結合改進聚合通道特征和灰度共生矩陣的俯視行人檢測算法
2019-01-07 12:16:28李琳,張濤
計算機應用 2018年12期
李 琳,張 濤
(信息工程大學,鄭州 450001)(*通信作者電子郵箱llbnerfg@163.com)
0 引言
目前,智能監控場景下的俯視行人檢測技術被廣泛應用于人流量統計[1]以及行人智能分析[2]中,以實現對人流量密集場所的有效監管。基于俯視的行人檢測近些年取得了突飛猛進的發展;然而行人的發型、發色以及復雜的周圍背景加大了檢測的難度,導致檢測效果仍不理想,需進一步改進。因此,俯視行人檢測技術具有極大的研究空間和重要的現實意義。本文重點研究在復雜背景下,基于俯視視角的行人檢測。
俯視行人檢測方法有以下幾類。第一類是基于形狀分析的方法,主要思想是通過描述行人頭部的外觀形狀,逐個篩選圖像樣本,得到最終檢測結果。Chen等[3]通過計算區域面積來識別行人頭部;Yu等[4]采用改進后的Hough變換,通過檢測類圓來達到檢測行人頭部的目的;Li等[5]通過Canny邊緣提取算法和Hough變換結合來提取行人頭部特征。基于形狀分析的方法計算效率高,但是實際檢測過程中,容易將外觀類似頭部的背景誤檢為目標。第二類是基于機器學習的方法,隨著機器學習的蓬勃發展,基于機器學習的特征提取法逐步成為俯視行人檢測的常用方法。此類方法首先借助合適的特征描述子,對樣本圖片進行特征提取,之后根據大量訓練樣本構建俯視行人頭部檢測分類器,在此基礎上采用分類器進行分類。相比于形狀分析法,機器學習法能適應環境的變化,在很大程度上提高了檢測系統的魯棒性。牛勝石等[6]在梯度特征中加入自生長梯度特征,并采用支持向量機(Support Vector Machine, SVM)和Adaboost組合分類器進行訓練;湯石晨等[7]通過線性回歸模型訓練行人的面積特征來檢測運動斑塊中的頭部目標;Li等[8]采用局部二值模式(Local Binary Pattern, LBP)提取行人頭部特征,輸入Adaboost進行分類訓練;Tang等[9]采用改進后的梯度方向直方圖(Histogram of Oriented Gradients, HOG)描述子提取行人頭部特征,輸入SVM分類器訓練得到分類模型。
上述方法通過提取具有一定魯棒性的特征來訓練分類器,達到了很好的分類效果,但是只利用單一的特征進行訓練容易造成較高誤檢。在實際的監控視頻中,存在諸多具有干擾性的背景,比如:行人穿著的接近發色的深色衣服、行人隨身攜帶的背包,以及在其他方面與行人頭部相似的物體。這些干擾的存在加大了檢測的難度。單一的特征分類器在這種場景下的檢測率較低,這是因為在背景存在諸多干擾時,單一的特征往往不能夠全面地描述行人頭部,易使分類器混淆行人頭部和其他干擾背景,造成誤檢與漏檢,所以研究者嘗試使用多種特征來刻畫行人目標。Liu等[10]結合行人頭部顏色和形狀描述子來提取行人頭部特征,提高了算法的檢測準確率;Zeng等[11]采用俯視行人的頭肩模型,通過HOG-LBP特征構建行人特征描述子,該算法很好地表征目標的輪廓和形狀,并且具有良好的灰度不變性。多特征融合的方法在很大程度上改善了分類器的分類效果。然而,幾個單一特征的結合不僅提高算法性能有限,并且增大了計算復雜度。所以如何選擇合適的特征使分類器在提高檢測率的同時保持較快的檢測速度是當前的研究重點。
在上述研究的基礎上,本文提出了結合改進聚合通道特征(ACF)和灰度共生矩陣(GLCM)的俯視行人檢測算法。首先,改進ACF的顏色通道以及梯度直方圖通道;然后,嘗試采用多特征融合的方法,將改進后的ACF特征與GLCM結合起來,分別提取目標的顏色、梯度、梯度方向直方圖以及紋理特征,輸入Adaboost算法進行訓練檢測得到結果。實驗結果表明,所提多特征融合的方法,能夠過濾掉與人頭相似的背景,有效降低分類器的漏檢與誤檢率,實現了較高的檢測性能。
1 特征分析
1.1 改進的聚合通道特征
1.1.1 特征描述
ACF特征起初被用來解決人臉識別問題,之后逐漸被應用于行人檢測中。ACF特征的基本結構是通道,它分別采用顏色、梯度以及梯度方向直方圖三個不同的通道描述圖像。這種混合通道的采用大大提高了描述子對不同種類信息的分類表示能力,有助于提高復雜背景下目標的檢測效果。
ACF特征的計算流程示意圖如圖1所示,在積分通道特征的基礎上,ACF描述子采用特征金字塔算法提高了特征提取的速度。下面就該描述子的計算方法進行簡要介紹。
1)通道類型。ACF特征定義了10個通道,分別是3個LUV顏色通道、1個梯度通道和6個梯度方向直方圖通道。計算梯度幅值的過程采用一維微分模板[-1,0,1]和[1,0,-1]分別得到水平方向的梯度分量Gx(x,y)和豎直方向的梯度分量Gy(x,y)。梯度方向直方圖通道遵循HOG的思想,構造方式是將圖像均勻分割成若干塊,計算每個塊中像素的梯度方向,將其按照劃分的6個梯度方向區域進行統計,其中每一個方向區域都分別是1個特征通道。圖像中像素點(x,y)的梯度幅值和梯度方向計算式如式(1)、(2)所示:
(1)
a(x,y)=arctan(Gy(x,y)/Gx(x,y))
(2)
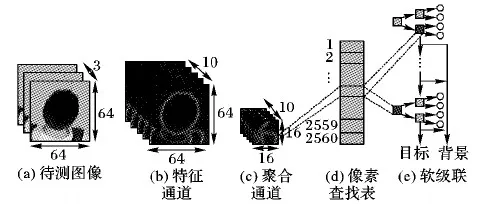
圖1 聚合通道特征計算示意圖Fig. 1 Schematic diagram of aggregate channel features
2)特征計算。聚合通道的特征計算十分簡單,首先給定一個彩色圖像作為輸入,計算預定義的通道。然后,根據預設因子對通道特征進行平均池化下采樣,將下采樣得到的矩陣矢量化為像素查找表,該矢量即為最終的特征描述子。
3)多尺度計算。為了提升計算效率,ACF特征采用一種特征金字塔算法。在行人檢測中,目標的高矮、遠近導致它到攝像頭的距離不同,如果采用相同的尺度檢測目標會導致漏檢和誤檢,采用多尺度計算能夠有效解決這一問題。傳統的做法是先將圖像進行重采樣縮放到若干尺度,再采用滑動窗口法計算每個尺度下圖像的特征。這種方法存在冗余計算,且耗時大。而ACF算法則先計算幾個特定尺度層s∈{1,1/2,1/4,…}下的特征,然后直接使用一種快速估計算法計算其余中間尺度下的特征值。采用快速特征金字塔作為估計算法,利用近似公式(3),在允許的誤差范圍內根據當前尺度的特征C估計相鄰尺度上對應的通道特征:
Cs≈R(C,s)·s-λΩ
(3)
式中,λΩ表示每個通道特征對應的系數。
1.1.2 改進顏色通道
ACF特征通道中融合了LUV顏色描述子。對于顏色通道的選擇,本文作出改進,選用更適合的HSV(Hue, Sturation, Value)顏色通道代替原先使用的LUV顏色通道。
HSV顏色空間[14]屬于非線性色彩表示系統,它的顏色參數分別是:色調(H),飽和度(S)和亮度(V)。HSV顏色空間對色彩的感知和人十分接近,它能夠從人類的視角非常直觀地表達色彩信息,達到更好的顏色對比效果。HSV顏色通道能夠更細致地刻畫目標和背景之間的灰度差別,有效提高檢測率。利用RGB(Red, Green, Blue)計算HSV顏色空間的計算式如下:
S=
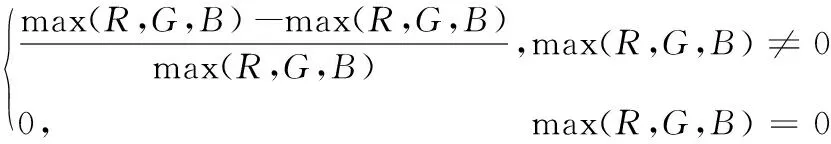
(4)
H=
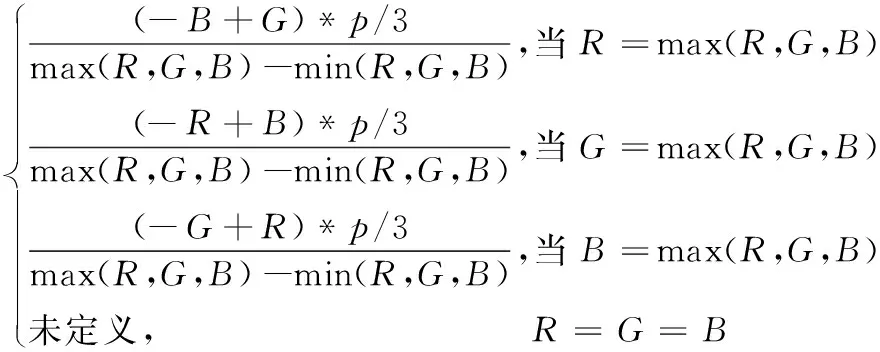
(5)
V=max(R,G,B)
(6)
1.1.3 改進HOG通道
傳統HOG算法[15]的基本思想是通過提取圖片的梯度大小和方向來描述行人特征。它將圖像分成小的連通區域,名為細胞單元(cell),然后統計每個胞元內部像素的梯度和方向直方圖,隨后對梯度強度作歸一化,將胞元有一定重疊地組合成塊(block),以梯度作為權重統計塊內像素的方向直方圖,串聯起來得到最終的HOG特征。
HOG描述子對幾何和光學形變有良好魯棒性,但同時,它也存在著計算量大的缺陷。為了提高算法的實時性,本文結合行人頭部的特點,對HOG描述子作出如下改進,在不影響檢測性能的基礎上縮短提取特征的時間。
首先,由于俯視行人的頭部特征形狀近似圓形,較為統一,細節特征較少,所以考慮不再將塊進一步細分為更小的細胞單元,并且采用無重疊的子塊,減少提取到的冗余信息。其次,本文考慮將0°~180°的角度范圍擴展至-180°~180°,這樣能夠更完整地體現目標的變化特征。
對改進前后的HOG特征維數進行對比。當檢測圖像大小為64×64時,傳統HOG算法將方向直方圖劃分為6個相等大小的區域,采用8×8大小的像素組成一個胞元,每2×2大小的胞元組成一個塊,且移動步長為8,則傳統HOG描述子的維數為6×4×7×7=1 176。而本文改進算法將圖像等分成4×4共16個方形塊,塊與塊之間互不重疊,則改進后的HOG描述子只有16×6=96維。相比于傳統方法,本文提出的改進算法突出了俯視行人的紋理和顏色特征,弱化了不必要的細節特征,大大降低了傳統HOG描述子的維數,在保證分類準確率的前提下,減少了冗余的計算量。
1.2 改進的紋理特征
本文采用灰度共生矩陣來描述圖像的紋理特征。灰度共生矩陣通過統計圖像中一定距離d和一定方向θ上兩像素點灰度的空間相關性來描述紋理。
灰度共生矩陣定義彼此距離為d、方向夾角為θ的一對像素,其灰度值分別為i和j時的概率,記為P(i,j,d,θ)。通常方向夾角選取0°、45°、90°、135°四個方向。下面給出像素灰度值分別為f(x1,y1)=a與f(x2,y2)=b的像素距離為d時的灰度共生矩陣計算公式:
P(i,j,d,0°)=#{((x1,y1),(x2,y2))∈(Lr,Lc)×
(Lr,Lc)|x2-x1=0,|y2-y1|=d,
f(x1,y1)=i,f(x2,y2)=j}
(7)
P(i,j,d,45°)=#{((x1,y1),(x2,y2))∈(Lr,Lc)×
(Lr,Lc)| (x2-x1=d,y2-y1=d) or (x2-x1=-d,
y2-y1=-d),f(x1,y1)=i,f(x2,y2)=j}
(8)
P(i,j,d,90°)=#{((x1,y1),(x2,y2))∈(Lr,Lc)×
(Lr,Lc)| |x2-x1|=d,y2-y1=0,
f(x1,y1)=i,f(x2,y2)=j}
(9)
P(i,j,d,135°)=#{((x1,y1),(x2,y2))∈(Lr,Lc)×
(Lr,Lc)| (x2-x1=d,y2-y1=-d) or (x2-x1=-d,
y2-y1=d),f(x1,y1)=i,f(x2,y2)=j}
(10)
其中:L為圖像的灰度級;Lr和Lc分別表示圖像的行數和列數;#{·}表示該集合中的元素個數。
由于直接將灰度共生矩陣送入分類器會產生較大計算量,所以為了減小計算復雜度,本文采用文獻[13]提出的4種特征參數來間接描述圖像的紋理特征。
1)能量。
能量特征參數又被稱為二階矩,它是矩陣值的平方和。能量的大小表示的是圖像灰度分布的勻稱度以及紋理細膩度。若一幅圖像的灰度分布均勻且紋理細膩,則能量值小;反之,如果圖像中的灰度分布不均且紋理粗糙,則能量值大。能量的計算式如下:
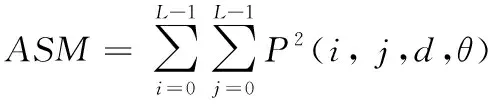
(11)
2)熵。
灰度共生矩陣的熵能夠反映出圖像中攜帶的信息量多少,屬于隨機性度量值。當圖像的灰度共生矩陣中所有值均相等時,圖像的隨機性較大,熵值大;相反,當圖像灰度共生矩陣中的值分布不均時,圖像的隨機性較小,熵值小。熵值的計算式如下:
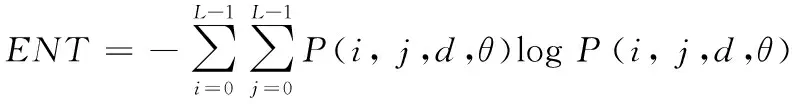
(12)
3)對比度。
對比度指的是灰度共生矩陣主對角線附近的慣性矩,主要用來表示圖像的清晰度以及溝紋深淺程度。如果圖像清晰且紋理溝紋深,則對比度大;而當圖像模糊且溝紋較淺時,對比度小。對比度采用式(13)進行計算:
(13)
4)相關度。
相關度是用來度量灰度共生矩陣的元素在水平或垂直方向上的相似度。當矩陣中的值變化較小時或者圖像紋理具備一些規律性時,相關值大;當矩陣中各元素的值相差很大時,相關值小。相關度的計算式如下:
(14)
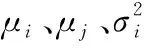
(15)
(16)
(17)
(18)
灰度共生矩陣的特征參數能夠對紋理進行細致的刻畫。為了驗證灰度共生矩陣作為分類特征的有效性,隨機選取100張行人頭部圖像,以及100張干擾背景圖像(包括深色背包、衣服等),分別計算所有行人頭部和所有干擾背景在4個方向0°、45°、 90°、 135°上的特征參數,取平均值進行對比,結果如圖2所示。實驗中取灰度級為L=16,距離d=1。由圖2可以看出,頭部目標和干擾背景的特征值之間存在明顯差異,因此將灰度共生矩陣作為附加的特征輸入分類器能夠有效降低因干擾背景導致的誤檢率。
由于灰度共生矩陣的特征維數只有4維,過低的維數會導致較差的分類效果。所以本文參考文獻[13]中的方法,在訓練過程中采用大小為8×8、步長為6的窗口,按照從左至右、從上至下的順序依次在圖像上滑動,計算每個窗口內的特征參數。將每個窗口的4維特征參數依次串聯起來,得到最終的灰度共生矩陣描述子,維數為10×10×4=400。這種基于小區域計算共生矩陣的方法不僅大幅度提高了訓練效果,并且由于是在局部方格上進行操作,所以提取到的特征對圖像的幾何和光學形變具有良好的不變性。
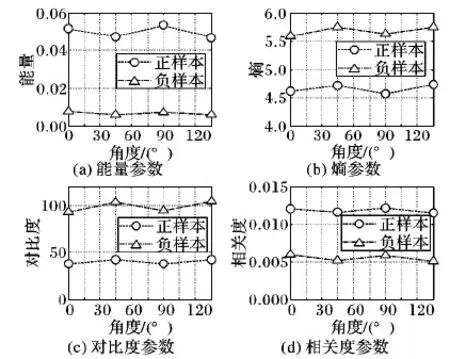
圖2 四種特征參數對比Fig. 2 Parameter comparison of four kinds of features
1.3 軟級聯Adaboost分類器
傳統Adaboost算法的基本思想是將K個弱分類器(Weak classifier)級聯組成更強的強分類器H(x)。
為了提升分類效果,本文采用深度為2的決策樹作為弱分類器,并且使用軟級聯Adaboost[16]取代傳統分類器以實現更優的分類性能。
軟級聯Adaboost分類器相對于傳統Adaboost分類器在算法上有了改進。不同于傳統方法需要反復的調參才能獲得近似最優的級聯結構,軟級聯方法在每個弱分類器之后都設置了一個閾值,樣本每通過一個弱分類器就作出一次決策,從而使分類器的復雜度和分類能力得到逐級提升,實現了更好的分類性能。
2 結合改進ACF和GLCM的俯視行人檢測算法
2.1 算法流程
本文從多特征融合的角度出發,分別提取圖像的聚合通道特征(ACF)和灰度共生矩陣(GLCM)特征,利用Adaboost分類器進行訓練,得到分類器1和分類器2,以級聯的方式將聚合通道特征和灰度共生矩陣特征參數訓練得到的兩個分類器結合起來,采取這樣的方法能夠有效過濾掉干擾背景,準確檢測出目標。本文算法流程如圖3所示,具體步驟如下。
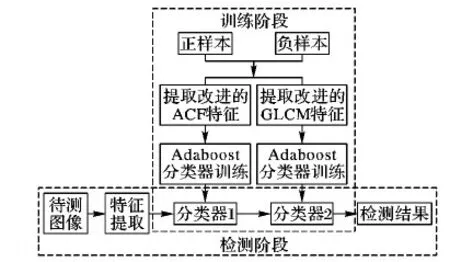
圖3 本文算法流程Fig. 3 Flow chart of the proposed algorithm
2.2 訓練階段
訓練階段的步驟如下:
1)將訓練的正樣本和負樣本歸一化至64×64大小,灰度化之后作為輸入。對樣本進行下采樣得到大小為16×16的圖像,分別計算訓練樣本10個通道的ACF特征,其中包括3個HSV通道、6個改進的HOG通道,以及1個梯度幅值通道。計算得到特征向量。
2)采用區域法計算歸一化后正負樣本的灰度共生矩陣,選取塊大小為8、步長為6、灰度級為16、距離為1、方向為0°。利用得到的共生矩陣,分別計算能量、熵、對比度和相關度,得到4維的特征參數。最終每個樣本得到400維特征向量。
3)將得到的聚合通道特征向量和灰度共生矩陣特征向量分別送入軟級聯Adaboost分類器進行訓練,其中:軟級聯閾值設置為-1,弱分類器個數為128。得到分類器1和分類器2,用于后續的測試。
2.3 測試階段
測試階段的步驟如下:
1)首先按幀讀入圖像,進行圖像灰度化。采用滑動窗口法計算原圖的ACF特征,窗口大小為64×64。利用特征金字塔的思想直接對圖像特征進行縮放,得到不同尺度圖像下的特征向量。
2)將計算得到的特征向量送入Adaboost分類器1進行分類得到檢測結果的坐標(bounding box)和目標窗口。將檢測到的行人頭部窗口以及其坐標作為候選目標,進行下一步的篩選。計算該目標的共生矩陣參數向量,輸入分類器2,排除干擾背景,得到最終的輸出結果。
3 實驗結果及分析
為了驗證本文所提算法的有效性,在配置為Intel Core i5 CPU 2.40 GHz、內存6.00 GB的計算機上采用Matlab 2014平臺編寫算法驗證實驗。本文研究的對象是俯視鏡頭下拍攝到的行人目標。實驗用到的樣本圖像取自某學校食堂抓拍的彩色監控圖像序列,分辨率為320×240。訓練集中的正樣本通過人工裁剪圖像序列中的頭部目標區域得到,樣本大小為64×64,數量為850張。在截取的頭部樣本中,約60%的頭部樣本選取較為規范的類圓形頭像,約40%的頭部樣本則選取一些發型發色不規律的人頭像,采用上述樣本集訓練得到的分類器泛化能力較強。訓練集中的負樣本從1 000多張不含行人的圖片中隨機截取得到,大小為64×64,數量為4 000張。從監控序列中選取完整連續的3段視頻圖像序列作為測試視頻,每段視頻有200幀,其中每幀至少有1個行人目標,行進速度和方向均為隨機。用于測試的圖像序列中具有較多干擾背景如深色的背包、服裝等,且序列中頭部目標包含多種發型及發色,增大了檢測難度。測試集樣本與訓練集樣本沒有重疊。
對比實驗采用準確率(precision)和召回率(recall)作為最終評價指標,計算式如下:
precision=tp/(tp+fp)
(19)
recall=tp/(tp+fn)
(20)
其中:tp是正確檢測的行人數目;fn是漏檢的人數;fp是算法誤檢出的行人數目。所以,tp+fp是算法總共檢出的行人總數,tp+fn是所有正樣本的數目。
實驗采用本文算法和文獻[12]中所提的ACF算法進行測試對比,結果如表1所示。
從表1中可以看出,本文提出的方法明顯縮減了漏檢和誤檢人數,在準確率和召回率上都比文獻[12]方法略高。一方面,本文采用的HSV顏色通道相比LUV通道能夠達到更好的顏色對比效果,能夠提取出魯棒性更強的顏色特征;另一方面,本文結合了顏色、梯度、梯度方向直方圖以及紋理4種特征,把改進后的聚合通道特征和灰度共生矩陣融合起來,將聚合特征描述子檢測到的目標窗口輸入灰度共生矩陣紋理描述子中進行篩選,極大程度上減少了誤檢與漏檢目標,提高了準確率和召回率。兩種檢測方法的檢測結果如圖4所示。

表1 不同方法實驗結果對比Tab. 1 Comparison of experimental results of different methods
在Matlab 2014環境下,一幅320×240的RGB圖像,用傳統ACF算法結合灰度共生矩陣檢測需要2 s,而本文算法需要約0.5 s,提升了運算速度。

圖4 俯視行人不同算法檢測結果對比Fig. 4 Zenithal pedestrian detection result comparison of different algorithms
4 結語
本文提出了一種針對俯視視角的行人檢測算法,從多特征融合的角度出發,將改進后的聚合通道特征和灰度共生矩陣訓練得到的分類器級聯起來,通過逐級篩選的方式進行分類,得到檢測結果。該算法融合了顏色、梯度、梯度方向直方圖和紋理特征,通過從不同角度描述行人來有效檢測行人頭部,減小了干擾背景對分類的影響,大幅提高了檢測性能,為后續的行人跟蹤與智能分析奠定了良好基礎。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
