大數據環境下的礦產知識庫構建:以鎢礦為例
2018-09-20 05:24:10常力恒朱月琴汪新慶劉雨江
中國礦業 2018年9期
常力恒,朱月琴,汪新慶,張 旋,劉雨江,吳 碩
(1.中國地質大學(武漢)資源學院,湖北 武漢 430074; 2.自然資源部地質信息技術重點實驗室,北京 100037; 3.中國地質調查局發展研究中心,北京 100037; 4.中國科學院大學,北京 100049;5.北京語言大學出版社,北京 100083)
1 大數據環境下地質知識庫構建面臨的機遇和挑戰
1.1 機遇
目前,隨著地質資料信息化工作的推進,形成了大量結構化、非結構化數據。地質數據中非常重要的一部分是以文獻、報告等自然語言進行表示的。地質文獻作為研究成果的高度總結,包含地質過程發生的時間、空間、特征要素以及與周圍環境的相互作用、成因耦合等信息。因此,如何從這種泛結構化的、模糊的、定性的海量地質文獻報告中快速的提取數據,并以獲得的大樣本數據,綜合、分析、挖掘地質資料中的潛在價值,更好的服務于地質科學問題的研究是目前面臨的任務和機遇。物聯網、云計算、虛擬化等信息技術的發展以及多節點分布式的大數據平臺建設,為海量數據的高性能計算提供了條件。機器學習、深度學習、人工智能等技術的革新為地質大數據的研究提供了方法。
2017年11月“地質云”平臺發布,2018年2月《巖石學報》出版了“地質大數據”專輯,2018年4月在廣州中山大學舉辦了“全國大數據與數學地球科學”學術研討會,2018年5月在杭州浙江大學舉辦了“大數據時代——地質學的挑戰與機遇”學術研討會。應用大數據的思維方法,開展數據的相關性分析,構建地質知識庫,實現問題的智能分析求解,已成為發展趨勢。
1.2 挑戰
盡管目前知識庫構建技術已逐漸成熟,但在實際應用中依然面臨巨大的困難和挑戰。在地質領域中,數據類型眾多,數據描述無統一規范,因此在分詞的過程中會出現信息丟失。如何準確的對地質術語進行自動識別、劃分,是構建知識庫,進行知識計算面臨的重要問題。由于地質數據具有時間跨度大、空間覆蓋范圍廣、數據關聯性強、不確定性等特點[1-2],導致對于地質實體關系高度復雜,地質現象、地質過程的形成機理及規律性無統一的認識。因此,在知識的匯聚融合中會出現知識沖突,并隨時間變化會不斷形成新的認識,甚至否定原有認識。如何綜合不同數據源的資料,構建統一知識庫也是目前面臨的問題。
1.3 地質知識庫構建的意義及應用
區域成礦預測是分析研究區的地層、大地構造、蝕變、巖漿巖等成礦地質條件以及物化探異常信息,進行綜合評價圈定找礦靶區[3]。目前,成礦預測主要分為以數據驅動和以知識(模型)驅動為主的兩類方法。數據驅動是從數據中發現規律并進行預測,知識(模型)驅動是研究成礦規律,總結找礦標志特征及找礦模型。地質數據平臺的建設及數據匯聚體系形成,提供了地質條件分析的數據源。因此,如何充分利用數據,發現數據中存在的本質關聯特征,從數據中提取控制成礦的關鍵信息,構建地質知識庫,建設地質大腦,對于認識礦床的形成原因,圈定預測靶區具有重要意義。
我國鎢礦資源豐富,類型多樣,分布相對集中。總結不同類型鎢礦的地質條件特征,構建鎢礦知識庫,對于研究鎢礦成礦規律以及深部礦產預測具有一定的指導作用。
目前,知識庫的應用主要有智能語義搜索[4]和問答系統[5-6]。而研究人員關注的更多為應用知識庫如何解決目前面臨的問題,如成礦譜系形成的特征分析及關鍵控制因素,板塊運動下物質循環與致礦異常的形成機理分析。因此,綜合知識庫可以開展地質實體(礦床、控礦要素、巖體)空間關聯性分析,理清物質相互作用過程。對于地質信息工作者可以從知識計算、智能分析推理進行研究。
2 大數據環境下知識庫構建
知識庫是針對某一領域問題求解的需要,將具有相互聯系的知識集合經過組織、分類,并按一定的表示方式在計算機中存儲,這些知識包括與領域相關的理論知識、事實數據及專家經驗知識[7-10]。建立鎢礦知識庫的目標是探索以數據驅動的思想自動分析不同鎢礦類型形成的主要控制因素,定量分析地質實體的相關性。
2.1 知識庫構建現狀
目前,大量的學者對知識庫構建進行了研究。朱木易潔等[11]介紹了知識圖譜的構建方法及構建過程;劉嶠等[6]、漆桂林等[12]分析了知識庫構建的主要技術;劉嶠等[6]對知識庫構建目前存在的問題進行了分析。另外在不同學科領域,構建了大量的知識庫。何凱濤等[13]論述了數字礦床模型的概念,采用樹狀結構,建立不同類型銅礦床的礦床地質知識模型,采用產生式規則表示法,構建了規則知識庫;邢寶榮[14]分析了儲層構型要素及幾何特征,采用層次分析法,構建了辮狀河儲層地質知識庫;鐘秀琴等[10]基于OWL本體與Prolog規則構建了平面幾何知識庫;閆洪森等[15]基于本體的思想構建了茶葉領域的知識庫。Li等[16]構建了判別魚類病癥的規則知識庫。另外,國內外互聯網公司也推出了自己的知識庫產品,如百度的知心、谷歌的Knowledge Graph、維基百科的Wikidata、微軟的Probase。
2.2 要素模型
建立鎢礦知識庫,需要對知識類型進行分類,確定知識存儲的數據模型。礦床數據模型可以分為礦床模型和找礦模型。礦床模型研究的是礦床形成原因及機理,預測要素模型反映了礦床所處的地質環境及物化遙等特性。根據《Mineral Deposits Models》一書中對礦床地質環境的描述,模型包括巖石類型、結構構造、成礦時代、沉積環境、構造、伴生礦床、礦化蝕變、礦物特征等[17]。礦床學的書籍中也對礦床研究的主要內容進行了說明和論述,內容包括大地構造環境,物質組成、物質來源及成礦過程,成礦控制因素,地層、構造、巖漿巖、圍巖蝕變與礦床關系,成因機理,礦體形態特征及時空分布規律等[18]。關于找礦模型,成秋明在文獻[19]中說明了找礦標志組合包括成礦有利構造環境、有利圍巖條件、有利構造條件、巖漿條件、礦體結構與構造、礦石礦物、圍巖蝕變、微量元素組合、磁異常、重力異常等。綜合礦床模型及找礦模型建立了鎢礦知識庫存儲的數據模型,包括大地構造環境、圍巖條件(巖石類型,結構構造)、構造條件、巖漿條件(巖石組成、來源)、礦體條件(組成、結構構造)、礦石礦物、成礦時代、蝕變、元素異常組合等(表1)。

表1 知識庫要素模型
2.3 鎢礦知識庫構建
根據全國礦產資源潛力評價鎢礦數據、對鎢礦文獻信息提取的結果,以及要素模型對數據進行整理,建立鎢礦知識庫。根據《重要礦產預測類型劃分方案》[20],將鎢礦預測類型劃分為石英脈型、矽卡巖型、斑巖型、云英巖型、陸相火山巖型、沉積變質型、層控矽卡巖型和砂礦型等8種。在對數據的整理過程中,預測類型還包括類似A-B形式的復合類型。目前共形成105條記錄。由于每條記錄所包含描述信息較多,下面僅以一例說明知識庫存儲結構及數據(表2)。

表2 鎢礦知識庫中數據(示例)
3 鎢礦知識庫實踐及應用
知識庫的建立是為了使計算機能夠分析礦床形成條件,從而預測在不同的地質條件下礦體賦存的概率。本文以數據的分類為例說明知識庫應用的一個方面。分類是根據事物的組成、性質、功用等不同表現方面,依據屬性特征的差異性對事物進行劃分,將某方面特征相似的事物進行歸并。對于礦床則表現在構造環境、物質來源、形成過程等多個方面。正確的劃分礦床類型對于認識、指導生產實踐具有重要意義。
實驗數據為1例從數據庫中抽取并去除預測類型的鎢礦記錄。由于數據量占篇幅原因選擇記錄中的成礦巖體、賦礦地層巖性、礦物組合、蝕變4個特征屬性作為數據分類的計算變量。
分類計算的核心是通過字符串的模糊匹配,分別計算測試數據的每一特征要素與數據庫中匹配特征要素的相似度,累加求和所有特征要素相似度,選擇每一種預測類型相似度最高的值,最后將所有預測類型對應相似度值進行綜合排序,相似度最高對應的預測類型則為實驗數據的分類結果。本實驗基于python的fuzz.ratio字符串模糊匹配算法,對數據進行分類。其中,匹配程度最高為石英脈型,相似度為46.5%,其次相似度分別為矽卡巖型43.25%,斑巖型38.25%。具體計算結果如圖1所示。
實驗數據對應類型為矽卡巖型,與計算結果存在一定偏差。根據文獻[21]可知廣西資源縣牛塘界鎢礦礦石類型以矽卡巖型為主,次為石英脈型和花崗巖型,礦石品位以石英脈型較高。因此實驗數據兼具矽卡巖型與石英脈型特征,與計算結果基本吻合。表3為相似度對比結果表。從表中可以看出篩選的結果數據與測試數據特征要素匹配程度非常相近。
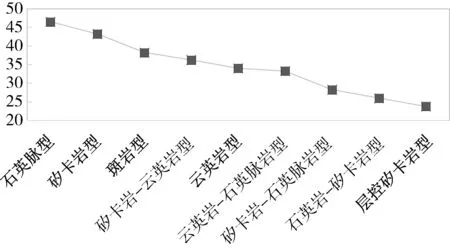
圖1 分類計算結果圖
表3 相似度對比結果表

數據成礦巖體賦礦地層巖性礦物組合蝕變匹配度廣西資源縣牛塘界鎢礦(測試數據)(矽卡巖型)黑云母花崗、細-中粒黑云母花崗巖或中-細粒白云母花崗泥質粉砂巖和粉砂質泥巖主要金屬礦物有白鎢礦、黃鐵礦、方鉛礦;次要有閃鋅礦、黃銅礦;脈石礦物主要有石英、石榴子石、透輝石、符山石、綠泥石、方解石。次有陽起石、透閃石、斜黝簾石、螢石、鈉長石硅化、黃鐵礦化、碳酸鹽化、綠泥石化、堿性長石化,角巖化、矽卡巖化廣東省南雄棉土窩鎢礦(石英脈型)中細粒白云母花崗巖變質砂巖、板巖和石英斑巖礦物組合:金屬礦物有黑鎢礦、白鎢礦、黃鐵礦、黃銅礦、方鉛礦、閃鋅礦、錫石、輝鉍礦、輝鉬礦、毒砂等;脈石礦物主要有石英(約占90%~95%),其次為長石、綠泥石、電氣石、白云母,少量方解石和石膏等硅化、電氣石化、黃鐵礦化、綠泥石化、絹云母化46.5%特征要素匹配度依次:46%、43%、46%、51%江西省修水香爐山鎢礦(矽卡巖型)黑云母二長花崗巖含炭硅泥質灰巖和灰質泥巖、中厚層狀條帶狀灰巖金屬礦物有白鎢礦、磁黃鐵礦、黃鐵礦、白鐵礦、黃銅礦、閃鋅礦、方鉛礦等;主要脈石礦物有透輝石、石英、方解石、長石,其次有(絹)白云母、石榴石、透閃石、螢石等云英巖化、硅化、綠泥石化、螢石化和高嶺土化43.25%特征要素匹配度依次:35%,42%、52%、44%
4 分析討論
針對實驗結果,查閱了相應礦床地質特征描述的文獻資料。根據文獻[21]對測試數據廣西資源縣牛塘界鎢礦的賦礦地層巖性描述為灰黑色變質泥質粉砂巖、粉砂質絹灰黑色變質泥質粉砂巖、粉砂質絹云板巖夾大理巖或矽卡巖化大理巖。而知識庫中該礦床對巖性描述缺少大理巖或矽卡巖化大理巖等關鍵詞,直接導致計算結果存在偏差。造成這一問題的主要原因在于數據來源的準確性,另一個原因在于字符串匹配算法對于所有詞進行同等匹配,即不能識別關鍵詞,未對敏感詞賦予較高權重,進而增加結果的準確性。本文僅對第一種原因進行了實驗,利用修改后的數據重新計算匹配度,結果見圖2。對比圖1,圖2中包含矽卡巖的預測類型的數據匹配程度更高,結果更為準確。
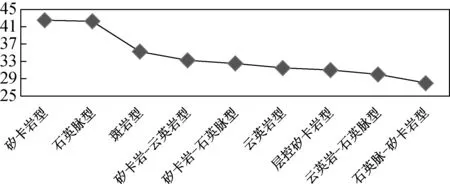
圖2 修正測試數據后計算結果圖
5 結 語
從多源海量的數據中挖掘知識,分析數據之間的相關性,構建地質知識庫對于計算機自動推理、智能分析、輔助決策具有重要意義。因此本文以礦床模型、成礦預測理論為指導,構建了要素模型,結合潛力評價數據和文獻資料構建了鎢礦知識庫。在應用實踐方面,以數據分類為例,進行了文本的相似度計算,實驗結果表明數據源的質量對結果劃分具有重要影響。在數據準確,描述完整的情況下,匹配算法可以很好的識別礦產預測類型。對于另一個問題,計算機自動識別和區分不同要素變量、不同詞匯的重要性程度,如何融合地質專家認識對不同信息賦予不同權重進行礦產分類,是下一步工作的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大地構造與成礦學(2021年5期)2021-10-27 11:15:36
大地構造與成礦學(2021年4期)2021-08-24 05:34:48
礦產勘查(2021年3期)2021-07-20 08:01:52
大地構造與成礦學(2021年3期)2021-06-29 11:16:24
大地構造與成礦學(2021年2期)2021-05-07 13:57:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
