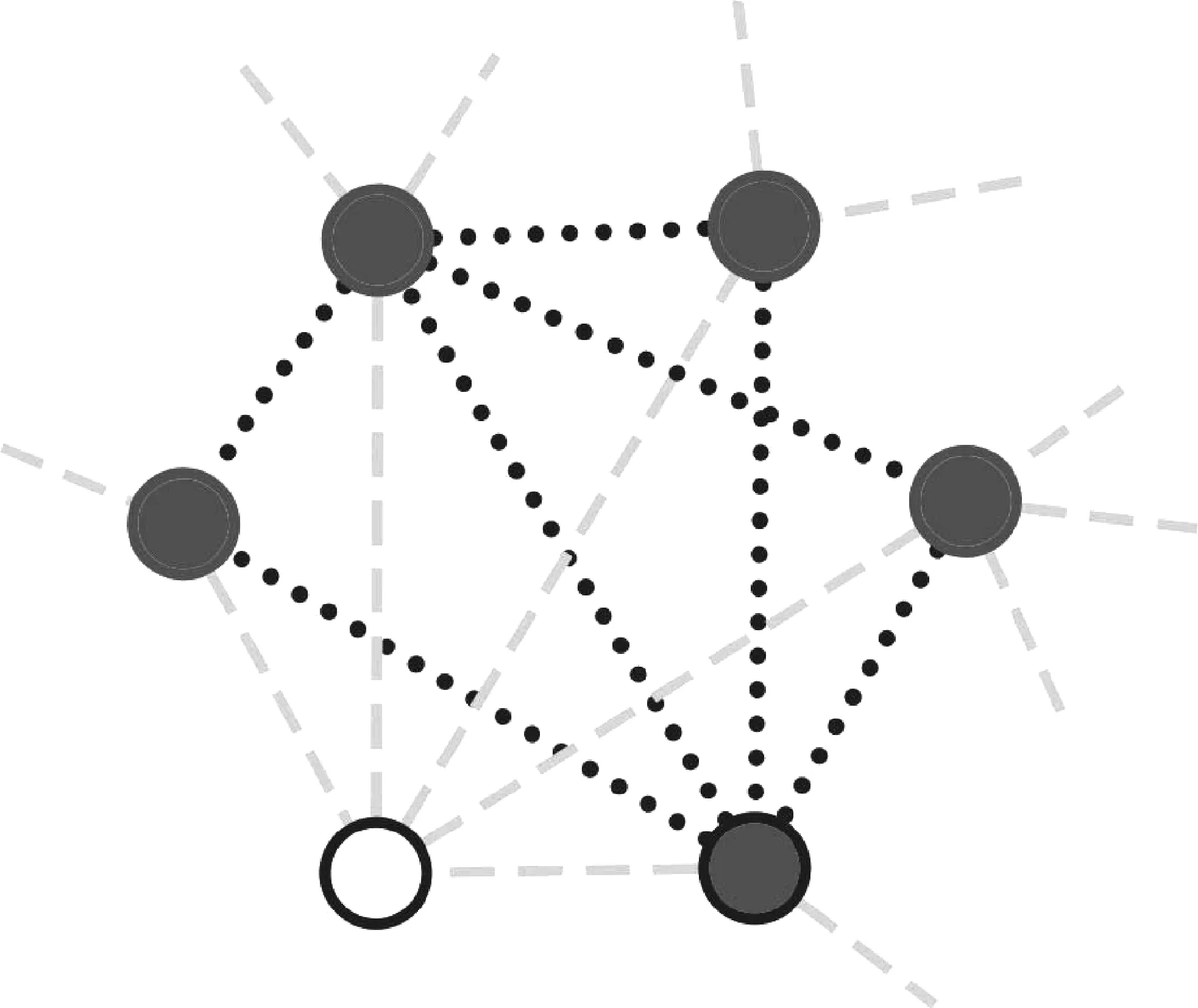
圖4 聚類系數計算示意圖
2.4 模塊度
模塊(module,或稱社團)結構是復雜網絡的一個基本特性,也是復雜網絡研究的重點內容。模塊是網絡的一個子集,它要求模塊中節點之間的邊連接緊密,而不同模塊之間節點的邊連接稀疏。圖5是一個含有12個節點和三個模塊的網絡示意圖[23]。模塊內的節點具有相似的屬性,依據這一特點,模塊結構已在很多領域取得了成功的應用。如在蛋白質相互作用網絡中,功能相似的蛋白質在網絡中往往以模塊的形式存在。因此,通過挖掘模塊結構可以預測未知蛋白質的功能;在人類社會中,人以類聚是模塊結構在社會網絡中的真實反映。社會學家可以利用模塊結構研究人們的心理行為、興趣愛好等。通過構建包含已知和未知語義的甲骨字網絡,在此基礎上分析此網絡是否具有模塊度特性,進而利用模塊內結點的屬性,可以預測同一模塊內未知甲骨字的語義信息。如在圖5中下方的一個含有五個節點的模塊中,假如我們已知其中四個甲骨字描述了某種場景信息(如婚娶),那么根據模塊結構中節點具有相同屬性的特性,可以推測剩余一個未知語義的甲骨字也用來描述婚娶信息。
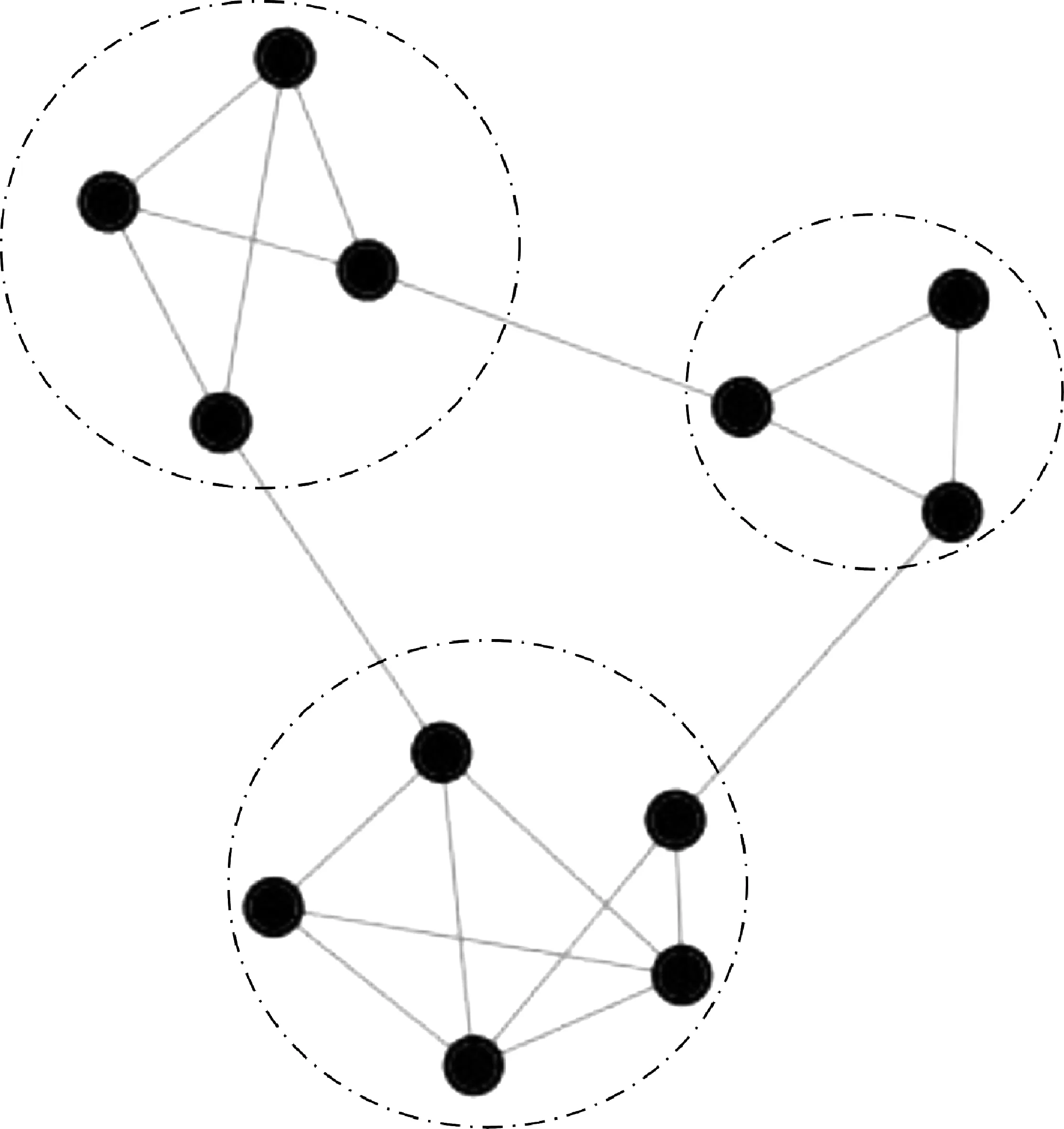
圖5 網絡模塊結構示意圖[23]
模塊度(modularity)[24]不僅是一種用來挖掘網絡中模塊結構的方法,而且是一種用來衡量網絡是否具有模塊結構的標準。雖然基于模塊度的方法具有“分辨率限制”(Resolution limit)的問題[25],但它仍然被廣泛用于判斷一個網絡是否具有模塊結構的評價標準。對于有權重的網絡,模塊度(Q)的定義如式(5)所示。
(5)
其中,nc是網絡劃分的模塊個數,W是網絡中所有邊的權值之和,Wv是模塊v內部所包含的邊的權重和,Sv是所有與模塊v內部的點相關聯的邊的權重和。利用模塊度方法對甲骨字網絡進行分析,得到的模塊度的值為0.292 1。根據文獻[26]我們得知,如果一個網絡的模塊度大于等于0.3,說明這個網絡具有很強的模塊特性。另外,從局部連接比率和聚類系數可以說明我們構建的甲骨字網絡具有較強的局部特性。綜上所述,甲骨字網絡具有良好的模塊結構屬性,這種屬性為我們通過識別模塊結構進而破譯未知甲骨字的語義提供了直接數據和理論上的依據。
3 討論
作為一個新的研究方向,語言網絡正在悄然興起,并取得了一些有意義的結果[27]。本文第一次使用大規模的拓片信息創新性地構建了甲骨字網絡,其主要表現在以下三個方面: 一是構建的網絡充分捕捉了甲骨文系統的語義單元信息;二是構建網絡的方法保留了甲骨文系統單音節詞多、復音節詞少的特性;三是構建的網絡中邊權重反映了甲骨字之間的同現關系。
在甲骨字網絡之上,深入研究了網絡的度分布、局部連接比率、聚類系數和模塊結構特性。本文構建的甲骨字網絡可為網絡甲骨學家和歷史學家預測未知甲骨字的場景和語義提供數據支持和直接的研究理論思路。但是,本文還存在一些不足之處需要我們進一步研究: 第一,式(2)中參數length選取具有不合理性: length表示的是同一拓片上兩個甲骨字之間殘缺字的個數,因此,length的值不能設置過大。如何利用甲骨文字系統的意義選取length的值是我們需要進一步研究的問題。第二,由于破譯未知甲骨字的語義是甲骨學研究的重要內容,因此另外一個不足之處是本文既沒有利用構建的網絡破譯已識甲骨字的一些偏旁部首的可能含義,也沒有依據已識甲骨字推斷未識甲骨字或其偏旁部首的可能含義。如何設計高效算法推斷未識甲骨字或其偏旁部首的可能含義是我們下一步重點研究的內容。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
開放教育研究(2020年2期)2020-03-31 01:54:14
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
現代語文(2016年21期)2016-05-25 13:13:44
