單機多核計算機環境下的遙感圖像并行處理技術
2018-11-23 07:35:44陸冬華趙英俊張東輝
地理空間信息 2018年11期
陸冬華,趙英俊,張東輝,秦 凱
(1. 核工業北京地質研究院 遙感信息與圖像分析技術國家級重點實驗室,北京 100029)
遙感對地觀測作為一項重要的空間探測技術,自20 世紀60 年代以來逐漸發展,已在氣象、農業、林業、資源、環境、生態、水利、海洋、大氣、水文、災害、全球變化等民用領域,以及情報偵查、戰場監視、導彈制導、隱身等軍用領域發揮了積極作用[1]。遙感傳感器技術的發展,使得獲取的遙感數據空間分辨率和光譜分辨率不斷提高,數據量不斷增大,因此需要更強的計算資源對其進行處理[2]。美國最先進的WorldView3衛星遙感數據,其全色空間分辨率為0.3 m,多光譜16個波段的空間分辨率為1.24 m[3],每100 km2融合后的數據約為17 GB;加拿大Itres公司的航空高光譜傳感器CASI和SASI,分別擁有32和100個波段[4],相對飛行高度為1 000 m時,空間分辨率分別為0.49 m和1.22 m,長度為10 km的單條測線獲取的數據分別約為8 GB和15 GB。目前大多數的商業軟件均未采用多線程數據處理技術,因此對數據量巨大的遙感圖像進行分析時需要耗費大量的計算時間。
國內外學者對多線程和并行處理遙感圖像方面開展了相關研究工作。QIN C Z[5]等利用多線程的方式對存儲在文件系統中的遙感數據進行并行讀寫,降低了數據讀寫在遙感影像處理中占用的時間;劉世永[6]等利用MPI技術在超微高性能計算機上實現了多線程原始柵格影像的標準瓦片輸出;吳煒[7]等針對集群計算機實現了高分辨率遙感影像的多尺度分割;周海芳[8]等實現了基于GPU的圖像配準并行計算;LYU Z H[9]等針對高性能集群實現了遙感圖像聚類分析。
遙感圖像并行處理面臨兩個難題[5]:遙感數據量巨大,從計算機硬盤調入內存需耗費大量時間;存儲遙感數據的文件格式種類繁多。目前國內外的研究主要側重于多臺計算機或集群的分布式計算以及GPU并行計算,該類方法雖可大幅提高數據的處理效率,但由于大多數科研人員仍以單臺計算機運算為主要工作方式,且編程復雜度高,分布式需綜合考慮不同計算機之間的數據傳輸與協同問題,GPU的程序開發需綜合考慮GPU內不同類型顯存的性能差異以及顯存與內存之間傳輸數據的低效率問題[10]。隨著計算機硬件的發展,Intel 和AMD等多核處理器的市場占有率逐步上升,而以往的分類算法一般為串行執行,無法發揮多核處理器的計算優勢[11]。因此,本文重點針對單機多核環境下的遙感圖像并行處理關鍵技術進行研究,一方面利用空間數據抽象庫(GDAL)開源庫解決不同格式數據的輸入輸出問題,另一方面通過OpenMP解決單臺計算機CPU資源的充分利用問題,降低了開發難度,有效提高了圖像處理速度。
1 不同類型遙感數據的輸入和輸出
由于多源遙感數據來自不同的衛星中心和傳感器,遙感數據格式缺乏統一標準,不同的傳感器數據具有不同的文件格式,甚至同一傳感器,因其來源不同,文件格式也略有差異[12]。為了解決這一問題,1998年加拿大的Warmerdam F開始了GDAL項目的編寫工作,并得到了許多個人和團體的支持[13]。截至目前GDAL已能支持超過150種空間數據格式,并被ESRI的ArcGIS10、Google Earth,跨平臺的GRASS GIS 系統等多家遙感和GIS軟件使用[14]。
GDAL 是一個獨立的專業開源庫,是在X/MIT 許可協議下的開源柵格空間數據轉換庫[13]。GDAL 的特點為[15]:①可擴展性、可移植性較好,若想支持某種新的數據格式,只需添加該格式驅動程序即可;②API 功能全面,可嵌入到其他程序中;③可跨平臺運行;④支持常用的空間數據格式。
GDAL讀寫柵格數據最主要的核心類如圖1所示。GDAL讀寫文件操作流程如圖2所示。
GDALDataset類繼承自GDALMajorObject,負責管理存儲在硬盤上不同文件格式的遙感數據,利用GDALDataset中的函數可獲取遙感數據的元數據信息、投影坐標信息、波段數量等;并可利用該類中的RasterIO函數完成多波段數據讀寫操作。
GDALDriver類是數據格式的抽象,每種格式均會生成GDALDriver的一個實例,所有屬性和方法均來自于其對應的GDALDataset類[16],通常用于創建不同格式的遙感數據文件。將遙感數據格式的名稱傳遞給GDALDriver類,其將裝載相應格式的信息,并創建相應的GDALDataset類,實現對文件的讀寫。
GDALRasterBand類負責管理GDALDataset類中的單一波段,獲取該波段的信息和數據,實現數據的讀寫操作。

圖2 GDAL讀寫文件操作流程圖
2 OpenMP共享存儲編程
OpenMP 是由世界上主要的計算機硬件和軟件廠商提出的標準,跨平臺、可伸縮的模型為并行程序的設計者在桌面電腦和巨型機上開發并行程序提供了簡單靈活的接口,規范了一系列編譯指導語句、子程序庫和環境變量,在不降低性能的情況下克服了機器專用編譯指導帶來的移植性問題,得到了各界的認可。自發布以來,OpenMP已得到工業界和學術界的大力推動,成為共享主存多處理機上并行編程的事實標準。理論上,OpenMP更好地利用了共享內存體系結構,允許運行時調度,避免了消息傳遞的開銷,并提供了細粒度和粗粒度運行機制[17-18]。
并行計算的主要實現過程為:主進程(處理器)將一個大任務(待處理數據)分派到若干個子進程(處理器)上進行處理,再由主進程負責收集不同子進程的數據處理結果并進行組合,以達到多處理器共同完成某一任務的目的[19]。首先由主線程執行程序的串行部分,再由派生出的其他線程執行程序的并行部分。相對于其他并行算法而言,OpenMP并行算法的開發十分簡單,即便是已開發的單線程算法也十分容易改造,無需程序員進行復雜的線程創建、同步、負載平衡和銷毀等工作。
OpenMP多線程的編寫非常簡單,包括兩種方式:①在循環體for(int i=0;i<N;i++)結構的前一行加入#pragma omp parallel for標識;②通過#pragma omp parallel{…} 標記并行塊范圍。系統將根據當前線程數自動對任務進行分配,利用omp_set_num_threads(int num)可設置并行區中活動的線程個數。使用OpenMP時,需在包含文件中加入函數庫<omp.h>。常用的函數和編譯指導語句如表1[20-21]所示。

表1 OpenMP常用函數和編譯指導語句
3 遙感圖像單機并行化處理
遙感圖像并行化處理的前提是遙感圖像各部分計算不存在依賴關系,即在串行計算時,先計算得到的結果不對后計算得到的結果產生影響。遙感所涉及的算法種類繁多,大多可實現并行化處理,如圖像變換、圖像配準、圖像融合、目標提取等;但各方法處理過程完全不同,因此并行化算法的開發也不盡相同。為了降低算法的并行化難度,突出遙感并行化算法的一般過程,本文以Majority濾波和局部均方差計算為例進行闡述。
3.1 遙感圖像的分塊
由于遙感圖像輸入輸出數據占用了大量的磁盤空間,無法一次性將所有數據讀入內存,因此必須將其進行分塊處理,每次僅讀取數據的一個分塊到內存中,處理后再輸出到磁盤空間。分塊方法通常包括行優先、列優先和平均分塊[5]3種。行優先處理方法,根據內存大小,將遙感圖像分成行數相近的若干個數據塊;列優先處理方法,根據內存大小,將遙感圖像分成列數相近的若干個數據塊;平均分塊處理方法,根據內存大小,將遙感圖像分成大小相近的數據塊,每個數據塊中數據的行數和列數相當。
處理過程中,由于Majority濾波和局部均方差計算均需對M×M窗口內的像素值進行統計和計算,為了保證分塊數據邊界計算的正確,輸入的數據應在分塊的基礎上,在上下左右各增加(int)(M/2),即若第i個分塊的左上角坐標為(xoff, yoff),大小為(xBlockSize,yBlockSize),則讀取的數據范圍應為(xoff-(int)(M/2),yoff-(int)(M/2)),大小應為(xBlockSize+M-1,yBlockSize+M-1),其中M為基數。
3.2 遙感并行算法的實現
首先利用GDAL打開待處理的圖像文件,讀取圖像的行列數、坐標信息、投影信息等基本信息;再計算分塊大小,確定每個分塊的左上角坐標以及行數和列數,利用OpenMP開始多線程計算,利用GDAL讀取分塊數據,并進行Majority計算;然后利用GDAL寫入處理后的數據;當所有線程都結束后,關閉遙感數據文件。
以數據分塊結果構建for循環體,并在for循環體前加入#pragma omp parallel for編譯指導語句,由于在每個線程均存在IO操作,而單機多線程的讀寫將顯著降低讀寫效率,因此在IO語句前加入#pragma omp critical原子處理編譯指導語句,避免多線程同時進行IO操作。for循環體前的編譯指導語句為:
//#pragma omp parallel for
for (int iBlock= 0; iBlock < 分塊總數 ;++ iBlock)
IO操作前的編譯指導語句為:
#pragma omp critical //原子處理
iBand->RasterIO(GF_Write, xOff, yOff, xBlockSize,yBlockSize,……);
4 數據實驗與分析
4.1 實驗算法
1)Majority算法,主要應用于遙感圖像分類的后處理。利用M×N的移動窗口,對窗口內的圖像像素值進行統計,將出現頻率最多的像素值設置為M×N窗口的中心像素值,M和N通常為基數。
2)局部均方差算法,主要應用于圖像增強和邊緣檢測。利用M×N的移動窗口,對窗口內的圖像像素值進行標準方差計算。
4.2 數據實驗
實驗平臺為惠普計算機圖形工作站Z800,內存為64 GB,2顆Intel Xeon x5690 CPU,主頻為3.46 GHz,每顆CPU為6核,開發平臺為Viusal Studio,將項目→屬性→VC++目錄→包含目錄和庫目錄中分別設置為GDAL的頭文件目錄和LIB文件目錄。將GDAL的Bin文件夾設置于環境變量中,或直接拷貝Bin文件夾中的文件到工程數據文件目錄,完成對GDAL庫編譯環境的設置;然后在C/C++的語言選項中設置OpenMP支持為“是(/openmp)”,完成對OpenMP編譯環境的設置。
以Majority算法為實驗對象,輸入圖像大小為3 000×2 500的單波段分類數據,輸出為Majority濾波結果,分別測試在窗口尺寸為3×3和5×5,并發線程數為1~12情況下的計算性能,如表2所示,可以看出,線程并發數由1增加到4的過程中,計算時間逐漸縮短,當并發線程增加到5之后,計算時間開始變長,達到12時計算時間最長。圖3更加清晰地反映了這一過程。
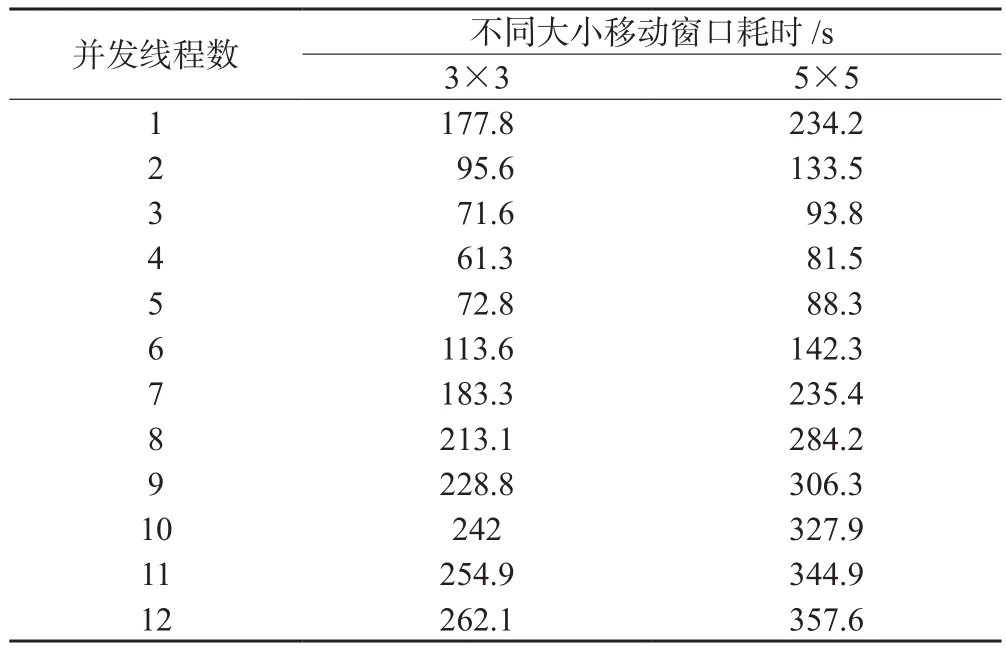
表2 Majority算法不同線程耗時表

圖3 Majority算法不同線程耗時曲線
Majority算法實驗說明盡管計算機CPU共有12個核心,但計算時間并未隨并發數量的增加而逐漸縮短,而是在4個線程并發時達到最高效率。為了進一步研究并行算法的效率,本文繼續對局部均方差算法進行實驗。
以局部均方差算法為實驗對象,輸入圖像大小為3 000×2 500的單波段16 bit整型灰度數據,輸出為方差計算結果,分別測試在窗口尺寸為3×3和11×11,并發線程數為1~12情況下的計算性能,具體如表3所示,可以看出,從線程并發數由1增加到11的過程中,計算時間基本上逐漸縮短,達到12后略有延長。圖4更加清晰地反映了這一過程。

表3 局部均方差算法不同線程耗時表
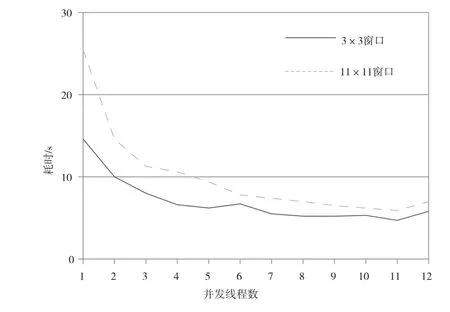
圖4 局部均方差算法不同線程耗時曲線
4.3 實驗結果分析
實驗結果表明,局部均方差算法通過OpenMP的加速效果較好;而當并發線程數為4時,Majority算法的計算效率最高。為了進一步分析導致實驗結果的原因,對參與計算的各函數進行逐一計算,分析各函數對并行效率的影響。其代碼主要結構為:
omp_set_num_threads(nThread);
#pragma omp parallel for
for(int i= 0;i<M;i++)
for(int j=0;j<N;j++)
{
//測試代碼
…
}
當測試代碼為空或僅包含基本的數學運算(加、減、乘、除、開方運算)時,并發線程由1增加至12時,程序運行時間逐漸縮短。
當測試代碼為int a[5000]或int *a=new int[5000/nThread]時,并發線程由1增加至6時,程序運行時間逐漸縮短,增加至7時,運行時間有所延長,但隨后又逐漸縮短。
當測試代碼為int *a= new int[10]時,程序運行時間與并發線程數的變化與Majority算法的規律相同,即1~4個線程,程序運行時間逐漸縮短,之后隨并發數增加程序運行時間逐漸延長。
Majority算法中使用了C++STL map類,該類對并發線程的加速也有較大影響,當測試代碼部分為map<int,int> statics變量聲明時,1~5個并發線程數時,程序運行時間縮短,隨后延長;將map<int,int> statics變量聲明放在for循環體之外,測試代碼僅為statics.find(2)時,1~4個線程程序運行時間逐漸縮短,之后隨并發數增加程序運行時間逐漸延長。
由此可知,影響Majority算法加速效果的主要原因為C++STL map類的變量聲明和查找函數;由map類中的哪個函數產生的影響還需進一步研究,但比較明確的是,程序在運行過程中申請內存或新建數組,會在一定程度上影響OpenMP的加速效果。
5 結 語
本文將GDAL開源庫與OpenMP相結合,開展了遙感數據在單機多核計算機環境下的處理實驗,利用GDAL實現了多種遙感數據的讀寫操作,利用OpenMP將串行程序改寫為并行程序。GDAL讀取遙感數據后,應根據內存大小對遙感數據進行分塊處理,利用OpenMP將for循環體并行化,可有效提高遙感圖像的處理效率。
實驗結果表明,并行程序對遙感圖像處理的加速效果與處理算法緊密相關,不同的算法需要調整并發線程數才能達到最佳的處理效率,單純的增加線程有時不但不能提高處理效率,反而會延長處理時間。
