LDA在提取涉警輿情關鍵詞中的應用
2018-12-19 12:44:28羅玉王玲
現代計算機 2018年32期
羅玉,王玲
(西華大學計算機與軟件工程學院,成都 610039)
0 引言
伴隨著社會的迅速發展和信息技術的廣泛應用,涉警輿情越來越多輿情信息的增長速度越來越快,一些負面涉警輿情,甚至是謠言,在網上傳播,如果不引起重視任由其發展,必然會對公安工作的正常建設造成不良影響,引發涉警輿情危機。所以如果能通過一些關鍵詞幫助公安人員進行輿情分析,那么無疑對社會的長治久安具有重大意義。
1 主題爬蟲
考慮到涉警輿情數據來源廣,文本數量龐大,種類多,本文使用主題爬蟲技術,主題爬蟲技術是一種依照特定的對象,主動的抓取萬維網信息的程序或者腳本[1]。相較于通用爬蟲,主題爬蟲對爬取對象更加聚焦,抓取的網頁信息與特定主題相關。主題爬蟲主要面對兩個問題主題的描述和主題的相似度計算。主題描述,指用戶對所要爬取主題的描述。主題描述的好壞,對于爬蟲的結果有著較大的影響[2]。通常主題描述有兩種方法,一種是專家確定關鍵詞集,另一種是通過初始頁面提取關鍵詞。
當前學者在此基礎上提出了一些新的方法,李東暉[3]等提出了一種無監督的主題自動擴展技術,能讓一個簡單抓取腳本從開始的主題不斷積累主題知識。主題爬蟲的另一個核心問題,主題相似度計算根據符合要求的主題判斷當前網頁和當前網頁的URL是否保留的算法。有兩處需要進行主題相似度計算,一是對當前爬取頁面的正文內容,二是對當前頁面中的URL。根據網頁結構、內容,判斷是否與期望主題相關,Guo[4]等提出基于SVN分類的主題爬蟲技術,通過訓練SVN分類器,來表現文字內容和鏈接的主題相關度。
由于依據擔負任務、職能、領域的不同,人民警察種別,分為戶籍、交通、治安、消防森林、經濟、經濟犯罪偵查等警種,在這里,我們可以把警種類別看作不同的主題,每個警種對應一個或多個主題,每個主題下有與之相關的關鍵詞。
本文將采取LDA方法來進行主題爬蟲,利用Word2Vec詞向量表示計算主題和網頁內容的相似度,主題之間的相似度[5]。
2 LDA主題模型
LDA主題模型屬于監督學習,它是一種文檔的主題生成模型,它可以從語料中抽取潛在的主題,已經被普遍的應用到信息的主題發現中。
該模型的主要思想是一個主題由一些詞生成,一篇文章則由一些主題生成,即一篇文章由某些詞語生成。LDA模型如圖1所示。
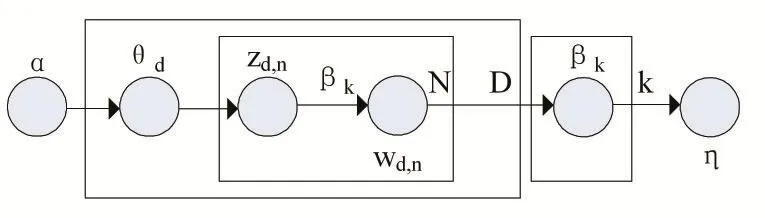
圖1
其中,wd,n是可計算變量,表示一個文檔D中的詞匯,zd,n代表每個詞在主題上的設定值,θd代表每個文檔在主題空間中的比例,βk代表主題空間中第K個主題,α和η分別代表預先設定的比例系數和主題參數。圖中矩形部分表示重復過程,|D|表示該語料庫中文檔的數量,K是當前主題空間的主題數。
因此,文檔集D={d1,d2,...,dn}中的任意一個文本d={w1,w2,...,wn}的概率生成過程如下:
(1)D中詞的總個數N服從泊松分布。
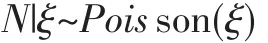
(2)主題分布 θ服從狄利克雷分布,即 θ|α~Dir(α)
(3)關于每個n,n∈{1,2,...,N}均存在潛在主題zn服從多元分布,zn|θ~Mult(θ)參數
(4)每個詞wn也服從多元分布,即:
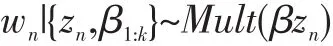
ξ,α,β表示超參數,其中,ξ僅僅確保表達的完整性,對模型的求解過程無影響;α表示任意一個與文檔中主題分布有關的狄利克雷超參數;β表示一個與文本集合中主題詞概率相關的狄利克雷超參數。這些超參數根據經驗或多次訓練來設定。
綜上所述,LDA模型采用對文檔中每一個詞語的概率來進行計算,即:
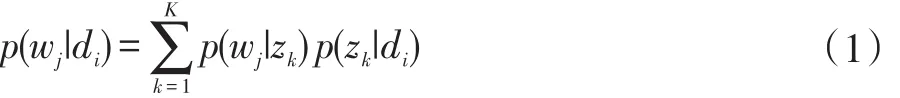
P(wj|di)表示每個文檔中單詞出現的概率,即詞頻,P(wj|zk)表示某個主題中每個單詞出現的概率,P(zk|di)表示某個文檔中每個主題出現的概率。故得到文檔中每個詞的生成概率為:
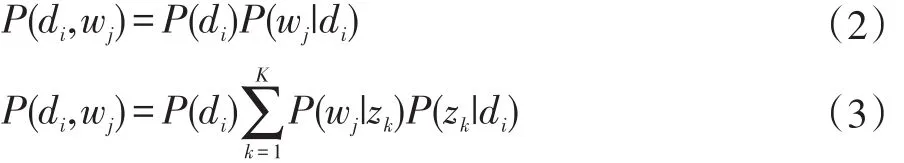
3 關鍵詞提取
本文的關鍵詞算法采取融合LDA和TF-IDF的自動擴展提取算法。TF-IDF(Term Frequency-Inverse Document Frequency)在自然語言中通常用來表示詞語的重要性的加權技術。TF表示詞語的頻率(Term Fre?quency)如公式(4)所示,IDF表示的是是逆文本頻率(Inverse Document Frequency),一個特定詞語的IDF,表示總的文件數除以包含該詞的文件的數,為了簡化計算將得到的商取對數。如公式(5)所示。

這里ni,j表示第j篇文檔的第i個詞語,|D|代表總的文檔數,|{j:ti∈dj}|代表包含詞語ti的文件數目。
我們選定部分初始關鍵詞,將其加入到爬取種子集中,作為數據抓取的初始種子,通過這些初始種子檢索新聞網站,通過融合LDA和TF-IDF算法抽取出文本關鍵詞,將符合標準的關鍵詞作為種子加入到種子集中,再進行新一輪的爬取。如圖2所示。
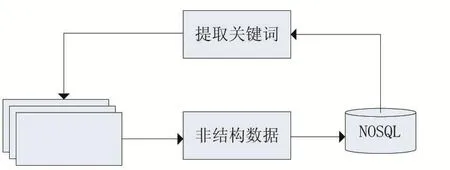
圖2 種子集獲取流程圖
4 實驗結果和分析
本實驗主要是使用Python實現,通過爬取互聯網上的新聞作為訓練語料,主要來自新浪、新華網、中國新聞網等,抓取新聞正文五萬篇。使用Gensim包實現LDA主題模型的訓練,訓練過程采用Gibbs采樣,由于時間和資源有限,選取三個區分度較高的主題作為實驗素材,考察實驗效果,選取消防、經濟犯罪偵查、刑事案件三個主題,結果如表1所示。
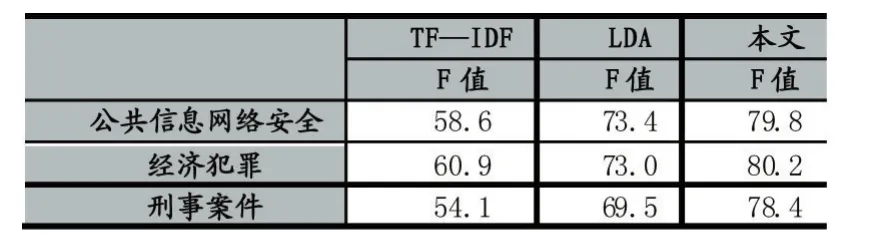
表1 F值對比表
表1結果表明,LDA融合TF—IDF的算法在F值上優于單純地使用LDA和TF-IDF,證明了LDA主題爬蟲的可行性和有效性,并隨著主題更新的次數不斷增加,會有一定提升。
實驗進行了6次更新,得到更新后的主題文檔,通過統計對比了前后主題文檔中出現相同的詞,詞的主題概率提高了3.12%。
5 結語
本文提出了一種涉警輿情關鍵詞提取方法,通過使用融合LDA和TF-IDF抽取關鍵詞的方法和為垂直領域的關系抽取提供了一種新思路,為垂直領域的關鍵詞提取建提供了良好的借鑒,后續的工作中將會加大對數據的采集,提高關鍵詞抽取的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
