基于決策樹(shù)推薦克隆重構(gòu)的方法
2018-08-27 10:59:12折蓉蓉張麗萍
計(jì)算機(jī)應(yīng)用 2018年7期
折蓉蓉,張麗萍,侯 敏,閆 盛
(內(nèi)蒙古師范大學(xué) 計(jì)算機(jī)與信息工程學(xué)院,呼和浩特 010022)(*通信作者電子郵箱cieczlp@imnu.edu.cn)
0 引言
近年來(lái)軟件開(kāi)發(fā)環(huán)境、操作系統(tǒng)及軟件相關(guān)領(lǐng)域的不斷發(fā)展,導(dǎo)致軟件復(fù)用的規(guī)模越來(lái)越大,軟件開(kāi)發(fā)的成果被越來(lái)越多的人們直接復(fù)用。為了提高軟件的開(kāi)發(fā)效率,開(kāi)發(fā)人員會(huì)復(fù)用大量的代碼,被復(fù)用的代碼稱為克隆代碼[1],據(jù)統(tǒng)計(jì)一個(gè)軟件系統(tǒng)中的克隆代碼達(dá)到9%~17%,有的甚至達(dá)到50%以上[2]。
克隆代碼的大量使用導(dǎo)致了軟件復(fù)雜性的增加,僅僅檢測(cè)出克隆代碼并不能降低軟件維護(hù)成本。現(xiàn)有研究表明,重構(gòu)與軟件的質(zhì)量(如可維護(hù)性和穩(wěn)定性)有著密切的聯(lián)系,經(jīng)過(guò)重構(gòu)的克隆代碼往往比未經(jīng)過(guò)重構(gòu)的克隆代碼具有更高的質(zhì)量,所以重構(gòu)對(duì)于軟件的進(jìn)化具有積極的意義。
重構(gòu)軟件系統(tǒng)中克隆所有代碼是不切實(shí)際的,也不是所有克隆代碼都需要重構(gòu),雖然預(yù)測(cè)克隆重構(gòu)代碼的方法相繼提出,然而國(guó)內(nèi)外針對(duì)機(jī)器學(xué)習(xí)預(yù)測(cè)出需要重構(gòu)的克隆代碼的方法極少,因此本文將重構(gòu)作為一個(gè)機(jī)器學(xué)習(xí)問(wèn)題,預(yù)測(cè)需要重構(gòu)的克隆代碼,以降低軟件的復(fù)雜性和維護(hù)成本。
1 相關(guān)工作
1.1 克隆代碼定義及分類
當(dāng)前,人們廣泛采用的克隆代碼的概念是將具有相似語(yǔ)法及語(yǔ)義特征的代碼段稱為克隆代碼[3]。基于對(duì)代碼質(zhì)量造成重要影響的是克隆代碼的大量使用,近年來(lái)代碼分析領(lǐng)域中比較活躍的分支為克隆代碼的相關(guān)研究。克隆代碼的類型從不同的角度進(jìn)行劃分,當(dāng)前進(jìn)行分類的角度主要分為兩種。一種角度是根據(jù)代碼相似度,將其分成Type- 1、Type- 2、Type- 3及Type- 4四類[4](定義如表1);另一種角度是根據(jù)檢測(cè)粒度,將其分成文件克隆、類克隆、函數(shù)克隆、塊克隆以及語(yǔ)句克隆等五種類型[5]。

表1 克隆類型的定義
1.2 克隆檢測(cè)
克隆檢測(cè)是指查找源代碼中的克隆代碼,并以克隆對(duì)(Clone Pair)或克隆群(Clone Group)的形式反饋。其中,克隆對(duì)是指相互之間存在克隆關(guān)系的代碼段;克隆群是一些克隆代碼段的集合,其中任意兩個(gè)代碼段都是克隆對(duì)。目前,克隆檢測(cè)領(lǐng)域的研究已較為成熟,許多檢測(cè)方法及技術(shù)被提出,主要包括:基于文本的克隆檢測(cè)方法[6]、基于Token的克隆檢測(cè)方法[7]、基于抽象語(yǔ)法樹(shù)(Abstract Syntax Tree, AST)的檢測(cè)方法[8]、程序依賴圖(Program Dependence Graph, PDG)[9]、基于低級(jí)語(yǔ)言[10]的檢測(cè)方法、基于Metrics[11]的檢測(cè)方法等。
本團(tuán)隊(duì)在克隆檢測(cè)方面也進(jìn)行了大量研究:史慶慶等[12]使用優(yōu)化后綴數(shù)組的方法進(jìn)行克隆代碼檢測(cè),并實(shí)現(xiàn)了一款檢測(cè)軟件源代碼中克隆群的工具——FCD(Function Clone Detector)。FCD能夠把軟件系統(tǒng)中的Type- 1和Type- 2函數(shù)克隆高效地檢測(cè)出來(lái);張久杰等[13]實(shí)現(xiàn)了基于Token編輯距離的檢測(cè)方法,能有效檢測(cè)Type- 3克隆代碼,解決了克隆檢測(cè)中Type- 3類型克隆檢測(cè)的難題,解決了以往對(duì)克隆代碼分析的研究對(duì)象大多局限于Type- 1和Type- 2類型的問(wèn)題,并為后續(xù)研究克隆代碼的演化、克隆代碼性能分析提供更加全面、準(zhǔn)確的數(shù)據(jù)來(lái)源。
1.3 克隆重構(gòu)
重構(gòu)的概念由Opdyke[14]提出,重構(gòu)就是通過(guò)改變程序代碼的內(nèi)部結(jié)構(gòu)而不改變程序代碼的外部行為來(lái)提高代碼的質(zhì)量,尤其是代碼的可擴(kuò)展性與可維護(hù)性。多年來(lái)軟件重構(gòu)作為提高代碼質(zhì)量的有效途徑,已成為軟件工程領(lǐng)域的熱點(diǎn)問(wèn)題。出現(xiàn)了許多針對(duì)不同類型的克隆代碼的重構(gòu)方法和技術(shù),主要包括:Bakota[15]采用進(jìn)化分析方法提取可重構(gòu)的克隆代碼;Rahman等[16]用度量提取可重構(gòu)的克隆代碼。Fowler[17]提出兩種重構(gòu)方法:提煉函數(shù)(Extract Method)和函數(shù)上移(Pull Up Method),這兩種方法是重構(gòu)克隆代碼常用的技術(shù),通常重構(gòu)克隆代碼需要結(jié)合使用這兩種方法,首先執(zhí)行“提煉函數(shù)”,然后執(zhí)行“函數(shù)上移”。克隆代碼重構(gòu)可以提高代碼的可維護(hù)性。
以Apache Ant中的一小段代碼為例來(lái)理解克隆重構(gòu)。Apache Ant的r436724中的克隆代碼重構(gòu)細(xì)節(jié)如圖1所示,開(kāi)發(fā)人員在維護(hù)日志提交內(nèi)容中有如下表述:“重構(gòu)DirectoryScanner來(lái)減少重復(fù)的代碼,測(cè)試全部通過(guò)”。源代碼的更改確認(rèn)了重構(gòu)DirectoryScanner中的克隆兄弟姐妹:分散在兩個(gè)方法中的克隆兄弟姐妹被提取到一個(gè)名為processIncluded的新方法中,并且這兩個(gè)方法調(diào)用新的方法來(lái)保存程序的外部行為。這就是重構(gòu)克隆代碼的一個(gè)實(shí)例。

圖1 克隆重構(gòu)實(shí)例
1.4 決策樹(shù)
決策樹(shù)又稱判定樹(shù),是一種運(yùn)用于分類的樹(shù)形結(jié)構(gòu),構(gòu)造決策樹(shù)采用的是一種自上而下的遞歸方法。將一組帶有類別標(biāo)記的訓(xùn)練數(shù)據(jù)作為決策樹(shù)的輸入,一棵二叉樹(shù)或者多叉樹(shù)作為輸出,以下兩步主要是決策樹(shù)的分類過(guò)程。
第1步 構(gòu)建決策樹(shù)模型,此過(guò)程就是進(jìn)行機(jī)器學(xué)習(xí)的過(guò)程。從數(shù)據(jù)中獲取知識(shí),使用訓(xùn)練集建立模型同時(shí)優(yōu)化。
第2步 進(jìn)行分類,使用生成的決策樹(shù)對(duì)輸入數(shù)據(jù)進(jìn)行分類。對(duì)輸入的記錄,從根節(jié)點(diǎn)依次測(cè)試記錄的屬性值,直到到達(dá)某個(gè)葉節(jié)點(diǎn),從而找到該記錄所在的類。
尤為關(guān)鍵的是構(gòu)造一棵決策樹(shù),構(gòu)造決策樹(shù)的過(guò)程分為三步:1)特征選擇;2)生成決策樹(shù);3)剪枝。
具體原理如下:
InfoGain(D,A)=H(D)-H(D|A)
(1)
(2)

(3)
其中:D代表整個(gè)訓(xùn)練樣本;訓(xùn)練樣本有k類;A代表特征,A將訓(xùn)練樣本分為n類;Pi為數(shù)據(jù)集中第i個(gè)類別占樣本總數(shù)的比例,Pji為j個(gè)剪枝數(shù)目中第i個(gè)類別所占比例。
決策樹(shù)相對(duì)于其他分類器而言有如下優(yōu)點(diǎn)。
1)速度快:不僅計(jì)算量小,而且分類規(guī)則轉(zhuǎn)化較容易。
2)準(zhǔn)確性高:挖掘出的內(nèi)容不僅可以清晰地反映出哪些字段比較重要,而且分類規(guī)則精準(zhǔn)性較高、便于理解。
2 基于決策樹(shù)推薦克隆重構(gòu)的方法
本文提出的基于分類器推薦克隆代碼重構(gòu)的方法共分為5個(gè)步驟,如圖2所示。

圖2 整體工作流程
2.1 克隆檢測(cè)
如果不知道哪些代碼片段是克隆代碼、克隆代碼所在的位置,也無(wú)法識(shí)別重構(gòu)代碼,解決克隆代碼引起的問(wèn)題,克隆代碼檢測(cè)是研究克隆重構(gòu)的基礎(chǔ),因此本研究使用目前比較成熟的克隆檢測(cè)工具——NiCad進(jìn)行克隆檢測(cè)。NiCad檢測(cè)工具是由加拿大皇后大學(xué)Roy等[6]開(kāi)發(fā)的克隆檢測(cè)工具,當(dāng)前最新版本為NiCad 4.0,適用于C、Java、Python等主流開(kāi)發(fā)語(yǔ)言,能夠檢測(cè)Type- 1、Type- 2、Type- 3的克隆代碼。由于它能有效檢測(cè)Type- 3克隆代碼,解決了以往對(duì)克隆代碼分析的研究對(duì)象大多局限于Type- 1和Type- 2類型的難題,并為后續(xù)研究克隆代碼的重構(gòu)、克隆代碼性能分析提供更加全面、準(zhǔn)確的數(shù)據(jù)來(lái)源。
本研究使用subversion從版本管理器中獲取某次提交之后的結(jié)果作為一個(gè)版本的源碼,然后使用NiCad進(jìn)行克隆檢測(cè),該工具可以檢測(cè)Java語(yǔ)言的Type- 1、Type- 2與Type- 3函數(shù)克隆,并具有很高的精度值和召回率。檢測(cè)結(jié)果以克隆對(duì)、克隆群和克隆函數(shù)的形式反饋出來(lái),本研究只用克隆函數(shù)、克隆群形式的檢測(cè)結(jié)果,檢測(cè)結(jié)果存儲(chǔ)到XML文件中。下面以Tomcat軟件為例,介紹克隆檢測(cè)結(jié)果。圖3呈現(xiàn)了以克隆函數(shù)形式反饋出來(lái)的部分內(nèi)容檢測(cè)結(jié)果,它顯示的是一個(gè)代碼片段的文件,提供每一個(gè)代碼片段的文件路徑、起始行號(hào)、結(jié)束行號(hào)、片段源碼等信息。圖4呈現(xiàn)了以克隆群形式反饋出來(lái)的部分檢測(cè)結(jié)果,它是克隆群文件,克隆群包含的克隆片段、檢測(cè)出來(lái)的克隆群信息都包含在里面。
2.2 識(shí)別重構(gòu)的克隆代碼
近年來(lái)隨著克隆代碼檢測(cè)技術(shù)日益成熟,克隆代碼的重構(gòu)也逐漸成為了熱門(mén),在對(duì)軟件系統(tǒng)中克隆代碼重構(gòu)之前,識(shí)別出需要重構(gòu)的集合是非常重要的。本文識(shí)別克隆代碼重構(gòu)實(shí)例具體過(guò)程分為如下3個(gè)步驟。

圖3 部分檢測(cè)結(jié)果(克隆函數(shù))

圖4 部分檢測(cè)結(jié)果(克隆群)
步驟1 通過(guò)相鄰版本間定義重構(gòu)實(shí)例。克隆重構(gòu)簡(jiǎn)單來(lái)說(shuō)就是代碼的更改,即定義克隆類C為由兩個(gè)或更多個(gè)克隆片段組成的集合。一個(gè)克隆類C至少有兩個(gè)克隆片段被合并,并且保留原始代碼段的外部行為,超過(guò)兩個(gè)克隆片段的克隆類C,則C被認(rèn)為是克隆重構(gòu),如果任何兩個(gè)克隆片段被重構(gòu),則為重構(gòu)實(shí)例。
步驟2 生成重構(gòu)候選集。本實(shí)驗(yàn)選擇了5個(gè)著名的開(kāi)源系統(tǒng),Tomcat、ArgoUML、PostgreSQL、Lucene、Apache Ant,收集了這些系統(tǒng)的所有公開(kāi)版本,要在所選目標(biāo)系統(tǒng)中識(shí)別克隆重構(gòu)實(shí)例,用Demeyer等[18]開(kāi)發(fā)的度量工具M(jìn)oose Metrics從源代碼中提取類、方法、屬性、計(jì)算必要的度量來(lái)生產(chǎn)重構(gòu)候選集。
步驟3 優(yōu)化重構(gòu)候選集。生成重構(gòu)候選集之后,依據(jù)以下3個(gè)條件對(duì)重構(gòu)候選集進(jìn)一步篩選和優(yōu)化:
1)相鄰版本間克隆類的兩個(gè)兄妹消失;
2)對(duì)于克隆代碼片段內(nèi)的方法,源代碼行數(shù)減少,并且至少一種方法被添加進(jìn)此方法中;
3)一個(gè)原始克隆代碼中新的源類被創(chuàng)建并作為父類。
選擇這3個(gè)條件是因?yàn)樗鼈儼怂信c克隆重構(gòu)有關(guān)的重構(gòu)模式。通過(guò)使用這種基于度量值的方法,手動(dòng)檢查克隆克隆重構(gòu)候選者,據(jù)Demeyer等[18]使用發(fā)現(xiàn),這種方法可以檢測(cè)到適用于克隆重構(gòu)的所有Fowler重構(gòu)模式,包括“Extract Method”“Extract Superclass”“Pull-Up Method”“Replace Method with Method Object”“Template Method”等方法。
若滿足其中任意一個(gè)條件則一個(gè)克隆類C被當(dāng)作候選,重構(gòu)實(shí)例如表2所示。
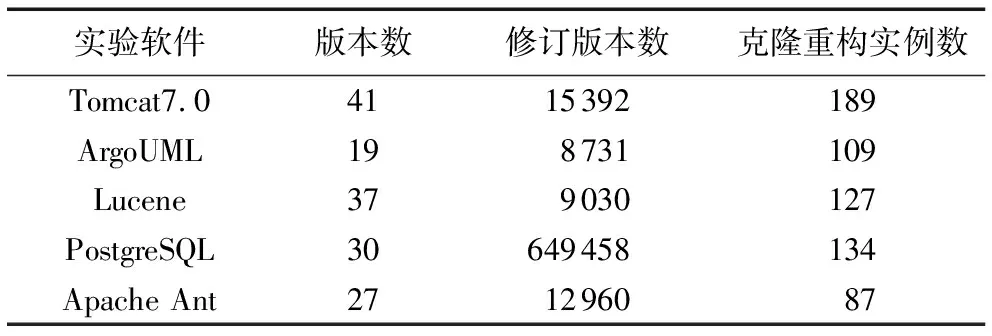
表2 識(shí)別克隆重構(gòu)實(shí)例
為了構(gòu)成完整的分類器訓(xùn)練數(shù)據(jù)集合,還需要收集非克隆重構(gòu)實(shí)例。非克隆重構(gòu)實(shí)例的收集則比較簡(jiǎn)單,只需觀察從克隆開(kāi)始版本到本研究中的最后一個(gè)版本,選擇沒(méi)有任何重構(gòu)的克隆代碼(包括重命名標(biāo)識(shí)符),則為非克隆重構(gòu)實(shí)例。
2.3 特征提取
特征提取是機(jī)器學(xué)習(xí)和模式識(shí)別領(lǐng)域常用的數(shù)據(jù)預(yù)處理方式,是訓(xùn)練機(jī)器學(xué)習(xí)模型的必要步驟,Wang[19]提出了使用克隆代碼的危害性可能與克隆代碼段的特征以及克隆內(nèi)容的特征有關(guān),并在兩個(gè)大型工業(yè)軟件上進(jìn)行了評(píng)估。Steidl等[20]用克隆代碼段、克隆關(guān)系的特征來(lái)自動(dòng)識(shí)別克隆代碼的bugfixes,并進(jìn)行了驗(yàn)證。本團(tuán)隊(duì)王歡等[21]針對(duì)克隆代碼有害性特征數(shù)量多且不容易提取、質(zhì)量粗糙的情況,提出了一種有害性特征選取的組合模型。基于以上研究得出Type- 3的克隆、克隆代碼的圈復(fù)雜度、克隆代碼段的行數(shù)、分支語(yǔ)句的比例等特征與克隆代碼的有害性和重構(gòu)相關(guān),因此本文從克隆關(guān)系、克隆代碼段及克隆內(nèi)容這3個(gè)維度中提取特征,詳細(xì)特征信息如表3所示。
特征的提取是建立在克隆代碼檢測(cè)和重構(gòu)標(biāo)注的基礎(chǔ)上,通過(guò)分析克隆檢測(cè)結(jié)果可以為本文研究基礎(chǔ)性的克隆代碼數(shù)據(jù),包括克隆代碼的數(shù)量、位置等數(shù)據(jù)。克隆群是不是Type- 3的克隆、克隆代碼段的Token大小這兩個(gè)特征直接從NiCad克隆檢測(cè)結(jié)果中提取,對(duì)于其他特征本文使用代碼工具SourceMonitor提取。SourceMonitor是一款可對(duì)多種語(yǔ)言(C++、C、C#、VB.net、Java、Visual、Basic和HTML)編寫(xiě)的代碼進(jìn)行度量的工具,并且針對(duì)不同的語(yǔ)言,輸出不同的代碼度量值。將克隆代碼作為輸入,SourceMonitor便會(huì)輸出相應(yīng)克隆代碼的靜態(tài)特征值。圖5是SourceMonitor對(duì)部分克隆代碼進(jìn)行度量的結(jié)果。代碼行數(shù)是從SourceMonitor工具的
2.4 訓(xùn)練決策樹(shù)分類器
決策樹(shù)方法在分類、預(yù)測(cè)等領(lǐng)域有著廣泛的應(yīng)用,C4.5是比較成熟的決策樹(shù)算法,C4.5算法是決策樹(shù)分類問(wèn)題中必不可少的挖掘工具。之所以選擇C4.5是因?yàn)樗a(chǎn)生的預(yù)測(cè)準(zhǔn)確性不低于其他的分類方法。哈爾濱工業(yè)大學(xué)袁悅[22]使用機(jī)器多種學(xué)習(xí)的方法來(lái)預(yù)測(cè)克隆代碼的一致性維護(hù)需求模型,經(jīng)實(shí)驗(yàn)發(fā)現(xiàn)決策樹(shù)的預(yù)測(cè)模型最佳,Wang等[23]用決策樹(shù)預(yù)測(cè)克隆代碼的質(zhì)量且取得良好的效果。受此啟發(fā)本研究選用決策樹(shù)來(lái)預(yù)測(cè)需要重構(gòu)的克隆代碼。

表3 特征選擇
構(gòu)造一棵決策樹(shù)的步驟如下。
1)數(shù)據(jù)預(yù)處理:將屬性變量處理形成決策樹(shù)的訓(xùn)練集,這里只需處理連續(xù)型的屬性變量,若沒(méi)有連續(xù)型的屬性變量則忽略。
2)計(jì)算屬性的信息增益率。
3)生成決策樹(shù):每一個(gè)根節(jié)點(diǎn)屬性的取值對(duì)應(yīng)一個(gè)子集,對(duì)樣本子集遞歸執(zhí)行步驟2),直到分類屬性上取值都相同時(shí)生成決策樹(shù)。
4)對(duì)新數(shù)據(jù)集進(jìn)行分類:根據(jù)構(gòu)造的決策樹(shù),提取分類規(guī)則且進(jìn)行分類。
算法描述如下。
輸入:訓(xùn)練樣本samples,候選屬性的集合attributelist。
輸出:一棵決策樹(shù)。
創(chuàng)建節(jié)點(diǎn)N
ifsamples都在同一個(gè)類Cthen
returnN作為葉節(jié)點(diǎn),以類C標(biāo)記
ifattribute_list為空then
returnN作為葉節(jié)點(diǎn),標(biāo)記為samples中最普通的類
選擇attribute_list中具有最高信息增益的屬性best_attribute
標(biāo)記節(jié)點(diǎn)N為best_attribute
for eachbest_attribute中的未知值ai
由節(jié)點(diǎn)N長(zhǎng)出一個(gè)條件為best_attribute=ai的分枝
設(shè)si是samples中best_attribute=ai的樣本的集合
ifsi為空then
加入一個(gè)樹(shù)葉,標(biāo)記為samples中最普通的類
else 加上一個(gè)由Generate_decision_tree返回的節(jié)點(diǎn)

圖5 部分克隆代碼度量結(jié)果
訓(xùn)練分類器,需要一個(gè)包含克隆重構(gòu)實(shí)例和非克隆重構(gòu)實(shí)例的樣本數(shù)據(jù)庫(kù),然而未經(jīng)重構(gòu)的克隆實(shí)例通常比重構(gòu)實(shí)例多出幾倍,訓(xùn)練所有克隆實(shí)例將會(huì)在構(gòu)造分類器時(shí)引入對(duì)未克隆重構(gòu)的偏奇。為了解決這個(gè)問(wèn)題,使用隨機(jī)欠采樣來(lái)減小未重構(gòu)克隆的大小。隨機(jī)欠采樣簡(jiǎn)單來(lái)說(shuō)就是從原始數(shù)據(jù)集中刪除數(shù)據(jù),從而提供相同比例的數(shù)據(jù)。具體來(lái)說(shuō),本文隨機(jī)選擇一組Dmaj中的多數(shù)類實(shí)例,并從D中刪除這些樣本,計(jì)算過(guò)程如下:
|D|=|Dmin|+|Dmaj|-|E|
(4)
其中:D是數(shù)據(jù)集;Dmin表示少數(shù)類數(shù)據(jù)的集合,在本實(shí)驗(yàn)中就是克隆重構(gòu)實(shí)例;Dmaj表示多數(shù)類數(shù)據(jù)的集合,在本實(shí)驗(yàn)中就是非克隆重構(gòu)實(shí)例;E表示D上采樣過(guò)程中產(chǎn)生的任何集合。
2.5 評(píng)估分類結(jié)果
在對(duì)未知數(shù)據(jù)樣本進(jìn)行預(yù)測(cè)時(shí),部分被正確分類,部分被錯(cuò)誤分類,因此,為了評(píng)價(jià)克隆代碼重構(gòu)預(yù)測(cè)模型,本研究選用常用的召回率、精度值、F值來(lái)評(píng)價(jià)分類器的性能,對(duì)應(yīng)的混合矩陣如表4所示。表4中:正確的正例(True Positive, TP)用TP來(lái)表示;錯(cuò)誤的反例(False Negative, FN)用FN來(lái)表示;錯(cuò)誤的正例(False Positive, FP)用FP來(lái)表示;正確的反例(True Negative, TN)用TN來(lái)表示。

表4 混合矩陣
精度值(Precision)的定義如式(5)所示、召回率(Recall)的定義如式(6)所示、F值的定義如式(7)所示:
Precision=TP/(TP+FP)
(5)
Recall=TP/(TP+FN)
(6)
F=(2*Precision*Recall)/(Precision+Recall)
(7)
其中:精度值是分類問(wèn)題中常用的指標(biāo),它反映分類器對(duì)數(shù)據(jù)集的整體分類性能;召回率度量分類器正確預(yù)測(cè)克隆重構(gòu)的比例。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)?zāi)繕?biāo)軟件
本實(shí)驗(yàn)選取5款開(kāi)源軟件分別是:Tomcat 7.0、Apache Ant、ArgoUML、Lucene、PostgreSQL,基本信息如表5所示。本研究之所以選擇這些系統(tǒng)不僅僅是這些系統(tǒng)比較龐大,而且這幾個(gè)系統(tǒng)已經(jīng)通過(guò)趙玉武等[24]在克隆代碼Bugs的研究中進(jìn)行了實(shí)驗(yàn)。

表5 實(shí)驗(yàn)軟件基本信息
3.2 實(shí)驗(yàn)結(jié)果
由于位于決策樹(shù)根部附近的特征不能代表其預(yù)測(cè)能力,因此選擇不同的特征子集,并使用每個(gè)子集來(lái)訓(xùn)練一個(gè)新的分類器。本實(shí)驗(yàn)選擇三個(gè)子集的特征。這三個(gè)子集分別是克隆關(guān)系、克隆內(nèi)容以及克隆代碼段。
實(shí)驗(yàn)結(jié)果如表6所示(使用子集對(duì)克隆重構(gòu)組、非重構(gòu)組進(jìn)行分類訓(xùn)練的性能),從表6中可以得出如下結(jié)論。
1)在5個(gè)目標(biāo)系統(tǒng)中,沒(méi)有一個(gè)特征子集的性能始終優(yōu)于其他子集。
2)和所有特征訓(xùn)練的分類器相比,克隆代碼片段的特征可以產(chǎn)生最接近的結(jié)果。如重構(gòu)組ArgoUML目標(biāo)系統(tǒng)中所有特征訓(xùn)練分類器的精度值為0.813、召回率為0.785,與此最相近的是受過(guò)克隆上下文訓(xùn)練分類器的精度值為0.798、召回率為0.779。其他目標(biāo)系統(tǒng)也是如此。
3)與克隆上下文相關(guān)的特征產(chǎn)生的結(jié)果略低于受過(guò)所有特征訓(xùn)練的分類器。如重構(gòu)組ArgoUML目標(biāo)系統(tǒng)中所有特征訓(xùn)練分類器的精度值為0.813、召回率為0.785。受過(guò)克隆上下文訓(xùn)練分類器的精度值為0.751、召回率為0.732,略低于所有特征訓(xùn)練的分類器。其他目標(biāo)系統(tǒng)也是如此。
4)通過(guò)學(xué)習(xí)克隆關(guān)系的特征,例如特征3(克隆類是否是一個(gè)Type- 3克隆),或者特征4(克隆片段是否在同一個(gè)文件中,或者是兄妹姐妹),分類器的性能獲得一小部分的改進(jìn)。如重構(gòu)組ArgoUML目標(biāo)系統(tǒng)中所有特征訓(xùn)練分類器的精度值為0.813、召回率為0.785,受過(guò)克隆關(guān)系訓(xùn)練分類器的精度值為0.635、召回率為0.801,略低于所有特征訓(xùn)練的分類器。其他目標(biāo)系統(tǒng)也是如此。
基于以上結(jié)論,得出克隆代碼段的特性獨(dú)立于克隆關(guān)系及克隆內(nèi)容,產(chǎn)生的結(jié)果可用于推薦重構(gòu)的克隆代碼。

表6 使用子集對(duì)不同組進(jìn)行分類訓(xùn)練的性能對(duì)比
本實(shí)驗(yàn)選取K折交叉驗(yàn)證來(lái)評(píng)估驗(yàn)證,此方法的基本思想是將輸入數(shù)據(jù)集劃分為訓(xùn)練集和測(cè)試集,因?yàn)闇y(cè)試集和訓(xùn)練集中測(cè)試集對(duì)分類器是不可見(jiàn)的,所以進(jìn)行交叉驗(yàn)證的對(duì)象是訓(xùn)練集輸出的結(jié)果。
第1步 將數(shù)據(jù)集D劃分為k個(gè)大小相似的互斥子集,即D=D1∩D2∩D3∩…∩Dk,每個(gè)子集之間沒(méi)有交集。
第2步 然后每次用k-1個(gè)子集的并集作為訓(xùn)練集,余下的那個(gè)作為測(cè)試集,這樣得到k組訓(xùn)練/測(cè)試集。
第3步 可以進(jìn)行k次訓(xùn)練和測(cè)試,最終返回的是這k個(gè)結(jié)果的均值。
第4步 可以隨機(jī)使用不同的劃分次數(shù)。
本實(shí)驗(yàn)選取K=10,即K折交叉驗(yàn)證來(lái)評(píng)估分類器預(yù)測(cè)模型,通過(guò)利用大量數(shù)據(jù)集以及使用不同技術(shù)進(jìn)行大量實(shí)驗(yàn)發(fā)現(xiàn)10折獲得的誤差最小,因此本實(shí)驗(yàn)將數(shù)據(jù)集分為10份。驗(yàn)證結(jié)果如表7所示,分別顯示了重構(gòu)組和非重構(gòu)組的精度值、召回度、F度量。
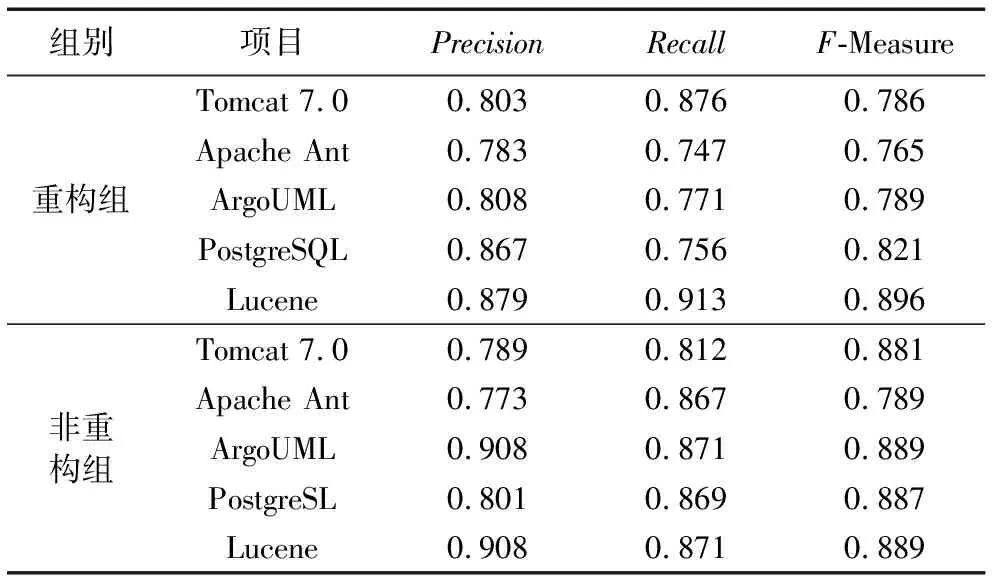
表7 對(duì)不同組的測(cè)試結(jié)果對(duì)比
從表7的重構(gòu)組對(duì)比可以得出,重構(gòu)組10倍交叉驗(yàn)證的精度值從78.3%提高到了87.9%,提高了9.6個(gè)百分點(diǎn);召回率從74.7%提高到了91.3%,提高了16.6個(gè)百分點(diǎn);F值從76.5%提高到了89.6%,提高了13.1個(gè)百分點(diǎn)。從表7的非重構(gòu)組對(duì)比中可以得出,非重構(gòu)組10倍交叉驗(yàn)證的精度值從77.3%提高到了90.3%,提高了13個(gè)百分點(diǎn);召回率從81.2%提高到了87.1%,提高了5.9個(gè)百分點(diǎn);F值從78.9%提高到了88.9%,提高了10個(gè)百分點(diǎn):因此得出本文所構(gòu)造的分類器比隨機(jī)選擇執(zhí)行來(lái)的效果更佳。
3.3 同類實(shí)驗(yàn)對(duì)比分析
當(dāng)前國(guó)內(nèi)外使用機(jī)器學(xué)習(xí)的方法預(yù)測(cè)出需要重構(gòu)的克隆代碼方法較少,本團(tuán)隊(duì)的劉冬瑞等[25]也曾使用機(jī)器學(xué)習(xí)方法預(yù)測(cè)需重構(gòu)的克隆代碼,然而其度量值的選取是根據(jù)ISO軟件質(zhì)量標(biāo)準(zhǔn)選取的,不能很好地體現(xiàn)需重構(gòu)克隆代碼的特征,而本研究度量值的選取是從重構(gòu)實(shí)例中提取的,相對(duì)而言,可信度更好,可行性更強(qiáng)。使用機(jī)器學(xué)習(xí)方法預(yù)測(cè)出需要重構(gòu)的克隆代碼具有代表性的是文獻(xiàn)[26]所提出的方法,鑒于文獻(xiàn)[26]直接從公司收集的克隆代碼,而本研究使用NiCad來(lái)檢測(cè)克隆代碼,同時(shí)本研究與文獻(xiàn)[26]提取的特征也不完全一致,因此僅對(duì)推薦克隆重構(gòu)做對(duì)比實(shí)驗(yàn)。其中本文研究與文獻(xiàn)[26]所使用的項(xiàng)目均為Java項(xiàng)目,實(shí)驗(yàn)平臺(tái)同為操作系統(tǒng):Ubuntu14.04 64位、8 GB內(nèi)存、2核CPU。版本信息如表8所示。
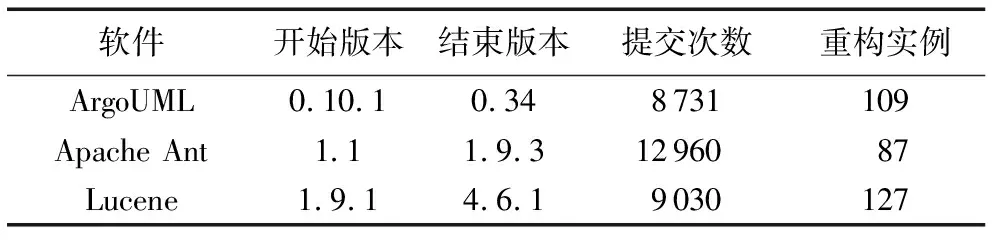
表8 推薦克隆重構(gòu)對(duì)比實(shí)驗(yàn)軟件信息
通過(guò)對(duì)比實(shí)驗(yàn),結(jié)果如表9所示。

表9 推薦克隆重構(gòu)同類實(shí)驗(yàn)結(jié)果對(duì)比
從推薦克隆重構(gòu)結(jié)果中分析軟件ArgoUML的精度值、召回率和F值,與文獻(xiàn)[26]的方法相比,本文方法的精度值提高了10個(gè)百分點(diǎn)、召回率提高了10個(gè)百分點(diǎn)、F值提高了9.8個(gè)百分點(diǎn)。從推薦克隆重構(gòu)結(jié)果中分析軟件Apache Ant的精度值、召回率和F值,與文獻(xiàn)[26]的方法相比,本文方法的精度值提高了10個(gè)百分點(diǎn)、召回率提高了6個(gè)百分點(diǎn)、F值提高了3.3個(gè)百分點(diǎn)。從推薦克隆重構(gòu)結(jié)果中分析軟件Lucene的精度值、召回率和F值,與文獻(xiàn)[26]的方法相比,本文方法的精度值提高了4.5個(gè)百分點(diǎn)、召回率提高了9.6個(gè)百分點(diǎn)、F值提高了2.4個(gè)百分點(diǎn)。綜上本文推薦克隆代碼重構(gòu)方法的召回率、精度值、F值均高于文獻(xiàn)[26]方法。
4 結(jié)語(yǔ)
針對(duì)克隆代碼的大量使用會(huì)導(dǎo)致長(zhǎng)期軟件維護(hù)問(wèn)題甚至引入錯(cuò)誤的問(wèn)題,本文提出了一種基于決策樹(shù)的分類器來(lái)推薦克隆進(jìn)行重構(gòu)的方法,通過(guò)Nicad檢測(cè)出源代碼中的克隆代碼,使用基于度量值的方法將重構(gòu)實(shí)例標(biāo)注出來(lái),同時(shí)使用SourceMonitor提取出特征并構(gòu)建樣本數(shù)據(jù)集。最后對(duì)600多個(gè)克隆實(shí)例使用10折交叉來(lái)驗(yàn)證,發(fā)現(xiàn)本文提出的基于決策樹(shù)的分類器來(lái)推薦克隆重構(gòu)方法的精確度、召回率及F值都能達(dá)到80%以上,驗(yàn)證了本文方法的有效性。本研究可以為克隆重構(gòu)提供更好的資源分配,從而改進(jìn)克隆管理。
本文的研究?jī)?nèi)容與實(shí)驗(yàn)仍然存在一些不足之處,例如目前只能推薦用Java開(kāi)發(fā)項(xiàng)目的克隆重構(gòu)、推薦克隆重構(gòu)精度有待提高,在后續(xù)研究中將繼續(xù)改進(jìn),嘗試使用深度學(xué)習(xí)、半監(jiān)督學(xué)習(xí)來(lái)推薦克隆重構(gòu)。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
