融合詞語共現距離和類別信息的短文本特征提取方法*
2018-10-08 07:25:08馬慧芳邢玉瑩張旭鵬
計算機工程與科學 2018年9期
馬慧芳,邢玉瑩,王 雙,張旭鵬
(1.西北師范大學計算機科學與工程學院,甘肅 蘭州 730070;2.桂林電子科技大學廣西可信軟件重點實驗室,廣西 桂林 541004)
1 引言
隨著微博、社交網站等應用的發展,越來越多的信息以短文本的形式存在且呈爆炸式增長。快速有效地從海量短文本數據中獲取所需要的關鍵信息,短文本挖掘技術發揮著非常重要的作用。短文本特征極度稀疏且難以提取。通常來說,特征獲取主要有兩大類方法:一類稱為特征選擇[1],指的是從原有的特征中提取出少量的、具有代表性的特征,但特征的類型不發生變化;另一類稱為特征抽取[2],是指從原有的特征中重構出新的特征,新的特征具有更強的代表性。
傳統的詞條加權方法主要分為兩種:無監督的詞頻TF(Term Frequency)、詞頻-逆文件頻率TF*IDF(Term Frequency*Inverse Document Frequency)[3,4]和有監督的tf*χ2(term frequency*chi-square)、tf*ig(term frequency*information gain)[5]等。采用無監督的方法能夠給詞條加權,卻忽略了短文本的類別信息。有監督的詞條加權方法[6,7]將其考慮進來,并在一定程度上提高了短文本特征提取的表現力。
與長文本相比,短文本具有特征高度稀疏的特點。從詞項共現角度來看,兩個詞項的關聯性可從詞項共現的角度體現,且短文本所包含的詞語稀少,兩詞項之間相隔詞項的距離對語義信息的計算也造成了一定的影響;從類別信息的角度來看,特征詞在類間的分布以及在類內部文檔中的分布情況可以考慮進來進行綜合加權。一方面,若特征詞在各個類間分布比較均勻,這樣的詞對分類基本沒有貢獻,若特征詞比較集中地分布在某個類中,而在其它類中幾乎不出現,這樣的詞就能夠很好地代表這個類的特征。如何將這種詞語的類別信息挖掘出來是至關重要的。
基于以上考慮,本文提出了一種新的短文本特征提取方法,即融合詞語之間的共現距離和類別信息的短文本特征提取方法CDCISE(Combining term co-occurrence Distance and Category Information for Short text feature Extraction)。首先,計算詞項之間共現距離相關度,同時結合詞項在整個文本的共現區分度,并以此為依據對詞項進行加權;其次,改進期望交叉熵計算方法,充分考慮短文本的類別信息,使得在對短文本進行特征提取時更加合理;再次,將共現區分度和類別信息結合計算詞條權重,避免了傳統的基于詞頻的文本特征提取方法表現力較差的問題;最后,使用該方法分別在中文、英文的數據集上進行實驗,實驗結果表明,該方法有效地提高了短文本特征提取的效果。
2 相關理論
2.1 特定文本中詞項的相關度
給定短文本集合D={d1,d2,…,dm}和詞項集T={t1,t2,…,tn},詞項ti與詞項tj在特定短文本ds中的相關度的計算公式如下:
(1)
其中,distds(ti,tj)為詞項ti與詞項tj在短文本ds中的共現距離[8],由這兩個詞項之間相隔的詞項數計算得出,即|j-i|-1。例如,短文本d1“社交網絡環境下的隱私保護策略”在經過停用詞過濾、文本分詞的預處理過程后變為“社交 網絡 環境 隱私 保護 策略”,詞項“社交”與詞項“隱私”之間的共現距離distd1(社交,隱私)=2。傳統的距離計算方法在計算兩個詞項之間的距離時忽略了兩詞項與其相隔詞項之間的語義聯系,采用共現距離的計算方法,將詞項的上下文語境考慮進來,使得計算結果更為可靠。利用詞項之間的共現距離來計算兩個詞項之間的相關度與傳統的計算相關度的方法[9]相比也顯得更為合理。由于計算公式(1)時需要遍歷語料庫中所有詞項,因此計算的時間復雜度為O(n2)。
2.2 期望交叉熵
期望交叉熵ECE(Expected Cross Entropy)是一種基于信息論的特征選擇方法,它反映了文本類別的概率分布以及在包含某個特征詞時文本類別概率之間的距離,考慮了詞頻以及詞項和類別之間的關系。ECE值越大,表明該特征詞越能表示一個類的特征,即該特征詞對類別分布的影響越大。詞項ti的ECE值計算公式如下:
(2)
其中,P(ti,ds)表示詞項ti在短文本ds中出現的概率;P(Cr)表示Cr類短文本在短文本集D中出現的概率;P(Cr|ti)表示短文本ds包含詞項ti時屬于類別Cr的概率。
3 融合詞語共現距離和類別信息的短文本特征提取方法
3.1 基于詞語共現距離的詞條加權方法
短文本特征提取是短文本挖掘技術的關鍵步驟,可以幫助人們快速有效地從海量數據中獲取關鍵信息。
特征提取實質上是一個文本降維[10]的過程,其目的是通過剔除決策意義不大的詞項進而提高短文本分類的準確性和效率。傳統的詞條加權方法未充分考慮詞語之間的語義信息和類別分布信息,本文提出的融合詞語共現距離和類別信息的短文本特征提取方法的總體流程如圖1所示,具體由如下幾個步驟構成:
步驟1對k類測試短文本集合D′進行預處理得到k類短文本集合D和詞集T;
步驟2利用詞語之間的共現距離計算每個詞項的關聯權重;
步驟3利用期望交叉熵對某個類中的每個詞項計算其ECE″值;
步驟4結合步驟2和步驟3的計算結果得到某個類別中所有詞項的權重值,分別將不同類別中的詞項按權重值進行降序排序,取前K個作為特征詞,構造出新的特征詞項集合。

Figure 1 Flow diagram for short text feature extraction combining term co-occurrence distance and category information圖1 融合詞語共現距離和類別信息的短文本特征提取方法流程圖
傳統的詞條加權方法在計算詞項共現情況時沒有考慮到詞項之間的距離,本文提出的利用詞項共現距離的方法來計算某個詞項的關聯權重可以有效地解決這一問題。本階段用到的符號定義如表1所示。
由公式(1)可計算:
(3)

Table 1 Notation definition表1 符號定義表

(4)
則詞項ti在特定短文本ds中的關聯權重計算公式如下:
(5)
(6)
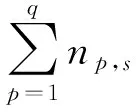
(7)
其中,cowr(ti)反映了詞項ti在第Cr類短文本集中關聯權重的整體情況。
3.2 構造特征詞典
如何從短文本中選取最能代表類別特征的詞項作為特征詞項是構造特征詞典的關鍵。所選的特征詞應該滿足以下兩個條件:一是能夠較好地概括短文本的內容信息;二是有較好的局部指示性,即該詞項能較好地揭示短文本所在類別的信息。第一個條件采用關聯性加權策略即可滿足,第二個條件可以采用ECE"值[11]來權衡所選的特征詞的局部指示性。
在公式(2)中,詞項ti在所有的類別中具有綜合的權重值。然而,在大多數情況下,一個能代表A類信息的詞項,很有可能對類別B分布的影響不大。因此,應該將該詞項在不同類別中的權重值考慮在內。詞項ti在類別Cr中的權重值計算公式如下:
(8)
由公式(8)可知,當P(Cr|ti)的值越大,即詞項ti和類別Cr相關性越強時,P(Cr|ti)/P(Cr)越大,則詞項ti對類別Cr的作用就越大。當詞項ti與某一類別強相關,且與其他類別的相關性較弱時,被選中的可能性也就越大。詞項ti在除類別Cr外的其它類中的權重值計算公式[12]如下:
(9)
其中,ECE′(ti,Cj)表示詞項ti在剩下k-1個類別中的平均權重。
(10)
其中,ECE″(ti,Cr)反映了詞項ti在類別Cr中的整體權重值。該值越大,說明詞項ti對類別Cr的指示性越強。利用公式(10)對類別Cr中的所有詞項計算其ECE″值。在類別Cr中詞項ti的最終權重計算公式如下:
Wti=cowr(ti)×ECE″(ti,Cr)×idf(ti)
(11)
(12)
其中,cowr(ti)揭示了對于第Cr類短文本集而言詞項ti的重要程度;ECE″(ti,Cr)反映了詞項ti對短文本所屬類別的指示性;idf(ti)為詞項ti的逆向文檔頻率,表現了詞項ti對短文本的區分程度,可以由第Cr類的短文本總數|Dr|除以其中包含詞項ti的短文本數,再將得到的商值取對數計算可得。如果包含詞項ti的短文本數越少,則idf(ti)的值越大,說明詞項ti對類別區分的能力也越強。
對類別Cr中的詞項按Wti值進行降序排列,取前K個詞項作為特征詞項。對短文本集中的每個類別進行相同的處理,并把得到的每一類別的特征詞項進行合并構造出新的特征詞典。
隨著特征詞典大小的增長,本文方法的計算時間會呈現出指數的增長趨勢。這是由于在詞項集中,每計算一個詞項與其余詞項之間的相關度與共現度需要遍歷一次文本庫,故在特征詞典長度為n時,該算法的時間復雜度為O(n2)。
4 實驗與結果分析
4.1 實驗數據集及預處理
為了驗證本文提出方法的有效性,分別收集中國計算機學會CCF(China Computer Federation)會議推薦列表中的A類會議與B類會議中的15類共750篇文章標題作為英文數據集,中國科學引文數據庫CSCD(Chinese Science Citation Database)中的5類共12 534篇文章標題作為中文數據集進行實驗。本文采用5折交叉驗證的方法,將所有類別中的數據樣本隨機劃分成五個大小相等的子樣本,交叉驗證過程重復五次。每次一個樣本被保留作為測試集的驗證數據,其余四個樣本作為訓練數據。訓練集主要用來訓練使用本文方法學習所得的模型,測試集主要用來驗證本文方法是否能對短文本進行準確分類。
對短文本集進行預處理,包括數據去噪、文本分詞、停用詞過濾等處理。其中對中文分詞的處理采用了jieba中文分詞工具。得到新的短文本特征詞項集后,將實驗中的短文本以向量形式進行表示并采用支持向量機SVM(Support Vector Machine)與k-NN(k-Nearest Neighbor)分類器進行分類。其中,SVM采用Libsvm包,將k-NN中的近鄰數設置為61進行比較。
4.2 評價指標
本文涉及的評價指標包括準確率Accuracy和F1-measure[13],其定義如下:
(13)
其中,TP、TN、FP、FN分別為真正(事實上是正樣本,被判定為正樣本)、真負(事實上是正樣本,被判定為負樣本)、假正(事實上是負樣本,被判定為正樣本)、假負(事實上是負樣本,被判定為負樣本)。P是精確率,R是召回率,其計算公式如下:
(14)
(15)
4.3 實驗結果與相關分析
為了驗證本文方法的有效性,共設計了三個實驗。實驗1使用SVM和k-NN分類器來驗證使用本文方法獲取到的特征詞典的大小對短文本分類準確性的影響;實驗2將本文方法與其他方法得到的特征詞典進行對比;實驗3將不同方法得到的特征詞典應用到SVM分類器中,驗證使用不同策略的特征提取方法對短文本分類的影響。本文將只考慮類別信息不考慮詞語之間的共現距離的特征提取方法CISE(combining Category Information for Short text feature Extraction)、考慮共現距離但不考慮類別信息的特征提取方法CDSE(Combining term co-occurrence Distance for Short text feature Extraction)、考慮詞語之間的共現情況但不考慮類別信息的特征提取方法TCSE(combining Term co-occurrence Condition for Short text feature Extraction)以及TF*IDF方法與本文方法得到的特征詞項集進行比較,驗證使用本文方法所構造的特征詞典對短文本進行分類的高效性。
選擇以上四種特征提取方法作為對比方法是基于以下幾點考慮:(1)本文的方法是在傳統的特征提取方法基礎上通過融合詞項之間的共現情況以及短文本的類別信息改進而來的,CDSE方法和CISE方法與本文的方法最為相似;(2)選用CISE方法將短文本的類別信息考慮進來而不考慮詞項之間的共現情況可以顯示出類別信息對構建特征詞典的重要性;(3)TF*IDF方法則是將共現距離與類別信息均忽略的傳統特征提取方法。
4.3.1 特征詞典大小對短文本分類的影響
為了驗證使用本文方法獲取到的特征詞典的長度對短文本分類造成的影響,分別取特征詞項集中的前30、40、50、60、70、80、90、100、110、130、160、180、200、230、250、280和300個特征詞項構造特征詞典,在SVM和k-NN分類器上進行分類測試。其中,SVM分類器使用了Libsvm-3.2.1版本的插件,通過調整相應參數并最終選用非啟發式線性核函數作為訓練支持向量機模型的主要函數。在使用k-NN分類器進行模型訓練時,通過調整K近鄰數發現當特征詞典長度一定時,以20為基數,步長為2的速度增長所得到的準確率和F1-measure值在近鄰數為61時能較好地反映出所訓練模型的高效性。
如圖2所示,在SVM和k-NN兩種分類器上,使用本文方法得到的特征詞典均可以有效地對短文本進行分類且使用SVM分類器的分類效果明顯優于k-NN分類器的。

Figure 2 Effect of feature dictionary size on short text classification圖2 特征詞典大小對短文本分類的影響
在使用SVM訓練出的分類模型進行短文本分類時,隨著特征詞項數目從30增加到300,準確率和F1-measure值均呈現出先增長后下降的波動走勢直至趨于穩定,且當Top值在60時達到峰值,分類效果最佳。在使用k-NN訓練出的分類模型進行短文本分類時,準確率和F1-measure值呈現出先增長后下降的波動趨勢且特征詞典長度為80時分類效果最佳。
4.3.2 特征詞典比較
為了驗證使用本文方法得到的特征詞典對短文本分類的高效性,對比了上述5種特征提取方法所得到的特征詞典。以處理后的人工智能與模式識別這一類別3 598個詞項中的前30個詞項為例,如表2所示,使用CDSE方法得到的特征詞項與TCSE方法得到的特征詞項相比,前者較能表示該類的特征,說明使用詞語之間的共現距離來衡量兩個詞項之間的共現情況更為有效。
顯然,與本文方法相比,使用CISE與CDSE方法得到的特征詞典均有欠缺,證明了詞語之間的共現距離與類別信息這兩個因素都不可忽視,而將兩個因素均未考慮在內的TF*IDF方法得到的特征詞項效果最差。該實驗說明了與其它4種方法相比,使用本文方法提取出來的特征詞項能更好地表示特征且使用這種方法得到的結果也更為合理。
4.3.3 不同特征提取方法對短文本分類的影響
為了驗證使用不同策略的特征提取方法對短文本分類造成的影響,選取不同長度的特征詞典在Libsvm中訓練分類模型,實驗1的結果顯示使用SVM分類器在特征詞典長度為60時分類準確度最高,效果最好且使用該分類器的波動程度與k-NN分類器比較而言較為穩定。所以,選取SVM分類器并在中英文數據集上進行實驗,觀察特征詞項數目為60時各個方法得到的特征詞典對短文本分類準確性的影響,其準確率和F1-measure值如表3所示。
使用本文方法在中英文數據集上進行短文本分類時得到的準確率和F1-measure值均大于其它4種方法,說明本文方法更能有效地對短文本進行分類且本文提出的特征提取方法適用于不同種類的語言。
此外,詞語之間的共現情況較類別信息而言對短文本分類造成的影響更大,且使用共現距離來衡量詞項之間的共現程度明顯優于傳統共現情況計算方法。然而,采用傳統的特征提取方法對短文本進行分類時,其準確率和F1-measure值最低,分類效果最差。

Table 2 Comparison of different feature dictionaries表2 不同特征詞典的比較

Table 3 Classification performance of the feature extraction methods表3 不同特征提取方法的分類性能
5 結束語
針對傳統的詞條加權方法沒有充分考慮到詞語之間的語義信息和類別分布信息,本文提出了一種新的短文本特征提取方法,即融合詞語共現距離和類別信息的短文本特征提取方法。該方法利用詞語之間的共現距離計算相關度,避免了傳統方法無法判斷一個特征是否有區分度以及區分度是否足夠的缺點,并將詞條的類別信息充分考慮在內,使得對文本提取的特征更加合理。在中文、英文數據集上的實驗說明,該方法能顯著提高短文本特征提取的效果。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
