卷積神經網絡對SAR目標識別性能分析
2018-11-06 09:46:14,,
雷達科學與技術 2018年5期
關鍵詞:模型
, ,
(海軍航空大學, 山東煙臺 264001)
0 引言
合成孔徑雷達(Synthetic Aperture Radar,SAR)由于具有全天候、全天時和一定的穿透成像能力,可以不受氣候條件對地面及海面目標持續觀測,已經被廣泛應用于戰場偵察和情報獲取等領域[1]。區別于傳統光學圖像,SAR圖像具有微波波段成像和相位相干處理的顯著特征[2],這使得SAR圖像一方面可以反映出目標的微波散射特性,獲得大量從光學圖像和紅外遙感圖像無法得到的信息[3],另一方面也受到陰影、迎坡縮短和頂底倒置等不利影響,增強了圖像的模糊性和畸變性,難以直接解讀。SAR自動目標識別(Automatic Target Recognition,ATR)作為SAR圖像解譯中的重要環節,一直都是國內外學者的研究重點[4]。傳統SAR圖像目標識別方法主要由預處理、特征提取、識別分類等相互獨立的步驟組成,特征提取過程一般需要借助SIFT[5],HOG[6]等算法提取具有良好區分性的特征才能較好地實現分類,但復雜的流程不僅限制了SAR圖像目標檢測識別的效率,也制約了目標檢測識別的精度[7]。
卷積神經網絡(CNN)作為一種端到端的處理架構可以直接使用圖像的原始像素作為輸入,降低了對圖像數據預處理的要求并且避免了復雜的特征工程,自動學習數據的分層特征相比人工設計特征提取規則可以對原始數據進行更本質的刻畫。此外,局部連接、權值共享及池化操作等特性可以有效地降低網絡的復雜度,減少訓練參數的數目,使CNN模型對平移扭曲縮放具有一定程度的不變性和容錯能力[8]。1995年,Lecun等提出的LeNet-5系統[9]在MNIST數據集上得到了0.9%的錯誤率,并在20世紀90年代成功應用于銀行的手寫支票識別,但此時的CNN只適合小圖片的識別,對于大規模數據識別效果不佳[8]。2012年,Krizhevsky等[10]提出的AlexNet在ImageNet大規模視覺識別挑戰競賽(ImageNet Large Scale Visual Recognition Challenge,LSVRC)上取得了15.3%的Top-5錯誤率(指給定一張圖像,其標簽不在模型認為最有可能的5個結果中的幾率),遠遠超過第二名26.2%的成績,使得卷積神經網絡開始受到學界的高度關注,許多性能優秀的網絡模型也在AlexNet之后被陸續提出[11]。2014年,Szegedy等[12]提出了基于Inception結構的GoogLeNet,將Top-5錯誤率降低到了6.67%。同年,牛津大學的視覺幾何組提出的VGGNet[13]也取得了優異的成績,獲得了ILSVRC-2014中定位任務第一名和分類任務第二名。2015年,He等[14]提出的殘差網絡(Residual Network,ResNet)致力于解決識別錯誤率隨網絡深度增加而升高的問題,使用152層深度網絡取得了3.57%的Top-5錯誤率。2017年,中國自動駕駛創業公司Momenta的WMW團隊提出的SENet(Squeeze-and-Excitation Networks)[15]通過在網絡中嵌入SE模塊,在圖像分類任務上達到了2.251%的Top-5錯誤率,是迄今為止該挑戰賽上取得的最好成績。此外,近年來出現的DenseNet[16],ResNext[17],ShuffleNet[18]都在不同方面提升了卷積神經網絡的性能。
當前,很多卷積神經網絡模型在計算機視覺領域取得了很好的效果,但很多性能優異的網絡尚未推廣到SAR圖像目標識別領域,且在各類挑戰賽中參賽者一般會使用每副驗證圖像的多個相似實例去訓練多個模型,再通過模型平均或DNN集成獲得報告或論文中描述的足夠高的準確率,導致不同抽樣方式或集成大小下模型準確率與報告中的網絡性能產生偏差。基于此,本文首先介紹了幾種具有代表性的卷積神經網絡模型,然后在MSTAR數據集上對各網絡的性能進行測試,分析不同模型對SAR圖像識別的性能,為卷積神經網絡在SAR圖像目標識別上的應用建立基礎參考。
1 近五年主流卷積神經網絡模型
1.1 AlexNet
AlexNet[10]是一個8層的卷積神經網絡,由5個卷積層(其中一些緊跟著最大池化層)和3個全連接層組成,最后通過softmax層得到分類評分。AlexNet的主要創新點在于:采用了修正線性單元[19](Rectified Linear Units,ReLU)作為激活函數,更加符合神經元信號激勵原理,這種簡單快速的線性激活函數在大數據條件下相比于sigmoid等非線性函數可以獲得更好和更快的訓練效果;采用了Dropout和數據增強(data augmentation)等策略防止過擬合,降低了神經元復雜的互適應關系,增強模型魯棒性;采用兩塊GTX 580 GPU并行訓練,兩個GPU可以不用經過主機內存直接讀寫彼此的內存, 大幅提高了網絡訓練速度。
1.2 VGGNet
VGGNet[13]是牛津大學和Google DeepMind公司的研究員一起研發的深度卷積神經網絡,探索了卷積神經網絡的深度與其性能之間的關系,突出貢獻在于證明使用很小的卷積(3×3),增加網絡深度可以有效提升模型的性能。VGGNet還采用了多種方法對網絡性能進行優化:采用尺度抖動(scale jittering)方法對圖片進行裁剪,得到尺寸不一的圖片進行訓練,增強模型魯棒性和泛化能力;采用預訓練(pre-trained)方法先訓練淺層網絡,再利用訓練好的參數初始化深層網絡參數,加速收斂;在網絡中去掉了AlexNet中提出的局部響應歸一化策略,減少了內存的小消耗和計算時間。
1.3 GoogLeNet
GoogLeNet由Szegedy等于2014年提出的,是一個基于Inception結構的22層深度卷積神經網絡架構。該網絡的顯著特點是不僅增加了網絡的深度,還通過引入Inception模塊拓寬了網絡的寬度,主要原理是利用密集成分來近似最優的局部稀疏結構。 Inception模塊的結構如圖1所示,采用了不同尺度的卷積核(1×1,3×3,5×5)來處理圖像,使圖像信息在不同的尺度上得到處理然后進行聚合,使模型同時從不同尺度提取特征,增強了學習能力,該模塊的使用使得GoogLeNet的參數比AlexNet少12倍,但準確率更高。圖1中粉色部分的1×1卷積核的作用是降低參數量,加速計算,詳細原理可見文獻[20]。此外,GoogLeNet的作者還做了大量提高模型性能的輔助工作,包括訓練多個模型求平均、裁剪不同尺度的圖像做多次驗證等,詳見文獻[12]的實驗部分。
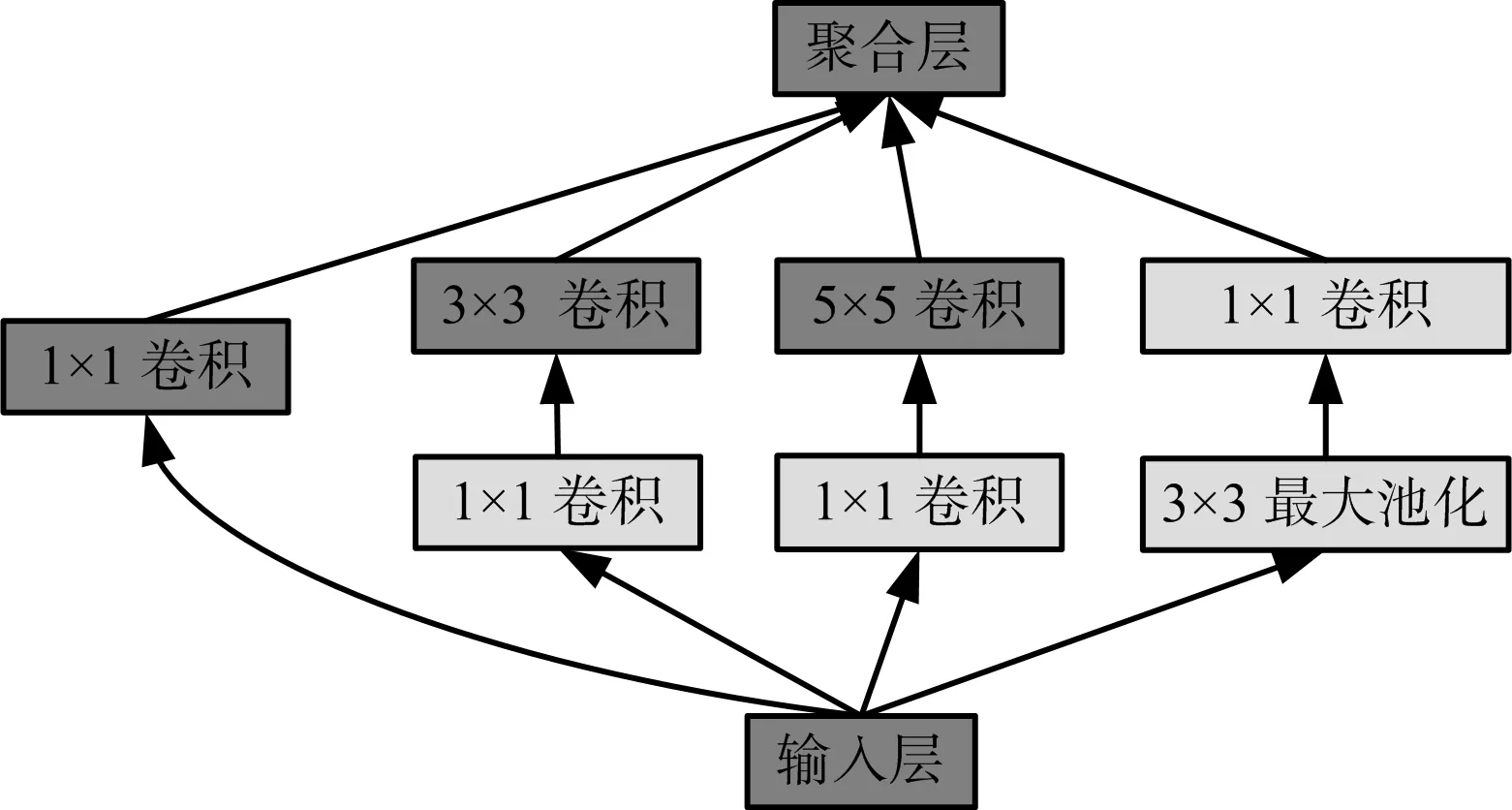
圖1 Inception模塊結構
1.4 ResNet
自VGGNet提出以來,學者們紛紛致力于通過提升網絡的深度以取得更好的性能,但隨著網絡深度的不斷增加,梯度彌散/爆炸[21](vanishing/exploding gradients)問題和隨機梯度下降法(Stochastic Gradient Descent,SGD)難以優化深層網絡帶來的退化[22](degradation)問題隨之而來,導致訓練和測試誤差隨網絡深度增加而增大。He等針對該問題提出了一個152層的殘差網絡結構(residual network),如圖2所示。H(x)是某一層原始的期望映射輸出,x是輸入,通過快捷連接[23-24](shortcut connections)在網絡中加入一個恒等映射(identity mapping),就相當于從輸入端旁邊開設了一個通道使得輸入可以直達輸出,優化目標由原來的H(x)變成輸出和輸入的差H(x)-x,而對于一個可優化的映射,其殘差也會很容易優化至0,且將殘差優化至0和把此映射逼近另一個非線性層相比要容易得多[25],因此這樣的結構降低了深層網絡參數優化的難度,解決了退化問題。文獻[26]是He等對ResNet的后續研究,對自身映射在殘差網絡中的作用進行了更深層次的分析和驗證,并提出了改進版的ResNet。
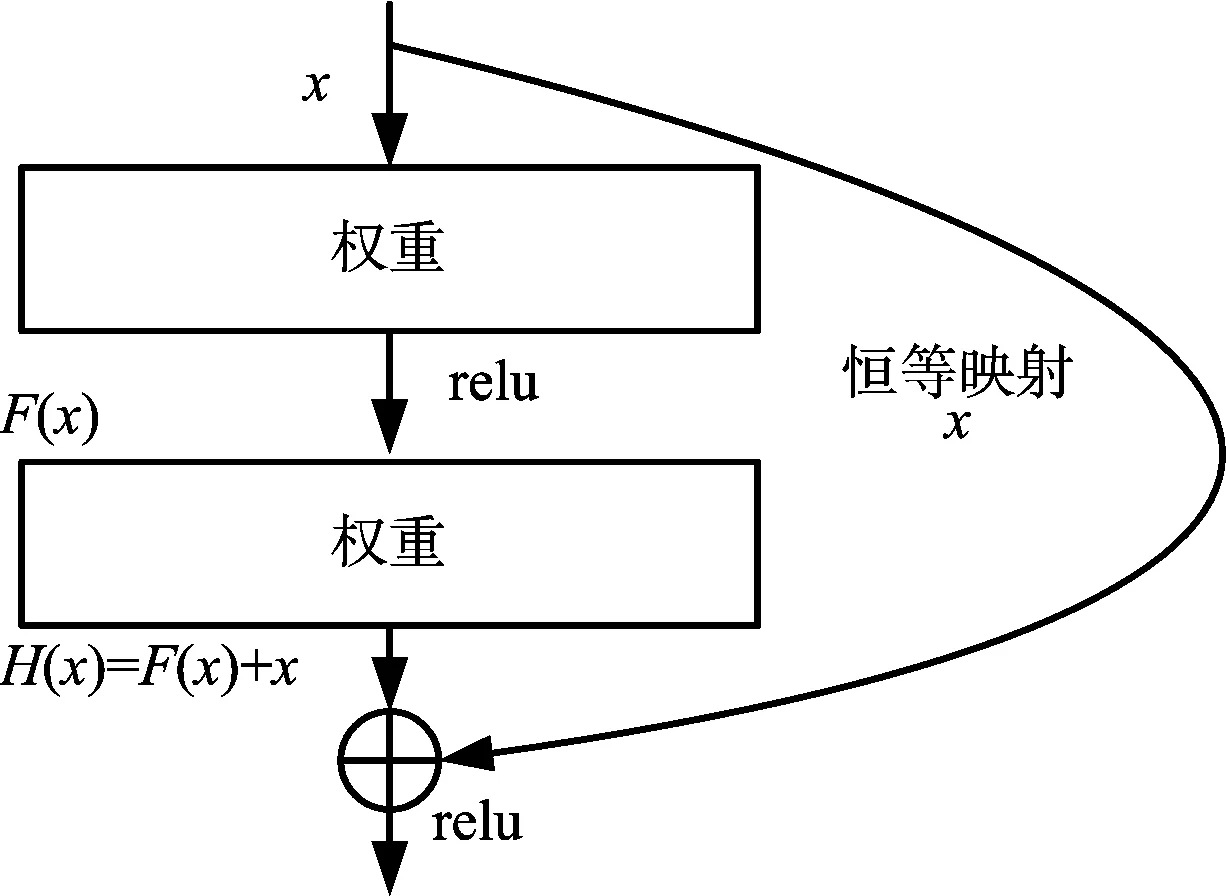
圖2 殘差網絡結構
1.5 DenseNet
ResNet結構中的數據旁路(skip-layer)技術可以使信號在輸入層和輸出層之間高速流通,核心思想是創建一個跨層連接來連通網路中前后層。文獻[16]基于這個核心理念設計了一種具有密集連接的卷積神經網絡,即DenseNet。其與ResNet最大的區別在于網絡每一層的輸入都是前面所有層輸出的并集,而該層所學習的特征圖也會被直接傳給其后面所有層作為輸入,通過密集連接實現特征的重復利用,增強了網絡的泛化能力。在密集連接的前提下可以把網絡的每一層設計得很“窄”,即只學習非常少的特征圖(最極端情況就是每一層只學習一個特征圖),所以可以達到降低冗余性的目的。簡單來說,DenseNet有以下優點:減輕了梯度消失問題;強化了特征傳播;大幅度減少了參數數量。這篇論文獲得了2017年IEEE國際計算機視覺與模式識別會議的最佳論文獎。
1.6 SENet
前述很多工作都是從空間維度層面來提升網絡的性能,文獻[15]將考慮重點放在卷積神經網絡特征通道之間的關系,在網絡中引入了包含壓縮(Squeeze)和激發(Excitation)操作的SE模塊,并基于此提出了SENet。Squeeze操作將每個二維的特征通道變成一個實數來代表全局的感受野,并且輸出的維度和輸入的特征通道數相匹配。Excitation操作是一個類似于循環神經網絡中門的機制,通過參數w來為每個特征通道生成權重,用來顯式地建模特征通道間的相關性。最后進行重新標定權重(reweight)操作,將 Excitation的輸出權重看作是進行過特征選擇后每個特征通道的重要性,然后通過乘法逐通道加權到先前的特征上,提升有用的特征并抑制對當前任務用處不大的特征。文獻[15]將SE模塊嵌入ResNeXt,BN-Inception,Inception-ResNet-v2上進行結果對比均獲得了不錯的增益效果。
2 基于經典卷積神經網絡模型的SAR圖像目標識別實驗
2.1 數據集



圖3 MSTAR數據集
2.2 實驗準備
由于數據集中的原始圖片大小均為128像素×128像素且目標基本都處于圖片的中心位置,故不需要對原圖片作預處理,只進行數據整理即可。首先為訓練集和測試集中的所有圖片制作標簽,用0~8分別代表9類待識別目標,之后將各類數據重新編號整理至同一文件夾下,最后通過pytorch框架中的Dataset模塊將數據導入網絡中,可以用于直接訓練。
本文實驗在64位Ubuntu 14.04系統環境下進行,軟件方面主要基于深度學習架構pytorch和python開發環境pycharm,硬件主要基于Intel(R) Core(TM) i7-6770K @ 4.00 GHz CPU和NVIDIA GTX1080 GPU,采用 CUDA8.0加速計算。
2.3 實驗結果及分析
2.3.1 識別精度分析
為了準確對比各網絡的表現,結合數據集實際情況對實驗條件作了以下統一設置:迭代次數設置為50次,即將所有圖片在網絡中訓練50次,批處理大小為16,即每次向網絡中輸入16張圖片數據同時進行處理,反向傳播過程采用交叉熵損失函數,學習率設置為0.01。分別在LeNet,AlexNet,VGGNet-16(表示16層的網絡,下同),Inception-v3(GoogLeNet的改進型),ResNet-18,ResNet-101,ResNet-152,SEResNet-18,SEResNet-101,DenseNet-161(每層通道數為48)共10個模型上測試網絡的識別能力。各網絡的訓練損失曲線和精度曲線如圖4和圖5所示,最終訓練精度和測試精度如表1所示。
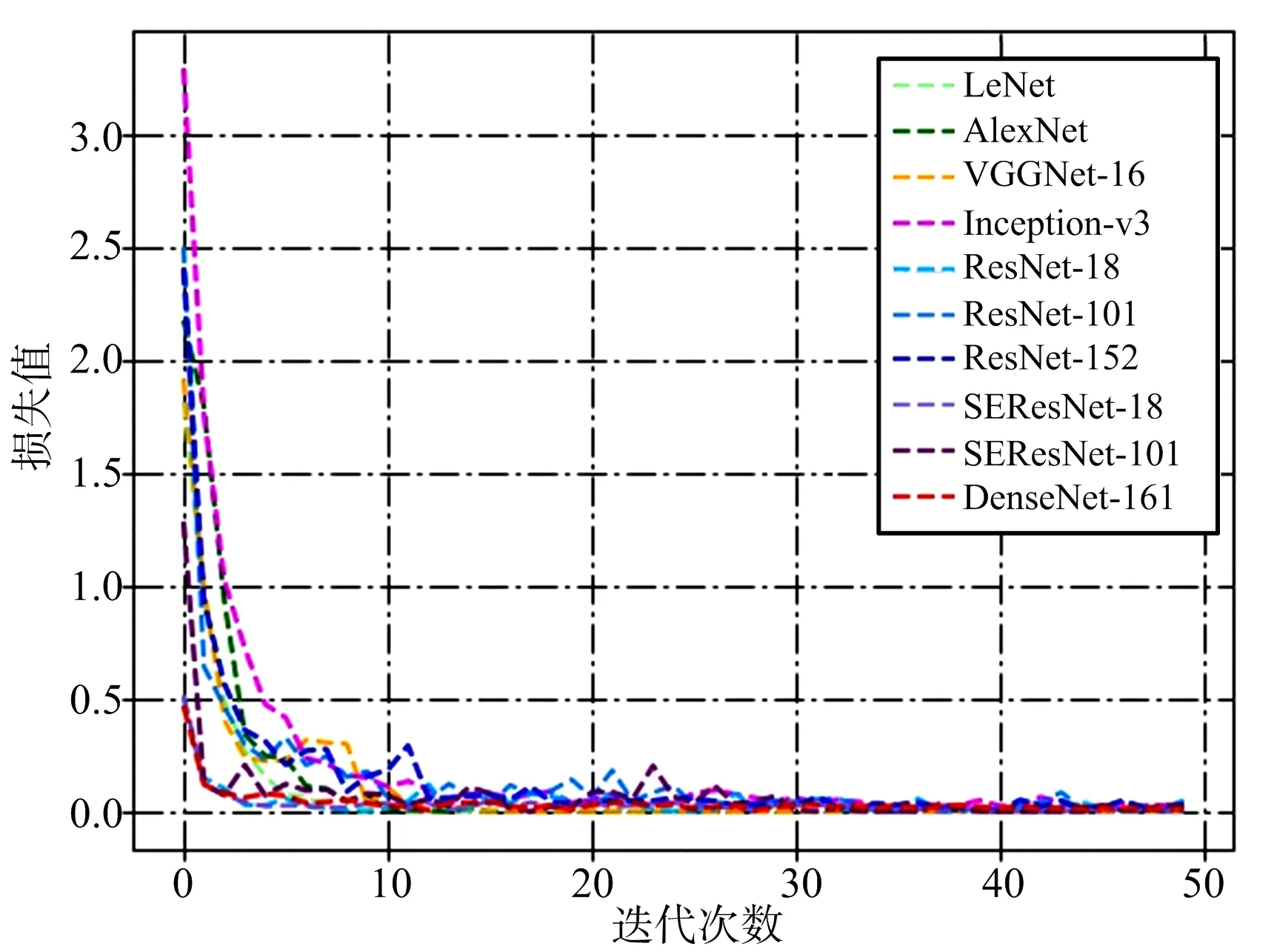
圖4 模型損失曲線
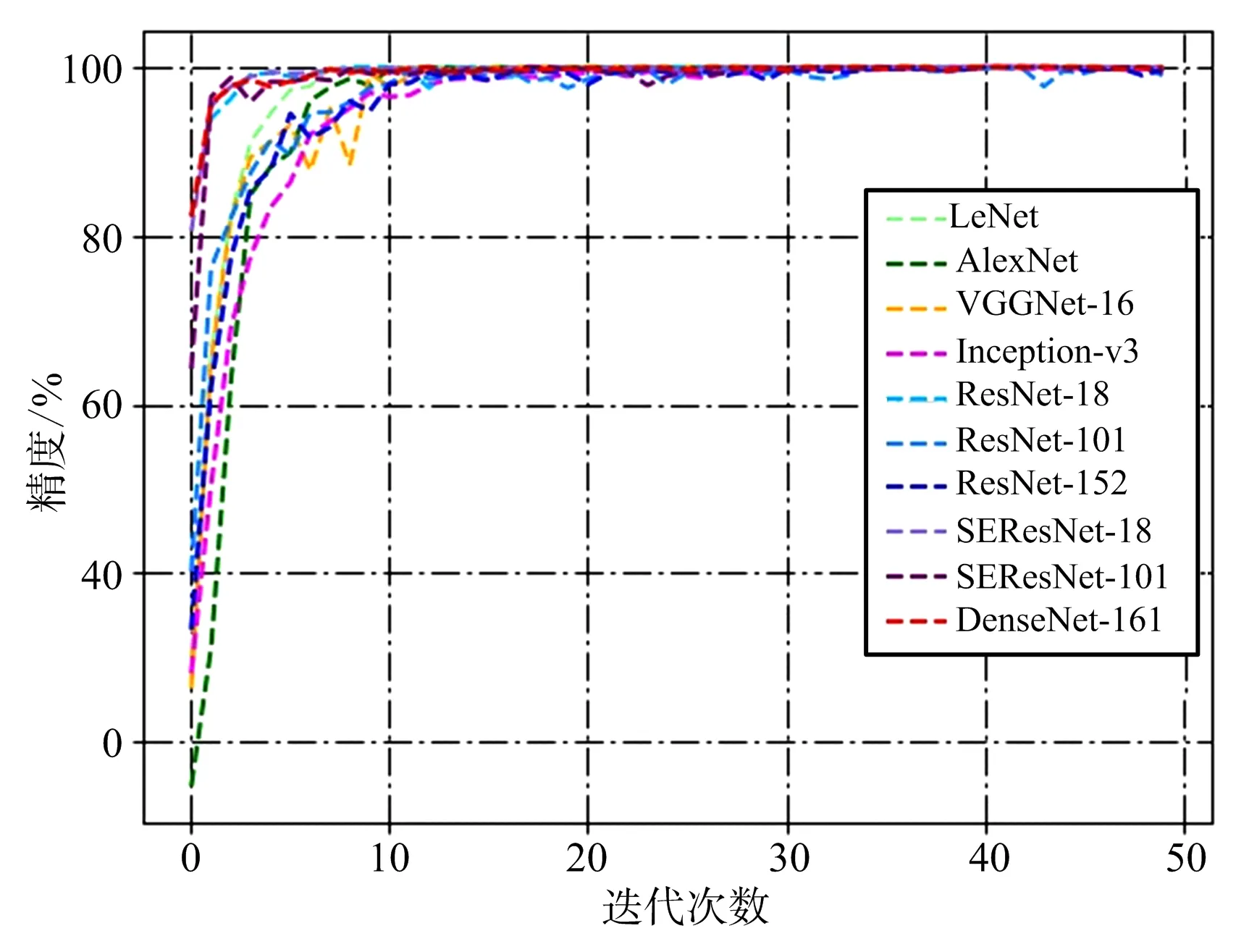
圖5 模型精度曲線
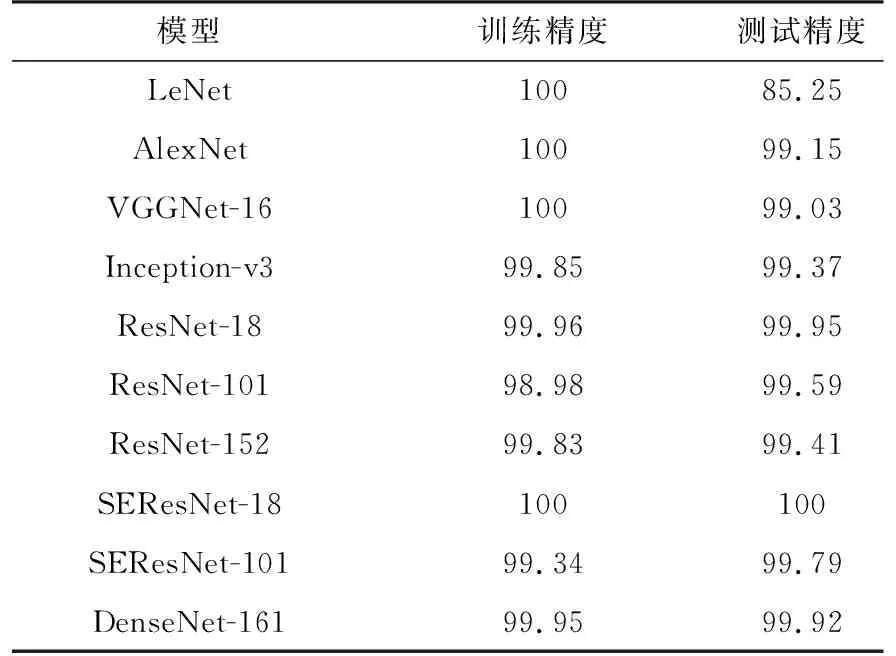
由圖4可以看出,各網絡在迭代數據集10次左右后都趨于收斂,說明對訓練集達到了較好的擬合效果。根據表1可知,除LeNet外的所有模型在測試集上的最終精度都達到了99%以上,SEResNet-18達到了100%的識別精度,測試精度充分說明了CNN模型對SAR圖像具有較強的識別和學習能力。LeNet,AlexNet和VGGNet-16三個模型雖然在訓練集上都達到了100%的精度,但測試集上的精度卻低于其他模型,反映出這些模型的泛化能力不如其他模型。值得注意的是,ResNet和SEResNet系列模型都體現出了網絡層次加深識別精度卻有所下降的趨勢,這并不符合預期,原因在2.3.3節中進行分析。
各模型在測試集上都取得了很高的精度且差異很小,除了網絡自身具有較好的性能外,可能還受到以下兩點原因的影響:一是本文所采用的數據集屬于中小型數據集,總共只有5 156張圖片,9種類別,而實驗中采用的網絡基本都是可以訓練百萬量級圖片,完成近千種分類的大型網絡,因而會得到較好的識別效果;二是由于SAR圖像數據獲取渠道有限,實驗中的訓練集和測試集圖片僅是不同俯仰角成像下的SAR圖像,數據集間的差異較小,導致得到了較高的識別精度。雖然數據集較小且訓練和測試圖片差異較小,但并不影響研究各模型的性能差異,且表1中實驗結果基本真實地反映了各模型在其他數據集上的相對表現。
2.3.2 計算資源分析
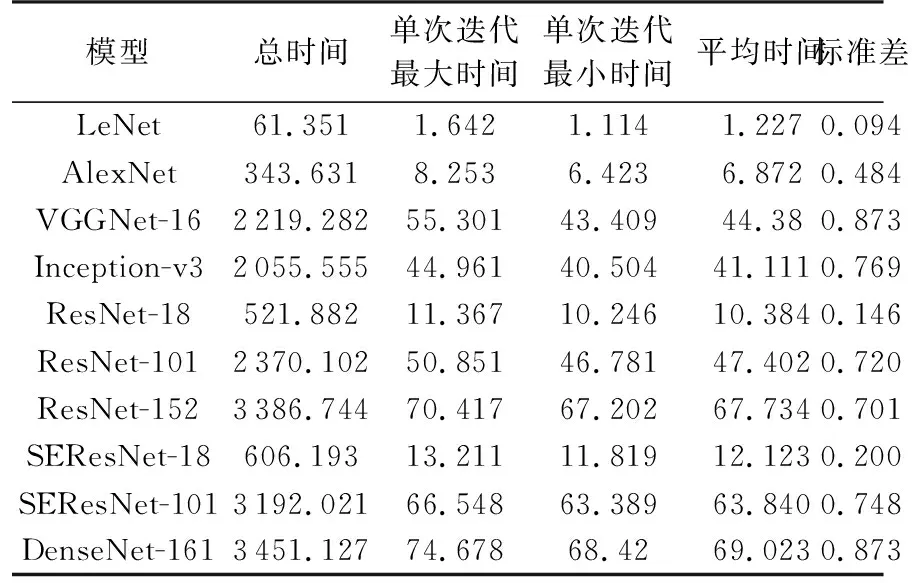
除了需要考量模型的識別性能,運算時間和模型尺寸等指標也是應用中需要考慮的重要指標。為此,在實驗過程中記錄了各模型訓練和測試時每個迭代周期內的運算時間,并由此計算出各模型的運行總時間、平均時間、單次迭代最大最小時間及時間的標準差,結果如圖6和表2所示。
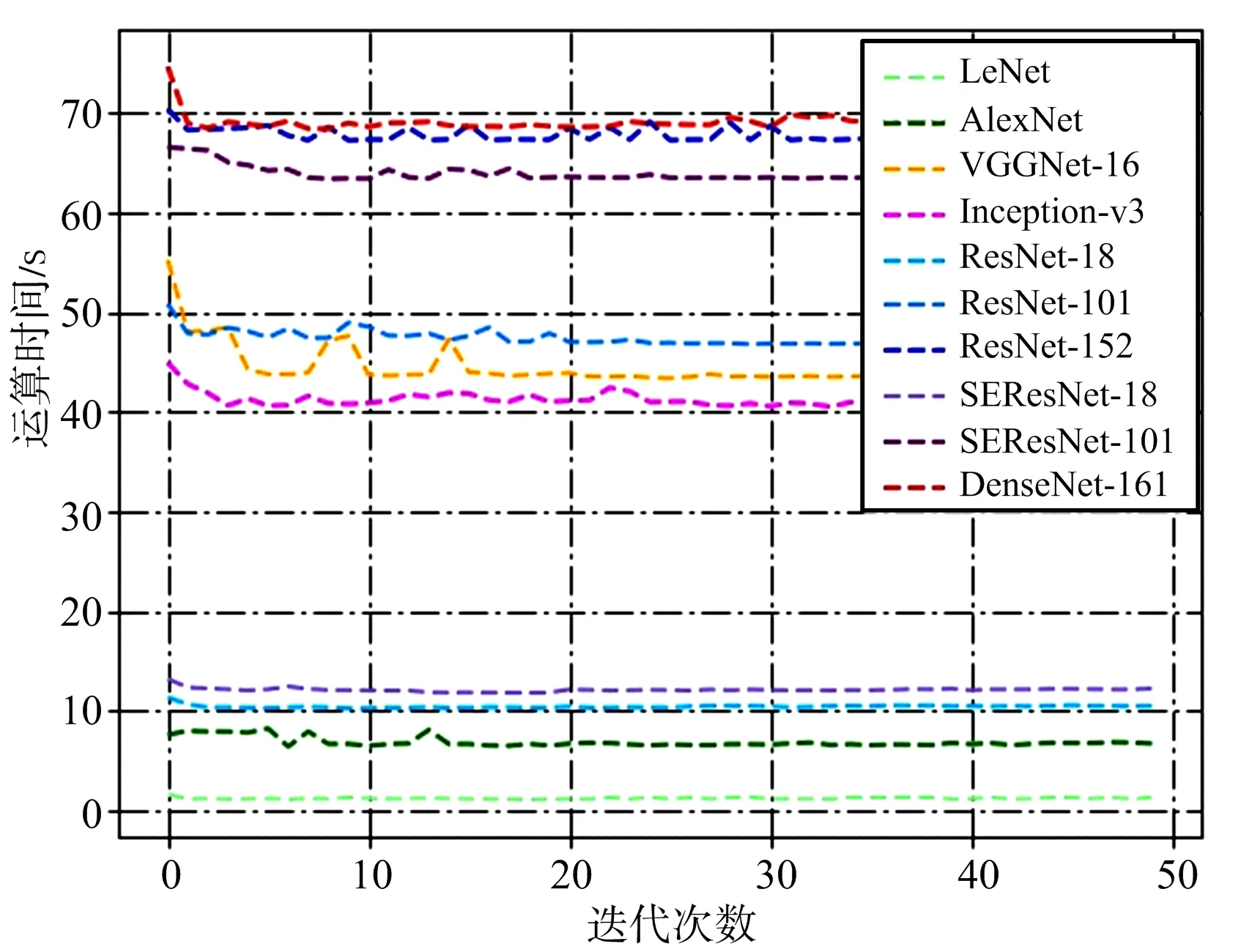
圖6 模型運算時間
s
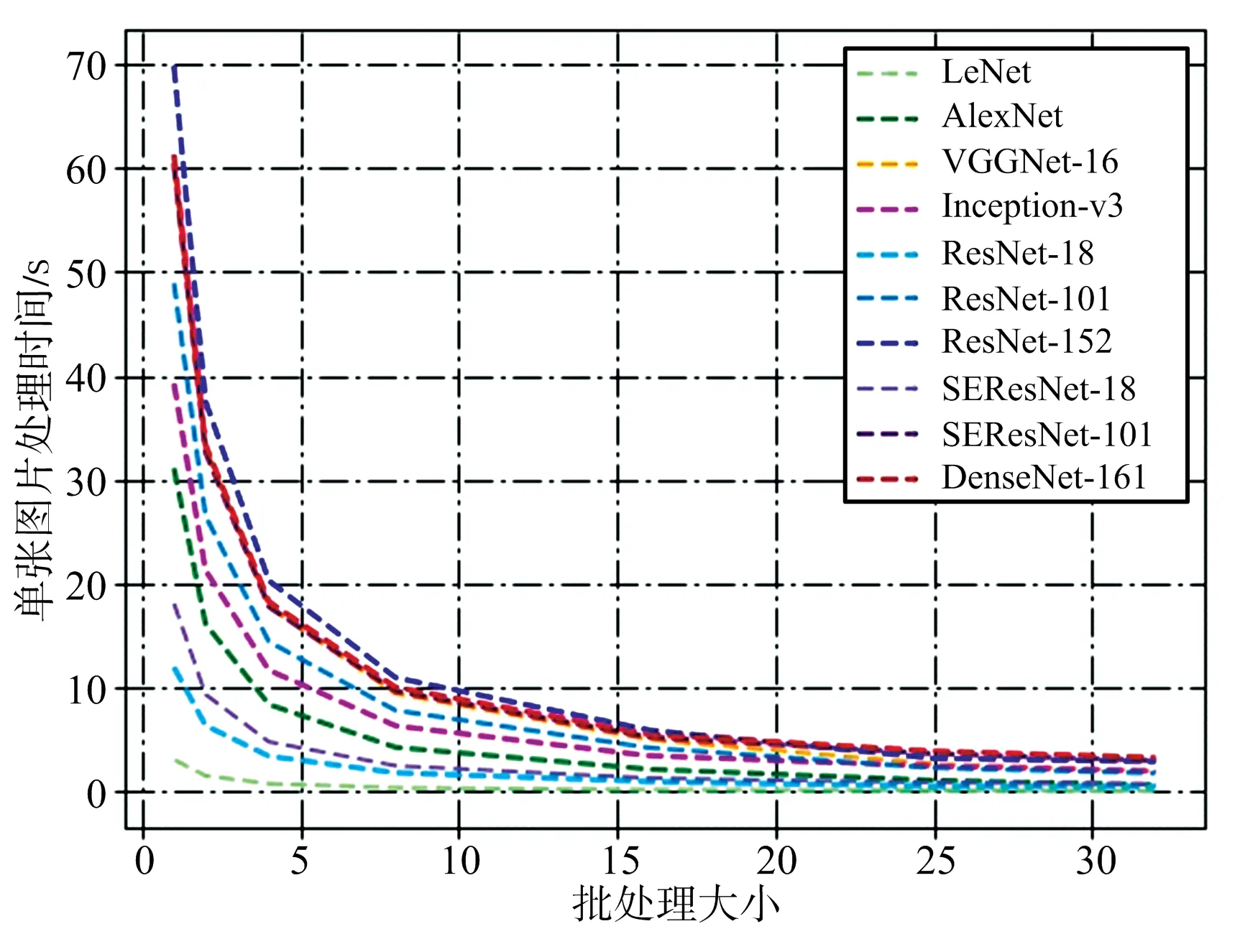
圖7 單張圖片處理時間
由圖6和表2可知,模型的運行時間基本分成了3檔,LeNet,AlexNet,ResNet-18和SEResNet-18的運行時間比較短,Inception-v3,VGGNet-16和ResNet-101居中,SEResNet-101,ResNet-152和DenseNet-161運行時間最長,最長時間和最短時間相差近57倍,說明模型深度的增加會明顯提高運行時間,也說明在達到基本相同精度的條件下,CNN模型運行時間還有很大的壓縮空間。運行時間標準差反映了迭代時的穩定性,可以發現,對于計算時間較小的模型,其穩定性也較好。
另外,SE模塊的引入使得計算時間有所增加,SEResNet-101的計算時間接近ResNet-152,計算開銷有所增大,但SEResNet-101相比ResNet-101獲得了較大的性能提升。
圖7給出了模型處理每張圖片所需時間與批處理大小的關系,二者呈近似反比關系,批處理大小從1增加到10,每張圖片所需的處理時間可以下降3~4倍。由圖中還可看出,對于單張圖片處理時間越大的網絡,處理時間隨批處理大小下降的趨勢就越明顯,這也是批量處理技術廣泛應用于當前大型網絡加速計算的原因所在。
為了更加全面地研究各模型的計算資源占用情況,實驗還記錄了各模型在經過訓練后的尺寸大小,如表3所示,圖8給出了各模型的平均運行時間和模型尺寸之間的對應關系。
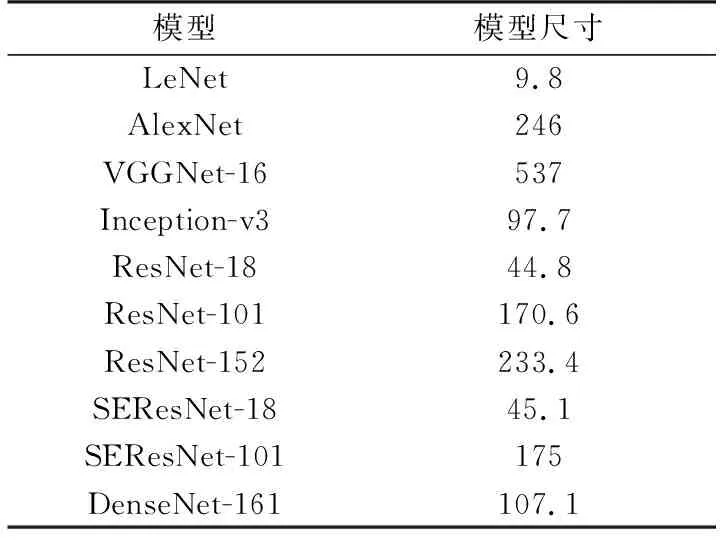
表3 模型尺寸 MB
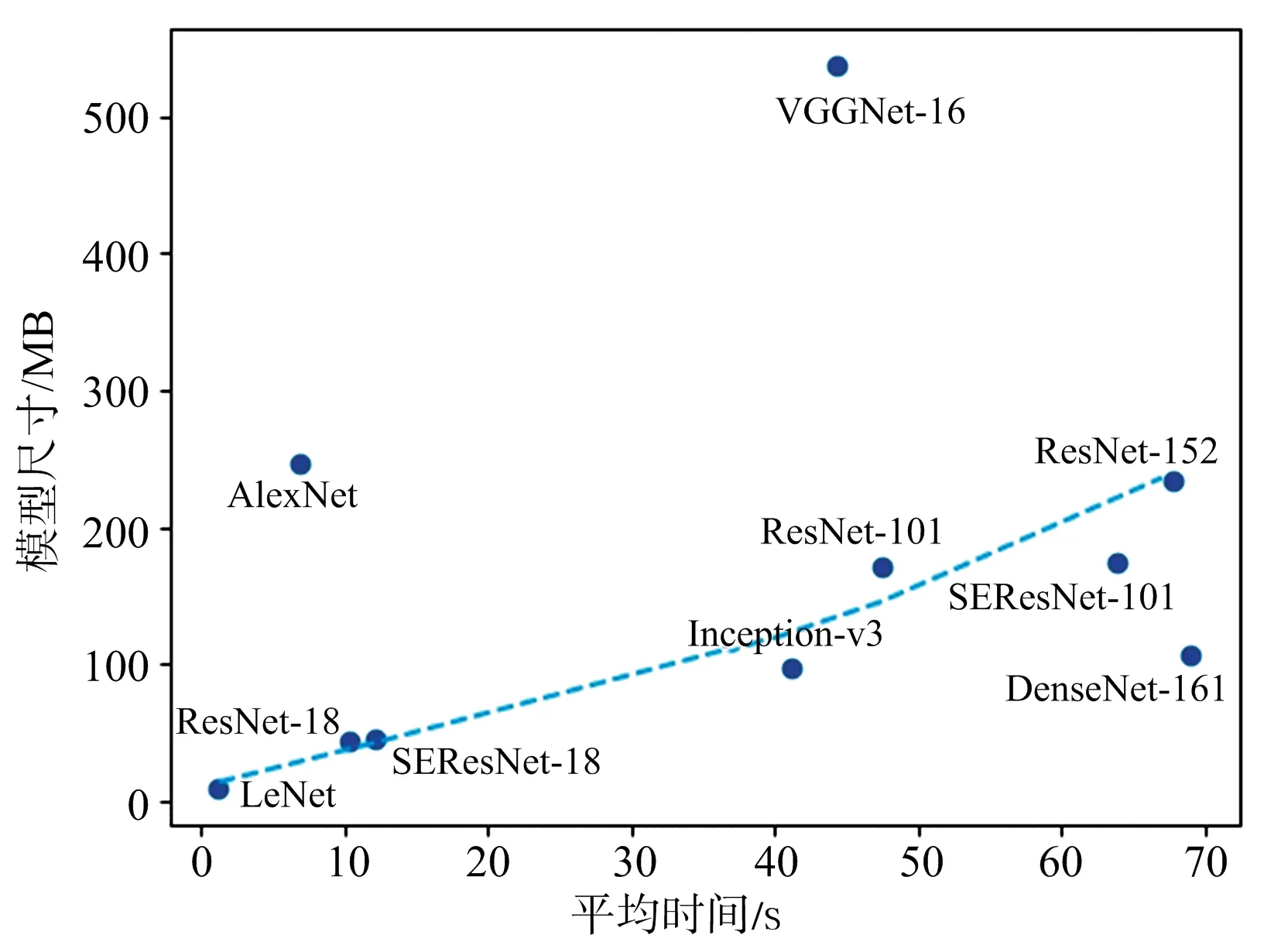
圖8 模型平均運行時間和模型尺寸關系圖
由圖8可以看出,作為早期的CNN模型,AlexNet,VGGNet都是通過加深網絡深度和提高模型復雜度來獲取更好的性能,從而增加了模型尺寸,而ResNet,DenseNet等新型網絡在獲得更好的識別性能的同時還顯著降低了模型尺寸。圖8中除AlexNet,VGGNet和DenseNet-161以外其余網絡的模型尺寸基本與運行時間呈正相關,DenseNet-161雖然模型較小卻耗時最多,主要是因為其密集連接結構會極大地增加運算量,說明運行時間不僅與模型尺寸相關,很大程度上也受到實際運算量的影響。
綜合考慮識別精度和計算耗費,ResNet-18和SEResNet-18兩個模型可以在較小的運算時間和模型大小下,取得和其他模型相當或優于其他模型的識別效果,在本實驗數據集下是理想的選擇。
2.3.3 梯度彌散問題的討論
為便于分析,從實驗結果圖5中選取部分模型,如圖9所示。
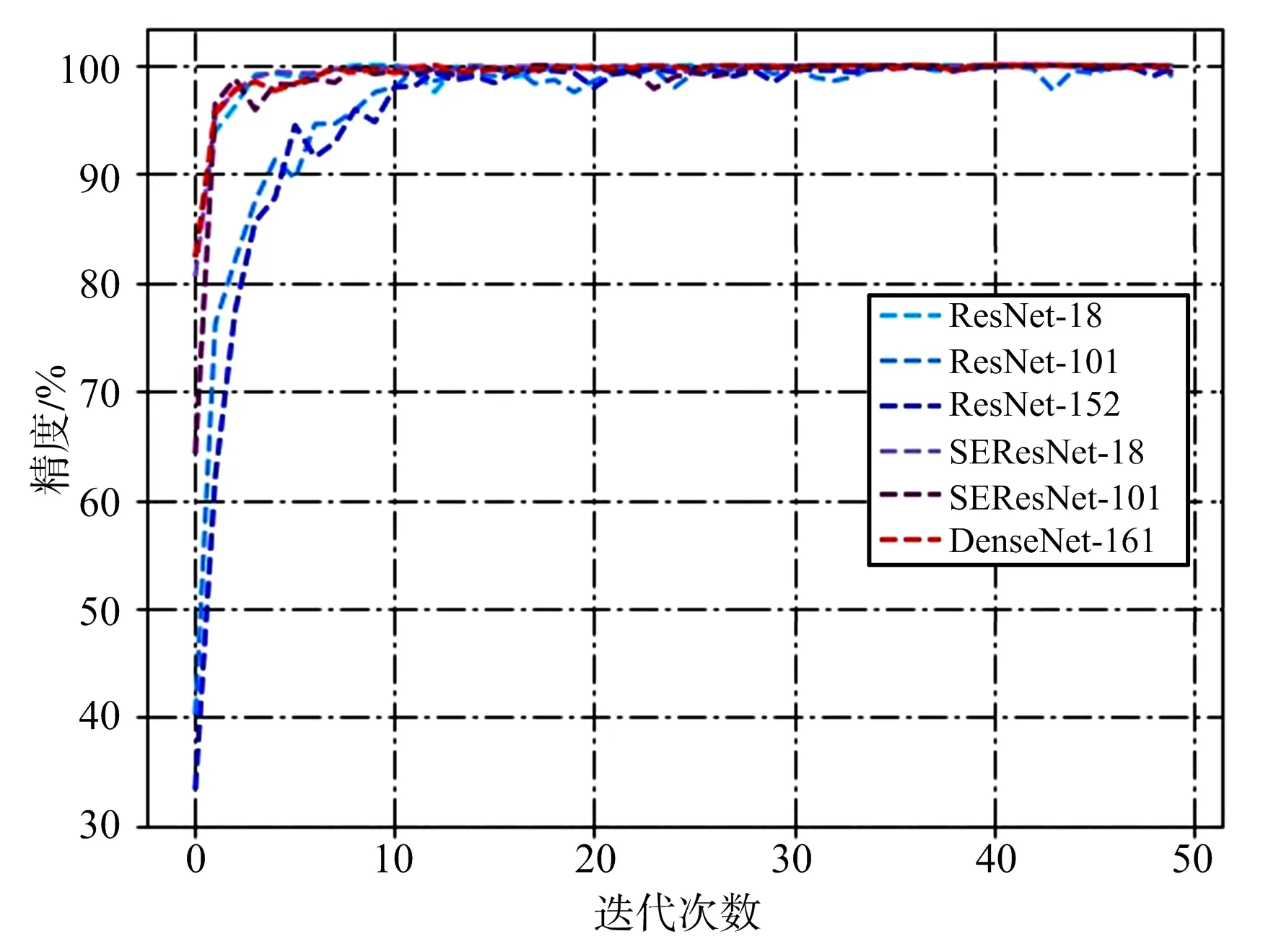
圖9 部分模型精度圖
結合表1和圖9可以看出,淺層網絡ResNet-18和SEResNet-18都取得了很好的識別效果,而深層網絡ResNet-101 和ResNet-152模型沒有取得預想中的比ResNet-18更好的識別性能,引入SE模塊的SEResNet-101和采用了密集連接方法的DenseNet-161模型則獲得了優于ResNet-101和ResNet-152的識別性能。以上現象說明深層網絡中梯度前向傳播時出現的“梯度彌散”問題在ResNet-101和ResNet-152中并沒有得到很好的解決,而SE模塊和密集連接方法則有效緩解了這一問題。
3 結束語
SAR圖像目標自動識別是SAR圖像解譯中的重要環節,也是研究熱點和難點。本文將計算機視覺領域關于目標識別的最新成果和近年來出現的若干性能優異的CNN模型應用到SAR圖像目標識別上,取得了很好的識別效果,多個模型識別率達到99%以上。綜合考量這些CNN模型在SAR圖像數據集上的識別性能、計算消耗、運作機制等指標,對比分析了不同模型的優劣之處,實驗結果為SAR圖像目標識別系統在實際應用中選擇、組合和優化各類CNN模型提供了數據支撐和有效參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
