高分一號影像地物識別精度分析
2018-12-26 08:35:42張志勛常永青朱理想
地理空間信息 2018年12期
張志勛,常永青,王 春,朱理想
(1.如皋市勘測院,江蘇 南通 226500;2南京市規劃局,江蘇 南京 210029;3滁州學院,安徽 滁州 239000;4.南京市測繪勘察研究院股份有限公司,江蘇 南京 210019)
隨著高分遙感技術的發展,國內外學者使用高分影像數據進行了廣泛的研究[1-3]。目前國外主要的高分衛星影像數據主要有IKONOS、QuickBird、World View等。高分一號(GF-1)衛星是我國發射的第一顆高分辨率衛星,已經運行超過4 a時間,其獲取的影像主要包括地面分辨率優于2 m的全色影像和地面分辨率優于8 m的多光譜影像,其中多光譜影像主要包括4個波段,分別為藍光波段(0.45~0.52μm)、綠光波段(0.52~0.59μm)、紅光波段(0.63~0.69μm)和近紅外波段(0.77~0.89μm)。目前,高分一號數據被廣泛應用于土地利用、城市發展及農業生產等多個領域[4-6],取得了較好的成果。
在影像數據應用過程中,常涉及到影像的分類問題,而分類精度決定分類結果是否可用。常用的傳統分類方法主要是目視解譯和基于統計分析的分類方法[7],其中基于統計分析的分類方法主要分為監督分類和非監督分類,采用不同的分類方法得到的結果精度也有所差別。目前,在監督分類中,最大似然法(maximum likelihood,ML)[8-9]和支持向量機法(support vector machine,SVM)[10-11]應用最為廣泛。傳統分類方法算法成熟,在軟件中操作簡便。將不同分類方法應用在我國高分影像的分類中,對我國高分影像的影像分類問題的研究具有參考價值。本文采用監督分類和非監督分類對GF-1影像數據進行分類,并對分類結果進行精度驗證,以探討各分類方法在GF-1影像分類中的適用性,尋找最佳分類方法。
1 數據來源
本研究采用的是國產高分衛星GF-1號遙感數據,影像獲取時間為2014-04-27。影像中心坐標為115°55′47″E、40°30′52″N,主要包括北京西北部區域和河北部分區域,選取的實驗區位于北京市延慶區西北部龍慶峽風景區東南部區域,該區域為溫帶季風氣候,以暖溫帶落葉闊葉林為主,其中夾有部分針葉林,耕地主要是旱地。研究區域內影像云量為0,主要地類包括了林地、草地、耕地、水域和建設用地,土地類型相對齊全。

圖1 研究區融合影像
由于多光譜影像與全色波段影像存在空間位置誤差,因此需要對影像進行幾何校正,參照多光譜影像,對全色波段影像進行校準。采用高斯-克呂格投影和二項式校正方式,校準精度小于0.5 個像元。裁剪實驗區域影像數據,采用Gram-Schmidt Spectral Sharpening(GS)融合方法進行影像融合[12],使用標準假彩色(Band4 Band 3 Band 2)顯示(圖1)。
2 研究方法
2.1 分類方法
為尋找到較好的影像分類方法,選取ENVI軟件監督分類方法中的Maximum Likelihood(ML)、Mahalanobis Distance(MsD)、Minimum Distance(MD)和Support Vector Machine(SVM)以及非監督分類方法中的ISODATA和K-Means等分類方法進行影像分類。
2.1.1 ML法
最大似然法是根據像元歸屬概率進行類別劃分的分類方法,其使用的是一個概率模型,分類時假定各類分布函數呈正態分布,因此對選擇的訓練樣本要求較高。分類器公式如下[13]:
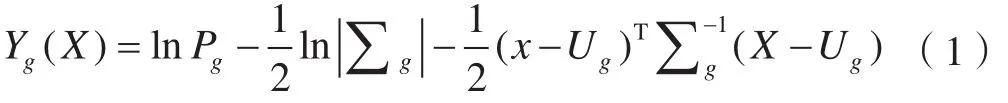
式中,Pg表示第g類樣本的概率;Ug表示第g類樣本的總體均值向量(下同);∑g表示第g類總體協方差矩陣(下同);表示∑g的逆矩陣(下同);X表示像元特征向量,T表示向量轉置(下同)。
2.1.2 MsD法
馬氏距離法根據數據協方差距離,判別影像像元與各地類訓練樣本之間的相似度,進而進行影像分類。馬氏距離公式為[14]:
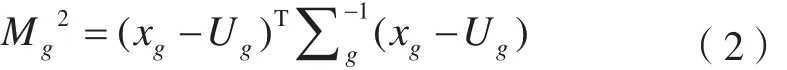
式中,xg表示第g類樣本的m維向量;xg=(x1,x2,……,xm)T。
2.1.3 MD法
最小距離法根據各地類均值向量和標準差向量計算像元到各地類中心的距離,以最小距離為依據進行類別劃分,常采用歐幾里得距離公式[15]:
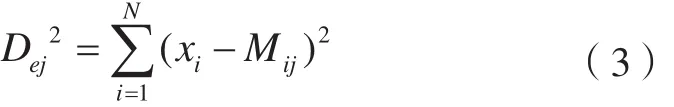
式中,N表示波段數;xi表示像元的第i個波段像元值;Mij表示在第i個波段第j類的像元均值。越小說明該像元越接近第j類地類,歸為值最小的那一地類。
2.1.4 SVM法
支持向量機是能夠基于有限樣本進行統計學習的算法,應用范圍非常廣泛。支持向量機包括了線性和非線性兩種,在圖像分類中對訓練樣本的要求較低。支持向量機分類訓練形式如下[16]:
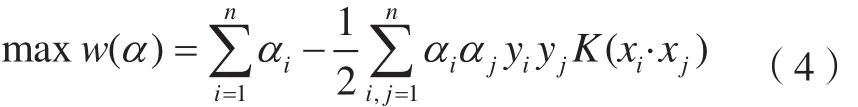
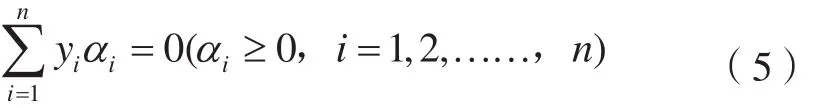
式中,K(xi·xj)=Φ(xi)TΦ(xj)是核函數;一般有線性核、多項式核、RBF核和Sigmoid核等形式。
2.1.5 ISODATA法
迭代自組織數據分析算法是一種典型的非監督分類方法,是一種應用聚類分析思想對像元進行類別劃分的方法。根據不同類別聚類中心的距離判斷進行多次合并與分類,最終得到相對優化的聚類結果。ISODATA算法的詳細步驟參見參考文獻[17]。
2.1.6 K-Means法
K-Means算法也是一種常見的非監督分類方法,采用的是聚類思想,其分類標準是誤差平方和的大小,具體形式如下[18]:
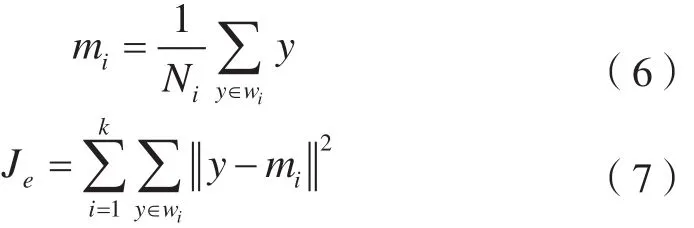
式中,mi表示樣本像元均值;Ni表示第i個聚類wi中的樣本數;Je表示樣本集y和類別集Ω的誤差平方和準則函數。然后進行聚類中心修改,并重新計算Je值,直到其不再發生新值變化。
監督分類需要選擇合適的訓練樣本,一般在樣本選擇時應盡量保證各地類樣本均呈正態分布,同時不同樣本之間應避免重復像元。因此參照Google Earth衛星地圖選擇訓練樣本,在實驗影像上根據研究區實際情況,共分為林草地、耕地、水域和建設用地四大類,每個地類的訓練樣本都不少于100個像元,并對訓練樣本進行可分離性檢驗,可分離系數大于1.9的表示可分離性較好,小于1. 8的需要重新選擇訓練樣本或者進行地類合并。本研究中,除耕地–建設用地可分離系數為1.899外,其他各地類組合類型的可分離系數均大于1.99,訓練樣本滿足要求。非監督分類ISODATA分類中,分類數設置為5~10,最大迭代次數設置為20次,非監督分類K-Means分類中分類數設置為10。
2.2 驗證方法
分類精度驗證主要包括分類面積精度驗證和分類結果空間位置精度(即像元精度)驗證。本研究采用面積統計對分類結果進行面積精度驗證,分別采用基于真實地表感興趣區和目視解譯影像的混淆矩陣,對分類結果進行像元精度驗證。真實地表感興趣區參照Google Earth衛星地圖在研究區影像上進行選擇,由于研究區域范圍較小,因此采用點選式,各地類分別均勻地選取了120個點。目視解譯結果由于可以參考的信息較多,一般與實際地物分布十分接近,可以看成是實際地物分布結果,特別是高分影像,由于地面分辨率較高,其目視解譯的結果與實際地物分布能夠有較高的吻合度。因此參考Google Earth衛星地圖,使用ArcGIS軟件對研究區處理后的影像進行目視解譯,解譯地類與分類地類相同,并在ENVI軟件中將矢量文件轉換為分類影像文件,以目視解譯結果作為真實地類分布。
3 結果分析
3.1 分類結果
分別采用監督分類和非監督分類共6種分類方法進行影像分類,并對研究區影像進行目視解譯,最終結果見圖2。由圖2可以看出,6種分類結果差異較為明顯,尤其是建設用地和耕地的結果,ML、MsD和SVM3種方法的分類結果一致性較好,與目視解譯結果吻合度較高,MD和K-Means分類結果的斑塊完整性較差,斑塊明顯破碎。除K-Means分類外,各分類結果的水域分布總體一致。從目視解譯結果可以看出,研究區內,林地和耕地面積分布最廣,林地、耕地和建設用地之間的交叉區域較多,水域較為集中且與其他地類之間分割明顯。
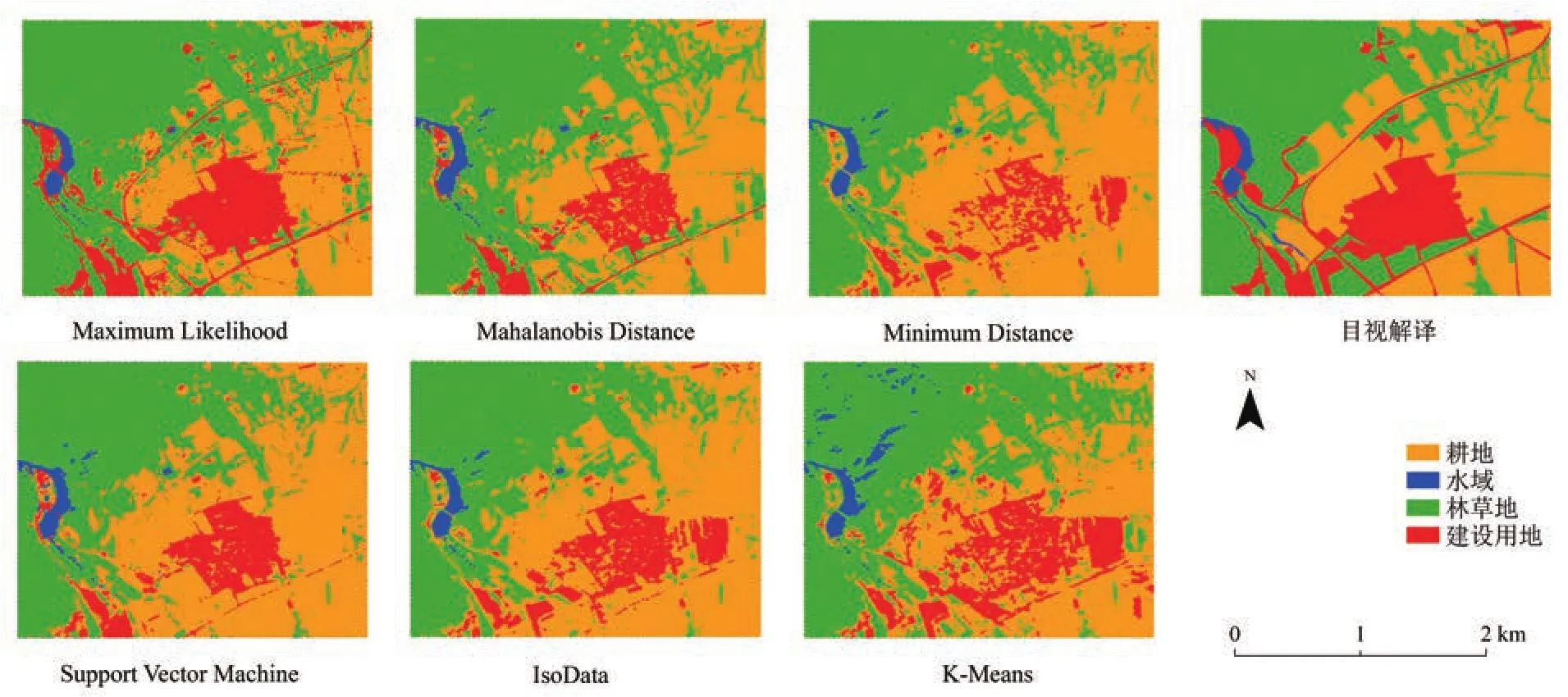
圖2 分類結果
3.2 精度驗證
3.2.1 面積精度
在ENVI軟件中使用統計工具,對各地類的像元數進行統計;在Excel表格中計算各地類的面積,統計面積占比,并計算其相對于目視解譯結果的分類方法的標準誤差和地類標準誤差(表1)。
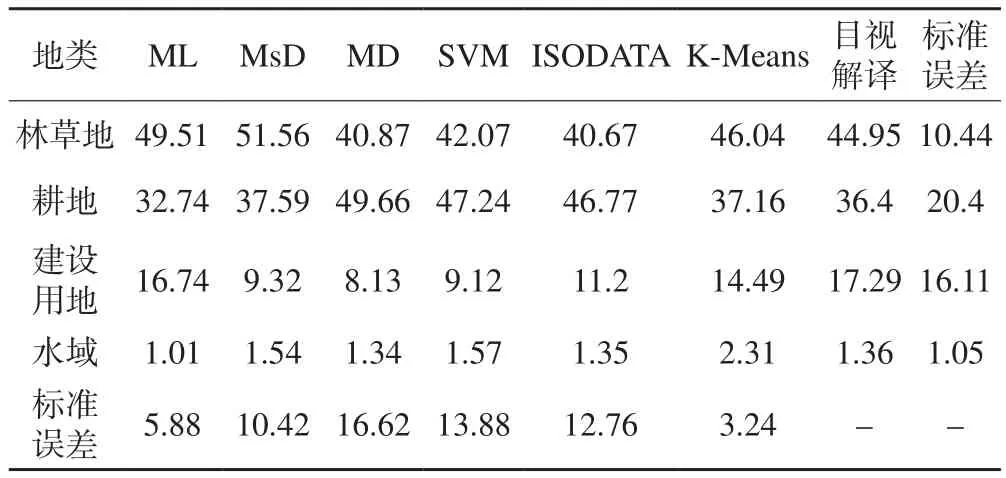
表1 分類結果面積占比統計及標準誤差/%
由表1可知,ML 和MsD分類結果中林草地面積占比明顯多于其他分類方法的分類結果,MD、 SVM和ISODATA分類結果中耕地面積占比最大。從面積占比上看,K-Means分類結果與目視解譯結果最為接近,標準誤差最小,為3.24%,精度最高,其次是ML分類方法,MD和SVM分類結果的面積精度較低。各地類中,水域面積占比標準誤差為1.05,分類精度最高,說明各種分類方法都能夠很好地將水域與其他地類區分開;誤差最大的是耕地,由于耕地類型具有較為復雜的光譜信息,與其他地類存在較多異物同譜的現象,其中作物生長較好的耕地易與林地同譜,土質較硬或沙石較多且處于休耕期的耕地易被分為裸地或建設用地;北方耕地多為旱地,因此與水域不會存在異物同譜現象。
3.2.2 基于地表真實感興趣區的像元精度
使用ENVI軟件,依據實際地類新建一組感興趣區文件,與各分類方法的分類結果進行混淆矩陣分析,統計各分類結果的總體精度、Kappa系數,并計算各地類用戶精度的平均值。計算平均用戶精度是為了避免因某一地類占比過大而導致總體精度和Kappa系數失真的問題,統計結果見表2。
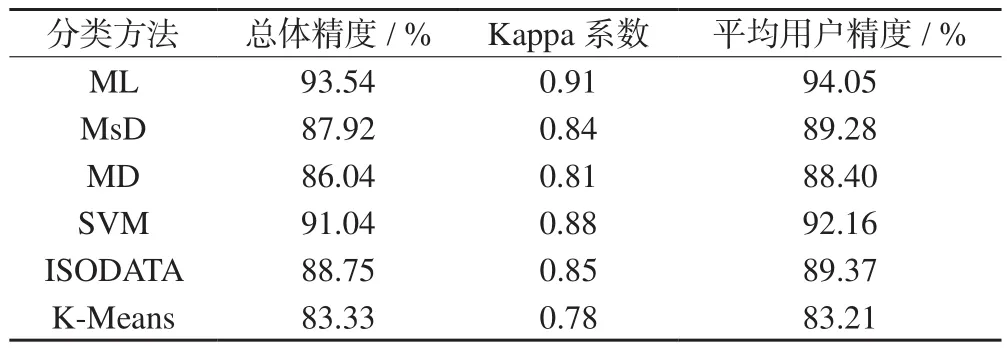
表2 分類精度結果
由表2可知,各分類方法中基于地表真實感興趣區的總體像元精度均高于80%,分類結果較好。其中ML的分類結果總體精度最高,為93.54%,Kappa系數為0.91;其次是SVM分類,總體精度為91.04%,Kappa系數為0.88。監督分類結果明顯好于非監督分類,非監督分類中ISODATA分類結果的精度較好,分類總體精度僅次于ML分類和SVM分類,而K-Means分類結果較差,整體精度在各分類方法中最小。平均用戶精度與總體精度接近,且整體上略高于總體精度,與總體精度相差較小;其中,相差最大的是MD分類,差值為2.36%,說明本研究結果的總體精度受較大地類的影響不明顯,總體精度的結果較為可靠。
3.2.3 基于目視解譯的像元精度
將目視解譯結果作為真實地類影像結果,與各分類方法的分類結果進行混淆矩陣分析,統計各分類結果的總體精度、Kappa系數,并計算各地類用戶精度的平均值,結果見表3。
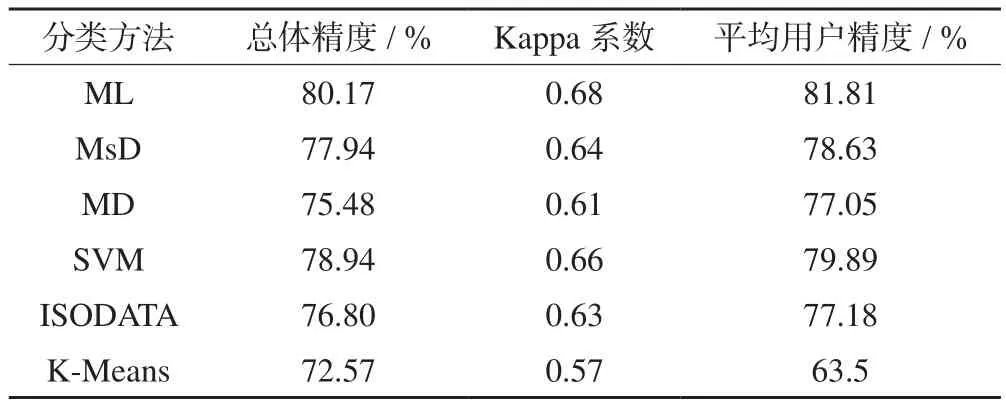
表3 分類精度結果
由表3可知,各分類方法中基于目視解譯的總體像元精度在72.57~80.17%之間,與基于地表真實感興趣區的像元精度相比較低。其中,總體精度最高的是ML分類,為80.17%,其Kappa系數為0.68;其次是SVM分類,總體精度為78.94%,Kappa系數為0.66。與基于地表真實感興趣區的像元精度驗證結果類似,基于目視解譯像元精度驗證中用戶平均精度整體略高于總體精度,總體精度的結果較為可靠,監督分類結果優于非監督分類。
4 結論與討論
本研究基于GF-1號影像數據,通過比較監督分類和非監督分類共6種分類方法的分類精度,得到如下結論:6種分類結果差異較為明顯,但是ML、MsD和SVM 3種方法的分類結果一致性較好;與目視解譯結果相對比,各類分類方法中K-Means分類面積誤差最小,精度最高,其次是ML分類方法;基于地表真實感興趣區和基于目視解譯的像元精度結果趨同,總體精度最高的均為ML分類,監督分類結果整體上優于非監督分類,非監督分類中ISODATA分類結果最好,甚至優于部分監督分類的分類結果。
面積精度最高的K-Means分類的兩種基于像元精度驗證的總體精度分別為83.33%和72.57%,均為精度最低。說明面積精度并不能真實反映分類結果的精度情況,因為分類中存在錯分地物面積相互抵消的情況,這就使得像元精度較低的分類結果可能會有較高的面積精度。因此,在驗證分類結果時,不宜采用面積精度,而應該使用像元精度。
結合兩種基于像元分類精度結果來看,基于地表真實感興趣區的各種分類的總體精度普遍比基于目視解譯的高出11個百分點左右。為驗證地表真實感興趣區與目視解譯結果的一致性,將地表真實感興趣區與目視解譯數據進行混淆矩陣分析,結果顯示,二者的總體精度為98.33%,說明地表真實感興趣區的選擇與目視解譯結果基本一致,二者可以相互驗證。在實際工作中,我們大多數情況下無法使用目視解譯數據進行精度驗證,更多的是采用基于地表真實感興趣區的混淆矩陣來驗證分類結果。通過本研究發現,基于地表真實感興趣區和基于目視解譯的驗證結果趨勢相同,因此基于地表真實感興趣區的混淆矩陣可以很好地代替目視解譯結果來進行精度驗證。但是在驗證時,應該扣除一個經驗值以更加接近實際的精度值,本研究中,這個經驗值約為11%。
本研究中采用的分類方法是常用的監督分類和非監督分類方法,主要存在同物異譜和異物同譜的問題,影響分類精度,而目前面向對象的分類方法較好地解決了這一問題,在影像分類中得到了廣泛的應用。因此,比較面向對象的分類方法與傳統監督和非監督分類方法的分類精度將是下一步研究的重點。本文中選取的研究區域較小,而且僅基于一個時期的一景影像中的部分區域進行研究,數據豐富度較低,在后續的研究中將增加不同時期、不同區域的數據進行比較研究,以提高數據豐富度,增加研究結果的可信度。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
