自然環境下樹上綠色芒果的無人機視覺檢測技術
2018-12-04 09:03:00熊俊濤陳淑綿陳偉杰楊振剛
農業機械學報 2018年11期
熊俊濤 劉 振 林 睿 陳淑綿 陳偉杰 楊振剛
(華南農業大學數學與信息學院, 廣州 510642)
0 引言
農業航空技術開始于20世紀20年代,如今已經成為世界各國農業領域的重要技術之一[1]。由于無人機具有工作適用性、靈活性和機動性等優勢,近年來在農業領域得到了諸多應用,并逐漸成為現代農業工程一種新型設備[2-3]。
國內外關于農用無人機的研究主要集中在病蟲害的監控[4-8]以及農藥噴灑[9-13]方面,因無人機的空中作業機動性和靈活性較好,也逐漸應用于農作物產量估計上。李昂等[14]利用無人機拍攝從抽穗期到成熟期的水稻冠層影像,根據水稻圖像的顏色特征對圖像進行分割,提取出水稻穗數量并代入水稻產量估算公式進行估產。趙曉慶等[15]利用無人機獲取大豆多個生育期的高光譜數據,并對采樣空間尺度進行優化選擇,得到能較準確估計大豆產量的采樣空間尺度。HUANG等[16]使用無人機拍攝高分辨率的彩色圖像,利用從棉花田獲取的多個彩色圖像,提取三維點云數據,計算棉花的高度,從而估計棉花產量。此外,SENTHILNATH等[17]利用無人機獲取的高分辨率圖像估計西紅柿產量,CARL等[18]通過無人機獲取的圖像估計黑槐花和花蜜的產量,YU等[19]開發了一種基于無人機的高通量表型分析(High throughput phenotyping,HTP)平臺,在大豆生長階段收集高分辨率多光譜圖像,并設計了一種大豆產量估計模型。
從國內外研究可知,使用無人機估計農作物產量的研究對象主要集中于地面生長高度較低的水稻、大豆和棉花等農作物上,較少使用無人機進行樹上水果產量估計。而對樹上水果產量估計的研究,主要集中在使用地面拍攝設備獲取圖像[20-23]。對于較高且樹冠面積較大的果樹,使用地面拍攝設備只能拍攝到離地面較近樹冠的水果,而長在高處的水果,只能遠距離拍攝或者以仰視的角度拍攝,很難拍攝到樹冠頂部的水果。無人機則可以克服這個缺點,實現從空中拍攝到樹冠高處和樹冠頂部的水果。本文提出一種基于無人機的樹上綠色芒果的視覺檢測技術,利用無人機獲取芒果圖像,制作訓練集,訓練用于識別綠色芒果的YOLOv2模型,實現樹上芒果的準確識別,為芒果產量的智能化估計提供視覺技術支持。
1 圖像采集及圖像拼接
所用無人機為大疆PHANTOM 3 STANDARD型四軸飛行器,如圖1a所示,其自帶的相機拍攝圖像的分辨率為4 000像素×3 000像素,影像最大光圈是F2.8, 94°廣角定焦鏡頭,等效焦距20 mm,拍攝時手動控制在距離芒果樹1.5~2 m處進行拍攝,如圖1b所示。圖像拍攝時間為08:00—10:00,共拍攝471幅圖像用于圖像識別算法研究,為滿足樣本的多樣性,挑選出包含不同距離和光照情況的圖像,共挑選出360幅圖像,如圖2所示。隨機選取300幅圖像作為訓練集,剩余60幅圖像作為測試集。

圖1 圖像采集現場Fig.1 Image acquisition scence

圖2 無人機采集到的芒果圖像Fig.2 Mango images collected by unmanned aerial vehicle
為得到整棵樹的圖像,在采集圖像時,手動控制無人機在距離芒果樹1.5~2 m處拍攝圖像,分兩次拍攝樹的兩側,如圖3a所示。在采集單側圖像時,從樹的左上角開始拍攝,從上往下,如圖3b所示,按數字順序采集整棵樹的圖像,其中相鄰兩幅圖像的重疊位置用于圖像拼接,本文使用基于SURF的圖像拼接算法[24],按拍攝順序依次拼接圖像,得到整棵樹一側的圖像,結合兩側可以得到一棵樹完整的圖像。本文挑選5棵樹進行拍攝,先人工計算沒有被遮擋、直接可見的芒果數量,然后再進行圖像采集,用于驗證模型的有效性。

圖3 圖像采集Fig.3 Image acquisition
2 基于YOLOv2的綠色芒果視覺檢測方法
近年來深度學習在目標檢測領域取得了較大的進展,GIRSHICK等[25]提出了區域卷積神經網絡(RCNN),在VOC2012數據集上平均精度提高了30%,達到了53.3%。在RCNN的基礎上,GIRSHICK[26]和REN等[27]提出了快速區域卷積神經網絡(Fast RCNN)和超快速卷積神經網絡(Faster RCNN),在提高檢測正確率的同時增加了檢測速率,檢測速率達5 f/s。REDMON等[28]提出了YOLO模型,平均精度達63.4%,檢測速率達到45 f/s。隨后,REDMON等[29]在YOLO模型的基礎提出了YOLOv2模型,在VOC2007上平均識別精度(MAP)達76.8%,識別速率達到67 f/s。
參照文獻[30]的思想,將分類和定位整合到同一個網絡當中,與之前大部分目標檢測框架使用的特征提取網絡VGG-16相比,YOLO模型使用類似goollenet的網絡結構,計算量小于VGG-16,能在保證正確率的同時擁有較快的檢測速率,標準的YOLO模型檢測速率達到45 f/s,Fast YOLO模型檢測速率達到了155 f/s,但正確率略低于VGG-16。YOLOv2模型以Darknet-19為基礎網絡模型,包含了19個卷積層和5個最大池化層,在保持YOLO模型檢測速率的同時提升了檢測精度,使用分辨率為544像素×544像素的圖像時,YOLOv2模型在VOV2007數據集上可以在正確率比Faster RCNN高的情況下,處理速率達到40 f/s,如表1所示。
使用YOLOv2模型作為樹上芒果的檢測方法,先對300幅訓練集圖像進行人工標記,標記圖像中的感興趣區域(Region of interest,ROI),然后用標記好的圖像通過預訓練,調整YOLOv2模型網絡參數,最后用調整好的參數訓練YOLOv2模型網絡,如圖4所示。
2.1 標記訓練數據集
YOLOv2模型需要人工設置標簽,根據人工設置的標簽進行自我學習,要測試模型檢測的精度,也需要對測試集進行人工標記感興趣區域。所以在訓

表1 目標檢測模型性能對比Tab.1 Performance comparison of object detection box
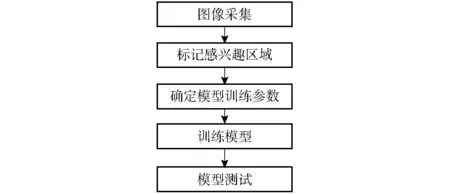
圖4 模型訓練流程Fig.4 Model training process
練模型之前,需要對訓練集和測試集圖像進行人工標記感興趣區域,并記錄標記的矩形框的右上角坐標和矩形框的長、寬作為YOLOv2的輸入。為了使模型有較高的檢測效果,標注的樣本中包含了不同光照角度和不同拍攝距離的芒果樣本,同時適當加入了遮擋的芒果。在300幅訓練集圖像中,共標記出2 542個芒果樣本,部分芒果樣本如圖5所示,其中順光樣本1 673個,占樣本總數的65.81%,逆光樣本869個,占樣本總數的34.19%,其中有遮擋的樣本中,順光樣本293個,逆光樣本125個,共有418個樣本,占樣本總數的16.44%。

圖5 訓練樣本示例Fig.5 Examples of training sample
2.2 模型參數選擇
訓練模型時,輸入圖像的分辨率、批處理量(batch)、學習率都會影響最終模型的檢測效果,因此在訓練模型之前,需要選擇合適的參數。本文訓練使用的操作系統為Ubuntu 16.04,訓練使用框架為Darknet,CPU為i7-8700,主頻為3.2 GHz,六核十二線程,內存32 GB,顯卡為GeForce GTX 1080,顯存為8 GB,使用YOLOv2官方提供的預訓練模型對數據集進行訓練。因為40 f/s的速率可以滿足實際應用的要求,而識別精度則越高越好,因此,輸入圖像分辨率設定為544像素×544像素。
2.2.1批處理量
在訓練模型的過程中,為準確計算損失函數對參數的梯度,需要對數據集上的每一個樣本進行計算,對于深度神經網絡而言,這樣做計算量會非常巨大。所以,一般在訓練深度神經網絡時,會分批從數據集中抽取少量的圖像,然后計算這批圖像的平均值,抽取圖像的數量即為批處理量(batch),但批處理量太小會造成模型無法收斂的情況,批處理量太大會使收斂速率變慢,因此要選擇合適的批處理量。本文分別選取16、32、64、128、256作為批處理量,其他參數使用默認值,其中學習率為0.01,對模型訓練500次的平均精度進行比較,如表2所示。

表2 不同批處理量模型的平均精度對比Tab.2 Performance comparison of model with different batches
從表2可以看出,其他參數不變的情況下,隨著批處理量的增大,訓練500次模型的檢測精度逐漸增大,但MAP并非隨著批處理量的增大而線性增大,當批處理量從16增大到64時,MAP增大了18.08個百分點,而批處理量從64增大到256時MAP只增大了3.20個百分點,而批處理量增大會使訓練時間明顯增加,綜合考慮檢測精度和訓練時間兩個因素,本文選擇64作為批處理量。
2.2.2學習率
學習率的大小影響模型的收斂速率,學習率太小,會使模型收斂緩慢,學習率太大,會使代價函數震蕩,甚至無法收斂。從表2可以看出,當批處理量為64,學習率為0.01時,模型訓練500次MAP為74.37%,檢測精度高于70%,收斂速率較快,而且還未達到收斂,所以本文設置初始學習率為0.01,前500次學習率保持不變,之后每訓練100次,學習率變為當前學習率的0.95倍。
2.3 模型訓練與測試
基于YOLOv2官方提供的預訓練模型,根據預訓練得到的參數對測試集進行訓練,其中批處理量為64,初始學習率為0.01,在訓練次數達到500次以后,每訓練100次學習率變為當前學習率的0.95倍,其他參數使用YOLOv2默認的參數,其中動量系數為0.9,網絡損失值變化情況如圖6所示。

圖6 訓練階段損失值變化情況Fig.6 Change of loss value in training stage
從圖6可以看出,隨著訓練次數的增加,損失值逐漸減小,前500次訓練損失值變化較大,訓練次數達到500以后損失變化趨于平緩,當訓練次數達到2 500以后損失值趨于平穩,從2 500次到4 000次時,損失值一直穩定在0.1~0.2,因此暫停訓練,選擇訓練2 500、3 000、3 500、4 000次的模型,使用60幅測試集圖像進行測試,測試結果如表3所示。

表3 不同訓練次數的模型檢測平均精度對比Tab.3 Performance comparison of model with different numbers of training
從表3可以發現,當訓練次數達到2 500以后,模型的MAP變化較小,當訓練次數為3 000時,模型的MAP最高,因此選擇訓練次數為3 000時的模型作為本文的芒果檢測模型,經測試使用GeForce GTX 1080顯卡運行模型時,檢測一幅圖像的平均時間為0.08 s,其中部分檢測結果如圖7所示。

圖7 樹上芒果圖像的檢測結果Fig.7 Detection results of mango image on tree
3 試驗與結果分析
為檢測本文算法對果實識別的準確性,本文設計了果實識別試驗,對測試集中的60幅圖像進行識別測試,部分識別結果如圖7所示。因為芒果是單個生長的,所以本文通過計算正確識別芒果的個數和錯誤識別芒果的個數作為識別正確率的標準,錯誤識別數為假陰數和假陽數之和,其中假陰包含漏識別和一框多果兩種情況,沒有被框標記出來的芒果記為漏識別,一框多果,只記為正確識別一個,其余果記為假陰,例如一個框包含兩個果,算正確識別一個,假陰一個;假陽包含誤識別和一果多框兩種情況,矩形框將背景框出來記為誤識別,同時一個果包含多個框,只記為正確識別一個,其余框記為假陽。統計60幅測試集圖像中,共有438個芒果,芒果的識別統計結果如表4所示。438個芒果中有397個芒果被正確識別,識別正確率為90.64%,錯誤識別的芒果數為41個,識別錯誤率為9.36%,其中假陰(漏識別,一框多果)25個,假陽(誤識別,一果多框)16個。為測試不同情況下本文算法的識別正確率,本文分別按圖像中含果實數和圖像光照情況進行進一步統計分析。

表4 圖像檢測結果統計Tab.4 Statistics of detection results of images
同時利用Ostu、K-means、模糊C均值聚類(Fuzzy C-means clustering,FCM)算法對60幅測試集圖像進行識別,與本文算法進行對比,識別結果如表5所示。由表5可知,因為綠色芒果和背景(樹葉)都為綠色,芒果和背景的顏色區別不明顯,使用Ostu、K-means、FCM 3種算法識別的正確率較低,這3種算法中,FCM算法有較高的識別正確率,識別正確率為82.42%,Otsu有較高的運行速率,識別一副圖像的平均時間為0.09 s。本文算法識別正確率為90.64%,識別一幅圖像的平均時間為0.08 s,與Ostu、 K-means及FCM算法相比,本文算法有較高的識別正確率和運行速率。

表5 不同識別算法性能對比Tab.5 Comparison of segmentation algorithms
3.1 不同果實數的圖像檢測結果分析
在自然環境下拍攝的芒果圖像,往往一幅圖像中所拍攝的芒果數量是不同的,圖像中含果實數目的不同會對檢測結果造成不同的影響,如果圖像中只有一個芒果,所拍攝的芒果一般比較完整清晰,比較容易識別。相對單果圖像而言,如果一幅圖像中含有多個芒果,可能會出現2個或多個果實粘連或者相互遮擋的情況,增加檢測難度。因此本文按圖像中含果實的數量分3個梯度對60幅測試集的檢測結果進行了統計,3個梯度分布為圖像中果實數小于5、圖像中果實數為5~10以及圖像中的果實數大于10,含不同果實數圖像檢測結果統計如表6所示。
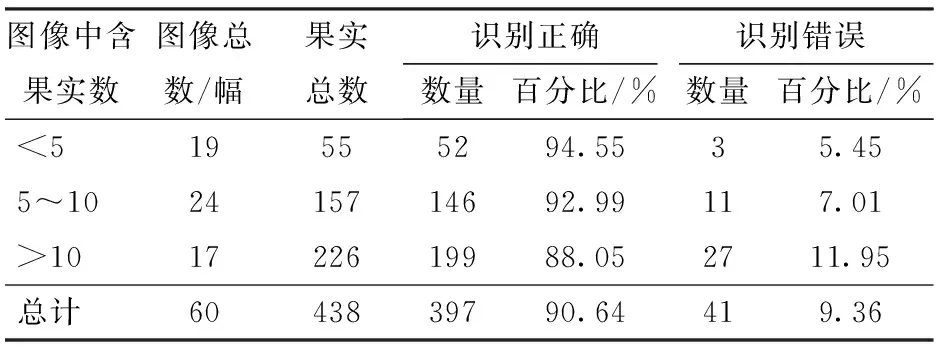
表6 含不同果實數的圖像檢測結果統計Tab.6 Statistics of detection results of images with different quantities of fruits
由表6可以看出,隨著圖像中果實數量的增加,識別正確率下降,識別錯誤率上升。是因為隨著果實數量的增加,多個果實粘連和遮擋情況越多,當圖像含果實數較多時,幾乎每幅圖像都有粘連和遮擋情況發生,雖然通過邊緣檢測分隔了部分粘連的果實,但還是有相互粘連和遮擋的果實會被識別為一個果實,降低識別正確率。除此之外,含果實數量較多的圖像,一般拍攝距離較遠,因此背景會比較復雜,圖像中的芒果也比較小,比較模糊,從而導致識別正確率降低,識別錯誤率增加。
3.2 不同光照情況下圖像檢測結果分析
在自然環境下,拍攝時的光照角度不同也會影響檢測的效果,在順光條件下拍攝的圖像一般比較明亮清晰,在逆光條件下拍攝的圖像會比較陰暗模糊。因此,本文將60幅測試集圖像的檢測結果分為順光和逆光兩組進行統計分析,統計結果如表7所示。

表7 不同光照情況下圖像檢測結果統計Tab.7 Statistics of image test results of different illumination conditions
從表7可以看出,在逆光條件下的檢測效果明顯比順光條件下的檢測效果差,因為在逆光環境下拍攝的圖像比較暗,果實和背景的顏色分量值均降低,各分量值的對比度降低,邊緣特征和顏色特征也被弱化,從而增加了逆光條件下的檢測難度。
3.3 整棵樹芒果數量檢測結果分析
為進一步驗證模型的有效性,本文選擇5棵樹,先人工計算沒有被遮擋、直接可見的芒果數量,然后再按第1節中的方法進行圖像采集和拼接得到整棵樹的圖像,用本文算法對圖像進行檢測,用算法檢測出來的芒果數量與人工計算的芒果數量進行對比驗證。用算法檢測樹兩側的圖像得到整棵樹上芒果的數量,統計結果如表8所示。

表8 整棵樹芒果數量檢測結果統計Tab.8 Statistics of mango count test results
其中,總計為正確識別的芒果數量加上假陽(誤識別,一果多框)數量,即算法檢測出來的芒果
數量,誤差計算公式為
(1)
式中E——誤差,%TP——正確識別數
R——人工計算芒果個數
FP——假陽數量
由表8可知,總的識別正確率為79.70%,遠低于3.1節和3.2節的正確率,這主要是因為采集圖像時,只從2個角度獲取芒果樹圖像,有些芒果在這2個角拍攝不到,而人工計數時可以看到。從誤差來看,算法統計的芒果數量小于人工統計的芒果數量,而且誤差范圍集中在11%~15%之間,平均誤差為12.79%,在實際應用時,可統計多棵芒果樹的誤差,再根據多棵果樹的平均誤差和算法檢測的芒果數,估計芒果的實際產量。
4 結論
(1)提出了一種自然環境下樹上綠色芒果的無人機視覺檢測技術,使用無人機采集圖像,對圖像進行人工標記感興趣區域,通過預訓練確定了YOLOv2模型訓練的批處理量和學習率,利用預訓練確定的訓練參數訓練YOLOv2模型,最終訓練得到的模型在測試集上的平均精度為86.43%。
(2)本算法對芒果識別具有較高的正確率,60幅測試集圖像中共拍攝到438個芒果,正確識別的芒果有397個,識別正確率為90.64%,識別錯誤率為9.36%。對含不同果實圖像識別的正確率如下:含果實數小于5的圖像,識別正確率為94.55%;含果實數5~10的圖像,識別正確率為92.99%;含果實數大于10的圖像,識別正確率為88.05%。不同光照條件下識別正確率如下:順光條件下識別正確率為93.42%,逆光條件下識別正確率為87.18%。
(3)本算法識別一幅圖像的平均時間為0.08 s,對于不同情況下的芒果識別正確率較高,使用無人機可以快速準確地估計芒果的產量,為果園自動化管理和收獲提供方法支持與參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
