基于相容性分析的醫療診斷專家系統
2018-12-04 02:14:46季長清李媛媛唐曉君
計算機工程與應用 2018年23期
關鍵詞:分析
肖 鵬,劉 娜,季長清,李媛媛,路 瑩,唐曉君
1.大連工業大學 信息科學與工程學院,遼寧 大連 116034
2.大連大學 物理科學與技術學院,遼寧 大連 116622
3.大連交通大學 軟件學院,遼寧 大連 116052
1 引言
醫療專家系統[1]是專家系統研究的一個重要方向,其目標是通過具有大量專門知識的計算機程序來模擬醫學專家的分析過程,以解決醫療診斷中的各種復雜問題。因此,作為人工智能應用的一個重要分支,醫療診斷專家系統比醫學專家擁有更多的專業知識和更快的解答問題能力,已經在醫療診斷領域發揮著良好的輔助作用。
如圖1所示,一個典型的醫療診斷專家系統[2]主要由以下6部分組成:病例數據庫、醫學知識庫、知識獲取、推理模型、解釋機制和用戶GUI。其中,病例數據庫,醫學知識庫是醫療診斷專家系統數據的來源和基礎;用戶GUI和解釋機制屬于人機交互部分;知識獲取的有效性及其數據處理決定了推理過程要用到的數據正確性;推理模型實現知識推導求解進而得出診斷結論,其好壞直接決定了最后結論的正確與否。因此,知識獲取和推理模型是醫療診斷專家系統的核心部分,采用什么樣的數據處理方式和知識推理模型是醫療診斷專家系統研究的重要內容。
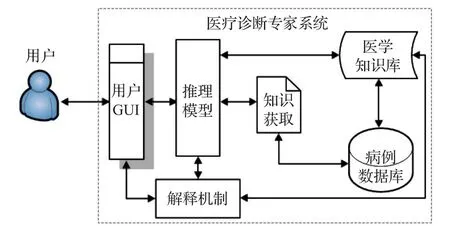
圖1 醫療診斷專家系統組成
近年來,醫學診斷專家系統的研究[3-19]得到了廣泛關注,其關鍵技術在醫學臨床上也得到了深入的應用。隨著醫學診斷專家系統的不斷發展,其推理模型也成為醫學專家系統研究的一個熱點和關鍵點,并有了一些相關的研究。醫學診斷專家系統的推理模型主要有處方產生式推理模型[3-7]、模糊推理模型[8-13]和機器學習推理模型[14-19]等。大部分推理模型都依賴于權值設定,而權值設定又完全依賴于醫生的經驗值。因此,權值給定質量直接影響了診斷結果,有待進一步研究和改進,以期找到更實用的權值設定和自動賦值方法。
本文研究了大量醫學病例數據的自身相容性問題,這些數據在某些屬性上具有相容性,即病例的相似性和關聯性。例如,在肺炎病人眾多的表現癥狀中,發燒是常見的表現癥狀,是其重要屬性;同時發燒和咳嗽又具有一定的關聯性。如何利用數據相容性分析來建立屬性權值自動設定模型,以增加醫學診斷的準確度,是推理模型研究的一個新方向。另一方面,在實際應用中醫學專家系統會對所有屬性進行分析,這大大增加了計算量和分析問題的復雜性。如何對屬性進行有效的降維也有待進一步研究。
本文針對醫學病例數據的特點及相容性分析進行了研究,提出了一種基于屬性相容性分析的醫療診斷方法。此方法先利用屬性相容性分析對醫療數據進行數字化處理,根據屬性之間的關聯度構造屬性相關矩陣;接著利用屬性相關矩陣對屬性進行剪枝處理,以減少無效屬性的計算;基于相容性分析構造較為實用的權值設定數學模型;最后在進行病例相似度計算時采用群體決策策略來完成最終診斷。
2 相關工作
醫學診斷推理模型是從大量病理知識和病例中推導求解進而得出最后診斷結果。對于醫學診斷推理模型人們做了大量的研究工作,早期的工作主要集中在簡單的產生式系統推理模型中。陳漫紅[3]等人將產生式系統推理引入到青光眼診斷專家系統中,其推理機制的核心是采用深度優先語義遍歷和正向啟發式推理策略。產生式系統推理模型簡單明了,但無法診斷癥狀復雜且與其他疾病存在共同癥狀的疾病,其應用有限并且缺乏有效篩選機制。
針對多種疾病可能性的癥狀難診斷這一難題,很多研究人員將概率理論引入到診斷推理過程中。于佳[4]等人將統計分析應用到甲狀腺超聲診斷中。文獻[5-7]試圖利用貝葉斯定理推算出引發癥狀的癥病置信度,當置信度達到某一概率時,診斷規則才會被觸發,減少了不確定性誤診的可能性。但在現實生活中這些概率數據收集困難,其往往是通過大量數據統計得到,或是由權威專家給出。這些統計數據自身的可靠性和代表性直接決定了推理結論的正確與否。
模糊邏輯能模擬人腦方式進行模糊綜合判斷,推理解決常規方法難以應付的規則型模糊信息問題。因此,模糊推理模型自提出以來就成為診斷專家系統的經典模型,后續很多學者在模糊邏輯基礎之上進行了相關模型的研究[8-13]。研究者普遍采用模糊集規則來進行醫療診斷系統的設計,然而模糊診斷知識獲取困難,自我學習能力差,容易發生誤診。另外,加權模糊規則的設置還有賴于醫生的經驗。這些都影響了基于模糊邏輯的醫療診斷專家系統的實際應用。
目前機器學習推理在醫療專家系統中的研究已成為熱點。機器學習推理能擺脫主觀因素和不確定性帶來的干擾,直接進行確定性推理,被廣泛地應用在各種專家系統中。陳藹祥[14]等人提出了一個ADST系統,利用支持向量機、決策分類樹和樸素貝葉斯三種不同的方法進行結節病和肺結核的診斷。鄭明杰[15]等人關注機器學習方法在肺音分類中的應用。隨著機器學習和人工智能算法的不斷發展,越來越多的復雜算法[16-19]被引入到醫療診斷專家系統研究中來。Inbarani[16]等人提出了粒子群算法和粗糙集相結合的醫療診斷方法。馮嬌嬌[17]等人將人工神經網絡模型應用到慢性腎病診斷中。文獻[18]將數據挖掘應用到醫療專家系統中,借助數據挖掘技術提取醫院數據,加快了醫療數據的利用。文獻[19]將TF-IDF權重改進算法應用到智能導醫系統中,依據患者癥狀進行兩類TF-IDF權重計算得到可能疾病,以引導患者準確掛號。
機器學習大大加快了醫療診斷專家系統學習獲取知識的過程和效率,提高了系統的智能化和準確化。然而,機器學習也存在著局限性和不足:機器學習推理模型過分依賴于以往的診斷數據,學習效果和實用性有限,如不同癥狀屬性對診斷結果的影響不同,其權值的設定原則也受診斷數據影響;機器學習訓練對所需的病例樣本在數量上和代表性上有較高要求,系統設計人員很難用一個有效固定標準來衡量。與上述工作不同,本文考慮的是基于相容性分析的機器學習方法。針對現有診斷推理模型在病例推理過程中過于依賴權值設定和醫生經驗值的問題,本文提出了一種基于屬性相容性分析的醫療診斷方法,以解決屬性冗余和權值賦值的難題。
3 相容性分析
醫學病例庫一般由大量屬性組成,這些屬性大部分為文本型數據,不利于數據的分析處理。對這些屬性進行數字化處理之后,需要對所有屬性進行降維簡約化處理以減少計算量和分析復雜性。相容性分析作為一種有效的特征屬性提取方法,被普遍應用于網絡流量分析[20]、圖像處理[21]等領域。本文所提的醫療診斷專家系統首先對病例庫的文本屬性進行數字化處理,然后利用相容性分析進行剪枝并提取有效屬性和設定權值,最后根據相似度計算結果和群體決策理論進行輔助診斷。
現在假設有病例數據庫集合L={L1,L2,…,Ln,…,LN},集合中每一個病例記錄由多個屬性和疾病結果組成,即某病例記錄Ln由向量<f1,f2,…,fm,…,fM,r>構成。其中 f1,f2,…,fm,…,fM為病例的M個屬性特征,r為所患疾病結果。其數據形式未處理前如表1所示。
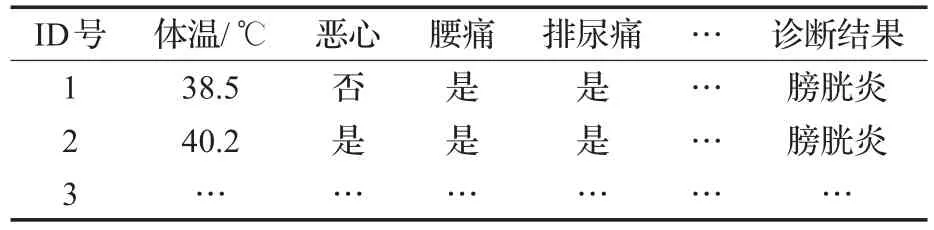
表1 某醫學病例數據庫樣例
現有待診斷病例集合Q={q1,q2,…,qk,…,qK},對于任意一個q,存在著相似度向量<d1(q,l),d2(q,l),…,dm(q,l),…,dM(q,l)>,其中 q∈Q,l∈L ,dm(q,l)代表著待診斷病例q和病例記錄l在第m個屬性特征上的距離。基于dm(q,l)公式,可以計算集合Q和L之間所有dm距離,以方便進行相容性分析計算。
對每一個病例重復這個過程,可以得到一個M×M的協方差矩陣A,其第i行和第 j列的協方差Aij如公式(1)所示:
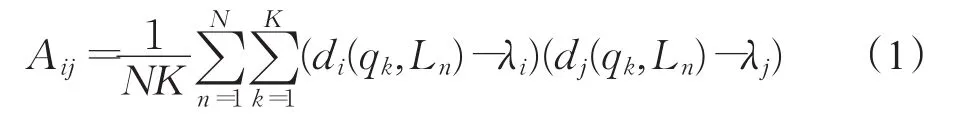
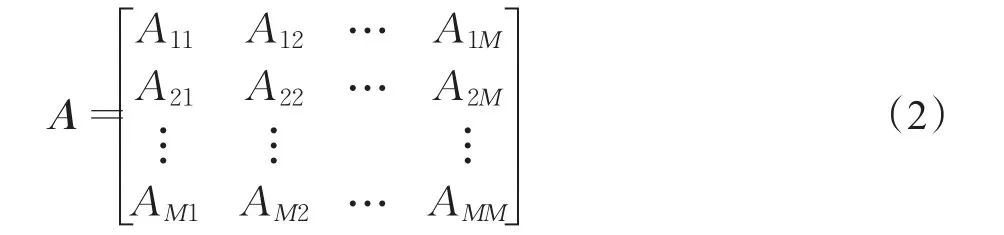
于是,協方差矩陣A如下所示:
計算出協方差矩陣A,下面就可利用相容性分析的方法進一步分析。相容性分析是針對數據各屬性成員之間的相關性進行分析,并構造屬性相關矩陣。針對已有 M 個屬性特征 f1,f2,…,fm,…,fM,利用公式(3)來構造屬性相關矩陣。

其中Rij表示第i個屬性 fi和第 j個屬性 fj之間的相關性,其值越大,相關性越大。
于是,得到了屬性相關矩陣如下:
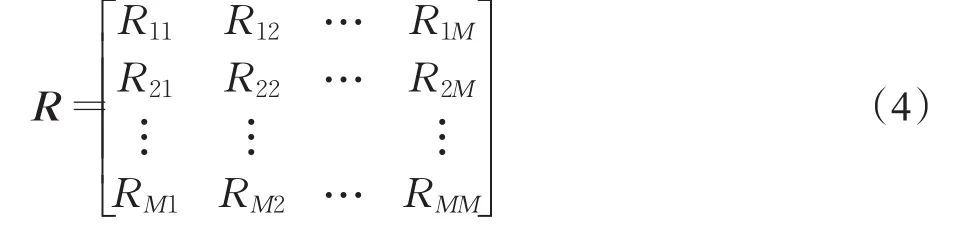
利用屬性相關矩陣,可以從眾多屬性特征中提取相關性較大的屬性進行后續的計算處理,并對相關性較小的屬性進行剪枝處理。相容性分析能有效地減少病癥的冗余屬性,達到了降維和減少計算的作用。
4 基于相容性分析的醫療診斷算法
本文針對醫療病例數據提出的醫療診斷推理模型如圖2所示。
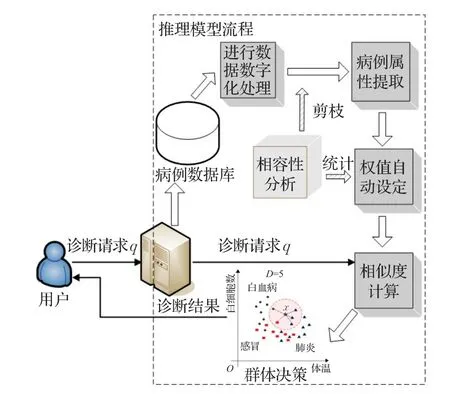
圖2 推理模型流程圖
系統主要由數據數字化處理、病例屬性提取、權值設定、相似度計算和群體決策等幾個步驟組成。相容性分析是整個推理模型的基礎,其強大分析能力能很好地解決屬性剪枝和權值自動設定的處理要求。
首先,病例數據由臨床產生,形成的大規模病例數據庫可用于分析計算。在針對病例數據庫自身特點進行數據數字化處理之后,利用相容性分析方法計算出病癥屬性的相容性,并進行重要屬性特征的提取,減少了無效屬性的計算,實現了數據的剪枝處理。針對各屬性特征的重要性不同,利用相容性進行權值的自動設定計算。系統在接收到用戶的診斷請求即查詢點q之后,計算其與病例數據庫中所有樣本的加權相似度。最后根據相似度計算結果進行群體決策,并將最終診斷結果返回給用戶。
接下來本文將重點介紹此流程中的重要數學模型及關鍵處理技術。
4.1 權值設定模型
考慮到屬性的值對結果影響不同,傳統的基于權重的數字化方法常根據屬性貢獻大小來賦值。貢獻大的屬性在數字化時賦一個較大的值,貢獻小的就賦一個較小的值,而不是把是非邏輯的文本屬性值簡單地設定為1或0。但是屬性的數字化賦值往往由人為經驗得出,不可避免受醫學專家主觀意識的影響。為了使權值客觀地反映出屬性對診斷結果的影響,本文通過對病例數據庫進行相容性分析,自動學習得到各屬性權值。在數字化過程中,對于是非邏輯的文本型屬性值可設定為1或0,通過機器學習,根據不同屬性的重要性來自動獲取其權值,客觀地反映了臨床病例數據經驗,排除人為因素干擾。
現有病例數據庫集合L={L1,L2,…,Ln,…,LN},其中任一個病例記錄Ln由向量<f1,f2,…,fm,…,fM,r>組成,f1,f2,…,fm,…,fM為病例的M個屬性特征,r為所患疾病結果。
通過數據相容性分析可得到各屬性對結果影響程度的百分比統計信息,其集合形式為S={s1,s2,…,sn,…,sM}。假設存在著權重影響因子集合 α={α1,α2,…,αn,…,αM},其值由公式(5)決定。

根據權重影響因子集合α,可以計算得到權重集合W={ω1,ω2,…,ωn,…,ωM},其計算公式如下:

其中,i的取值范圍為i=1,2,…,M。
權值自動設定模型從病例數據庫中學習得到權值。由概率統計理論可知,如果屬性 fi為真使得某疾病結果r被診斷的頻率高,那么屬性 fi對診斷結果為r是重要的,其權重ωi就高,反之亦然。本文的權值設定模型通過機器學習自動得到權重集合,減少了人為設定權值所帶來的干擾和誤差。有了權重集合,就可以根據學習來的權重大小,在編碼過程中自動賦予相應數值,實現查詢病例與病例數據庫樣本之間相似度計算。
4.2 相似度計算
本文通過基于權值的疾病相似度計算來進一步確定疾病的可能性。所用到的部分符號定義如前文所示。對于任意待診斷病例q,其與任一病例數據樣本l之間的相似度計算如下:

其中q∈Q,l∈L,di(q,l)代表著待診斷病例q和病例記錄l在第i個屬性特征上的距離。
在相似度計算中,將病例的不同病癥屬性基于樣本庫的統計分析進行差別化對待,使其不受量綱的影響,自動化設定權值,滿足了實際應用需求。
4.3 群體決策策略
臨床診斷的正確性和醫學不確定因素有直接關系,不確定信息來源于知識庫中的不確定性、病人數據中的不確定性和推理中的不確定性等。例如,很多疾病具有極其相似的病癥屬性,給推理過程帶來很大不確定性。尤其在基于最大相似度的判斷方法中,單個病例的不確定因素對醫學決策過程影響更大。為了解決這一問題,提出了診斷過程群體決策概念,如圖3所示。以二維空間為例,三種疾病數據樣本和待診斷病例x被映射到體溫和白細胞數兩屬性的二維坐標系中。為減少單一的最大相似度計算帶來的誤差和不確定性診斷,以群體決策投票來決定最終診斷結果。
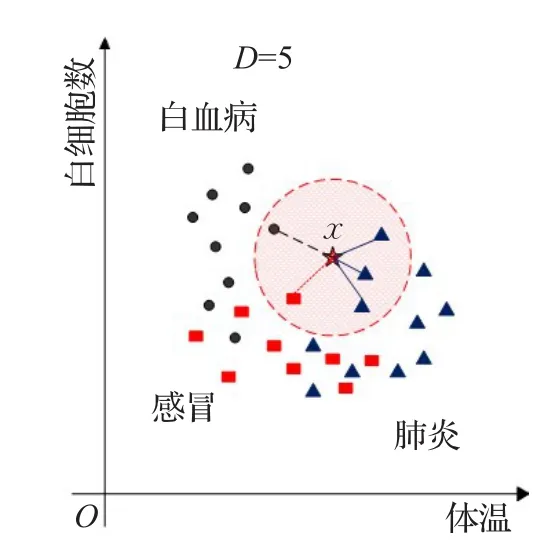
圖3 群體決策策略
以群體決策人數D=5為例,先根據公式(7)計算待診斷病例x和所有病例樣本之間的相似度,取與其相似度最大的前五個病例樣本,即距離最短的前五個數據點。這五個病例樣本中的絕大多數所患疾病結果r決定了待診斷病例x的診斷結果。如圖所示,最終待診斷病例x被診斷為肺炎。由于篇幅所限,本文所給例子是以二維空間為例,但所提方法可以任意擴展到高維,滿足病癥屬性多樣性需要。
現有病例數據庫集合L={L1,L2,…,Ln,…,LN}、待診斷病例集合Q={q1,q2,…,qk,…,qK}、疾病類別集合R={r1,r2,…,rj,…,rJ}。其中某病例記錄 Ln由向量<f1,f2,…,fm,…,fM,r>構成,f1,f2,…,fm,…,fM為病例的M個屬性特征,r為所患疾病結果且r∈R。
給定一個待診斷病例x∈Q,其屬于哪種疾病的先驗概率P(r|x),其最大似然分類如公式(8)所示:

若群體決策人數為D,則群體決策的概率為:
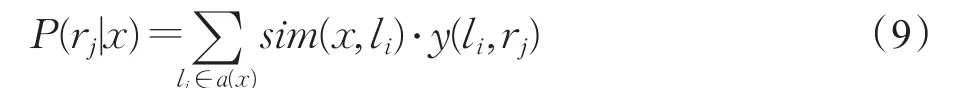
其中a(x)表示前D個最相似病例樣本,sim(x,li)表示待診斷病例x與樣本li的相似度計算,y(li,rj)為指示函數,其值由公式(10)得到:

即當li∈rj時,y(li,rj)值為1,否則 y(li,rj)值為0。
由于在相似度計算中值越小相似度越大,待診斷病例x所屬疾病類別為:

對于病癥屬性交叉和重疊普通存在的醫學病例數據而言,群體決策策略能有效地減少誤診率和提高診斷效率。
5 實驗評測
在本章中,介紹了實驗環境及測試數據情況,本文中所提到的方法采用MATLAB編寫,均在Windows平臺下實現。
5.1 實驗配置
所有實驗均在Windows 7 64位系統中實現運行,主機配置如下:Intel?Core? i3-2350 2.30 GHz CPU,500 GB SCSI硬盤,4 GB內存。
實驗數據來源于某醫院信息系統數據庫中的真實病例。這些數據包含了病人病癥特征和醫生給出的正確診斷結果。它真實地反映了臨床醫學數據庫中的數據特征。為了實現病歷數據到實驗數據的轉化,進行了數字化處理,并對原數據屬性特征做了最大化的保留。實驗中將數據集隨機分成兩部分,一部分作為病例數據庫集合,另一部分作為待診斷病例集合。
5.2 實驗結果
圖4展示了病例樣本數量對診斷準確率的影響,實驗從病歷數據庫中隨機抽取病例作為病例樣本,且每種疾病按100條和1 000條兩種比例抽取。為了驗證群體決策的效果,實驗將群體決策人數D設置成從2到50之間變化,參與計算的病癥屬性數目為6。
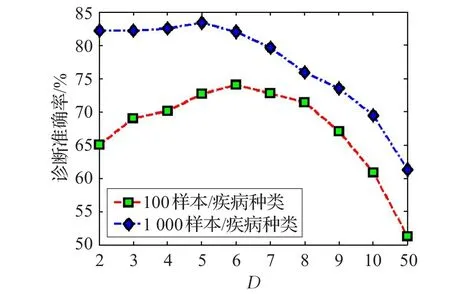
圖4 病例樣本數量與診斷準確率關系
由圖4可知,病例數據庫集合的樣本密度對診斷準確率的影響很大,樣本越多,診斷準確率越高。而且采用1 000樣本/疾病種類的診斷精度要遠遠高于采用100樣本/疾病種類的診斷精度。另外,還能看出D的取值并不是越大越好,在本實驗中,D=5具有較好的實驗效果。在最開始決策人數較少時,群體決策達到了應有的少數服從多數的效果。一旦D值過大,相反還影響了診斷準確度。這也是和不同疾病的病癥數據相融合有很大關系,過分擴大決策人數數量相反還加重了疾病診斷的模糊性。因此,在群體決策中針對不同數據集特點探索適當的決策人數是很有必要的。
圖5展示了病癥屬性數量與診斷準確率關系,即屬性相容性對實驗精度的影響。實驗中的病例數據集合樣本按1 000樣本/疾病種類比例抽取,屬性特征的提取按相容性分析中的高值依次獲取。
如圖5所示,顯然診斷準確率隨著屬性數量的增大而增長,病癥屬性越多,計算所得診斷結果準確率越高。在群體決策人數D相同的情況下,參與診斷的病癥屬性多的準確率遠遠高于病癥屬性少的準確率。正如所預測的那樣,相容性分析對準確率的影響是明顯的。當然,參與計算的屬性數目多,計算開銷也會相應增大,這一點在后面的時間開銷實驗中作評估。
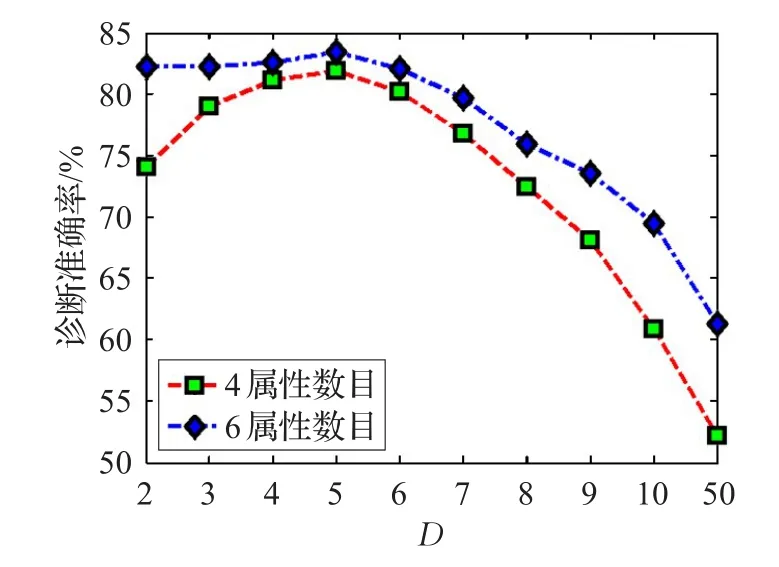
圖5 病癥屬性數量與診斷準確率關系
圖6 展示了病癥屬性數量及D取值對運行時間的影響。實驗采用4種屬性數目和6種屬性數目進行對比。待診斷病例集合記錄數為5 000條數據,病例數據集合樣本密度為1 000樣本/疾病種類,群體決策人數D設置為從2到50之間變化。
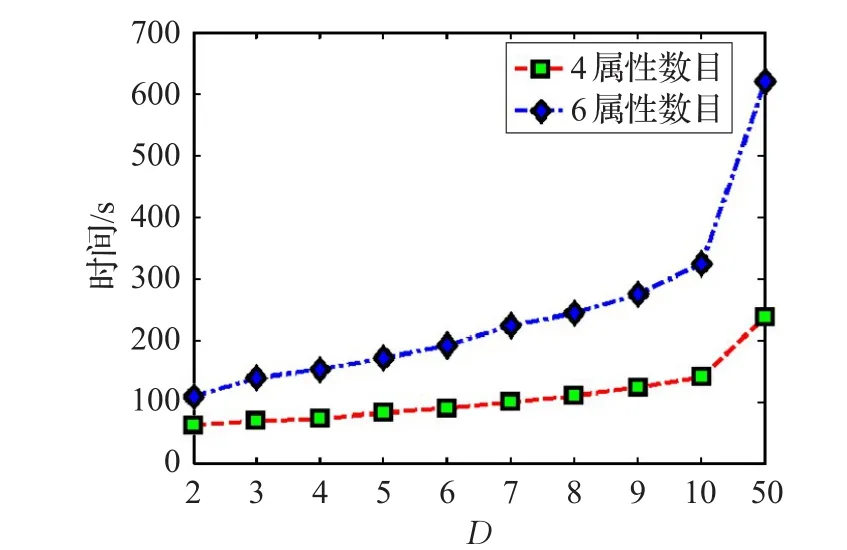
圖6 運行時間對比
如圖6所示,隨著D數目的增長,診斷時間也隨著增長。在相同D值的情況下,屬性數目越多,診斷執行時間越長,并且兩者差距越來越大。當D=50時,計算復雜度更是急劇增長。可見,數據維數和D所帶來的計算次數對運行時間有著深遠的影響。
圖7展示了不同樣本密度情況下兩種方法的運行時間對比,其中本文采用的權值自動設定方法由相容性分析學習所得,權值人工設定方法中各權值由人工設定。為公平起見和減少人為經驗干擾,人工設定方法各權值為平均值,歸一化為1。實驗中的病例數據集合樣本按樣本/疾病種類比例抽取,從100到600之間變化。屬性特征的提取按相容性分析中的高值依次獲取。群體決策人數D=5。
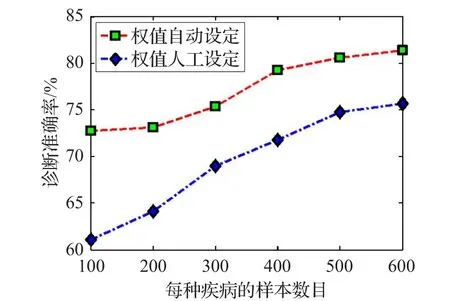
圖7 不同方法比較
如圖7所示,權值自動設定方法診斷準確率要高于權值人工設定方法。且在當樣本密度較小的情況下,這一優勢更明顯,這也驗證了權值自動設定借助機器學習的優勢。還可以看出,兩種方法診斷準確率都隨著樣本密度的提高而提高,這和個體數量及其相容性特征有著很大關系。
從實驗結果可以看出,無論是所需測試樣本密度還是診斷準確率上,基于相容性分析的診斷方法都具有較高的準確率和性能。
6 結束語
本文研究了醫療診斷病例數據的相容性分析問題。為了解決醫療診斷專家系統權值設定和自動賦值的難題,將相容性分析引入到醫療診斷中,并提出了一種基于屬性相容性分析的醫療診斷方法。針對權值賦值問題,利用基于屬性的相容性分析對醫療數據進行數字化處理,提出了較為實用的權值設定數學模型;針對疾病癥狀屬性多影響診斷結果問題,利用屬性之間的關聯度構造屬性相關矩陣,并對屬性進行剪枝處理;為了減少誤診率,系統采用群體決策策略來完成診斷。最后,針對所提方法進行了實驗模擬。實驗結果表明,該方法具有一定的有效性和實用價值。
猜你喜歡
現代畜牧科技(2021年9期)2021-10-13 06:39:14
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
當代經濟研究(2016年5期)2016-12-01 03:12:05
現代農業(2016年5期)2016-02-28 18:42:46
出版與印刷(2016年3期)2016-02-02 01:20:11
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
華北水利水電大學學報(社會科學版)(2014年3期)2014-04-16 04:38:31
終身教育研究(2014年5期)2014-02-28 01:23:06
