基于馬爾科夫模型的聾生閱讀輸入分析
2018-09-10 20:01:35姚茂建李晗靜呂會華
北京聯合大學學報 2018年3期
姚茂建 李晗靜 呂會華

[摘要]以不同類型文本閱讀輸入角度出發,分析聾生的閱讀輸入規律,以反映聾生閱讀時的表現。通過聾生閱讀輸入的文本與中文分詞標準匹配率在不同等級的轉移情況建立馬爾科夫過程,預測聾生的閱讀輸入結果。通過閱讀實驗以驗證馬爾科夫模型預測的結果,實驗結果顯示,聾生更習慣于閱讀較小的組合詞塊,單音節詞、雙音節詞、三字及四字多音節詞對聾生閱讀有較大影響,這與馬爾科夫模型預測結果比較符合。
[關鍵詞]聾生;自然輸入標注;閱讀輸入;馬爾科夫模型
[中圖分類號]G 762[文獻標志碼]A[文章編號]1005-0310(2018)03-0086-07
Abstract: This article starts with different types of text reading input and analyzes the reading input rules of deaf students to reflect the performance of deaf reading. The Markov process is established through the transfer of the
matching rate of deaf students reading input and the Chinese word segmentation standard at different levels, and finally predicts the reading input of the deaf student. Through reading experiments to verify the results of Markov model predictions, the experimental results show that deaf students are more accustomed to reading smaller combined word blocks, and monosyllabic words, two-syllable words, three\|syllable and four-syllable words have a greater impact on deaf reading. This is in line with the Markov model predictions.
Keywords: Deaf students; Natural typing annotations; Reading input; Markov model
0引言
許多聽力障礙學生的漢語語言是在教學條件下專門培養的,生活環境中無法使用口耳傳遞交流,缺乏語言環境的真實感,也常借助表象來理解詞義,就會含混,甚至誤解[1]。這種含混情況,聾生在漢語書面語上表現突出,常常詞不達意,顛倒語序。關于聾生的閱讀研究大多集中在聾人讀者的閱讀技巧和閱讀策略[2]、語義識別、詞匯、語法、比喻語言、推理能力和工作記憶的測試研究[3],閱讀理解中的實詞和虛詞理解程度差異性[4],詞匯意義的具體性[5]。從以上研究中可以看出,目前聾生閱讀理解的研究相對比較多,但是以聾生閱讀輸入為基礎去提高聾生閱讀理解能力的研究相對較少。詞匯量的多少以及語法掌握程度是閱讀寫作的基礎,通過了解聾生的詞匯能力及語法知識能有效預測他們的閱讀能力[6-8],以往有關聾生詞匯和語法的研究主要具有以下特征:詞匯量少、詞匯貧乏、句子簡短、句式單一[9]。為提高聾生閱讀效果,大多數研究過度強調閱讀技巧或閱讀策略,而忽略了聾生本身的閱讀規律。因此需要尋求一種客觀、定量的評價聾生閱讀輸入的方法,這種方法能反映聾生閱讀時的內在規律,最大程度上反映聾生的閱讀情況。
漢字是由象形文字演變而來的,具有獨特的語標書寫特點,并不能像英文單詞那樣直接輸入字母表征出來[10]。用拼音輸入漢字,在腦海中會有一個預處理過程,即文本信息的抓取,記錄輸入過程就對應著用戶閱讀時的表現。例如,拼音輸入漢字“中國”,我們會在腦海中產生“中國”一詞,并通過鍵盤輸入拼音“zhongguo”,同時會出現一系列同音異形詞組選項,如圖1所示,最后通過數字鍵(1~5)或空格鍵(默認第一個詞組)進行對應詞組的選定,實現拼音到漢字的轉寫。拼音是將漢字轉錄成拉丁字母的輸入方式,漢語的拼音輸入方式是順序式的。如“中華人民共和國今天成立了”,一種閱讀輸入方式為“[中華][人民][共和國][今天][成立][了]”,另一種閱讀輸入方式是“[中華人民共和國][今天][成立了]”,等。從某種意義上來說,記錄和儲存用戶輸入的文本過程,就能反映他們閱讀理解的形式,是詞級別還是短語級別,或者對語句的完整語義是否存在正確的理解。
受到以上啟發,首先,我們通過自然輸入標注軟件記錄聾生閱讀輸入的文本,以側面反映聾生的閱讀過程,建立馬爾科夫模型,以更加科學的方法評價聾生閱讀理解輸入情況。其次,根據模型得出的結果,我們提出相應的假設。再次,通過不同條件下的閱讀實驗以驗證模型預測的結果,分析造成這一結果的原因,發現聾生閱讀規律。
1相關工作
本文以不同專業的聾生作為實驗對象,對聾生拼音輸入的文本進行統計分析。
1.1自然輸入標注實驗
聾生閱讀是一個復雜的構建文本意義的過程,它涉及3種水平的信息加工活動:詞語的識別、句子的理解和文本的解讀[11]。聾生對詞語的識別過程,如果能通過拼音輸入待測試文本,記錄聾生腦海中的預處理過程,即對文本信息的抓取,那么就能很好地反映聾生對中文語句的理解過程。文獻[3]指出,語言理解是指人們借助于聽覺或視覺的語言材料,在頭腦中構建的一種主動的、積極的、有意義的過程。而自然輸入標注(Natural Typing Annotations, NTAs)軟件通過拼音輸入待測試文本,就能記錄測試者相應的閱讀文本內容以及詞語輸入的形式,并以“|”符號標記測試者閱讀理解短語詞塊的大小。軟件輸入測試文本如圖2所示,上一部分為輸入框:拼音輸入內容,下一部分是軟件自動記錄框:輸入過程中產生的信息。進行自然輸入測試實驗前,預先設定輸入法無聯想提示功能,排除聯想記憶對語句自然輸入的干擾,在不告訴實驗目的的情況下,記錄聾生閱讀理解后自然輸入過程。
本研究選取特殊教育學校聽力障礙大學生為測試對象。其中計算機專業大三學生17名:男生9人,女生8人;園林技術專業大三學生12名:男生3人,女生9人;視覺傳達設計專業大三學生14名:男生8人,女生6人。測試獲得自然輸入標注文本數據43份,其中計算機專業學生占總測試人員的39.53%,園林技術專業學生占總測試人員的27.91%,視覺傳達設計專業占總測試人員的32.56%。其中男生占總體人數的46.51%,女生占總體人數的53.49%。
為了使測試具有針對性,選取與聽障大學生相關專業的測試文本,分別對應于計算機、園林技術、視覺傳達等專業內容。測試開始前,將說明文本投影在教室顯示屏上,并用手語的方式重復講解一遍,告知學生軟件使用方法,學生完全理解后,再以自己最習慣的方式進行文本內容的閱讀輸入。
1.2自然輸入標注文本
中文語句的呈現方式可表示為S=c1c2…cn(c1代表一個中文字符,n表示句子S的長度),S=|c1c2…ci1-1|…|ci2ci2+1…cN|cN+1…cn|可以為句子S的一種輸入形式。亦可以將對應的句子切分為S=|s1|s2|…|sM|(其中s1=c1c2…ci1-1,…,sM=cN+1…cn,M詞是語言材料中最小的意義單元,各種復雜的句法、語義都依靠詞來表達。中文分詞標準,其參考標準為《現代漢語語料庫加工規范——詞語切分與詞性標注》,是經過長期探索和實踐經驗得到的現代漢語分詞規范。為研究聾生閱讀規律,我們將中文分詞標準作為參照標準,對各專業聾生自然輸入文本相對頻率以及全體聾生自然輸入文本與中文分詞標準相對頻率分別進行統計畫圖,分別如圖3、圖4所示。
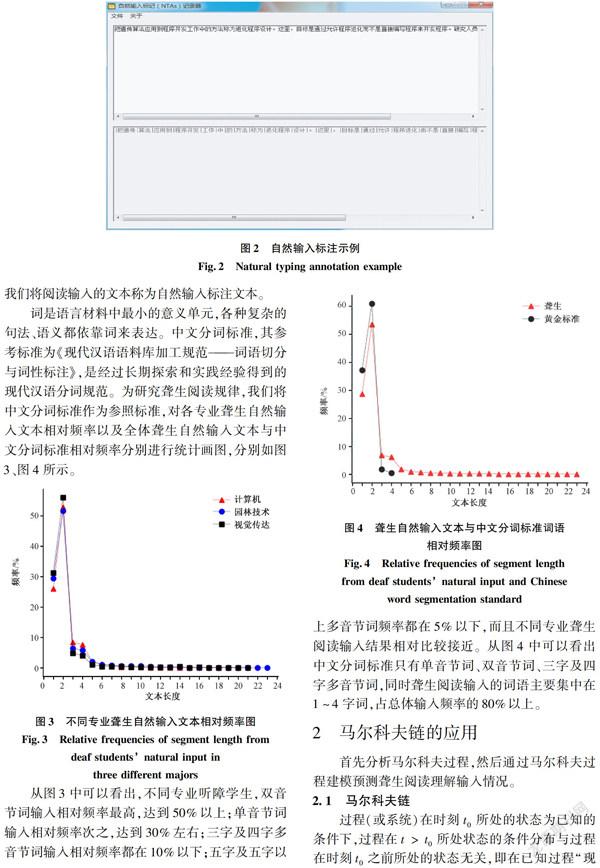
從圖3中可以看出,不同專業聽障學生,雙音節詞輸入相對頻率最高,達到50%以上;單音節詞輸入相對頻率次之,達到30%左右;三字及四字多音節詞輸入相對頻率都在10%以下;五字及五字以上多音節詞頻率都在5%以下,而且不同專業聾生閱讀輸入結果相對比較接近。從圖4中可以看出中文分詞標準只有單音節詞、雙音節詞、三字及四字多音節詞,同時聾生閱讀輸入的詞語主要集中在1~4字詞,占總體輸入頻率的80%以上。
2馬爾科夫鏈的應用
首先分析馬爾科夫過程,然后通過馬爾科夫過程建模預測聾生閱讀理解輸入情況。
2.1馬爾科夫鏈
過程(或系統)在時刻t0所處的狀態為已知的條件下,過程在t>t0所處狀態的條件分布與過程在時刻t0之前所處的狀態無關,即在已知過程“現在”的條件下,其“將來”不依賴于“過去”,而只與t0時刻有關,這種性質為無后效性[12]。如果n個事件在變動過程中,任意一次的變動結果都具有無后效性,那么這n個事件組成的集合就叫做馬爾科夫鏈,事件演變的過程則稱為馬爾科夫過程。
2.2狀態及狀態轉移過程
在馬爾科夫過程預測中,狀態是一個重要概念,它表示事件在某個時刻發生的某種結果。對事件進行預測,就需要知道事件發生的可能結果,求出每種結果發生的概率,進而預測事件出現每種結果的可能性程度。例如,城市居民出行方式預測過程中,有“公交”“自行車”“步行”“地鐵”或“其他”等出行狀態。
事件在發展變化過程中,從某一種狀態轉變為另一種狀態,這種轉變就叫狀態轉移。例如,某人的身體情況有兩種狀態,健康或者發燒,從健康轉變為發燒、或從發燒轉變為健康就是狀態轉移。將事件隨時間的變化而進行的狀態轉移,稱為狀態轉移過程。
2.3狀態轉移概率及狀態轉移矩陣
2.4馬爾科夫過程建模
利用馬爾科夫鏈存在與之前的狀態無關,只由文本變化、大腦進行閱讀、拼音輸入等因素確定的極限狀態這個特點,將聾生專業文本自然輸入標注文本與中文分詞標準匹配率劃分為若干種有限狀態,把非專業文本自然輸入作為下一個狀態,則從上一個狀態到下一個狀態聾生自然輸入標注文本與中文分詞標準匹配率的變化情況,可反映不同專業文本自然輸入條件下,聾生閱讀理解后輸入的詞塊規律,而這種規律具有穩定的轉移趨勢。這種轉變是由聾生專業文本閱讀后輸入狀態向非專業文本閱讀后輸入狀態的轉化,即相當于現在所處的狀態向下一時刻的轉化,因此與之前的狀態無關,此過程具有無后效性。學生閱讀理解后自然輸入過程就可以看成是馬爾科夫鏈,利用馬爾科夫鏈的極限分布,就可以對總體聾生閱讀輸入情況進行預測。
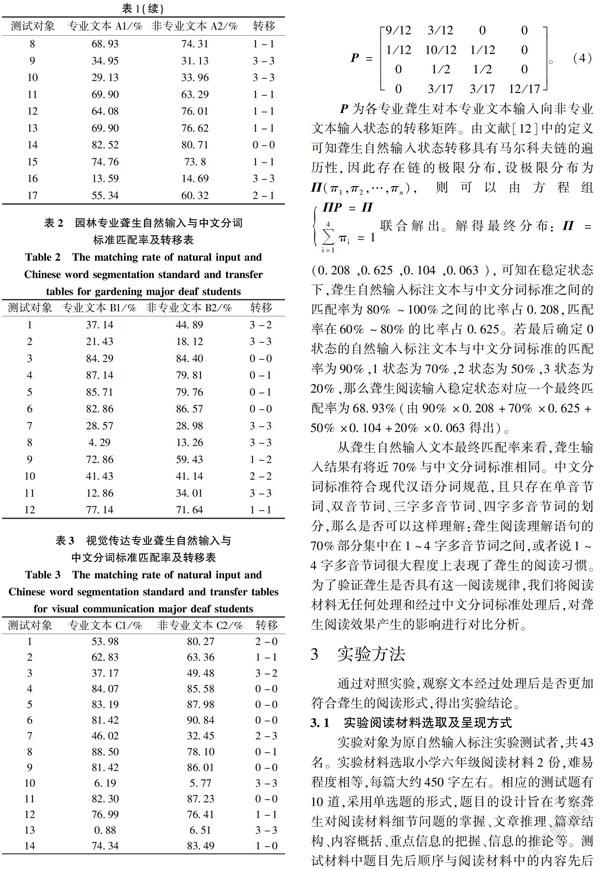
把要考評的學生閱讀理解自然輸入過程分為兩個階段(本專業文本輸入,非本專業文本輸入)。將自然輸入標注文本與中文分詞標準匹配率在80%~100%之間記為狀態0,60%~80%之間記為狀態1,40%~60%之間記為狀態2,40%以下記為狀態3,共為4個狀態。以ni表示本專業文本i等級學生數,nij表示i等級轉移到j等級的人數,以nij/nj表示i等級轉移到j等級的概率。各專業聾生自然輸入與中文分詞標準匹配率及轉移表分別如表1、表2、表3所示,并計算得出轉移矩陣(4)。
從聾生自然輸入文本最終匹配率來看,聾生輸入結果有將近70%與中文分詞標準相同。中文分詞標準符合現代漢語分詞規范,且只存在單音節詞、雙音節詞、三字多音節詞、四字多音節詞的劃分,那么是否可以這樣理解:聾生閱讀理解語句的70%部分集中在1~4字多音節詞之間,或者說1~4字多音節詞很大程度上表現了聾生的閱讀習慣。為了驗證聾生是否具有這一閱讀規律,我們將閱讀材料無任何處理和經過中文分詞標準處理后,對聾生閱讀效果產生的影響進行對比分析。
3實驗方法
通過對照實驗,觀察文本經過處理后是否更加符合聾生的閱讀形式,得出實驗結論。
3.1實驗閱讀材料選取及呈現方式
實驗對象為原自然輸入標注實驗測試者,共43名。實驗材料選取小學六年級閱讀材料2份,難易程度相等,每篇大約450字左右。相應的測試題有10道,采用單選題的形式,題目的設計旨在考察聾生對閱讀材料細節問題的掌握、文章推理、篇章結構、內容概括、重點信息的把握、信息的推論等。測試材料中題目先后順序與閱讀材料中的內容先后順序無關。測試材料分為未處理和經過中文分詞標準處理兩種情況,對測試材料處理后的部分內容呈現方式如下:
東海龍王父子稱霸一方,作惡多端,還經常興風作浪,害得人們不敢下海捕魚。哪吒決心治一治他們,為老百姓出一口氣。
3.2實驗結果統計
閱讀材料時間為10分鐘,閱讀完畢后,將閱讀材料上交,過5分鐘后再進行測試答題。測試指導語:請回憶閱讀材料內容,并根據閱讀材料內容,回答問題。共10道題目,每題有4個選項,請選擇與文章內容最相符的選項。每道題答對記1分,答錯或不答記0分。被試得分情況如圖5所示。
3.3實驗結果分析
我們使用SPSS統計軟件對實驗結果進行配對樣本t檢驗,實驗結果如表4所示。可以看出,在閱讀材料未處理情況下,43名同學的閱讀平均得分成績為6.35,而經過中文分詞標準處理后的閱讀平均成績為7.19。
樣本相關性如表5所示,本次樣本共選取了43名聾生,閱讀材料處理與未處理之間的相關性為0.549,相關系數越大表示相關程度越高,顯著性水平<0.05。由于選取的置信水平α=0.05,即置信區間為95%,實驗結果P<0.05,則拒絕原假設H,表明閱讀材料未處理與處理后具有顯著相關性。
配對樣本檢驗結果如表6所示,兩組配對實驗的均數差值為-0.837,標準差為1.446,標準誤差為0.221,95%的置信區間為[-1.282,-0.392],差值為負數表示聾生閱讀未處理材料比閱讀處理后的材料得分低。在閱讀表現上,聾生閱讀處理后的材料(7.19±1.617)比閱讀未處理材料(6.35±1.402)的閱讀表現高0.837分,差異具有統計學意義,同時由表6看出P<0.05,即閱讀材料未處理與經過中文分詞標準處理后對聾生閱讀得分有顯著性差異。由此可見,1~4字多音節詞很大程度上體現了聾生的閱讀規律,將語句切分處理對聾生閱讀理解具有一定的幫助作用。
漢語書面語的書寫方式為緊密排列、字字相連,這對讀者分詞斷句和語義提取造成了一定的困難。以漢語為母語的人在閱讀時一般會通過小聲默讀的形式加深對語義的理解,但也會遇到停頓、復讀、回看等情況,而以漢語為第二語言的聾人來說,這些問題比較突出。通過記錄聾生的閱讀理解輸入表現,分析在輸入中是否存在分詞斷句、語義提取等現象。語感會對閱讀起到幫助理解作用,而語感是對文字進行理解、體會、分析的感悟能力,記錄聾生閱讀輸入表現能很好地體現閱讀理解形式。一般來說,好的閱讀表現能從閱讀分詞上來體現。馬爾科夫建模結果顯示,聾生輸入結果有接近70%部分與中文分詞標準相同,表明分詞能表征聾生的閱讀理解輸入形式。同時閱讀材料在經過處理與未處理情況下,對聾生閱讀表現具有顯著性差異,閱讀材料作分詞處理能降低聾生理解難度,有利于提高理解能力。這種差異解釋了對語句進行分詞劃分有助于辨別詞語、關鍵詞定位,達到正確理解語義的目的,聾生能較好的理解并回憶起文章的內容,而且這種方式在一定程度上比較符合聾生的閱讀習慣,能更好地概括信息。
4結束語
本文通過自然輸入標注軟件記錄聾生閱讀輸入過程,提出運用馬爾科夫模型預測聾生閱讀輸入結果的方法。將閱讀材料分詞處理后,對聾生閱讀能起到幫助作用,這比較好地解釋了馬爾科夫模型預測結果。聾生閱讀輸入的文本存在分詞斷句現象,記錄閱讀輸入過程能反映聾生閱讀理解形式,這為研究聾生閱讀模式、閱讀特點提供了一個新思路。
雖然文章材料作分詞處理后能幫助理解,但是多長的斷句能更好地幫助聾生閱讀理解?同時,聾生閱讀是一個復雜的過程,影響聾生閱讀理解還有很多內在因素,如聾生與健聽人書面語交流流暢程度、自身聽力情況、普通學校就讀時間等等,都會間接地影響聾生的閱讀表現。這說明在考慮外部因素外,還應根據聾生自身情況,分析對聾生閱讀的影響以改進聾生閱讀形式,為提高聾生閱讀能力提供科學依據。將不同專業聾生閱讀表現進行對比分析,發現聾生共同的閱讀形式,將這種閱讀形式加入到聾生閱讀文本中進行評估是后期主要研究方向。
[參考文獻]
[1]張寧生.教學實踐中耳聾兒童學習語言的某些特點[J].心理學報,1980,12(4):390-396.
[2]Banner A, Wang Y. An analysis of the reading strategies used by adult and student deaf readers[J]. Journal of Deaf Studies and Deaf Education, 2011, 16(1):2-23.
[3]彭聃齡.普通心理學[M].第4版.北京:北京師范大學出版社,2012:132-135.
[4]Krejtz I, Szarkowska A, ogińska M. Reading function and content words in subtitled videos[J]. Journal of Deaf Studies and Deaf Education, 2016, 21(2):222-232.
[5]Moreno-pérez F J, Saldaa D, Rodríguezortiz I R. Reading efficiency of deaf and hearing people in Spanish[J]. Journal of Deaf Studies and Deaf Education,2015, 20(4):374-384.
[6]Coppens K M, Tellings A, Verhoeven L, et al. Depth of reading vocabulary in hearing and hearing-impaired children[J]. Reading and Writing, 2011, 24(4):463-477.
[7]Kyle F E, Campbell R,Macsweeney M. The relative contributions of speechreading and vocabulary to deaf and hearing childrens reading ability[J]. Research in Developmental Disabilities, 2016, 48:13-24.
[8]Adams-Means C L. Deaf learners: developments in curriculum and instruction[J]. Disability Studies Quarterly, 2006, 26(4):218-223.
[9]Takahashi N, Isaka Y, Yamamoto T, et al. Vocabulary and grammar differences between deaf and hearing students[J]. Journal of Deaf Studies & Deaf Education, 2016, 22(1):88.
[10]Zhang D, Mao Y, Liu Y, et al. The discovery of natural typing annotations: user-produced potential Chinese word delimiters[C]//Meeting of the Association for Computational Linguistics and the International Joint Conference on Natural Language Processing. 2015:662-667.
[11]Wauters L, Bon W H J V, Tellings A, et al. In search of factors in deaf and hearing childrens reading comprehension [J]. American Annals of the Deaf, 2006, 151(3): 371-380.
[12]張衡.馬爾科夫鏈的一個應用[J].長春光學精密機械學院學報,1994,17(3):44-49.
[13]耿建軍,焦德杰. 基于馬爾科夫鏈的統計分析的教學評估方法[J]. 聊城大學學報(自然科學版),2006,19(4): 97-100.
(責任編輯白麗媛)
