基于雙向長短時記憶聯結時序分類和加權有限狀態轉換器的端到端中文語音識別系統
2018-10-16 08:23:50RYADChellali
計算機應用 2018年9期
關鍵詞:模型
姚 煜,RYAD Chellali
(南京工業大學 電氣工程與控制科學學院,南京 211816)
0 引言
在過去三十年,自動語音識別系統被各大高校和研究機構廣泛地研究,在性能上基本滿足了日常使用的要求。在此期間,基于混合高斯模型/隱馬爾可夫模型(Gaussian Mixture Model/Hidden Markov Model, GMM/HMM)的聲學模型范式一度成為自動語音識別的主流框架。其中,HMM用來處理語音信號在時序上的變化性,GMM用來完成聲學輸入到隱馬爾可夫狀態之間的映射[1]。然后多層感知器被用來替代GMM完成HMM發射概率的計算,在一定程度上優化了這套識別框架[2]。隨后,Geoffrey Hinton領導的深度學習開始興起,使得深度神經網絡(Deep Neural Network, DNN)被引入到自動語音識別的聲學模型建模當中[1,3-5]。依靠DNN深度抽象和強大表示學習的能力,語音識別系統的識別準確性又一次獲得了大幅提升。
然而在混合DNN/HMM系統的訓練過程中,依然需要利用GMM來對訓練數據進行強制對齊,以獲得語音幀層面的標注信息進一步訓練DNN。這樣顯然不利于針對整句發音進行全局優化,同時也相應地增加了識別系統的復雜度,提高了搭建門檻。另外由于HMM屬于生成模型,其中存在與實際發音不符的條件獨立性假設[6],導致了這套基于HMM的識別框架在理論上就存在重大缺陷,并不十分完美;同時在DNN發展基礎上,循環神經網絡(Recurrent Neural Network, RNN)和長短時記憶(Long Short-Term Memory, LSTM)神經網絡依靠強大的序列輸入建模能力進一步提高了語音識別準確度[7];并且近幾年,有相關研究嘗試在語音識別中應用卷積神經網絡(Convolutional Neural Network, CNN),利用其卷積不變性來克服語言信號本身的多樣性來進行語音識別,并獲得不錯的性能表現[8]。不過這些語音識別系統中仍然保留著HMM結構。這也就意味著在序列標記任務中,依然需要忍受不合理的HMM假設。
對于序列標記任務,Graves等[9]提出了在循環神經網絡訓練中引入了聯結時序分類(Connectionist Temporal Classification, CTC)目標函數,使得RNN可以自動地完成序列輸入自動對齊任務。本文在Graves工作的基礎上,進一步深入研究了深度循環神經網絡(Deep RNN),并針對漢語發音特性,提出了以聲韻母為建模單元的基于雙向長短時記憶(Bidirectional Long Short-Term Memory, BLSTM)神經網絡的聲學模型,并成功地將CTC函數應用于該聲學模型的訓練中。另外結合中文語言學知識,創新運用了基于加權有限狀態轉換器(Weighted Finite-State Transducer, WFST)的中文解碼方法[10],解決了發音詞典和語言模型等語言學知識無法順利融入語音解碼過程中的難點問題。該解碼方法將CTC標簽、發音詞典和語言模型編碼進單獨的WFST網絡中,組成一個完整的搜索圖。根據CTC網絡的輸出,利用束搜索技術在搜索圖中解碼獲得最終整體得分最高的識別文字串。實驗結果表明了本文設計的基于BLSTM-CTC的端到端語音識別系統,在識別性能上不僅大幅超越了傳統的GMM/HMM系統,而且與同樣建模單元的混合DNN/HMM系統相比,音素錯誤率和單詞錯誤率分別降低了4.7%和4.43%,同時在語音識別速度上提高了一倍多。
1 基于雙向長短時記憶網絡的聲學模型
相較于前饋神經網絡(Feedforward Neural Network, FNN),RNN是一種允許隱層神經元存在自反饋通路的神經網絡類型。循環鏈接使得循環神經網絡的隱層單元具備了記憶上一層刺激的能力,最終隨時序作用于網絡輸出層。這一特性也使得循環神經網絡特別適用于處理序列形式的輸入數據[11]。而對于一些序列標記任務,如:手寫識別、語音識別,不但需要過去時刻的上下文信息,同樣也希望獲得未來時刻的上下文信息,來進一步預測當前時刻的狀態。雙向循環神經網絡(Bidirectional Recurrent Neural Network, BRNN)就提供了一種優雅的解決方案[12]。它通過在RNN基礎上增加一套完全獨立的后向傳播隱層,讓前向隱層和后向隱層共同作用于輸出層,這樣更加準確地預測當前輸出狀態。圖1為RNN和BRNN在時間維度上展開的網絡結構對比。
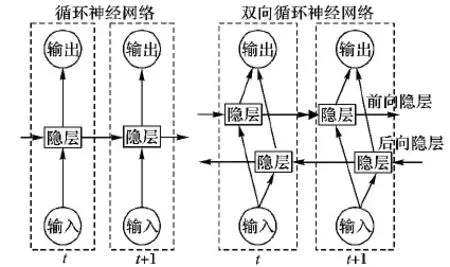
圖1 標準和雙向RNN對比
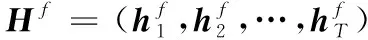
(1)
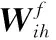
(2)
在每個t時刻,計算當前循環隱層的狀態,并把[hf,hb]作為下一層隱層的輸入。這樣不斷迭代,直到計算出輸出層的最終狀態。
本文采用時序反向傳播(Back-Propagation Through Time, BPTT)算法來學習循環神經網絡中各層間的連接權值。在實際應用中,因為各層梯度會隨反向傳播不斷減小而出現梯度消失現象,這樣很難讓RNN充分學習到上下文的長時依賴[13]。針對此種情況,Sainath等[14]引入 LSTM模塊作為構建RNN隱層的單元。一個LSTM記憶模塊主要包含:一個記憶單元,用來存儲網絡時序狀態;和3個控制門,分別為:輸入門、輸出門和遺忘門,用來控制信息流。具體網絡結構如圖2所示。其中虛線箭頭是將記憶單元和各個控制門聯系到一起進行精確定時輸出的窺視孔連接,實心黑體圓表示乘法單元。在t時刻,LSTM的輸出計算如下:
it=σ(Wixxt+Wihht-1+Wicct-1+bj)
(3)
ft=σ(Wfxxt+Wfhht-1+Wfcct-1+bf)
(4)
ct=ft⊙ct-1+it⊙φ(Wcxxt+Wchht-1+bc)
(5)
ot=σ(Woxxt+Wohht-1+Wocct+bo)
(6)
ht=ot⊙φ(ct)
(7)
其中:i,o,f,c分別代表輸入門、輸出門、遺忘門和記憶單元;W·x為與輸入層連接的權值矩陣,W·h為與上一層隱層連接的權值矩陣,W·c為與記憶單元連接的權值矩陣;σ(·)為sigmoid激活函數,φ(·)為tanh激活函數。以同樣的方式,可以計算得到后向隱層的LSTM的輸出。

圖2 一個LSTM記憶塊
2 端到端系統的訓練及解碼
2.1 基于聯結時序分類目標函數的端到端訓練
在大詞匯量連續語音識別中,聲學模型訓練通常采用嵌入式訓練方式,即利用HMM讓模型自動對齊語音分割與音素標記,進而來訓練聲學特征映射模型,如:GMM、DNN。這樣無疑增加了混合DNN-HMM系統的復雜度,而且HMM的局限性也不利于語音識別技術的進一步發展。本文應用CTC技術對基于BLSTM的聲學模型進行端到端的訓練,徹底解決對于隱馬爾可夫模型的依賴問題。
CTC訓練是在RNN輸出層應用CTC目標函數,自動完成輸入序列與輸出標簽之間的對齊。對于序列標記任務,假設存在一個大小為K的標簽元素表L(如:音素集或字符集)。假設給定輸入序列X=(x1,x2,…,xT),和對應輸出標簽序列z=(z1,z2,…,zU),CTC訓練的目標就是在給定輸入序列下,通過調整RNN內部參數最大化輸出標簽序列的對數概率,即max(lnP(z|X))。其中輸出標簽zu∈L∪{
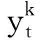
(8)
通過定義映射Φ:L≤T|→L′T,再將標簽序列z映射到CTC路徑p上。這是個1到n的映射,也就是一個輸出標簽可以對應于多個CTC路徑,例如:“AA- -BC-”與“-AAB-CC”都可以被映射到標簽序列“ABC”。因此可以用所有CTC路徑的概率來表示輸出標簽z的概率:
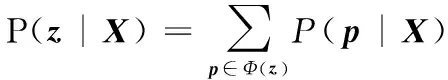
(9)
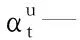
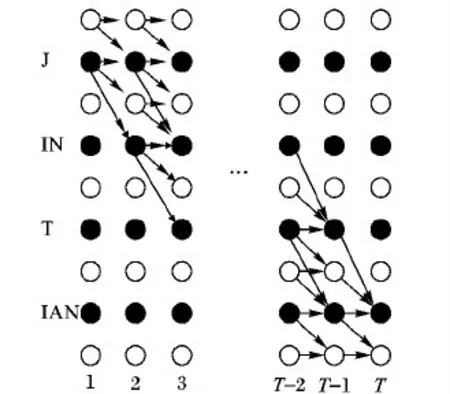
圖3 中文“今天(J IN T IAN)”構成的籬笆圖
然后計算標簽序列z的似然度:
(10)
其中:t可以為1到T中的任意時刻。根據CTC目標函數lnP(z|X),對網絡輸出yt求微分,得:
(11)
其中:γ(l,k)={u|lu=k}表示返回在擴展標簽序列l中標簽為k的下標。由于目標函數可微,可通過BPTT訓練算法進一步計算RNN內部權值的梯度。
2.2 基于加權有限狀態轉換器的中文解碼
語音解碼過程非常依賴于語言學知識,文獻[15-16]都沒能很好地融合語言文法規則。本文根據漢語的發音特點和語言學知識,將聲學模型輸出、發音詞典和語言模型用WFST形式表示,構建一個基于WFST的綜合搜索圖來進行語音解碼,有效地保證了語音語言學知識的完整性,同時大幅提高解碼效率。
WFST解碼網絡由標記(Token)轉換器、詞典(Lexicon)和語法(Grammar)三部分構成,表示形式如圖4所示。其中:
1)語法轉換器G,主要編碼了符合文法規則的單詞序列,可以通過手工或數據學習的方式獲得。圖4(a)表示了由“今天好熱”和“今天下雨”構成的語言模型,其中轉換器輸入、輸出用“:”分隔,弧上權值對應語言模型概率。
2)詞典轉換器L,主要編碼了發音詞典構建單元與單詞之間的映射關系,圖4(b)為“好”字發音的WFST形式,其中標記
3)CTC標記轉換器T,主要編碼了語音幀級的CTC標簽到詞典單元的映射關系;圖4(c)對應了發音單元“H”的CTC轉換器,其中
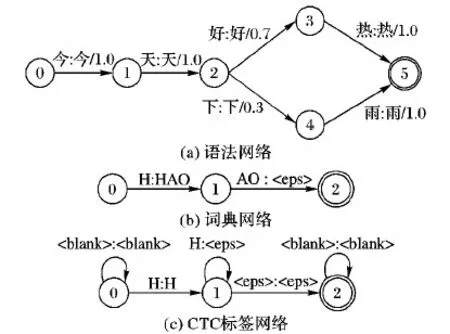
圖4 三種WFST網絡示例
實際應用中,先分別生成各自層面的標記T網絡、字典L網絡和語法G網絡,然后利用組合、最小化和確定化算法將它們組合在一起。首先,通過組合操作將詞典網絡L和語法網絡G合并得到LG網絡;其次對LG網絡作確定化和最小化操作,進行權重推移以優化WFST網絡;最后與CTC標簽網絡合并,生成一個完整搜索圖S:
S=T°min(det(L°G))
(12)
其中°、det和min分別表示組合,確定化和最小化操作[17-18]。搜索圖S可以將本文聲學模型輸出的CTC標簽映射為對應的文字序列,并且得到每種可能文字序列的概率,最終選擇整體得分最高的文字序列作為識別結果。
基于BLSTM-CTC的端到端中文識別系統的具體識別流程如圖5所示。圖5的下半部分為雙向長短時記憶神經網絡的輸入部分,是原始語音信號經過加窗分幀操作和特征提取后的聲學參數序列;中間部分描述的是一個深度長短時記憶神經網絡,分別由輸入層、輸出層和多個的循環隱層構成,能夠根據上下文信息輸出當前語音幀對應的CTC標簽概率;上半部分描述了一個CTC籬笆網絡,最終可以通過網絡輸出概率和完整的WFST轉換器在CTC網絡中搜索得到輸入語音序列對應的字符串識別結果。

圖5 BLSTM-CTC聲學模型流程
3 實驗與分析
3.1 實驗數據
本文實驗在THCHS-30中文數據集上進行。該數據集包含來自50人的35 h錄音數據,采樣頻率為16 kHz,量化位數為16 b。其中25 h(10 000句)錄音數據作為訓練集,大約2 h(893句)作為開發集,剩下的大約6 h(2 495句)作為測試集,同時該數據集還包含一個基于單詞的3-gram文法模型和一個基于音素的3-gram文法模型,及對應的詞典和音素詞典。由于漢語以音節為發聲單元,包含23個聲母和24個韻母,并且每個發音單元包含陰平、陽平、上聲、去聲和輕音5種聲調,于是本文采用包含聲調的共218個聲韻母為基本建模單元,測試各個模型的性能。
3.2 聲學模型對比
1)GMM-HMM。輸入特征參數采用包含一階、二階差分共39維的梅爾頻率倒譜系數(Mel Frequency Cepstral Coefficient, MFCC),分別以單音子、三音子為建模單元進行實驗,其中HMM狀態經過基于決策樹的狀態聚類處理。單音子模型的狀態數為656個,搜索圖大小為718 MB;三音子模型的上下文相關狀態數為1 658個,搜索圖大小為747 MB。
2)DNN-HMM。特征參數為40維的梅爾標度濾波器組特征參數(Mel-scale Filter Bank, FBank),同樣分別以單音子、三音子為建模單元。其中DNN模型包括4個隱層,每層1 024個神經元節點;輸入層經拼幀操作后總共有440(40×11)個節點;在對單音子建模時,DNN輸出層包含656個輸出節點;對三音子建模時,DNN輸出層包含1 658個輸出節點。訓練數據通過GMM-HMM系統進行強制對齊,以獲得了語音幀級別的標注信息。另外,搜索圖與上述GMM-HMM系統相同。
3)BLSTM-CTC。輸入特征參數為包含一階、二階差分共120維梅爾標度濾波器組特征(Mel-scale Filter Bank, FBank),建模單元為單音節,其中BLSTM聲學模型包括4個隱層,每層包含正向和后向傳播兩部分共640個LSTM單元;輸入層包括120個輸入節點;輸出層包括220個輸出節點。將CTC目標函數作為BLSTM網絡的目標函數,和利用BPTT算法來訓練循環神經網絡。搜索圖大小為439 MB。
3.3 結果對比
本文所有實驗都是基于相同的訓練集、開發集、測試集和語言模型,在GTX 1070顯卡和i7 CPU構建的硬件計算平臺上,利用Kaldi語音識別工具包完成了對以上各種聲學模型的測試。圖6展示了各系統性能對比結果,其中本文提出的BLSTM-CTC端到端系統獲得了11.16%的音素錯誤率(Phoneme Error Rate, PER)和24.92%的單詞錯誤率(Word Error Rate, WER)。與基于單音節和基于上下文相關狀態的傳統GMM-HMM識別系統相比,在PER上分別降低了21.04%和9.13%,在WER上分別降低了25.91%和11.02%。另外,與基于單音節的混合DNN-HMM系統相比,端到端系統在PER和WER上分別降低了4.7%和 4.43%;同時識別率上非常接近基于上下文相關狀態的混合DNN-HMM識別系統的10.27%的PER和23.69%的WER。實驗結果表明了基于BLSTM的聲學模型在應用CTC訓練準則后,充分挖掘循環神經網絡對序列數據的建模能力,在模型表示能力上要明顯優于GMM和DNN,同時也使得語音識別系統擺脫了不合理HMM條件假設。

圖6 不同系統音素錯誤率(PER)、單詞錯誤率(WER)和實時率(RTF)對比
另外,本文對語音識別系統的另一個重要性能指標——解碼速度作了對比分析。由3.2節中給出的各模型搜索圖和圖6中實時率的對比,可以發現端到端系統在解碼時間上相比GMM-HMM系統減少了66.7%,并且相比混合DNN-HMM系統減少了57.1%;同時搜索圖(TLG)大小只有GMM-HMM系統的GMM-HMM和DNN-HMM系統的0.61倍。證實了端到端技術在有效降低識別錯誤率的同時優化了系統結構,并獲得了巨大的存儲空間和解碼時間上的節省。
4 結語
本文深入研究深度循環神經網絡,搭建了基于BLSTM-CTC的端到端中文語音識別系統。該端到端系統將CTC訓練準則成功地應用在BLSTM聲學模型訓練中,擺脫了對HMM的依賴;結合漢語語言學知識,設計了基于WFST的解碼方法,解決了聲學模型、發音詞典和語言模型難以融合的問題。在THCHS-30數據集上,實驗表明該端到端技術不僅明顯地降低了識別錯誤率,而且有效地簡化系統復雜度,大幅提高了識別速度。當然語音識別是一個受外部環境和說話人因素影響非常大的多重識別過程,如何減少這些因素的影響,進一步提升模型的區分度和魯棒性,將是下一階段的研究工作重點。另外通過遷移學習,將端到端系統應用于不同領域或不同環境,也是接下來研究的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
