CNN加速器中卷積計算單元的硬件設計
2019-01-08 08:37:44楊博文楊海濤高浩浩
數字技術與應用 2019年10期
楊博文 楊海濤 高浩浩

摘要:卷積神經網絡(CNN)所有子層中卷積層的計算是整個網絡計算中最耗費計算資源的問題,本文提出了一種對卷積神經網絡的卷積層并行化實現方案。首先對系統的整體處理結構進行分析,然后對計算核的結構進行詳細討論,最后將卷積層中卷積運算并行映射到陣列處理器上。實驗結果表明,在250Mhz的工作頻率下,該結構可使FPGA(Field Programmable Gate Array,FPGA)提高峰值運算速度。
關鍵詞:卷積神經網絡;現場可編程門陣列;卷積層
中圖分類號:TP391.4 文獻標識碼:A 文章編號:1007-9416(2019)10-0136-02
CNN是著名的深度學習架構,從人工神經網絡擴展而來,它已經大量用于不同應用,包括視頻監控,移動機器人視覺,數據中心的圖像搜索引擎等[1-2]。由于CNN的特殊計算模式,通用處理器實現CNN并不高效,所以很難滿足性能需求[4]。于是,基于FPGA,GPU甚至ASIC的不同加速器被相繼提出以提升CNN設計性能[5-6]。卷積神經網絡加速器主要由卷積、池化、數據選擇、輸入輸出緩存等單元組成,其中卷積模塊根據多個一定的權重(即卷積核),對一個塊的像素進行內積運算,它的輸出就是提取的特征之一,但因為卷積核的大小一般小于輸入圖像的大小,因此卷積提取出的特征更多的關注的是局部信息[3]。卷積計算單元是計算核的主要模塊,主要的功能是對輸入數據進行特征提取,其內部包含多個卷積核,組成卷積核的每個元素都對應一個權重系數和一個偏差量。
1 卷積計算模塊設計
卷積運算是兩個卷積核大小的矩陣的內積運算,即相同位置的數字相乘再相加求和。通常情況下,靠近輸入的卷積層,譬如第一層卷積層,會找出一些共性的特征,如手寫數字識別中第一層一般是找出諸如“橫線”、“豎線”、“斜線”等共同特征,稱之為基本特征,經過池化操作后,在第二層卷積層,可以找出一些相對復雜的特征,如“橫折”、“左半圓”、“右半圓”等特征,越往后,卷積核設定的數目越多,體現出的特征越細致。
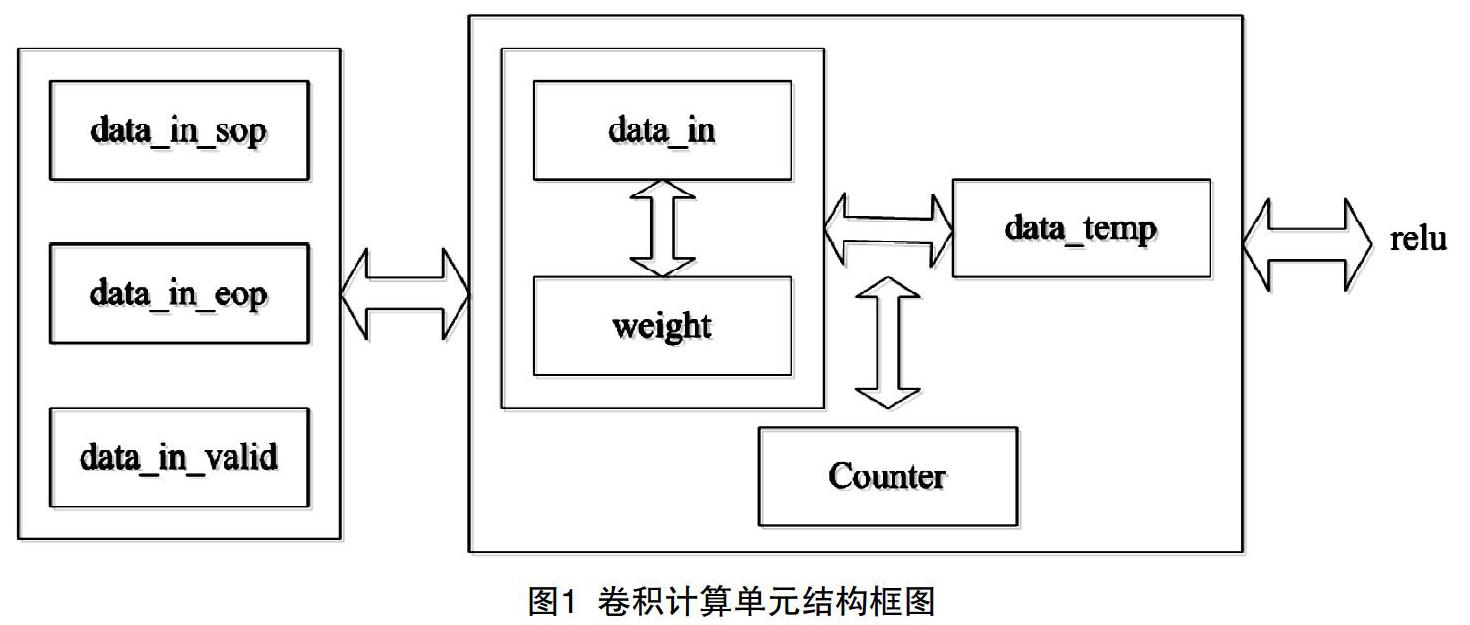
卷積計算單元的結構框圖如圖1所示,主要由數據輸入信號data_in和權重輸入信號weight_in進行卷積計算,當信號data_in_sop為1時,則判斷信號data_in_valid為高,即輸入數據有效,當data_in_eop信號為1時,則數據有效信號為低,讀入數據結束。當復位信號為低時,輸入原始數據的中間寄存器data_in_temp和weight_in_temp為0,當復位信號拉高時,中間寄存器data_in_temp和weight_in_temp分別等于輸入的信號data_in和weight_in。因為網絡中存在不同大小的卷積操作,通過全局控制器counter_control信號對網絡的計算進行控制,當counter_control為0時,表示網絡的第一層計算,則控制不同大小計算的寄存器max為121,支持網絡中的11×11塊大小的卷積運算;當counter_control大于1小于105時,表示網絡的第二層計算,則控制不同大小計算的寄存器max為25,支持網絡中的5×5塊大小的卷積運算;當counter_control大于106小于419時,表示網絡的第三、四、五層計算,則控制不同大小計算的寄存器max為9,支持網絡中的3×3塊大小的卷積運算。在計算卷積操作之前,定義寄存器counter用于計數,當data_in_valid為高,counter等于max時,則計數器歸1,重新開始計數;當counter不等于max時,則計數器counter自加1,否則為0,依次循環。
執行卷積操作時,當計算器counter等于1時,中間結果信號data_temp等于輸入原始數據和權重乘積;當計算器counter大于2小于max時,中間結果信號data_temp等于輸入原始數據和權重乘積加前面的中間結果。當counter等于max時,執行ReLU操作,對得到的最終結果進行判斷,當data_temp大于等于0,則輸出信號data_out等于data_temp,否則置為0。其中,當data_in_valid為高且counter與max相等,則輸出有效信號data_out_valid為1,否則為0;當data_in_valid為高且counter_sop與max相等,則輸出開始信號為1,否則為0;數據輸出結束信號data_out_eop比輸入結束信號延兩拍。
2 實驗結果
在Zynq-7000 XC7Z045-2FFG900CFPGA上電路綜合成功后生成的全局時序報告,工作頻率為250Mhz。如表1所示芯片資源利用率情況,開發板上的資源足夠充足,可以滿足工程實現需要的資源,符合設計的要求。
參考文獻
[1] 雷杰,高鑫,宋杰,etal.深度網絡模型壓縮綜述[J].軟件學報,2018,29(2):251-266.
[2] 王磊,趙英海,楊國順,etal.面向嵌入式應用的深度神經網絡模型壓縮技術綜述[J].北京交通大學學報:自然科學版,2017,41(06):34-41.
[3] 蹇強,張培勇,王雪潔.一種可配置的CNN協加速器的FPGA實現方法[J].電子學報,2019,47(7):1525-1531.
[4] 趙彤,喬廬峰,陳慶華.一種基于FPGA的CNN加速器設計[J].通信技術,2019(5):1242-1248.
[5] 趙博然.FPGA實現的可編程神經網絡處理器[D].西安電子科技大學,2018.
[6] 周飛燕,金林鵬,董軍.卷積神經網絡研究綜述[J].計算機學報,2017,40(6):1229-1251.
