基于改進極端隨機樹的異常網絡流量分類
2018-11-20 06:08:38韋海宇柯文龍
計算機工程 2018年11期
韋海宇,王 勇,,,柯文龍,俸 皓
(桂林電子科技大學 a.計算機與信息安全學院; b.信息與通信學院; c.廣西高校云計算與復雜系統重點實驗室; d.廣西可信軟件重點實驗室,廣西 桂林 541004)
0 概述
隨著計算機網絡服務技術的迅速發展,計算機網絡安全已經成為一個備受關注的問題,如何快速、準確地發現網絡中的異常流量已經成為目前網絡安全管理的主要研究內容。異常網絡流量通常定義為偏離正常的網絡連接,主要包括網絡掃描、網絡攻擊、病毒感染等[1]。檢測、監控網絡安全狀態,進行網絡流量分類十分有必要,但是在海量的網絡流量數據下,異常網絡流量相對來說非常少,因此,識別少量異常流量樣本是一項具有價值的研究。
近年來,機器學習算法快速發展,并被廣泛應用到網絡流量分類中。機器學習分類是一種有監督學習,首先需要提取數據樣本,根據標簽從數據集中學習,通過訓練生成分類模型,然后將新的數據導入到分類模型中進行自動分類,分類的效果取決于分類樣本的特征屬性和分類模型的訓練。本文提出一種基于改進極端隨機樹的異常網絡流量分類方法,以期在大量網絡流量情況下提高對少量異常網絡流量樣本的識別率。
1 相關工作
文獻[2]提出一種基于C4.5決策樹和支持向量機(Support Vector Machine,SVM)檢測異常流量的組合算法。首先根據C4.5算法對異常網絡流量進行分類,將其分為正常網絡流量和異常網絡流量,然后使用SVM算法對異常的網絡流量進行細分類,將其分為不同攻擊類別。該算法在KDD CUP 99數據集上能夠獲得較好的效果,但該數據集存在大量的重復數據,對模型的結果影響較大。
為了減少分類模型的訓練時間,文獻[3]首先根據主成分分析(Principal Component Analysis,PCA)方法對數據進行降維,然后使用隨機森林對異常網絡流量分類。雖然PCA能夠有效地減少網絡流量特征,但也會在一定程度上丟失一些重要數據特征。
文獻[4-5]通過設計基于C4.5的決策樹對異常流量數據進行分類。該方法簡單、計算速度快、分類結果較好,但對新的網絡環境適應性比較差。
文獻[6-7]基于層次聚類方法對數據進行特征選擇,其中文獻[7]基于低維數據使用SVM算法對流量數據進行分類,該方法在NSL-KDD數據集上可得到95.2%的分類準確率,但是在少量樣本的U2L類別上分類結果相對較差。
文獻[8]提出PSO-Random Forest的異常流量檢測算法,首先根據粒子群優化(Particle Swarm Optimization,PSO)算法獲得最優的特征組合,然后使用隨機森林算法對這些特征進行分類。該算法在KDD CUP 99數據集上能夠獲得很好的效果。
在異常網絡流量分類的問題上,研究者關注分類準確率和時間效率,致力于結合各個算法的優點提高分類的精度,減少分類模型訓練時間。
文獻[9]首先提出一個基于密度比的數據特征轉換算法以獲得更好的特征表示,然后基于SVM實現網絡流量的分類。該方法在NSL-KDD數據集上得到了99.28%的準確率。
文獻[10]提出超圖遺傳算法和SVM算法的組合算法,其中超圖遺傳算法對模型和數據特征選擇進行參數優化。該文在實驗中對使用特征選擇算法后的數據和原始數據進行分類結果比較,結果表明特征選擇可以更好地提高分類檢測率。
文獻[11]提出基于詞袋模型聚類的異常流量識別方法,首先根據K-Means算法對流量做均值聚類,得到網絡流量的關鍵特征,然后利用SVM、C4.5等分類算法進行識別,平均識別率達到90.9%。
文獻[12]研究集成學習方法在異常網絡流量中的應用,重點介紹Adaboost算法、Boost算法等,該文總結得出集成方法在異常網絡流量分類中效果更為明顯,能達到81%左右的準確率。
文獻[13]首先根據分類與回歸樹(Classification and Regression Tree,CART)算法將網絡流量分為異常流量和正常流量2種流量類型,然后比較SVM、Naive Bayes、Neural Network在攻擊類別分類中的效果。利用該方法在NSL-KDD數據集上對DoS、R2L和Probe的分類獲得了96%的準確率,但該文未研究U2R攻擊類別的分類。
綜上所述,目前的異常網絡流量分類方法研究主要集中在決策樹、SVM等機器學習方法,但是仍存在一些問題。多數研究只考慮在整體上評估分類效果,而對于少量樣本的類別并沒有過多關注。此外,決策樹對少量樣本類別的數據容易過擬合,或者是算法模型復雜、訓練時間長、使用的實驗數據存在樣本重復等。針對以上問題,本文提出一種基于極端隨機樹的改進算法(IET)。本文的創新點在于:1)結合極端隨機樹(ET)和隨機森林算法(RF)的優點,改進分類模型的訓練方法和最后的投票決策[14]過程;2)更全面地訓練少量樣本的類別,同時保持算法模型基分類器的隨機獨立性。
2 極端隨機樹算法
文獻[15]提出極端隨機樹算法,該算法是一種集成算法,用{T(K,X,D)}表示,其中,T表示最后的分類器模型,D為數據樣本集,K為基分類器的數量,每個基分類器根據輸入樣本X={x1,x2,…,xM}產生預測結果,最終通過投票確定最后的分類類別。ET算法的具體步驟如下:
步驟1給定原始數據集D、樣本數量N、特征數量M,在極端隨機樹的分類模型中,每個基分類器使用全部的樣本進行訓練。
步驟2根據CART決策樹算法生成基分類器。為增強隨機性,在每個節點分裂時隨機從M個特征中選擇m個特征,對每個節點選擇最優屬性進行節點分裂,分裂過程不剪枝。對分裂產生的數據子集再迭代執行步驟2,直至生成一棵決策樹。
步驟3重復步驟1和步驟2迭代K次,生成K棵決策樹以及極端隨機樹。
步驟4對生成的極端隨機樹使用測試樣本生成預測結果,對所有基分類器的預測結果進行統計,利用投票決策的方法產生最終的分類結果。
ET算法具有如下優點:1)是一種集成學習算法,其通過投票決策產生預測結果,具有更好的泛化能力;2)使用全部數據樣本訓練基分類器,使得所有樣本都被訓練;3)在節點分割上隨機選擇分割屬性,增強了基分類器間節點分裂的隨機性。但是該算法也有些不足,表現在每棵決策樹都使用全部樣本進行訓練模型,這使得決策樹間的隨機性有所降低,對結果預測造成影響。為既能保證模型得到充分訓練,又能提高基分類器間的獨立性,本文提出改進的極端隨機樹算法。
3 改進的極端隨機樹算法
本文在訓練分類模型的過程中,對一部分基分類器采用全部樣本構建決策樹,另一部分基分類器采用經過重采樣的樣本來構建決策樹,同時在最后投票結果中,對于使用重采樣樣本進行訓練的基分類器,采用加權投票方法,優化分類器的投票過程,形成改進的極端隨機樹算法。具體算法框架如圖1所示,其中分類過程包括3個部分:特征選擇,裝配訓練模型,投票代理決策。

圖1 改進的異常網絡流量分類算法框架
3.1 特征選擇
特征選擇的具體步驟如下:
步驟1特征預處理。首先將數據的空值特征進行替換,在本文中,將空值特征用0替換,消除網絡流量類型偏差的影響;其次,為統一數據格式,本文將網絡協議、服務類型、網絡狀態等名義變量映射為數值索引,例如協議內容包括{icmp,tcp,udp},對應的索引地址為{0,1,2}。
步驟2計算特征值的信息增益率。例如設定A為網絡協議的某個特征,數據集D中特征A的信息增益率gainRation(D,A)根據式(1)計算。
(1)
要求得特征A的信息增益率,應已知該屬性的信息熵gain(D,A)和信息分裂度量splitInfo(D,A)。gain(D,A)根據式(2)計算。
(2)
其中,pa為特征A各類劃分的頻率,entropy(D)和entropy(A)的計算方法如式(3)所示。
(3)
在式(3)中,C表示在數據集D有C種類別,本文中C取{0,1,2,3,4},分別表示DoS、Probe、R2L、U2R和Normal,pc表示C=c在總樣本中的占比,該表達式表示關于第c個分類的信息度量。相應地,在求entropy(A)時,C表示在特征A上可劃分的類別,pc表示該類別數據子集與總數的占比,最后求得關于特征A的信息熵。
根據式(4)計算特征A中的分裂信息度量:
(4)
步驟3特征排序和選擇。根據樣本特征的信息增益率對其進行排序,選擇相關性較大的特征,同時去除相關性較小的特征,在本文中根據閾值選擇網絡流量特征。
3.2 改進的訓練模型
本文算法主要是改進訓練方法和模型,具體步驟如下:
步驟1選擇特征向量。計算數據樣本特征值的信息增益率,并對其建立特征值的索引信息。
步驟2生成字典對象,在訓練極端隨機分類樹時使用字典保存基分類樹模型。
步驟3裝配訓練模型。采用與其他算法不同的組裝方法,在構建的訓練模型中,一部分基分類器使用全部的訓練樣本,另一部分基分類器使用重采樣的方法產生訓練樣本。該過程的目的是既能全面訓練少量樣本,又能增強基分類器間的獨立性,以達到更好的預測結果。本文首先生成10以內的隨機整數,對2求余,若為0,則采用抽回樣本進行訓練;若為1,則采用全部樣本進行訓練。在訓練過程中,使用字典T←{t1,t2,…,tk}記錄每棵決策樹的訓練,其中ti表示每個基分類器的分類規則,同時記錄訓練樣本的信息。
步驟4訓練分類器。如果輸入樣本低于節點最低樣本或者經過規則可以確定分類類別,則生成葉子節點,否則隨機選擇若干個候選屬性A←{a1,a2,…,am},產生相應的候選樣本子集Dm={D1,D2,…,Dm}。
步驟5選擇分裂的屬性值,該過程與CART的分裂規則一致,但是在選擇節點分裂的特征值時根據分裂分數最高,即max(score(A,D))的屬性進行分裂,產生2個數據子集數據。評估分裂分數是特定歸一化后的信息增益計算方法,通過式(5)計算。
(5)

步驟6分別對左子樹和右子樹迭代執行上述步驟,生成決策規則,直到滿足條件為止。
步驟7對上述步驟重復K次。
3.3 改進的投票方法
在改進的分類器模型中,對于使用重采樣數據進行訓練的基分類器采用加權投票表決方法。在抽回采樣中,使用bagging方法從原始訓練集中有放回地抽取樣本,形成新的樣本子集,該樣本被稱為Out-of-Bag(OOB)數據。對于原始數據樣本,每個未被抽取的概率為:
(6)
將當前決策樹的OOB數據記為Ot,由于決策樹訓練過程是有監督的,通過比較當前分類器的分類結果和真實樣本,得到Ot中分類正確的樣本個數,記為Ott。由此,可得到當前決策樹t的分類準確率:
(7)
將決策樹OOB數據的分類準確率pt作為對應分類決策樹的權重,對樣本x的分類結果進行加權統計,對于預測的類別投票記為:
(8)
其中,Tt,x表示分類正確或者錯誤,取值1或者0,最后得票最多的即為最后的分類結果。
4 實驗與結果分析
4.1 實驗數據
KDD99數據集于1999年產生,由于該數據集重復樣本比較多,因此本文使用NSL-KDD數據集[16]。該數據集是在KDD99數據集上進一步整理得到的數據集,共有41個網絡流量特征,包括連接特征、時間特征、數據包統計等信息。從數據類型上看,該數據集有3個名義數據、6個二分類屬性和32個數值類型。協議類型有ICMP、UDP、TCP 3種;狀態類型有OTH、REJ、RST、OS0等16種;服務類型有IRC、FTP、whois等70種;攻擊類型有DoS、Probe、R2L和U2R 4種。該數據集的攻擊類別信息如表1所示。

表1 NSL-KDD數據集攻擊類別
本文對NSL-KDD數據進行混洗后按6∶4劃分進行實驗,即訓練集占總數據的60%,測試集占40%。在本文中,所有對比的實驗結果都是基于同組數據的情況下進行,數據樣本分布如表2所示。

表2 實驗數據樣本分布
實驗的硬件配置為IntelCore(TM) i5-4210H@2.90 GHz,4 GB RAM,軟件配置為Windows 10 64位操作系統,Scikit-Learn 0.18。
4.2 分類性能評估方法
在特征選擇過程中,主要是計算流量特征的信息增益率,根據信息增益率值從大到小進行排序和篩選。
為有效評估分類效果,實驗中對于分類結果的評價指標使用精確率和召回率。分類精確率計算公式如下:
(9)
其中,TP表示在正樣本中分類正確的樣本,FP表示將負樣本分為正確的樣本,FN表示正樣本數分為負樣本數。召回率計算公式如下:
(10)
4.3 特征選擇結果
本文實驗計算屬性的信息增益率,并對其進行排序,圖2列出了數據集中各個特征信息增益率的值以及排序的結果。從圖2中可以看出:將信息增益率閾值調整到0.01時,最后獲得39個數據特征;將閾值調整到0.1時,獲得33個數據特征,其中srv_serror_rate的信息增益率最高,達到0.507,而num_outbound_cms和is_host_login的信息增益率為0。

圖2 特征選擇排序結果
4.4 分類結果對比
根據不同的數據集驗證極端隨機樹(ET)、隨機森林(RF)和本文提出的改進極端隨機樹方法(IET),比較這三種集成算法的分類效果,從各個網絡流量類別分類的精確率、召回率和時間上進行比較,最后驗證基分類樹個數與精確率的關系以及基分類器與時間的關系。本文提出的算法基于開源機器學習庫Scikit-Learn[17],對其中的極端隨機樹算法進行改進并編碼實現。
將本文算法同其他集成算法的分類結果相比較,取Scikit-Learn中的極端隨機樹和隨機森林算法作為對比,分別計算未經特征選擇的數據、特征的信息增益率大于0.01的數據,以及數據特征的信息增益率大于0.1的數據,比較同類數據集下3種算法的精確率p和召回率r。
從表3~表5中可以看出,對于5種流量類別的分類結果,3種算法對DoS、Probe這兩種攻擊類型的數據集上分類結果總體相差不大,精確率都能達到0.99,主要是該類數據的訓練樣本比較多,訓練過程比較充分,而R2L和R2R這兩類數據樣本則有所不同,具體數據比較如表中加粗部分所示。
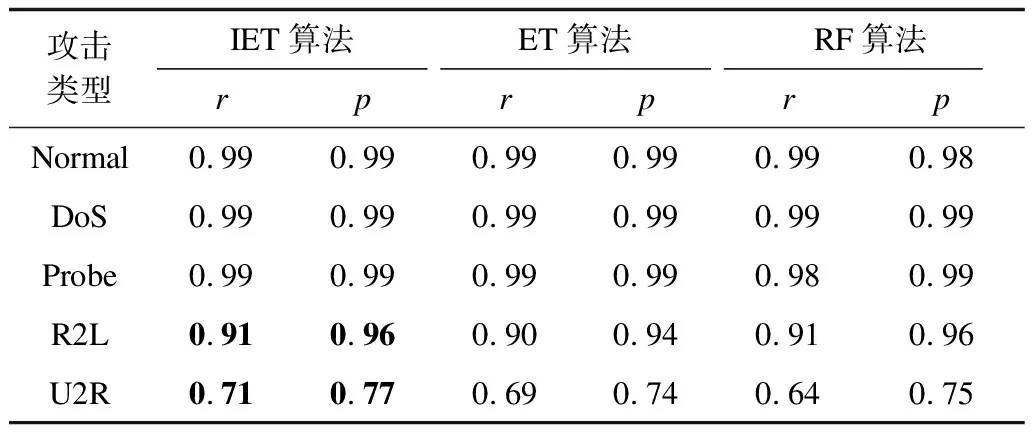
表3 3種算法在未經特征選擇的數據集上的結果

表4 3種算法在信息增益率大于0.01數據集上的結果

表5 3種算法在信息增益率大于0.1數據集上的結果
由表3可見:對于攻擊類別為R2L的網絡流量類型,本文算法召回率達到0.91,精確率達到0.96;對于U2R類型的攻擊類別,本文算法召回率達到0.71,精確率達到0.77,分別為該網絡類別最好的劃分結果。
由表4可見:對于攻擊類別為R2L的網絡流量類型,本文算法召回率達到0.92,精確率達到0.96;對于U2R類型的攻擊類別,召回率達到0.52,精確率達到0.86;在U2R上,IET算法的表現介于ET算法和RF算法之間,RF算法的精確率要高于IET算法,但是IET算法的召回率要高于RF算法,而IET算法與ET的算法相比,召回率稍低,但是精確率較高。
由表5可見:在R2L類別上,本文算法召回率達到0.92,精確率達到0.97;在U2R類別上召回率為0.46,精確率為0.86。
在建模時間上,本文算法和原始算法在使用實現4個線程同時工作時,設定基分類器的個數為180個,選不同的數據集進行實驗,訓練時間和預測時間的時間控制在1 min以內,結果如圖3所示。可以看出,本文算法建模時間始終保持在極端隨機樹和隨機森林之間,能夠保證算法在時間上的可行性。

圖3 3種算法在不同數據集上的建模時間
圖4顯示了特征維度與總體分類精確率的關系。可以看出,本文算法在閾值為0.01的數據上,整體分類準確率的表現比原始數據維度的結果更優,達到0.995 6,而當篩選的閾值為0.1時,分類結果相比于原始數據與閾值為0.01時略差一些。

圖4 基分類器個數與精確率的關系
圖5顯示了基分類器個數與時間的關系。可以看出,本文算法在設定閾值為0.01時,建模時間相對更短,比選擇篩選閾值為0.1的數據建模時間更長,表明在異常網絡流量的特征選擇過程中,使用信息增益率進行特征選擇是有效且可行的。

圖5 基分類器個數與建模時間的關系
5 結束語
為提高對少量異常網絡流量樣本的分類準確率,本文提出一種基于改進極端隨機樹的分類方法。首先在特征選擇部分約減數據維度,除去不相關的數據特征,然后基于改進的極端隨機樹構建異常流量分類模型。實驗結果表明,本文方法在重組的NSL-KDD數據上可達到0.995 6的分類精確率,在異常流量分類中相對于其他集成分類方法準確度更高,同時在少量樣本條件下的分類結果表現更優。
本文算法尚有一些改進的地方,例如在原始數據樣本上與其他算法相比,算法的魯棒性相對較好,但不顯著,原因在于數據分布很不均衡。未來將在實際的網絡流量上驗證本文算法,進一步提升模型的分類性能,同時對其進行并行化訓練和預測,減少訓練和預測時間。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
