基于機器學習的無參考圖像質量評價綜述
2018-10-16 05:49:48楊璐,王輝,魏敏
計算機工程與應用 2018年19期
楊 璐,王 輝,魏 敏
1.中國科學院 光電技術研究所,成都 610209
2.中國科學院大學,北京 100049
3.成都信息工程大學 計算機學院,成都 610225
1 引言
視覺質量是圖像復雜且固有的特征,其復雜度在和人腦視覺處理機制相關[1],因此對圖像質量準確建模一直是熱點研究問題。通常方法是與理想的成像模型或者完美的參考圖像對比得到失真度量[2]。根據是否存在可參考的圖像,將圖像質量評價方法分為全參考(Full Reference,FR)、半參考(Reduced Reference,RR)和無參考(No Reference,NR)質量評價三類,其中無參考圖像質量評價(NRIQA)也叫盲圖像質量評價(Blind Image Quality Assessment,BIQA)[3-4]。NRIQA方法在實際應用中,需求廣泛但實現難度大于有參考圖像或特征的方法。隨機器學習發展尤其是深度學習對各個領域的影響一致[5],NRIQA技術也在不斷革新。本文通過分析近十幾年典型的NRIQA算法,歸納不同算法特點,研究其現狀及發展趨勢,為后續研究提供參考資料。文章結構如下:第1章介紹常用數據庫和衡量NRIQA算法性能的指標,總結NRIQA算法面臨的主要問題和解決方法概要;第2章介紹典型算法,這些算法在提出時都具有當時最先進的性能,甚至沿用至今,極具代表性;第3章統計在LIVE數據庫[6-8]對比實驗及算法魯棒性測試實驗,即在LIVE[7]數據庫上重新訓練,并在CSIQ數據庫[9]上測試;第4章根據分析實驗結果得出結論,總結盲圖像質量評價現狀及發展趨勢。
2 無參考圖像質量評價方法衡量
圖像質量評價旨在擬合人眼,通常以算法的評價值與與人眼的主觀評分值進行計算比較。在公共數據庫上,圖像的主觀評分值用平均主觀得分(Mean Opinion Score,MOS)表示或者使用平均主觀得分差異(Differential Mean Opinion Score,DMOS)表示。其范圍因不同數據庫而異,常見有[0,1]、[0,5]、[0,9]和[0,100]。MOS值越大表示圖像質量越好,DMOS值越大表示圖像質量越差。近年來提出的NRIQA方法大都基于機器學習方法,每種算法都有自己的提出思想和特點。為了方便與其他方法對比,通常選擇在公共數據庫上訓練并測試,使用公認的技術指標進行算法性能衡量。本章首先介紹常用的圖像質量評價數據庫和公認的算法性能衡量指標。
2.1 常用數據庫和算法性能指標
僅介紹常見的幾個公開數據庫和常用性能指標。
(1)LIVE(Laboratory for Image&Video Engineering)數據庫[7]是最為廣泛應用的共享數據庫,共982幅圖像,包含JPEG2000、JPEG、白噪聲、高斯模糊和快速瑞利衰減5種其他基準庫共有失真類型,圖像質量用范圍為[0,100]的DMOS值表示。
(2)CSIQ(Categorical Subjective Image Quality)數據庫[9]共866幅失真圖像,6種失真,圖像質量由范圍為[0,1]的DMOS值表示。
(3)TID2008(Tampere Image Database)數據庫[10]包括1 700失真幅圖像,17種失真,范圍[0,9]的MOS值表示質量。
(4)TID2013數據庫[11]將TID2008擴充至3 000幅圖像,包含24類失真,同時給出峰值信噪比、結構相似度SSIM 值[2,6]、MSSIM[12]值、像素域的 VIF[13]值等作參考。
NRIQA算法性能衡量指標最廣泛采用的是視頻質量專家組(VQEG)采用的評估標準——線性相關系數和秩相關系數。此外,還有評估方式[14-15]以解決沒有MOS值的大規模圖像數據庫。
(1)線性相關系數(Linear Correlation Coefficient,LCC),也稱皮爾遜線性相關系數(Pearson Linear Correlation Coefficient,PLCC),描述預測值與主觀評分之間的相關性和算法的準確性。
(2)秩相關系數(Spearman’s Rank-Order Correlation Coefficient,SROCC)衡量算法的單調性。
2.2 難點及現有解決方案
基于學習的圖像質量評價難點有二:第一,圖像質量與視覺、心理等復雜因素有關,當前沒有成熟的理論支撐模型;第二,如上述介紹基準庫數據量太小,無法支撐大型深度網絡,擴充數據庫費時、昂貴、緩慢。典型的NRIQA方法幾乎都是從以上兩個問題著手解決。
2005年第一次將自然場景統計(Natural Scene Statistics,NSS)[16]用于圖像質量評價后,大量實驗表明NSS特征與圖像質量存在密切關系。之后采用小波、DCT等提取不同子帶特征,或在空域獲取NSS特征,如:CORNIA[12]和BRISQUE[17]。在學習方法中,使用支持向量回歸或神經網絡提取特征并映射到MOS/DMOS,或使用碼本結合特征。利用沒有MOS/DMOS值的數據集,通過學習構造碼本克服數據規模的缺陷如CORNIA,盡管其具有高維度但后來BIQA模型中經常采用,例如:BLISS[18]、dipIQ[19]和IQA-CNN[20](一個卷積和兩個全連接層的CNN作為CORNIA端到端版本)。
對于深度學習,常見的(Opinion Free,OF)BIQA模型采用其他方式標記圖像質量,利用其他非IQA數據庫擴大訓練集規模。如BLISS利用FRIQA測量得出的綜合分數,先進的FR方法與主觀意見分數高度相關,可用作人眼意見分數的近似值;dipIQ利用具有不同圖像內容的大規模數據庫獲得大量質量可識別圖像對,然后使用RankNet[21]從數百萬的DIP中學習BIQA模型;RankIQA[22]使用相對質量排序已知的降質圖像訓練連體網絡,再將網絡參數遷移到傳統CNN上訓練更深層廣泛的網絡;DLIQA[23]保留了圖像的語義信息,按設定規則標記圖像質量等級,MEON[14]使用不同數據庫對子任務進行分別訓練。對于(Opinion Aware,OA)BIQA方法,直接在標注了質量分數的IQA庫訓練,但也采取不同措施增加數據量或擴展網絡深度。IQA-CNN從圖像中采樣32×32圖像塊從而增加訓練集規模;Deep-BIQ[24]利用遷移學習從預先訓練好的分類模型微調。對BIQA建模根據需求通常歸為回歸問題,按處理思路也被歸為分類問題或分類+回歸的問題。通用BIQA模型依靠失真圖像和相應意見分數來學習將圖像特征并映射到質量分數的回歸函數。可分為:
(1)單任務模型
失真類型已知的特定失真質量評價,如NSS[16]方法針對JPEG2000壓縮;
失真未知的通用失真質量評價,這也是大多數方法目標。
(2)多任務模型:如失真類型識別和質量預測
兩個子任務無關,如IQA-CNN++[25];
兩個子任務相關如MEON[14]。
分類問題:模型探討失真圖像質量的區間,通過其他方法處理具體意見分數。如DLIQA將盲質量評估重新定義為5級分類問題,對應于5種明確的心理概念以促進學習人類定性描述;HOSA通過K-均值聚類,學習感知特征與主觀意見分數之間的映射關系。該類方法通常在輸出層添加回歸模型實現質量分數的輸出。
3 NRIQA學習模型
下文將NRIQA模型即BIQA模型分為基于機器學習和基于深度學習。盡管深度學習屬于機器學習范疇,但由于近幾年發展迅猛,一些特有的學習手段如殘差網絡相繼被提出,因此越來越多的人將其單獨看作一種學習方法。基于機器學習的BIQA模型利用能夠表征自然場景特性的統計模型估計出參數并作為作為回歸特征,學習回歸模型獲得圖像的質量分數,自然場景統計NSS是最典型的特征。基于深度學習的BIQA模型面臨的首要難題是現有訓練集規模不夠,最大的數據庫也僅包含了千位的圖像及注釋。為擴展網絡深度遷移學習是自然聯想到的方法,繼承預訓練用于分類任務網絡的結構和權重進行微調,但其性能和效率很大程度上取決于預訓練任務的普遍性和相關性。為解決圖像標注數據量不足,基于深度學習的BIQA算法分為兩類:一類直接利用標注的MOS/DMOS標簽訓練淺層網絡,這類方法稱為OA-BIQA(Opinion Aware);另一類從結合其他非IQA數據庫設計自動標簽生成模型、任務分段實現等方式增加訓練數據規模,稱為OF-BIQA(Opinion Free)方式或OU-BIQA(Opinion Unaware)。以下選擇典型的機器學習算法和深度學習算法詳細介紹,以通用的全參考方法作對比。
3.1 典型全參考對比方法
FRIQA方法相比BIQA方法,已經形成了較為完善的理論體系和評價模型。在提出新的BIQA方法后,會與FRIQA方法比對。實驗數據表明,典型BIQA方法其性能接近甚至優于FRIQA方法。最常用的FRIQA是基于像素統計的均方誤差MSE、峰值信噪比PSRN,和基于結構信息的結構相似度SSIM[2],基于SSIM還有多種變形,如效果不錯的 IW-SSIM[26]、MS-SSIM[2]。此外,2011年提出的特征相似性指數FSIM[27]強調人類視覺系統理解圖像主要根據圖像低級特征,使用相位一致性和梯度兩種特征建立相似性指數,又加入顏色特征建立彩色圖像特征相似度指數FSIMc[27]。2012提出的梯度相似度GSM[28]強調梯度能傳達重要的視覺信息,梯度特征和像素值結合能達到不錯的效果,實驗測得性能比FSIM差,但算法計算速度快很多。2014提出的視覺顯著性指數VSI[29]認為超閾值的失真很大程度上會影響圖像的顯著圖,把FSIMc中的相位一致性特征換成了顯著圖。更多的全參考方法參見文獻[30]。
3.2 機器學習中的典型模型
通用BIQA算法學習從圖像特征到相應質量分數映射,或者在映射之前將圖像分成不同的失真。這類型的算法均面臨以下問題:(1)需要大量樣本訓練魯棒性;(2)實驗證明算法對不同數據集敏感;(3)使用新訓練樣本時必須再訓練。而NSS特征反映了圖像內容的自相似性和特定性,因此不存在對不同數據庫敏感,使用新樣本時也無需再訓練。
2005年,Sheikh等提出NSS[16]學習模型,第一次嘗試對JPEG2K壓縮圖像進行無參考質量評價。方法的成功表明人對圖像質量的感知和失真的可感知性確實與圖像的自然性有關。但模型精度無法提高很快被超越,其原因在于提取的先驗信息并不能完全解釋降質過程,第二表征JPEG2K壓縮的NSS模型不完善。
2010年,Moorthy等提出BIQI[31],一個基于NSS的NRIQA框架。BIQI對5項失真預設5個質量評估算法實現失真未知的IQA任務。估計存在已定義失真的概率,再計算各個失真對應質量,最終質量表示為失真概率與對應質量加權求和。BIQI模型分成兩步的思想對后續研究有重要影響,但局限性也很明顯,對于未定義失真類型BIQI無計可施。
2010年,Saad等提出BLIINDS[32]以改善機器學習訓練出的算法其性能受特征的限制。模型基于局部離散余弦變換系數的統計,以期到達滿足實時系統需求的性能。但其準確率一般,究其原因未能如預想一樣盡可能多地提取決定視覺質量的特征,提取的特征并不足以表示圖像質量。
2011年,Moorthy等再提出DIVINE[33]基于失真識別的圖像真實度和完整性評估指數。基于失真圖像統計特性變化完成失真類型識別和質量預測,但DIIVINE計算量大,實時性不強。
2012年,Saad等提出BLINDS的后續研究模型BLIINDS-II[34]。依賴貝葉斯推理模型預測給定某些特征的圖像質量。
BLIINDS-II和DIVINE、BLIINDS方法對比較。BLIINDS-II和DIIVINE間有明顯的設計差異。BLIINDSII采用更簡單的表示方式,使用更低維的特征空間和更簡單的單級(貝葉斯預測)框架,在更稀疏的DCT域中運行。BLIINDS指數旨在實現在實時系統中運行的質量評估算法所需的速度和性能。
2012年,He等人基于NSS稀疏表示提出了SRNSS[35]。在小波域中提取NSS特征;通過稀疏編碼表示特征。SRNSS模型采用更少的參數,多次實驗顯示具有強魯棒性。
2012年,Peng等人提出無參考圖像質量評估的碼本表示CORNIA(Codebook Representation for Noreference Image Assessment)[12]。CORNIA提取圖像塊作為局部特征,表明可以直接從原始圖像中學習特征。不考慮任何先驗知識使其適應性更廣,基于CORNIA的后續研究取得了很好的效果。
2012年,Mittal等提出另一種在空域提取NSS特征的模型:盲圖像空間質量評估器BRISQUE(Blind/Referenceless Image Spatial Quality Evaluator)[17]。靈感來自Ruderman[36]關于空間自然場景建模以及SSIM的成功。模型使用局部標準化亮度系數來量化失真產生的“自然度”損失,具有非常低的計算復雜性適合實時應用。
CORNIA和BRISQUE對比,提取NSS特征傳統方法是通過圖像變換和濾波技術,如小波變換、余弦變換和Gabor濾波等,非常耗時不適用于實時系統。CORNIA和BRISQUE都是在空域提取NSS特征。不足的是這類模型一旦建立很難優化,不會像深度學習模型一樣隨訓練數據增加,模型更加準確。
2015年,Zhang等提出集成的局部自然圖像質量評價器 ILNIQE(Integrated Local Natural Image Quality Evaluator)[37]。通過整合多個NSS特征:歸一化亮度統計、均值減法和對比歸一化統計、梯度統計、Log-Gabor濾波器響應的統計和顏色統計學習多元高斯模型。但LINIQE并沒有比CORNIA或者BRISQUE得到更好的結果,究其原因選擇的特征并不能完全表征圖像質量。
2015年,Zhang等提出了基于圖像語義顯著性方法SOM(Semantic Obviousness Metric)[38]。語義顯著性特征來自目標檢測方法BING[39]找到的圖像中多個作為目標的概率排序的相似區域。雖然BING非常快,有很高的物體檢測率和良好的泛化能力,但也決定了SOM與圖像中目標息息相關,目標豐富質量差的圖像獲取的信息也能多于目標少質量好的圖像,同時對于天空這類不具有明確邊界的圖像算法存在局限性。
2016年,Xu等人提出了高階統計聚合算法HOSA(High Order Statistics Aggregation)[40]。圖像塊作為局部特征,通過K均值聚類構造包含100個碼字的小碼本。將每個局部特征軟分配給幾個最近的聚類,并且將局部特征與對應聚類之間的高階統計量(均值、方差和偏度)的差異軟聚合,以建立全局質量感知圖像表示。
3.3 深度學習中的典型OA模型
在深度學習中質量預測是在輸出層做回歸,將圖像多維特征轉化為一個可以表示質量的數值。通常依賴失真圖像和相應意見分數來學習將圖像特征映射到質量分數的回歸函數。這類型的模型被認為是具有“觀察意識”(Opinion Aware,OA)的BIQA模型。以下介紹幾種典型算法模型。
2014年,Kang等提出IQA-CNN[20]基于卷積神經網的BIQA模型。將特征提取和回歸集成到CNN框架加深網絡深度提高學習能力,同時可以使用反向傳播等方法訓練,方便結合改善學習的技術如dropout[41]和ReLU[42]。IQA-CNN相當于CORNIA的神經網絡實現。IQA-CNN關注由圖像降級引起的失真,例如模糊、壓縮和加性噪聲等,對于對比度或亮度引起的質量差異不作為失真。
2015年,Kang等繼續提出基于IQA-CNN的后續研究,一個簡潔的多任務CNN:IQA-CNN++[25]估計圖像質量并識別失真,其參數比IQA-CNN減少了近90%。IQACNN++增加卷積層數量并減小濾波器的接受野,修改全連接層。在滿足需求的前提下希望獲得更多的信息,局限在于訓練集規模太小限制了網絡深度。
2017年,Bianco等提出DeepBIQ[24],基于分類任務預先訓練的卷積神經網絡(CNN)遷移學習實現BIQA任務。通過對圖像子區域預測分數累加和求平均來估計整體圖像質量。微調采用隨機初始化值代替預先訓練CNN的最后一個全連接層作為新的CNN。遷移學習使得網絡深度增加,但其性能受到原始任務影響。
2018年,Boss等提出無參考圖像質量評價之深度圖像質量方法DIQaM-NF(Deep Image QuAlity Measure for NR IQA)[43],在作者提供的參考中方法命名為deepIQA,一些引用也采用此命名。基于端對端訓練,包含10個卷積層和5個池化層,以及2個全連接層。可能數據量無法支撐這深度的網絡,實驗結果并未超越IQA-CNN這樣的淺層網絡。
3.4 深度學習中的典型OF/OU模型
訓練可靠的OA-BIQA模型需要大量的人工評分訓練樣本,但通過主觀測試獲得意見分數通常昂貴且耗時,訓練數據極其有限。同時OA-BIQA模型通常具有弱泛化能力,在實踐中的可用性受限。相比之下OF-BIQA不需要主觀評分來進行訓練,具有更好的綜合能力的潛力。因此有必要開發不依賴主觀意見分數來進行訓練“自主意識”(Opinion Free,OF)的BIQA模型。第一個OF-BIQA模型是2012年由Mittal等提出的TMIQ模型[44]。TMIQ將概率潛在語義分析pLSA應用于從大量原始和失真圖像中提取的質量感知視覺詞,以揭示對視覺質量至關重要的潛在特征或主題,但效果不是很理想。之后Mittal等提出了另一個OF-BIQA模型NIQE[45],優于TMIQ,而且不需要失真圖像訓練。但在所有類型的失真中無法普遍適用,并且當失敗時,很難調整模型來提高性能。這些OF-BIQA模型都不如當時先進的OA-BIQA模型如BRISQUE、CORNIA,故不再贅述。BLISS用于將OA-BIQA模型擴展到OF-BIQA模型,并實現與CORNIA、BRISQUE可比較的性能。
2014年,Ye等提出基于使用合成分數盲學習圖像質量方法BLISS(Blind Learning of Image Quality using Synthetic Scores)[18]。BLIS從全參考(FR)IQA測量得出的綜合分數訓練BIQA模型。先進的FR方法與主觀意見分數高度相關,可用作人眼意見分數的近似值,結合不同的FR方法以生成綜合評分代替人工評分。因此BLISS基于FFIQA的準確性,選擇的FRIQA方法直接影響訓練結果。
2015年,Hou等提出從語言描述學習規則進行定性評價的BIQA模型DLIQA[23]。可以保留語言描述到數值分數的這種不可逆轉換中失去的信息,學習后算法時間復雜度非常低;模型對小樣本問題具有強魯棒性。但定性標簽無法直接同其他算法作比較,且同一等級的圖像無法按質量排序,需要在輸出層按某一規則轉成質量分數。
2017年,Ma等提出dipIQ[19]方法。生成質量可識別圖像對DIP解決訓練數據不足的問題,再使用RankNet[21]從DIP中學習OF-BIQA模型。自動DIP生成引擎是選擇3個FRIQA模型 MS-SSIM[2]、VIF[13]和GSMD[46],采用文獻[8]中提出的非線性邏輯函數將3種模型的預測映射到LIVE庫DMOS規模。
2017年,Liu等提出RankIQA[22]。生成有序的降質圖像訓練連體網絡進行質量相對排名,再將經過訓練的網絡遷移到傳統CNN上,使該CNN可從單幅圖像中估計出絕對圖像質量。作者嘗試了從淺到深的3種網絡,最深的VGG-16取得了最好的結果,在有足夠訓練數據前提下,若嘗試更深的網絡可能獲得更好的效果。
2017年,Kim等提出一種基于卷積網絡的盲圖像評估器 BIECON(Blind Image Evaluator based on a Convolutional Neural Network)[47]。模仿FR-IQA方法,先生成局部質量再匯總回歸得到主觀評分。不同于IQA-CNN,局部質量訓練的圖像塊質量分數由全參考方法獲得。
2018年,Ma等提出端到端優化的多任務深度神經網絡MEON(Multi-task End-to-End Optimized deep Neural Network)[14]。靈感來自 BIQI[31]和IQA-CNN++[25],MEON先訓練一個失真類型識別子網絡,再從預訓練的早期層和第一個子網絡的輸出訓練質量預測子網絡。選擇生廣義分裂歸一化GDN[48]作為激活函數。
2018年,Kim繼續提出深度圖像質量評估器DIQA(Deep Image Quality Assessor)[49]。訓練過程包括回歸到客觀誤差圖和回歸到主觀評分兩部分。另外,采用兩個簡單的手工特征捕獲由于規范化和特征映射無法檢測到的特定失真統計數據。
2018年,Gao提出通過多級深度表示的盲圖像質量預測BLINDER[50]。從有37層的DNN模型VGGnet中提取多級表示,分別在每個層上計算一個特征表示,然后估計每個特征向量的質量得分,最后平均這些預測分數來估計整體質量。
BIECON、MEON、DIQA和IQA-CNN對比,BIECON、DIQA和IQA-CNN++雖然都是基于CNN,且采用局部描述符增加數據量,但是它們從設計到實現都不同。IQA-CNN++僅僅將圖像分成圖像塊,沒有更多的處理,其多任務方式也只是共享一些早期層,子任務間沒有直接聯系。BIECON和DIQA、MEON結構及思想反而更接近,都是將訓練過程分為兩步,第一步作為預訓練跟后續訓練有直接關系;同時第一步訓練能夠使用大規模訓練集。不同在于MEON作為多任務模型,第一步訓練結果即為子任務,BIECON和DIQA的第一步訓練僅作為代理回歸目標,屬于單任務模型,比較有意義的在于它們提出了可視化方法分析CNN模型所學到的內容,可視化學習過程對理解和研究深度學習至關重要。DIQA不同于BIECON增加了手工特征,但這類特征在不滿足應用情況下不僅無效果甚至會產生負面影響。基于CNN或DNN的BIQA模型雖然可直接使用訓練神經網絡的最新方法,并可通過添加更多隱藏層升級網絡,但是都存在以下局限性:它們的模型實際上并不深;通常使用模型中最后一層的輸出作為質量預測的特征表示。除了RankIQA嘗試16層的網絡,BLINDER采用了37層的網絡,使用更深的模型,探索更多級的特征,是基于神經網絡的BIQA模型提高性能最直接的方法。
4 實驗對比
整體流程:首先統計排序算法在LIVE數據庫常見失真測試結果,均按照80%的訓練數據,20%的測試數據,再選擇準確性和相關性高的算法測試泛化能力。先在整個LIVE數據庫訓練,再CSIQ和TID2013數據庫上測試。若提供相應數據直接采用,未提供數據提供了開源模型的自行測試,未開源且數據不全的模型給出已有且有參考性數據,不參與排序。
首先,統計多篇算法在LIVE庫上計算的PSRN和SSIM在常見失真項JP2K、JPEG、WN和BLUR的SROCC和LCC值作為全參考方法參考。基于假設:單個失真數據記錄正確,每項保留小數點后三位,考慮到數據有限且中位數差異不大,取值最后取平均數。
采用如表1同樣的方法依次統計PSRN方法的LCC中位數均值,SSIM方法的SROCC和LCC中位數均值。最后,得到SROCC值和LCC值作為全參考方法代表。
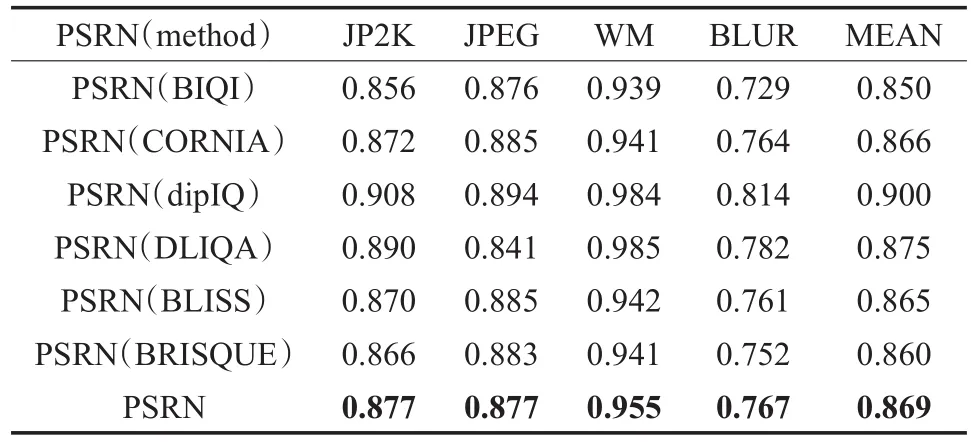
表1 LIVE庫上PSRN方法SROCC中位數均值
表2列出了經過同樣計算得出的各個算法綜合SROCC和LCC值,前4種算法單項失真數據不全,僅提供原文數據參考。表3列出各算法最敏感失真類型及其測得的SROCC、LCC值和最不敏感的失真類型及其測得值(后為失真類型)。
以PSRN和SSIM方法作為參考,在LIVE數據庫的測試排序可以看出選擇的大部分典型方法優于PSRN,IQA-CNN、dipIQ、CORNIA等幾種方法優于優于SSIM,因此在特征選擇和方法思想上都值得進一步探討,其中CORNIA實現在空域提取NSS特征,IQA-CNN可視為CORNIA的卷機網絡實現;dipIQ訓練數據標簽源于全參考方法,且擁有大量訓練數據。
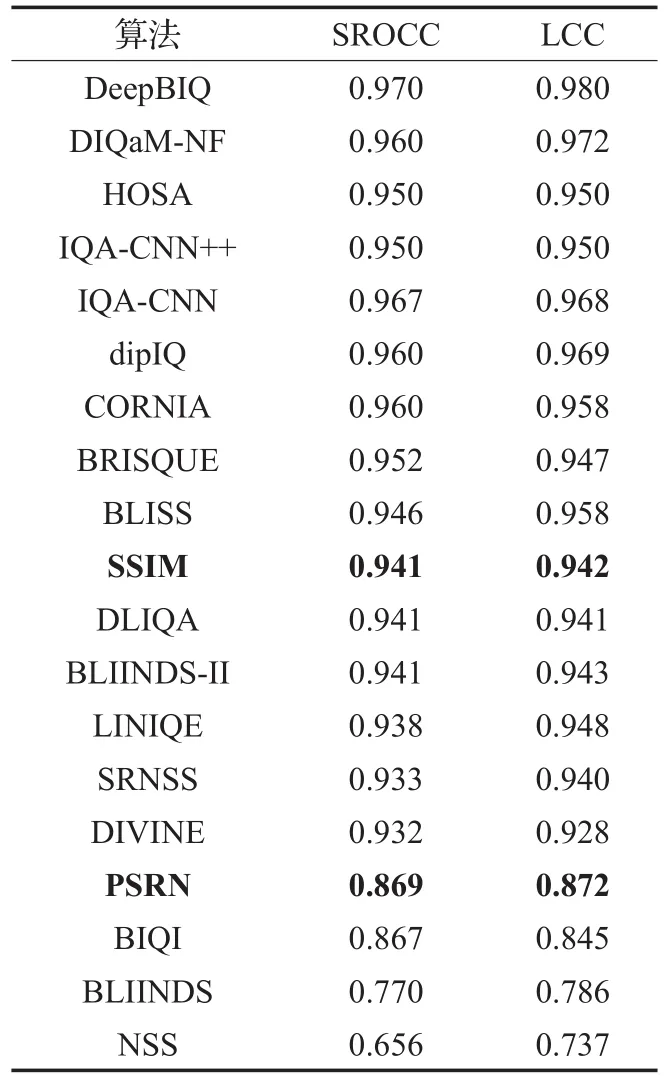
表2 典型模型在LIVE庫排名
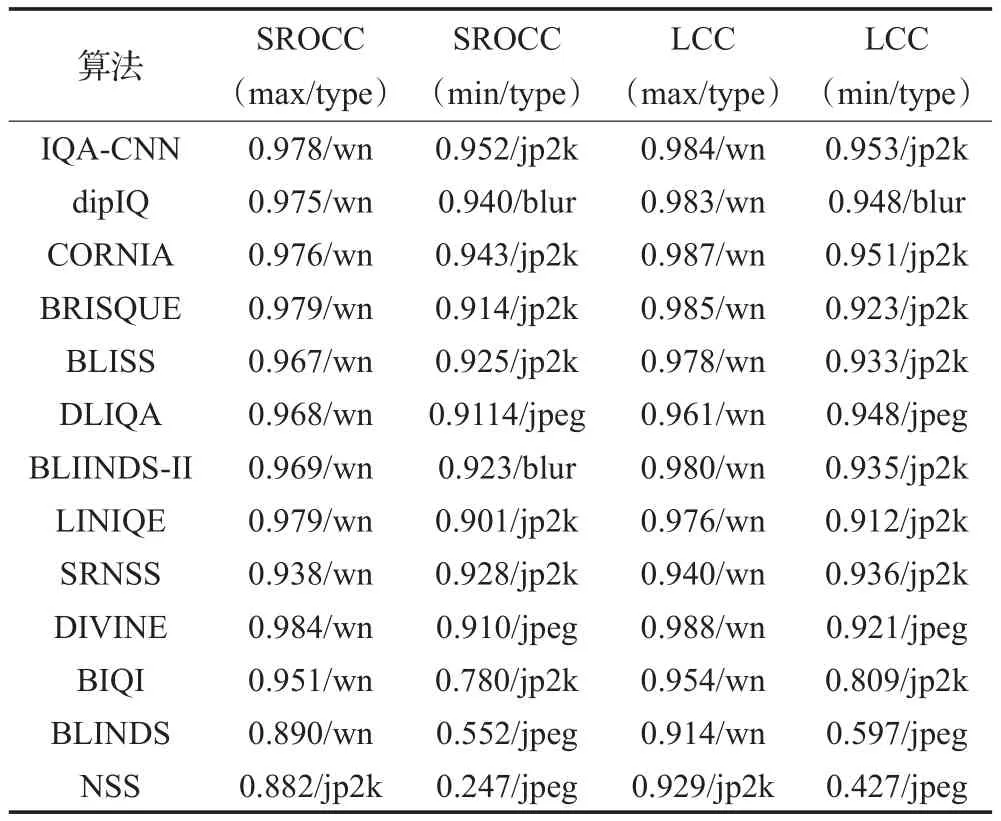
表3 LIVE基準庫SROCC和LCC最值
統計顯示除NSS專門為JP2K失真建模外,其余算法對白噪聲失真WN預測表現高于其他項,在JP2K失真上表現很差的情況下也接近或高于NSS算法。除了第一次嘗試對單項失真利用NSS特征建模的思想外,NSS算法不具有競爭力。BIQI、BLINDS方法最高/低的SROCC差異巨大,BIQI根據選擇的失真類型預設對應的質量評價算法,jp2k失真特征和評價方法的選擇均會影響最終結果。BLINDS也因最高的SROCC值低于0.9不再繼續討論。基于深度學習的方法如IQA-CNN、dipIQ等取得更高的分值。SROCC值與LCC值具有強一致性,高SROCC值對應高LCC值。接下來進行泛化能力測試。
對比表3可以看到算法對不同數據庫敏感,在TID2013庫中,算法準確率有不同程度下降且SROCC與LCC最值對應的失真類型不再高度一致(見表4)。對WN失真敏感度降低,對JP2K預測能力提高。
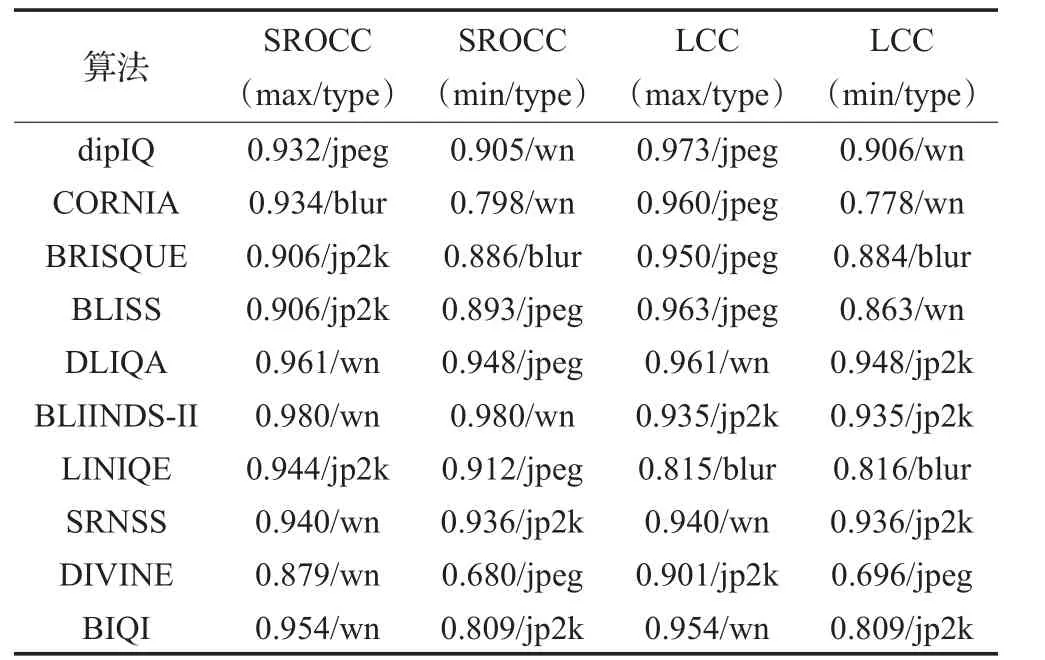
表4 TID2013基準庫SROCC和LCC最值
在CSIQ數據庫,算法實現比在TID2013上貼近預訓練效果(見表5)。但原因可能在于CSIQ數據量小,與LIVE庫差不多,相對而言TID2013庫數據量大,更好的方法是從更多不同庫選擇同失真類型、同規模數據測試,并在多個庫訓練交叉檢驗,缺點在于耗時緩慢,難以一一實現。在這3個數據庫上僅僅對比了常見的4種失真,而現實生活中則存在更多類型失真。排名結果如表6、表7。
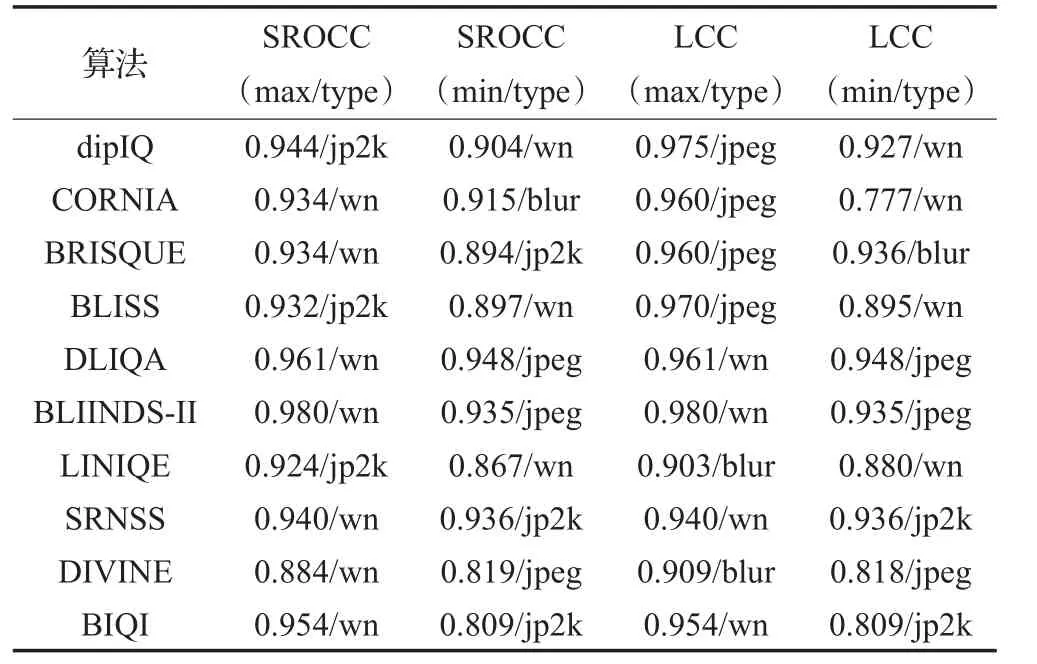
表5 CSIQ基準庫SROCC和LCC最值
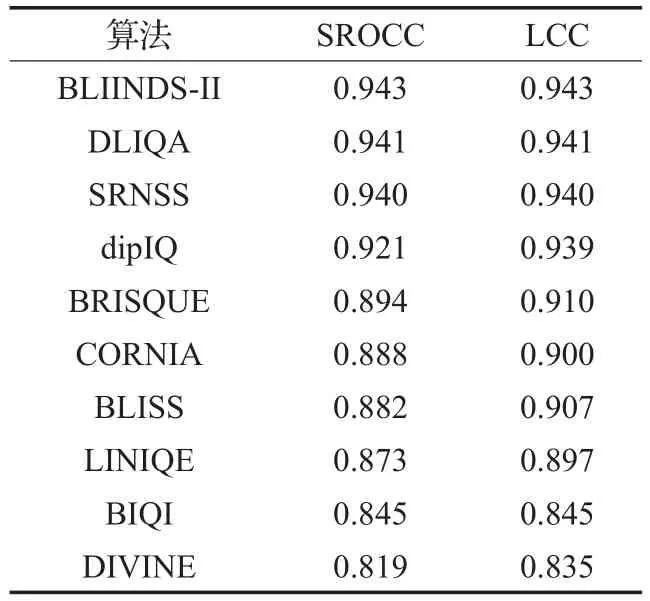
表6 TID2013庫上算法性能排名

表7 CSIQ庫上算法性能排名
除算法如IQA-CNN、HOSA等無法重新訓練也沒有參考數據對比外,在TID2013和CSIQ數據庫上算法的綜合排名基本一致。
如表8,TID即TID2013數據庫。選擇對應算法表現最優的失真SROCC比上表現最差的SROCC值MAX-srocc/MIN-srocc說明面對不同失真類型的穩定性,其值越接近1說明算法對不同失真類型的評價表現接近。表8按算法魯棒性排序,BLIINDS-II、DLIQA、SRNSS其泛化能力都很強,處在前三,準確性也不錯,dipIQ泛化能力不如這3個算法但也遠好于后面的算法,同時dipIQ對于不同失真表現穩定。其中BLIINDS-II在DCT域中提取特征,SRNSS在小波域中提取特征。頻域中可捕獲到空域中無法察覺的信息,但同時也丟失了空域位置信息,稀疏編碼使得魯棒性強,但有限的特征使準確率難以提高;DLIQA提取語義信息與人眼相關性極大,學習后算法時間復雜度低,不過定性的質量評價到定量評價的映射直接決定最終結果,對算法影響極大;而dipIQ訓練數據近百萬。CORNIA成功的從空域中提出特征并對后續研究有深遠影響,在圖像處理中因像素周圍的像素點關系密切有著天然優勢。BLISS結合不同的FR方法生成可以代替MOS/DMOS值的分數,大大增加訓練樣本,也給其他的OF-BIQA模型提供了一種可行的方案。BRISQUE方法在確保準確度前提下具有非常低的復雜度,但相對于BIQA方法近幾年獲得的準確率,BRISQUE方法還有更大的優化空間。LINIQE、DIVINE、BIQI方法準確度次之,同時對于不同失真表現效果差異較大,算法不夠穩定。BIQI方法設計理念比較簡單,對于特定應用場景簡單有效,在對失真類型的準確評價和不同失真的評價算法的選取等方面優化或許會取得更好的成績。
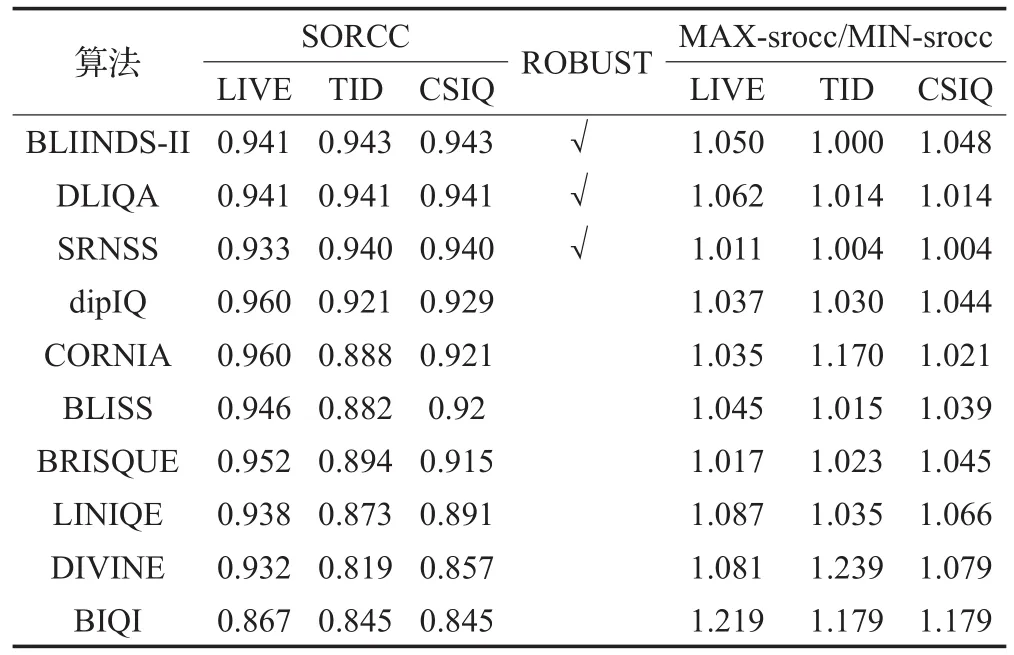
表8 算法性能特點總結
不足的是實驗僅僅單向測試了算法的泛化能力,后續考慮在CSIQ、TID2013等數據庫訓練,在LIVE等數據測試,更多的交叉檢驗能更好地說明了算法魯棒性。同時,可實現IQA-CNN、BIECON等方法參與測試,新的方法不斷涌現,基于不同的設計優化理念、更深的網絡層數都讓無參考圖像質量評價不斷地取得新進展,讓新方法也參與到眾多的比較中有利于對比優化。
5 結束語
通過研究典型算法不難發現:第一,同一個研究團隊持續跟進算法不斷更新性能,如圖像與視頻工作實驗室Laboratory for Image&Video Engineering先后提出了BRISQUE、DIVINE、BLIINDS-II等方法;第二,積極利用各個領域新技術如深度學習方法大膽嘗試;第三,深度學習方法取得了更好的成果,但并非所有的深度學習方法都絕對優于其他機器學習方法。前兩點保證了關于盲圖像質量評價問題的研究從未間斷,且發展過程有跡可循;第三點說明整理并分析不同方法優缺點,互相借鑒、優化創新便可能取得新進展。分析現有的方法不同特點,可以推斷盲圖像質量評估發展大約分為以下幾個方向。
(1)復合失真圖像質量評價:現有的BIQA方法通常只能處理僅包括一種失真類型的圖像,但實際失真圖像通常包括多項失真,如同時包含JPEG壓縮、模糊和噪聲等。
(2)增強型質量改變評價:當前方法測量的質量變化僅包含單項失真產生的降質,不考慮如對比度、亮度或其他圖像增強引起的質量改變。
(3)擴充數據規模研究:想通過更深層的網絡提升準確度就需要大規模的訓練集。增加可用數據是持續研究的熱點問題。一是逐步擴大現有公開庫,二是創新優化OF-BIQA方法。
(4)HVS特征研究:圖像質量評價旨在擬合模仿人眼功能,對視覺特征研究和準確建模是長遠研究內容。
(5)理論結合應用需求:不僅關注算法的準確度、一致性、魯棒性,還有實時性,不同需求針對性,將理論成功轉化應用;利用應用效果反向優化算法,研究并完善理論體系,構建成熟的評價框架。
(6)深度學習方法研究:深度學習復興至今,前饋網絡的核心思想并沒有發生重大變化,如上述方法依然使用相同的反向傳播和梯度下降方法。但基于算法上的改變如使用交叉熵損失函數代替均方誤差損失函數,使用ReLU替代Sigmod則顯著改變了神經網絡的性能。在對HVS特征研究有限的情況下,對工具進行改進,可能會對無參考圖像質量評價提出更穩定、更強大的算法。
猜你喜歡
石油瀝青(2021年4期)2021-10-14 08:50:44
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
河南科技(2014年23期)2014-02-27 14:19:15
