排序學習研究進展與展望
2018-10-18 06:10:52李金忠劉關俊閆春鋼蔣昌俊
自動化學報 2018年8期
李金忠 劉關俊 閆春鋼 蔣昌俊
隨著互聯網和云計算技術的迅猛發展以及網絡用戶規模的爆發式增長,互聯網已經步入了“大數據”時代.中國互聯網信息中心發布第39次中國互聯網絡發展狀況統計報告指出,截至2016年12月底,我國網頁數量為2360億,網民規模達7.31億,搜索引擎用戶規模超過5.93億.面對互聯網上如此海量繁雜的網絡大數據與千差萬別的網絡搜索用戶,傳統的信息檢索模型、機器學習方法在搜索引擎系統中的應用面臨著極大的挑戰.如何從互聯網上的海量數據中,準確、及時、高效地獲取用戶所需信息是信息檢索研究的主要問題,其本質即是信息的排序問題.排序是信息檢索和很多實際應用如搜索引擎和推薦系統等所面臨的核心問題,排序模型在互聯網搜索和推薦中起著關鍵作用,其排序性能的優劣直接影響互聯網用戶使用搜索引擎和推薦系統的體驗.因此,針對排序技術的研究是基礎且關鍵的研究問題之一.
傳統的信息檢索排序模型主要有相關性排序模型和重要性排序模型.相關性排序模型主要包括布爾模型、向量空間模型和概率檢索模型(BM25和統計語言模型),重要性排序模型主要包括PageRank算法[1]、HITS算法[2]、TrustRank算法[3]、BrowseRank算法[4]和ClickRank算法[5]等網頁排名算法模型.
這些傳統的排序模型的構建過程一般通過人工依據經驗去調整排序模型中所涉及到的一些參數,但這些經驗參數不易調節且易產生過擬合;另一方面,盡管這些不同的排序模型大體上都使得排序效果得到了一定的性能提升,但如何將不同排序模型融合在一起以構建一個性能更優的統一排序模型,并不易于處理.同時,隨著影響排序性能的排序特征的不斷增加,排序特征已有成百上千種,傳統的排序模型的構建方法已不再適于處理如此多維和復雜的排序特征.而機器學習方法具有能自動調整參數,融合多個模型的結果,通過規則化的方式避免過擬合等優點.在如此背景下,涌現了大量的研究者運用不同的機器學習技術去訓練排序模型以解決信息檢索中的排序問題,并由此產生了信息檢索與機器學習交叉的一個熱點研究領域—排序學習(Learning to rank).排序學習就是利用機器學習方法在排序學習數據集上進行訓練,自動產生排序模型,從而解決排序問題.和傳統排序模型相比,排序學習的優勢在于對眾多排序特征進行組合優化,對相應的大量參數自動進行學習,最終得到一個高效精準、更加優化的排序模型.
排序學習是信息檢索和機器學習交叉的一個研究熱點.近幾年,SIGIR、WWW、WSDM、CIKM等國際頂級會議將Learning to rank作為一個主要的Session或Track,特別是在2012年的SIGIR大會上,最佳論文榮譽提名獎[6]和最佳學生論文獎[7]都頒給了Learning to rank方面的論文,SIGIR2015、CIKM2016、KDD2016和 WSDM2016等的最佳(學生)論文獎也頒給了Learning to rank方面的論文[8?11].2010年,Springer期刊Information retrieval以特刊形式在其上刊登了“Learning to rank for information retrieval”[12].同年,Yahoo舉辦了Yahoo!Learning to Rank Challenge[13]比賽.很多知名的搜索引擎公司、推薦系統和大型電子商務平臺等在很大程度上依賴于排序學習方法為用戶提供高質量的搜索和推薦結果.
對排序學習的研究方興未艾,不僅具有重要的理論研究價值,也具有廣闊的實際應用前景.盡管排序學習在學術界取得了大量的研究成果和在工業界取得了令人矚目的成功,但在排序學習的研究領域中仍還有許多相關的問題有待更全面深入地探討.鑒于此,本文詳細分析了當前排序學習的研究進展,并重點對排序學習的發展趨勢和有待深入研究的重難點進行了展望,以示拋磚引玉.
本文第1節描述了排序學習問題;第2節對排序學習方法進行了分類;第3節到第5節分別歸納了排序學習的數據集、方法應用和方法軟件包.第6節展望了發展趨勢;第7節對全文進行了總結.
1 排序學習問題描述
排序學習是利用機器學習方法在數據集上對大量的排序特征進行組合訓練,自動學習參數,優化評價指標以產生排序模型.
圖1展示了排序學習的一個典型框架,該框架涉及排序學習的三個重要方面—數據集、方法和評價指標.排序學習數據集主要包括訓練集(Training set)和測試集(Test set),通常也包括驗證集(Validation set).訓練集用來訓練排序模型,驗證集用來選擇排序模型(若沒有驗證集,則訓練集也用來選擇排序模型),而測試集則用來檢驗最終選擇的排序模型的性能.排序學習數據集由若干維排序特征數據和若干等級的相關性標注數據構成.排序特征數據x描述了查詢–文檔對q,d〉的特征表示,如tf、idf、BM25、PageRank等特征值;相關性標注數據y描述了文檔與對應查詢的相關性程度,如兩級標注(0和1)或多級標注(0、1、2、3、4等).相關性標注數據多采用人工判斷給定(顯式標注),也可利用點擊數據等獲得(隱式標注).排序學習方法從排序學習數據集中學習并獲取排序模型,其主要有Pointwise、Pairwise和Listwise三大類,而采用的機器學習技術主要有感知機、神經網絡、支持向量機、Boosting、樹、極限學習機、貝葉斯和進化算法等.排序學習評價指標用于度量排序模型的性能,如信息檢索中常用的準確率(Precesion,P)、召回率(Recall,R)、平均精度均值(Mean average precision,MAP)、歸一化折扣累積增益(Normalized discounted cumulated gain,NDCG)、期望倒數排序(Expected reciprocal rank,ERR)等.典型排序學習框架包含一個學習系統(Learning system)和一個排序系統(Ranking system).在學習系統中,通過排序學習方法從訓練集中學習排序模型并最終獲得最優排序模型;在排序系統中,利用訓練出來的最優排序模型對測試集進行排序預測,并通過信息檢索評價指標進行度量.從整個排序學習框架來看,最終獲得的排序模型的性能取決于訓練集(若包含驗證集,則取決于訓練集和驗證集)、排序學習方法和評價指標.在同一數據集上,不同的排序學習方法在不同評價指標上其性能表現有所差異;在不同數據集上,同一排序學習方法在不同評價指標上其性能表現也將會略有不同.
2 排序學習方法分類
從不同的角度,依據不同的分類標準可以將現有排序學習方法劃分成不同的類型,如依據輸入數據樣例或依據采用機器學習技術的不同,可劃分成如圖2所示的類別.
2.1 依輸入數據樣例的分類
按照訓練模型時輸入數據樣例的不同,Liu[14]和Li[15]將排序學習方法分為3大類:Pointwise(單文檔)、Pairwise(文檔對)、Listwise(文檔列表).
在Pointwise方法中,將訓練集中每一個查詢下的每一個文檔看做一個訓練樣例,其輸入是單個文檔,包括每個文檔的特征.Pointwise方法把排序問題轉換成分類問題(二值、多值)、回歸問題或序數回歸問題求解,其目的是將訓練樣例盡可能準確地映射到區間里.
在Pairwise方法中,將訓練集中的每一個查詢下的任意兩個具有偏序關系的文檔對作為一個訓練樣例,其輸入是文檔對.Pairwise方法把排序問題主要看成為一個二分類問題,它考慮文檔對之間的偏序關系,更接近排序問題的實質.訓練排序模型的目標是去追求排序結果列表中不正確的偏序對盡量的少,越少則表明越好.若學習后獲得的文檔對的偏序關系和它們的真實文檔對的偏序關系是完全一致的,則說明結果完全正確.
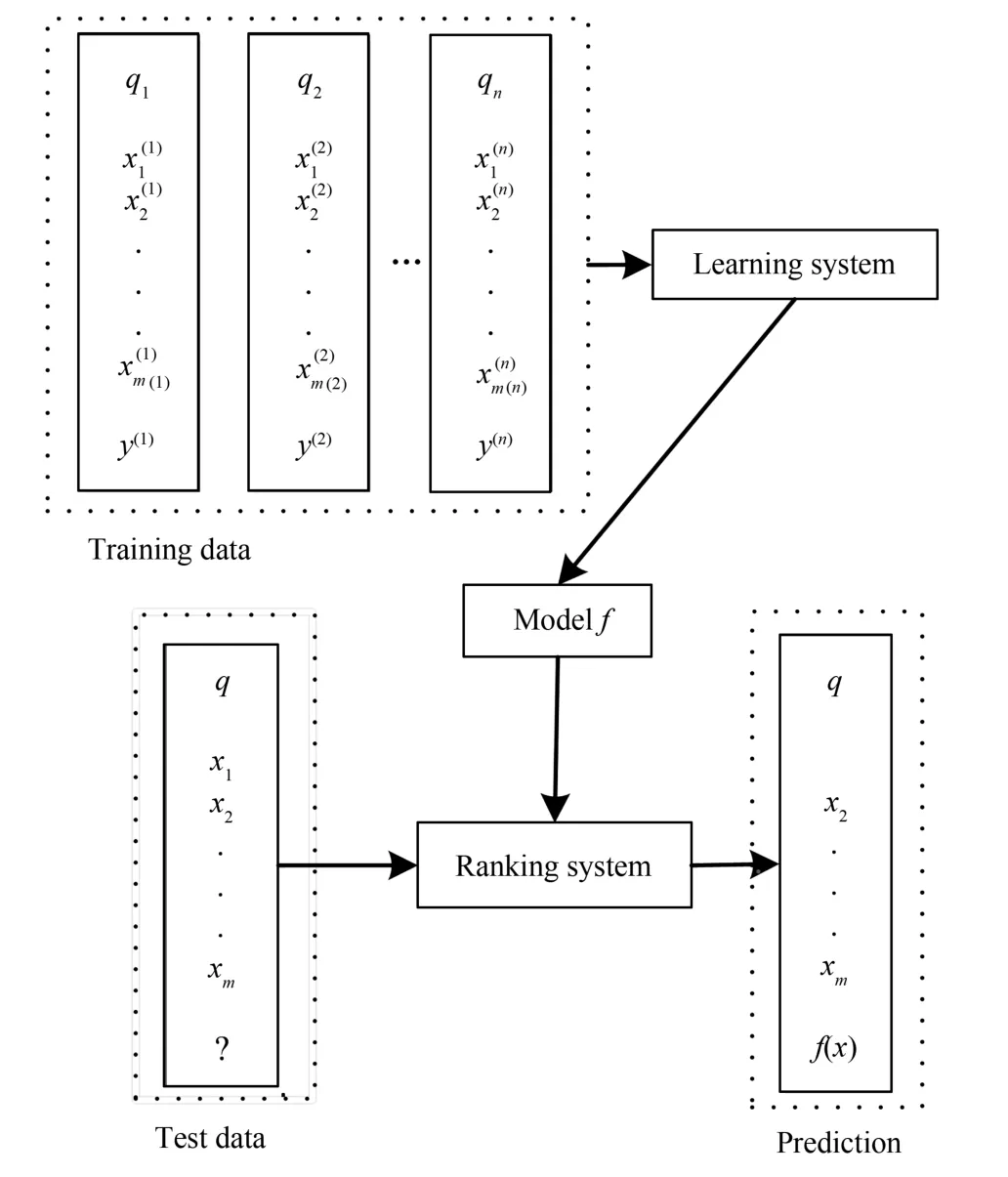
圖1 排序學習典型框架[14]Fig.1 A typical framework of learning to rank[14]
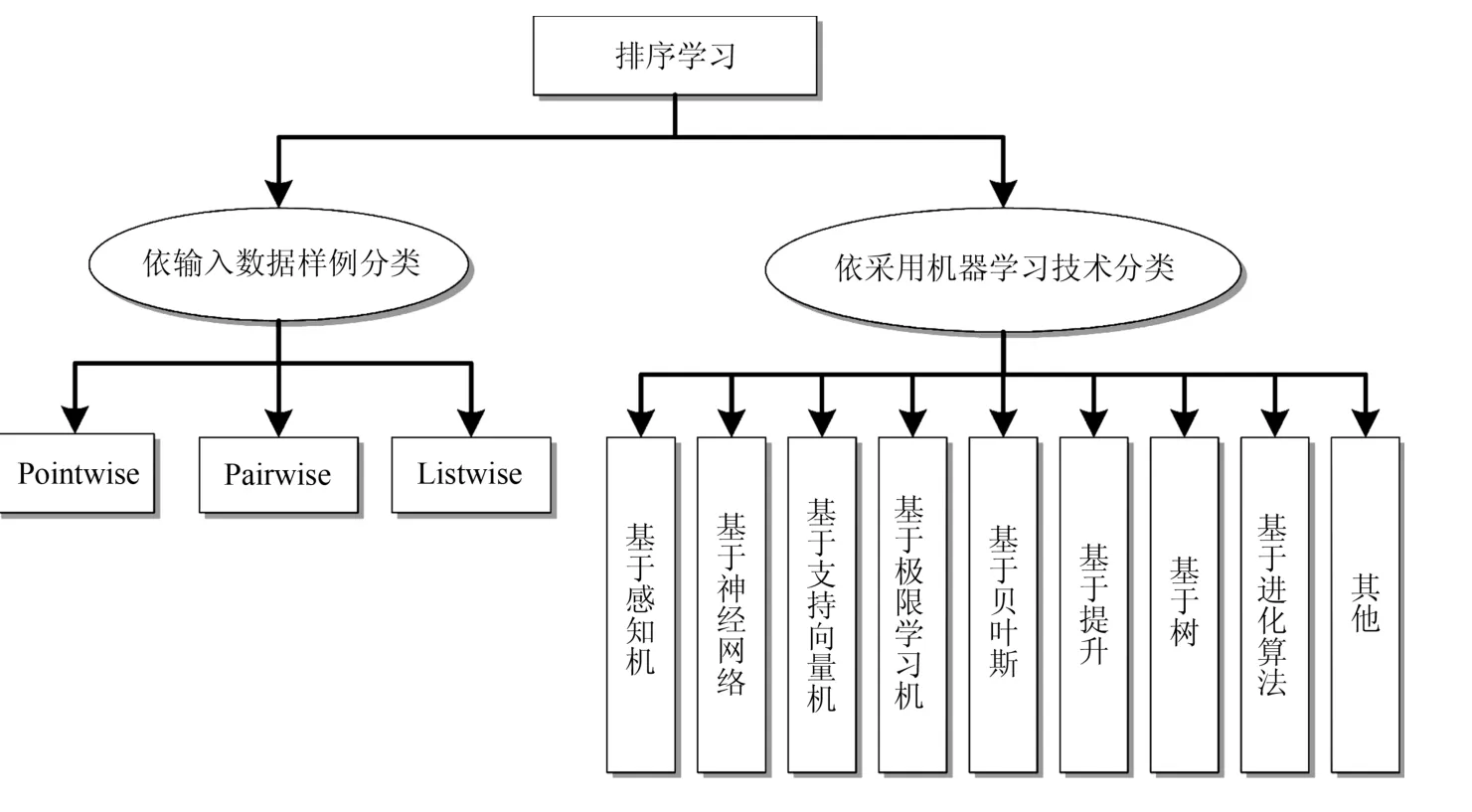
圖2 排序學習方法分類Fig.2 Categories of the learning to rank approaches
在Listwise方法中,輸入不再是單個文檔或文檔對,而是一組文檔列表,是將每一個查詢下對應的所有文檔的排序結果列表作為一個訓練樣例,更加全面地考慮了同一查詢下不同文檔的序列關系.Listwise方法以不同的方式度量文檔排序序列的排序效果,訓練排序模型的目標是使得結果列表與真實列表中文檔排序順序越接近越好.Listwise方法也可再細分為兩類:直接優化基于排序列表的損失的Listwise方法和直接優化信息檢索評價指標的Listwise方法.前類Listwise方法繼承了Pointwise和Pairwise方法的研究思路,通過定義Listwise損失函數并最優化該損失函數而求得排序模型,其損失函數構造為用于衡量預測的文檔序列與真實的文檔序列之間的差異.后類Listwise方法將排序模型的構建與信息檢索中的評價指標建立起關聯,獲得了最優評價值的排序模型被認為是最優排序模型,其基本思想是先定義信息檢索中某個具體的評價準則(如NDCG等)的優化目標,再選擇適當的機器學習方法和優化算法去學習排序模型以構建更能滿足用戶需求的最優排序模型.
表1從排序學習的輸入數據、樣本復雜度、所轉化的主要問題和所具有的特點4個方面總結了Pointwise、Pairwise和Listwise三大類排序學習方法.實踐經驗結果表明,基于Listwise排序學習方法的排序模型的有效性通常要優于Pointwise和Pairwise這兩大類排序學習方法的[14?15].當前,Listwise排序學習方法已成為近年來被研究最多的方法.
2.2 依采用機器學習技術的分類
依據訓練模型時所采用機器學習技術的不同,我們將排序學習方法分為以下幾類:基于感知機、基于神經網絡、基于支持向量機、基于極限學習機、基于貝葉斯、基于提升、基于樹、基于進化算法的排序學習方法和其他排序學習方法等.
2.2.1 基于感知機的排序學習方法
感知機(Perceptron)是一種二分類的線性判別模型,對應輸入空間中將實例劃分為正例和負例兩類的分離超平面w·x?b=0,其輸入和輸出分別為樣本實例的特征向量和類別.感知機學習旨在追求一個能夠將訓練數據完全正確線性劃分的正、負例分離超平面,即通過學習策略最小化風險以優化模型參數w和b,從而對新的實例實現準確預測.感知機是神經網絡與支持向量機的基礎.
PRank[16]是基于感知機的排序學習方法的代表之一,它是一種基于感知機同時在線學習線性模型的排序學習方法.該方法的基本思想是利用大量的并行感知機同時在線學習線性模型,每個模型在相鄰等級之間做分類,旨在找到一個能成功將全部訓練樣例準確映射到所定義的k個區間內的感知機模型.PRank方法的目標是最小化排序損失,希望預測排序盡可能接近真實排序.它通過迭代學習來實現,在第t次迭代中,排序模型獲取與查詢q相關的文檔的排序值xt,算法預測其分值ηt=minr∈{1,···,k}{r:wt·xt?btr<0}, 并獲取其真實排序值yt.如果排序模型將xt的分類預測為ηt而不是yt,那么wt·xt的值在btr的錯誤方,則需修改w和b的值以更新排序規則;否則,設置wt+1=wt,?r:btr+1=btr.重復迭代,直到訓練過程結束, 最終輸出H(x)=minr∈{1,···,k}{r:wT+1·x?bTr+1<0}.PRank方法直觀簡單,其正確性和收斂性在理論上得到了證明.
文獻[17?18]等也利用感知機設計排序學習方法.Gao等[17]提出了基于感知機的算法LDM(Percep)以最小化排序列表中不一致文檔對的數量.Xia等[18]針對只利用“正例”排序進行訓練的關系排序學習方法R-LTR,進一步改進關系排序模型,提出了基于結構化感知機的排序學習方法PAMM.
基于感知機的排序學習方法簡單且易于實現,并可從數學上嚴格證明算法的收斂性,但收斂速度較慢.設計基于感知機的排序學習方法的難點在于損失函數的定義及如何最小化損失函數.
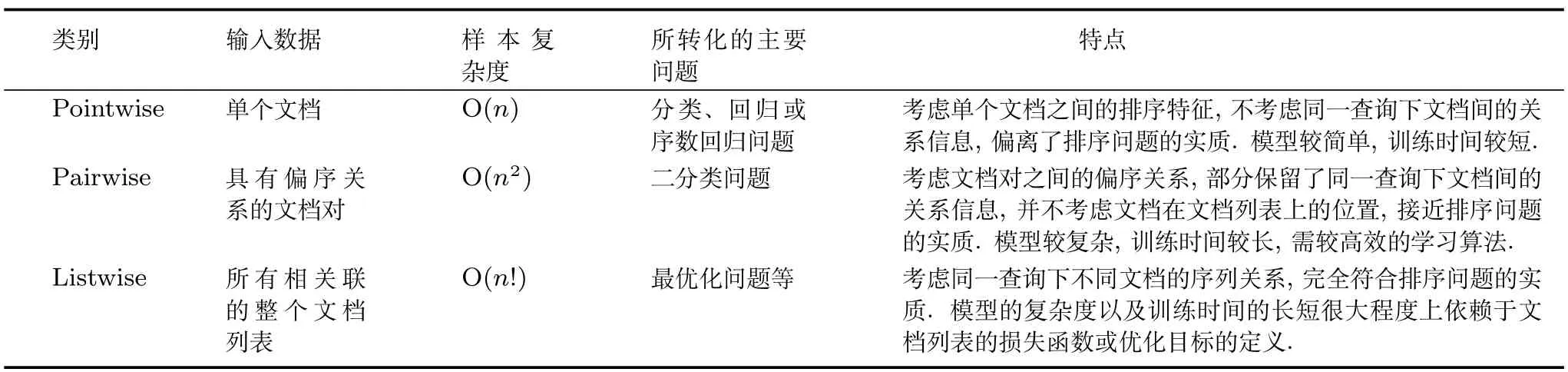
表1 Pointwise、Pairwise和Listwise排序學習方法對比Table 1 Comparison of Pointwise,Pairwise and Listwise learning to rank approaches
2.2.2 基于神經網絡的排序學習方法
神經網絡(Neural network,NN)是感知機的無環網絡,其中一些感知機的輸出結果又作為其他感知機的輸入.NN的主要思想是在給定的訓練樣本下,通過模仿生物神經網絡所出現的一些屬性,試圖構建一個能優化分離數據成正例和反例的n維決策邊界面.它根據訓練數據來調整神經元之間的“連接權重”以及每個功能神經元的閾值,其學習過程中需使用一些優化方法,如梯度下降法,以找到一個能最大限度地減少錯誤分類數量的解.
RankNet[19]是基于神經網絡的排序學習方法的代表之一,該方法依賴于每一個文檔對,定義了一個基于概率的損失函數,運用神經網絡和梯度下降法試圖最小化一個交叉熵損失函數.在RankNet中,給定關聯于偏序文檔xu和xv,基于真實標注構建目標概率,它表示文檔xu排在文檔xv前面的概率;基于由評分函數f計算文檔的評分差異定義模型概率Pu,v,即;在文檔對上定義損失函數為目標概率和模型概率之間的交叉熵,即,最終目的是優化C的總和,使損失函數最小.在RankNet中,神經網絡用于建模,梯度下降法作為優化算法去學習評分函數.優化過程中,在訓練數據上使用當前網絡去計算評分,使用計算損失,基于相關計算公式更新網絡參數.由于RankNet的訓練數據為各查詢下若干文檔對,因此需針對文檔對的輸入去調整神經網絡的權值.
RankNet不僅在理論上是一個很好的模型,而且是第一個應用于互聯網搜索引擎的排序學習方法,微軟已經將RankNet技術應用于其搜索引擎必應(Bing)中.為了改進RankNet,研究者們又提出了FRank和LambdaRank等排序學習方法以追求更好的排序結果.FRank[20]與RankNet的區別在于所使用的損失函數不同,它采用的是 fidelity函數作為損失函數.LambdaRank[21]是基于RankNet的改進方法,對梯度的計算方式引入信息檢索評價指標NDCG,針對迭代過程中所生成的文檔列表以及相應的NDCG取值的變化情況來確定每個文檔對的梯度,從而體現如何調整文檔之間的相對順序以最大化NDCG,希望所構建的相應損失函數能與最終的評價準則盡可能相一致.
文獻[22?25]等也是基于神經網絡的排序學習方法.ListNet[22]是基于神經網絡和梯度下降的排序學習方法,它將排序問題看作一個排列概率問題,考慮實際排序列表與真實排序列表分別對應的概率分布之間的比較,采用K-L散度來定義排序損失函數.ListMLE[23]則根據實際打分函數計算真實排序列表的概率分布,從而考慮最大化實際理想排序列表的對數似然函數來度量排序損失.Xia等[24]使用神經張量網絡為搜索結果多樣化建模文檔新穎性,基于文檔新穎性的新模型,在關系排序學習框架下,設計了兩種新的多樣性排序學習方法R-LTRNTN和PAMM-NTN.Rigutini等[25]提出了一種基于比較神經網絡(CmpNN)的偏序排序學習方法SortNet.
基于神經網絡的排序學習方法的學習能力較強,對噪聲數據魯棒性和容錯性較強,但需調節的參數較多,訓練速度慢,容易過擬合,泛化性能較差,有可能陷入局部極小值.
2.2.3 基于支持向量機的排序學習方法
支持向量機(Support vector machine,SVM)是一種建立在統計學習的VC 維(Vapnikchervonenkis dimension)理論和結構風險最小化原理之上的機器學習方法.SVM的主要思想是在給定訓練樣本下,構建一個n維超平面作為決策邊界曲面,最優化分離這些數據,使得正例和負例之間的隔離邊界被最大化.SVM可看成是感知機的一種改進版本,它的目標是構建一個不僅能將正例和負例分開且能使得間隔最大化的分離最優超平面.
Joachims[26]提出了一種基于SVM 的代表性排序學習方法Ranking SVM,該方法從用戶的點擊序列中獲取具有偏序關系的訓練樣本對,將排序問題轉換為一個二值分類問題,并使用SVM 去訓練排序模型.給定n個訓練查詢和每個查詢相關聯的文檔對以及對應的相關性標注,即訓練數據,則Ranking SVM的優化問題可數學形式化為:.其中控制模型ω的復雜度.該問題等價于最小化正則化 Hinge損失函數,即,通過解決對偶問題i=1,···,n來獲得最優化參數,最終輸出排序模型〉. 可知,Ranking SVM繼承了SVM的框架和特性,其目標函數非常相似于SVM的,與SVM的差異主要在于約束條件.Ranking SVM的約束條件是從文檔對中構建的,其損失函數也是定義在文檔對上的Hinge損失.
基于支持向量機的排序學習方法還有文獻[27?30]等.SVM-MAP[27]方法定義了評價指標為平均精度均值(MAP)的目標函數,并以此設計了一個基于Hinge的損失函數來替代原MAP的目標函數,利用結構化SVM的框架來設計排序方法,同時使得目標函數中松弛變量的總和上有界約束位置敏感準則(1-AP).SVM-NDCG[28]方法與SVMMAP方法類似,但要求上有界約束位置敏感準則(1-NDCG).Zhao等[29]提出了一種深度特征學習結構化SVM的排序學習方法以同時解決學習有效特征和排序學習的優化問題,該方法在一個聯合的學習框架下,通過結構化SVM學習,可同時獲得深度線性特征集和構建結構化感知的排序模型.Li等[30]把排序學習問題看作為一個結構化學習問題,基于結構化SVM設計了一個Bregman距離函數以構建排序模型,并為該排序模型開發了一個魯棒性結構化學習框架,提出了魯棒性結構化Bregman距離函數的排序學習模型.
基于支持向量機的排序學習方法具有嚴密的理論基礎,較強的泛化能力,且易于使用;小樣本數據下可得到較高的準確率,但處理大規模排序學習數據集時顯得效率低下.
2.2.4 基于極限學習機的排序學習方法
極限學習機(Extremelearningmachine,ELM)可視為一種新型簡單、快速有效的單隱層前饋神經網絡的學習方法.與前饋神經網絡相比,ELM的主要特點是隱藏結點參數不僅與訓練數據無關,而且彼此獨立,還有隱藏結點參數在訓練數據出現之前可以生成.ELM算法思想是首先給定網絡隱層結點參數和激活函數,設置輸入結點和隱層結點的連接權重及隱層結點的閾值;然后將網絡輸入輸出關系變成一個矩陣向量形式H·β=O計算隱層輸出矩陣H;最后通過β=H+O求解獲得網絡輸出連接權重β,其中H+是H的廣義逆運算.
傳統的神經網絡學習算法,如反向傳播算法,需通過人工設置較多的網絡訓練參數,并且很容易陷入局部最優解.而ELM算法只需設置網絡中隱層結點的個數,在其執行過程中,無需去調整網絡的輸入權重以及隱元的偏置,可隨機初始化輸入權重和偏置,學習一次就可得到相應的輸出權重,即可獲得唯一的最優解.ELM算法實際上為廣義單隱層神經網絡提供了一個統一的解決方案,它是從傳統神經網絡擴展到正則網絡和支持向量網絡.
Zong等[31]應用ELM,從Pointwise和Pairwise兩個視角分別設計了Pointwise RankELM和Pairwise RankELM兩種排序學習方法以解決相關性排序學習問題,并提出了線性隨機結點的ELM和線性內核版本的ELM.在Pointwise RankELM排序學習方法中,針對線性隨機結點的ELM,先依據給定的訓練樣本,產生L個帶有每個結點隨機分配參數(a,b)的隱藏結點,再計算隱層輸出矩陣,并計算輸出權重和計算測試樣例的輸出函數f(x)=h(x)·β.而針對線性內核的ELM,計算測試樣本的輸出函數:·和. 而在Pairwise RankELM排序學習方法中,與Pointwise RankELM 不同的是:1)在線性隨機結點中,Pairwise RankELM是構建矩陣w存儲查詢文檔關系的信息,并計算相應的Laplacian矩陣,而計算輸出權重β時,是按照進行計算的.2)在線性內核中,Pairwise RankELM首先構建矩陣w存儲查詢文檔關系的信息,并計算相應的Laplacian矩陣,再按照f(x)kernel=去計算測試樣本的輸出函數f(x).
Chen等[32]提出了一種新的運用ELM的排序學習方法ELMRank,給出定理并證明了ELMRank也繼承了ELM 的計算可行性,并針對假設空間能力,確立了ELMRank的泛化分析.
基于極限學習機的排序學習方法只需設定網絡的隱層結點數,無需迭代調節隱層結點的學習,只需一次學習就可獲得唯一最優解;具有簡單易用、訓練參數少、學習速度快和泛化性能好且廣義逼近能力強的優點,但沒有較好的魯棒性.
2.2.5 基于貝葉斯的排序學習方法
貝葉斯(Bayesian)方法是一種基于假設的先驗概率、給定假設下觀察到不同數據的概率和觀察到的數據本身信息而計算假設概率的方法.該方法首先綜合未知參數的先驗信息與樣本數據信息,然后依據貝葉斯公式去計算后驗信息,最后依據所得出的后驗信息去推斷未知參數.
Guo等[33]提出了BLM-Rank,一種貝葉斯線性模型的排序學習方法,該方法在貝葉斯個性化排序標準的框架下,使用一個線性函數去評分樣本的值,依賴于樣本的評分建模樣本的Pairwise偏好,并采用了隨機梯度法去最大化BLM-Rank中的先驗概率,且在GPU上實現了該方法.BLM-Rank方法首先從訓練數據中構建Pairwise訓練樣本和構建正偏序對的訓練集,然后混排Γ+中的Pairwise訓練數據以便于將要遍歷的次序是無偏的和隨機的,再對每個樣例(xi,j,xi,k)∈Γ+,依條件循環執行w=w+α·以獲得最終w,最后產生線性函數F(xi,j,w)=wTxi,j.
還有一些基于貝葉斯的排序學習方法,如Cossock等[34]為排序學習設計貝葉斯最優化排序函數,并對貝葉斯最優子集排序作統計分析;Wang等[35]提出了一種簡單快速的排序學習模型RankBayes,該模型可以應用樸素貝葉斯算法去實現.
基于貝葉斯的排序學習方法具有堅實的數學基礎,計算簡單、快速;容易理解和解釋,且易構造,估計模型參數時無需復雜的迭代;支持增量學習,但需要計算先驗概率,對輸入數據的表達形式較敏感.
2.2.6 基于提升的排序學習方法
提升(Boosting)是一類可將弱學習器提升為強學習器的方法,通過線性組合若干個弱學習器,有監督的迭代以改進弱學習器的機器學習方法.Boosting的理論基礎是弱可學習理論,其工作機制是:先從初始訓練集訓練出一個弱學習器,再根據弱學習器的性能調整訓練樣本分布,使得當前弱學習器做錯的訓練樣本在下一次迭代中受到重點訓練,然后基于調整后的樣本分布去訓練下一個弱學習器;如此循環訓練,直至弱學習器的數目達到預先給定的值T,最終將這T個弱學習器進行加權組合以創建一個單一的強學習器使得整體性能得到提升.
RankBoost[36]是基于AdaBoost算法的排序學習方法,通過最小化實例對的分類錯誤而訓練排序模型,其學習目標是通過結合多個弱排序器構成最終唯一的排序模型.RankBoost是Pairwise排序學習方法,實質是在優化文檔偏序對間的分類誤差,整體還是Boosting框架,在逐層迭代過程中,根據前一階段的學習情況調整各訓練數據的權重.具體來說,RankBoost方法基于分布Dt訓練弱學習器ht,得到弱排序器ht:x→R,而后選擇合適的αt∈R,再通過更新分布,此處Zt是一個歸一化因子.最后,輸出最終排序模型:.由上可知,RankBoost排序學習方法是基于當前文檔對的分布Dt去學習最優的弱排序器ht,并選擇對應弱排序器的權重αt,以便進行線性權值疊加.
AdaRank[37]是一種基于Boosting算法框架、能直接最小化定義在信息檢索評價準則上的指數損失函數的Listwise排序學習方法,該方法在調整訓練數據權重的基礎上不斷地構造弱排序器,最終線性組合各弱排序器以用于排序預測.
基于提升的排序學習方法簡單易用、設置參數較少、不易過擬合、能有效降低偏差,且具有理論支持,具有較強的特征選擇能力和一定的泛化能力,但有效合理地選取損失函數和更緊致的泛化誤差界是兩大難點問題.
2.2.7 基于樹的排序學習方法
樹(Tree)是具有相同數據類型的數據元素的集合,樹狀結構表示數據元素之間存在著“一對多”的樹形關系.一般的,一棵樹包含一個根結點、若干個內部結點和葉子結點.根結點包含樣本全集,葉子結點對應于樣本實例,其他結點則對應數據屬性.根據數據屬性的不同,劃分每個結點包含的樣本集合到葉子結點中.對于給定的訓練樣本,根據數據屬性采用樹狀結構建立模型.提升樹是以分類樹或回歸樹為基本分類器的提升方法.
基于樹的排序學習方法的代表之一是LambdaMART[38?39],該方法是基于RankNet的LambdaRank的提升樹版本.LambdaMART方法利用多重加法回歸樹(Multiple additive regression tree,MART)取代LambdaRank方法中的神經網絡以優化目標函數,優化過程中采用近似牛頓迭代法(Newton-Raphson)確定每一個葉子節點的輸出值.LambdaMART方法的基本思想是訓練一個弱模型的集成,組合每一個弱模型的預測為一個比單個模型的預測更強大和更準確的最終模型.LambdaMART從名字上可拆分成Lambda(即λ)和MART兩部分,λ是MART學習過程中所使用的梯度,采用MART去優化λ以訓練排序模型.某個查詢q下的每個文檔對di,dj〉的梯度定義為,其中|?Mij|表示交換文檔di和dj的排序位置后所引起的該查詢的有效性M(M可為信息檢索中一些常用的有效性評價指標,如歸一化折扣累積增益NDCG等)的改變量.每個文檔di的梯度定義為,其中I表示某查詢q下的所有文檔對di,dj〉的下標集合.MART直接在函數空間求解梯度函數,循環構建多棵樹,每棵樹的擬合目標是損失函數的梯度λ,通過不斷疊加學習到的回歸樹而更新排序模型F,即,其中η表示學習率,γlk表示第k個訓練樣例的第l個葉子結點的輸出值.LambdaMART方法的框架本質是MART算法,其創新在于訓練過程中使用λ梯度,其特點是不顯式定義損失函數,而是定義損失函數的梯度函數,以解決排序損失函數不易被直接優化的問題.
LambdaMART在解決實際排序問題中已經被證明是一個非常成功的排序學習方法的代表之一,后續出現了較多對該方法的深入研究.Capannini等[40]開發了一個最有效的基于樹的學習器的多線程實現的、開源的可提供優化的C++框架,這些學習器包括梯度提升回歸樹 GBRT、LambdaMART、Oblivious LambdaMART、一種誘導Oblivious回歸樹的森林算法.Lucchese等[41]提出了一種新的有效排序學習方法X-DART,該方法借用CLEaVER方法中樹的剪枝策略以改進DART,最終提供更魯棒和緊湊的排序模型.
還有許多工作對基于樹的排序學習方法進行了研究.Chen等[42]使用隨機梯度提升回歸樹訓練排序函數.Kocsis等[43]提出了一種提升樹策略的排序學習方法.Asadi等[44]聚焦于使用梯度提升回歸樹進行排序學習運行時的性能優化.Yin等[8]采用梯度提升決策樹和邏輯損失函數設計了排序學習方法LogisticRank以進行搜索結果的排序.Lucchese等[11]為排序學習任務提出了一種有效的樹集成的遍歷算法QuickScorer以快速排序文檔.Dato等[45]擴展了文獻[11]的工作,提出了一個利用Oblivious和Non-oblivious回歸樹加法集成建模的排序函數來對文檔進行有效評分的新算法框架,旨在對大型Web搜索引擎返回的查詢結果進行快速排序.Lucchese等[46]提出了一個為優化基于回歸樹集成的機器學習排序模型的新框架,該框架是對樹集成的后期學習優化,其目標是去改進排序效率而不影響排序質量.Mohan等[47]提出了一種基于初始化梯度提升回歸樹的排序學習方法以用于Web搜索,該方法組合了隨機森林和梯度提升回歸樹,首先運用隨機森林去學習出一個排序函數,再將該函數作為梯度提升回歸樹的初始值繼續學習更優的排序函數.de S等[48]提出了一個基于Boosting和隨機森林排序學習的通用框架以平滑組合加法樹集成學習.它使用隨機森林模型作為Boosting方法的弱學習器,依賴于通過隨機森林所產生的詞袋樣本以決定最終加法模型中每一個弱學習器的影響和通過一個更可靠的錯誤率估計以更新樣本分布的權值.Ibrahim等[49]深度比較了基于隨機森林的Pointwise和Listwise排序學習方法,即RF-point和RF-list,設計了一種能直接優化任意排序標準的基于隨機森林的Listwise排序學習方法,還設計了一種能融合不同分裂標準到單棵樹中的隨機森林的混合排序學習方法,該混合方法結合了樹構建的早期的Listwise目標和晚期的Pointwise目標.
基于樹的排序學習方法計算簡單,易于理解,速度快,學習效果通常較好,但樹的分裂標準和剪枝策略對產生的排序模型的性能影響較大,如何選擇最優特征來劃分特征空間是一大難點;容易發生過擬合,不過,隨機森林可以在很大程度上減少過擬合.
2.2.8 基于進化算法的排序學習方法
進化算法(Evolutionary algorithm,EA)是來自于大自然的生物進化靈感的一個“算法簇”,是一類基于遺傳和選擇等生物進化機制的迭代優化的搜索算法.EA的主要思想是:在搜索最優解的過程中,一般是從原問題的一個解(或解集)進化到另一個較好的解(或解集),再從這個改進的解(或解集)繼續進一步迭代進化以獲得更優化的解(或解集).EA求解問題的主要步驟是:隨機生成一個或一組初始解;評價當前該解或該組解的性能;選擇當前該解或從該組解中選擇給定數量的解迭代執行進化操作以獲取新解;若新解滿足給定的停止條件則結束迭代,否則將進化所得到的新解作為當前解再重新迭代執行進化操作.
EA并非直接處理求解問題的具體參數,而是針對求解問題的整個參數空間給出相應的編碼方案.它是一種能適應不同問題和環境的魯棒性智能優化方法,且在大多數情況下都能進化到用戶滿意的優化解.EA從某個單一的或一組初始點開始搜索,搜索中只要有目標函數值的信息就可優化,可不必用到目標函數的導數信息等,也不必要求目標函數是連續的,且具有較好的全局尋優能力,因而有較多的進化算法應用于排序學習問題中.將進化算法應用于設計排序學習方法,關鍵問題是解和排序模型的映射問題、適應度函數或優化目標的相應設計問題.
較早的基于進化算法的排序學習的代表性方法之一是Yeh等[50]運用遺傳編程技術設計排序學習方法RankGP,該方法將排序模型表示為種群中的個體(解),一個個體I是一個潛在的排序函數,使用3個組件定義一個函數表達I=(Sv,Sc,Sop),其中Sv表示符號標記集,指訓練集的特征,Sc表示預定義的實數集,值域∈[0,1],Sop表示算術操作集.I被定義為一個二叉樹結構,它的葉子結點是特征或常量,非葉子結點是如+、?、×、÷等操作,利用種群的遺傳編程在樹上執行排序模型的學習.在進化過程中,通過交叉、變異、復制和選擇等進化操作迭代產生一個新種群.在每次迭代中,使用平均精度均值MAP建模適應度函數以評價種群中每個個體在訓練集上的性能.當進化結束時,將會產生一個適應度值最優的個體,以此個體作為最優排序模型.
受基于遺傳編程的排序學習方法的啟發,Lin等[51]運用分層多種群遺傳編程改進RankGP方法,提出了排序學習方法RankMGP以學習排序函數.Keyhanipour等[52]提出了一種新穎的排序學習方法MGP-Rank,該方法從任意的基準數據集中,在基于點擊數據概念的特征產生框架下產生點擊特征,使用一種分層的多種群遺傳編程框架去找最優化的排序函數.
借鑒RankGP方法將遺傳編程應用于設計排序學習方法的經驗,越來越多的基于進化算法的排序學習方法被提出來.Wang等[53]提出了一系列通用定義和一個為進化計算在排序學習研究中應用的共同框架,并基于該框架,提出了一種使用免疫規劃的排序函數發現方法.He等[54]提出了一種基于克隆選擇算法的排序學習方法RankCSA,直接優化信息檢索的性能評價指標(MAP)以學習有效的排序函數.Diaz-Aviles等[55]基于粒子群優化框架,提出了一種新穎的排序學習方法SwarmRank直接最大化信息檢索中廣泛使用的評價標準以學習排序模型.Alejo等[56]提出了一種基于粒子群優化算法的排序學習方法RankPSO以直接優化評價標準而訓練排序模型.Bollegala等[57]提出了一種基于差分進化算法的排序學習方法RankDE去學習排序函數以對所檢索的文檔進行排序.Wang等[58]提出了一種基于協同進化算法的并行排序學習框架CCRank,目標是顯著改進學習的效率且同時保持精度,并采用三種基于進化算法(遺傳編程、免疫規劃和基于樹的幾何差分進化)的排序學習方法(RankGP、RankIP和RankGDE)實現了該框架.Ibrahim 等[59]運用進化策略設計排序學習方法ES-Rank以解決排序學習問題.Tian等[60]利用多核處理器將B細胞算法并行化,并將克隆交叉思想融入到并行B細胞算法中,同時提出了一種抗體的先序編碼序列將樹結構轉化為線性結構,進一步設計了基于并行B細胞算法的排序學習方法RankBCA.Li等[61]提出了一種基于現代投資組合理論和歸檔式多目標模擬退火算法框架的風險敏感的魯棒性排序學習方法R2Rank,以同時優化增益和風險并獲取有效性和魯棒性之間的均衡.
基于進化算法的排序學習方法可直接優化信息檢索的評價標準,往往訓練得到的排序模型可獲得相對更優的評價性能.但由于該類方法存在大量迭代,通常計算復雜度較高和收斂速度較慢,故需花費的學習時間可能相對較長.可喜的是,由于進化算法通常具有天然的并行性,所以可將該類方法進行并行化,從而提高其效率.而且,進化算法非常適合大數據分析,所以基于進化算法的排序學習方法適合解決大數據排序學習問題.
2.2.9 其他排序學習方法
Moschitti[62]研究了一種具有語法和語義結構的基于核理論的排序學習方法.Ailon等[63]提出了一種有效的兩階段的基于偏好的排序學習方法.Niu等[7]開發了一些混合方法來提高排序學習方法的效果和效率,他們指出排序應是一個top-k的問題,并建立了一個完整的top-k排序框架,提出了若干種Pointwise、Pairwise和Listwise的混合排序學習方法,還闡述了如何獲得高效可靠的top-k標注數據,如何設計有效的top-k排序學習模型,對排序結果采用何種評價準則進行可靠地評價等.
還有一些研究排序學習相關問題的工作.Zhou等[64]利用輔助數據進行排序學習.Macdonald等[65]針對不同信息需求類型,不同排序學習方法和不同排序學習語料庫,全面調研了如何最佳地部署排序學習以獲取有效的排序模型.Lai等[66]通過一個有效的Primal-Dual算法解決稀疏排序學習問題.Lai等[67]為排序學習提出了一種新的特征選擇方法.Ma等[68]為排序學習提出了一種新穎的訓練查詢選擇方法.Wang等[69]研究了個性化搜索中具有選擇偏見的排序學習問題,在排序學習框架下如何利用稀疏的點擊數據.Wu等[70]提出了一種從Listwise訓練數據中學習非線性排序模型的分而訓練的方法.Joachims等[71]利用有偏反饋數據提出了無偏排序學習.Calumby等[72]評論了交互式信息檢索系統中交互式排序學習相關方面,主要集中在概述、最新進展、重要挑戰和有前景的研究方向.
表2總結了一些典型排序學習方法所屬類別.從表2可以看出,同一排序學習方法,從不同角度看待,分別屬于不同類型的排序學習方法,它們之間的關系是交叉重疊的.依據不同角度,排序學習可分為不同的種類,如若按需求場景對排序學習進行分類,則可分為有效性排序學習、魯棒性排序學習、多樣性排序學習、可信性排序學習、時效性排序學習、個性化排序學習和多目標排序學習等方法.若按照所轉化的問題不同,可分為基于分類、基于回歸、基于序數回歸、基于凸優化和基于多目標等的排序學習方法.盡管角度不同,分類不同,但設計排序學習方法的重難點問題仍在于如何構建損失函數(優化目標)和如何對損失函數(優化目標)進行學習以產生性能優良的排序模型.
3 排序學習數據集
目前已有公開的基準排序學習數據集主要包括:LETOR、MSLR-WEB10K 和 MSLRWEB30K、Yahoo! learning to rank challenge set、Yandex internet mathematics 2009、WCL2R以及Istella LETOR和Istella-S LETOR等.
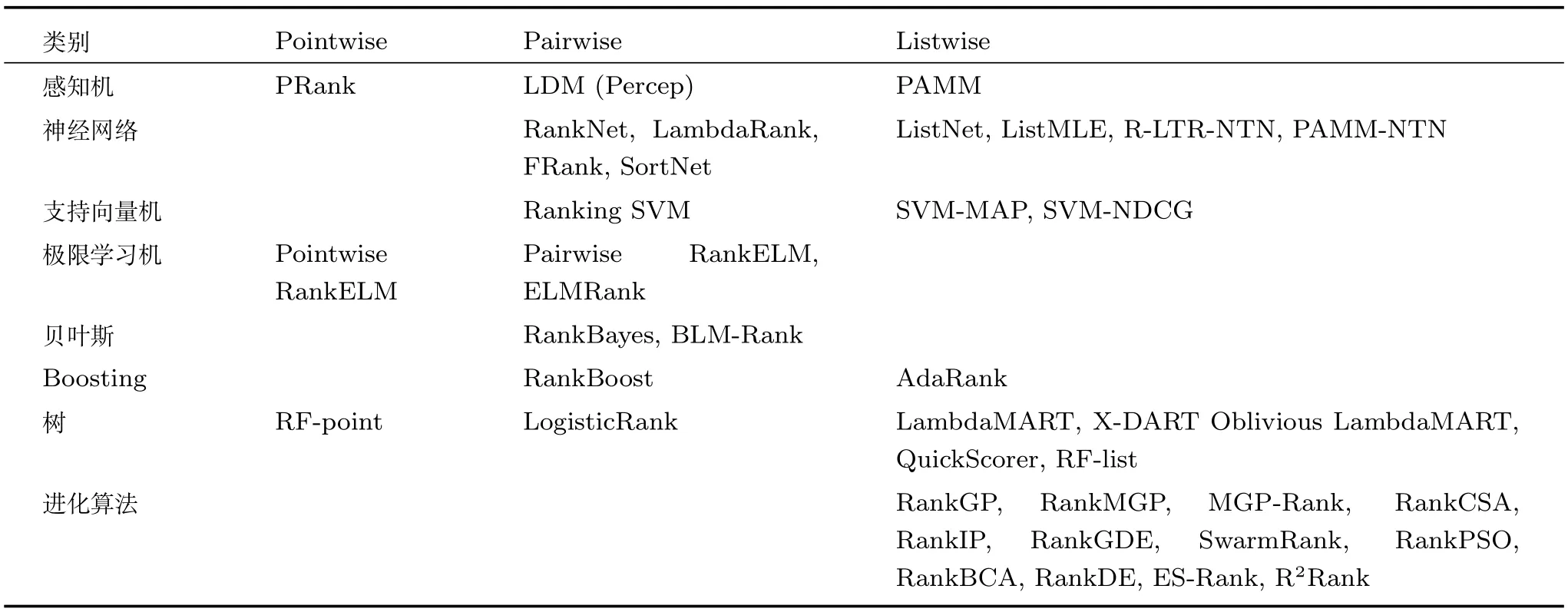
表2 排序學習方法類別及實例Table 2 Categories and instances of the learning to rank approaches
LETOR1https://research.microsoft.com/en-us/um/beijing/projects/letor是由微軟亞洲研究院開發的小規模排序學習數據集,于2008年和2009年分別發布了LETOR3.0和LETOR4.0數據集.LETOR3.0是OHSUMED和Gov中的一些數據集,如HP2003和TD2004等;LETOR4.0新發布了兩個稍較大的數據集MQ2007和MQ2008,提供了4種排序設置的數據集:監督排序、半監督排序、排序聚合、列表排序,則總共包括了8個數據集.Qin等[73]對排序學習數據集LETOR進行了詳細的描述,包括如何選擇文檔語料和查詢集,如何對文檔進行采樣,如何提取排序學習特征和元信息以及如何劃分數據集等.
MSLR-WEB10K和MSLR-WEB30K2https://www.microsoft.com/en-us/research/project/mslr/是由微軟亞洲研究院于2010年開發的兩個相對較大規模的排序學習數據集.MSLR-WEB30K是規模較大、且公共可利用的排序學習數據集,它包含了3萬多個查詢和300多萬個文檔,具有100多維排序特征.MSLR-WEB10K是從MSLR-WEB30K中隨機采樣的一個子數據集,它包含1萬個查詢和100多萬個文檔.每個排序學習數據集都包括從查詢–文檔對中提取的排序特征向量以及相關性判斷標注,相關性判斷標注是從微軟的商業Web搜索引擎Bing的一個檢索標簽集中獲得的.每個數據集被分成查詢數量約相等的5個部分以進行5折(folds)交叉驗證.在每個數據文件中,包含若干條記錄,每條記錄代表一個查詢–文檔對,它包含查詢與文檔的相關性程度、查詢編號以及表征查詢–文檔對的136維排序特征.
Yahoo!learning to rank challenge set3http://webscope.sandbox.yahoo.com/catalog.php?datatype=c是2010年舉行的Yahoo!排序學習挑戰賽所采用的排序學習數據集,包含Yahoo!learning to rank challenge set 1和Yahoo!learning to rank challenge set 2.Chapelle等[13]詳細介紹了該數據集的構建,包含查詢、文檔和相關性等級標注的收集,但沒有揭露這些查詢、URLs和排序特征的描述,僅僅提供了特征值.
Yandex internet mathematics 2009數據集4http://imat2009.yandex.ru/en/datasets是由俄羅斯的商業Web搜索引擎Yandex所發布的用于“the Yandex internet mathematics competition”的基于機器學習的排序競賽的排序學習數據集,這些數據由Yandex評估員將查詢–文檔對的特征向量和相關性等級標注都用實數來表示以用于學習和測試.同Yahoo!learning to rank challenge數據集一樣,不包含原始查詢和原始文檔的URLs,并且也不能揭示特征的語義信息.
WCL2R5http://www.latin.dcc.ufmg.br/collections/wcl2r是由米納斯吉拉斯聯邦大學等單位于2010年開發的具有點擊特征數據的用于排序學習研究的基準數據集,它是從一個現實生活的搜索引擎TodoCL日志中提取的點擊數據等顯著性特征組成的排序學習數據集.Alcntara等[74]對WCL2R 排序學習數據集提供了詳細的描述,包括如何獲取語料、查詢和相關性標注,如何構建可學習的數據特征和如何劃分數據集等.
Istella LETOR和Istella-S LETOR6http://quickrank.isti.cnr.it/istella-dataset/是由意大利ISTI-CNR的Istella團隊等于2016年開發的兩個較大規模的、特別適用于求解排序學習問題的有關效率和可擴展性的大規模實驗的排序學習數據集.Istella LETOR是目前規模最大、且公共可利用的排序學習數據集,按80%、20%的模式劃分成訓練集和測試集;Istella-S LETOR是對Istella LETOR中每個查詢平均采樣約103個樣本的無關對所形成的一個相對較小的排序學習數據集,按60%、20%、20%的模式劃分成訓練集、驗證集和測試集.
表3從查詢個數、文檔個數、特征個數、相關性等級標注和來源這5個方面總結了各種排序學習數據集的相關信息.從表3中的數據來看,小規模排序學習數據集偏多,查詢、文檔和特征個數整體都相對較小,缺乏大規模排序學習數據集.
4 排序學習方法應用
對排序學習的研究已不僅限于理論、方法和數據集方面,它正被越來越多地應用于信息檢索等領域中解決實際的排序問題.排序是很多實際應用所面臨的核心問題,如Web搜索、推薦系統、微博排序、多媒體檢索、專家發現、機器翻譯、問答系統、計算廣告學、摘要提取、查詢擴展和重寫及建議、生物醫學信息學等.
4.1 Web搜索
Web搜索是排序學習方法最早也是目前最成功的實際應用之一.研究提取查詢–文檔的哪些排序特征以及如何結合排序學習方法訓練排序模型以提高用戶對Web搜索的結果排序的滿意度,成為基于排序學習的Web搜索的主要任務.
很多知名的互聯網公司如 Bing、Yandex、Yahoo、百度和搜狗等搜索引擎,都依賴于排序學習方法為用戶提供高質量的搜索結果,如排序學習方法RankNet[19]已應用于微軟的搜索引擎Bing當中以對Web搜索結果進行優化排序,排序學習方法LogisticRank[8]已應用于雅虎搜索引擎中優化搜索結果的排序.Zhang等[75]在網絡搜索實際場景中實證研究了包括線性回歸、RankBoost、ListNet、ListMLE 和SVM-MAP這5個代表性的排序學習方法的有效性.Macdonald等[76]為Web搜索研究了排序學習模型的可遷移性.Kang等[77]基于使用成對偏好模型的集成的排序學習模型,對Web搜索中的關聯實體進行實體排序.
4.2 推薦系統
將排序學習方法應用于推薦系統中主要需解決兩大關鍵問題:1)挖掘用戶和物品(對象)的哪些排序特征?2)運用排序學習方法如何整合這些特征,構建更加貼合用戶需求的推薦模型,以提高推薦系統的性能和用戶滿意度?
Karatzoglou等[78]闡述了不同類別的排序學習方法的關鍵思想如何應用到具體的協同過濾方法中.Sun等[79]將排序學習方法RankSVM應用于推薦系統中,為用戶產生物品的推薦列表.Yao等[80]為物品推薦應用排序學習技術,將用戶間的社交信息融入Listwise排序學習模型的訓練中以改進物品排序列表的質量.Canuto等[81]應用排序學習技術自動地學習標簽排序函數,綜合比較了8種不同排序學習方法(包括List-Net、RankSVM、RankBoost、AdaRank、多重加法回歸樹MART、LambdaMART、隨機森林和遺傳算法)融入標簽推薦中的效果.Ifada等[82]針對基于標簽的項目推薦系統,開發了一種新穎的排序學習方法Go-Rank以直接優化等級平均精度GAP,從而產生一個推薦項目的最優化列表.黃震華等[83]對近些年基于排序學習的推薦算法的研究進展進行了綜述,對其問題定義、關鍵技術、效用評價、應用進展等進行概括、比較和分析,并對基于排序學習的推薦算法的未來發展趨勢進行了探討和展望.
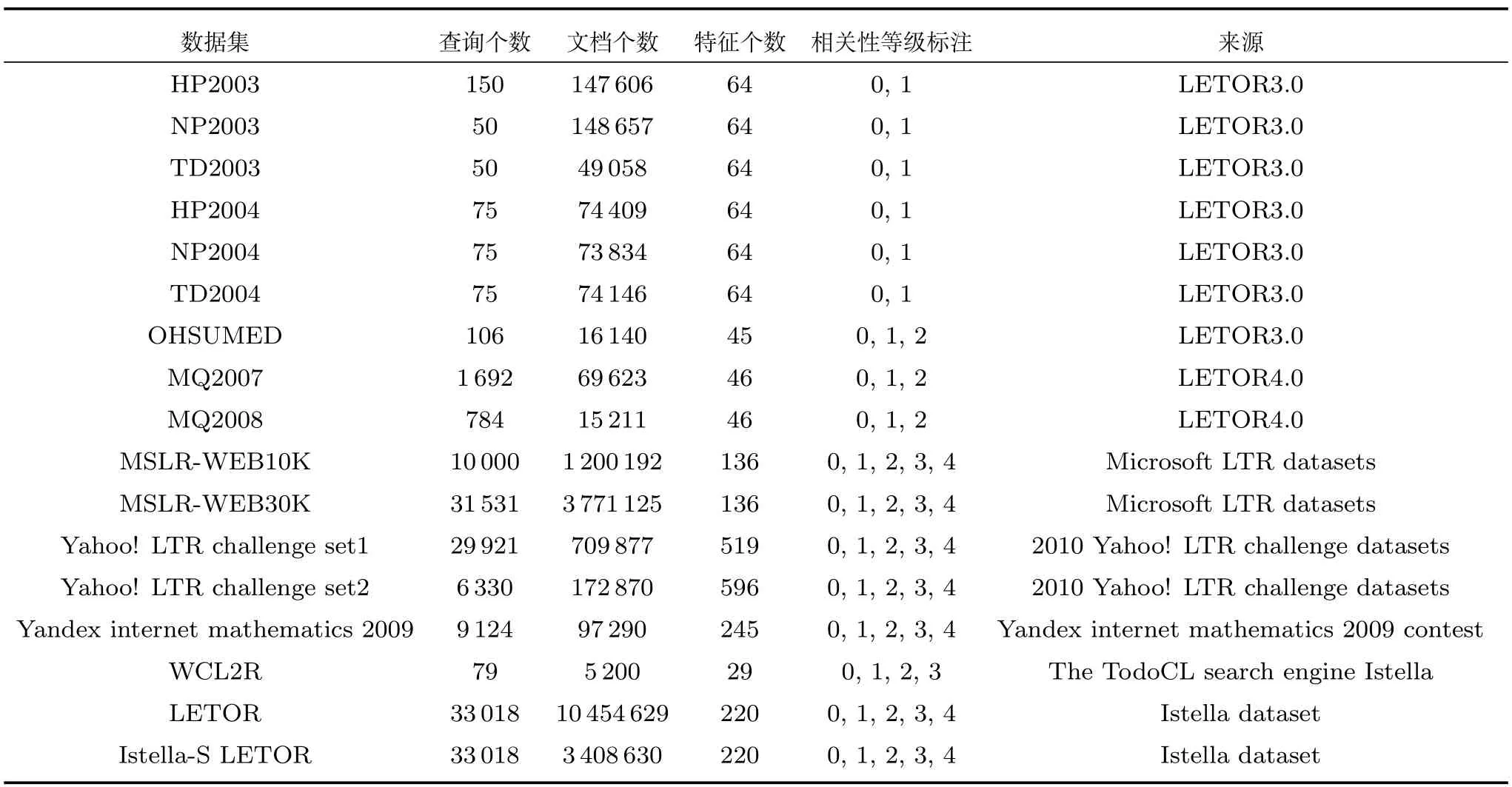
表3 排序學習數據集Table 3 Datasets of learning to rank
4.3 微博排序
隨著微博用戶的劇增和博文數量的指數級增長,越來越多的排序學習方法應用于解決微博的排序問題.Berendsen等[84]研究了為微博搜索而創建偽測試集的方法,利用排序學習技術,使用偽測試集作為訓練集去訓練和調節微博排序器.Dong等[85]使用具有Freshness特征的Twitter數據,利用排序學習技術(梯度提升決策樹)去學習排序函數以用于改進Recency排序.Duan等[86]提取Tweet的內容相關性特征、Tweet用戶帳號權威性特征和Tweet的特定特征,使用排序學習方法RankSVM學習排序模型以對微博搜索結果進行排序.
應用排序學習方法解決微博排序問題取得了較好的效果,但仍存在一些難點問題:1)由于微博數據的增量變化,要求能增量地提取微博排序特征以增量構建多維復合特征集,這就要求排序學習方法能支持微博數據集的增量學習;2)由于微博用戶和信息數量過大以及各自的動態變化,這就要求排序學習方法能支持排序模型的動態學習.而現有應用于微博排序的的排序學習方法都缺乏對數據和模型的增量和動態性支持,這是未來需要突破的重難點.
4.4 多媒體檢索
Chelaru等[87]利用排序學習技術研究了社交特征對視頻檢索有效性的影響.Yu等[88]利用排序學習技術得到一個用于圖像檢索的排序模型,該模型共同考慮了圖像檢索中用戶的視覺特征和點擊特征.Zhao等[89]運用深度神經網絡和潛在的結構化SVM,提出了一種稱為深度潛在結構化SVM的新型聯合排序學習方法以進行多媒體檢索.Karaoglu等[90]使用排序學習方法在計算機視覺中組合不同目標檢測器.Wang等[91]將行人再識別任務建模為一個Listwise排序學習問題,集成卷積神經網絡學習具有自適應Listwise約束的深度特征.
4.5 專家發現
Volkovs等[92]運用排序學習方法聚合專家偏好.Moreira等[93]探索了排序學習方法和排序聚合方法對學術出版物的數字化圖書館中專家發現任務中的應用.Zheng等[94]從文本內容、專家社區中帶有引用模式的圖形結構和有關專家的配置文件信息中,探討了使用排序學習方法組合專家們的多種評估以發現專家.Chen等[95]融合多特征,基于ListNet排序學習方法設計了專家列表排序方法以發現專家.
4.6 機器翻譯
Delpech等[96]提出了一種從語料庫中,為特定領域的雙語詞典提取新的組合翻譯方法,并采用排序學習技術為候選翻譯結果進行排序.Li等[97]將Listwise排序學習方法應用于機器翻譯的自動評估.Lee等[98]將排序學習方法應用于英語–韓語機器翻譯中解決謂詞參數的重排序.Farzi等[99]使用基于語法的排序學習系統改進統計機器翻譯.
4.7 問答系統
Wu等[100]提出了一種新的基于意圖的語言模型,采用LambdaMART排序學習方法評估該模型參數以提高問答社區中短查詢的搜索相關性.Nguyen等[101]運用Ranking SVM 排序學習方法為重排序問題學習的社區問答競賽進行排序問題學習.Verberne等[102]為問答系統排序答案任務評估了一些排序學習方法,如Ranking SVM 和SVMMAP等.
4.8 計算廣告學
Ciaramita等[103]從機器學習的視角研究了贊助商搜索問題,從點擊數據中在線學習以解決贊助商搜索問題.Tagami等[104]基于排序學習方法,為上下文廣告而提出了一種點擊率預測算法.Karimzadehgan等[105]提出了一種隨機排序學習方法,并應用于上下文廣告中.
4.9 摘要提取
Shen等[106]主要探討怎樣使用支持向量機來訓練以查詢為主的多文檔文摘的特征權重.Zhu等[107]將他們提出的關系排序學習方法應用于基于話題的多文檔摘要任務中.Tran等[108]采用自適應排序學習方法為高影響事件的時間軸摘要進行實體排序以均衡新穎性和顯著性.Tran等[109]提出了一個優化框架,并闡述了使用排序學習方法在該優化框架下如何從網絡新聞事件中自動構建時間軸摘要.
4.10 查詢擴展、重寫和建議
Xu等[110]提出了一個新穎框架以探索使用排序學習方法去優化偽相關性反饋,為查詢擴展比較評估了一些排序學習方法.Lin等[111]基于排序學習方法從社會化標注中進行擴展詞提取,并構造詞排序模型用于社會化標注查詢擴展任務中.Dang等[112]提出使用排序學習方法執行查詢重寫,用僅有的兩個特征重排序通過基于日志的查詢擴展技術所產生的重寫查詢或擴展查詢的列表.Santos等[113]提出了一種用于查詢建議問題的排序學習方法,該方法利用從候選查詢建議的結構化表示中挖掘出的多個排序特征以產生高效的查詢建議.
4.11 生物醫學信息學
Liu等[114]運用排序學習技術,提出了一種廣泛應用于蛋白質遠程同源性檢測以及蛋白質功能和結構預測的計算方法ProtDec-LTR,該方法在監督學習框架下組合了三種最先進的排序預測器以訓練最優排序模型.他們[115]還將基于個人配置信息的偽蛋白融入到排序學習算法框架中改進ProtDec-LTR方法以提高預測性能.Shang等[116]將自動摘要提取看作為一個排序問題,應用排序學習方法自動提取基因摘要.Jing等[117]基于排序學習算法開發了一個軟件MQAPRank以用于改進全球蛋白質模型質量評價.
4.12 其他應用
Saleem等[118]使用排序學習方法進行基于個性化決策策略的Web服務選擇.Deveaud等[119]通過使用排序學習方法以自動配置任務算法中的參數.Zhou等[120]將排序學習技術應用于關系實體搜索.Chen等[121]將排序學習技術應用于語義關聯排序.Kong等[122]采用排序學習方法RankBoost和Ranking SVM獲取候選抄襲源文檔以解決抄襲檢測源檢索問題.
由上述歸納可知,排序學習方法已經在不同應用領域中取得了大量的研究成果.概括起來,將排序學習方法用于解決一些實際應用領域中的排序問題時,需要解決兩大難點問題:1)針對實際應用,提取哪些排序特征以更好地表征該應用;2)如何針對實際應用,構建損失函數或優化目標以指導排序學習方法訓練出更優的排序模型.
5 排序學習方法軟件包
近年來,排序學習方法得以迅速發展,并能夠廣泛地運用于眾多的實際應用中解決排序問題,離不開許多精心設計和實現的排序學習方法的開源軟件包.目前常用的排序學習方法軟件包有RankLib、QuickRank、Lerot、L2RLab、ESRank、LTR、MLR-master和SVMrank等.
RankLib7https://sourceforge.net/p/lemur/code/HEAD/tree/RankLib/是一個優秀的基于Java語言的排序學習方法庫的開源實現,隸屬于美國的馬薩諸塞大學和卡內基梅隆大學合作項目Lemur,該款軟件被廣泛采用.RankLib是由馬薩諸塞大學的研究者vdang開發的一個排序學習方法軟件包,當前已經實現了 8種流行的方法,包括 MART、RankNet、RankBoost、AdaRank、ListNet、Coordinate ascent、LambdaMART 和Random forests.它實現了許多信息檢索的評價標準,同時還提供了多種執行方式去實施評價.
QuickRank8https://github.com/hpclab/quickrank,9http://quickrank.isti.cnr.it是一款高性能排序學習工具箱,提供了一些排序學習方法的C++多線程實現,能將基于學習樹的模型翻譯為可用于快速評分文檔的高效的C++源代碼,注重于效率方面的設計和開發.目前,在該套裝工具箱中實現了GBRT、LamdaMART、Oblivious GBRT/LamdaMART、Coordinate ascent、Line search、RankBoost、CLEAVER、X-CLEAVER 和X-DART等方法.QuickRank還引入了前期和后期學習的優化器理念,即排序學習方法可在執行訓練階段之前或之后被執行.優化器可以根據其定義處理數據集或模型,可以通過設置相應的選項同訓練階段一起在流水線上執行,或作為一個獨立的進程工作在以前受過訓練的模型或數據集上.目前,在QuickRank中已實現了CLEAVER優化器,該優化器在后期學習中剪枝一個集成模型以提高優化器的效率而不會妨礙其有效性.
Lerot10https://bitbucket.org/ilps/lerot軟件包是由微軟劍橋研究院Katja Hofmann和荷蘭的阿姆斯特丹大學Anne Schuth等為信息檢索而開發的一個在線排序學習方法框架,該框架是為在線排序學習方法運行實驗而設計.Lerot提供了一個對在線排序學習方法進行評估和實驗的解決方案,是一個開源的軟件,其代碼易于加入新的在線排序學習方法和/或反饋機制而被擴展.目前,包括了一些在線學習算法、交互方法和一套完整的評價方法,并已有在線排序學習方法作為插件集成到搜索引擎solr中.
LTR11https://github.com/yaschool/ltr,12http://yaschool.github.io/ltr/index.html軟件包是一個用于解決機器學習問題的開源C++算法庫,包括排序、分類和回歸問題.LTR的主要思想是源代碼的易于擴展性和泛化性,通過廣泛使用C++模板和多態性而實現的.在當前的LTR算法庫中,實現了以下算法:分類 (kNN、Naive Bayes、QDA、Fisher LDA)、回歸(LSM)、排序(RankGP 和Linear ranker)、集成(Boosting、Bagging和RSM).用戶可以在該軟件包中添加自己編寫的代碼以執行學習和測試,也可以使用該軟件包中帶有人工可讀的配置文件的控制臺應用程序.每一個訓練有素的排序器/分類器/回歸器可以在C++代碼中被序列化,以便不依賴于LTR算法庫而被使用在其他項目上.
L2RLab[123]是為排序學習所開發的一個集成的實驗環境,它集成了新排序學習模型的開發、評估、比較和分析性能以輔助排序學習研究者開展實驗.L2RLab軟件包主要由兩大模塊構成:可視化應用程序界面和一個有助于添加由研究人員所開發的新算法和性能度量指標的框架,其主要功能包括數據集的預處理、模型的訓練和測試、模型的分析和比較.L2RLab易于添加新的排序學習方法,提供了易于使用的接口以避免實驗應用的重新編碼,其系統接口允許用戶去設置和控制實驗執行,執行的結果可以數字和圖形的可視化方式展現.目前,L2RLab中包含RankPSO等很少量的排序學習方法.
ESRank13http://www.cs.nott.ac.uk/psxoi/ESRank.zip是英國諾丁漢大學和米尼亞大學的Osman Ali Sadek Ibrahim等實現的基于進化策略的排序學習方法ES-Rank的JAR包.
MLR-master14https://github.com/bmcfee/mlr/軟件包由美國加利福尼亞大學的Brian McFee和Daryl Lim開發的一款排序學習方法的工具,包括Metric learning to rank(MLR)和Robust MLR的代碼.該軟件包基于結構化SVM框架,支持不同排序評價準則,如AUC,Precision@k,MRR,MAP和NDCG.
SVMrank15http://www.cs.cornell.edu/People/tj/svm light/svmrank.html#References是為有效地訓練排序SVM 的結構化SVM 的一個實例,由美國康乃爾大學的Thorsten Joachims在具有GNU編譯器套件(GCC)的Linux操作系統上開發實現的一個早期的排序學習方法Ranking SVM 的開源軟件.后期有研究者開發實現了該方法的C++版16http://dlib.net/svmrankex.cpp.html和Python版17http://dlib.net/svm rank.py.html的代碼.
表4從開發語言、特點和來源這3個方面歸納了各種排序學習方法軟件包的相關信息.

表4 排序學習方法軟件包Table 4 Software packages of the learning to rank approaches
6 排序學習發展趨勢
排序學習不僅在學術界得到了積極的研究,而且在工業界也取得了廣泛的發展.在排序學習理論與方法方面,研究人員豐富了機器學習的相關理論并提出了多種不同的排序學習方法;在排序學習實際產品應用方面,已經成為各個互聯網搜索引擎和推薦系統等應用中網頁、物品等對象排序的核心技術,很多知名的互聯網公司如Bing、Yandex、Yahoo、百度和搜狗等搜索引擎和大型電子商務平臺如eBay、亞馬遜、淘寶天貓、1號店、國美等,在很大程度上都依賴于排序學習方法為用戶提供高質量的搜索、推薦和廣告等排序結果.盡管,排序學習已取得了較多的成果和較大的成功,但在排序學習領域中仍還有許多相關的問題尚未完全探討,下面分別從排序學習的理論、方法、應用、需求場景、數據集和評價指標等方面總結在未來值得做進一步研究的排序學習問題.
6.1 排序學習理論研究
Chapelle等[124]指出:通過基準實驗,許多排序學習方法已被證明是有效的.然而,因為小規模測試數據和訓練,有時基準實驗是不可靠的.在這種情況下,排序學習理論是必要的,以保證在無限未知的數據訓練中排序學習方法的性能.他還指出排序學習理論已經有了一些嘗試,但仍還有很大的發展空間去探索以解決以下難點問題:1)關于數據生成(例如,查詢和文檔)的一個合理假設;2)關于代理損失函數的一個泛化界;3)代理損失函數和排序度量標準之間的關系;4)當文檔的數量接近于無限時,排序度量標準的極限的存在性等.
6.2 排序學習方法展望
隨著機器學習技術的不斷發展和改進,排序學習方法也需不斷跟進和完善.基于一些新興的智能優化算法、深度學習或其他新型機器學習技術,在未來可嘗試運用它們開發出新的排序學習方法以追求更高的效果和效率.
6.2.1 基于新興或混合型智能優化算法的排序學習
當前,雖已有較多的研究成果運用進化算法去設計排序學習方法,但運用新近開發的智能優化算法設計排序學習方法的研究仍還較少.近年來不斷涌現出了一些新興的智能優化算法,如煙花算法、螢火蟲算法、布谷鳥搜索算法、隨機蛙跳算法、猴子搜索算法、蝙蝠算法、花朵授粉算法、細菌覓食優化算法、稻田算法和智能水滴算法等,如何結合排序學習問題,基于這些新興的智能優化算法或與已有的智能優化算法融合成更為高效的新型混合智能優化算法去設計排序學習方法,從而更高效地解決信息檢索中的排序學習問題,是一個值得去開辟和嘗試的研究方向.
6.2.2 基于深度學習的排序學習
深度學習是近年來最受矚目的技術熱點之一,它已經成為了工業界解決眾多應用問題的神器.目前,深度學習的主要模型有卷積神經網絡、遞歸神經網絡、深度信念網絡、限制玻爾茲曼機、自動編碼器、長短時記憶網絡和生成式對抗網絡[125]等.還有一些蓄勢待發的基于深度學習與其他方法結合的混合學習方法正在引領前沿,如深度強化學習、深度遷移學習、深度貝葉斯學習和深度森林等.
國際學術界公認的“排序學習”領域的代表人物Li等[126]指出深度學習的一些基本技術(如單詞嵌入、遞歸神經網絡和卷積神經網絡)已經應用于圖像和語音領域、自然語言處理和信息檢索領域,如圖像搜索、機器翻譯和知識問答等.最近有些研究者對深度學習在自然語言處理[127]、控制領域[128]、人體行為識別[129]、視頻目標跟蹤[130]等領域進行了綜述.Wang等[131]為Listwise排序學習方法提出了一種基于注意力的深層神經網絡,可更好地將查詢和搜索結果的不同嵌入(如卷積神經網絡或word2vec模型)與基于注意力的機制進行融合.Severyn等[132]用卷積深神經網絡對短文本進行排序學習.程學旗等[133]指出利用深度學習方法自動學習多樣性排序特征和樣本之間的依賴關系也是一個非常有前景的方向.
這些研究為深度學習技術運用于排序學習問題中開辟了思路,期待開發出更多基于深度學習的排序學習方法以增強大規模排序學習的效果和效率.
6.2.3 基于其他新型機器學習技術的排序學習
近年來,隨著云計算技術和大數據的發展,互聯網數據量的劇增和機器計算能力的提高,人工智能再次飛速發展,新型機器學習技術和新的機器學習理論框架也不斷被提出,比如在線機器學習、對偶學習、對抗學習、指示學習、多視圖學習、終身學習、元學習和平行學習[134]等.基于這些新型的機器學習技術和理論框架,結合排序學習問題的特點,開發新型排序學習方法,提高排序學習方法的效果和效率,也許有些新的排序學習方法還是應對大數據時代搜索引擎和推薦系統等實際應用中排序問題的有效途徑.
設計排序學習方法關鍵在于依據排序學習問題所轉化為分類、回歸、序數回歸和凸優化等問題,如何定義輸入輸出空間、假設空間、損失函數或優化目標.而設計新的排序學習方法的難點問題是如何依據排序學習問題的特點,結合新的機器學習技術,設計出新穎高效的排序學習方法.
6.3 排序學習方法應用領域的拓展及不同排序學習方法的應用檢驗
目前,有些排序學習方法已經成功應用于較多領域解決相應的一些排序問題,如Web搜索和推薦系統等,渴望能拓展到更多的應用領域中,如資源配置、模式識別等.對于需要排序的應用問題,只要能提取出若干排序特征以構建排序學習數據集,都可嘗試運用排序學習方法去解決.針對實際應用問題,提取什么樣的排序特征以及如何合理度量排序特征設計損失函數或優化目標是需要解決的難點問題.
雖然排序學習方法已經成功地應用于如Bing,雅虎搜索、百度和Yandex等搜索引擎公司和如eBay、淘寶天貓、1號店、美團和國美等大型電子商務平臺,但真正用于具體的排序系統中的排序學習方法卻很少,主要是RankNet和LambdaMART等,大部分排序學習方法并沒有在實際的排序應用場景中得到相應檢驗,期待更多真實的搜索引擎或推薦系統等應用中的排序系統將更多的排序學習方法進行性能檢驗,并將性能最優秀的排序學習方法融入其中.
6.4 排序學習需求場景的探討
隨著互聯網上千差萬別的網民涌現、排序學習應用領域的不斷擴展,所需求的排序場景也趨于多樣化,不再只是僅僅追求排序模型的有效性,對排序模型的魯棒性、多樣性和可信性等以及排序學習方法的自適應性和高效率等,在一些實際的應用場景中也是非常重要的.為此,不同排序場景需求的排序學習是未來迫切需要探討、解決的問題.
6.4.1 魯棒性排序學習
當前,排序學習方法方面,已有的絕大部分工作中,是去比較和評估多個排序函數,基于一些信息檢索度量指標(如NDCG、ERR等)選擇一個最佳的排序函數,通過制定先進的排序功能和/或開發復雜的排序學習方法提高檢索結果的平均有效性.然而,相對于簡單的基準,這些方法通常會提高搜索結果的平均性能,但往往忽視了魯棒性的重要問題[6].而對于一個商業搜索引擎公司,其真實的場景是更復雜的:伴隨著更多的訓練數據、新近開發的排序特征、或更神奇的排序算法,需要周期性地更新和改進排序函數,但排序結果不應顯著性地發生改變.如此需求將對排序學習領域的魯棒性帶來新的挑戰[124]:1)如何度量排序模型的魯棒性?2)如何學習一個強魯棒性的排序模型?
研究者們對排序模型的魯棒性問題進行了積極的探索.TREC 2013 web track和TREC 2014 web track都為Web評價算法提出了一個風險敏感的檢索任務.Wang等[6]討論了排序學習中的魯棒性問題.Din?cer等[135?137]從風險敏感參數加權線性組合、學生t檢驗和卡方統計等理論中提出了一些風險敏感的度量和選擇單/多基準來研究檢索系統的魯棒性.Ding等[138]從噪音數據中進行排序學習.Li等[61]提出了一種風險敏感的魯棒性排序學習方法以均衡有效性和魯棒性.盡管已取得了一些研究成果,但更合理地度量排序模型的魯棒性和更好地學習一個強魯棒性的排序模型是值得進一步作深入探討的研究問題.因此,設計更優秀的魯棒性排序學習方法是一項具有挑戰性的創新工作.
6.4.2 多樣性排序學習
現有排序學習方法主要關注于檢索結果的有效性,大部分缺乏考慮多樣性等質量指標,導致所呈現給用戶的檢索結果較單一,難以滿足用戶的不同信息需求.考慮多樣性質量指標也逐漸成為衡量搜索引擎和推薦系統好壞的重要因素,為此有必要建立符合實際需求的優化目標.考慮多樣性質量指標時,難以合理有效地度量和均衡.這也將帶來新的挑戰:如何度量排序模型的多樣性?如何學習相應的多樣性排序函數?
在排序結果的多樣化方法方面,Liang等[139]提出多元數據融合方法以提升搜索結果的多樣性.Liang等[140]使用監督學習策略解決個性化的搜索結果多樣化問題.Wu等[141]提出了一類支持結果多樣化的數據融合方法.Deng等[142]調研了查詢結果多樣化的復雜性問題.
中科院計算所研究員程學旗團隊在多樣性排序學習方面做出了突出的貢獻.他們考慮排序結果的多樣化,提出了一種通過直接優化任意多樣性評估度量指標學習關系排序模型的新的多樣性排序學習的通用框架[143]和3種多樣性排序學習方法[18,24,144],他們分別采用隨機梯度下降法、感知機和神經張量網絡去學習排序模型,取得了很好的效果.同時,他們團隊[133,145]指出由于搜索結果多樣化任務本身的復雜性,多樣化評價準則本身不可導和不連續,使得直接對其進行優化仍然存在許多有待解決的困難,并指出多樣化是排序學習發展的一個新方向,還面臨很多挑戰,需要不斷探索.
6.4.3 可信性排序學習
互聯網中蘊藏著海量的網頁資源,其中不乏作弊、不可信和惡意網頁(Web spam),其信息良莠不齊,將嚴重影響排序結果的質量.同時,網頁信息的可信與否難以確定、可信與不可信也不好度量.若一個檢索結果中充斥了大量的不可信信息,將增加用戶檢索有用信息的難度,嚴重惡化用戶的檢索體驗,是互聯網信息檢索所面臨的最大挑戰之一.因此,研究可信性排序學習問題,設計可信性度量指標和可信性排序學習方法以訓練可信性排序模型,從而提高排序結果的可信性,對改善用戶體驗具有重要意義.
現有相關工作往往忽略了網頁信息的可信性,已公開發表的考慮可信性質量指標的排序學習問題的研究成果較少,大多是對Web spam進行檢測過濾,即使有的研究考慮到搜索結果的可信性,但大多是將可信性和相關性各質量指標聚合在單個目標中,掩蓋了各單個質量指標的值.針對可信性排序學習問題,所要解決的重難點問題主要是可信和不可信排序特征的提取和度量、排序模型的可信性度量以及高可信排序模型的學習.
6.4.4 多目標排序學習
近年來,為了更進一步提高用戶對信息需求的滿意度,研究人員不僅考慮搜索結果質量的相關性,且更多地關注于排序結果的多樣性、新鮮性等方面,也掀起了一些多目標排序學習方面的研究.Dai等[146]指出監督排序學習方法通常追求高相關性的優化而忽略搜索結果質量的其他方面,如新鮮性和多樣性.他們通過開采混合標注,將多個方面(如新鮮性與相關性)的目標進行組合以產生總的質量,使用排序學習方法RankSVM去優化模型參數.Svore等[147]考慮了多個度量策略作為訓練目標,提供了在多個被分級的度量策略上進行優化的解決方案,將多種度量合并成可以學習的一個單一的梯度度量,采用LambdaMART排序學習方法去優化.Kang等[148]提出了一種在排序學習場景中垂直搜索的多方面(如匹配度、距離、聲譽等)相關性構想.還有如前所指出的魯棒性排序學習、多樣性排序學習和可信性排序學習,都可考慮轉化為多目標排序學習.
上述研究雖然在排序學習方法中同時考慮了相關性和其他多方面質量指標,但其優化的目標僅為一個融合多方面質量指標的目標函數,這帶來了如何為各質量指標合理設置權重的難點問題,在用戶缺乏先驗知識的情況下難以處理.因此,為有效地均衡相關性和多方面質量指標,需尋求可同時優化多個獨立的目標函數的多目標排序學習方法,這也是一項具有挑戰性的創新工作.設計多目標排序學習方法的難點在于排序模型的多個優化目標函數的合理設計和均衡以及排序模型的效果和排序學習的效率之間的均衡.
6.4.5 自適應排序學習
現有主流的檢索系統通常只有一個通用的排序特征集和從這些特征集中所學到的或經驗得到的相同排序模型.不同的查詢詞在同一排序模型下的性能表現大體上也是不同的,采用同一排序模型是難以保證為所有的用戶和查詢都能較好的工作,缺少針對不同場景的不同排序模型.為此,可針對不同場景(如凸顯魯棒性、多樣性、可信性和馬太效應等)應用不同排序特征去訓練相應排序模型,依據查詢詞所屬場景選擇不同的排序模型.那么,如何使檢索信息匹配檢索場景,以感知不同的應用場景而自適應地調用不同的排序模型?為此,需提出基于多維度質量指標的自適應排序學習以感知不同需求場景而自適應地調用不同場景的排序模型.如何正確地識別需求場景,并能自適應地調用對應場景的排序模型是需解決的難點問題.期待出現更多應用場景、更炫的自適應排序學習方法,推動排序學習研究向實用化邁進,以應對更復雜的真實搜索、推薦場景,以進一步提高排序結果質量和用戶滿意度.
6.4.6 大數據排序學習
隨著互聯網大數據的快速發展,可構建的排序學習大數據越來越大,其類型也越來越多.現有排序學習方法絕大部分存在高度迭代,面對大數據,如此排序學習方法訓練排序模型時間較長,內存消耗較大,效率低下,尤其是在需要實時處理數據的領域,問題尤為突出.為了維持在大數據上的排序速度,傳統的以效果為中心的排序學習方法需要額外的硬件和能耗,所付出的代價昂貴[149].為了取得排序的效果和效率的持續改進,在保證一定排序效果的前提下,并行化排序學習方法以加快排序模型的訓練速度,可提高排序學習方法的效率.Wang等[149]針對大數據環境,提出了一個共同優化有效性(相關性)和效率(速度)的排序學習的統一框架和能捕獲這兩個競爭目標間均衡的新度量標準.Cao等[150]提出了一種大數據環境下的分布式排序學習方法.
由于現有排序學習方法大多是基于內存的,無法將大數據一次性裝載進計算機內存,故需提出新型數據并行、模型并行的排序學習方法以適應大數據處理的需求.在大數據時代,大數據排序學習是未來的發展趨勢之一,其關鍵在于突破內存限制,設計能快速有效均衡效果和效率的大數據排序學習方法.
6.4.7 大規模分布式并行排序學習
現有大部分排序學習方法是以串行方式訓練排序模型的,當面對大規模排序學習數據集時,這是很難去保證其學習效率.隨著多核處理器、云計算技術、并行編程模型等的快速發展,為開發大規模分布式并行排序學習方法提供了一條可行之道.可將適用于處理大規模數據的機器學習方法,如感知機、神經網絡、支持向量機、梯度提升決策樹、隨機森林和進化算法等在并行編程模型如MapReduce和Spark等框架下,將它們并行化,設計分布式并行排序學習方法.目前,研究者們已開發了少量的分布式并行排序學習方法.Sculley[151]關注于在大規模數據集上進行學習的排序學習方法.通過從一個隱式的Pairwise擴展索引中采樣樣本對,并應用有效的隨機梯度下降學習器去學習排序模型,從而提高大規模排序學習的效率.Shukla等[152]在Spark分布式集群計算系統上并行化ListNet排序學習方法.Wang等[59]提出了一種基于協同進化算法的并行排序學習框架.Tian等[60]設計了基于并行B細胞算法的排序學習方法以改進收斂率和運行速度,提高最優解的質量.
再者,由于現實世界中待排序樣本大量涌現,因此算法的可擴展性成為更加棘手的問題,目前隨機、在線等優化策略已經在解決大規模分類問題中表現出優越性,如何結合這些技術并且有針對性地設計大規模分布式并行排序學習方法也將是我們今后的研究方向,其思路可從數據并行、算法并行和數據算法混合并行三方面去開展該研究.
6.4.8 在線增量式排序學習
傳統上,排序學習方法以批處理模式在一個由查詢和文檔對以及與它們相關聯的手動創建的相關性標注所構建的完整數據集上被訓練,是一種離線方式.這種方式有許多缺點,且在許多情況下是不切實際的.首先,創建如此數據集是昂貴的,因此對于較小的搜索引擎,比如小的網絡存儲搜索引擎,是不可行的.其次,對于專家標注文檔相關性,如在個性化搜索的情況下,它也許是不可能的.再者,文檔對查詢的相關性會隨著時間的推移而改變,如在新聞搜索引擎中[153].因此,許多在線排序學習方法開發出來以解決此問題.
Suhara等[154]提出了在線排序學習方法.Hofmann等[155]給出了如何平衡信息檢索中Listwise和Pairwise在線排序學習的勘探和開采.Chen等[156]提出了在線排序學習方法,并比較了在線排序學習的絕對反饋和相對反饋方法.Grotov等[153]總結了在線排序學習所使用的一些算法,如Bandit算法、決斗強盜梯度下降(Dueling bandit gradient descent,DBGD)等.Schuth等[157]擴展了DBGD為概率多級梯度下降,提出了一種多級梯度下降的快速在線排序學習方法.Zhao等[10]通過構建魯棒的梯度探索方向,提出了兩種方法改進在線排序學習方法.
通常,在線排序學習方法是從用戶的交互數據中而不是從已標注的數據集中學習,基于用戶實時點擊反饋數據進行增量學習,它能快速學習原始排序列表的前端的最佳重排序.增量學習強調如何基于環境而行動,以取得最大化的預期利益.Keyhanipour等[158]提出了一種在增量學習框架下具有點擊特征的排序學習方法.盡管現已開發出一些在線排序學習方法,但由于用戶交互數據具有偏見和噪音,如何盡可能地消除偏見和噪音的影響,開發更優秀的在線增量式排序學習方法以快速可靠地從用戶交互數據中學習仍是一個主要挑戰.
6.4.9 基于用戶行為的個性化排序學習
傳統搜索引擎對不同用戶的查詢所返回的搜索結果的排序是相同的,然而有時不同用戶對相同查詢會有不同的意圖,這就要求排序學習方法能適應個性化搜索和推薦等服務,能針對不同用戶的查詢和信息需求,呈現出可滿足不同用戶個性化偏好的排序結果.為此,可將個人信息和用戶行為等融入到排序學習中,設計基于用戶行為的個性化排序學習方法,最終達到個性化排序的要求,這是一個有挑戰的任務,其關鍵是要解決如何正確地從用戶行為中識別用戶真實意圖以及如何融入用戶行為設計感知用戶意圖的個性化排序學習方法這兩個重點問題.
6.4.10 其他需求場景
時效性排序學習、交互式排序學習、上下文排序學習、多任務排序學習、稀疏排序學習、關聯排序學習、語義感知的排序學習、地理位置感知的排序學習等都值得作進一步的研究.
總之,設計不同需求場景的排序學習方法的難點在于如何將不同需求場景的實際情況與構建的損失函數或優化目標有機融合,從而指導排序學習方法學得一個能滿足需求場景的更優的排序模型.
6.5 大規模排序學習數據集的構建
從表2中總結的排序學習數據集可看出,現有排序學習數據集的查詢和文檔總數并不多,總體規模比較小,最大的數據集也難以滿足網絡大數據的要求,難以全面可靠地反映出排序學習方法的真實性能.為了更準確可靠地評價排序學習方法的整體性能和提高排序學習方法在實際應用場景中的性能,應在大規模的排序學習數據集上進行訓練和測試.更大的數據量、更豐富的數據多樣性,可以保障算法獲得足夠多的訓練,讓它們變得更加智能.為此,需盡可能開采互聯網上廣泛的信息資源,使用更多數量和種類的查詢,更多數量和種類的網頁信息,提取更豐富的排序特征(如多樣性、時效性、可信性特征,語義特征,基于點擊、瀏覽、Session等用戶行為特征,社交關系特征等)以及未標簽的數據去構建大規模排序學習數據集.基于大規模排序學習數據集訓練準確可靠的排序模型,為測試未知數據的排序提供保障.目前,如此大規模排序學習數據集仍還非常稀缺,其難點在于如何從大規模查詢–文檔對中提取豐富多樣的排序特征和設計新的排序特征以更好地描述數據集,以及如何最小化噪音數據.解決好這些難點問題,有利于構建高質量的排序學習數據集,從而可更有效地構建高效的排序模型.因此,構建大規模排序學習數據集仍是一個開放問題.
6.6 排序學習評價指標
排序學習性能的評價是一個非常重要的問題,它是衡量各種排序學習方法優劣的量化指標.在信息檢索領域,傳統評價指標主要有精度(P)、平均精度(Average precision,AP)、平均精度均值(MAP)、召回率(R)、調和平均值F指標(F-measure)、排序倒數(Reciprocal rank,RR)、平均排序倒數(Mean reciprocal rank,MRR)、期望排序倒數(ERR)、排序偏好精度(Rank biased precision,RBP)、累積增益(Cumulated gain,CG)、折扣累積增益(Discounted cumulated gain,DCG)、理想折扣累積增益(Ideal discounted cumulated gain,IDCG)和歸一化折扣累積增益(NDCG)以及一些意圖感知(Intent aware,IA)的多樣性評價指標,如Precision-IA、MAP-IA、α-NDCG、ERR-IA等.這些信息檢索的評價指標都可用于評價排序學習方法的性能.
隨著排序學習場景需求的增多,需更多新的評價指標來評估排序學習方法的優劣,如可信性排序學習場景需求中就需要評價排序模型的可信性指標,而在馬太效應需求的排序場景中需要能評價排序模型的馬太效應的指標等.為此,我們需針對不同需求場景來設計一些新的評價指標以衡量排序模型的優劣.如何將排序學習的需求場景特性融入評價標準中以設計出能合理有效度量排序模型性能的新評價指標,是一個關鍵難點.
總之,對排序學習的研究,既要注重對排序學習的理論研究,也要注重對排序學習方法和排序學習數據集的研究,還要檢驗和拓寬排序學習方法在實際排序場景中的應用.應加強應用于排序學習中統計學習理論的推導和證明,各種排序學習方法之間的對比和集成,各種排序學習數據集中查詢量、文檔量和特征維數等之間的對比和分析,改進和完善已有的各種排序學習方法和盡可能開發新的具有更強表征力的排序特征,繼續探索和開發更高級的新排序學習方法,使排序學習方法不斷得到豐富和發展,并在實際應用中得到檢驗.
7 結束語
排序學習是信息檢索、機器學習和數據挖掘等領域中的一個重要問題,它在當代搜索引擎和推薦系統等實際應用中占有舉足輕重的地位.本文對排序學習所涉及的較多方面的研究現狀和進展進行了歸納和分析,并詳細探討了排序學習的未來發展趨勢,希望能起到拋磚引玉的作用,能對學術界和工業界的相關研究人員提供有益幫助.期待學術界和工業界的研究者們應用更富有創造性的機器學習算法,更神奇的排序特征,以及更加強大的計算力,開發高效且接地氣的排序學習方法,開創排序學習的一片新天地.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
