數據驅動下的礦產預測模型構建方法研究
2018-09-20 05:24:08朱月琴常力恒
中國礦業 2018年9期
關鍵詞:模型
聶 虹,朱月琴,常力恒,閆 東
(1.中國地質大學(北京)地球科學與資源學院,北京 100083; 2.自然資源部地質信息技術重點實驗室,北京 100037; 3.中國地質調查局發展研究中心,北京 100037; 4.中國地質大學(武漢)資源學院,湖北 武漢 430074; 5.中國礦業大學(北京)地球科學與測繪工程學院,北京 100083)
0 引 言
人類提升對世界的認識能力的方法就是從現實世界中發現規律,從感性認識上升到理性認識。從自然科學的角度來看,人類描述自然規律的方法是用數學公式的方法,將規律用一個數學公式(或者類似的數學工具)表達,這就是所謂的模型(model)或模式(pattern),所謂的數學建模就是從大量的數據中發現數量之間關系并且用數學公式的方式體現出來。建模首先就得有數據,隨著IT技術的興起,人類收集了海量的數據,但傳統的計算科學已經越來越難以處理海量的數據。為了適應數據量的飛速膨脹,我們需要一種新的研究工具才能更有效地進行科學計算,因此,以處理海量數據為核心的“第四范式”——數據密集型科研應運而生。這是一個計算無處不在、軟件定義一切、數據驅動發展的新時代。
大數據技術,包括海量數據獲取技術,海量數據存儲技術,海量數據的計算技術,海量數據的分析技術和數據可視化,已成為當前第四范式的主要工具。大數據正在引發地球科學領域異常深刻的革命,大數據的關鍵不在于數據的大,而在于思維的新,從數據出發,讓數據說話,依靠人工智能方法,讓機器學習、深度學習、可視分析等大數據技術逐步成為必需。大數據作為第四科學范式的研究領域十分寬廣,它將改變地球科學家的思維方式,從邏輯思維方式轉變為數據驅動的關聯思維方式[1]。
如何從數據抽象出模型。從理論上講,只要有足夠代表性的樣本(數據),就可以運用數學方法找到一個或者一組模型的組合使得它非常接近真實情況。計算機技術的進步、大數據的普及使得在數據驅動下構建模型得以實現,對一個問題暫時不能用簡單而準確的方法解決時,可以根據以往的歷史數據,構造出近似的模型來逼近真實情況,實際上是用計算量和數據量來換取研究時間,得到的模型雖然和真實情況有偏差但是足以指導實踐。機器學習,是人工智能領域的一個分支,其基本思想是基于數據構建統計模型,并利用模型對數據進行分析和預測;而深度學習基本上是“更深層次”的機器學習,運用的都是數據驅動的思維去構建模型。
1 研究方法與模型現狀分析
1.1 數據驅動下的模型構建方法研究現狀
機器學習可以發揮出計算機在推理和學習等方面的能力,實現自動學習數據,從中提取出復雜的模式,繼而提出智能決策,在金融和醫學等領域越來越受到人們的關注[2]。
互聯網金融的興盛,每時每刻都在產生著海量的各類金融數據,有效地管理它們并及時地預測與分析發展其發展態勢,更深層次地挖掘出它們背后潛在規律和內在的聯系,需要將金融數據與人工智能、機器學習等緊密地聯系起來。金融領域里人工智能和機器學習的應用主要以下幾個部分:面向金融客戶的應用、管理層面的應用、交易及資產組合管理、監管合規等[3]。金融風險預測傳統上依靠經驗判斷,隨著業務量的增大和金融數據的日益龐大,傳統的方法已經無能為力,機器學習方法為金融風險預測注入了新的動力,主要使用的機器學習算法包括人工神經網絡、決策樹、K最近鄰分類算法、貝葉斯網絡、集成學習技術和支持向量機等。如:Chen等[4]提出了一種結合模糊邏輯和人工神經網絡的混合破產預測模型,Min等[5]提出的一種基于支持向量機的破產預測模型,Chaudhuri等[6]提出一種基于模糊支持向量機的破產預測模型。Oliveira[7]通過組合指數平滑、自回歸積分滑動平均模型模型、人工神經網絡模型和支持向量回歸機來預測金融時序數據。
1.2 數據驅動下的礦產預測模型研究現狀
礦產預測是礦產資源勘查的重要組成,經歷了由定性預測到定量預測的過程[8](表1),預測方法具有復雜、精細、多元信息綜合等特點。礦產預測的方法可以分為知識驅動(依據專家經驗知識,各類參數由專家確定)和數據驅動[9](對成礦要素和已知礦點相關關系進行定量化分析之后,建立數學模型)。數據驅動的建模方法主要有:證據權模型[10-14]、邏輯回歸[15-16]、D-S證據理論[17-18]、模糊邏輯[19]、人工神經網絡[20-21]、支持向量機[22-23]和隨機森林[24-25]等方法應用的都很廣泛。

表1 礦產資源預測評價發展歷程
近年來,隨著地質大數據時代的到來,使得礦產預測向定量化、智能化、三維可視化等方向發展。利用數據挖掘等技術,更深層次地識別和提取出找礦信息,分析礦產資源信息的空間關聯性,結合地質、物探、化探、遙感資料,開展綜合信息礦產預測工作。
隨著人工智能、機器學習、深度學習的興起,機器學習和深度學習算法在礦產礦產資源評價中應用的也比較廣泛。如:Brown[26]在礦產資源評價中使用了人工神經網絡模型;陰江寧等[27]應用Hopfield循環神經網絡對新疆東天山的銅鎳硫化物礦床進行礦產資源評價;Abedi等[28]在評價斑巖銅礦資源中使用了多分類支持向量機;Carranza等[29]在預測菲律賓碧瑤地區金礦資源時使用了邏輯回歸、證據權和隨機森林三種模型。相較于以前統計方法,機器學習算法的優勢在于能更好地表現出礦化點和空間要素之間的非線性的復雜關系。
但是機器學習算法的預測效果,仍然受很多不確定因素的影響,比如:模型的優化,如何調整各模型的參數達到最優,使其更加適用于礦產預測;訓練樣本的選擇,訓練樣本數據的數量和質量對礦產預測也有很大的影響。
本文采用的是決策樹、支持向量機、卷積神經網絡算法來構建礦產預測模型,分析三個模型的性能和評價結果,找出更適合提高礦產預測效率的算法模型。
2 數據驅動下的礦產預測模型構建
當前的礦產預測工作中,應用地質、物探、化探、遙感等多種綜合信息來找礦,是當下礦產勘查工作發展的新思路。對于研究物探、化探資料傳統的方法是找到各種化探和物探異常,再用地質理論對它們進行分析和解釋。本文中,改變了傳統的研究思路,將地質、物探、化探、遙感數據融合起來,將區域航磁數據與化探數據統一格式,同時進行計算處理。運用決策樹、支持向量機(SVM)、卷積神經網絡算法(CNN)構建礦產預測模型,學習區內全部數據,提取特征,分析預測“有礦單元”,即已有礦床(點)產出的區域。具體工作流程如圖1所示。
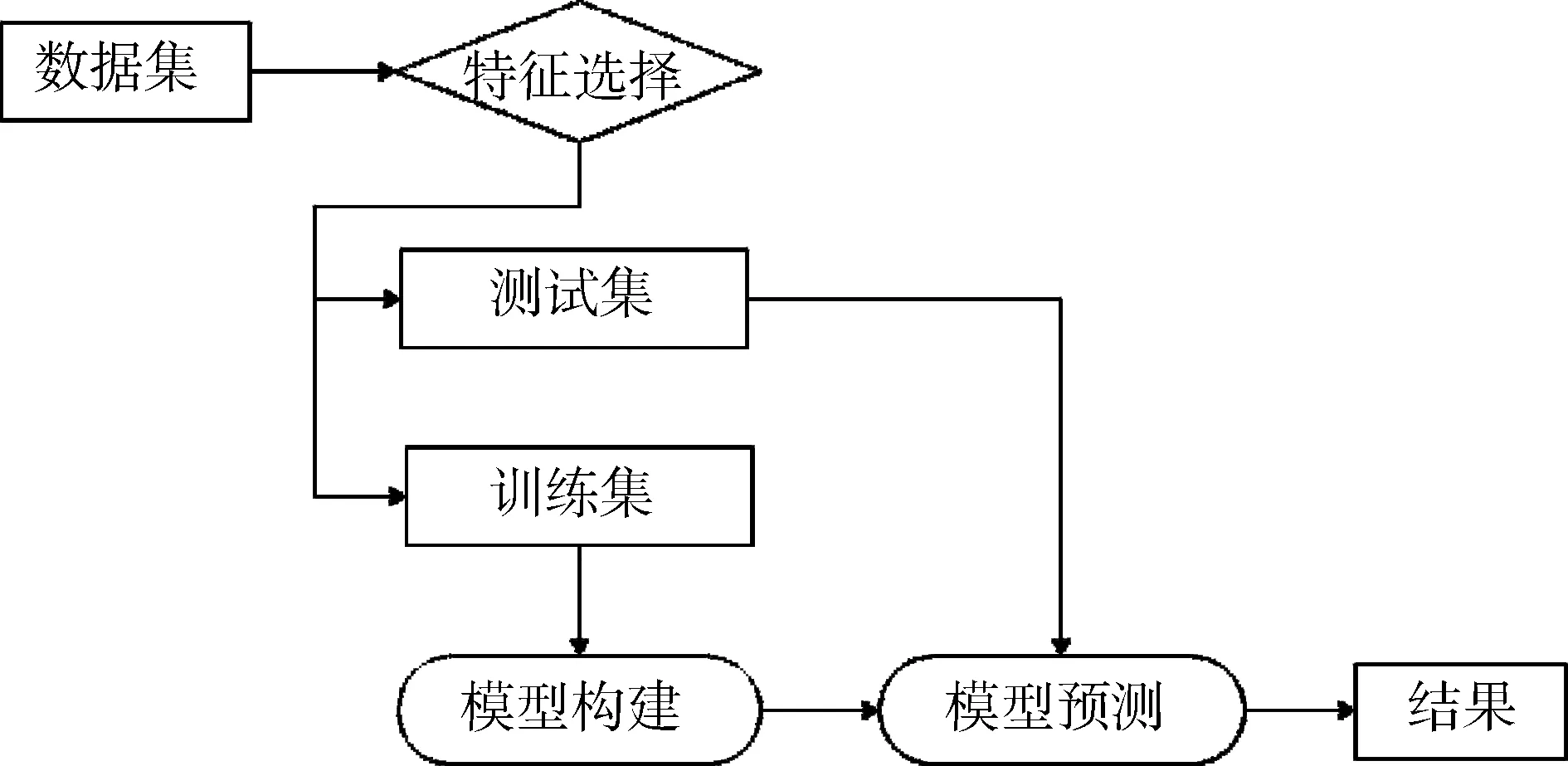
圖1 建模流程圖
2.1 數據預處理(關聯分析)
2.1.1 面向礦產資源信息的空間關聯性分析
所謂的關聯性分析,即將多源、多類的數據綜合起來,探索出數據中潛在的相關關系和相關程度,找出數據之間的關聯性,繼而挖掘出地質大數據中更深層次的潛在價值、地質要素之間的共生組合規律等。
礦產資源數據具有空間特征、屬性特征、時間特征等。不同類型的地質空間數據從某一個方面反映了地質對象的屬性特征,而對于空間位置相鄰或相同的數據,在空間特征上也往往存在著相似性,屬性特征上呈現出一定的空間關聯性。因此,可以針對不同類型的空間數據,建立數據之間基于位置的強關聯。將不同專題類型的空間數據統一至相同的坐標系統下,提取數據的空間屬性特征,建立數據的空間屬性數據庫。關聯性分析則是在空間數據庫的基礎上發現和挖掘不同項集之間隱藏的關聯關系。統計礦床產出位置不同的地質現象、地質體、地球化學元素等空間實體出現的頻數。將頻數最高的特征屬性或超過一定閾值范圍的特征屬性轉換為關聯規則[30]。
2.1.2 物化探信息綜合處理
本文是以化探資料為主要信息,結合地、物、遙資料,開展綜合信息礦產預測工作。需要解決兩個問題:一是精準的異常下限確定——提高原始數據精度;二是有效的分幅平差處理——消除系統誤差,提取低緩異常信息。
目前確定異常下限的方法十多種,并且不斷有新方法被提出,不同方法確定的異常下限相差懸殊(達數倍)。化探資料處理的首要問題是準確確定異常下限。
應用分形理論準確確定了各圖幅、各元素的正異常下限和負異常上限。
消除各圖幅系統誤差:①分幅定量系數補償;②分幅相鄰邊沿平均值補償,其共同的問題是低緩假異常產生、低緩真異常丟失。本文采取的工作方式是通過異常下限的準確確定,以線性擬合方案精確的進行分幅平差處理,以確保低緩信息(異常)不被遺漏。
為使物探、化探數據能夠同時進行相關定量處理,選取以化探數據坐標點為中心,以1 km為直徑范圍內平差后航磁數據的最大值(ΔTd)和最小值(ΔTx)作為新的航磁參數,如此選擇即考慮到航磁的正、負異常,同時兼顧了航磁梯度帶的特征。經整理構建起全區樣本——即多個變量形成的定量處理的數據集。
2.2 模型構建
選用規格單元為研究對象,以物探、化探、遙感數據為變量,構建起礦產預測模型。
2.2.1 標記數據
在經過物化探信息綜合處理后的數據集中每一條記錄對應一個特定的統計單元,數據取值為0、1。對于某一找礦證據或含礦屬性來說,1代表單元內有礦床(點)存在或有找礦證據存在;0代表無礦或無找礦證據存在[31]。
2.2.2 訓練集和測試集選取
從中選擇一定量的特征數據作為訓練樣本構建算法模型,在總數據集中隨機選取其中一半的數據,作為訓練樣本集進行訓練,構造模型,其余數據作為預測集,對訓練出的模型進行預測。
2.2.3 基于決策樹的礦產預測模型
決策樹(decision tree),顧名思義,就像一棵樹,是一種特殊的樹形結構。它類似于流程圖的結構,其中每個內部節點表示一個屬性上的“測試”,每個分支表示測試的結果,每個葉節點表示類標簽(在計算所有屬性之后所采取的決定)。從根到葉的路徑代表分類規則,從而生成一棵決策樹[32]。進行從數據產生決策樹的機器學習技術叫做決策樹學習,通俗說就是決策樹。在機器學習中,決策樹是預測模型,將預測的對象屬性與對象值之間建立一種映射關系。在做數據挖掘時,決策樹會經常使用,既可以通過它來分析數據,也可以做預測。在做面向礦產預測評價的機器學習時,決策樹也是用的比較多的一種算法。
2.2.4 基于SVM的礦產預測模型
在機器學習中,支持向量機(support vector machine,SVM)是分類與回歸分析中分析數據的監督式學習模型與相關的學習算法。SVM算法最初是為二值分類問題設計的,實現多分類的主要方法是將一個多分類問題轉化為多個二分類問題。將給定一組訓練樣例,每個訓練樣例標記為屬于兩個類別中的一個或另一個,通過這樣的算法延伸,如果有k個類別的樣本的話,就可以構造出了k個二分類SVM,SVM可被推廣為結構化的支持向量機,推廣后標簽空間是結構化的并且可能具有無限的大小。SVM的優勢體現在可較好地解決小樣本情況下非線性函數擬合問題,并且具有適應性強、全局優化、訓練時間短、泛化性能好等優點。
2.2.5 基于卷積神經網絡的礦產預測模型
深度學習受到了越來越多研究者的關注,它在特征提取和建模上都有著相較于淺層模型顯然的優勢。深度學習善于從原始輸入數據中挖掘越來越抽象的特征表示,而這些表示具有良好的泛化能力。它克服了過去人工智能中被認為難以解決的一些問題,且隨著訓練數據集數量的顯著增長以及芯片處理能力的劇增,它在目標檢測和計算機視覺、自然語言處理、語音識別和語義分析等領域成效卓然,因此也促進了人工智能的發展。
深度學習是包含多級非線性變換的層級機器學習方法,深層神經網絡是目前的主要形式,其神經元間的連接模式受啟發于動物視覺皮層組織,而卷積神經網絡(CNN)則是其中一種經典而廣泛應用的結構(圖2)。
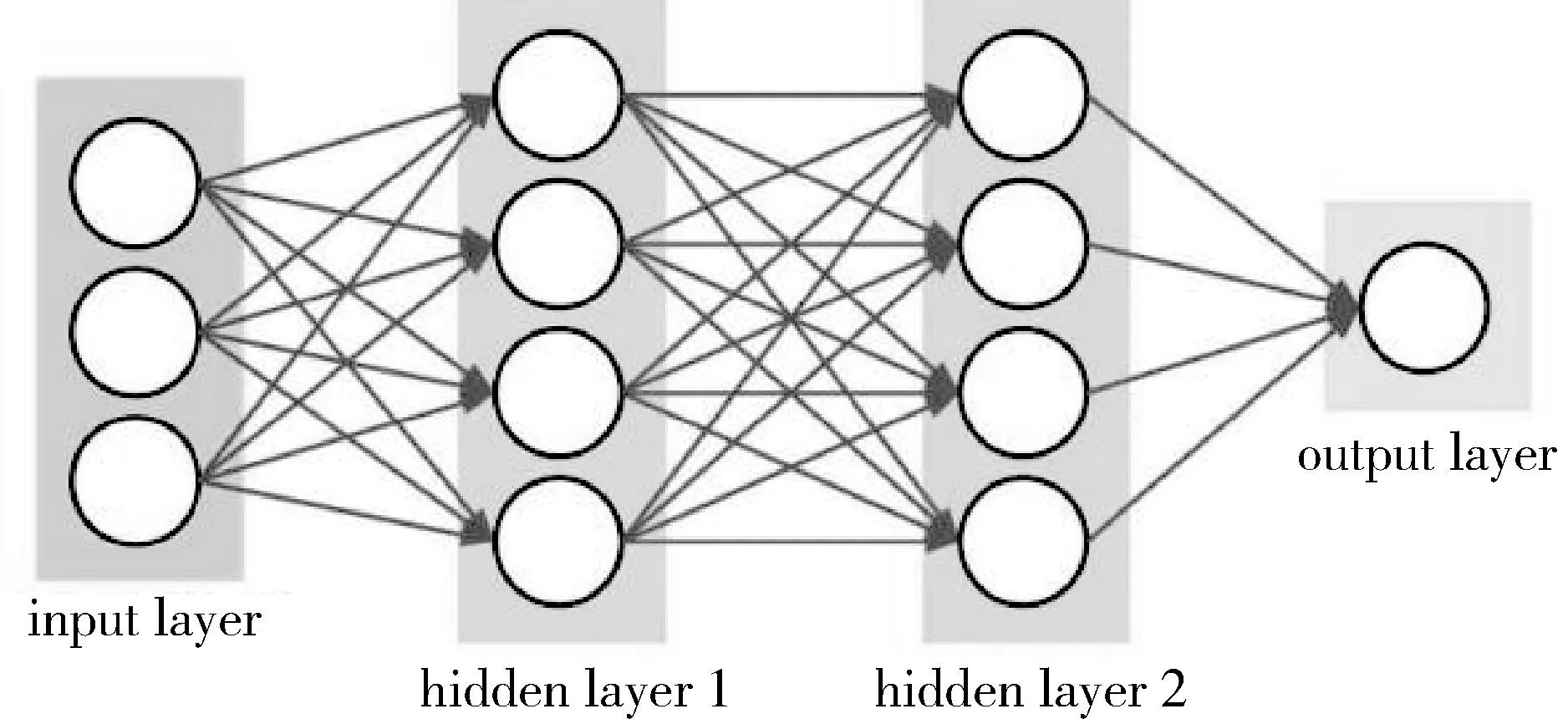
圖2 卷積神經網絡的結構
3 實踐與探索
3.1 數據準備
數據來源為甘肅省北山地區(含敦煌地塊),將其不同時期、不同測區的10份航空磁測數據資料,3 893 381個測量數據。其中1∶20萬地球化學水系沉積物測量圖幅29幅,成圖樣品間距2 km×2 km,樣品數24 825件,樣本測試元素39種。區內現已發現Au礦床(點)109個(中型5個,小型23個,礦點61個,礦化點20個)。
經對全區不同時期的物探、化探原始數據做分區、分幅平差處理后,消除原始數據因系統誤差對定量處理結果產生的影響,不同比例尺航磁測量數據接圖部位的平差后;然后選取以化探數據坐標點為中心,以1 km為直徑范圍內平差后航磁數據的最大值和最小值作為新的航磁參數。將全區按5 km間距繪制正方形網格,計算各網格范圍內所有樣本39個化學元素的均值,選擇航磁數據的最大值和最小值(共41個變量),整理之后便構建起全區24 821個樣本。其中,2 500個為已知有礦單元,22 321個尚未發現Au礦的單元。
3.2 模型構建
處理后的數據集24 821條記錄對應一個特定的統計單元,數據取值為0、1。對于某一找礦證據或含礦屬性來說,1代表單元內有礦床(點)存在或有找礦證據存在;0代表無礦或無找礦證據存在,其中屬性為1的為2 500個,屬性為0的為22 321。
本文中決策樹的構造使用的是基于基尼系數的CART分類樹。①對于當前節點的數據集為D,如果樣本個數小于閾值或者沒有特征,則返回決策子樹,當前節點停止遞歸。②計算樣本集D的基尼系數,如果基尼系數小于閾值,則返回決策樹子樹,當前節點停止遞歸。③計算當前節點現有的各個特征的各個特征值對數據集D的基尼系數。④在計算出來的各個特征的各個特征值對數據集D的基尼系數中,選擇基尼系數最小的特征A和對應的特征值a。根據這個最優特征和最優特征值,把數據集劃分成兩部分D1和D2,同時建立當前節點的左右節點,做節點的數據集D為D1,右節點的數據集D為D2。⑤對左右的子節點遞歸的調用1-4步,生成決策樹。
本文中支持向量機參數選擇,懲罰因子C=1.0,本次研究的數據中,懲罰因子的變化對于預測結果的影響不大;核函數參數選擇徑向基核函數,表達式:K(x,z)=exp(γ‖x-z‖2)K(x,z)=exp(γ‖x-z‖2),其中,γ大于0;分類決策參數decision_function_shape選擇OvO,OvO(one-vs-one)是指每次在所有的T類樣本里面選擇兩類樣本出來,不妨記為T1類和T2類,把所有的輸出為T1和T2的樣本放在一起,把T1作為正例,T2作為負例,進行二元分類,得到模型參數。我們一共需要T(T-1)/2次分類。
ROC曲線能很容易地查出任意界限值時的對性能的識別能力。ROC曲線越靠近左上角,試驗的準確性就越高。最靠近左上角的ROC曲線的點是錯誤最少的最好閾值,其假陽性和假陰性的總數最少(圖3)。
本文中建立的卷積神經網絡模型,設置32個濾波器,長度為3,寬度為3的卷積窗口,通過大量的實踐測試得來的,這個大小的卷積核最好用。卷積層數設置為4層,因為數據大小的原因,最終選擇用4層卷積來實現。
3.3 分析對比
從三種模型對比中,可以看出在有礦點數據的預測中,決策樹模型更精確,達到了89%,SVM模型的精確度略低,為83%,CNN模型的精確度相對偏低,只有55%;在無礦點預測判斷中,SVM模型的精度最好,達到了100%,CNN模型的精度略低為97%;召回率衡量了分類器對正例的識別能力,SVM模型在有礦點預測中召回率最高,決策樹模型的在無礦點預測中召回率更高,因此,在本次測試的數據中,CNN模型的精度和召回率偏低,決策樹模型和SVM模型準確度和召回率更高,更合適這批數據的處理(表2)。
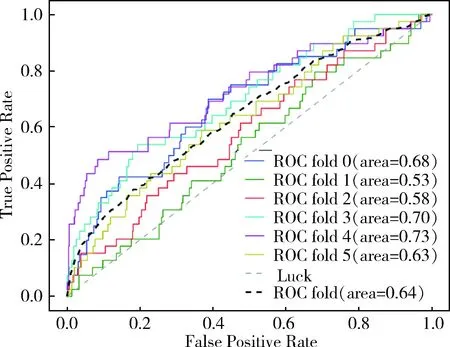
圖3 SVM模型的ROC曲線
表2 三個模型預測結果
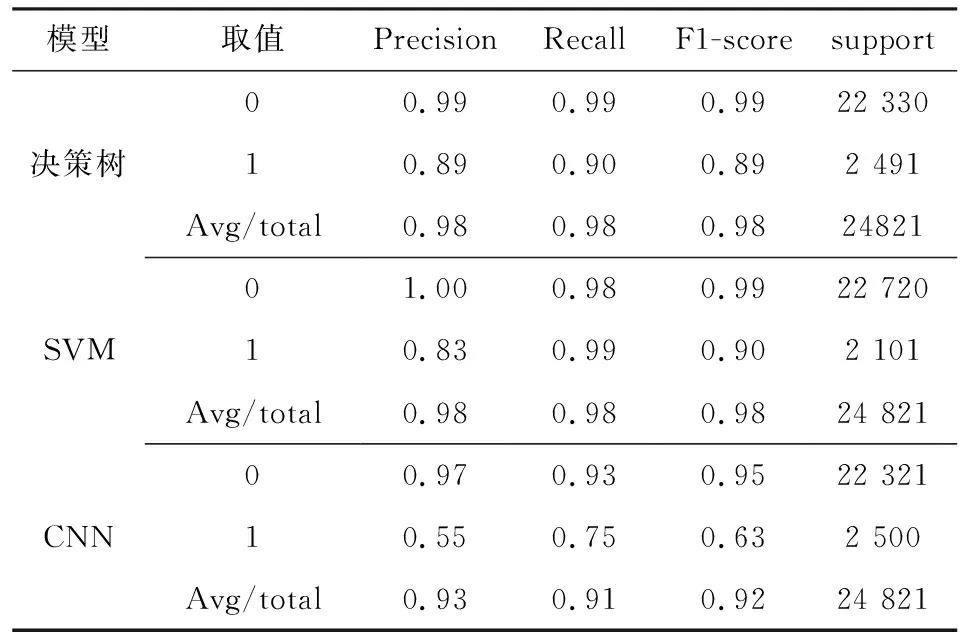
模型取值PrecisionRecallF1-scoresupport00.990.990.9922 330決策樹10.890.900.892 491Avg/total0.980.980.982482101.000.980.9922 720SVM10.830.990.902 101Avg/total0.980.980.9824 82100.970.930.9522 321CNN10.550.750.632 500Avg/total0.930.910.9224 821
注:精度(precision)=正確預測的個數(TP)/被預測正確的個數(TP+FP);召回率(recall)=正確預測的個數(TP)/預測個數(TP+FN);F1=2×精度×召回率/(精度+召回率);Avg/total:各指標的加權平均值。
4 結 語
本文以甘肅省北山地區(含敦煌地塊)基于區域地球化學信息的物化探綜合信息的Au礦數據為例,通過對全區以1 km網格劃分24 821個格子(研究單元)為樣本數據進行了基于各類機器學習、深度學習方法的重新學習及分析,其預測結果基本上達到了預期結果。但模型中還有很多需要完善的地方,比如決策樹的剪枝,通過剪枝能使決策樹對訓練數據有很好的分類能力,防止過擬合現象;針對當前這組訓練的數據,卷積神經網絡模型的效果并不是很理想,可能是數據量偏少、樣本單一的原因等。在今后的工作中會逐步加以改進,構建更合適的礦產預測模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
