透明計算中用戶訪問行為特征分析與預測
2018-08-20 03:42:38侯翔宇李偉民盛津芳
計算機工程與應用 2018年16期
王 斌,陳 琳,侯翔宇,李偉民,盛津芳
WANG Bin,CHEN Lin,HOU Xiangyu,LI Weimin,SHENG Jinfang
中南大學 信息科學與工程學院,長沙 410083
School of Information Science and Engineering,Central South University,Changsha 410083,China
1 引言
近年來,云計算作為網絡計算模式的典型代表,使計算由軟硬件為中心轉變為面向服務的模式,能夠根據終端用戶的需求把服務端的存儲和計算資源傳輸到客戶端[1]。透明計算是云計算的一個特例,是一種以用戶為中心的新型服務模式,旨在為用戶提供無處不在的透明服務。
透明服務平臺作為透明計算服務端的核心,負責統一存儲并管理多個用戶的資源,包括操作系統、應用程序和用戶數據[2-3]。同時還要快速高效、安全和可靠地處理各用戶發送的資源訪問請求,以保證用戶的服務體驗質量。透明服務平臺采用基于虛擬磁盤的方案來實現,在終端用戶看來,服務端存儲的是終端的虛擬磁盤數據,終端對虛擬磁盤的訪問請求最終被重定向到服務平臺[4]。針對透明服務端如何提高用戶的虛擬磁盤數據訪問效率和安全可靠性,文獻[5]設計了一個局域網中高效可靠的塊級存儲訪問協議NSAP(Network Storage Access Protocol)。文獻[6]分析驗證了基于虛擬磁盤的透明計算系統性能瓶頸在于服務端,而cache的命中率又是服務端性能表現最關鍵的因素,最后在服務端和客戶端制定了緩存分配策略。文獻[7]提出了一個評估透明計算多級高速緩存層次結構以及整個透明計算系統的行為和性能的模擬框架TranSim。通過使用TranSim,系統設計者可以方便快捷地評估緩存策略的有效性和系統性能。
如上所述,目前關于透明計算服務端性能優化和安全可靠性保障的研究側重于自身的存儲架構、調度策略和訪問協議,但沒有研究工作從透明計算需求的源頭:用戶以及用戶訪問行為的特征來分析和預測其對透明服務平臺的影響。如文獻[8]提出了基于關注關系和用戶行為的物品推薦算法。文獻[9]通過記錄學生學習操作行為,并結合傳感器數據,提出一種場景感知分類算法。文獻[10]結合訪存敏感和用戶行為敏感的MPSoC應用映射技術,提出一種混合的動態映射策略。文獻[11]分析了多臺終端加載相同操作系統過程中數據的訪問信息,發現用戶行為具有集中和相似的特征。因此,本文在構建基于多層虛擬磁盤存儲模型的透明服務平臺基礎上,首先對大量用戶訪問服務平臺數據塊的行為進行統計分析,并利用信息熵策略挖掘出被頻繁集中訪問塊的時序特征。然后利用三次指數平滑方法預測未來一段時間用戶對這些塊的訪問行為。最終結果可以為服務平臺制定更高效的緩存策略提供有效的依據,進而幫助透明服務端提高服務性能和體驗質量。
2 透明服務平臺存儲模型及訪問機制
透明服務平臺位于透明計算服務端,它為用戶屏蔽了硬件平臺和操作系統的異構性,統一集中管理系統資源,并轉化為服務提供給用戶。因此,透明計算用戶自主可控地按需使用服務的過程本質是對透明服務平臺數據訪問的行為。透明服務平臺的架構和原理決定了用戶數據訪問的機制,是用戶行為分析的基礎。
透明服務平臺存儲了所有透明終端用戶的虛擬磁盤數據,但透明計算需要面對大量異構的終端用戶,如果數據共享程度不高,會導致大量的數據冗余。為此,本文所構建的透明服務平臺中,實現了一個多層樹狀虛擬磁盤存儲模型,如圖1所示。虛擬磁盤中數據資源按資源共享程度及性質劃分成3類:系統資源、應用群組資源和用戶個性化資源。系統資源主要指操作系統以及相關數據,該類資源共享程度最高,能被所有用戶共享,所構成的鏡像稱為系統虛擬磁盤鏡像(System Virtual Disk Image,S_VDI)。應用群組資源主要指各種相關的應用軟件數據組成的集合,具有相同的應用屬性的應用軟件通常歸為一個群組。該類資源只能被同一群組下的用戶共享,所構成的鏡像稱為群組虛擬磁盤鏡像(Group Virtual Disk Image,G_VDI)。用戶個性化資源主要指用戶的私有數據資源,一般包括用戶私有文件或者操作系統、應用軟件的個性化配置信息,該資源僅用戶自身才能訪問,所構成的鏡像稱為用戶虛擬磁盤鏡像(User Virtual Disk Image,U_VDI)。
在面對多終端用戶對共享層資源同時進行訪問時,采用寫時重定向(Redirect on Writing,ROW)機制來進行控制。具體做法是:將系統虛擬磁盤鏡像S_VDI和群組虛擬磁盤鏡像G_VDI以只讀的方式存儲于服務端,共享給多個終端用戶;采用ROW機制將終端用戶對共享的虛擬磁盤鏡像S_VDI和G_VDI的改寫塊保存于與用戶對應的用戶虛擬磁盤鏡像U_VDI中,并采用Bitmap[12]來標記各個改寫塊的位置,從而實現了多個終端用戶對共享數據的共同讀寫。在圖1中,當用戶i請求第7和8號數據塊時,由于用戶對應的U_VDI中存儲了數據塊7的改寫塊,對7號塊的數據訪問讀請求被定位到用戶對應的U_VDI,而數據塊8在U_VDI和G_VDI的位圖中都沒有改寫標記,因此其請求定位到了S_VDI,最后將所有讀取到的數據塊重新排序組合后返回給終端用戶。
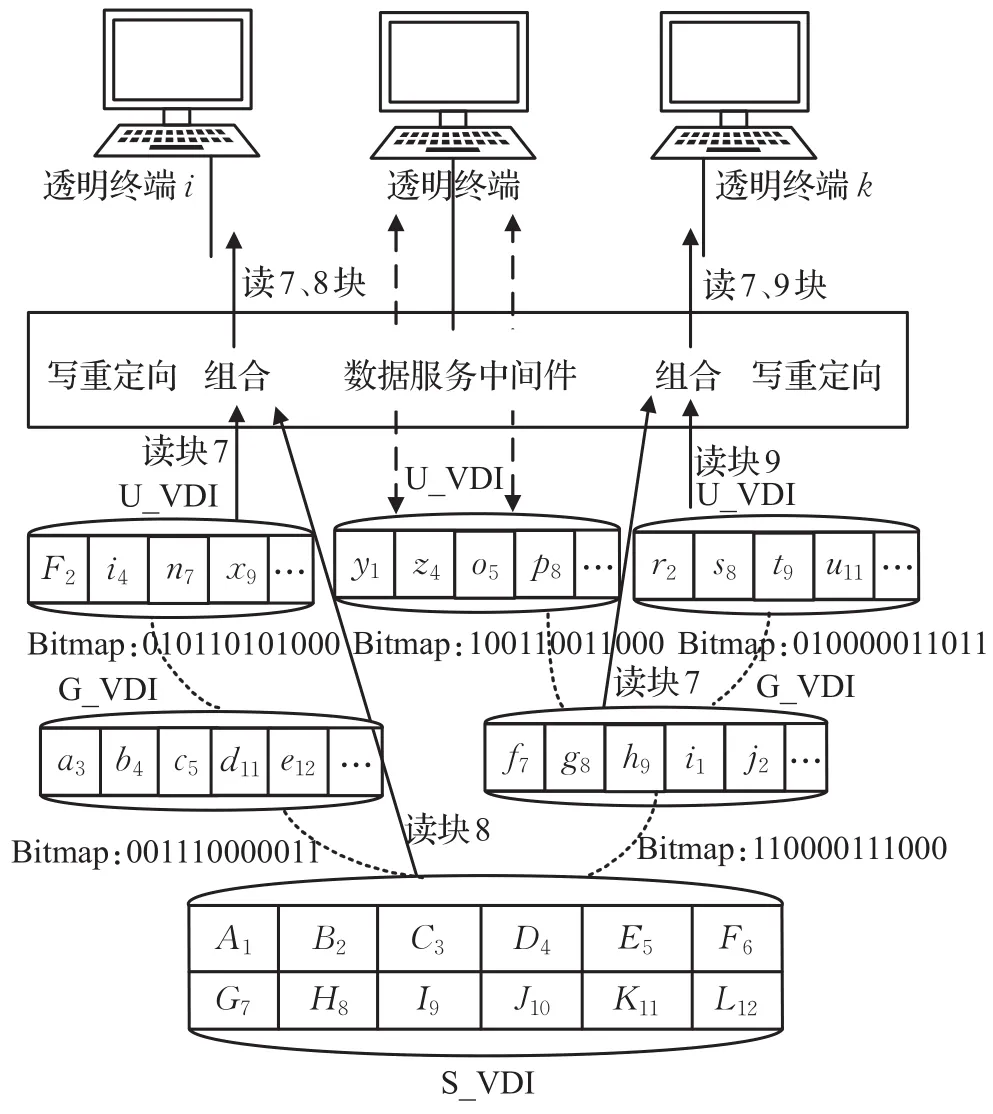
圖1 透明服務平臺虛擬磁盤存儲模型及訪問機制
需要注意的是,如果在有相關緩存機制的情況下,用戶對服務平臺的數據訪問首先會被定向到緩存池。而本文所研究的用戶行為是在沒有緩存機制的情況下進行的,目的正是為了更好地挖掘和預測用戶行為特征,為緩存策略提供依據。整個存儲模型和數據訪問機制對用戶是透明的,用戶所獨占的一個既包括操作系統,又涵蓋應用軟件、個人私有數據的“本地磁盤”實際上在服務端被劃分成多個部分,S_VDI和G_VDI是多用戶共享,僅U_VDI為每個用戶獨享的私有數據。
由上述描述可以看出,透明服務平臺的虛擬磁盤模型具有多層次、高共享和低冗余的特點,因此,其用戶數據訪問行為模型也會不同于其他虛擬磁盤存儲模型。另一方面,透明計算是強調以用戶為中心的網絡計算服務模式,面對大量的異構終端用戶,并且用戶的所有資源均存儲在服務端,用戶在獲取服務時會帶來大量的與服務端的數據交互行為。因此,分析和預測透明計算用戶行為特征具有重要的現實意義。
3 用戶訪問行為分析
3.1 行為表示
透明計算客戶端是一個僅需保留必要的計算和輸入/輸出硬件的設備,本地不存儲任何操作系統和應用軟件,通過網絡按需從服務平臺將其以數據塊的形式加載到客戶端設備上流式執行。給定時間內,用戶對服務平臺的數據訪問請求作為一次用戶訪問行為,用戶訪問行為用塊的集合來表示。本文出現的“用戶”是指全體用戶的集合。基于此,給出下面相關概念。
定義1設某特定時間段Tα內被訪問的數據塊集合為,若時間點Tm∈Tα,所有用戶在Tm時刻對數據塊Bi的訪問次數為count(Bi,Tm) ,那么數據塊Bi在Tα時間區間內被用戶訪問的頻數為:
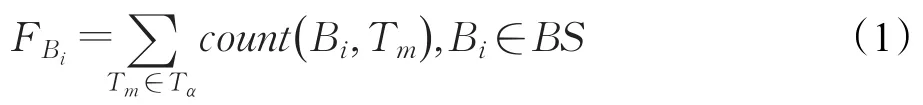
通過式(1),得出在Tα時間區間內不同數據塊被訪問的頻數集合F={FB1,FB2,…,FBn}。記數據塊Bi在Tα時間區間內被訪問的概率為P(Bi),那么:
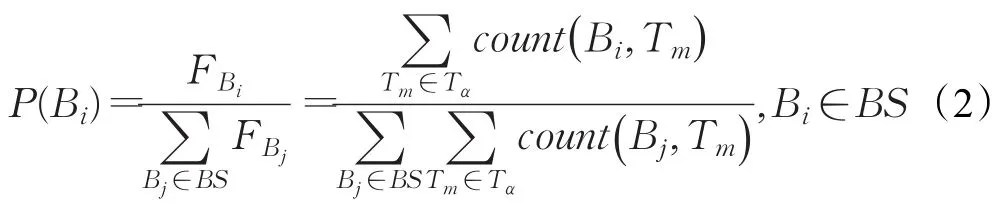
對不同數據塊在Tα時間區間內計算訪問概率,得出概率集合P={P(B1),P(B2),…,P(Bn)} 。
3.2 行為熵策略
香農提出的信息熵概念,反映了信源整體的統計特性,是對總體的平均不確定性的度量。
用戶的行為表現為:對透明服務平臺上不同數據塊的訪問。對這一信源進行熵運算,可以從宏觀上量化用戶的操作行為特征[13]。根據信息熵的相關概念與公式,結合3.1節的概率集合P,得出其概率空間表示為:

基于信息熵本身的概念,能夠得到如下的推論。
推論1H(B)越大,用戶對數據塊的訪問越平均,即在該區間內,用戶行為越分散。反之,H(B)越小,用戶對數據塊的訪問越集中,即在該區間內,用戶行為越集中,則越能體現出用戶行為偏向和特征。
證明 以各數據塊被訪問的頻數集合{FB1,FB2,…,FBn}為離散信源,依據最大離散熵定理和信息熵的極值性,有即當信源出現的可能性相等時,信源的熵達到最大。由此可得,H(B)越大,用戶對數據塊的訪問行為越分散;H(B)越小,說明用戶行為越集中。
推論2H(B)=0具有兩種不同的含義。第一種表示在該區間內用戶只對某一數據塊進行操作,即對該數據塊的需求為100%;第二種表示在該區間內用戶對所有的數據塊都沒有進行操作,即所有客戶端都沒有被使用。
證明 由信息量的非負性可知,當H(B)=0時,對于任意數據塊Bi,有如下推導:

P(Bi)=0或lbP(Bi)=0?P(Bi)=0或P(Bi)=1
那么,由信息熵的確定性可知,P(Bi)=0即為用戶只對數據塊Bi進行操作;P(Bi)=1即為用戶對所有的數據塊都沒有進行操作。
在多臺透明服務終端設備相繼啟動時,記錄該時間段內對數據塊的訪問信息,計算對各個數據塊的訪問次數,訪問分布的情況如圖2所示。
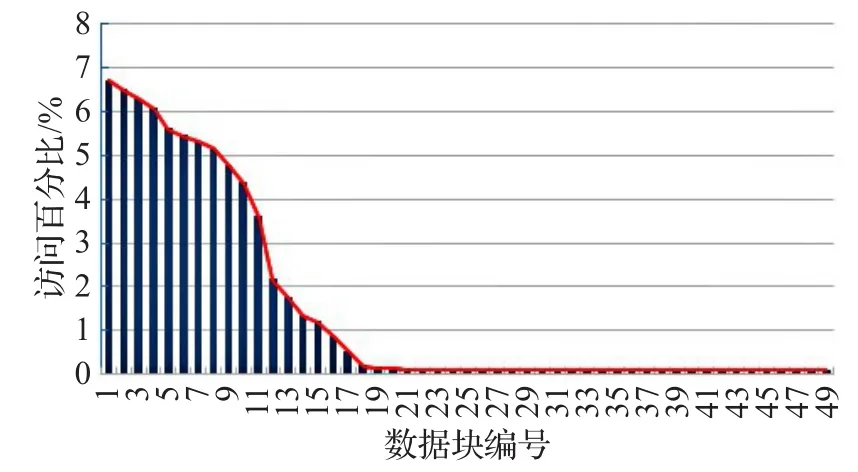
圖2 多臺透明服務終端啟動時數據塊訪問分布
這些數據塊即為系統共享資源存儲層中操作系統啟動時需要加載的對象。在這段時間內,68.591%的訪問集中在了17.8%的數據塊上,呈現為長尾分布。因此利用信息熵量化用戶行為并挖掘行為時序特征是可行的。
3.3 行為特征歸類
用戶在不同的時刻對資源有不同的需求,式(3)計算出來的熵值反映了一段時間內用戶宏觀上的行為特征。本文根據熵值判斷用戶當前行為屬于集中式還是分散式的特征,因此需要對用戶行為熵集合中的熵值進行處理。
(1)根據熵值初步地把用戶訪問行為分成分散式和集中式兩類。記錄下熵值所對應的時間T,用二元組HT<H,T>來表示不同時間段的熵值。用戶行為熵集合HTS={HT1,HT2,…,HTn},為HT按時間推進的有序集合。選取HTS中熵值最大的點HTj和最小的非零點HTk。借鑒數據挖掘中的K最近鄰算法,將HTj和HTk作為種子結點,并且遍歷HTS集合,得到兩個以HTj和HTk為中心的有序的類集合HTjS和HTkS,集合中元素順序為HT下標的升序排列。
(2)分別對有序集合HTjS和HTkS進行處理,獲得用戶行為集中或分散的連續時間段。若其中HT下標為連續的,將這些連續的點歸為一個小集合;若HT下標出現斷點,則從該點開始,使之與后面下標連續的點歸為一個新的小集合。將獲得的所有小集合按時序生成特征軌跡,至此便完成了對HTS中熵值的特征歸類。
算法1特征歸類算法
輸入:HTS //用戶行為熵集合
輸出:Collections //表示用戶行為分散或集中的連續時間段集合
1.提取HTS中的最大、最小熵值
pick the max and min H in HTS
2.根據信息熵對用戶訪問行為分類
i←0
for eachHTinHTS
If|HTi.H-Hmax|>|HTi.H-Hmin|then
addHTiintoHTSmini←i+1
else
addHTiintoHTSmax
i←i+1
3.對表示訪問行為集中的集合按時間連續性進行劃分
i←0
for eachHTinHSmin
pickHTj(HTjis the next one ofHTi)
ifj=i+1then
addHTiandHTjinto one Collection
i←i+1
else
addHTiandHTjinto different Collection
i←i+1
4.對表示訪問行為分散的集合按時間連續性進行劃分
do like step 3 inHSmax
5.return Collections
設算法1返回的集合群體為S1,S2,…,Sn,以時序排列。有這樣的特點:(1)同一集合中的熵值是等價的,即使其數值不同,但是含義相同,表示用戶在此時間段內的行為是分散的或集中的。(2)兩個相鄰的集合Si與Si+1,一個處于“峰”,一個處于“谷”,處于“峰”的熵值代表該時間段內用戶的操作為分散式,而處于“谷”的熵值代表操作為集中式。
3.4 行為預測
用戶對不同應用的操作和對不同文件的讀取請求,通過對服務端數據塊的訪問來實現。本文根據3.3節描述的行為特征歸類,選取在一段時間內呈現出被集中訪問的數據塊作為預測的對象。若數據塊在近期訪問次數較多,并且預測出在短時間內仍然保持著較高的訪問量,說明用戶短時間內的操作仍然集中在某些應用和文件上。根據預測結果可以優化服務端緩存替換策略,縮短客戶端的響應時間。
指數平滑法[14]是基于時間序列進行預測的重要方法。它認為時間序列的態勢具有穩定性或規則性,最近的過去態勢,在某種程度上會持續到未來。指數平滑法兼容了全期平均和移動平均所長,不舍棄過去的數據,但是僅給予逐漸減弱的影響程度,適用于中短期趨勢[15]。用戶的訪問行為具有時序性,且本文涉及到的預測是對短時間內仍保持較高訪問量的數據塊訪問次數的預測,因此選用指數平滑法作為預測模型。
指數平滑預測方法有多種模型:
(1)一次指數平滑值
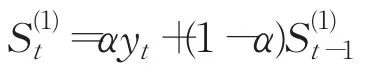
(2)二次指數平滑值
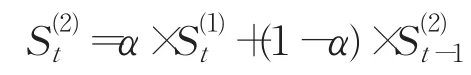
(3)三次指數平滑值

其中,α為平滑系數;yt為t時刻的觀測值;為一次、二次、三次指數平滑值。一次指數平滑法只適合于具有水平發展趨勢的時間序列分析;二次指數平滑法是對一次指數平滑的再平滑,能夠修正滯后偏差,但也只適合于對具有線性特征的模型進行預測[16];三次指數平滑法是唯一的非線性平滑法,尤其適用于時間序列上呈二次曲線趨勢的預測[17]。
隨機抽取透明計算服務端的某數據塊,圖3為其一個小時內被訪問的次數,可知數據塊訪問次數在時序上呈現出非線性的變化特征,因此三次指數平滑法更符合數據塊訪問量的變化趨勢,本文采用三次指數平滑法進行預測。
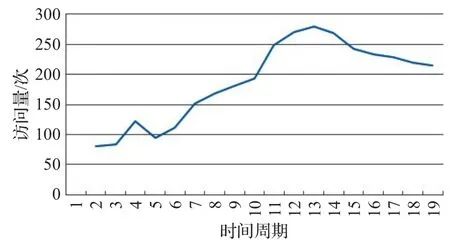
圖3 數據塊在各周期的訪問量
三次指數平滑法的預測模型為:

其中,?t+T表示t時刻之后T個周期的預測值。3個預測參數at、bt、ct由一次、二次、三次指數平滑值通過下式計算得出:
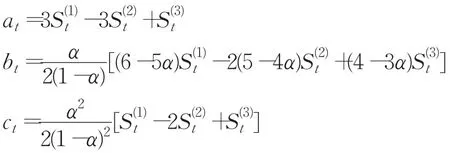
4 實驗分析
為了驗證信息熵與三次指數對用戶行為預測的有效性和準確性,本文采用透明服務平臺進行實驗。該系統包括一個透明服務器、30臺瘦終端、5臺移動終端。透明服務器采用三層存儲模式,分別存儲操作系統、組群、用戶的數據;瘦終端和移動終端沒有硬盤和操作系統,只有運算功能和基本的緩存,分別以有線和無線的形式連接網絡。實驗中35名用戶使用Win7和CentOS6.5兩種操作系統各自自由操作90 min。每個終端并行使用多種應用,根據統計分析,平均每隔5 min用戶使用的應用和訪問的文件極大概率會產生變化。因此,透明服務器將監控到的數據塊的訪問以5 min為一個時間周期進行統計,將90 min分為18個時間段。
4.1 統計信息熵及行為歸類
根據使用Win7和CentOS6.5下的兩次實驗結果,在35個用戶90 min的自由操作中,平均請求數據塊1253萬次,每個時間段訪問到的不同數據塊約32000到48000個。使用式(3)計算各個時間段內的信息熵,取前10個周期結果如圖4所示。
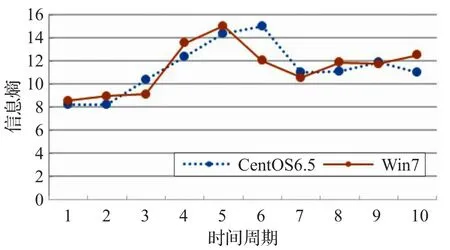
圖4 信息熵時序圖
由圖4可以看出,兩條信息熵曲線在時序上有比較明顯的波動,信息熵的數據反映了所有用戶的操作行為特點。熵值較高的時間段表示用戶使用的應用和讀取的文件比較分散;熵值較低的時間段表示用戶使用的應用和讀取的文件比較集中,即用戶的行為更加集中。兩條曲線中熵值最低的時間段均為最早的幾個周期,數據塊的訪問最為集中。經過分析,這段時間內,終端大多為啟動階段,主要從透明服務平臺三層存儲的系統虛擬磁盤層中訪問和加載操作系統資源,這一層數據共享程度最高,因此訪問最為集中。后續時間周期中,用戶自由操作,主要從群組虛擬磁盤層和用戶虛擬磁盤層中按需訪問數據塊,同時也會從系統虛擬磁盤層中加載少量用來支持應用運行的數據塊,因此后續時間周期的信息熵整體上大于初始時間段。
信息熵量化了用戶的行為,為了對每個時間段內用戶行為分類,對得到的熵值做特征歸類處理,結果如圖5所示。
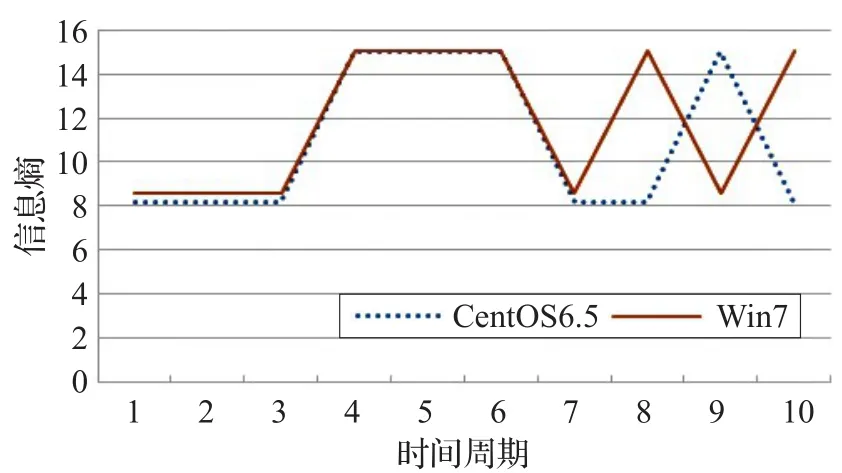
圖5 信息熵特征歸類處理
圖5顯示了圖4中兩條曲線特征歸類后的結果,將反映用戶同一行為特征的點歸于一類。由圖可知,用戶在使用CentOS6.5操作系統時,在1、2、3、7、8、10這幾個時間周期內,用戶使用的應用或訪問的文件較為相似,行為較為集中;在其余時間段內行為較為分散。同理可找到使用Win7系統時,用戶行為集中和分散的時間段。
根據圖5得到的結果,選取兩條曲線中熵值較低的時間段內包含的數據塊。根據統計,CentOS6.5和Win7兩次實驗中,用戶行為集中的時間段內訪問的不同數據塊個數分別為4257塊和3962塊,占整個實驗訪問過的所有數據塊的15.8%和12.3%。
4.2 平滑系數α擬合
本文使用三次指數平滑法對數據塊的訪問數量進行預測,使用式(4)進行計算。其中平滑系數α是三次指數平滑法擬合效果的關鍵,如果數據波動較大,α值應取大一些,可以增加近期數據對預測結果的影響。如果數據波動平穩,α值應取小一些。本文在確定α值時采用試算法,即取多個α值進行擬合實驗并加以比較。實驗α取值范圍為[0.1,0.7],取值步長為0.05,選取Win7、CentOS6.5實驗中待預測的數據塊各1000個,比較不同α下預測的均方誤差MSE,選擇誤差最小的α值。擬合實驗結果如圖6所示,實驗選取0.35作為α的值。
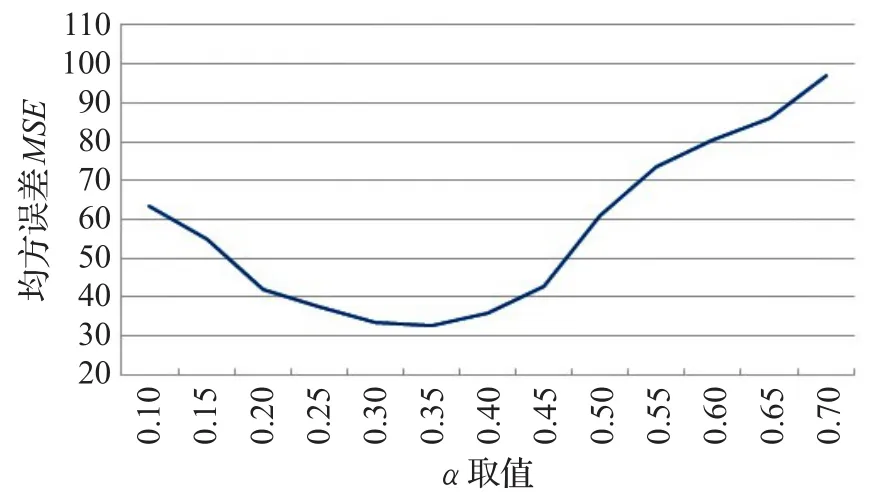
圖6 α擬合實驗
4.3 數據塊單周期預測
本實驗通過比較預測值和觀測值的誤差衡量預測算法的準確度。隨機選取一個數據塊,偏移量為1033808,從第5個周期開始,使用式(4),取T=1。根據當前的觀測值不斷預測下一個周期該數據塊的訪問次數。結果如表1所示。
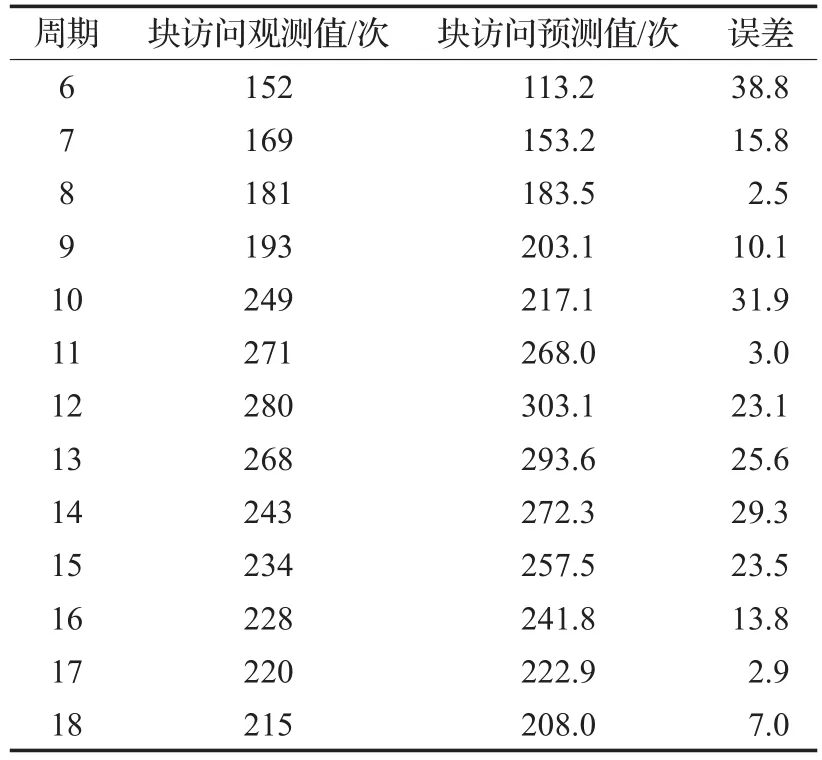
表1 單個數據塊6~18周期預測情況
根據前10個周期的觀測值,對兩次實驗中的4257個數據塊和3962個數據塊進行第11個周期的訪問預測,使用式(4),同樣取T=1。以作為準確率的衡量指標。其中St代表t時刻的預測值,Yt代表t時刻的觀測值,E的取值越小代表越精確。預測結果精確度分布如圖7所示。

圖7 預測結果精確度分布
在誤差低于0.1,0.1~0.2,0.2~0.3以及高于0.3的范圍內,數據塊所占比例分別為:CentOS,65%、18%、10%、6%;Win7,62%、21%、8%、9%。
在上述兩個實驗中,使用三次指數平滑預測算法預測一個周期后的數據塊訪問次數。表1證明了此算法可以在時序上根據觀測值不斷修正預測結果,迅速減小預測誤差;圖7證明了此算法可以對下一個周期數據塊的訪問次數給予較為精準的預測。
4.4 中短周期預測精度測試
4.3節證明了三次指數平滑算法在單周期預測精確度較高,但僅僅能預測一個周期是不夠的。為了驗證此算法在多少周期內預測結果可接受,以前10個周期作為觀測值,對所有數據塊進行第11~18周期的預測。使用式(4),T分別取1~8,并以平均誤差作為衡量指標,實驗結果如圖8所示。
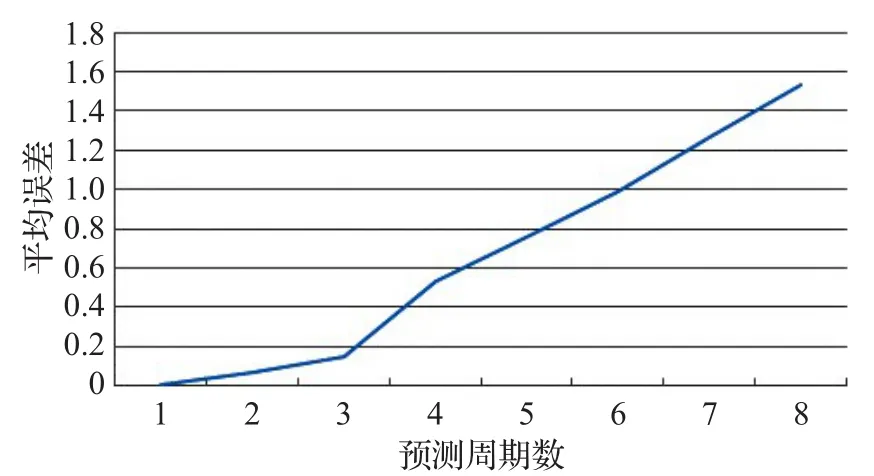
圖8 中短周期預測精確度測試
上述實驗表明,在預測1~3個周期時,平均誤差分別為0.07、0.12、0.19,從第4個周期開始,誤差急劇增加。由此得出結論,使用三次指數平滑預測法可以對數據塊在3個周期內給予較為準確的預測。
5 結束語
本文在透明計算背景下,根據透明服務平臺三層虛擬磁盤存儲的特點,基于信息熵和三次指數平滑對透明計算用戶行為特征進行分析和預測。此方法基于信息熵策略從宏觀上分析用戶行為需求,進而挖掘出被頻繁集中訪問的數據塊的時序特征。在此基礎上利用三次指數平滑算法預測將來一段時間內這些塊的訪問頻率。實驗表明,此方法能夠較為準確地發現集中訪問的數據塊,并對這些數據塊給予較為精確的預測,從而達到對用戶行為分析和預測的目的。預測結果為制定更高效的緩存策略提供有效的依據,從而提高透明計算服務質量與性能。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
