一種自適應的RFID防碰撞算法
2018-12-20 01:56:54任柏翰張圣杰石浩森
計算機技術與發展 2018年12期
任柏翰,張圣杰,石浩森,宮 婧
(南京郵電大學,江蘇 南京 210023)
0 引 言
射頻識別(radio frequency identification,RFID)技術可以通過無線電訊號實現無接觸式自動識別,由于其具有閱讀速度快,可適應于各種惡劣環境,讀寫能力快等優點,現已廣泛應用于交通物流、食品管理、圖書館書刊借閱、門禁等各個領域[1]。但當多個標簽同時與讀寫器進行信息傳輸時,會出現“碰撞”現象,使閱讀器無法正常工作,嚴重影響系統正常運行。為解決這一問題,現已提出了多種RFID防碰撞的算法[2]。
1 當前防碰撞算法
常用的防碰撞算法一般可以分為兩類:確定算法和非確定算法[3]。非確定算法主要是基于ALOHA算法,包括時隙ALHOA算法、分群時隙ALOHA算法等。確定性算法主要是基于二進制樹搜索的算法,包括二叉樹搜索算法、動態二叉樹搜索算法、自適應樹搜索算法等[4]。
純ALOHA算法[5]就是當需要發送數據時,標簽以循環序列形式發送數據,在第一次發送之后,需要等待相對較長的時間再次發送數據,直到所有標簽都完成了數據的發送。時隙ALOHA算法[6]把時間以幀為單位分成時間段,每個時間段由若干個時隙組成,標簽發送數據幀只能在時隙開始時發送,按照這種方法,可以大大減少因為幀重復引起的沖突。
二叉樹搜索[7]的基本思想是將處于沖突的標簽分成左右兩個子集0和1,先查詢子集0,若沒有沖突,則正確識別標簽結束。若仍有沖突則再繼續分裂,把子集0分成00和01兩個子集,依次類推,直到識別出子集0中所有標簽,再按此步驟查詢子集1。
四叉樹搜索的基本思想是將處于沖突的標簽分成四個子集00、01、10和11,先查詢子集00,若沒有沖突,則正確識別標簽結束。若仍有沖突則再繼續分裂,依次類推,直到識別出子集00中所有標簽,再按此步驟依次查詢子集01、10、11。
2 改進防碰撞算法
ALOHA算法當標簽達到一定數量的時候,容易發生某些標簽多次碰撞無法識別的狀況,也就是“標簽饑餓”現象[8]。二進制樹形轉化法則不存在這一現象。目前已經存在的算法有動態二叉樹搜索算法、動態的四叉樹搜索算法、自適應的二四叉樹防碰撞算法[9]。
二叉樹搜索時,不存在空閑時隙,但是碰撞時隙的數量非常多;四叉樹搜索時,可大幅度減少碰撞時隙,不過增加了空閑時隙的數量。自適應的二四叉樹,引入碰撞因子的概念,根據當前集合碰撞因子的大小,自適應地選擇采用搜索樹的類型,從而大幅提高效率。
不過之前的文章由于考慮到引入八叉樹系統設計算法更加復雜,因此沒有對八叉樹進行進一步的分析,而是僅分析二四叉樹。當標簽數目較多時,為進一步優化算法,文中提出一種自適應的二四八叉樹算法,以進一步優化標簽碰撞識別過程。
動態八四二叉樹搜索流程如圖1所示。
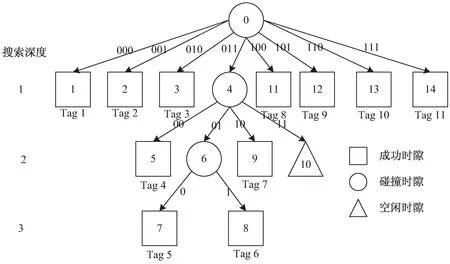
圖1 動態八-四-二叉樹搜索流程
通常來講,當系統內的標簽數量越多,則出現碰撞的位數也就越多,從而碰撞位占標簽總比特位的比例也就越大。為了更好地決定采用幾叉樹進行搜索,定義了碰撞因子μ來計算這個比例,以便有效地利用碰撞信息,提高算法效率。
定義:假設每個標簽的ID碼長度為n比特,其中碰撞間隙內產生碰撞的比特位為nc,則
(1)
其中,碰撞因子μ包含了待識別的標簽的數量的信息。
假設系統內有M個待識別的標簽,每個標簽的ID碼長度為n比特,其中任意一位不發生碰撞的概率為(1/2)M-1,由此可得:
(2)
式2表明,系統中標簽的個數越大,碰撞因子值越高;反之,碰撞因子值越低。由此說明碰撞因子的大小可以用來估計待識別標簽的數量。
在文獻[10]中給出了計算碰撞因子值的方法,即碰撞因子與叉樹的關系。假設系統內有M個待識別的標簽,自適應多叉樹的叉數為L,當搜索的深度為1時,標簽的識別概率為P(1)=(1-1/L)M-1;當搜索深度為2時,識別概率為P(2)=P(1)[1-P(1)];以此類推,當搜索的深度為k時,得到標簽的識別概率為P(k)=P(1)[1-P(1)]k-1。
所以,需要搜索的深度均值為:
(3)
所需的平均時隙為:
(4)
根據計算可知,當L=M時,所需的平均時隙最少。理論上來講,待識別的標簽越多,多叉樹的叉數越多,但實際上只考慮二叉樹、四叉樹和八叉樹。
通過比較得知:當M<3時,T為T2;當3≤M≤5時,T為T4;當M>5,時,T為T8。其中,M=3為二叉樹和四叉樹的臨界值,此時計算得μ=0.75;M=5為四叉樹和八叉樹的臨界值,此時μ=0.937 5。因此得出,當μ<0.75時,選擇使用二叉樹搜索;當0.75≤μ≤0.937 5時,選擇四叉樹搜索;當μ>0.937 5時,選擇使用八叉樹搜索。
EIAMS算法流程如圖2所示。
Step1:讀寫器初始化查詢堆棧,發出查詢命令。
Step2:與閱讀器前綴相符合的標簽響應。
Step3:若標簽響應數為1,識別成功,為成功時隙;若無標簽響應,識別失敗,為失敗時隙;若有多個標簽響應,則進入碰撞時隙。
Step4:碰撞時隙:計算碰撞因子μ,若μ>0.937 5,采用八叉樹,根據碰撞首位,重新確立八個查詢代碼,并進入棧記錄;若0.75<μ<0.937 5,則采用四叉樹,根據碰撞首位,重新確立四個標簽查詢,并進入棧記錄;若μ<0.75,則采用四叉樹,根據碰撞首位,重新確立八個標簽查詢,并進入棧記錄。
Step5:判斷棧,如果棧空,則結束,如果不為空,跳轉到Step2。
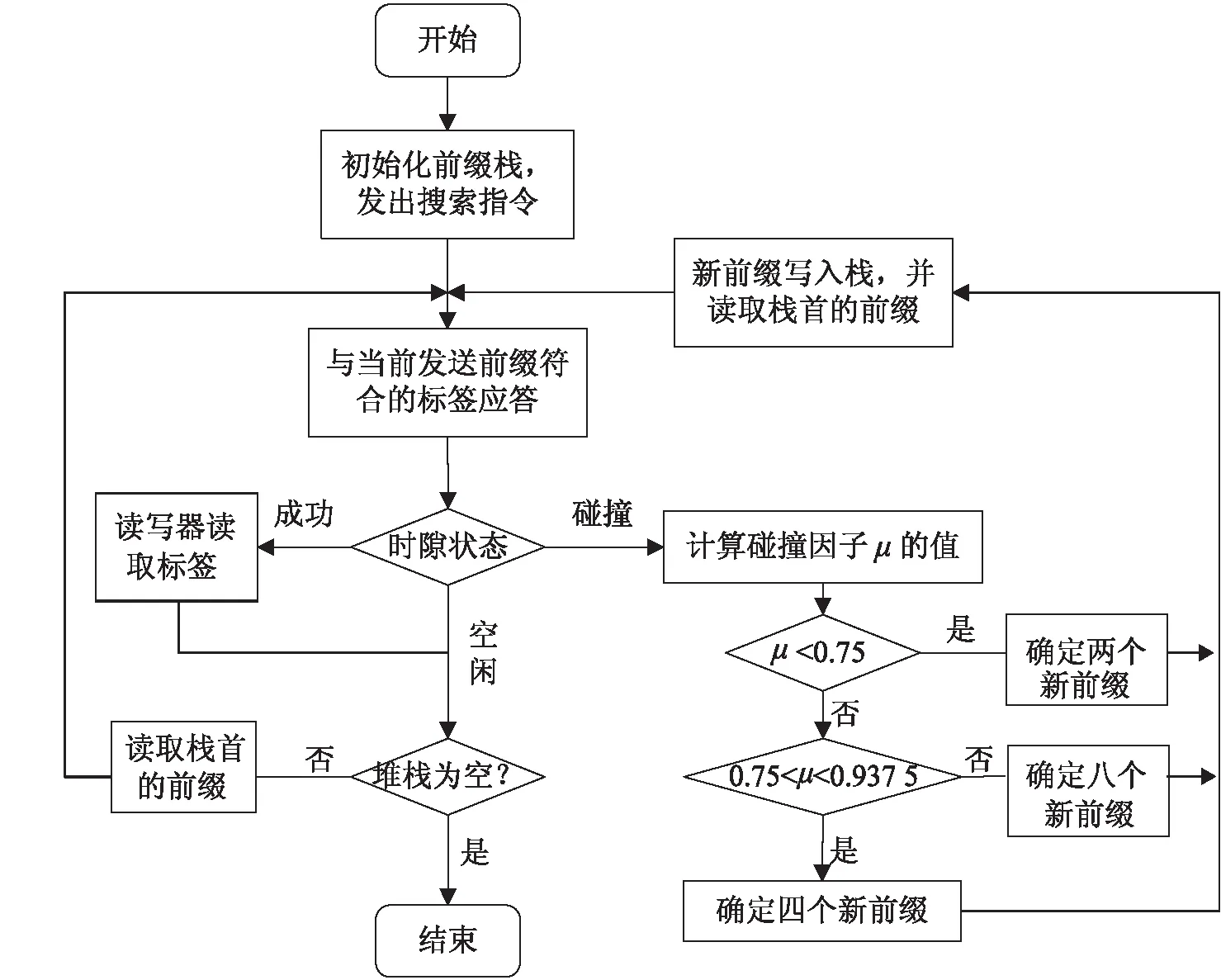
圖2 EIAMS算法流程
3 算法性能分析
標簽在識別過程中的時隙總數即為時間復雜度。假設待識別的標簽數為n,在純二叉樹搜索算法中,總時隙數為2n-1[11];在純四叉樹搜索時,有如下推導的過程:
在純四叉樹中,葉子節點的度為0,記葉子節點個數為n0;其他節點的度為4,記其他節點的個數為n4;此總節點數為N,有:
N=n0+n4
(5)
除根節點,其他所有節點都有一個根,考慮根的個數為:
N=0×n0+4×n4+1
(6)
聯立式1和式2可得:
n0=3×n4+1
(7)
由于n0=n+nk,nk為空閑時隙,因此
n+nk=3×n4+1
(8)
對于一個發生碰撞的時隙,其空閑時隙最大數量為2,最小數量為0。
當一個碰撞產生2個空閑時隙時,nk=2×n4,代入式8可得n=n4+1,時隙總數為N=n+nk+n4=4n-3;當一個碰撞不產生空閑時隙時,nk=0,代入式8可得n=3×n4+1,時隙總數N=n+n4=(4n-1)/3。
因此,在純四叉樹中識別的時隙總數取值范圍為:[(4n-1)/3,4n-3]。
同理可得,在純八叉樹中識別的時隙總數取值范圍為:[(8n-1)/7,8n-7][12]。

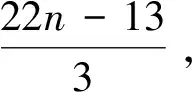
由此可見,改進后的算法與之前的算法相比,在時間復雜度上沒有量的提高,在識別的時隙總數上有較為明顯的減少。因此,改進算法近一步優化了RFID防碰撞算法。
在實際應用中,由于二叉樹、四叉樹、八叉樹在搜索流程中所占比例不同,因此在總時隙處理上不能簡單地進行平均,而是應該進行加權平均。采用平均方法與實際狀況盡管會存在一定差距,不過在總體趨勢上,基本是相同的。
4 實驗仿真分析
根據上面的算法描述,采用MATLAB_R2017a對改進算法與之前常見的二叉樹、四叉樹、二四叉樹等算法進行仿真對比分析。
仿真過程中,四種算法統一采用隨機生成的16位RFID標簽。對不同算法在標簽總數從10到300以步長為10變化,每種算法重復進行1 000次進行仿真,記錄下參數后最后取平均值。圖3為四種算法所需要的總時隙數、吞吐率的比較。
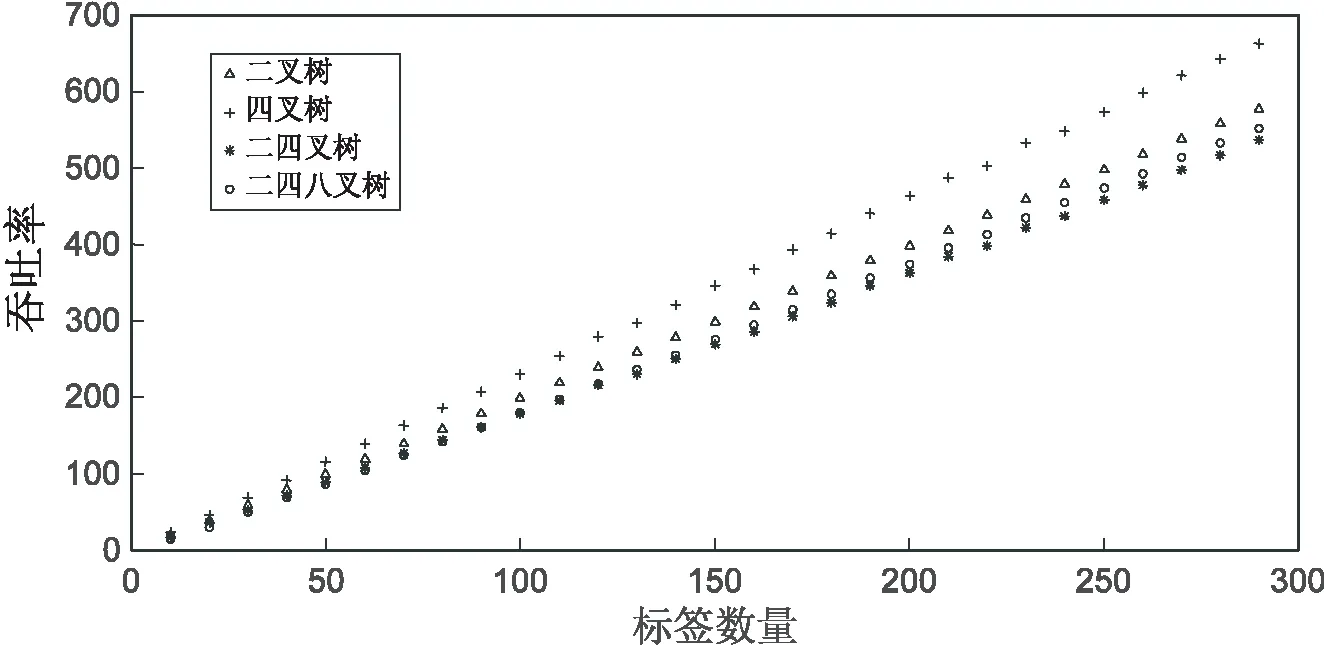
圖3 總時隙數變化仿真圖
為了更好地衡量算法的優化程度,定義算法提升度的概念,根據時隙多少來衡量算法的優化程度,算法提升度公式為:

(9)
將二-四叉樹算法與二四八叉樹算法選擇部分標簽數量,列出算法提升度表格,如表1所示。
根據上述實驗仿真結果可知,從總時隙上看,當標簽在數量較少時,二四八叉樹算法明顯優于二四叉樹;而當大于100時,二四八叉樹卻不如二四叉樹,不過兩種算法相差依然較小。根據算法提升度表格可以看出,隨著標簽數量的提高,與二四叉樹相比改進后的算法提升度在降低。因此,改進后的算法更加適用于中小型系統[13]。

表1 算法提升度
吞吐率變化仿真如圖4所示。
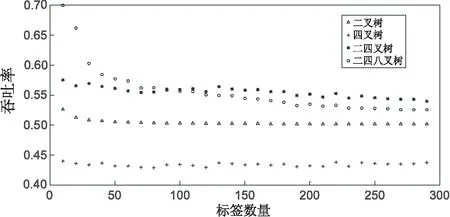
圖4 吞吐率變化仿真圖
從吞吐率看,當標簽在100之內時,二四八叉樹顯然優于二四叉樹,當標簽大于100時,二四叉樹優于二四八叉樹。不過對比單一的二叉樹和四叉樹,二四八叉樹無論在總時隙還是吞吐率上,都有明顯的優化。
可見,在標簽數目比較多,即碰撞率高時,引入八叉樹反而會減弱算法。以4位標簽為例,分析樹形即可發現原因。當采用二四八叉樹時,樹第一層為八叉樹,將前3位標簽分開,由于標簽長度總為偶數,這時必定會有1層需要用二叉樹;如果采用二四叉樹,第一層對應前兩位,第二層對應后兩位,總時隙數比改進后的算法反而要優化。
5 結 論
為解決射頻識別過程中多個標簽同時存在引發的碰撞問題,在自適應二四叉樹防碰撞算法的基礎上,將八叉樹引入,提出了一種改進的自適應的二四八叉樹算法。算法通過計算標簽的碰撞因子,自適應地選擇最優樹的叉樹,然后進行搜索,從而大大減少了空閑時隙。對改進算法進行復雜度分析后,發現改進算法的復雜度與標簽數量近似呈線性關系。
針對不同標簽數量的搜索過程,在總時隙數和吞吐率兩個方面對算法進行仿真。結果表明:當標簽數目較少時,采用二四八叉樹相結合的算法優化效果十分明顯,可以大幅度提高系統吞吐率;不過當標簽數目較多時,二四八叉樹在總時隙數上不如二四叉樹。與單純的二叉樹或者四叉樹相比,不論總時隙數多少,改進后算法都具有明顯的提高。
在實際應用中,如果標簽長度為奇數,或者標簽中有奇數位數未使用,讀卡器不需要識別。這時候采用二四八叉樹將會有較優的結果。
6 結束語
提出了一種改進的自適應的二四八叉樹算法,根據碰撞因子自適應選擇搜索樹的叉數,仿真結果表明,在標簽一定的數量內,算法大幅度減少了總時隙,提高了吞吐率,不過超過一定數量算法性能會降低,適用于小型的射頻識別系統。目前,算法僅僅研究了基于多叉樹二進制防碰撞算法,今后可以在此基礎上,著重研究多種防碰撞算法的混合使用。
