基于最長屬性路徑過濾的SPARQL查詢優化
2018-11-20 06:08:36林曉慶程經緯
計算機工程 2018年11期
關鍵詞:方法
林曉慶,張 富,程經緯
(1.東北大學 計算機科學與工程學院,沈陽 110819; 2.遼東學院 信息工程學院,遼寧 丹東 118003)
0 概述
資源描述框架(Resource Description Framework,RDF)現已成為語義網數據表示和交換的核心模型,因此,可用的RDF數據越來越多。RDF數據是陳述的集合,形式為(Subject,Predicate,Object)三元組,其中,Subject為主語,Predicate為謂詞,用于聯結主語和賓語,Object為賓語。SPARQL是標準的RDF數據查詢語言,因其可對RDF數據查詢以獲得有用的Web信息,故被廣泛應用。但是在SPARQL查詢執行處理過程中會產生大量冗余的中間結果,尤其在處理大規模的RDF數據時,這大幅降低了SPARQL查詢的執行效率。因此,SPARQL查詢優化處理成為了研究熱點。
早期的RDF搜索系統是面向RDF三元組行存儲的關系式數據庫管理系統,例如Jena[1]及Sesame[2]等。這些系統利用關系式數據庫管理系統的查詢處理模塊對RDF數據進行存儲和處理。SW-store[3]、RDF-3x[4]、Hexastore[5]和gStore[6]能夠有效地處理大規模的RDF數據,其中SW-store采用垂直分割存儲,將三元組表按謂詞進行分割,能夠快速合并聯接。目前多數SPARQL優化技術主要通過制定一個最優的查詢執行計劃來減少中間結果。文獻[4]利用動態規劃方法估計最優的查詢執行計劃,該方法需要指數級數量的時間和空間的開銷,而且沒有利用RDF數據圖結構信息。文獻[6]提出一種VS樹和VS*樹索引,利用子圖匹配進行帶通配符處理或精確的SPARQL查詢處理。文獻[7]通過RDF圖屬性路徑索引過濾掉冗余的中間結果,取得了較好的效果,但該方法不處理包含文字和空節點的三元組模式,并且只利用了屬性路徑索引信息。文獻[8]提出了一個對大規模RDF數據動態計算查詢代價的查詢優化方法,但該方法需要較大的存儲開銷。目前,基于分布式RDF存儲的查詢搜索引擎開發也吸引了很多研究者的注意[9-11],這些分布式RDF系統能夠減少輸入的聯結,比集中式存儲更能有效地提高查詢性能,因為網絡上傳輸查詢中間結果的開銷很大。文獻[12]提出2個輔助的索引結構:ID-塊位矩陣和ID-謂詞位矩陣,通過查詢處理器動態地產生聯結執行的順序以降低中間結果。文獻[13]利用在原始的RDF數據圖上提煉有效的RDF圖索引,通過該索引進行中間結果過濾。文獻[14]則結合哈希映射和選擇策略樹進行SPARQL的查詢優化。
為提高SPARQL查詢的執行效率,本文根據RDF數據圖的結構特點,通過使用屬性路徑與基于關系的存儲模型,提出一種兩階段SPARQL查詢優化方法。第一階段將SPARQL查詢按所含的公共變量進行分塊,第二階段則利用選擇度計算最長屬性路徑,從而過濾中間冗余結果。
1 SPARQL查詢及查詢執行
SPARQL[15]已經被W3C推薦為RDF數據的標準查詢語言,是一種通過在RDF數據上進行三元組模式匹配來獲取結果的查詢語言。一個基本的SPARQL查詢由SELECT子句和WHERE子句構成,其中,“pattern1”“pattern2”等都是三元組模式,操作符“.”聯結2個三元組模式,每個三元組模式都由主語、謂詞、賓語構成,這三項為文字或者為變量。在查詢中,將已知的用文字表示,未知的用變量表示,如下所示。
SELECT ?variable1 ?variable2…
WHERE {pattern1.pattern2.… }
由LUBM基準給出的第9個查詢實例Q9如下所示。在該實例查詢中,查詢所有學生、教師及課程并且滿足課程由學生選擇、教師教授學生、授課老師是學生的指導教師,“rdf”和“ub”都是前綴,“?X rdf:type ub:Student”等都是三元組模式。本文處理的SPARQL查詢可以包含謂詞為變量的三元組模式。
PREFIX rdf:
PREFIX ub:
SELECT ?X ?Y ?Z WHERE{
?X rdf:type ub:Student .
?Y rdf:type ub:Faculty .
?Z rdf:type ub:Course .
?X ub:advisor ?Y .
?Y ub:teacherOf ?Z .
?X ub:takesCourse ?Z}

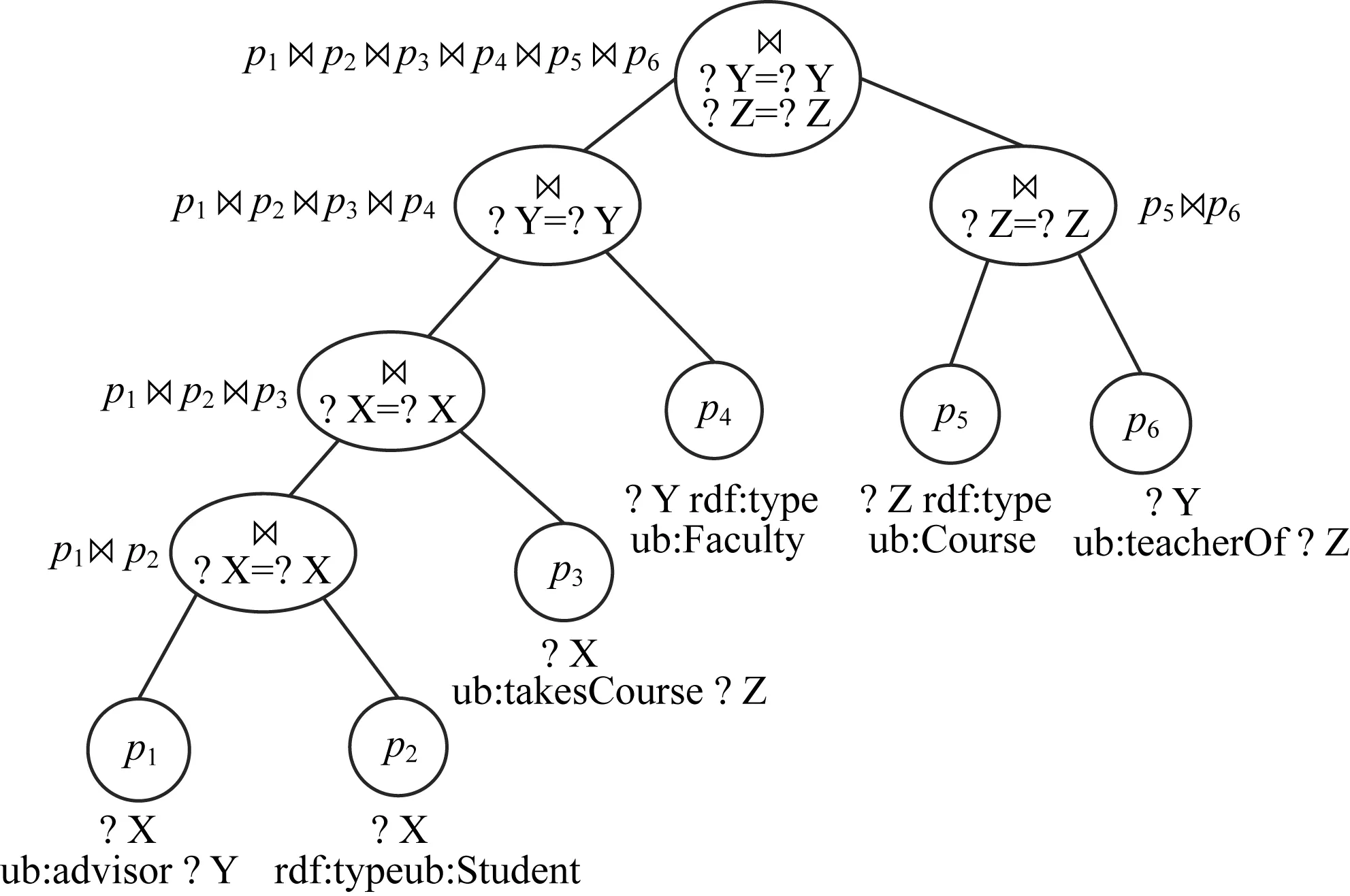
圖1 Q9的一個查詢執行計劃

表1 不同聯結產生的中間結果數量
2 SPARQL查詢優化
本文優化方法流程如圖2所示。在第一階段,將SPARQL查詢圖進行分塊,在塊內按每個聯結代價重新排序并執行部分聯結,代價的估計根據聯結產生中間結果的數量;在第二階段,利用最長屬性路徑索引過濾掉冗余的中間結果,與文獻[7]方法中的屬性路徑過濾類似,但本文在過濾時使用最長屬性路徑進行匹配過濾,而不是某一個路徑長度范圍內的所有屬性路徑進行過濾,避免了過多的重復計算。
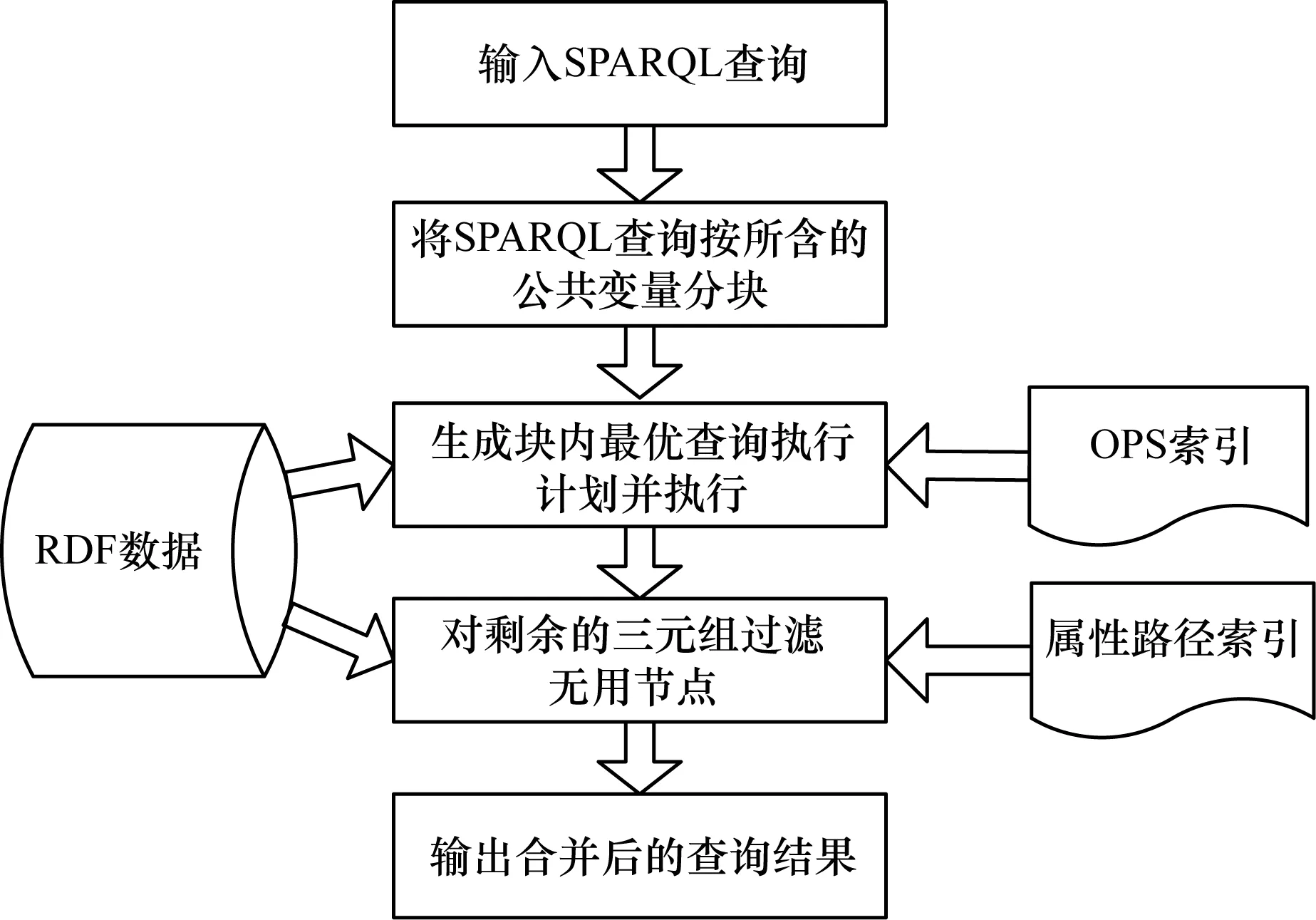
圖2 本文方法流程
本文的查詢執行計劃是一個圖而不是一棵樹,便于重用塊內聯結的結果。以Q9的一個查詢圖(見圖3(a))為例,在第一階段,將SPARQL查詢圖按含有相同的聯結變量進行分塊,圖3(b)即為Q9查詢圖的一個分塊,然后根據三元組模式都含有相同的聯結變量“?X”劃分為一塊。
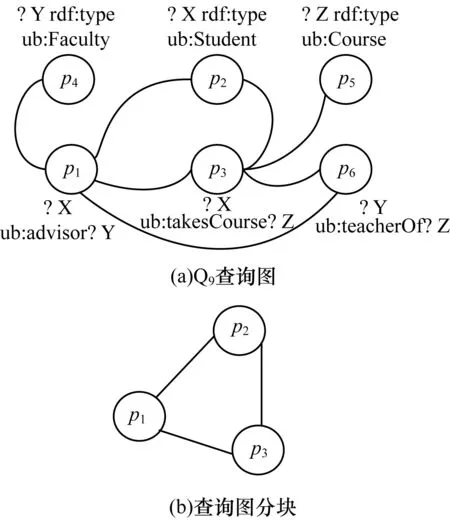
圖3 Q9查詢圖及其分塊
2.1 選擇度計算
選擇度根據匹配聯結pn的三元組個數計算獲得,匹配的三元組數量越多,選擇度最小,計算公式如下:
SELECTIVITY=min(sel(p1),sel(p2),…,sel(pn))
如果#(p1)<#(p2)<#(p3),則sel(p1)>sel(p2)>sel(p3)。為節省空間和時間,選擇度的計算針對至多含有一個查詢變量的三元組模式。最頻繁的一種三元組模式是(?S,P,O),即給定三元組的主語P、謂詞O,返回對應三元組中主語S的值。
本文建立一個OPS(賓語,謂詞,主語)索引[5]計算選擇度。指定賓語和謂詞可以獲取對應的主語id列表和匹配的三元組個數,以此來實現塊內最優執行計劃,索引結構如表2所示,其目的是先執行聯結次數較少的聯結,減少不必要的聯結。
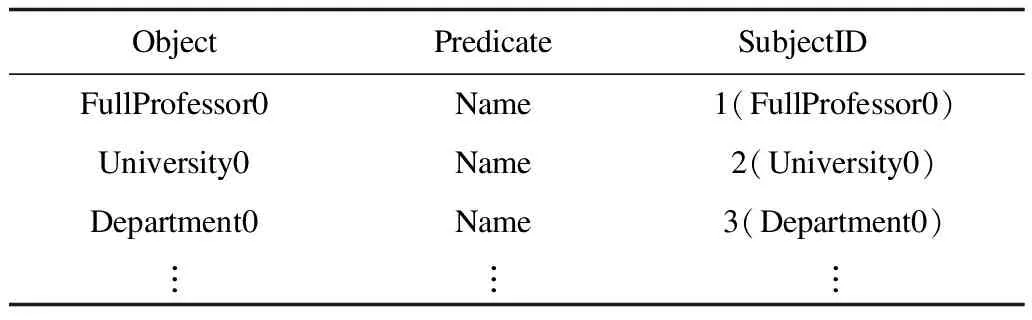
表2 OPS索引結構
2.2 屬性路徑索引
本節介紹屬性路徑索引,對第二階段剩余聯結進行過濾。屬性路徑索引是從RDF數據圖中提取的,本文的RDF數據圖的定義采用文獻[16]中的定義:
定義1一個RDF數據圖是一個三元組(V,L,E)。其中:V是一個有限的節點集,VE表示實體節點,VC表示類節點,VV表示數據節點,構成不相交的并集VEVCVV;L是一個有限的邊標簽集合,L=LRLA{type,subclass},LR代表實體之間的邊,LA代表實體和數據值之間的邊;E是一個有限的邊集,邊的形式為:e(v1,v2),v1,v2∈VE,e∈L,只有v1,v2∈VE,e∈LR;e∈LA,當且僅當v1∈VE且v2∈VV;e=type當且僅當v1∈VE且v2∈VC;及e=subclass當且僅當v1,v2∈VC。
本文定義一個RDF實體關系圖以用于建立屬性路徑索引:
定義2一個RDF實體關系圖G’是一個三元組(V’,L’,E’),其中,頂點V’=VE,邊標簽L’=LR,且E’?E,E’聯結2個實體節點。VE表示實體頂點的集合(例如IRIs),只有RDF數據中存在邊e(v1,v2)∈E’并且v1,v2∈VE,RDF實體關系圖中存在邊e(v1,v2)∈VE。
本文的屬性路徑索引是建立在RDF實體關系圖上,不包括數值類型的三元組,如圖4所示。包含數值的三元組在第一階段進行處理。
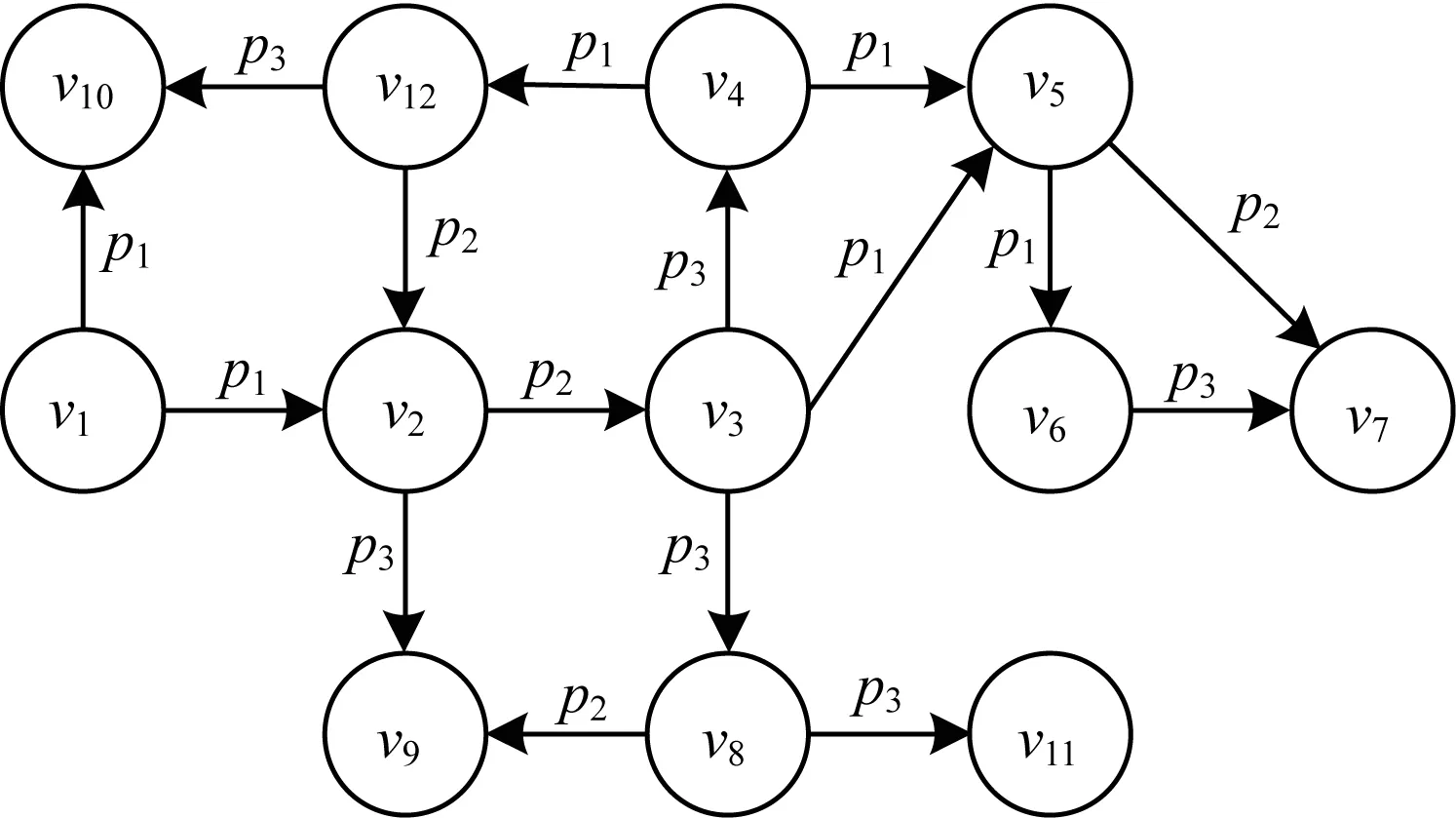
圖4 RDF實體關系示意圖
定義3入邊屬性路徑是一個三元組謂詞的序列,如果一條路徑的終端節點是n,則稱這是一條節點n的入邊屬性路徑。
例如,Q9中的“?X ub:advisor ?Y.?Y ub:teacherOf ?Z”聯結,存在一條“?Z”的入邊屬性路徑“ub:advisor→ub:teacherOf”。表3顯示了圖4中的屬性路徑索引指向的頂點列表。例如,如果某一個SPARQL查詢中存在聯結“?n1p1?n2.?n2.p2?n3.?n3?p3?n4”,可以通過找到屬性路徑“
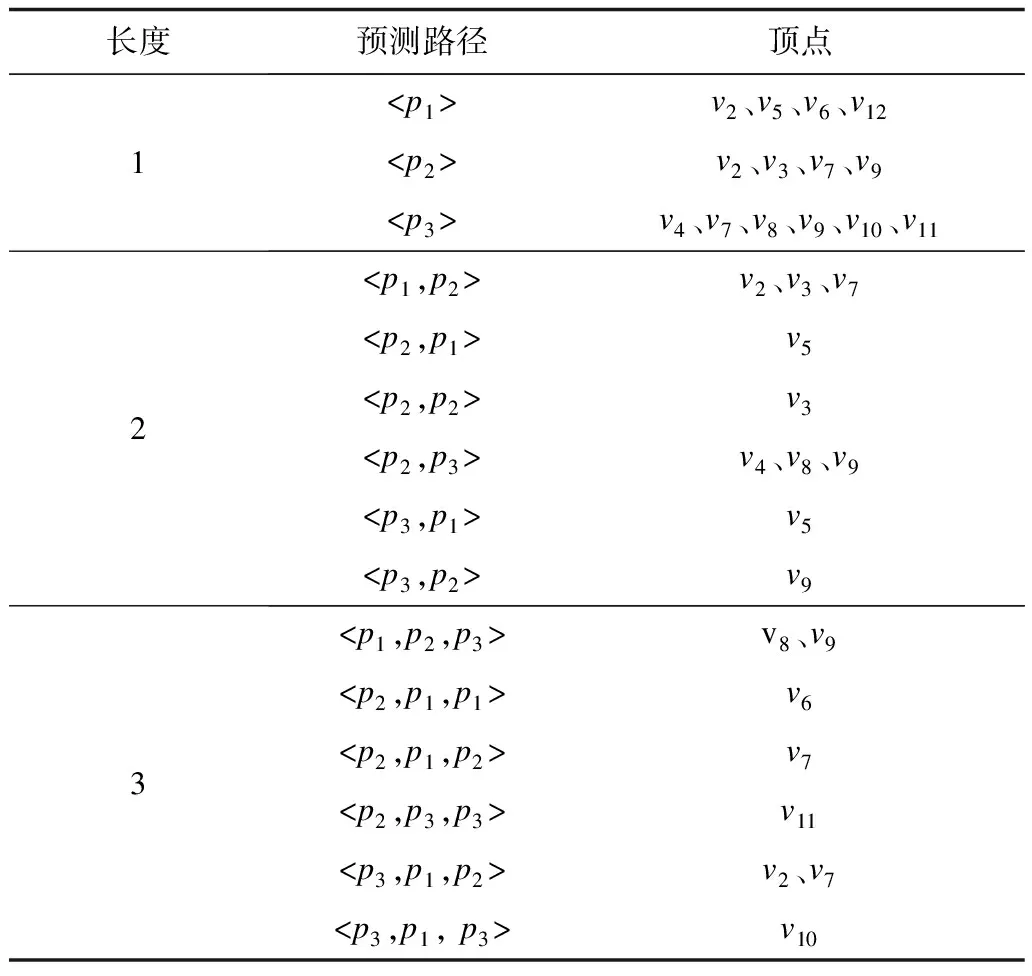
表3 屬性路徑索引指向的頂點
本文使用前綴樹結構存儲屬性路徑索引,前綴樹中的每一節點有一個指向對應謂詞路徑的節點列表的指針。該屬性路徑索引結構與信息檢索中的倒排索引有些類似。每個入邊屬性路徑可以看作是倒排索引的一個單詞,節點列表相當于倒排索引中排序的文檔ID號。屬性路徑索引中有大量重復的部分,如圖5所示,
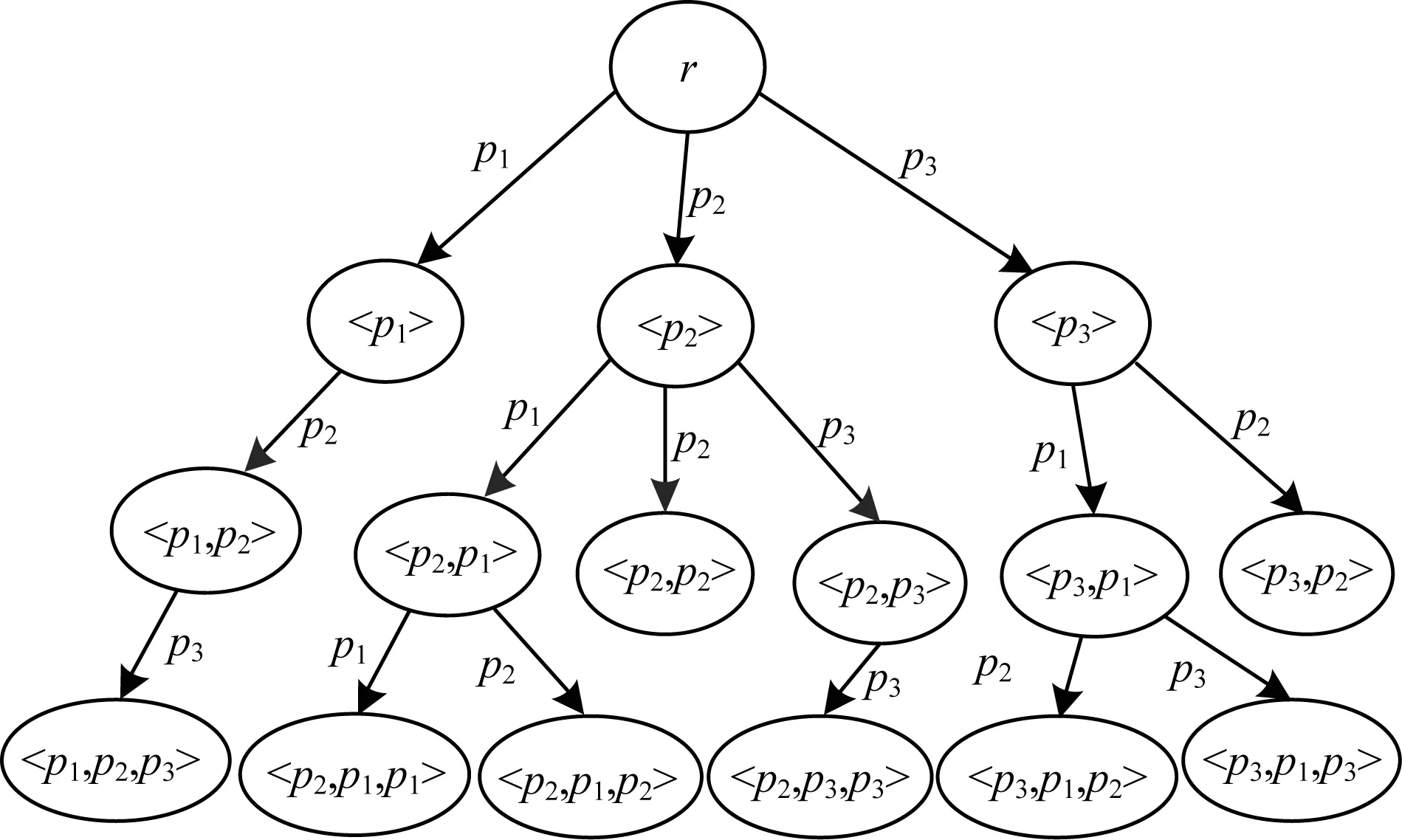
圖5 屬性路徑索引的前綴樹
圖6所示為當SPARQL查詢中含有謂詞為變量的聯結的情況。把謂詞變量當作一個特殊的謂詞處理,用pv代替。例如,在圖6中,頂點“?v4”的所有入邊屬性路徑為
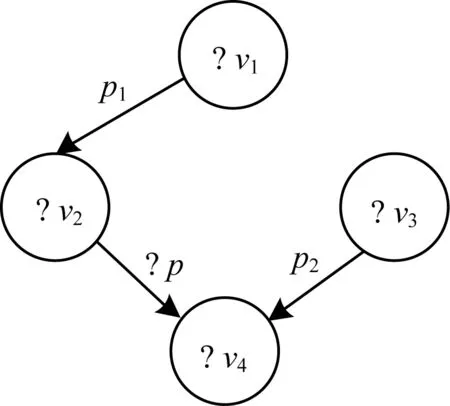
圖6 含有謂詞變量的SPARQL查詢
本文的兩階段查詢處理算法描述如下:
算法兩階段SPARQL查詢優化算法
輸入SPARQL查詢queryStr,屬性路徑前綴樹Trie
輸出合并聯結后的結果集Results
1.Parse queryStr;
2.Block queryStr into n blocks;/*對所有的聯結進行分塊,把含有公共變量的聯結劃分為一塊*/
3.For i←0 to n-1
4.Filter out joins with (?S,P,O) by get Variable Selectivity(queryStr.variable[i]) in order;/*對每個分塊中(?S,P,O)的聯結利用選擇度進行過濾*/
5.end For
6.For each variable v∈Variables
7.filterList←getVertexList(Trie,v);
8.Combine Results using filterList;/*Variables存放queryStr中的所有變量,通過前綴樹Trie,用每個變量的最長入邊屬性路徑過濾冗余的節點,并對過濾后的結果集Results進行合并*/
9.end For
10.Output Results;
該算法主要分為3個部分:
1)對輸入的SPARQL查詢進行分析并分塊(算法第1步和第2步)。
2)對于塊內的每個形如(?S,P,O)的三元組模式,利用選擇度函數getVariableSelectivity進行過濾(算法第3步~第5步),在該階段內利用選擇度函數將對形式為(?S,P,O)的聯結進行重新排序,首先執行當前查詢模式中聯接代價最小的查詢模式,盡可能地降低在查詢過程中產生的中間結果的數量。
3)對剩余的三元組利用屬性路徑索引Trie進行過濾(算法第6步~第9步),這是第2輪的中間結果過濾,因為屬性路徑至少包含一個三元組模式,所以利用屬性路徑過濾能夠比單個三元組模式過濾掉更多的中間結果,最后輸出顯示合并后的結果(算法第10步)。
本文算法的時間復雜度主要由第6步~第9步決定,為O(n×e),其中,n為輸入的SPARQL查詢中變量的數量,e為SPARQL查詢中每個變量的平均入邊數量。算法的時間受SPARQL查詢中變量的數量以及變量的入邊數量影響。
3 實驗與結果分析
本文實驗使用公開數據集LUBM、YAGO2、SPARQL基準數據集(SP2B)[17]及DBpedia SPARQL 基準數據集(DBSPB)[18],并用開源的RDF-3X[4]系統(0.3.5版本)、TripleBit[12]做比較。通過LUBM的generator,產生了10 000個大學的LUBM數據集。表4是這4個數據集的統計信息。其中,
YAGO2包含94個謂詞,LUBM和SP2B分別包含17個和77個謂詞,DBSPB包含39 675個謂詞。DBSPB是多個領域數據集的合并,YAGO2是一個異構數據集Wordnet和Wikipedia的合并,而LUBM和SP2B則是關于同類領域關系的描述。
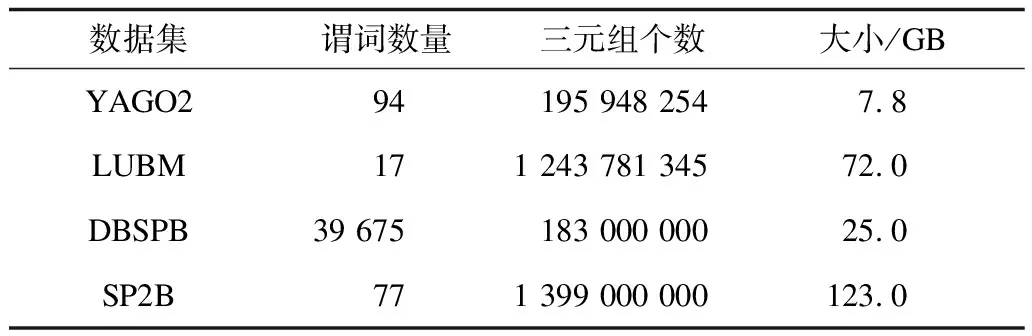
表4 數據集信息
表5顯示了最大長度為3的屬性路徑索引信息,包括屬性路徑索引指向的節點數量以及整個索引的大小。因為LUBM數據集具有相對單一結構化的模式特點,所以其包含較少的節點。
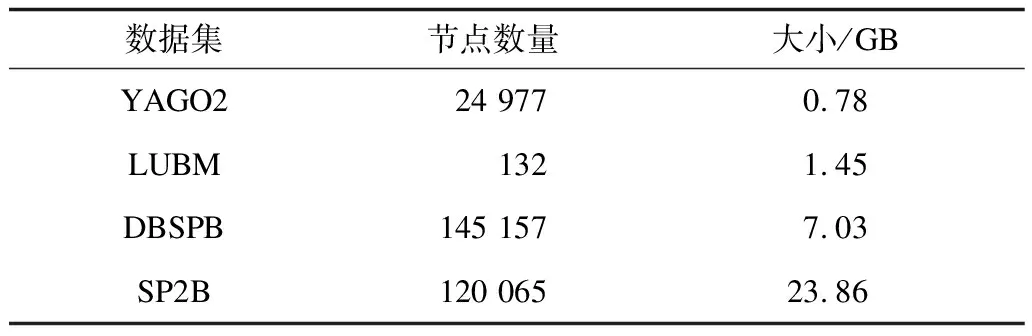
表5 屬性路徑索引信息
本文使用LUBM數據集基準中Q1~Q9進行比較實驗。表6顯示了2種方法對Q1~Q9產生的中間結果數量。通過比較可知:無論是簡單結構查詢還是復雜結構查詢如Q2和Q9,本文方法都比RDF-3X產生更少的中間結果;在查詢Q1與Q5上,本文方法與TripleBit方法產生的中間結果數量比較接近,因為沒有找到可過濾的屬性路徑索引。

表6 LUBM數據集中間結果數量
從YAGO2中,挑選屬性路徑長度為3~7的查詢各10個,計算平均查詢執行時間和中間結果數量。圖7顯示了平均執行時間和中間結果的數量隨著屬性路徑長度的變化情況。從中可以看出:除了屬性路徑長度為3時外,本文方法的執行時間和中間結果數量整體上都要低于RDF-3X,而且本文方法的執行時間和中間結果數量隨著屬性路徑長度變化增加緩慢;3種方法的執行時間曲線都隨著屬性路徑長度的增加而上升;本文方法雖然不是整體上都超過了TripleBit方法,但在路徑長度為3、4時本文方法與TripleBit方法的曲線非常接近,但本文的執行時間曲線比方法RDF-3X和TripleBit都平滑。TripleBit每次選擇最小的選擇性變量所對應的查詢模式執行,以此來降低在查詢過程中的中間結果集的大小,TripleBit性能降低的主要原因是查詢中包含更多聯結或者訪問更多選擇度索引塊。所以,對于屬性路徑長度較小的查詢,本文方法與TripleBit方法過濾效果相差不大,但對于屬性路徑較長的查詢,本文方法優于TripleBit方法。
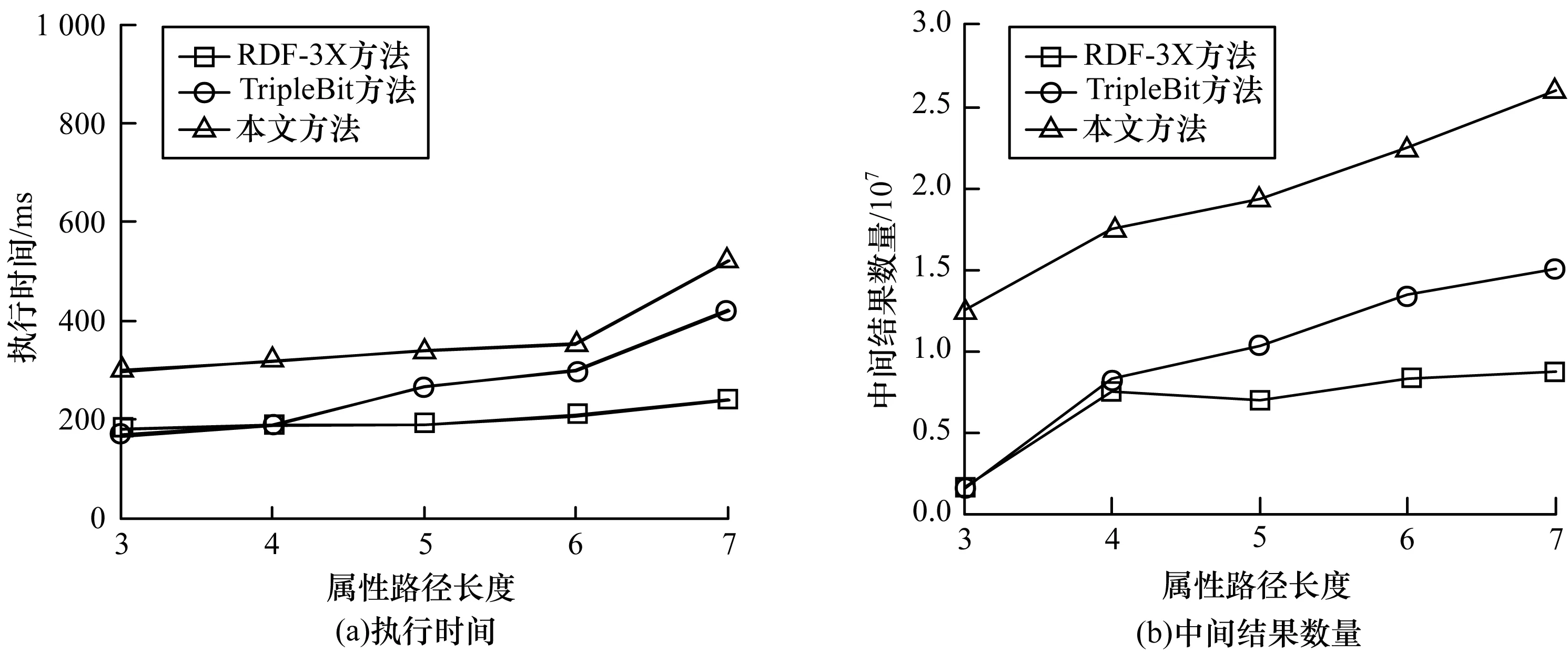
圖7 YAGO2數據集上的查詢性能比較
為驗證本文方法能夠適用于各種不同的RDF數據集,對數據集DBSPB和SP2B分別構建查詢Q10~Q13和Q14~Q17,查詢結果如圖8所示。這些查詢都有4次~5次的聯接次數并且有較長的屬性路徑。查詢的執行時間分別顯示在圖9(a)和圖9(b)中。從中可以看出,除了查詢Q10與Q17外,本文方法在這兩個數據集上實現的查詢執行時間都優于RDF-3X與TripleBit方法。查詢Q11、Q12、Q13、Q15、Q14及Q16在執行時間上明顯少于RDF-3X與TripleBit方法,主要原因是本文通過最長屬性路徑索引過濾掉大量無用的中間結果,TripleBit方法對于聯結比較多的查詢需要動態計算最優選擇性的三元組模式并且需要訪問更多的索引塊。對于查詢Q10與Q17,雖然沒有TripleBit方法執行效率高,但是相差不大,沒有超過的原因是在前綴樹索引結構中沒有找到可過濾的屬性路徑。
圖8 本文方法在DBSPB和SP2B數據集上的SPARQL查詢結果
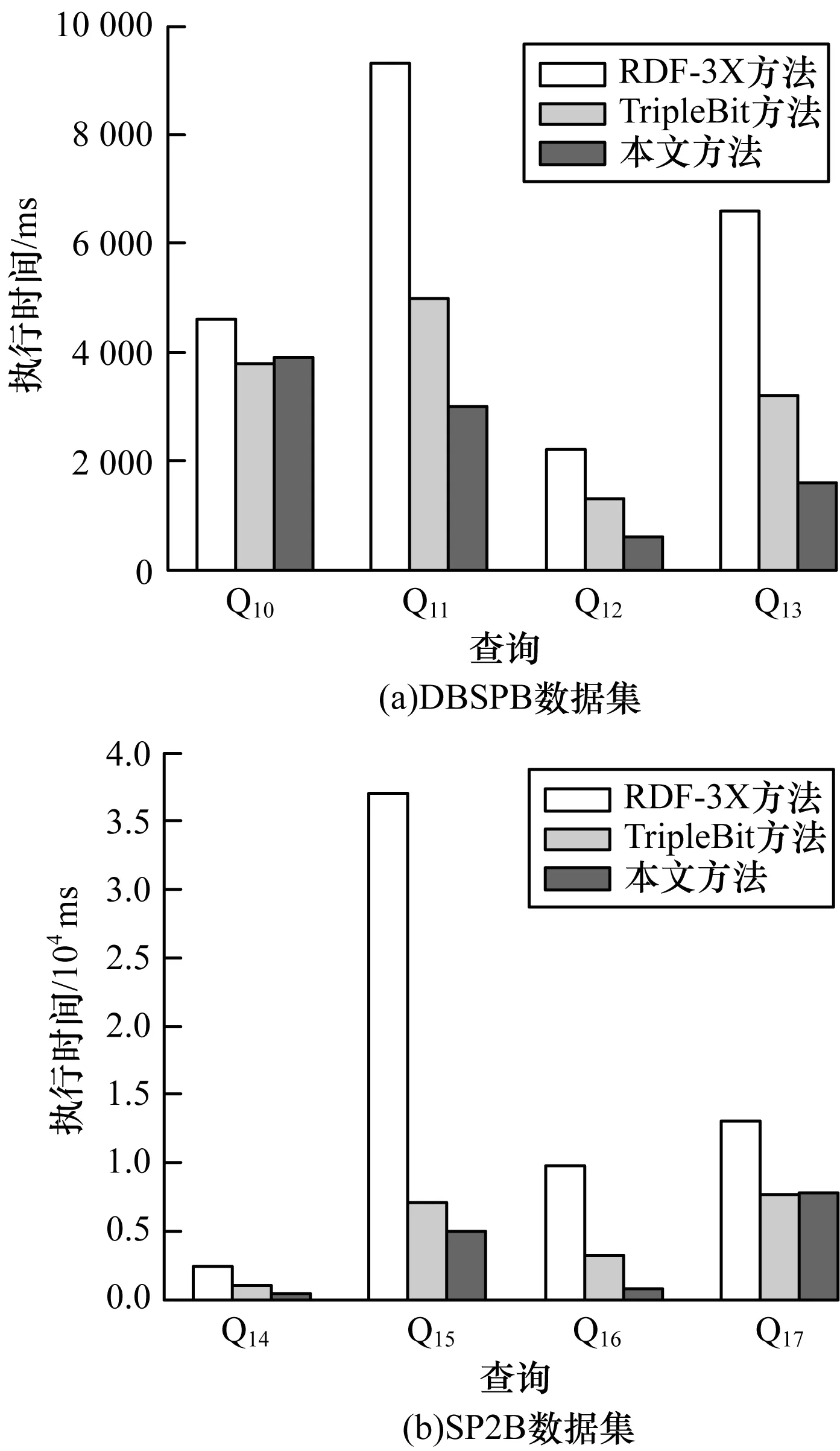
圖9 查詢執行時間比較
4 結束語
本文提出一種兩階段的SPARQL查詢處理方法,一方面通過計算選擇度找出聯結數最小的聯結,另一方面利用屬性路徑索引過濾冗余中間結果。雖然屬性路徑索引的存儲耗費了一定的存儲空間,但大幅提高了SPARQL查詢的執行效率。在不同的數據集上的實驗結果驗證了本文方法對中間結果過濾的可行性、有效性。未來將進一步提高聯結選擇度計算的準確度,并將本文方法運用到MapReduce等并行及分布式環境中。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
