基于小波能量譜分析與SVM的柴油機氣閥間隙異常故障診斷
2018-08-30 08:50:16蔣佳煒胡以懷陳彥臻
機電設備 2018年4期
蔣佳煒,胡以懷,柯 赟,陳彥臻
(上海海事大學,上海 201306)
0 引言
在旋轉機械故障的研究中,由于旋轉機械的振動信號在頻域內的能量分布具有比較明顯的特點,所以基于振動信號的故障診斷一直是學者們的研究熱點。基于統(tǒng)計分析和時域分析并利用機器學習的方法在機械故障診斷方面極具潛力,但是這些方法在柴油機故障診斷中運用卻不是很多[1-2]。一方面,柴油機振動信號是瞬時的,如果沒有合適的降噪方法與適當?shù)奶卣魈崛∈侄危蜔o法運用機器學習來進行模式識別;另一方面,柴油機的振動信號與許多運動機構有關,一個振動信號由多個激振力產生。作為柴油機機構中重要的運動部件,閥門、活塞環(huán)組和配氣機構是柴油機振動信號噪聲的主要來源,根據(jù)其振動信號的小波能量譜分析,可以從能量分布的角度對機械振動信號的特征進行有效提取[3],從而實現(xiàn)對這些運動部件的振動診斷。
隨著計算機技術的發(fā)展與智能算法的進步,支持向量機(Support Vector Machines,SVM)與神經網絡算法在機械故障診斷中的應用也取得了巨大的成功[4-6]。設計1套預測及智能檢測專家系統(tǒng),該系統(tǒng)能對未來時間范圍內發(fā)生的故障做出預測,但是知識的獲取及將領域知識轉化為規(guī)則卻比較困難,且一旦建立專家系統(tǒng),它不能處理知識庫規(guī)則以外的新情況,會影響預測的準確度和精度。SVM被認為是一種有效的機器學習方法,相比其他傳統(tǒng)的方法,其擁有更好的泛化性能[7]。
針對柴油機振動信號的特點,本文試圖利用小波能量譜分析對柴油機的振動信號進行特征提取,將能量在不同頻段上的分布作為特征向量輸入SVM,訓練SVM模型使之針對不同的振動信號與故障模型進行有效的分類,從而獲得精確的故障分析結果。
1 故障模擬試驗
本次試驗使用的是4135高速柴油機,本文使用的數(shù)據(jù)全部采集自實體柴油機試驗。4135高速柴油機型號為 4135AC、機號為 A0422497,其具體參數(shù)如表1所示。

表1 高速柴油機參數(shù)表
對 4135柴油機第一缸振動信號進行分析,試驗數(shù)據(jù)總共分為4組,分別為700 r/min工況下,氣閥間隙正常和異常產生的數(shù)據(jù),以及900 r/min工況下,氣閥間隙正常和異常產生的數(shù)據(jù)。正常情況下的進氣閥間隙和排氣閥間隙分別設置為0.25 mm和0.30 mm;異常情況下的進氣閥間隙和排氣閥間隙分別設置為0.65 mm和0.70 mm。
本次試驗共采集 4段信號,每段信號的采樣時長為20 s,采樣頻率為20.48 kHz,總共為65 536個點。
2 小波能量譜分析
2.1 小波分析
基于傅立葉變換的FFT頻譜分析能有效處理平穩(wěn)隨機信號,然而柴油機的振動信號中包含大量的非平穩(wěn)信號,所以基于傅立葉變換的頻譜分析無法滿足要求。
小波分析技術具有良好的時頻局部化特性,不僅可以分析平穩(wěn)的隨機信號,還可以分析非平穩(wěn)的隨機信號。因此,小波分析是診斷柴油機振動信號故障的較為理想的工具[8-13]。
2.2 小波原理簡介

信號f(t)的積分小波變換為

引入內積
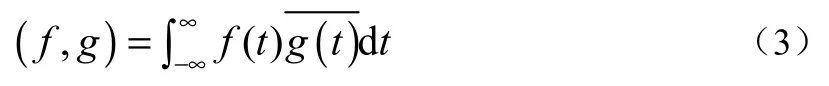
記

如果
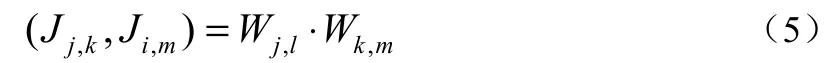
則稱J(t)為正交小波。
S. Mallat在構造正交小波基的時候提出了多分辨率分析(multi-resolution analysis)的概念,給出了正交小波的構造方法以及正交小波變換的快速算法,即Mallat算法。對于多分辨率分析的理解,以三層分解為例,其小波分解樹如圖1所示。小波分解將原始信號逐級向下分解。圖中 S代表原始信號,A1、A2、A3分別代表第一、二、三層中的低頻系數(shù),D1、D2、D3代表對應的高頻系數(shù)。
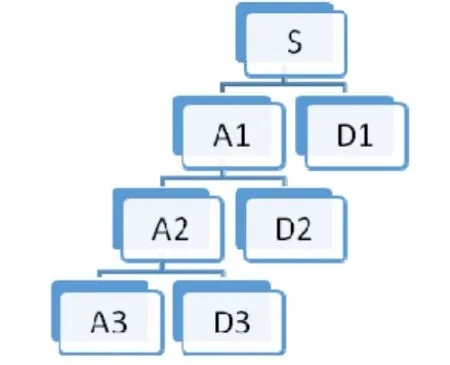
圖1 小波分解樹
本文利用多分辨率分析進行了故障診斷之前的特征提取。對其中4段信號進行小波分析,將每段信號分為10組,其中每組數(shù)據(jù)時長為2 s,頻率為20.48 kHz,每組數(shù)據(jù)包含2 000個點。使用db2作為小波基函數(shù),將樣本分三層,取出第三層中的低頻系數(shù)cA3。圖2為不同工況和條件下1組信號的小波分析圖。
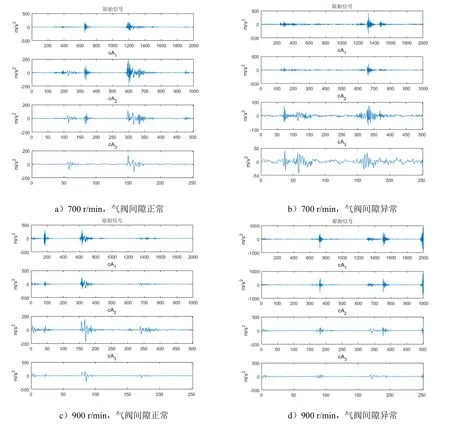
圖2 振動信號樣本小波分析結果
對提取出的低頻系數(shù)cA3進行能量頻段分析,提取能量特征值。設各個頻段的能量為其中:j為層數(shù);N為該頻段的采樣點數(shù)。表2~表5是各個頻段的能量和整個信號的能量比例。將結果作為特征構成五維特征向量輸入到遺傳算法優(yōu)化的支持向量機中進行分類。在40組數(shù)據(jù)中分出8組數(shù)據(jù)構成訓練集,剩下的32組數(shù)據(jù)構成測試集。

表2 700 r/min,氣閥間隙正常時的能量特征提取

表3 700 r/min,氣閥間隙異常時的能量特征提取

表4 900 r/min,氣閥間隙正常時的能量特征提取

表5 700 r/min,氣閥間隙異常時的能量特征提取
3 支持向量機分析
不同于傳統(tǒng)的機器學習方法,SVM是建立在統(tǒng)計學習理論基礎上的一種新的機器學習方法。傳統(tǒng)的機器學習方法遵循經驗風險最小的原則,而 SVM 是根據(jù)結構風險最小化原則所提出的。與人工神經網絡相比,SVM具有更強的推廣能力。
以二分類為例,假設SVM在訓練階段的輸入向量為n、維向量為x,SVM輸出為?1或1,即訓練樣本數(shù)據(jù)集為(xi; yj),其中通過一個非線性映射 ?,把樣本空間映射到一個高維乃至無窮維的特征空間中,在特征空間內構建一個超平面,該超平面可以表示成

所有的訓練樣本滿足如下條件


式中:C為用于平衡松弛變量i和分類邊界的懲罰參數(shù)。
式(8)的解為

式中:K為SVM的核函數(shù)。徑向基是應用廣泛的核函數(shù),該函數(shù)有兩個參數(shù):懲罰因子 C和核函數(shù)參數(shù)σ,其表達式為

由于徑向基核函數(shù)的參數(shù)C和σ的選取沒有理論基礎,而它們的取值會直接決定SVM分類器性能的優(yōu)劣。為了能夠找到C和σ的最優(yōu)值,將GA算法應用到SVM的參數(shù)尋優(yōu)中。GA_SVM的算法框圖如圖3所示。

圖3 GA_SVM算法圖
將4組數(shù)據(jù)每中每組10個樣本隨機抽取2個樣本作為訓練集輸入SVM模型進行訓練,得到一個訓練后的SVM模型。訓練集數(shù)據(jù)如表6所示。

表6 SVM訓練樣本
平行坐標是對多維空間的兩維表示,是表示多維數(shù)據(jù)及進一步分析其相互關系的重要可視化技術[14]。訓練后的SVM模型平行坐標圖如圖4所示。將剩下的每組8個樣本,共32個樣本作為測試集輸入到SVM模型中進行分類,最終測試結果如表7所示,支持向量機正確分類的準確率為100%。

圖4 訓練后的SVM平行坐標圖

表7 SVM測試集結果
4 結束語
本文利用小波分析對數(shù)據(jù)進行降噪,再利用小波能量譜分析對數(shù)據(jù)進行特征提取,將提取出的特征向量輸入到遺傳算法優(yōu)化的支持向量機中建立 SVM 模型,最后利用 SVM 模型對數(shù)據(jù)進行分類。該方法對本次試驗的40組數(shù)據(jù)分類的準確率可以達到100%,說明該方法快速有效,能對柴油機氣閥間隙的故障進行準確的分類,特別是能在不同工況下對柴油機氣閥間隙的異常做到準確的分類。本方法在其他機械故障診斷中也具有相當重要的參考價值。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
天天愛科學(2020年6期)2020-09-10 07:22:44
電子制作(2019年15期)2019-08-27 01:12:00
數(shù)學物理學報(2017年6期)2018-01-22 02:26:40
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
計算物理(2014年2期)2014-03-11 17:01:44
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
