深度神經網絡的語音深度特征提取方法
2018-10-11 00:38:56李濤曹輝郭樂樂
聲學技術 2018年4期
李濤,曹輝,郭樂樂
?
深度神經網絡的語音深度特征提取方法
李濤,曹輝,郭樂樂
(陜西師范大學物理學與信息技術學院,陜西西安 710100)
為了提升連續語音識別系統性能,將深度自編碼器神經網絡應用于語音信號特征提取。通過堆疊稀疏自編碼器組成深度自編碼器(Deep Auto-Encoding, DAE),經過預訓練和微調兩個步驟提取語音信號的本質特征,使用與上下文相關的三音素模型,以音素錯誤率大小為系統性能的評判標準。仿真結果表明相對于傳統梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficient, MFCC)特征以及優化后的MFCC特征,基于深度自編碼器提取的深度特征更具優越性。
語音識別;深度自編碼器;梅爾頻率倒譜系數;
0 引言
語音識別是人類與機器進行語音交流,機器理解、識別人類的語音信號后將其轉換成對應的文本或者命令的過程[1]。語音識別過程主要包括3個部分:語音特征的提取、建立聲學模型與解碼[2-3]。語音信號的特征提取在整個語音識別系統中至關重要,對這些特征進行降維、去噪,準確地提取出表示該語音本質的特征參數將使得后面的分類識別更有效,識別率更高。目前表示語音信息主要用的是短時頻譜特征,比如梅爾頻率倒譜系數(Mel-Frequency Cepstral Coefficient,MFCC)、差分倒譜特征(Shifted Delta Cepstra, SDC)、感知線性預測特征(Perceptual Linear Predictive, PLP)等。但這些短時頻譜特征在實際的使用中都存在一些不足:以MFCC為例,每幀只包含20~30 ms語音,不但容易受到噪聲干擾,而且還會忽略語音信號的動態特性和語音信號中所含有的類別信息,這些不足都會影響語音識別的準確率[4]。
2006年Hinton等[5]提出基于深度信念網絡(Deep Believe Network, DBN)的非監督貪心逐層訓練算法,將深度學習算法應用于訓練多層神經網絡,它特殊的訓練方式可以給神經網絡提供較優的初始權值與偏置,使得網絡能夠快速地收斂于合理的極值點,有效避免了傳統多層感知器(Multi-Layer Perceptron, MLP)在增加隱含層的同時易陷入局部最優解和需要大量有標記數據的問題。同時DBN的深度結構被證明相對于原有的淺層建模方法能夠更好地對語音、圖像信號進行建模。利用可以有效提升傳統語音識別系統性能的深度神經網絡DBN來進行語音識別[5],學習到了更能表征原始數據本質的特征。隨后Hinton等[6-7]提出了自編碼器(Auto Encoder, AE)的深層結構:深度自編碼器(Deep Auto Encoder, DAE)。自編碼神經網絡是一種網絡誤差函數定義與DBN不同的典型深度神經網絡。當隱含層節點的輸入、輸出呈線性關系,且訓練網絡采用最小均方誤差(Least Mean Square Error, LMSE)準則時,整個編碼過程與主成分分析(Principle Component Analysis, PCA)等效。當隱含層映射呈非線性映射時,即為自動編碼器。本文采用這種自編碼神經網絡結構進行語音信號特征的提取。
1 深度自編碼器的工作原理
深度自編碼器是一種期望網絡得到的輸出為其原始輸入的特殊深度神經網絡。由于令該網絡的輸出趨近與它的原始輸入,所以該網絡中間層的編碼完整地包含了原始數據的全部信息。但是是以一種不同的形式來對原始輸入數據進行分解和重構,逐層學習了原始數據的多種表達。因此整個編碼過程可看作是對信號的分解重構。將該網絡結構用于特征壓縮時,隱含層的神經元個數少于輸入層神經元個數;把特征映射到高維空間時,則隱含層神經元個數多于輸入層神經元個數。
自編碼器是使用了無監督學習與反向傳播算法,并令目標值趨近于輸入值的前向傳播神經網絡。可對高維數據進行降維,進而得到低維的特征向量。設向量為輸入樣本,則隱含層、輸出層神經元的激活情況計算公式為
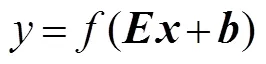
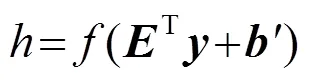
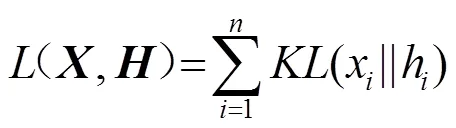
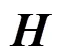
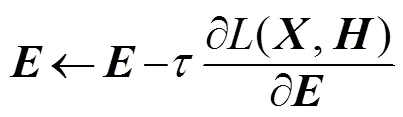
在訓練自動編碼器時,為了確保在處理數據過程中隱層神經元只有少部分被激活,故而限制隱含層的神經元被激活的數量,在損失函數中引入對激活隱層神經元數目的約束項,也就是實現對原始輸入數據的稀疏編碼,經證明稀疏編碼能夠有效降低模型的識別錯誤率[9]。損失函數為
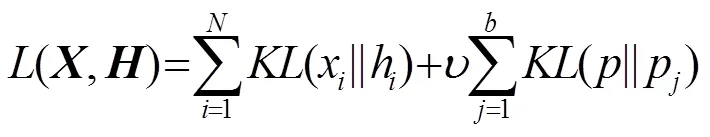
的方法:上層的輸出參數作為下層的原始輸入參數依次訓練整個網絡;微調階段利用反向傳播算法調整所有層的參數。
常見的自編碼器含有一個隱含層,如圖1所示。文獻[10]將深度神經網絡定義為隱含層層數超過一層的神經網絡。在本文中構建一個含有兩層隱含層的深度神經網絡來提取語音信號的深度特征。網絡結構如圖2所示。
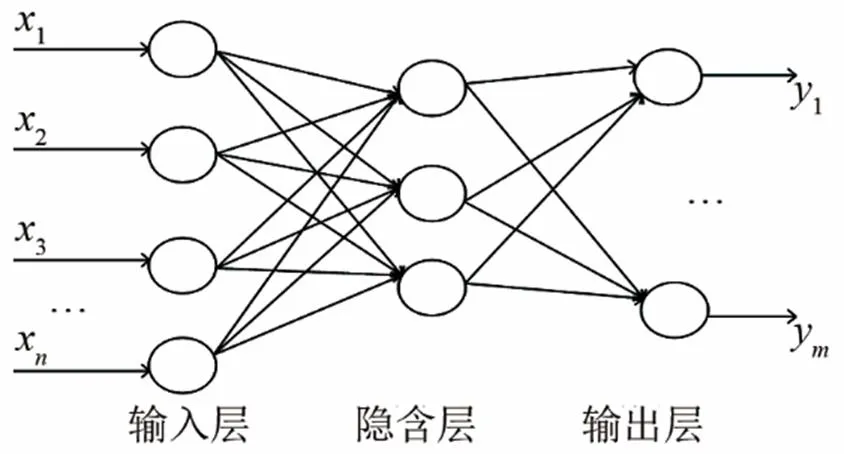
圖1 單隱含層神經網絡
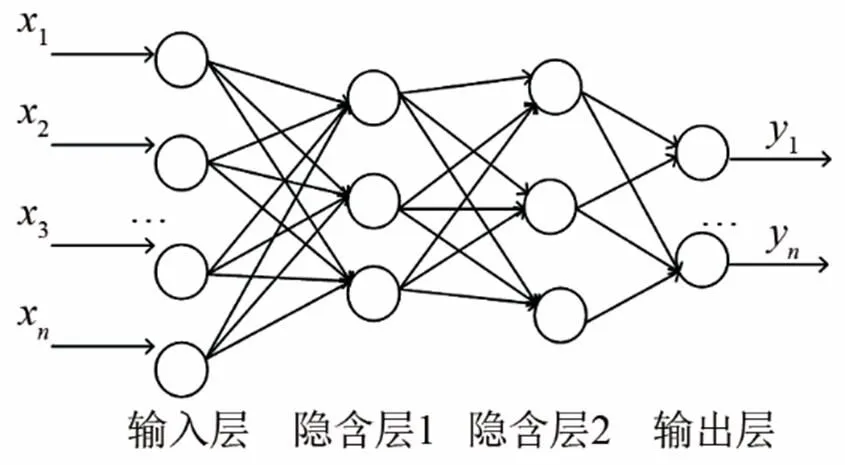
圖2 深度神經網絡
2 基于DAE模型的深度特征提取
因說話人、說話方式不同及噪聲等影響,可能使在實驗環境下表現優異的語音識別系統在實際應用中的識別性能不穩定。因此,使用改善系統的魯棒性和自適應能力的方法來優化聲學特征參數,增強識別系統的抗干擾能力,使其性能更加穩定,能夠應對多種環境。目前常用解決方法是:為增強特征參數的適應能力而對其進行特征變換處理;或為提高特征參數的魯棒性而對語音信號進行增強、濾波、去噪等處理。
新型的審批模式推廣與應用的必要的前提就是至上而下的重視和全面的科學指導與培訓,這是平臺運用成功的關鍵和必要的基礎條件。
提取深度特征之前,先對提取的MFCC特征進行特征變換,再作為深度自編碼器的原始輸入,進而得到識別率更高的語音深度特征,對原始MFCC特征依次進行線性判別分析、最大似然線性變換和最大似然線性回歸變換處理。
考慮到協同發音的影響,將已提取的39維MFCC特征向量(靜態、一階、二階差分)進行前后5幀的拼接,得到39 ×11=429維的特征向量。對這429維特征向量進行線性判別分析(Liner Discriminant Analysis, LDA)抽取分類信息,同時降低維度至40維從而得到LDA特征。然后對這40維LDA特征向量進行最大似然線性變換(Maximum Likelihood Linear Transformation, MLLT)來去除相關性得到LDA+MLLT特征,最后對經過去除相關性的40維LDA+MLLT特征在特征空間上進行最大似然線性回歸(Feature-space Maximum Likelihood Linear Regression, fMLLR)說話人自適應訓練,實現特征參數自適應,減小測試聲學特征與聲學模型參數之間的不匹配,得到了40維的LDA+MLLT+fMLLR特征。仿真結果表明,以上特征變換均能有效降低音素識別的錯誤率。
深度自編碼器能夠更好地對語音信號中與音素相關的信息進行逐層表征,基于深度自編碼器提取的語音深度特征過程,實質上是一種非線性的特征變換和降維過程。利用神經網絡的層次化提取信息過程來作為對原始輸入特征的非線性特征提取與轉換,使得特征維度與神經網絡訓練目標尺度分離。相對網絡首層輸入層而言,隱層的神經元個數要少得多,所以隱層在通過學習到原始輸入樣本的低維表示的同時,還可以最大限度地包含與高維表示相同的信息。并且可以通過更精細的子音素類別來表示音素目標,最終由原始輸入向量經過逐層映射得出對應隱含層的輸出向量。由此就得到能夠最大限度地包含輸入向量信息的一個低維編碼,這使得輸出的深度特征具有比傳統底層聲學語音特征參數相近或更好的特性區分性,還帶有類別信息,加強了特征表示聲學單元的能力,得到更有效的特征表達,進而提高后期語音識別系統的性能。使用DAE提取深度特征的流程圖如圖3所示。
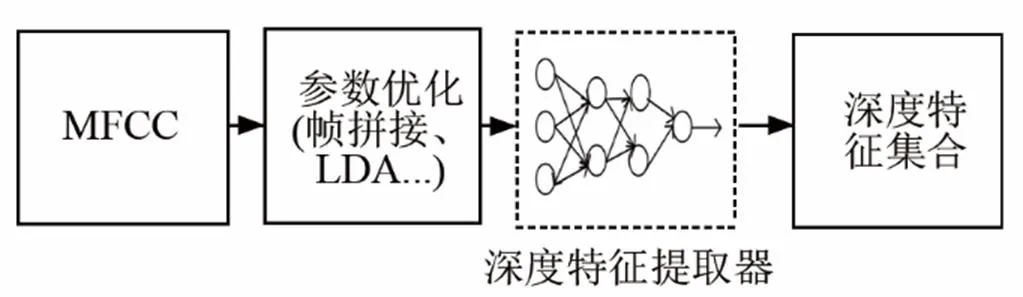
圖3 深度特征提取流程
本文使用的原始輸入特征是進行前后5幀拼接的40維LDA+MLLT+fMLLR特征,形成40×11=440維的輸入特征向量,這11幀拼接的LDA+MLLT+fMLLR特征相對于傳統的單幀特征更具優勢[11]:一個音素持續的時間大約在9幀左右,所以大約9幀的信息量就能夠包含一個完整的音素,同時也含有其他音素的部分信息,它可以提供單幀特征所體現不出的更細致更豐富的音素變化信息。
利用深度自編碼器神經網絡進行深度特征參數提取的步驟如下:
(1) 以11幀拼接LDA+MLLT+fMLLR特征作為輸入,經訓練得出第一層隱含層的網絡參數,并以此計算第一層隱含層輸出;
(3) 繼續把上一層的輸出作為第三層的輸入,再用同樣的方法訓練該層網絡的參數,而后利用反向傳播算法微調所有層的參數。最后將輸出層輸出的深度特征參數作為最終音素識別系統的輸入。
3 仿真結果與分析
3.1 數據庫與仿真環境
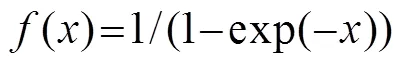
以11幀拼接的LDA+MLLT+fMLLR特征作為原始輸入,經過歸一化之后,所有輸入數據大小都在0~1之間。為保證實驗的準確性和客觀性,音素識別的基線系統選擇常用的混合隱馬爾科夫模型(Hidden Markov Model, HMM)+深度神經網絡模型(Deep Neural Network, DNN)音素識別系統。
3.2 分析
本文設計2個實驗來驗證深度特征的優越性,用音素錯誤率(Phoneme Error Rate, PER)作為評價特征有效性的標準。
3.2.1 最優神經網絡配置
隱層單元數與隱層數的選擇將影響后期識別的音素錯誤率。若神經元過少,學習的容量有限,網絡所獲取的解決問題的信息不足,難以存儲訓練樣本中蘊含的所有規律。若神經元過多就會增加網絡訓練時間,還可能把樣本中非規律性的內容存儲進去,反而會降低泛化能力。通過改變隱層層數與每層神經元個數來確定網絡最佳配置,設置隱層層數從1到3層變化,每個隱層所含神經元個數以50的偶數倍增加,最多為400個。為降低計算量,減少訓練時間,將每層隱含層的神經元設置成相同個數。對比不同網絡結構配置下音素識別率的變化,進而選定最優參數配置。圖4顯示了改變隱含層的層數與神經元個數對最終音素識別錯誤率的影響。
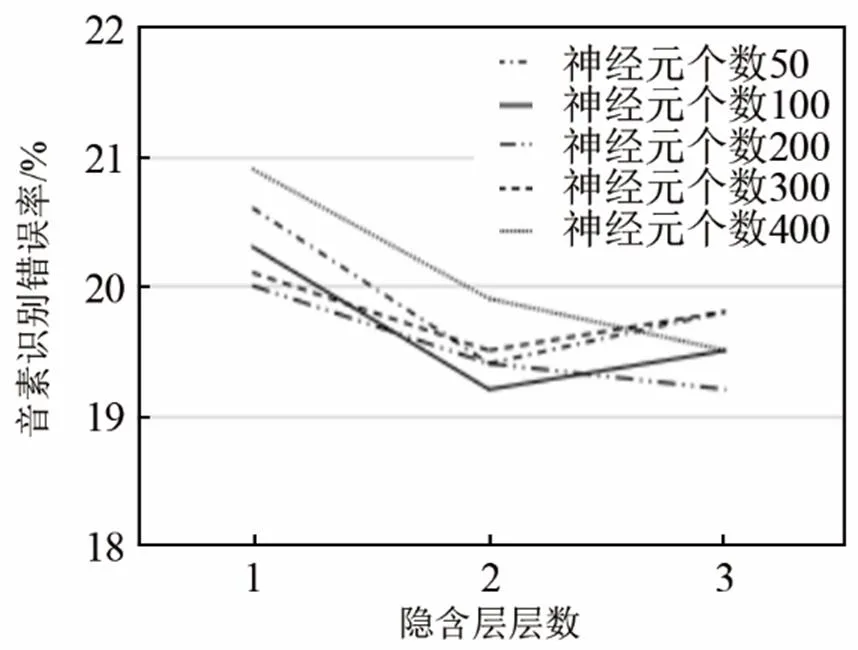
圖4 不同隱層層數與神經元個數對音素識別錯誤率的影響
從圖4可以看出,改變隱層層數和隱層神經元個數對降低音素識別錯誤率有一定影響,當隱含層為兩層且隱含層神經元為100時與隱含層為三層隱含神經元為200時錯誤率最小,并不是隱含層數與神經元個數越多越好。當隱層層數與隱層神經元個數增加至一定數量時,音素錯誤率不會降低反而上升,同時由于計算參數的增加使得訓練時間增長,為減少計算參數及訓練時間,同時確保音素識別正確率,本文選擇建立含有兩個隱含層的深度神經網絡。深度自編碼器的輸入神經元個數即為輸入特征的維數440,每一隱含層神經元個數為100,輸出層神經元個數設置為40,則該深度自編碼器結構可表示為440-[100-100]-40,“[ ]”中數字為隱層神經元的個數。
3.2.2 特征有效性對比
將本文特征解碼的結果與以下四種特征解碼得出的音素錯誤率進行對比,結果如表1所示。作為對比的四種特征分別為:(1) 原始MFCC特征參數;(2) LDA+MLLT特征:MFCC在三音素模型的基礎上進行LDA+MLLT變換;(3) LDA+MLLT +fMLLR特征:在(2)的基礎上進行基于特征空間的最大似然線性回歸(fMLLR)的說話人自適應訓練;(4) bottleneck特征:以11幀拼接的MFCC特征作為原始輸入,建立含有五個隱含層的DBN網絡,輸入輸出層神經元個數為440,第四隱含層為瓶頸層且其神經元個數為40,其余隱含層神經元個數為1 024,提取出bottleneck特征。
由表1可知,與傳統特征以及特征變換后的優化特征作為HMM+DNN系統的輸入相比,將深度特征作為系統原始輸入時,系統的音素錯誤率明顯下降,同時相對于使用DBN網絡提取bottleneck特征,其網絡參數的計算量和訓練時長較少。表1中的結果也證明了本文提取的深度特征的有效性。

表1 傳統特征與深度特征的音素錯誤率對比
4 結語
針對傳統語音特征的不足,本文對原始MFCC特征參數優化之后,建立含有兩個隱層的深度自編碼器,將優化后的MFCC參數作為其輸入,實現原始輸入的特征變換與降維,提取了可以更好地反應語音本質特征的深度特征參數,作為HMM+DNN 系統的輸入。實驗證明了本文特征的有效性。下一步研究將在本研究基礎上與DBN結合,提取更優異的聲學特征,進一步提高語音識別系統的性能。
[1] 韓紀慶, 張磊, 鄭鐵然. 語音信號處理[M]. 北京: 清華大學出版社, 2005.
HAN Jiqing, ZHANG Lei, ZHENG Tieran. Speech Signal Processing[M]. Beijing: Tsinghua University Press, 2005.
[2] 陳雷, 楊俊安, 王一, 等. LVCSR系統中一種基于區分性和自適應瓶頸深度置信網絡的特征提取方法[J]. 信號處理, 2015, 31(3): 290 -298.
CHEN Lei, YANG Junan, WANG Yi, et al. A feature extraction method based on discriminative and adaptive bottleneck deep confidence network in LVCSR system[J]. Signal Processing, 2015, 31 (3): 290-298.
[3] SCHWARZ P. Phoneme Recognition Based on Long Temporal Context[EB/ OL]. [2013-07-10]. http://speech. Fit. Vutbr. cz/ software/Phoneme-recognizer-based-long-temporal-context.
[4] GREZL F, FOUSEK P. Optimizing bottleneck feature for LVCSR[C]//IEEE International Confe rence on Acoustics, Speech and Signal Processing, 2008: 4792-4732.
[5] HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
[6] HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[7] 孫志軍, 薛磊, 許陽明, 等. 深度學習研究綜述[J]. 計算機應用研究, 2012, 29(8): 2806-2810.
SUN Zhijun, XUE Lei, XU Yangming, et al. Review of deep learning research[J]. Journal of Computer Applications, 2012, 29 (8): 2806-2810.
[8] 張開旭, 周昌樂. 基于自動編碼器的中文詞匯特征無監督學習[J].中文信息學報, 2013, 27(5): 1-7.
ZHANG Kaixu, ZHOU Changle. Unsupervised learning of Chinese vocabulary features based on automatic encoder[J]. Journal of Chinese Information Processing, 2013, 27(5): 1-7.
[9] COATES A, NG A Y, LEE H. An analysis of single- layer networks inunsupervised feature learnin[C]//Proc of International Conferenceon Artificial Intelligence and Statistics. 2011: 215-223.
[10] HINTON G E, DENG L, YU D, et al. Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups[J]. IEEE Signal Processing Magazine, 2012, 29(6): 82-97.
[11] SIVARAM G, HERMANSKY H. Sparse multilayer per-ceptron for phoneme recognition[J]. IEEE Transac-tions on Audio, Speech, and Language Processing, 2012, 20(1): 23-29.
Speech deep feature extraction method for deep neural network
LI Tao, CAO Hui,GUO Le-le
(School of Physics and Information Technology,Shaanxi Normal University,Xian,710100, Shaanxi, China)
In order to improve the performance of continuous speech recognition system, this paper applies the deep auto-encoder neural network to the speech signal feature extraction process. The deep auto-encoder is formed by stacking sparsely the auto-encoder. The neural networks based on deep learning introduce the greedy layer-wise learning algorithm by pre-training and fine-tuning. The context-dependent three-phoneme model is used in the continuous speech recognition system, and the phoneme error rate is taken as the criterion of system performance. The simulation results show that the deep auto-encoder based deep feature is more advantageous than the traditional MFCC features and optimized MFCC features.
speech recognition; Deep Auto-Encoding (DAE); Mel-Frequency Cepstral Coefficient (MFCC)
H107
A
1000-3630(2018)-04-0367-05
10.16300/j.cnki.1000-3630.2018.04.013
2017-08-04;
2017-10-18
國家自然科學基金資助(1202020368、11074159、11374199)。
李濤(1992-), 男, 新疆伊犁人, 碩士研究生, 研究方向為信號與信息處理。
曹輝,E-mail:caohui@snnu.edu.cn
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
