侗臺語族語言的編輯距離分類
2018-10-16 05:49:54趙志靖
計算機工程與應用 2018年19期
趙志靖,江 荻
1.揚州大學,江蘇 揚州 225009
2.中國社會科學院,北京 100081
1 侗臺語族語言的傳統分類
李方桂將侗臺語族分為兩大語群,即臺語群(壯語次群,西南次群(泰、傣語等))和侗水語群(侗語次群,水語次群,莫語次群,佯黃語次群),臨高話屬于壯語次群,沒有定黎語群。
羅常培將中國境內的侗臺語族分為3個語支,即壯傣語支(壯語、布依語、儂語、沙語、傣語),侗水語支(侗語,水家話(毛南、莫家、佯璜的語言看做水家語的方言))和黎語支(黎語)。
1987年《中國語言地圖集》將侗臺語族14種語言分為3個語支,即壯傣語支(壯語、布依語、傣語、臨高話),侗水語支(侗語、水語、仫佬語、毛南語、佯璜語、莫語、拉珈語),黎語支(黎語和村話),此外仡佬語是否作為語支未定。
梁敏、張均如建立了一個與黎、侗水、臺平行的仡央語支,將侗臺語族分為4個語支,即臺語支(包括國內的壯語、布依語、傣語、臨高話和國外的泰語、老撾語、撣語、石家話、土語、儂語、岱語、黑泰語、白泰語、坎梯語和已趨于消亡的阿含語等),侗水語支(包括侗語、仫佬語、水語、毛南語、莫語、錦語、佯璜語、拉珈語、標語等),黎語支(包括黎語、村語),仡央語支(包括仡佬語、拉基語、普標語、布央語、耶容語和越南北部的拉哈語等)。
本尼迪克特(P.K.Benedict)提出了卡岱語,分別將仡佬、黎語、臨高、拉嘉在3個不同的層次上獨立。
本文借助計算機手段,基于斯瓦迪士100核心詞,運用編輯距離算法對侗臺語族16種語言進行分類。
2 侗臺語族語言的編輯距離計算
2.1 比較詞表的選擇
確定語言分類的時候,選擇比較詞項是一個很關鍵的問題。擇詞合理與否直接影響到比較的結果。由于詞的性質不盡相同,同時比較詞項又有數量上的要求,因此操作起來十分困難。這就涉及到了可供操作且符合比較目的的比較詞表的選擇問題。選擇多少數目的關系詞才較適合作語言關系的分類比較,這個問題很重要。
東亞語言歷史研究中確定同源詞一直是一個費解的難題,學者們花費了大量精力構建各類破解方法,企圖甄別同源詞與借詞,以達到判斷語言相互關系的目的。江荻[1]認為“各種研究方法都不同程度深化和逼近了研究目標,但是各種方法又都有局限性。……所以我們又回到了甄別同源詞與借詞的原點”。另外,還有學者利用構造適合東亞語言比較的小規模核心詞集來簡化問題[2],如Matisoff建立的東南亞語言的200詞詞表;黃布凡提出的300詞的藏緬語核心詞詞表;鄭張尚芳建立的華澳語言比較300詞的詞表;江荻提出的200詞的漢藏語核心詞表。江荻認為[1]“這些核心詞集基本都是經驗性的,缺乏可信的選詞理據,同時,這些詞集很少得到應用,難以判斷實際效用。”以上詞表都是模仿斯瓦迪士核心詞集,期望尋找適合漢藏語言的核心詞集。這些研究基礎不同,所采用的詞匯標準大相徑庭,得出的結論自然不同,主觀性很強。
美國學者Swadesh為計算詞匯反映的史前民族接觸深度,提出了語言年代學概念及相關公式和方法,并創造了一個最具普遍性的200詞表(后修改另設100詞表)。他所提出的詞表得到印歐語等多種語言歷史年代分化數據的間接驗證,具有實踐應用經驗。很多學者也都利用斯瓦迪士詞表做相關研究,如日本學者王育德1962年用斯瓦迪士200詞表計算漢語方言北京話、蘇州話、廣東話、梅縣話和廈門話之間的關系[3];徐通鏘先生在1991年將斯瓦迪士100核心詞表應用到語言年代學的計算中,計算出了漢語方言北京話、蘇州話、長沙話、南昌話、廣州話、梅縣話、廈門話之間的同源百分比和分化年代[4];梁敏利用斯瓦迪士200詞表對仡佬、拉基、普標、布央等語言進行了研究,提出“為了避免選詞時的主觀傾向,以斯瓦迪士有關語言年代學統計中所采用的包括200多個基本語詞的詞表作基礎,從中剔除那些在我們對比的語言中沒有的或用詞組表示的詞項,最后選定了200個詞項作對比的基數(在某些語言之間也可能不足200個)”[5];王士元用斯瓦迪士百詞表劃分了侗臺語的譜系樹[6];毛宗武、李云兵用斯瓦迪士修正100詞表和基本200詞表,將炯奈語與苗瑤各語言或方言互相比較[7];Oswalt、Guy、Ringe、Kessler、Goh、Brown 等利用斯瓦迪士100詞表對語言進行分類[8];德國馬普所的ASJP項目采用斯瓦迪士100詞,后來又采用斯瓦迪士100詞中的40詞對語言進行自動分類[9];陳保亞[10-11]利用斯瓦迪士的第100核心詞與第200核心詞比例來觀察語言或方言之間的關系,經過他的廣泛應用,產生了詞集分層次的高低階概念,催生了關系詞階曲線判定法。關系詞階曲線判定法已取得令人滿意的成果,已可初步判定相關語言的關系。認為百詞表比語法、語音系統更穩定,不易借用;孫宏開用斯瓦迪士100詞基本詞表,以滾董話代表巴哼語,將苗瑤各語言或方言互相比較[12];鄧曉華、王士元[13]提到“斯瓦迪士的基本詞匯表已成功適用于世界上的多種語言,例如‘羅賽塔計劃’。”“國內大多數語言學者過分強調漢藏語言的特殊性,自立一套詞表,忽略斯瓦迪士百詞表的國際性、可比性和計量原則”他們利用略有調整的斯瓦迪士100核心詞(主體仍是斯瓦迪士100核心詞)對苗瑤語族、藏緬語族和壯侗語族做了計量分類;江荻[1]用基本層次范疇理論構建核心詞范疇以及為核心詞范疇擇詞,擇詞以斯瓦迪士核心詞為來源,觀察各詞項進入范疇和滿足基本層次范疇的隸屬程度要求,增補刪減,構建出修訂的斯瓦迪士核心詞集;江荻[14]采用詞頻統計的方法觀察斯瓦迪士詞表的分布特征,然后提出以詞頻方法構建核心詞表。
斯瓦迪士詞表是在印歐語調查研究的基礎上,經過反復的實踐而篩選出來的,具有普遍性,比較穩定。它的借用率很低,衰變率在不同的親屬語言中基本是相同的,用百詞表中同源詞比例的高低來確定同源語言親屬關系的遠近比其他方法似乎更可靠。從核心對應語素的比例來劃分譜系樹更能夠排除語言借用的干擾。兩種同源語言百詞表中同源詞數量越多,它們的親緣關系越近。盡管斯瓦迪士詞表的適用性和可用性存在爭議,但在世界范圍語言歷史研究中獲得了廣泛的應用,對世界各地語言具有一定的普適性,被各界學者廣泛運用來比較語言/方言之間的親屬關系,至少是目前國際語言學界公認的做歷史語言學比較的最佳優選詞目,同時具有比較強的可操作性。由于目前國內外還沒有人拿出更合理、更有說服力、實踐性更強的核心詞表,這本身也是一項非常困難的工作,因此本文計算的對象選用斯瓦迪士的100核心詞。斯瓦迪士100核心詞不是本文主觀擬定的,因此具有反映研究目的的效度。正如徐丹所說[15]“在語言學者沒有其他更好的方法之前,這一詞表仍然被廣泛使用,仍不失為有用的工具。”
2.2 語言距離的計算
客觀的語言距離的測量方法是基于語言本身的差異。Kessler于1995年第一次將編輯距離作為測量愛爾蘭方言間的語言距離[16]。從那以后,有很多的研究用這種方法來測量語言或方言間的距離。編輯距離在德國馬普所已有實踐,獲得較好成果。編輯距離被證明測量語言或方言間距離是有效的[17-20]。編輯距離指的是字符串A轉化為字符串B所需的最少編輯數[21]。那么相應地應用到語言學中,一個語言變體的一串語音表達可以相應地對應到另一個語言變體的一串語音表達。編輯距離可以發現一個語音變換為另一個語音所需的最少編輯操作數。假設這反映了語音差異的感知方式和語言演化過程中的變化現象,那么基于任何一個關系詞的不同語言的語音表達間的編輯距離,不同語言間的語言距離就可以被計算出來了。
語音字符串之間的距離通過編輯距離算法計算。編輯距離算法可以得到一個字符串變換為另一個字符串所需的插入、刪除、替換操作的最小代價,即得到兩個字符串之間的編輯距離。該算法的3種操作的“代價”均為1。例如對于斯瓦迪士100詞詞項“牙”,壯語的發音為[f?n],傣語的發音為[fan],它們之間的編輯距離為1(?替換為a)。上述計算過程,小的語音差異(如[a]和[a:])跟大的語音差異(如[a]和[?])是等同的,即編輯“代價”均為1。似乎看起來,大的語音差異應該賦予大的距離,但目前并沒有語音差異(元音間、輔音間距離的量化)的量化研究。這個問題可以通過將每個元音或輔音符號替換為特征束來解決,每個特征被看作是一個元音或輔音屬性,特征束是一系列的特征值,每個值表示對應元音或輔音屬性數值化的程度。本文采用Almeida&Braun系統對元音和輔音特征的定義[22]來求得元輔音間距離。這樣一來,元音間距離等于元音特征束之間的差異和除以特征數目的平均值。然后這些距離值用于替代編輯距離操作的默認“代價”值1。輔音間距離計算過程類似元音,不再贅述。
通過Python編制程序利用上述思路計算不同語言的兩兩詞匯之間的語音距離。利用詞匯距離我們就可以計算語言距離。有了語言距離就可以對語言進行分類了。前文提到,本文利用斯瓦迪士100詞進行語言距離計算。所以,當對兩個語言進行比較的時候,會得到100個編輯距離。兩個語言之間的距離等于100個編輯距離的和除以100。N個語言之間的所有距離會形成一個N×N的距離矩陣。
3 分類結果
3.1 語言材料
本文收集了16種侗臺語族語言的斯瓦迪士100核心詞。為方便觀察,本節列出了這16種語言的名稱及代碼。
臺語支(壯傣語支):壯語—Zhuang,泰語—Thai,老撾語—Laowo,撣語—Shan,臨高語—Lingao。
侗水語支:侗語—Kam(Southern_Dong),佯僙語—Then,莫語—Mak,仫佬語—Mulam,毛南語—Maonan,水語—Standard_Sui。
黎語支:黎語—Hlai。
仡央語支:仡佬語—Gelao,拉基語—Laji,布央語—Buyang,普標語—Pubiao。
3.2 距離矩陣
利用編輯距離算法及上文的計算思路得到侗臺語族16種語言之間的編輯距離(百分比表示),如表1所示。
3.3 語言分類樹形圖
一旦語言間距離計算出來了,有了距離矩陣,那么就可以對語言進行分類了,語言分類結果表明語言之間的關系。本文采用聚類分析技術。隨著計算機技術的發展,聚類分析的技術已經集成到計算機軟件中。生物學家開發的一些研究生物種系發生分類的程序,對語言學家很有幫助,因為生物學的分類與語言學分類相類似。聚類分析的結果是一個表示親緣關系的系統樹圖,系統樹圖是一個分層次的結構樹,樹的葉子節點是不同的語言。Mega是生物信息學上用來構建和繪制進化樹的軟件,本文利用Mega軟件中的鄰接法構建語言關系的樹狀圖。
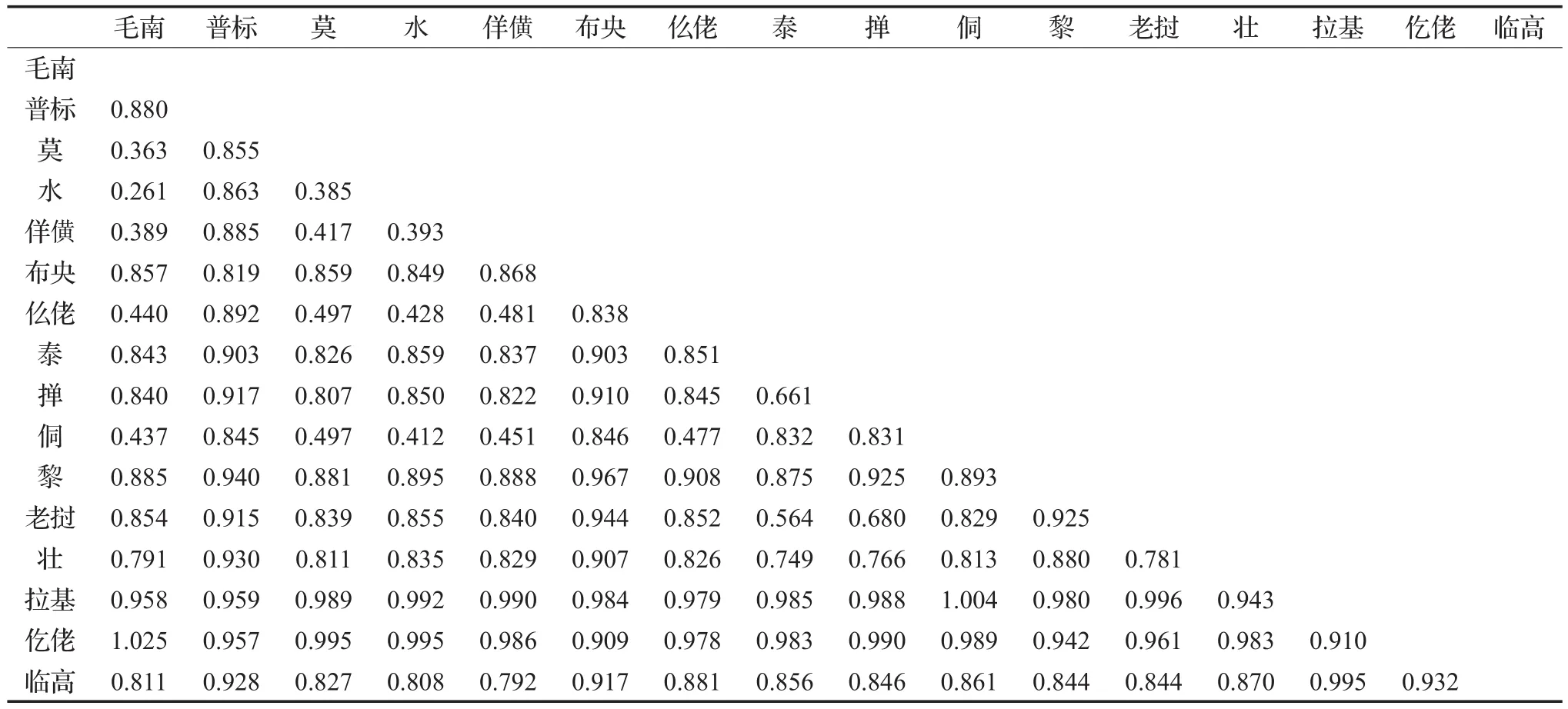
表1 侗臺語族16種語言之間的編輯距離
基于表1的侗臺語族16種語言之間的編輯距離,生成的語言關系的樹狀圖見圖1所示。
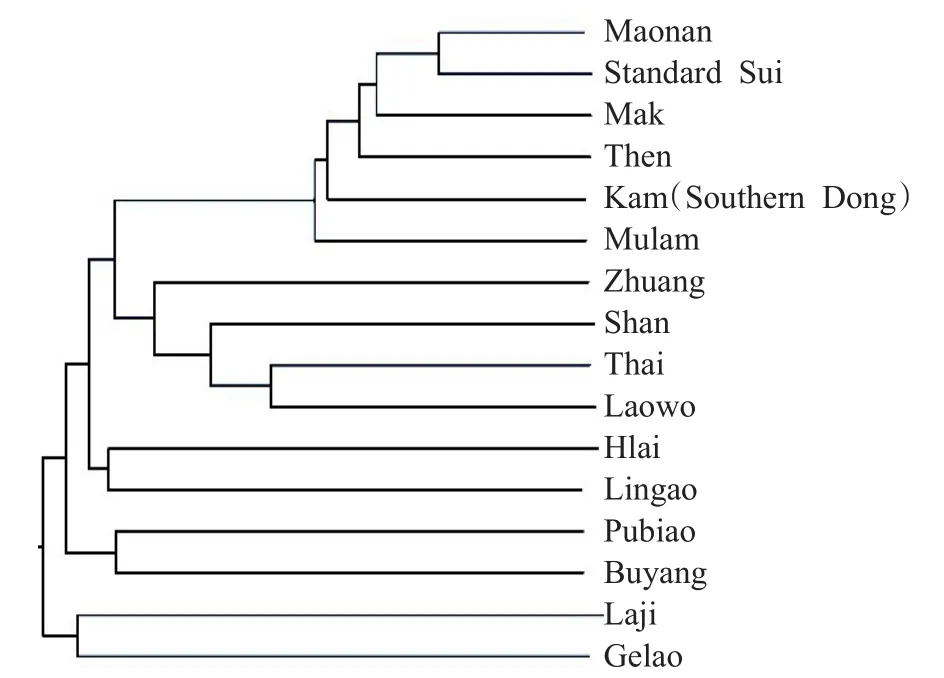
圖1 侗臺語族16種語言關系樹形圖
4 分析與討論
本文的樹形圖(圖1)分類將侗臺語族分為5個聚類,即仡佬和拉基、黎和臨高、布央和普標、壯傣(壯、撣、泰、老撾)、侗水(毛南、水、佯僙、侗、仫佬、莫語)。樹圖的第一層為兩份,即仡佬和拉基與其他等;第二層為兩份,即布央和普標(黎和臨高、壯傣、侗水);第三層為兩份,即黎和臨高(壯傣、侗水);第四層為兩份,即壯傣,侗水;第五層為泰和老撾與壯、撣組成一個簇,毛南和水與莫語、佯僙、侗、仫佬組成一個簇。本文分類與前人觀點基本一致,尤其是與梁敏的侗臺語族譜系樹圖(見圖2)基本相符,比如侗水(毛南、水、莫語、佯僙、侗、仫佬)語支語言之間的關系;壯傣(壯、撣、泰、老撾)語支語言之間的關系;仡佬和拉基之間的關系;布央和普標之間的關系。與國內觀點不同的是,本文將黎和臨高合并獨立一支,黎和臨高關系比較近。
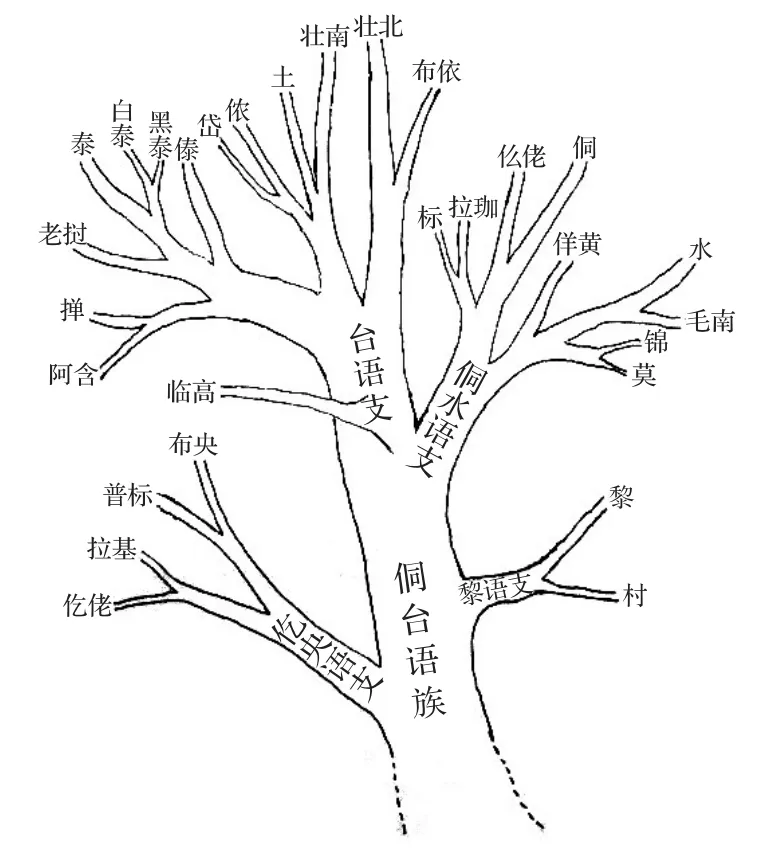
圖2 侗臺語族譜系樹圖
本文的樹形圖顯示,仡佬和拉基獨立一支,布央和普標獨立一支,這與梁敏先生的語言觀點是一致的。梁敏先生將仡佬、拉基、布央、普標稱之為仡央語群,它們之間的關系如圖3所示[5]。
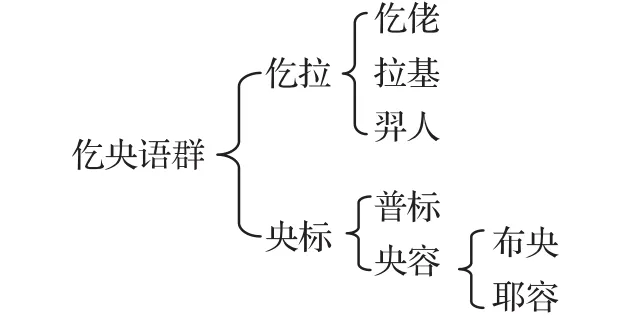
圖3 仡央語群
從圖3可以看出,仡佬和拉基關系密切,布央和普標關系密切。本文樹形結果也是如此。梁敏指出[5]“在仡佬、拉基、布央、普標這幾種語言之間,仡佬和拉基的同源詞較多……所以仡佬和拉基的關系更密切一些”“布央和普標同源的比例也較高,達38.74%,他們的語言系統在仡央語群中也是比較接近的……布央和普標的先民可能有過比較密切的關系和接觸來往。”“仡佬和拉基比較接近,可以看作是一小團,稱為仡拉語支;普標和布央內部也比較一致,又是另外一個小團,可以稱為央標語支。”
本文的樹形圖從整體上來看,相比仡佬和拉基與布央和普標,黎和臨高離壯傣和侗水更近,而且從樹圖樹枝的長度來看,壯傣和侗水兩個語支中,黎和臨高離壯傣語支更近。這與前人研究的觀點基本上是一致的。李方桂將臺語群分為兩個次群:壯語次群和西南次群。他在《中國的語言和方言》[23]中提到“壯語群包括廣西大部分地區和貴州南部以及云南東南部所使用的許多方言,使用于海南島北部臨高、澄邁和瓊山的熟黎話也屬于這個語群。但在海南島中部和南部的黎話與其他臺語相比似乎有很大的分歧。”從李方桂的論述中可以看出,黎和臨高與壯語群關系比較近,但是否歸屬于這個語群還是值得懷疑的。而本文樹形圖正是將黎和臨高單列一支,但又與壯傣語支距離比較近。1987年的《中國語言地圖集》和1996年梁敏的侗臺語族分類則直接將臨高話劃歸臺語支。梁敏用對比研究的方法分析臨高語和侗臺語族其他語言在語音、詞匯和語法方面的異同和它們在發生學上的親緣關系,認為臨高語是侗臺語族臺語支中的一個獨立語言[24]。另外,梁敏[25]指出“臨高人的先民屬壯泰種族集團的一部分。所以臨高語中與臺語支相同的語詞比它與侗水語支相同的多一些。”鄧曉華、王士元認為臨高分別與黎和壯的親緣關系最接近[13]。
與國內觀點不同的是,本文將黎和臨高合并獨立一支,黎和臨高關系比較近。國內學者將臨高歸在壯傣語支,并且認為與壯語關系最近,將黎單獨列為一支。本尼迪克特則將黎和臨高單列出來。但是也有學者認為黎和臨高有關系[13],如法國的薩維那(Savina)認為臨高是黎語的一支;德國人類學家史圖博(Stubel)提出臨高可能是黎語與泰漢語的混合語;鄧曉華、王士元認為臨高分別與黎和壯的親緣關系最接近。
5 本文方法與詞源統計法的比較
鄧曉華、王士元利用詞源統計法對苗瑤語族[26]、藏緬語族[27]和壯侗語族[13]做了計量分類。下面從相同點和不同點兩個方面將本文方法與詞源統計法做對比。
相同點:
(1)二者均借用生物學上關于物種進化關系分析的方法來分析語言的親緣關系。
(2)二者分析不僅可以顯示各種語言的親疏關系,更可以顯示出語言之間的親緣距離。
不同點:
(1)同源詞和借詞的問題
詞源統計法是建立在同源詞統計的基礎上的。詞源統計分析的基礎和前提是核心同源詞的選取。如何確定和優選核心同源詞是詞源統計分析的最重要步驟之一。這個問題一直存在較大爭論,同源詞有歷史文化層次的差別,有的同源詞較容易被借用,有的同源詞則被借用的概率較低,同源詞和借詞身份界定很困難。同源詞和借詞如何區分是個老話題,也是語言系屬討論中最敏感和引起爭議的問題,直到現在也未能徹底解決。
本文的編輯距離方法不涉及同源詞和借詞的問題,無需選取同源詞,規避了同源詞和借詞身份的界定。另外,詞源統計法界定的同源詞數據不同,得到的結果也會不同,本文方法得到的結果自始至終是一致的,可重復,可驗證,科學性較強。
(2)主觀性和客觀性的問題
詞源統計法的操作步驟可簡單歸結為:編制同源詞統計表并計算各對語言的同源比;距離矩陣;繪制樹形圖。本文方法可簡單歸結為:搜集各語言的用國際音標標音的斯瓦迪士100詞;距離矩陣;繪制樹形圖。需要說明的,鄧曉華在利用詞源統計法對語言進行數理分類時,同源詞的統計也是用斯瓦迪士100詞表(經過了一定的修訂,但主體仍然是100詞表,個別詞有所調整),看各對語言斯瓦迪士100詞中有多少詞是同源的,從而計算各對語言的同源比。很明顯,詞源統計法的第一步是經驗性的而非理據性的,不同人給出的結果也會不同。確定語言之間同源詞的時候仍依賴于專家們的經驗和判斷,帶有主觀性成分。
本文直接利用田野調查得到的用國際音標標音的斯瓦迪士100詞,后續過程全是計算機自動操作,中間不涉及同源詞的選擇和確認工作,利用的是語音原生材料,客觀性比較強。
(3)全面性和局部性的問題
詞源統計法只能做低一層次的語支和語言/方言層級的局部性分析,無法對高一層次的語族和語系層次做出整體的全面性分析。原因是語族和語系層次的同源詞選擇和確認很難做到,尤其是漢藏語言。
本文的編輯距離方法不僅能做低一層次的語支和語言/方言層級的局部性分析,而且還能對高一層次的語族和語系層次做出整體的全面性分析。這也是本文下一步的研究工作,如侗臺語族、漢語族、藏緬語族、南島語族之間的關系,這也是學界一直有爭議的話題,等等。
(4)本文方法特色之處
①對于新發現語言,可以利用本文方法進行快速分類,再結合歷史比較法確定該語言與其他語言之間的關系。
②本文方法能應用于非常大的語言樣本,這有利于大規模語言數據的統計研究和可以揭示之前未知的語言發生關系。
③本文方法為長久以來學術界因為傳統語言學研究產生的爭論提供一種可能的解決方案。
6 總結
本文借助計算機手段,基于斯瓦迪士的100核心詞,運用編輯距離算法以及生物學的種系發生樹方法,對侗臺語族16種語言進行了分類,顯示出了侗臺語族語言的類簇和分級層次。其結果表明,編輯距離的分類結果與已有的傳統語言學的分類結果基本是一致的,其操作過程是可以重復和驗證的,可推廣至更多的語言及方言的分類,在一定程度上彌補了歷史語言學的不足,也為計量法提供了新思路。同時,本文提出了跟傳統分類的不同看法,即黎和臨高關系非常近,黎和臨高合并,在侗臺語族中獨立一支。另外,本文也進一步驗證了斯瓦迪士100核心詞可用于語言關系分類的研究中。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
文苑(2020年4期)2020-05-30 12:35:30
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
瘋狂英語·新策略(2017年8期)2017-05-31 08:13:46
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
