基于正常行為的案例推理在偽裝船只識別中的應用?
2018-09-27 01:23:42鄔鵬飛
艦船電子工程 2018年9期
鄔鵬飛 姚 路 曾 斌
(海軍工程大學管理工程與裝備經濟系 武漢 430034)
1 引言
重點海域管控是維護我國海洋領土安全與海洋權的益重要環節。實現對海域的有效管控,船只身份的識別是其中一項重要的基礎性工作。獲取船只身份的最快速方法,無疑是通過接受船舶自動識別系統(AIS)數據來判斷,但由于AIS身份數據由目標船只本身主動廣播,比較便于造假,因此在軍事領域,通過AIS獲取船只身份的方法并不可靠。同時,隨著海上斗爭形勢的日益復雜,敵對勢力使用偽裝為民船對我領海進行滲透偵察的方式變得越來越普遍,使得對船只身份的識別變得更加復雜。因此必須加強對偽裝船只的識別研究,轉變現有的依靠指揮員經驗進行識別的傳統做法,實現對偽裝船只的快速準確識別,確保我海洋領土安全與海上權益不受侵害。
目前的針對船只識別的手段有很多,主要有紅外成像、合成孔徑雷達(SAR)成像和衛星遙感成像等方法,這些船只識別手段都有著不同的優點和局限性[1~4]。上述方法,本質都是從成像的角度出發,利用船只的外形特征來實現對船只身份的確定,而忽略了船只的行為因素。因此本文在上述研究的基礎上,將船只行為引入船只身份的識別中,從對比正常船只與偽裝船只在行為角度的差異出發,實現對船只目標身份的確定。船只行為特征是在一定自然條件下由于裝備等條件限制而形成的固有特征,船只只要有不正常的動作,必然產生不正常的行為,相比船只外形等特征,更加難以偽裝。隨著在計算機技術的發展,對于行為研究也變得越來越深入。劉智[5]等利用卷積神經網絡建立了一個人體行為識別模型;何傳陽[6]等采用Vibe算法對群體行為進行檢測,取得了較好效果;范菁[7]等利用聚類分析和HMM-RF模型對車輛行為檢測進行了研究。在上述研究的基礎上,通過采集船只行為案例,形成案例庫,抽象概括正常行為。比對目標船只行為與正常船只行為的相似度,若相似度小于閾值,則判定該船只行為是異常行為,以此對偽裝船只進行識別。
2 基于行為的船只身份識別基本原理
案例推理(Case-based Reasoning CBR),作為一種智能推理方法,它通過重用以往經驗解決來新問題,已受到大量學者關注[8]。在其應用當中,案例推理常常與規則推理結合,但在實際應用中發現,推理規則往往難以獲取,并且由于規則之間的相互依賴,導致對知識庫的日常維護較困難。針對以上問題,本文采用單一的案例推理模式,并針對案例數據維數高且并不是同等重要且不相關屬性容易影響推理結果這一現實情況,將鄰域粗糙集引入案例推理中,利用其對船只行為特征屬性進行約簡,抽取出決定目標屬性的關鍵屬性,在提高推理效率的同時,提高推理的準確性;考慮到案例庫的規模較大,為進一步提高推理效率,對案例庫進行聚類處理,將案例庫分為若干子案例庫,當有新問題的時候首先比較其與個子案例庫的聚類中心(特征案例)的相似度,優先搜索相似度較大的特征案例對應的子案例庫,避免遍歷整個案例庫,以提高搜索效率。由于到異常行為樣本的獲取比較困難,因此本文采用反向推理的模式,通過對比與正常船只行為的差異來判斷船只的可疑程度,認為與正常船只行為相似度較小的為偽裝船只。本文采用案例推理結合鄰域粗糙集來實現對偽裝船只的檢測,具體流程如圖1所示。

圖1 基于鄰域粗糙集與案例推理船只身份識別流程
3 基于案例推理與鄰域粗糙集的船只身份識別
3.1 船只行為描述
由于到船只行為是船只在一個時間段內產生的動作的集合,綜合考慮船只在一段時間內的動作、船只本身特性和當時的自然條件,形成對于船只行為的描述,主要包括幾個方面:
自然要素:風向,風力,浪高,浪向,流速,能見度;
船只基本要素:船只大小,最大觀測航速;
航行動作要素:指各種機動動作的機動參數,包括航向改變次數、航速改變次數;
交互動作要素:指各種通信的通信參數,包括目標與其他實體通信次數、通信實體數和通信時間;
狀態動作要素:包括與我方目標距離小于3海里時間和、與我方目標最小距離。
3.2 船只行為表示方法
案例表示是對船只行為案例的描述,將案例轉化為計算機可存儲和識別的數據結構。案例表示為兩個部分。
第一個部分是對案例(船只行為)的描述,主要包括自然條件,船只基本屬性,船只機動動作,艦船交互動作,船只狀態動作。
第二個部分是對目標船只身份的描述,即:客船、貨船、漁船、可疑船只。
根據以上的規則,我們可以用二元組的表達方式對案例進行描述,即 Case=(F,I),其中 F=(f1,f2,…,fn)為案例的各類屬性;I為船只的身份。
3.3 基于鄰域粗糙集的船只行為屬性約簡
基于粗糙集理論的屬性約簡,可以在保持決策表決策屬性和條件屬性之間的依賴關系不發生變化的前提下對決策表進行約簡[9]。然而,經典的粗糙集只適合處理離散化變量,對于現實應用中廣泛存在的數值型連續變量卻不能直接處理。因此,在使用經典粗糙集進行屬性約簡之前,往往首先采用一定的方法對連續數據進行離散化處理,將連續變量轉化為離散變量。在這一過程中將不可避免地帶來一定的信息損失,約簡的結果很大程度上依賴于數據離散的效果。針對這一問題,本文采用文獻[10]提供的方法,利用鄰域粗糙集對行為案例進行屬性約簡,以避免對數據進行離散化處理,從而最大程度保留原始數據的信息。

表1 船只行為屬性表
定義1:在給定實數空間n上的非空有限集合,對于?xi的鄰域δ-定義為
δ(xi)={x|x∈U,Δ(x,xi)≤δ}δ≥0其中Δ是一個距離函數。
定義2:U為論域,N是U上的鄰域關系,是鄰域粒度的集合。則稱(U,N)是一個近似鄰域空間。
定義3:實數空間Ω上的非空有限集合U={x1,x2,...,xn} 及其上的鄰域關系 N,即二元組 NS=(U,N),?X?U 則X在鄰域近似空間NS=(U,N)中的上近似和下近似分別為
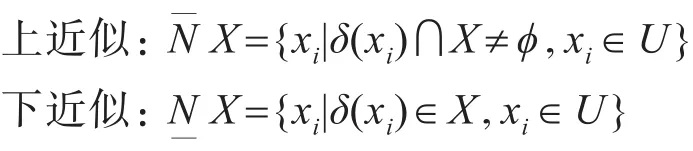
定義4:給定鄰域決策系統中,另B和D為U中的屬性集合決策集,B的正域記為PosB(D),負域記為 NegB(D),則:

定義5:決策屬性D對條件屬性B的依賴度定義為

定義6:對于鄰域決策系統 S=<U,C,D,V>,B?C,a∈B,屬性a的重要度為
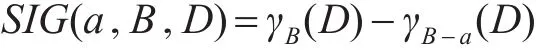
該方法從空集出發,每次循環都將重要度最大的屬性添加到約簡集中,然后計算剩余屬性的屬性重要度,繼續選擇重要度值最大的屬性添加到約簡集合中,直到所有剩余屬性的重要度基本不發生變化。具體流程如下:
步驟1 確定鄰域半徑r和重要度下限閾值;步驟2 令約簡集為空集;
步驟3 計算約簡集之外的剩余屬性的上近似集、下近似集、正域、依賴度和重要度;
步驟4 選擇重要度最大的屬性加入到約簡集中;
步驟5 返回步驟3,直到所有剩余條件屬性的重要度都低于閾值,算法停止,輸出約簡。
用上述方法對案例庫中的案例進行處理后,提取案例的關鍵屬性如表2所示。

表2 約簡后的船只行為關鍵屬性
3.4 船只行為案例相似度確定
3.4.1 案例屬性相似度計算
案例X與案例Y的相似度定義如下:


顯然,對于案例的推理過程中,相似度的計算至關重要。根據上述對案例屬性體系的約簡結果可知,案例的屬性值全為數值型,考慮到各個指標之間量綱的差異,將所有的數值型數據統一為一個指標矩陣,采用如下方法來計算數值型屬性間相似度:

通常與正常船只行為相似度較高的船只,我們認為它的可疑度較低,因此可疑船只的可疑度,可被定義為

max(sim(X,Yj))為目標船只行為案例與案例庫中所有相似度的最大值。
3.4.2 案例屬性權重分配
采用上述方法對各個類型的屬性計算出相似度后,還需有各個屬性的權重,才可以利用式(1)計算出兩個案例的相似度。對于各個屬性的權重的分配,可以采用專家打分或者層次分析(AHP)等方法,但這兩種方法高度依賴專家的主觀判斷,有時候并不能完全客觀地反映屬性的重要程度。這里介紹一種結合遺傳算法與自省學習的權重分配方法。該方法主要分為兩個階段,第一階段使用遺傳算法對權重進行初始分配,第二階段采用內省學習對權重進行調整。
其基本思想是:在初次訓練的過程中,利用遺傳算法,將屬性權重編碼為染色體,以推理正確率為適應函數,優選到符合優化目標的案例屬性初始權重。針對遺傳算法易陷入局部最優的缺點,利用內省學,進行二次訓練,在該訓練過程中,對于推理正確的案例,增大高相似度屬性的權重,減小低相似度屬性的權重,對于推理失敗的案例,則正好相反。內省學習,主要分為以下幾個步驟:
1)高相似度與低相似度的定義
定 義 :案 例 X=(x1,x2,…,xn), Y=(y1,y2,…,yn),如果滿足則稱第i個屬性為高相似屬性;若滿足,則稱第i屬性為低相似屬性。
2)權重調整
對于權重的增加或減少有兩種基本方法,第一種在所要調整的權重的原有基礎上增加或減少某個固定值,第二種在所要調整的權重的原有基礎上乘以或除以一個大于1的固定值。對于第一種方法,在權重的調整過程中,有可能會出現負權重的現象,因此本文采用第二種方法。
對于權重增加:

其中,ωi(t)為第i個特征屬性第t次迭代的權重;ωi(t +1)是第i個特征屬性第t+1次迭代的權重;本文k值取1.2。當權重調整完畢后,為保證,需要對其進行歸一化處理,具體方法如

對于權重減少:下:

3.5 案例檢索
3.5.1 案例聚類
為提高在大案例情況下的案例檢索效率,本文采用聚類方法對案例庫進行處理。聚類算法中,k均值聚類算法應用最為普遍,但其聚類效果與初始聚類中心的選擇關系密切,初始聚類中心選擇的好壞,很大程度上決定了聚類結果有效與否[11]。考慮到以上問題,使用如下方法獲得初始聚類中心,具體流程如下:
第1步,按式(1)計算任意兩個案例的相似度,從而找出相似度最小的兩個(或多個)案例作為頭兩個(或多個)聚類中心。
第2步,計算出與已有聚類中心相似度最小的案例,并把它作為下一個聚類中心。
第3步,重復第2步,直到找到k(聚類總數)個聚類中心。
這樣我們就找到了k個彼此間相似度最小的案例作為初始聚類中心。
案例歸類過程中采用相似度最大原則,即將案例歸類到與之相似度最大的案例類中,如果有多個最大相似類則將其歸類到案例數目最少的案例類中,若此時案例數目最少的案例類也有多個則隨機將其分配到其中一個案例類中。使同一類案例相似度高且各類案例的數量盡量相近,確保能快速找出新問題的相似案例與之匹配。
綜上,案例聚類算法的步驟如下:
第1步,從案例庫的m個案例中,按上述方法選取k個案例作為初始聚類中心。
第2步,按式(1)計算案例庫中所有案例與各聚類中心的相似度。
第3步,根據最大相似度對案例庫中每個案例進行歸類。
第4步,重新計算聚類中心,即將每類所有案例的平均值作為新的聚類中心。
第5步,重復第2步到第4步直到不再有案例被重新歸類。
第6步,結束聚類過程,輸出聚類結果,并將各案例類的聚類中心構成特征案例集(作為子案例庫的索引)。
3.5.2 搜索流程
在案例檢索匹配過程中,最近鄰方法(KNN)是一種應用較多的方法。常規情況下,最近鄰方法將計算所有案例與新問題之間的相似度,找出與該問題最相近的一個或幾個案例,在這種情況下,必須檢索整個案例庫,當案例庫案例數量較多時,其檢索效率并不高[12]。
針對船只行為案例庫較大的現實狀況,為實現對船只目標的快速識別,必須提高案例檢索的速度。因此本文采用層次檢索的策略,在成對案例庫的聚類的基礎上,當有新案例時,首先將新案例與每個子案例庫的特征案例進行比較,篩選若干個相似度最大的特征案例(一級檢索),然后再將新案例與特征案例所代表的子案例庫中的所有案例進行比較,如果存在相似度大于閾值的案例,則認為新案例為正常,否則即判定其為偽裝船只,并遍歷整個案例庫,得到其可疑度。檢索流程圖如圖3所示。
1)一級檢索
第1步,獲得當前探測到的船只行為數據所描述的新問題X=(x1,x2,…,xn)。
第2步,按式(1)計算X與所有特征案例間的相似度。
第3步,找出與新問題案例相似度最大的特征案例所對應的所有子案例庫(可能有一個,也可能有多個)。
2)二級檢索
檢索一級搜索篩選出的所有子案例庫。如果這些案例庫中存在與問題X相似度大于閾值b的案例,則將該案例作為X的匹配案例(即X為正常船只),否則X為偽裝船只,同時遍歷整個案例庫,利用式(4)計算出船只的可疑程度。
4 實例驗證
為驗證方法的有效性,使用我國沿海某海域2017年3月16日至11月6日的AIS數據為樣本。利用船舶自動識別系統(AIS)可以獲得船只的船位、船速、改變航向率、航向、船名、呼號、船長、危險貨物等數據[13],對這些數據進行簡單處理后,結合當日氣象就可以得到文中所需要的正常船只行為信息。通過對采集到的原始AIS數據進行預處理,得到了53246個正常船只行為案例。考慮到偽裝船只行為案例較少(僅通過其他途徑采集到5個),計算偽裝船只案例屬性值的均值和方差,再以5個原始偽裝船只行為案例為基礎,隨機選取其一個或多個屬性,加上或減去具有對應均值和方差的正態隨機值,仿真出49個偽裝船只案例,這樣就獲得了54個偽裝船只行為案例。
其中部分船只行為案例如表3所示,其中船只類別項中,1表示可疑船只,0表示正常船只。
4.1 驗證結果
使用53000個正常船只行為案例構建初始案例庫,使用246個正常船只案例和54個偽裝船只作為測試案例集,采用逐漸增加測試案例個數的策略,將本文方法與傳統案例推理方法(不進行屬性約簡,采用KNN檢索策略)進行對比,驗證本文提出方法的檢索時間效率,所得結果如圖4所示。
由圖4可以看出,當案例較少時,兩種方法耗時均很小,隨著案例庫的增加傳統案例推理方法的檢索時間會近似的線性增長,而本文所提出方法的增長速率要明顯小于傳統案例推理方法,兩種方法的搜索時間差異逐漸增大,相比于傳統案例推理,本文的方法效率更高,當測試集的數量為300時,節省時間69%。

圖4 推理時間圖
為驗證方法的有效性,將另測試案例的數量為300,通過取不同閾值,得到對應的虛警率和漏檢率,如圖5、圖6所示。

圖5 漏檢率隨閾值變化圖

圖6 虛警率隨閾值變化圖
可見,隨著閾值的增加,本文的方法比傳統方法漏檢率增長緩慢,隨著閾值的減小,虛警率增加相對也比較小,當閾值取0.86時,本文方法的推理正確達到最高,為91.2%,比傳統方法高8.7%。
4.2 結果分析
4.2.1 算法的檢索效率分析
對于船只身份推理問題,傳統的案例推理方法,案例庫中所有案例(假設有n個)都要參與案例檢索過程。那么1個新案例所檢索的次數為n次。而本文提出案例推理方法(假設分為m類,m<<n),在進行一級檢索時,新案例只與特征案例比較,一級檢索的次數為m次,在進行二級檢索時,只需要案例庫中一部分(通常為案例庫的若干分之一,假設有p個),那么二次過程的搜索次數為p,總搜索次數為m+p≈p<<n。特別案例數量很大時,m+p≈p與n差距更大,本文方法與傳統方法的檢索時間差異將更大。
4.2.2 算法的精確度分析
由于鄰域粗糙集的使用,原始案例中的非關鍵要素被去除,排除了不相關要素對推理結果的影響,有利于提高推理準確度;同時,由于在對案例庫進行聚類處理的過程中,與特征案例具有較高的相似度的案例都被歸到同一子案例庫中,從而保證與X有較高相似度的案例幾乎都包含由一級檢索得到的子案例庫中,使得在整個檢索過程中,與X有匹配度較高的案例不會被遺漏。
5 結語
根據偽裝艦船識別問題的實際,從艦船行為角度出發,利用鄰域粗糙集、案例聚類等方法,提出了基于案例推理的識別方法。使用計算機仿真,得到不同相似度閾值情況下的預警率與漏檢率,并將本文提出的方法與傳統案例推理方法進行對比,實驗結果表明,提出的方法在在不同閾值的情況下漏檢率與虛警率均優于傳統方法,同時能夠避免傳統案例推理方法隨著案例數量增多,檢索時間增長較快的缺點。盡管本方法在案例檢索階段具有較高的檢索效率,但在前期的訓練過程中,尤其是權重獲取與案例聚類階段耗費時間較多,如何提高前期訓練與案例處理效率還需要進一步研究。
猜你喜歡
少先隊活動(2021年2期)2021-03-29 05:40:48
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國公路(2017年7期)2017-07-24 13:56:38
Coco薇(2016年2期)2016-03-22 02:42:52
中學生數理化(高中版.高二數學)(2016年4期)2016-03-01 03:46:18
中國衛生(2015年4期)2015-11-08 11:16:06
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
